
Chapter 17. Case study: Shop It To Me
- Speed and scale considerations for the classifier system
- How the training pipeline was constructed
- Restructuring classification for very high throughput
So far, the chapters on classification have presented an overview of classification plus detailed explanations of what it takes to design and train a Mahout classifier, evaluate the trained models in order to adjust performance to the desired level, and deploy the classifier into large-scale systems. This chapter puts all those topics into practice in a case study drawn from a real-world online marketing company, called Shop It To Me (http://www.shopittome.com/), that selected Mahout as their approach to classification. You’ll examine the issues their small engineering team faced in building and deploying a high-performance Mahout-based classifier and see the solutions they came up with.
Chapter 16 focused on the scale requirements of the very large systems that are best served by Mahout classification. Similarly, the case study presented in this chapter deals with large data sets, but it also affords a look at a system with speed requirements that are extreme, even for Mahout systems. Because of the scale and especially the speed required, some of the solutions the team designed required substantial innovations. Overall, the system described in this chapter shows how you can push Mahout classifiers farther than appears possible at first glance.
After introducing the Shop It To Me system, we’ll look at how the outbound email system works and describe the data that the system produces. The goal of the case study classifier is presented along with the steps taken in training the model. Then we examine how the Shop It To Me team made the training and model computations go fast enough to meet their business requirements.
Finally, we bring together the lessons to be learned from this case study so that you can apply what you learn here to projects of your own.
17.1. Why Shop It To Me chose Mahout
The Shop It To Me marketing case study will show why Mahout can be ideal to solve problems of scale and speed that don’t yield well to other approaches. But in order for you to appreciate the challenges described in the case study, it’s helpful to have some background information about the company. Let’s look at what Shop It To Me does, what they wanted a classification system to do, and why they chose Mahout to build that system.
17.1.1. What Shop It To Me does
Shop It To Me is a free online personal shopper service that provides email notifications about sales (SaleMails) of interest to their customers. Their mission is to effectively connect a shopper with a list of sale items that are appropriate to the tastes of the customer and to do so in a timely manner. The latter is particularly important, because the business often deals with products that are temporarily discounted, and if options to click aren’t delivered promptly to the customers, the sale items will disappear before the shopper can shop. In short, the business mission of the company is to show people what they want to see.
Shop It To Me has relationships with hundreds of retailers that allow the company to know when items will go on sale. With over 3 million customers to date, Shop It To Me makes over 2 billion product recommendations per month, in order to construct the SaleMails that they send out to customers.
17.1.2. Why Shop It To Me needed a classification system
You may be wondering, “Why do classification?” for a business mission that’s essentially based on a form of recommendation; that is, predicting which sale items particular customers will want to see. The reason to choose classification is that the Shop It To Me situation is a case where normal recommendation methods don’t work well. Recommendation systems work well with items that are seen by many users. Classic examples include movies and music. People can be seen as related to each other by noting that they interact similarly with the same items, and that similarity can be used to predict other preferences. Most importantly, the items being recommended will still be there tomorrow.
This persistence isn’t true for the products being recommended to customers by Shop It To Me. The best sale items are, literally, here today and gone tomorrow (if not later today). The sale items may go away faster than feedback on who is clicking on the item can even be obtained, much less used productively. This ephemeral nature of items means that the recommendation system has to take into account the characteristics of items in the training data, such as brand, price, or color that will be shared with other items that appear later. To do this requires a different approach: the use of classification to make predictions that operate as part of a system that acts like a recommendation system. At Shop It To Me, available data includes the personal history of the users and the characteristics of the items to be recommended. These form the predictors. There’s also a good target variable as well: whether the user will click on an item.
In order to increase the utility of these recommendations, Shop It To Me has built an advanced classification system to help predict exactly which products will appeal to particular users. When constructing a SaleMail for a particular user, this classification system can compute the value of a classification model trained to predict whether this user will click on an item for each of hundreds of thousands of possible sale items. By ranking items according to the predicted probability of user interest, Shop It To Me can build SaleMails of particular interest to users.
17.1.3. Mahout outscales the rest
Building this system posed some particular challenges. Not only are there billions of training examples, but the required classification speed is fairly stupendous. A back-of-the-envelope calculation shows that millions of users need model evaluations for hundreds of thousands of items, giving hundreds of billions of evaluations. In order to meet the constraints of the email construction and delivery pipeline, these evaluations must be completed in just a few hours. This gives a raw classification rate requirement of tens of millions of classifications per second, which is, as they say in the old country, a lot.
To meet these severe requirements with reasonable-sized computing infrastructure, Shop It To Me has had to do some very interesting engineering. Several systems were used to produce prototype classifiers, including R (http://www.r-project.org/) and Vowpal Wabbit (https://github.com/JohnLangford/vowpal_wabbit/wiki), an open source SGD classifier sponsored by Yahoo. With R, simply handling the training data volumes and getting good integration with the existing Ruby/JRuby infrastructure at Shop It To Me proved very difficult. Vowpal Wabbit was able to handle the data volumes for training, but integrating a Vowpal Wabbit classifier well was also difficult.
Mahout, on the other hand, was able to handle the training volume and integrated well with the existing infrastructure. Mahout provides key portions of the Shop It To Me system, aspects of which are described in this chapter. Mahout isn’t the preferred solution for every project, but it proved to be the best choice for the engineering challenges of Shop It To Me.
Note
Some details of Shop It To Me’s system design, variable extraction, and model performance are proprietary and have been omitted or glossed over.
The system outline here is broadly descriptive and doesn’t contain an exact representation of all aspects of the Shop It To Me system. Enough details are included, however, to allow you to understand the scaling issues and solutions. Those issues start with the structure of the email system itself.
Shop It To Me is a Ruby shop, but they chose Java-based Mahout as a platform for modeling. This may seem like a contradiction, but as the Shop It To Me engineers determined, Java integrates remarkably easily into a system composed of Ruby-based web services and processes. One of the main reasons for this is that JRuby allows nearly transparent calling from Ruby code into Java without losing significant performance relative to standard Ruby. That allows classification services to be built using standard Ruby idioms and engineering practices.
On the other hand, model training at Shop It To Me is done using Cascading integrated into a Ruby workflow defined in Rake. The Java nature of Cascading is hidden in this system by a special-purpose domain-specific language (DSL) for writing Cascading flows.
Although significant Java expertise is still occasionally needed to extend or maintain this system, most of the integration between Mahout and JRuby doesn’t require encyclopedic knowledge of Java and can be accomplished using standard Ruby methods and tools.
17.2. General structure of the email marketing system
The overall data flow at Shop It To Me roughly follows the path shown in figure 17.1. This diagram shows how registration information is used to fill a user table as well as a brand preference table. It also shows how specialized data importer is used to find sale items from retail partners. The core of the system is the SaleMail constructor, which accesses tables containing information about current sale items, users, and their expressed interests. Models, including a click-prediction model, are used to select which items are to be included in each user’s email. The items included in each email are recorded in a table of item appearances.
Figure 17.1. The overall data flow for the Shop It To Me email marketing system. The dashed line illustrates how users provide feedback to the system by clicking on items in their emails.
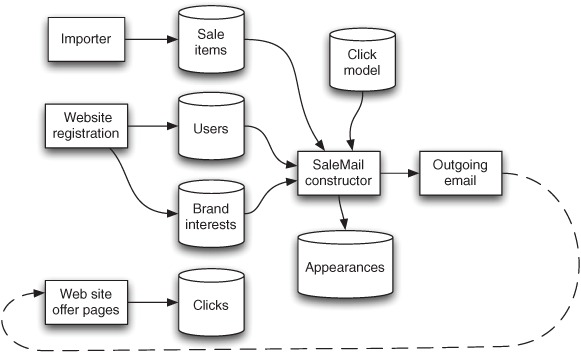
As figure 17.1 shows, users and items for sale form the data that make up the predictors for the click model used by the email generator. When users click on items in the emails that they receive, they cause web page visits to be recorded in log files. These recorded clicks are then turned into training data for the next round of modeling so that the click model can be updated. This updated model is then used for the next round of recommendations, and the cycle repeats. Some of these data sets are stored in relational databases, such as the table of users, but other data sets, such as the appearances table, are stored either in large collections of log files or are stored implicitly and must be reconstructed when needed.
The emails generated by the Shop It To Me system look like the one shown in figure 17.2, where you can see the top of an email offering a selection of wristwatches. Many more products are shown further down in the email.
Figure 17.2. Extract from a product suggestion email sent by Shop It To Me
The databases depicted in the workflow of figure 17.1 store the state of the entire system, including the offers that are available, the emails that were sent, and the preferences expressed. Figure 17.3 shows a simplified structure of the tables in the Shop It To Me system that are used to record the required user and item data along with the relevant actions needed to build the click model.
Figure 17.3. Simplified UML view of database tables used to support the data flow at Shop It To Me. Each sale item has a unique vendor and brand but can appear many times. Likewise, a user may indicate interest in multiple brands but will see many items. Each appearance may result in at most one click.
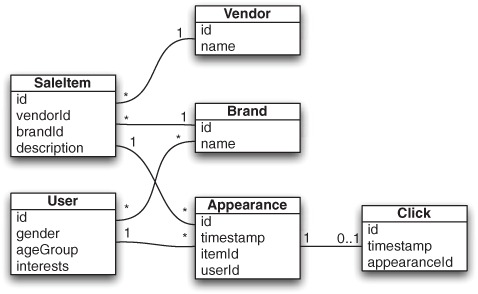
In figure 17.3, denormalized views of the User and SaleItem tables are exported as Apache Hadoop files for use in creating the training data. The Appearance table isn’t actually a database table, due to size. Instead it’s kept in conventional files that contain logs of emails sent out. The Appearance and Click tables are both exported to Hadoop for joining. Note how these tables are kept in a highly normalized form. This is important for transactional processing and for supporting web access, but this normalization must be removed for training.
You’ve now seen the framework of the Shop It To Me email system and how their marketing process is structured. Think about how they designed the classification system. Just as with any classifier you might build, the first stage for Shop It To Me was to train a model.
17.3. Training the model
Training a model first requires preliminary planning. You must consider how to pose the questions being asked in order to meet your goals and determine which target variables will be the output of your system. You must examine the available historical data, see what features are available for use as variables, and determine which of these will be most effective as predictor variables. For a Mahout classifier, it’s particularly important to scope the proposed project for pain points in order to best determine how to balance speed and size requirements, as you saw in previous chapters.
In this section, you’ll see how Shop It To Me accomplished these steps.
17.3.1. Defining the goal of the classification project
The Shop It To Me engineers approached their problem much as we outlined in previous chapters. The goal of their classification project was to produce a model that could predict whether a user would click on an item using the item’s appearance and the user’s clicking history as training data. Predicting clicks is the target; user and item characteristics are the predictors. To be usable, however, the Shop It To Me data required significant preprocessing.
The process of creating training data is shown in figure 17.4. This figure shows how user data is preprocessed and joined with item data to form the training data used in model training.
Figure 17.4. The data flow during the creation of model training data. The user’s brand interests are used to form user clusters. In parallel, clicks and appearances are joined and selectively downsampled. All of the data is then joined to produce the training data.

Some of the richest information available in the Shop It To Me system is the brand preference database. When users register with the Shop It To Me system, they’re asked which brands they like. Their answers are stored in the brand preference database and are an excellent source of information about what users do or don’t like. Unfortunately, this data isn’t in a form that’s usable for classification.
To rectify this, the data is first reduced using an SVD decomposition and then clustered using the k-means clustering algorithm. The SVD decomposition is a mathematical technique often used to reduce the dimensionality of observed data. This results in the assignment of all users to clusters of people who have expressed similar brand preferences. The brand preference cluster ID expresses the original brand preference information in a form very suitable for modeling.
The Appearances table is the largest table in the entire computation, and each record in the final training data can be traced back to a unique row in this table. Moreover, the rows of the Appearances table are downsampled at different rates depending on whether or not the appearance of the item resulted in a click. Unclicked appearances are downsampled substantially, but clicked appearances aren’t downsampled at all. In order to make downstream joins handle less data and thus be more efficient, clicks and appearances are joined in a full reduce join and are down-sampled in the reducer before joining them against user and item metadata.
Click and appearance data are then joined against user metadata, including gender, age, general geographic location, and brand preference cluster, as well as against sale item metadata including item identifier, color, size, and description. This second join is done using a map-side join because the user and item metadata tables contain only a few million entries and can be kept in memory relatively easily.
This final join could alternatively have been made into a reduce-side join and integrated into the click and appearance join step. It’s possible the performance of this alternative could have been improved with more experimentation.
17.3.2. Partitioning by time
Accumulated training data is partitioned by day to allow flexibility in terms of how much data is used for training and, most importantly, to allow test data to come from disjointed and later times than the training data. This gives a more realistic appraisal of performance because it includes real-world effects like item inventory changes. Daily aggregation also helps when it comes time to expunge old training data that’s no longer used in modeling.
Time partitioning also allows training data to be created incrementally, one day at a time. This means that the large cost of building a long-term training set can be paid over a long period of time rather than delaying the build process each day.
17.3.3. Avoiding target leaks
Throughout the chapters on classification, we’ve emphasized the importance of careful planning for feature extraction to avoid creating target leaks. In order to avoid problems with target leaks, Shop It To Me engineers used a multilayered segregation of data based on time. The SVD and k-means clustering of the brand preference information were based on an early time period and were kept relatively stable as models were rebuilt. The resulting cluster model was applied to data from a later time period to produce the actual training data. Additional, even more recent data was held back from the training algorithm to assess the accuracy of the trained model.
17.3.4. Learning algorithm tweaks
The default behavior of the Mahout learning algorithms was not entirely suited to the task that Shop It To Me needed to do, partly because of the way the classifier was being used as a recommender and partly because the model was difficult to train. These difficulties led the engineers there to extend the default Mahout logistic regression learning algorithm in several ways.
Optimizing Based on Per-User AUC
The AdaptiveLogisticRegression learning algorithm uses AUC as a default figure of merit to tune the hyper-parameters for binary models. In the Shop It To Me classification system, AUC is an accurate measure of how well the model predicts which user-item pairs are likely to result in a click. Unfortunately, one of the strongest signals in click-through models involves the classification of users into those who click and those who don’t. Because the fundamental problem in email marketing is to rank items for each user, predicting who will click isn’t of much interest. What matters is the prediction of which items the user will click on if they’re shown to the user. In order to help the learning algorithm find models that solve the right problem, a different figure of merit than normal was required.
In Mahout, there are two classes that can be used to compute different forms of AUC. Normal global AUC is computed by the GlobalOnlineAuc class, whereas AUC based on rankings within groups is computed using GroupedOnlineAuc. The AdaptiveLogisticRegression learning algorithm allows alternative AUC implementations and a grouping criterion to be supplied. Grouping on user or user cluster allows models that are good recommenders to be distinguished from models that simply pick users who click.
Mixed Rank and Score Learning
Whether learning a probability directly is better than learning an ordering of results is a major current area of research. These approaches seem equivalent at first examination, but several researchers have noted that there are differences in practical situations. One recent advance is represented by the paper “Combined Regression and Ranking” by Google researcher D. Sculley.[1] Shop It To Me engineers implemented this technique in a wrapper around Mahout code by maintaining a short history of training examples and using either the current training example or the difference between the current example and a previous one to compute the gradient for updating the model. Mahout has a largely untested implementation of this technique in the MixedGradient class.
1 D. Sculley, “Combined Regression and Ranking” http://www.eecs.tufts.edu/~dsculley/papers/combined-ranking-and-regression.pdf. See also the video lecture: http://videolectures.net/kdd2010_sculley_crr/
This technique was quite effective for Shop It To Me, but more experience is necessary to determine how often this will be true.
17.3.5. Feature vector encoding
Figure 17.5 shows a record from an idealized set of training data that might be used to build a click model. In this model, as in more realistic versions of such a record, there are three types of fields that are of interest:
- User-specific fields
- Item-specific fields
- User-item interaction fields
Figure 17.5. Fields in a possible training record for a simplified email marketing, click-through prediction model. The record contains user-specific, item-specific, and user-item interaction variables. Real models of this sort have many more fields than are shown in this conceptual example.
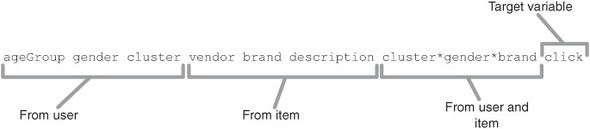
The user-specific fields include values for variables such as the age group, gender, and brand preference cluster. The item-specific fields include values for variables such as the vendor, brand, and item description. Of greatest benefit are the user-item interaction variables. The interaction variables enable the model to be more than a record of what items or kinds of items are most popular.
The interesting item here in contrast with our previous examples of feature encoding is the interaction variable that involves the user’s brand preference cluster identifier (cluster in the diagram), gender, and item brand.
To encode an interaction variable using the feature-hashing style recommended for SGD learning, the code needs to pick feature vector locations are that are independent of the feature vector locations used for each of the constituent features in the interaction. For example, figure 17.6 shows how we’d like things to work. Assuming we have a sparse feature vector of size 100, the locations for the feature “gender = female” might be assigned locations 8 and 21 by the hashed feature encoding. Similarly, “item = dress” might be assigned locations 77 and 87 in the vector. The interaction “female x dress” needs to be assigned locations that are as statistically independent from these four locations as possible, while still being deterministically computed based on these original values.
Figure 17.6. Interaction features need to be hashed to locations different from the locations of their component features.

One way that Shop It To Me engineers were able to get statistical independence for the locations was to use random seeds to combine the locations of each of the two locations. The seeds generated by the random number generator for this example were 22 and 92. To get the i-th location for the interaction feature, use
hash[i] = seed[0] * x[i] + seed[1] * y[i]
where x and y contain the feature locations for “woman” and “dress” respectively.
This method is closely related to double-hashing as used in Bloom filters, and it can be shown to provide reasonably good, independent locations for the composite features. The following listing provides a sample encoder with one implementation of an interaction encoder that’s based on this idea.
Listing 17.1. Sample encoder showing one implementation of an interaction encoder


The seeds ![]() and encoders
and encoders ![]() are kept around in the interaction encoder. The seeds are initialized
are kept around in the interaction encoder. The seeds are initialized ![]() in the constructor, which is where the array of encoders is passed in. In the addToVector () method, hashes from the encoders for each variable in the interaction are combined with integer multipliers
in the constructor, which is where the array of encoders is passed in. In the addToVector () method, hashes from the encoders for each variable in the interaction are combined with integer multipliers ![]() that were randomly chosen when the interaction encoder was constructed, based on the seed supplied at that time. This multiplicative
combination ensures that none of the feature locations chosen for the interaction encoder are likely to collide with any of
the locations chosen for the constituent variables. Note that CategoryFeatureEncoder is specific to this example and is not part of Mahout itself.
that were randomly chosen when the interaction encoder was constructed, based on the seed supplied at that time. This multiplicative
combination ensures that none of the feature locations chosen for the interaction encoder are likely to collide with any of
the locations chosen for the constituent variables. Note that CategoryFeatureEncoder is specific to this example and is not part of Mahout itself.
There are other possible approaches to interaction encoding. For instance, two sums of the locations of the first and second hashed locations for all constituent encoders could be kept and then combined using the standard double-hashing algorithm. The following code shows how this alternative encoding approach could work:

Here you have encoders ![]() for each constituent variable, just as before, but you only use the sums
for each constituent variable, just as before, but you only use the sums ![]() of the first and second probes for each constituent variable. When computing the locations
of the first and second probes for each constituent variable. When computing the locations ![]() for the interaction, combine these two sums using double hashing.
for the interaction, combine these two sums using double hashing.
Neither of these approaches has been rigorously evaluated, but both seem to have worked well in practice. Ironically, to use a classifier for recommendations, interaction variables between user and item are required, but having these interactions increases the work involved in encoding variables and computing classification results. Because the Shop It To Me classification throughput requirement is so high, that’s a big deal and has to be addressed by speedups in the classification system. These speedups avoid both the encoding cost and the computation cost of the classification computation itself.
17.4. Speeding up classification
As mentioned before, Shop It To Me had a firm requirement for performing classifications at a prodigious rate in their final system. In order to perform the required tens of millions of classifications per second on the available few machines, several improvements were needed over and above what base Mahout provides. Because the internal feature vector used has a length of over 100,000 elements, meeting this classification rate in a naive way would require a raw numerical throughput of several trillion floating-point operations per second, even if you don’t count feature encoding. With only a few dozen CPU cores available for the task, this wasn’t plausible.
To meet these requirements, Shop It To Me engineers made improvements that included the following:
- Caching partially encoded feature vectors
- Caching hash locations within encoders
- Splitting the computation of the model into pieces that can be separately cached
These improvements ultimately reduced the runtime model computation to three lookups and two additions. The necessary precomputation involved one encoding and model computation per user and a few hundred such computations per item. The overall savings due to these changes were about 3–4 orders of magnitude, which makes the overall model computation quite feasible. The improvements listed here may look relatively simple, but they provide a powerful extension of the way Mahout can be used for classification, and you may want to consider trying innovations such as these in your projects if your required throughput is as high as Shop It To Me’s is.
17.4.1. Linear combination of feature vectors
The feature-extraction system used in Mahout works by adding the vectors corresponding to separate features in order to get an overall feature vector. In the case of Shop It To Me, the feature vector can be divided into three parts related to the user, the item part, and both the user and item.
x = xuser + x(cluster + ageGroup) x itemBrand + xitem
This division into parts can clearly help with feature-encoding costs because you can cache these components instead of computing them on the fly each time you want to evaluate the model.
Caching the entire feature vector doesn’t work well because of the very large number of values that would have to be cached. Caching the pieces works because the number of unique pieces is much smaller. Essentially, the larger cache has a required size that’s nearly the product of the sizes of the smaller caches.
Figure 17.7 shows how the three parts of the feature extraction are used in the computation of the model score.
Figure 17.7. How model scoring works for the Mahout SGD logistic regression model

Using caching for these three components helped with speed somewhat, but, by itself, this caching did not improve speed enough. It did, however, lay the groundwork for additional improvements.
17.4.2. Linear expansion of model score
Splitting the feature vector into three pieces is useful for speeding up feature encoding, but the model computation that uses the feature vector is composed of linear operations all the way to the last step. This allows even more aggressive caching to be done. Moreover, the items cached at the later point in the computation are much smaller.
The way that logistic regression models such as the SGD models in Mahout work is that they produce a weighted sum of the features and then transform that weighted sum so that it’s always in the range from 0 to 1. When ranking values, you can omit that last transformation without disturbing the ordering of the final results. In Mahout, the classifyScalarNoLink(Vector) method in AbstractVectorClassifier omits this final transformation exactly as desired.
Once this final transformation is removed and the model is simplified to a weighted sum, you can use the linear combination property of feature vectors. Using the dot product notation, the model output, z, can be written this way:
z = β · x
Here β represents the weights the model applies to each feature, and x represents the features that are given to the model. Both quantities are vector-valued. The multiplication here is a dot product that indicates the sum of the products of corresponding elements of ? and x. The dot product is where all of the intensive computation happens. Note that this formula can be broken into three parts, just as the feature vector can be split:
z = β · xuser + β · x(cluster + ageGroup) x itemBrand + β · xitem
Pictorially, this split can be depicted by changing figure 17.7, which showed how the model computation works in Mahout’s SGD models, so that more computations are done separately before being finally combined.
Figure 17.8 shows user, item, and user-item features being applied separately to the weight vector, β, before the three components of the score are combined. The clever thing about this is that these three parts can now be efficiently cached.
Figure 17.8. How model scoring can be rearranged to allow precomputation and caching of intermediate results

Importantly, the value of each part is a single floating-point number rather than a vector, so in the case of a full cache hit, the cost of a single model computation for a particular user and item computation drops from several thousand floating-point operations to just two table lookups and two additions. There are only two lookups because the user component of the score is computed outside the inner loop. Caching smaller objects also decreases memory consumption, allowing more items to be cached.
The following listing shows how this works in code.
Listing 17.2. Using caching and partial model evaluation to speed up Item selection


This class shows some simplified code that does the model evaluation using caches for item and interaction effects. Assume
in this code that the model and the list of items will be populated by some other means ![]() .
.
What this class does when given a user is to first compute the score component for that user ![]() . Then it scans the list of all items and computes the model score for each item. The items with the top score are retained
. Then it scans the list of all items and computes the model score for each item. The items with the top score are retained
![]() . The score is computed in three parts. The part due to the user variables is computed outside the item loop
. The score is computed in three parts. The part due to the user variables is computed outside the item loop ![]() and retained. Then inside the inner loop, the item
and retained. Then inside the inner loop, the item ![]() and user-item interaction
and user-item interaction ![]() parts are each computed if they aren’t found in the appropriate cache data structure. The FeatureEncoder class is a convenience class that’s used to wrap the feature encoders for the various user and item features and their interactions.
Finally the components of the score are combined to get the final score
parts are each computed if they aren’t found in the appropriate cache data structure. The FeatureEncoder class is a convenience class that’s used to wrap the feature encoders for the various user and item features and their interactions.
Finally the components of the score are combined to get the final score ![]() .
.
Clearly it isn’t as simple to split up the model computation in this way, but in some cases it’s worthwhile due to the massive speedups available.
17.5. Summary
The online marketing case study presented in this chapter describes the innovative approaches used by Shop It To Me engineers in developing a Mahout classifier for predicting clicks for on-sale items presented to customers. The scale and the speed that Shop It To Me was able to achieve using Mahout classifiers both in training and when running a deployed model against live data illustrate how Mahout can be used in very large-scale problems.
The principles you have learned throughout the chapters on classification were applied in this real-world classifier. One important concept is the idea that classification can be a useful way to achieve results similar to recommendation in systems that preclude traditional recommendation approaches.
Another important principle that’s illustrated in this case study is the value of scoping out the problem carefully at the start, looking particularly for so-called pain points that could be a barrier to success if not addressed by the engineering design. These pain points are often caused by extreme requirements for speed and volume, and Shop It To Me’s online marketing system illustrated those challenges in abundance. Scoping the problem led engineers to recognize the value of switching to Mahout classification for this system and identified the need to extend the effectiveness of Mahout by some customization.
The Shop It To Me example also shows the power of using large-scale joins to implement the training pipeline in parallel, a take-home lesson described in the previous chapter. You will likely find many applications where this way of building a pipeline helps you meet the requirements for scale and speed of extremely large projects.
Other key ideas that this case study demonstrates are the innovations in the Shop It To Me system. These innovations include the use of ranking objectives for learning models and the use of grouped AUC for meta-learning. Learning with a composite goal that involves ranking and regression together appears to be a very powerful technique for nearly all applications of SGD learning. Grouped AUC as a target for the AdaptiveLogisticRegression to optimize learning meta-parameters looks like a very effective strategy whenever classifiers are used as recommenders.
In terms of throughput, the big lesson is the way that caching strategies were used to speed up the Mahout classifier. These methods included caching of partially encoded feature vectors, caching of hash locations within encoders, and splitting the computation of the model into pieces that can be separately cached. Even with the innovations in the Shop It To Me approach to using Mahout for classification, this isn’t the end of the line by any means. There are considerable degrees of improvement in training speed still available, and it’s unlikely that the last ounce of speed has been milked from the deployed models.
Just how far Mahout can go is a subject for the next chapter. And that’s the chapter you get to write.