
I will begin with a distillation of our journey, a process for applying the scientific method to software engineering in an industrial environment. We called our version of the scientific method the Quality Improvement Paradigm (QIP) [Basili 1985], [Basili and Green 1994]. It consists of six basic steps:
Characterize the current project and its environment with respect to the appropriate models and metrics. (What does our world look like?)
Set quantifiable goals for successful project performance and improvement. (What do we want to know about our world and what do we want to accomplish?)
Choose the process model and supporting methods and tools for this project. (What processes might work for these goals in this environment?)
Execute the processes, construct the products, and collect, validate, and analyze the data to provide real-time feedback for corrective action. (What happens during the application of the selected processes?)
Analyze the data to evaluate the current practices, determine problems, record findings, and make recommendations for future project improvements. (How well did the proposed solutions work, what was missing, and how should we fix it?)
Package the experience in the form of updated and refined models and other forms of structured knowledge gained from this and prior projects, and save it in an experience base to be reused on future projects. (How do we integrate what we learned into the organization?)
The Quality Improvement Paradigm is a double-loop process, as shown by Figure 5-1. Research interacts with practice, represented by project learning and corporate learning based upon feedback from application of the ideas.
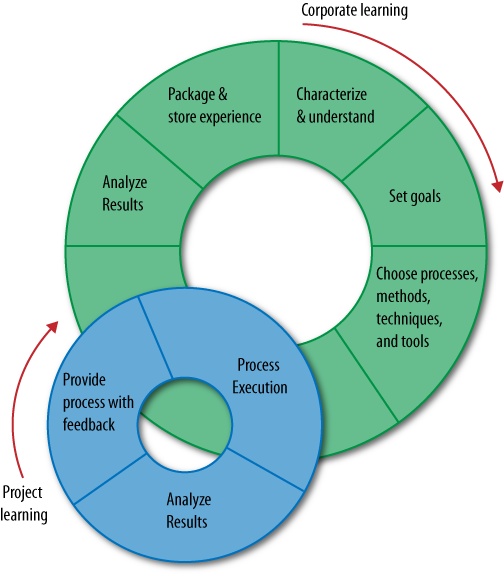
But that is not where we started. Each of these steps evolved over time as we learned from observation of the application of the ideas. In what follows, I will discuss that evolution and the insights it provided, with formal experiments playing only a support role for the main ideas.
The learning covered a period of 25 years, although here I concentrate on what we learned mostly in the first 20. The discussion is organized around the six steps of the QIP, although there is overlap in the role of many of the steps. In each case I say what we learned about applying the scientific method and what we learned about improving software development in the Flight Dynamics Division of NASA/GSFC.
We started in 1976 with the following activities, representing each step of the approach: characterize, set goals, select process, execute process, analyze, and package.
In the beginning, we looked at various models in the literature and tried to apply them to help us understand our environment (e.g., Raleigh curve or MTTF models). We found they were not necessarily appropriate. Either they were defined for larger systems than what we were building (on the order of 100KSLOC) or they were applied at different points in time than what we needed. This led to the insight that we needed to build our own environment-appropriate models using our own data. We needed to better understand and characterize our own environment, projects, processes, products, etc., because we could not use other people’s models that were derived for different environments [Basili and Zelkowitz 1978], [Basili and Freburger 1981], [Basili and Beane 1981].
We needed to understand our own problem areas. So over time, we began to build baselines to help us understand the local environment; see Figure 5-2. Each box represents the ground support software for a particular satellite. We built baselines of cost, defects, percent reuse, classes of defects, effort distribution, source code growth in the library, etc. We used these baselines to help define goals, and as historical data to establish the basis for showing improvement.

As we progressed over time, we learned that we needed to better understand the factors that created similarities and differences among projects so we would know the appropriate model to apply and what variables were influencing the effectiveness of the processes. Context, even within the local environment, was important.
From the very beginning, we decided to use measurement as the abstraction process to provide visibility into what was occurring, and developed data collection forms and a measurement tool. We collected data from half a dozen projects in a simple database and tried to interpret that data, discovering that sometimes we did not have the right data or sufficient information to answer our questions. We realized that we couldn’t just collect data and then figure out what to do with it; data collection needed to be goal-driven. This led to the development of the Goal Question Metric (GQM) approach to help us organize the data around a particular study [Basili and Weiss 1984]. You can also drown in too much data, especially if you don’t have goals. We have continued to evolve the GQM, for example, by defining goal templates [Basili and Rombach 1988].
We also understood the important role that nominal and ordinal data played in capturing information that was hard to measure in other ways. We moved from a database to a model-based experience base as our models evolved, based upon our experiences with over 100 projects in that environment.
We began by minimally impacting the processes, using heuristically defined combinations of existing processes. We began to run controlled experiments at the university, with students, to isolate the effects of small sets of variables at minimal cost [Basili and Reiter 1981]. When we understood the effects of those processes, we began to experiment with well-defined technologies and high-impact technology sets. Many of these technologies were studied first at the university in controlled experiments before being brought to the SEL for use on live projects, e.g., Code Reading by stepwise abstraction [Basili and Selby 1987], Cleanroom [Selby et al. 1987], and Ada and Object oriented design [Basili et al. 1997]. The university studies diminished the risks of applying these techniques in the SEL. Over time we began to understand how to combine controlled experiments and case studies to provide a more formal analysis of isolated activities [Basili 1997].
We began to experiment with new technologies to learn more about the relationships between the application of processes and the resulting product characteristics. But the motivation for choosing these techniques was based upon the insights we gained from observing the problems that arose in the SEL and were aimed at specific goals, e.g., minimizing defects. Based upon recognition of problems with requirements, for example, we developed a set of reading techniques for identifying defects in requirements documents [Basili et al. 1996].
We recognized the obvious fact that we needed to understand how to choose the right processes to create the desired product characteristics and that some form of evaluation and feedback were necessary for project control. Reusing experience in the form of processes, products, and other forms of knowledge is essential for improvement. We learned to tailor and evolve technologies based upon experience.
When we started, data collection was an add-on activity; we expected the developers to perform their normal development processes and fill out the data forms we provided. The process was loosely monitored to see that the data forms were being filled out and the developers understood how to fill out the forms. The lack of consistent terminal use and support tools forced the data collection to be manual. Sharing the intermediate results with the developers allowed them to provide feedback, identify misunderstandings, and suggest better ways to collect data. Over time, using GQM, we collected less data, and embedded data collection into the development processes so the data were more accurate, required less overhead, and allowed us to evaluate process conformance. We captured the details of developer experiences via interaction between developers and experimenters, providing effective feedback about local needs and goals. We combined controlled experiments and case studies with our general feedback process to provide more formal analysis of specific methods and techniques.
We began by building and analyzing the baselines to characterize the environment. Baselines were built of many variables, including where effort was spent, what kinds of faults were made, and even source code growth over time. These provided insights into the environment, showed us where to focus process improvement, and offered a better understanding of the commonality and differences among projects. We began to view the study of software development as following an experimental paradigm—i.e., design of experiments, evaluation, and feedback are necessary for learning. Our evolution of analysis methods went from correlations among the variables [Basili et al. 1983] to building regression models [Bailey and Basili 1983] and more sophisticated quantitative analyses [Briand et al. 1992], to including all forms of qualitative analysis [Seaman and Basili 1998]. Qualitative analysis played a major role in our learning process, as it allowed us to gain insights into the causes of effects. Little by little, we recognized the importance of simple application of the ideas followed by observation and feedback to evolve our understanding, which we incorporated into our models and guided where and when to use the more formal analytic approaches.
We realized it was impossible to run valid experiments on a large scale that covered all context variables. The insights gained from pre-experimental designs and quasi-experiments became critical, and we combined them with what we learned from the controlled experiments and case studies.
Our understanding of the importance, complexity, and subtlety of packaging evolved slowly. In the beginning we recorded our baselines and models. Then, we recognized the need for focused, tailored packages—e.g., generic code components and techniques that could be tailored to the specific project. What we learned had to become usable in the environment, and we needed to constantly change the environment based on what we learned. Technology transfer involved a new organizational structure, experimentation, and evolutionary culture change. We built what we called experience models—i.e., models of behavior based upon observation and feedback in a particular organization. We built focused, tailorable models of processes, products, defects, and quality, and packaged our experiences with them in a variety of ways (e.g., equations, histograms, and parameterized process definitions). The hard part was integrating these packaged experiences. All this culminated in the development of the Experience Factory Organization [Basili 1989]; see Figure 5-3.

The Experience Factory of processes, products, and other forms of knowledge is essential for improvement [Basili 1989]. It recognizes the need to separate the activities of the project development organization from the building of knowledge based upon experiences within the organization. Sample activities of the project organization are decomposing a problem into simpler ones, instantiation of the solution, design and implementation, validation, and verification. The goal is to deliver a product within cost and schedule. The activities of the Experience Factory are the unification of different solutions and redefinition of the problem, generalization, formalization, and integration of experiences. It does this by analyzing and synthesizing what it observes and experimenting to test out the ideas. Its goal is experience and delivering recommendations to the projects. It is responsible for the evaluation, tailoring, and packaging of experiences for reuse.
The Experience Factory cannot be built solely on the basis of small, validated experiments. It requires the use of insights and intelligent judgment based upon observation for the application of ideas, concepts, processes, etc.
Once we felt we understood how to learn from our observations and how to combine the results of case studies and controlled experiments (which was more publishable than our insights), we continued with our process of application, observation, and learning. We dealt with such topics as commercial off-the-shelf (COTS) development, reading techniques, etc.
Learning in an organization is time-consuming and sequential, so we need to provide projects with short-term results to keep the development team interested. We need to find ways to speed up the learning process and feed interim results back into the project faster. If we are successful in evolving, our baselines and the environment are always changing, so we must continue to reanalyze the environment. We need to be conscious of the trade-off between making improvements and the reuse of experience.