
Chapter 1. Understanding the Microsoft SharePoint 2013 architecture
In this chapter, you will gain architecture knowledge as you:
First of all, welcome to Microsoft SharePoint 2013. For many of you, architecture and design may be new to you; for others, you are continuing your education. No matter which category you fall into, SharePoint 2013 has a rich set of features that affect how you, as architects, plan and design successful SharePoint implementations.
For those of you who spent a great deal of time learning SharePoint 2010, you will find SharePoint 2013 a welcoming friend. The product is similar enough that you will quickly become comfortable with it, but different enough that additional planning aspects must be considered.
In this chapter, you will be introduced to SharePoint 2013 from the inside out. You will start with the components that make up the SharePoint farm and then dig your way down into the file system. There are new features that allow SharePoint 2010 and 2013 components to work together, so for those of you with experience in previous versions, you will certainly find value learning about the Feature Fallback behavior. SharePoint has a number of ways to deploy solutions. This chapter will review the farm and sandbox solutions and give you an introduction to the new SharePoint application model. Finally, you will be introduced to the various databases and encounter some critical nuggets that will help you understand the SharePoint 2013 architecture.
Exploring the SharePoint farm components
Most SharePoint professionals, when they first learn of SharePoint, are introduced through the web browser; after all, it is a web application. But the deeper their understanding goes, the more complex the SharePoint platform seems to get. While on the surface it may look like a simple web interface, in reality the object hierarchy, file system, and databases quickly inform you of the massive beast that lies beneath the covers of those web components. If you are accustomed to talking about SharePoint infrastructures with technology folks who lack an understanding of how SharePoint works, then you may find yourself referencing the Farm, only to find out that the person on the other side of the conversation has no idea of what you are talking about. With that said, you will begin the SharePoint journey at its highest logical container: the farm.
The SharePoint farm hierarchy
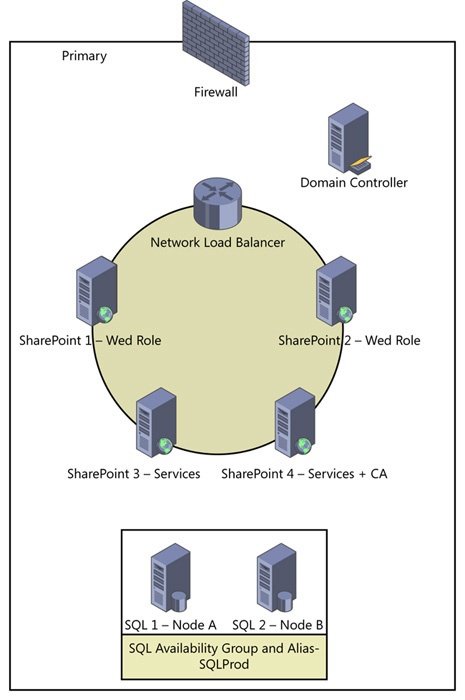
The SharePoint farm, in its simplest terms, is a collection of SharePoint and Microsoft SQL Server roles that are bound by a single configuration database. A farm may consist of a single server that will have both a version of SQL Server and SharePoint, or it may have many SharePoint servers similar to what’s shown in Figure 1-1.
Farm
When building the farm, the first component that gets created is the SharePoint Configuration and Admin Content Databases. You will learn more about these later in this chapter, but for now, it is important to note that these databases are created either while running the SharePoint Products Configuration Wizard or executing the New-SPConfigurationDatabase cmdlet; you will review the latter in the chapter dedicated to Windows PowerShell.
Prior to building the farm for SharePoint 2013, many things must be considered. Chapter 3, discusses many of the issues that are common to a wide variety of SharePoint environments and will offer suggestions on how you, as the architect, can avoid them. Now turn your attention to the SharePoint web application, which is hosted in Internet Information Services (IIS), as this is the next major component of the farm.
Web applications
In order for a SharePoint farm to exist, it must contain at least one SharePoint web application. This web application, known as the SharePoint Central Administration, is created for you during the installation process either by using the SharePoint Products Configuration Wizard or executing the New-SPCentralAdministration cmdlet using Windows PowerShell. This web application, along with every other SharePoint web application, is hosted within IIS, as shown in Figure 1-2.

As a SharePoint professional, a basic understanding of IIS is helpful—if not required. For those of you who are familiar with SharePoint 2010, the biggest difference you will notice here is the use of the Microsoft .NET Framework 4.0. Later in this chapter, you will gain a deeper understanding of how HTTP requests are handled through IIS, but for now, you will continue with your survey of the web application component.
The SharePoint web application has several subcomponents that should be planned prior to the creation of the web application. These include the name of the IIS website, port, host header, location of the IIS files, whether or not to allow anonymous access, whether or not to use Secure Sockets Layer (SSL) authentication, the use of a default sign-in page, application pool, failover database server, search server, database name, and service application proxy group.
In SharePoint 2010, there was an option to select Classic or Claims mode authentication. In SharePoint 2013, this option has been removed from the GUI. This may give you the impression that Classic mode is no longer available. While Classic mode has been deprecated in the product, it is still fully supported. Web applications will not be required to be migrated to Claims mode since there are still some business cases that will require Classic mode authentication: Business Connectivity Services (BCS), in conjunction with Kerberos delegation.
When selecting a name for the IIS website, choose between using an existing IIS website or create a new one to serve the SharePoint Foundation application. If you select an existing IIS website, that website must exist on all servers in the farm and have the same name, or this action will not succeed.
The first web application that is created is generally defaulted to port 80. Once a web application is assigned to this port, the GUI will autogenerate a port number. You may reuse port numbers if the web application uses a unique host header. Additional planning may be required if several sites are going to use SSL on port 443.
A host header allows for the specification of friendly URLs. The URLs will be configured in Domain Name System (DNS) and will be directed to the servers hosting web requests; this can be either directly to a server or to a network load balancer (NLB) that will direct traffic. The use of host headers allows for web applications to occupy the same ports as other web applications. Without host headers, the URLs may need to contain port numbers and may not be as friendly to the user. Port 80 and port 443 are implicit and do not need to be specified in the URL.
It is important to understand that you are not limited to using a host header per web application; the use of host headers for SharePoint site collections offers a scalable way to offer vanity URLs for each site collection. This process is often used in hosting situations, but it has some benefits in environments unrelated to hosting as well. The use of host headers for a web application where the site collections are differentiated by path (such as http://www.contoso.com/sites/team1 and http://www.contoso.com/sites/team2) are referred to as path-based site collections. The use of individual host headers for each site collection (such as http://team1.contoso.com) is referred to as host header site collections. While these two techniques can coexist, it requires additional web application zones. SharePoint web application host headers are intended only for path-based site collections; IIS will not respond to requests that have a different host name from that in the host header binding. You will continue your focus on site collection host header names later in this chapter.
When creating a new SharePoint web application, the GUI states:
If you opt to create a new IIS website, it will be automatically created on all servers in the farm. If an IIS setting that you wish to change is not shown here, you can use this option to create the basic site, then update it using the standard IIS tools.
While this is true, it is generally not recommended to make changes using IIS. It is also worth noting that the verbiage may be a little misleading. SharePoint web applications will be created only on SharePoint servers that are running the Web Application SharePoint Service.
The anonymous access setting does not guarantee that visitors will have anonymous access to the site; it simply allows the content owners to decide if they would like to allow anonymous access to their content. If this setting is set to false, content owners will not have the option. The configuration of anonymous access is a two-part process.
Configuring your SharePoint web application to use SSL allows for the communication between the users and the web server to be encrypted. A certificate must be added on each server or offloaded to the load balancer (if it supports it) in order for the web application to be accessible. For more information, please see Chapter 6.
There are many options when configuring authentication for a SharePoint web application. Negotiate (Kerberos) is the recommended security configuration to use with Windows authentication, but it requires the use of Service Principal Names (SPNs); for more information, see Chapter 6. If Negotiate is selected and Kerberos is not configured correctly, the authentication will fall back to NTLM. For Kerberos, the application pool account needs to be Network Service or an account that has been configured by the domain administrator. NTLM authentication will work with any application pool account and with the default domain configuration.
The Basic authentication method passes users’ credentials over a network in an unencrypted form. If you select this option, ensure that SSL is enabled so that the credentials are encrypted over the network.
The ASP.NET membership and role provider are used to enable Forms-based authentication (FBA) for a SharePoint web application. The use of membership and role providers requires additional changes to be made to the web.config files of the SharePoint web application, Central Administration, and the Secure Token Service. For more information on this configuration, please refer to the Chapter.
Trusted Identity Provider authentication enables federated users to access a SharePoint web application. This authentication is claims token-based, and the user is redirected to a logon form for authentication, which is normally outside of the SharePoint farm. For more information on this configuration, please refer to Chapter 6.
The default sign-in page is available to Claims mode authentication SharePoint sites. While it is obvious that this feature allows for the customization of the logon page, there are some additional benefits that aren’t so obvious. In SharePoint web applications that have multiple authentications available to them, by default, the users are prompted to select their authentication type. For many organizations, this is not a desired option. The use of a default logon page removes this option but still allows the web application to use multiple authentications. For more information, please refer to Chapter 6.
The public URL is the domain name for all sites that users will access in this SharePoint web application. This URL domain will be used in all links shown on pages within the web application. By default, it is set to the current server name and port unless a host header is specified for the site.
There are five zones that can be associated to a SharePoint web application: Default, Intranet, Internet, Extranet, and Custom. When creating or extending a SharePoint web application that uses a content database of another, you have the option to select a zone other than Default, which is already in use. This is not the case for a new SharePoint web application. You will learn about zones in more detail in Chapter 6.
An application pool is a grouping of URLs that is routed to one or more worker processes. In SharePoint, you have the opportunity to either use a unique application pool for each web application or share one among several pools. In general, application pools provide process boundaries that separate each worker process; therefore, a SharePoint web application in one application pool will not be affected by application problems in other application pools.
SharePoint 2010 introduced two distinct types of application pools, one for SharePoint web content applications, and another for SharePoint service applications. While it is technically possible to associate an application pool designed for SharePoint service applications to a web content application, it is not supported. Web content applications must be hosted by SharePoint web content application pools and vice versa.
Microsoft has soft limits around the number of application pools that should be used on a particular web server. If your design uses a distinct application pool for every SharePoint web content application and SharePoint service application, you will have more application pools than are technically supported without supplying more RAM to the minimum requirements. There are some design considerations to remember when determining how you plan your application pools. You will want to keep the total number of application pools under the recommended guideline, which is expected to stay at 20 application pools on a particular web server. As more testing is done, this guideline may change, so review these from time to time on Microsoft TechNet. Keep in mind that the more application pools you have, the more server resources will be dedicated to each web application. There may be business requirements that dictate if a SharePoint web application can share process boundaries with another. It is important to know that there are tradeoffs for either decision. In implementations that do not require process isolation, one approach is to use a common application pool for SharePoint web content applications and another for SharePoint service applications.
When creating a new application pool, you will need to specify a SharePoint Managed Account that will be used as the identity of the application pool. If the SharePoint Managed Account is not specified prior to entering the web application settings in the GUI, you will have the opportunity to create one at the time of adding the web application. This process will wipe out the settings you have entered and will need to be reviewed. You will learn about SharePoint Managed Account setting in more detail in Chapter 7.
SharePoint 2013 supports SQL Server database mirroring that is native in the product. This feature was introduced in SharePoint 2010. Using the failover database server property, you can choose to associate a database with a specific failover server. While planning how you will implement high availability in SharePoint, keep in mind that database mirroring has been deprecated in SQL Server 2012. Chapter 10, discusses the available options.
The database server will be prepopulated with the value that was used for creating the farm. The database server name should incorporate a SQL Server alias instead of referencing a database server directly by name. The use of SQL Server aliases will be discussed later in this chapter when the focus turns toward the databases.
When creating or managing SharePoint web content applications, you have the ability to choose the service applications that will be connected to the web application. A web application can be connected to the default set of service applications or to a custom set of service applications. You can change the set of service applications that a web application is connected to at any time by using the Configure Service Application Associations’ page in Central Administration. Please review Chapter 4.
Databases
Every SharePoint web application requires a database in SQL Server to support it. This is true even of the SharePoint Central Administration. Along with the farm configuration database, a configuration content database is required. Content databases are the backbone of any SharePoint environment; therefore, you will find a section dedicated to SharePoint databases later in this chapter.
Site collections
Every functional SharePoint web application is required to have at least one site collection. The site collection is a logical container that has one or more SharePoint sites (known as webs) that serve content to the users. Understanding the site collection is critical in SharePoint. The idea here is to not cover everything pertaining to the SharePoint site collection, but there are some features that may require additional planning outside of the normal information architecture components. For those of you familiar with previous versions of SharePoint, you will find that the SharePoint site collection has some exciting new features.
SharePoint 2013 continues to support both path-based and host-named site collections. Path-based site collections share the same host name as other site collections inside the SharePoint web application. The following are examples of path-based site collections:
Additional site collections are added to the SharePoint web application through the use of a managed path. The managed path in this example is sites. It is important to note that there are software boundary limits associated to the number of managed paths in a SharePoint web application. In the previous version, the limit was 20 managed paths per web application. As the product continues to be tested, this may change, so refer to TechNet from time to time to review the latest boundaries. Keep in mind that managed paths are cached on the individual web servers and require CPU resources to process incoming requests against the list of managed paths. The more managed paths you have defined, the more load on the web server for each request, because managed paths are cached on the servers and require CPU resources for processing incoming requests against the managed path list. Exceeding the supported boundary can cause poor performance and is not recommended.
Path-based site collections can be configured using Central Administration and support URLs that have implemented Alternate Access Mappings (AAMs). Depending on the configuration, path-based site collections can utilize any zone associated with AAM configurations.
Host-named site collections allow for the use of unique DNS names and provide a scalable solution to the use of managed paths as described previously. Unlike path-based site collections, host-named site collections cannot be created using Central Administration and must be done either through the SharePoint application programming interface (API) or Windows PowerShell. Here is an example of how to create a host-named site in Windows PowerShell using the New-SPSite cmdlet.
Create a host-named site collection using PowerShell
PS C:> $wa = Get-SPWebApplication http://contoso-inter3
PS C:> $site = New-SPSite -URL "http://blueteam.contoso.local" `
-OwnerAlias "contosospAdmin" `
-HostHeaderWebApplication $wa `
-CompatibilityLevel 15
PS C:>$site
Url CompatibilityLevel
--- -----------------
http://blueteam.contoso.local 15You can select a SharePoint site collection template using this script, or if you would like the content owners to decide, leave it blank and they will be prompted to select one, as shown in Figure 1-3.

Host-named site collections take on the same protocol scheme as the public URL in the web application. Review the code listing and output shown previously. The SharePoint web application public URL is http://contoso-inter3. If HTTPS was required, the public URL would need to be available over SSL. Since there is only one DNS name associated with a host-named site collection, they will only utilize the Default zone and do not support AAM configurations.
The Self-Service Site Creation feature is enabled at the SharePoint web application level inside Central Administration and is turned off by default. This feature allows users to create site collections without the need of a SharePoint administrator. The new site collections will utilize a path-based site collection schema. Once turned on, users will need to know the URL to create a new site collection. The page location is /_layouts/15/scsignup.aspx, as shown in Figure 1-4. You will learn more about the SharePoint file locations and their syntaxes later in this chapter.
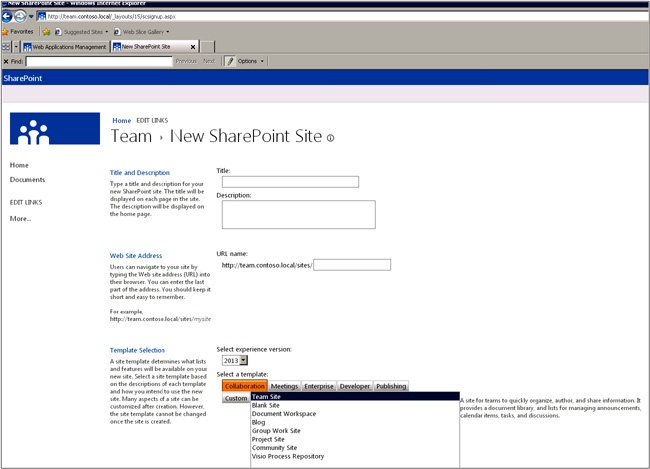
Quota templates can be used to restrict the size of the new site collections. They can warn the site collection administrator as they approach their max limit and then lock the site collection upon reaching the limit. It is highly recommended that quotas be used for all site collections.
Depending on the business requirements, the Self-Service Site Creation feature may offer some value, but it should not be turned on without proper planning. Make sure you review the latest software boundaries and have business processes in place to ensure that the number of site collections does not get out of hand.
The SharePoint site collection is the highest level of security autonomy, with the single exception of user policy settings that can be configured to allow a particular domain account explicit access to the entire SharePoint web application. An example of this would be the Search Service Application, since it grants the crawling account full read access to all SharePoint web applications that it needs to crawl. While farm administrators have the ability to give themselves access, either through the user policies or to grant themselves site collection administrator rights, these permissions are not granted by default. Site collection administrators are responsible for granting users rights to the site collections they control. Rights may be given either to particular authentication provider groups (such as Active Directory (AD) security groups, FBA roles, and so on) or to a specific individual. Rights given in one site collection cannot be inherited by another. The site collection acts as a logical boundary and will restrict composite applications and sandbox solutions to stay within the confines of the site collection.
Note
Sandbox solutions are restricted within a site collection by default, but may be given extended rights by way of a full-trust proxy.
Users and groups created at the site-collection level are available to all sites within the site collection. While sites may be able to break inheritance and change the permission structure, the site collection administrator has complete control over the site collection.
The site-collection level now exposes new search service configurations. Some of the search features available to the site collection administrator are as follows:
Search settings. Allows the site collection administrator to specify a search center for the site collection. If configured, users will see a system message that will allow them to retry their search from the specified search center. The site collection administrator also has the ability to configure which pages the search queries should be sent to.
Result types. Allow the site collection administrator to customize how the content in the site collection will be returned. The result types can be matched to specific content and can be displayed using a specific template. The out-of-the-box result types cannot be modified; this is shown in Figure 1-5. They are reserved for the search service. Site collection administrators may make a copy of the original and make changes to it.
Search schema. Site collection administrators may use the search schema page to view, create, or modify managed properties and map crawled properties to managed properties. Crawled properties are automatically extracted from crawled content. You can use managed properties to restrict search results, and present the content of the properties in search results. Changes to properties will take effect after the next full crawl. Please note that the settings which can be adjusted depend on your current authorization level.
Search result sources. Site collection administrators can configure search federation. By using search federation, users can simultaneously search content in the search index of the search service, as well as in other sources, such as Internet search engines.
Import search configuration. Site collection administrators may import search configurations created as an .xml file from an export.
Export search configuration. Site collection administrators may use this option to create an .xml file that contains their custom search configurations. This file may be used to share configurations or act as a backup of the current configurations.
Search query rules. Site collection administrators can create query rules to promote important results, show blocks of additional results, and even fine-tune ranking.

SharePoint 2013 offers a set of features that allow for site collections to function with components in other site collections. The features listed here will be discussed throughout other chapters, but it is important to know that they exist.
Content deployment source feature. Enables content deployment-specific checks on source site collection and enables setting up content deployment from the site collection to a target site collection.
Content type syndication hub. Provisions a site to be an Enterprise Metadata hub site.
Cross-farm site permissions. Use the cross-farm site permissions feature to allow internal SharePoint applications to access websites across farms.
Cross-site collection publishing. Enables site collection to designate lists and document libraries as catalog sources for cross-site collection publishing.
HTML field security allows the site collection administrator to specify whether contributors can insert external iFrames in HTML fields on pages in a site. IFrames are commonly used on webpages to show dynamic content from other websites, like directions from a mapping site, or a video from a video site. By default, the following external domains are allowed:
Youtube.com
Youtube-nocookie.com
Player.vimeo.com
Bing.com
Office.microsoft.com
Skydrive.live.com
Sites (webs)
The site collection is composed of at least one top-level site, often referred to as a web. When users create a new site, they will be prompted to create a website URL that will be appended to the DNS name assigned to the site collection. For instance, if a user created a new site for a blog, the URL name could be http://team.contoso.local/blog. During the site creation process, the user also has the ability to select a site template, specify permissions, and make decisions on how the navigation will work for the site. The site templates that are available to the user are dependent on the features that have been activated at the site collection and site level. While these templates may be important to the information architecture of the site, they will not be discussed here. The important action to note here will be to monitor the number of websites in a given site collection to ensure that they stay within the specified boundaries. There are some added benefits of grouping like site templates together in databases, so this should be considered while planning the information architecture. The creation of sites is generally handled by users in the Information Worker role, and it is difficult to plan for how they will structure their sites. Incorporating a solid governance plan is recommended.
Note
There is often a terminology conflict when referring to SharePoint site collections and SharePoint sites. This is largely due to the fact that the original programming objects used the term site for site collections and web for what is now called sites in the UI. Since the UI uses sites at this level, this same practice will be followed here to reduce confusion.
Site owners can give permission to access the site to the same users who have access to the parent site, or you can give permission to a unique set of users. This will be a recurring theme to the objects contained within the site. Creating a new permission structure that is different from the parent is referred to as breaking inheritance. You should encourage users to document the permission structures within their sites. This is important for a number of reasons. For one, it can be difficult to track document level permissions and be difficult to find a particular document if the wrong permissions are set on it. If the site owner is separate from the site collection administrator, they may choose to break inheritance solely for the purpose of having complete control over their site. If permissions are inherited, they will not be able to change user permissions on the new site unless they are site collection administrators.
Lists and libraries
As you dive deeper into the farm hierarchy, much of how the Information Workers choose to use SharePoint falls out of the hands of the SharePoint architect and into the hands of governance. A SharePoint environment can contain a single library that contains millions of documents or it may contain a large number of libraries that contain documents specific to business units. The choices here should be defined in the information architecture. There are some considerations that will need to be planned for and captured in the information architecture and governance plans. These include how to use lists and libraries, the supported security models, and how the new application infrastructure comes into play.
In truth, lists and libraries require planning. You invest a great deal of time and money building your SharePoint environments and you hope that the information architect works with the content owners to ensure that each list and library are well thought out. Here are a few questions that may help in this planning:
What kind of document should live here?
Who is responsible for it?
How long should it be here?
How many versions are needed?
Is this the only copy of this document?
Who has access to the library, folders, or documents?
What business processes are ties to documents in this library?
Large lists. SharePoint 2013 supports the use of large lists. As in the previous version, a list (or library) can contain tens of millions of items. From a SQL Server scalability perspective, this isn’t an issue. In the back end, all of these items are stored in a single table, so breaking lists into smaller units doesn’t impact performance. What can impact performance is the number of items the users decide to bring back into a particular view. By default, SharePoint will bring back pages in chunks of 30, but this is a setting that can be easily overridden by the user. As the list view approaches 5,000, performance will degrade and could potentially impact server performance. SharePoint has incorporated list view thresholds that can be fine-tuned and prevent the users from putting excessive loads on the servers. You will examine these settings in Chapter 9.
Security. Similar to the security described for sites, lists can break inheritance from their parent. This allows for the ability to restrict users who have site access from a particular list or library. The governance plan should highlight how and when security can break inheritance, since it has the tendency to start causing confusion the lower the unique access rules go down.
Apps. You may have noticed that many of the features that existed in previous versions of SharePoint are now considered apps. The SharePoint App model offers a new paradigm for deploying customizations to SharePoint. SharePoint apps, including everything from lists and libraries, are the preferred way of extending the platform (see Figure 1-6). They are deployed from the Corporate Catalog or Office Marketplace and offer flexible and reusable options for any SharePoint deployment: On Premise, Hybrid, or SharePoint Online. This topic is discussed further later in this chapter.

Folders
Over the years, folders in SharePoint have been associated with negative connotations. The truth is, folders are a critical component of the SharePoint information architecture and provide scalability to lists and libraries. The negative aspects have mainly stemmed from how people organize their documents in their network file systems. Often times, documents are thrown into any folder and when your information workers migrate content from their file system, they often bring the data in as is. Without a proper governance plan, this is simply moving a mess from one corner of the room to another.
The SharePoint view should be restricted to as few items as possible, while still adding business value. The performance hit is from the rendering of thousands of items. Folders allow for the organization of these items in much smaller units. The large list thresholds help to keep these designs from negatively impacting our infrastructure.
As with the SharePoint site and libraries, folders support unique permissions. For many organizations, this is a preferred method of dividing the permissions while still keeping documents in one library.
Folders have the ability to capitalize on library features like the Column default value settings feature, which allows for the automatic configuration of metadata based off of hierarchies inside the document library.
List items
The lists, libraries, and folders would have no value without the list item. Everything that is important to you inside your environment will probably fall within this category. List items can inherit permissions from the item, folder, list, and site, or have a unique permission assigned to them. While unique permissions at the item level aren’t typically recommended, it is a nice feature when used in conjunction with automated workflows.
Examining the SharePoint file system
As discussed earlier, the SharePoint farm contains web applications that are made up of content databases and a number of files located on the SharePoint servers. In this section, you will examine where the various sets of files are located and understand how they work. You will start your survey of the files system by being introduced to the IIS hierarchy. Once you have a basic understanding of the IIS files, you will look at how the files located in the SharePoint root folder work with the system. SharePoint 2013 has introduced a new methodology that allows content from SharePoint 2010 to work within the 2013 implementation. You will examine how Feature Fallback behavior works, which will be valuable for those planning on either upgrading to 15 or looking to deploy customizations written for SharePoint 2010 into the 2013 environment.
Finally, you will take a look at how SharePoint customizations are deployed to the farm. It is important to understand how these files work, not only from the perspective of a deployment process, but also how the locations of the files determine how the solution works from a security perspective. For those of you who understand code access security (CAS) policies in SharePoint 2010, you will find that the trust model in SharePoint has changed.
IIS files
Each SharePoint server in the farm is required to have the IIS role configured; IIS is responsible for hosting the application pool and web applications (see Figure 1-7) and receives and responds to user requests. You will learn how IIS works from the HTTP request later in this chapter, but for now, you will examine where these files are located.
IIS, by default, stores the SharePoint web application files at %SystemDrive%inetpubwwwrootwssVirtualDirectories. Each web application gets a unique folder that contains a series of files.
The file system and the database tables are fairly static throughout the life of the SharePoint environment. While SharePoint patches may change the contents within these structures, they are essentially the same as they were when the product was installed. As you add new lists and libraries to SharePoint, new files and database tables are not created.
From the IIS perspective, the file structure is pretty simple. Each web application gets both a unique set of files for that specific web application and a group of common files that are used by the entire SharePoint farm. Examine Figure 1-7. You will note that the team.contoso.local web application has a series of folders associated with it. Notice that some of the folders have blue arrows associated with them.

The top-level folders that do not have the blue arrow associated with them are local to the IIS web application and are unique. These folders (and files) are shown in the file system view in Figure 1-8. Any changes made to files in this location will affect only a single web application. If you have incorporated extended web applications, you will need to change the files in both sources. This is a common mistake when making changes to the web.config file.

_app_bin
Inside the _app_bin folder is a series of Microsoft.Office and Microsoft.SharePoint dynamic-link library (DLL) files that support the individual web applications. In addition to the .dll files, you will find .sitemap files. The SharePoint web content application will have a layouts.sitemap file. Central Administration is supported by layouts.sitemap and admin.sitemap.
_vti_pvt
The vti naming convention is left behind from the old FrontPage days. The original creator of FrontPage was Vermeer Technologies Incorporated; since SharePoint Designer’s roots originated with FrontPage, these extensions are still used today. The _vti_pvt contains three files by default: Buildversion.cnf, services.cnf, and service.cnf.
App_Browers
SharePoint populates this folder with three files by default: compat.browser, compat.crawler .browser, and compat.moss.browser. These files are used for SharePoint’s mobile support and contain XML that helps browsers interpret SharePoint sites. As new mobile browsers are released, these files will need to be updated if they are to support SharePoint. Additionally, if you were to deploy a new mobile Web Part adapter, the compat.browser file would need to be deployed to each server in the farm. Hopefully, this would be done using a SharePoint package and the SharePoint timer service. To review the contents of these files, open them using Notepad.
App_GlobalResources
SharePoint is localized to work in a number of worldwide cultures; the files, located in the App_GlobalResources folder, are responsible for localization (.resx) and contain XML entries that specify objects and strings that map the right text to the object when the application is rendered. An example is shown in Example 1-1.
Bin
The SharePoint web application Bin folder is used to store code files that can expand the functionality of SharePoint. This will be discussed later in the chapter as you learn about deploying solutions. As for this topic, custom development code files that are compiled as .dll files are typically deployed to either the Bin folder or the global assembly cache (GAC). Anything that is deployed to the GAC is fully trusted and has access to server resources; the bin relied on CAS policies. The policy was specified inside the web.config file on each server and one of the biggest changes along this topic from SharePoint 2010 is that the default trust level of the SharePoint web application is now Full instead of WSS_Minimal. It is no longer supported to use CAS policies in SharePoint.
wpresources
Upon examining IIS, you may notice that there are two folders for Web Part resources: wpresources and _wpresources. As with the other files that begin with an underscore, the _wpresources are for globally deployed Web Parts, and their code files are located in the GAC. The local Web Part resource files for the specific web application would exist in the wpresources folder. By default, both locations contain web.config files that are used for their specific scopes. The local version contains a number of defined handlers, while the global resource web.config file does not.
global.asax
The global.asax file has been a part of the .NET Framework since version 1.0 and is intended for handling application-level events raised by ASP.NET applications or HttpModules. The global.asax file that is deployed with SharePoint 2013 is an optional file and does not contain anything other than its assembly location.
web.config
As with the global.asax file, the web.config file has been part of the .NET Framework from the beginning. This file, however, contains critical configuration information and becomes complicated when comparing a standard web.config file with that of SharePoint. While making changes to the web.config file may be required to deploy new features to SharePoint or configure authentication, it is highly recommended that these changes not be done manually. Furthermore, each change that does happen will have to be implemented on each server that is hosting that particular SharePoint web application. As features are added to SharePoint web application, a copy of the web.config file is automatically created containing the last configuration. Making incorrect changes in this file can disable your SharePoint web application.
SharePoint Root
The SharePoint Root folder contains all of the critical files that are used by the SharePoint infrastructure. The virtual IIS folders discussed previously live in various places within this location. You will see a brief description of each of these folders and then dive into more detail on the ones that you are more likely to care about. Pay close attention to the case in the names. If the folder contains all capital letters, in many cases, it has a virtual mapping to IIS for each SharePoint web application.
ADMISAPI. Contains a number of files that provide or support administration web services. This location is mapped to the IIS _vti_adm virtual folder.
BIN. Contains a number of .dll and .exe files that support SharePoint. Most notably, this location contains OWSTIMER, PSCONFIG, SPMETAL, WSSTracing, WSSADMIN, VideoThumbnailer, SPWriter, and CsiSrvExe.
Client. Contains files for the support of Microsoft Online services.
CONFIG. Contains configuration files that are needed for a wide variety of SharePoint operations, including mapping objects from SharePoint 2010 to SharePoint 2013 during the upgrade process.
HCCab. Contains a series of .cab files that are broken down into the various languages installed on the system. These files are used in the SharePoint Help system.
Help. Contains a compiled HTML file that opens up the SharePoint Help system.
ISAPI. Contains a number of web service (.asmx), web service discovery pages (.aspx), and dynamic libraries (.dll) files that support web service operations for SharePoint. This location is mapped to the IIS virtual _vti_bin folder.
LOGS. By default, this is the location (%CommonProgramFiles%Microsoft SharedWeb Server Extensions15LOGS) of the Unified Logging System (ULS) logs that are configured in Central Administration. Depending on how the Diagnostic Log Settings are configured, this location may hold a wealth of information. Finding errors in this location may be difficult but is made easier by the implementation of the correlation token. You will learn about this in more detail in Chapter 9. These logs are used to populate the Usage and Health database as configured by the Diagnostics Data Provider: Event Log timer job.
Policy. Contains a number of configuration and dynamic library files that are responsible for assembly redirection. SharePoint 2013 has support for both SharePoint 2007 and SharePoint 2010.
Resources. Contains resources for localizing SharePoint 2013.
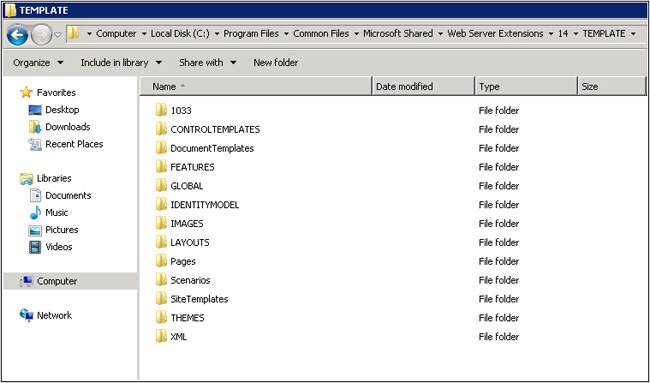
TEMPLATE. Contains a number of folders that support various customizations, features, and core website files. Figure 1-9 shows the complete listing of folders. Descriptions of the most notable folders include the following:
LCIDSts. Contains the local ID files that are copied to the root of the website when the Team Site template is selected.
ADMIN. Contains master pages and templates for the Central Administration website and other core features like BDC, Content Deployment, Search, and the Secure Store service.
CONTROLTEMPLATES. Contains control templates that determine the layout of list item forms.
DocumentTemplates. Contains the wkpstd.aspx page that is used to create document libraries.
FEATURES. Contains the additional functionality and features that extend SharePoint.
IMAGES. Contains images that are shared by all of the SharePoint web applications on the server. This location is accessible by the _layouts/images virtual directory.
LAYOUTS. Contains a wide variety of folders and files that are used for creating lists and site administration pages. This location is accessible by the _layouts virtual directory.
SiteTemplates. Contains the files that are copied when various site templates are created. These templates include the Blog, Central Administration, Meeting Workspaces, Group Work Site, Team Site, Tenant Administration, and Wiki Site.
SQL. Contains stored procedures for SQL Server.
THEMES. Contains a number of folders and their supporting files that provide the themes in SharePoint.
WorkflowActivities. Contains the Microsoft.SharePoint.WorkflowServices.Activities.dll file.
UserCode. Contains the User Code Host Service, User Code Worker Process, and User Code Process Proxy applications that support the Sandbox Solution architecture.
WebClients. Contains web client configurations for a number of SharePoint Service Applications and Services.
WebServices. Contains the web.config files for the application root, Business Data Connectivity, Security Token, Subscription Settings, Application Management, PowerPoint Conversion, Secure Store, and Topology services.

Feature Fallback behavior
One of the new features of SharePoint 2013 is the Feature Fallback infrastructure. In SharePoint 2010, if you installed a SharePoint on a new server, you would see the 14 (SharePoint root) and wpresources folder. In SharePoint 2013, we see not only the current version (15) and the wpresources folder, but also a folder for the previous version (14). The hierarchy of this folder is shown in Figure 1-10.
In SharePoint 2010, custom code from previous versions could be deployed, but depending on how the code was upgraded, it may have needed .dll redirections. The Feature Fallback infrastructure goes well beyond the capabilities of SharePoint 2010 by providing a full backward-compatible folder structure. To test how it works, take a SharePoint deployment project (.wsp) from SharePoint 2010 and deploy it to the 2013 infrastructure. You will notice, as shown in Figure 1-11, that the deployment files are implemented into the 14 root structure and the feature works exactly the way it did in SharePoint 2010.

In addition to being able to support previous versions of deployed solutions, the infrastructure of SharePoint 2013 also fully supports branding and other customizations from SharePoint 2010. In fact, when selecting new site templates, you can elect to choose a template from SharePoint 2010, as shown in Figure 1-12. This is a fantastic feature that may help organizations that have invested a great deal of time and money into their corporate brand to make the move to SharePoint 2013 without the fear of losing their investment. This is different from what SharePoint 2010 offered with its Visual Upgrade. New sites that were created in SharePoint 2010 had to use new templates and it was unsupported to use Windows PowerShell to modify those sites to use the 2007 master pages.

The SharePoint 2010 experience works through the entire site; you can, of course, upgrade to the SharePoint 2013 experience simply by clicking Start Now in the message bar across the top of the page, as shown in Figure 1-12.
Deployed solutions
The extensibility of SharePoint is one of its greatest product features; with the release of SharePoint 2013, the platform introduces yet another way to deploy solutions to your implementation: the SharePoint application model. The SharePoint application model joins farm and sandboxed solutions to help ensure that the information workers are getting the full power of what SharePoint has to offer. Previously, if an organization needed a particular solution, it may have been restricted to On Premise deployments. With the focus of bringing SharePoint to the cloud, Microsoft needed to reexamine how solutions would be deployed. In this section, you will see the highlights of farm solutions and sandboxed solutions, and then be introduced to the new SharePoint application model. Knowing how each of these types of solutions work may have implications about which SharePoint offering helps meet the business requirements you are trying to satisfy.
Farm solutions
Prior to SharePoint 2010, the only way to deploy customizations was by way of farm solutions. This model deployed fully trusted solutions to the file system of the server; therefore, if extending SharePoint was needed, a full understanding of the file system would certainly benefit SharePoint professionals. It is important to understand what type of solution is needed since some can still only be deployed as farm solutions. An example of these types of jobs would include timer jobs and other customizations that required server-side code. Farm solutions are restricted to On Premise deployments and deploy files to either the GAC (Windows Assembly) or the BIN folder of the SharePoint web application. Because of the global nature of this type of solution, a farm administrator would be required to deploy them.
Sandboxed solutions
As the SharePoint product matures and the needs of the organizations that use it change, other models were needed. With the release of SharePoint 2010, customizations were able to be deployed via sandboxed (or User Code) solutions. This model allowed for elements to deploy partially trusted code, meaning that the solutions only had access to certain resources. This helped isolate the code and offered resource throttling to ensure that a particular solution wouldn’t have a negative impact on the entire SharePoint farm. Sandboxed solutions took the deployment responsibilities from the farm administrators and handed it to the site collection administrators or a user who had full control at the root of the site collection. The overall configuration was still in the hands of the farm administrators. They were responsible for ensuring that the User Code Service was running and that the load balancing, quotas, and resource points were configured. Sandboxed solutions (like Farm solutions) are packaged as .wsp files, and they contain any number of elements: features, site definitions, assemblies, and Web Parts. The .wsp package was then deployed to a solution gallery for the site collection, where it could be put in service by the site collection administrator.
Once activated, the sandboxed solution shows its available components in the same way as a farm solution. Requests for sandboxed solution elements are passed to the SharePoint User Code service (SPUCHostService.exe), which either starts a new sandbox worker process (SPUCWorkerProcess.exe) or uses an existing one. The worker process then loads the solution assembly into a new application domain. If the maximum number of application domains is reached, an existing one is released prior to creating a new one. Once the assembly has been loaded, it is free to execute the code. Some solutions that are ideal for the sandbox would include Web Parts, event receivers, feature receivers, SharePoint Designer workflow activities and Microsoft InfoPath business logic.
SharePoint App model
Sandbox solutions were definitely a step in the right direction. For organizations who had policies that restricted the deployment of farm solutions or used SharePoint Online, the partially trusted model offered options they wouldn’t have with farm solutions.
Even with the flexibility offered by sandbox solutions, they still had limitations due to the nature of what they were designed to do. SharePoint 2013 and the growing implementations of SharePoint Online needed a new application deployment model. Enter the SharePoint App model.
The SharePoint App model offers a new paradigm of deploying customizations to SharePoint. SharePoint apps only support client-side code and offer a safer way to add customizations than farm solutions. Information workers can browse the SharePoint Platform Storefront or Corporate Marketplace and get the solutions they need. The app model has three different deployment models: SharePoint-Hosted App, Self-Hosted App, and Azure-Provisioned App. While the last two models don’t impact the design of the architecture, they are included here for reference.
The SharePoint-Hosted App is basically a subweb of a site collection, and apps can only deploy web-scoped features. One of the built-in features of SharePoint apps is that information workers cannot manipulate them; this avoids accidental breaking of the apps using the browser or Microsoft SharePoint Designer.
The Self-Hosted App model allows organizations to provide solutions on any platform using any language that is supported on that platform. In this model, the developing organization is responsible for providing the hosting infrastructure, which allows for greater flexibility in exchange for greater responsibility.
The Azure-Provisioned App model allows the flexibility of building solutions without having the developing team or organization host the solution. These components are provisioned as needed in Windows Azure.
The SharePoint app is isolated and the features are not visible outside of the app. If site collection resources are needed, farm solutions would still be the only option. From a security perspective, SharePoint apps are restricted to the permissions of the user, so having the information worker gaining access to resources they are restricted to is not an issue. To gain an understanding of how the infrastructure can be configured to support the new SharePoint App model, see Chapter 4.
Examining the SharePoint databases
The SharePoint file system doesn’t change as new site collections or sites are created. These components are created in new or existing databases. This means that the databases are considered the principal vehicles for service; see Chapter 10 for methodologies on protecting the SharePoint databases. The databases used in a specific environment are determined by the product, version, edition, and features that are running. Database size and the edition of SQL Server that should be used are determined by the capacity and feature requirements of the desired implementation.
In this section, you will review techniques for building the SharePoint environment using the SQL Server alias and encounter a brief overview of the databases that are the backbone of the SharePoint 2013 infrastructure.
SQL Server aliases
One might wonder why a book on the SharePoint 2013 architecture mentions SQL Server aliases. It is important to highlight them here because when reviewing a great number of SharePoint farms, this is one of the critical steps that is often neglected. Prior to the SharePoint 2010 June 2010 cumulative update, SQL Server aliases were required if the SharePoint implementation used named instances and provisioned the User Profile service. While this is not a limitation in the SharePoint 2013 infrastructure, it is still highly recommended that you use SQL Server aliases when addressing named instances. SQL Server aliases are essentially a variable that is configured on each SharePoint server that points to a particular SQL Server.
Type cliconfg into a cmd window or Windows PowerShell Mangement Shell. The SQL Server Client Network Utility will open, as shown in Figure 1-13.

Create a new TCP/IP server alias that points to the actual SQL Server named instance. In the event that you need to move data to another server, you simply need to modify the alias and move the data to the server you wish to use. If you fail to use aliases, there are many configuration settings that will need to be modified using Windows PowerShell.
SharePoint system databases
When you create the initial farm (either using the SharePoint Products and Configuration Wizard or Windows PowerShell), two databases are created: SharePoint_Config and SharePoint_Content_Admin. SharePoint web applications store their data in content databases.
SharePoint_Config. Contains data about all SharePoint databases, all IIS web applications, trusted solutions, Web Part packages, site templates, and farm and web application settings specific to SharePoint, such as default quotas and blocked file types. It must be colocated with the Central Administration content database (SharePoint_Content_Admin) and only one database SharePoint_Config database is supported per farm. The SharePoint_Config database isn’t expected to grow significantly, so it is considered to be a small database and can grow up to 1 GB.
SharePoint_Content_Admin. Similar to the content databases created for SharePoint web applications, this database stores the actual data for the Central Administration web application. The SharePoint_Content_Admin database must be colocated with the SharePoint_Config database. Similar to the SharePoint_Config database, it is not expected to grow significantly, so it is considered to be a small database and can grow up to 1 GB.
WSS_Content. Stores all site content, including files in document libraries, list data, Web Part properties, audit logs, apps for SharePoint, and user names and rights. All of the data for a specific site resides in one content database. Content databases can contain one or more site collections. The size of the content database will vary in size; while the databases are supported up to 4 terabytes, it is strongly recommended to keep them under 200 GB. The 4 terabyte size limits are for single-site repositories and archives with non-collaborative I/O and usage patterns such as Records Centers. It is recommended that administrators scale up databases that supports a site collection and scale out (by adding more databases) to support web applications that need additional site collections.
SharePoint service application databases
There are a number of service applications that rely on databases; these databases are created when the various service applications are provisioned. These services include User Profile service application, Search service application, App Management service application, Secure Store service application, Usage and Health Data Collection service application, Word Conversion service, Microsoft SharePoint Foundation Subscription service application, Business Data Connectivity service application, PerformancePoint Services service application, State service application, and Word Automation Services service application. Here is a breakdown of these services and their databases:
User Profile service. Contains the following three databases:
Profile. Stores and manages users and some social information; the majority of the social information has been moved to the My Site of the user. The size of the database can range up to 1 terabyte in some instances and is considered to be medium to large and is read-heavy.
Synchronization. Stores configuration and staging data for use when profile data is being synchronized with directory services such as Active Directory. The size of the database is dependent on the number of users, groups, and the ratio of users to groups. The database can get quite large.
Social Tagging. Stores social tags and notes created by users along with their respective URLs. The size of the database is determined by the number of tags and ratings created and used and can span from small to extra large (over 1 terabyte).
SharePoint Search service. Contains the following four databases:
Search Administration. Hosts the Search application configuration and access control list (ACL) for the crawl component. The database may grow up to 100 GB.
Analytics Reporting. Stores the results for the usage analysis reports and extracts information from the Link database when needed. The database can grow in excess of 100 GB and it is recommended using an additional Analytics Reporting database when the main database size becomes greater than 200 GB. During analytics updates, the database is write-heavy.
Crawl. Stores the state of the crawled data and the crawl history. Additional crawl databases should be created for every 10 million items crawled. The database is read-heavy and should be hosted by SQL Server 2008 Enterprise edition or higher so that the Search service can take advantage of data compression.
Link. Stores the information that is extracted by the content processing component and the click-through information. On sites with heavy traffic, the database should utilize separate spindles from other databases. Additional Link databases should be created for every 60 million documents crawled. The database grows on disk by 1 GB per 1 million documents fed and the click data grows linearly with query traffic (1 GB per million queries). An additional Link database should be added per 100 million expected queries per year. The database experiences heavy-writes during content processing.
App Management service application. Stores the App licenses and permissions that are downloaded from the Global Marketplace. The database is write-heavy during Apps installation and license renewal.
Secure Store service application. Stores and maps credentials such as account names and passwords. Microsoft recommends that the database be hosted on a separate database instance, with access limited to one administrator since it may contain sensitive data.
Usage and Health Data Collection service application. Stores health monitoring and usage data temporarily, and also is used for reporting and diagnostics. The Usage database is the only SharePoint database that can be queried directly and have schema modified by either Microsoft or third-party applications. The database size varies based on the retention policy and actual traffic load. It is recommended that the Usage database be placed on a separate spindle, and it is extremely write-heavy and can grow in excess of 1 terabyte.
Word Conversion. Stores information about pending and completed document conversations. The database is very small and is read-and-write-heavy once per conversion item.
Microsoft SharePoint Foundation Subscription Settings service application. Stores features and settings information for hosted customers. This database is not created by default and must be created by using Windows PowerShell or SQL Server. The database is typically small, being less than 100 MB. The database is read-heavy.
Business Data Connectivity service application. Stores external content type and related objects.
Project Server 2013. Stores all the data for a single Project Web App–enabled site along with all project and portfolio management (PPM) data, time tracking and timesheet data, and aggregated SharePoint project site data. The database is typically read-heavy.
SQL Server PowerPivot service application. Stores data refreshed schedules and PowerPivot usage data that is copied from the central usage data collection database. When in use, PowerPivot stores additional data in content databases and in the Central Administration content database. It requires SQL Server 2012 Analysis Service, Business Intelligence, or Enterprise edition.
Managed Metadata service. Stores managed metadata and syndicated content types. The database is read-heavy.
PerformancePoint service application. Stores temporary objects and persisted user comments and settings. The database is read-heavy.
State service application. Stores temporary state information for InfoPath Forms Service, Exchange, the chart Web Part, and Visio Services. The database size depends on the usage of the feature but can grow in excess of 200 GB. The database is read-heavy.
Word Automation Services service application. Stores information about pending and completed document conversions and is read-heavy.
Machine Translation Services service application. Stores information about pending and completed batch document translations with file extensions that are enabled. The database is read-heavy.
App for SharePoint. Stores information about apps for SharePoint and Access Apps. The databases are read-heavy.
Putting it all together
Up until this point, you have learned about the core components that make up a SharePoint farm and its subsequent web applications. To help understand how these components work together, this chapter will conclude by walking you through the SharePoint 2013 pipeline. To review, when you create a SharePoint web application, a new IIS web application is created that has a number of elements ranging from a content database to web application-specific files that include the web.config file. As you will learn in this section, config files are critical to how SharePoint responds to a particular user request. On a given SharePoint server, there are actually a number of config files, and each plays a distinct role in not only how SharePoint web applications work, but ASP.NET web applications in general. The configuration files operate in a narrowing scope from a high-level, server-wide configuration down to the specific details of each web application. The configuration file hierarchy starts with the machine.config file and ends with the web.config file within the IIS website. Remember that extending a SharePoint web application will create another IIS web application, so if the web.config file of one zone requires modification, the same may be true for the other IIS web application as well.
The various web.config files define a number of HTTP handlers and HTTP modules that map out the components that should be included in the HTTP pipeline. For the sake of this topic, this chapter will focus on the elements that are important to the SharePoint request. The modules that are listed in Figure 1-14 are at the end of the HTTP pipeline. These can be reviewed in greater detail by visiting IIS, selecting Modules | View Ordered List. Once there, examine the second column to see where the SharePoint .dll files enter the picture.

Web applications, like SharePoint, have the ability to modify the HTTP modules that will be processed within their web.config file. Upon examining the web.config file for Central Administration, take note that a number of modules have been removed: AnonymousIdentification, FileAuthorization, Profile, WebDAVModule and Session. A number of modules have also been added: SPNatvieRequest-Module, SPRequestModule, ScirptModule, SharePoint14Module, StateServiceModule, PublishingHttpModule, DesignHttpModule, and Session. With the single exception of the DesingHttpModule, this was the same configuration in SharePoint 2010.
The following steps explain the first HTTP request:
The user issues a request over the Internet.
The HTTP Protocol Stack (HTTP.sys) intercepts the request and passes it to the Svchost.exe.
3Svchost.exe contains the Windows Activation Services (WAS) and the WorldWide Web Publishing Service (WWW Service).
WAS requests configuration information from the configuration store, applicationHost.config. This will map virtual directories to physical directories.
WWW Service receives configuration information, such as application pool and site configuration.
WWW Service uses the configuration information to configure HTTP.sys.
WAS starts a worker process for the application pool to which the request was made.
Authentication is handled.
A request comes in for an ASP.NET page.
The request is given to the SharePoint14Module.
The page handler is unable to find a precompiled version of the page class on disk, so it must grab the file and give it to the ASP.NET engine for parsing.
The HTTP request enters the various SharePoint modules, as outlined in Figure 1-14.
The SharePoint14Module will contact either the file system or the content database for the appropriate page class information.
The ASP.NET page engine parses the file and generates a page class.
The page class is compiled into a .NET assembly and cached on the disk.
An instance of the requested page’s class is created.
The response generated from the requested page class is sent back to the original caller.
You will notice that step 12 actually includes a number of steps, since the HTTP request enters the SharePoint modules. ASP.NET generally expects that the incoming URL will map directly into the file system on the server. As you know, SharePoint makes extensive use of virtual directories that map into the SharePoint Root folder, which is used to return pages that exist in locations like /_layouts/. The modules that are native to ASP.NET are only configured to handle request for resources such as .aspx files. Since SharePoint is designed to store files of any type, the SharePoint modules help surface these documents, but only after verifying that the requesting user or process has permission to access the file. The caching mechanisms in SharePoint are required to work differently than the native ASP.NET caches to provide better performance for SharePoint pages. As a result, SharePoint serves most .aspx pages in decompile mode. Since SharePoint offers a robust client object model, the modules are also responsible for handing this feature since ASP.NET doesn’t have this type of functionality. SharePoint also has a highly configurable request throttling feature, which will honor, restrict, ignore, or reroute requests based on the health of the server. The SPRequestModule, which is the second SharePoint module in the pipeline, is responsible for registering the SharePoint virtual path provider, which serves, as an URL interpreter helping to route user requests to the appropriate file, checks to see if the file is checked out, and resolves the URL to a physical path. The SPRequestModule is also now responsible for handling the new Request Management (RM) feature in SharePoint. If the RM service is running (which is not enabled by default), the RM settings and check to see if Routing or Throttling has been enabled and then routes the request as necessary to a server running the Microsoft SharePoint Foundation Web Application service. The SPRequestModule also evaluates requests to see if they are from mobile devices and forwards those requests to the appropriate mobile page. Finally, the SPRequestModule then determines whether a request should be routed to the SharePoint14Module (owssvr.dll) and does some processing of the HTTP headers in the request that is expected by the SharePoint14Module.
In step 13, notice that the SharePoint14Module will contact either the file system or the content database for the appropriate page class information. This is where understanding the structure of IIS comes in handy. URLs with references to the _layouts directory (as shown previously in Figure 1-7) will use the file system. Basic requests for content will extract the data from the content database. The important takeaway here is that as each request is handled by IIS, various files are accessed both on the file system and in the database. Files that are in the database require a greater tax on the system since the SharePoint server will need to access the content database that resides in SQL Server. One of the most expensive hits in the HTTP request is when SharePoint has to pull data from SQL Server, so it is highly recommended that caching features be enabled when appropriate. You will gain an understanding of caching and performance in Chapter 9. One of the decisions you will need to make as you design your SharePoint solution will be to determine how each of these moving pieces should be used together to offer the best solution.