
Now that we have acquired some practice using services, we step up to the next level. We'll deploy Apache Spark on Swarm. Spark is an open source cluster computing framework from the Apache foundation, which is mainly used for data processing.
Spark may be (but not limited to) used for things, such as:
- Analysis of big data (Spark Core)
- Fast and scalable data structured console (Spark SQL)
- Streaming analytics (Spark Streaming)
- Graph processing (Spark GraphX)
Here we will focus mainly on the infrastructural part of Swarm. If you want to learn how to program or use Spark in detail, read Packt's selection of books on Spark. We suggest starting with Fast Data Processing with Spark 2.0 - Third Edition.
Spark is a neat and clear alternative for Hadoop, it is a more agile and efficient substitute for the complexity and magnitude of Hadoop.
The theoretical topology of Spark is immediate and can reckon the Swarm mode on one or more managers leading the cluster operations and a certain number of workers who are executing real tasks.
As for managers, Spark can use its own managers called standalone managers (as we'll do here) or use Hadoop YARN or even exploit Mesos features.
Then, Spark can delegate storage to an internal HDFS (Hadoop Distributed Filesystem) or to external storage services, such as Amazon S3, OpenStack Swift, or Cassandra. Storage is used by Spark to get data to elaborate and then to save the elaborated results.
We'll show you how to start a Spark cluster on a Docker Swarm cluster, as an alternative to start Spark with virtual machines. The example defined in this chapter can get many benefits from containers:
- Starting containers is much more quicker
- Scaling containers in a pet model is more immediate
- You can get Spark images without having to create VMs, to write custom scripts, adapt Ansible Playbooks. Just
docker pull - You can create a dedicated overlay network with Docker Networking features, without physically compromising or invoking a networking team
Let's start defining a tiny Apache Spark cluster built with the classical Docker tools, which are basically Docker commands on a Docker host. Before understanding the big picture, we need to start familiarizing ourselves with Swarm concepts and terminologies on the field.
In this chapter, we'll work with the google_container images, specifically with Swarm version 1.5.2. Many improvements are included in the 2.0 version, but these images are proven to be very stable and reliable. So, we can start by pulling them for the master and the workers from the Google repository:
docker pull gcr.io/google_containers/spark-master docker pull gcr.io/google_containers/spark-worker
Spark can run on the top of YARN, Mesos, or Hadoop. In the following examples and chapters, we're going to use its standalone mode, because it is the easiest and requires no additional prerequisites. In a standalone Spark cluster mode, Spark allocates resources based on cores. By default, an application will grab all the cores in the cluster, so we're going to limit the resources dedicated to the workers.
Our architecture will be very straightforward: one master, which will be responsible for managing the cluster, and three workers for the nodes running Spark jobs. For our purpose, the master has to publish port 8080 (the Web UI we'll use for convenience) and we'll call it spark-master. By default, the worker containers attempt to connect to the URL spark://spark-master:7077, so apart from linking them to the master, no further customization are required.
So, let's pass it to the practical part and initialize a Spark master with the following code:
docker run -d -p 8080:8080 --name spark-master -h spark-master gcr.io/google_containers/spark-master
This runs in the daemon mode (-d), a container from the gcr.io/google_containers/spark-master image, assigns the name (--name) spark-master to the container and configures its hostname (-h) to spark-master.
We can connect now a browser to the Docker host, at port 8080, to verify that Spark is up and running.

It still has no Alive Workers, which we're going to spawn now. We start the workers with the following commands just before we take note of the ID of the Spark master container:
docker run -d --link 7ff683727bbf -m 256 -p 8081:8081 --name worker-1 gcr.io/google_containers/spark-worker
This starts a container in the daemon mode, links it to the master, limits the memory-in-use to a maximum of 256M, exposes port 8081 to web (worker) management, and assigns it to the container name worker-1. Similarly, we start the other two workers:
docker run -d --link d3409a18fdc0 -m 256 -p 8082:8082 -m 256m -- name worker-2 gcr.io/google_containers/spark-worker docker run -d --link d3409a18fdc0 -m 256 -p 8083:8083 -m 256m -- name worker-3 gcr.io/google_containers/spark-worker
We can check on the master if everything is connected and running:

So far, we have discussed the not so important part. We're now going now to transfer the concepts already discussed to Swarm architecture, so we'll instantiate the Spark master and workers as Swarm services, instead of single containers. We'll create an architecture with a replica factor of one for the master, and a replica factor of three for the workers.
We'll define a real storage and start some real Spark tasks in Chapter 7, Scaling Up Your Platform.
We begin by creating a new dedicated overlay network for Spark:
docker network create --driver overlay spark
Then, we set some labels onto nodes to be able to filter later. We want to host the Spark master on the Swarm manager (node-1) and Spark workers on Swarm workers (node-2, 3 and 4):
docker node update --label-add type=sparkmaster node-1 docker node update --label-add type=sparkworker node-2 docker node update --label-add type=sparkworker node-3 docker node update --label-add type=sparkworker node-4
We will now define our Spark services in Swarm, similar to what we did for Wordpress in the preceding section, but this time we will drive the scheduling strategy by defining where to start the Spark master and the Spark workers with the maximum precision.
We begin with the master as shown:
docker service create --container-label spark-master --network spark --constraint 'node.labels.type==sparkmaster' --publish 8080:8080 --publish 7077:7077 --publish 6066:6066 --name spark-master --replicas 1 --limit-memory 1024 gcr.io/google_containers/spark-master
A Spark master exposes port 8080 (the web UI) and optionally, for the clarity of the example, here we also expose port 7077 used by the Spark workers to connect to the master and port 6066, the Spark API port. Also, we limit the memory to 1G with --limit-memory. Once the Spark master is up, we can create the service hosting the workers, sparkworker:
docker service create --constraint 'node.labels.type==sparkworker' --network spark --name spark-worker --publish 8081:8081 --replicas 3 --limit-memory 256 gcr.io/google_containers/spark-worker
Similarly, we expose port 8081 (the workers web UI), but it's optional. Here, all the Spark containers are scheduled on spark worker nodes, as we defined earlier. It will take some time to pull the images to the hosts. As a result, we have the minimal Spark infrastructure:
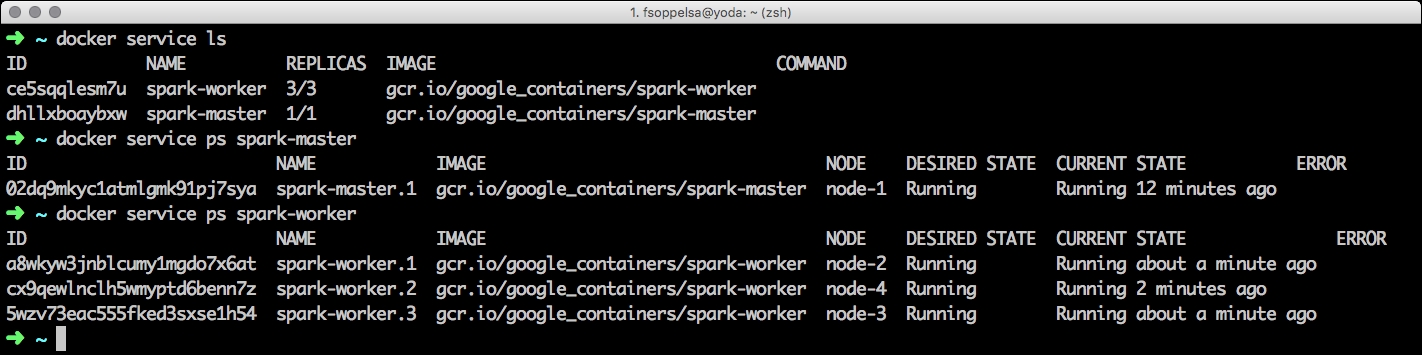
The Spark cluster is up and running, even if there is a little note to add:
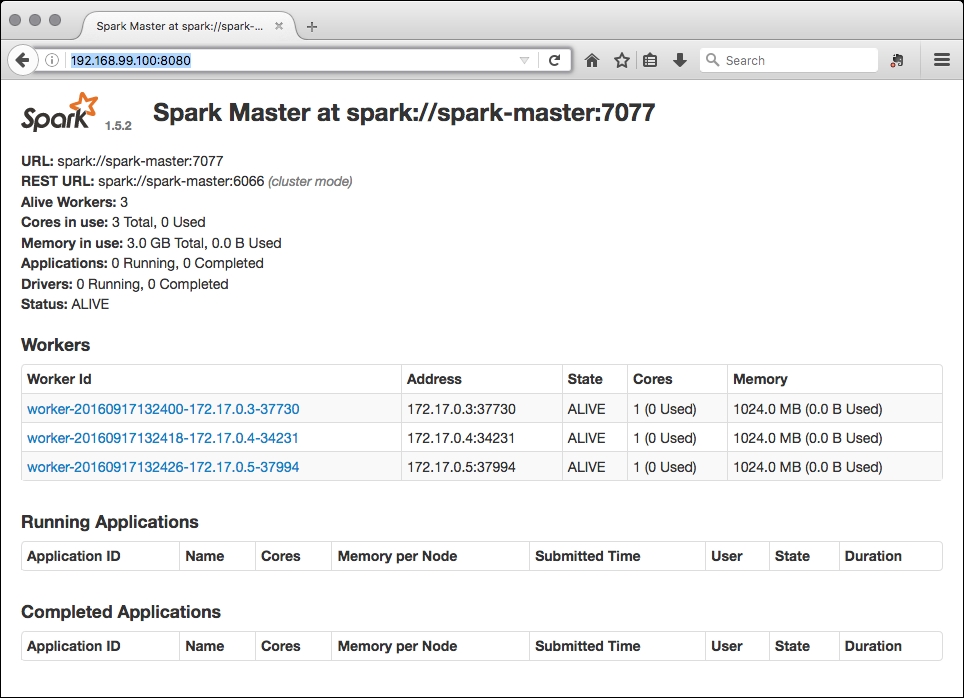
Despite the fact that we limited the memory to 256M for each worker, in the UI we still see that Spark reads 1024M. This is because of the Spark internal default configuration. If we connect to any of the hosts, where one of the workers is running, and check its statistics with the docker stats a7a2b5bb3024 command, we see that the container is actually limited:
