
C H A P T E R 3
Web Application Architecture
Before we start our journey into the internals of Spring MVC, we first need to understand the different layers of a web application. And we’ll begin that discussion with a brief introduction of the MVC pattern in general, including what it is and why should we use it. We will also cover some of the interfaces and classes provided by the Spring Framework to express the different parts of the MVC pattern.
After reviewing the MVC Pattern, we will go through the different layers in a web application and see what role each layer plays in the application. We will also explore how the Spring Framework can help us out in the different layers and how we can use it to our advantage.
The MVC Pattern
The Model View Controller pattern (MVC pattern) was first described by Trygve Reenskaug when he was working on Smalltalk at Xerox. At that time, the pattern was aimed at desktop applications. This pattern divides the presentation layer into different kinds of components. Each component has its own responsibilities. The view uses the model to render itself. Based on a user action, the view triggers the controller, which in turn updates the model. The model then notifies the view to (re)render itself (see Figure 3-1).
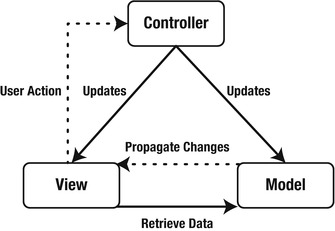
Figure 3-1. The MVC pattern
The MVC pattern is all about separation of concerns. As we mentioned previously, each component has its own role (see Table 3-1). Separation of concerns is important in the presentation layer because it helps us keep the different components clean. This way, we don’t burden the actual view with business logic, navigation logic, and model data. Following this approach keeps everything nicely separated, which makes it easier to maintain and test our application.

The classic implementation of the MVC pattern (as shown in Figure 3-1) involves the user triggering an action. This prompts the controller to update the model, which in turn pushes the changes back to the view. The view then updates itself with the updated data from the model. This is the ideal implementation of an MVC pattern, and it works very well in desktop applications based on Swing, for example. However, this approach is not feasible in a web environment due to the nature of the HTTP protocol. For a web application, the user typically initiates action by issuing a request. This prompts the app to update and render the view, which is sent back to the user. This means that we need a slightly different approach in a web environment. Instead of pushing the changes to the view, we need to pull the changes from the server.
This approach seems quite workable, but it isn’t as straightforward to apply in a web application as one might think. The Web (or HTTP) is stateless by design, so keeping a model around can be quite difficult. For the Web, the MVC pattern is implemented as a Model 2 architecture (see Figure 3-2)1. The difference between the original pattern (Model 1 was shown in Figure 3-1) and the modified pattern is that it incorporates a front controller that dispatches the incoming requests to other controllers. These controllers handle the incoming request, return the model, and select the view.
____________

Figure 3-2. The Model 2 MVC pattern
The front controller is the component that handles the incoming requests. First, it delegates the request to a suitable controller. When that controller has finished processing and updating the model, the front controller will determine which view to render based on the outcome. In most cases, this front controller is implemented as a javax.servlet.Servlet servlet (e.g., ActionServlet in struts or FacesServlet in JSF). In Spring MVC, this front controller is org.springframework.web.servlet.DispatcherServlet.
Application Layering
In the introduction, we mentioned that an application consists of several layers (see Figure 4-3). We like to think of a layer as an area of concern for the application. Therefore, we also use layering to achieve separation of concerns. For example, the view shouldn’t be burdened with business or data access logic because these are all different concerns and typically located in different layers.
Layers should be thought of as conceptual boundaries, but they don’t have to be physically isolated from each other (in another virtual machine). For a web application, the layers typically run inside the same virtual machine. Rod Johnson’s book, Expert One-on-One J2EE Design and Development (Wrox, 2002), has a good discussion on application distribution and scaling.

Figure 3-3. Typical application layering
Figure 3-3 is a highly generalized view of the layers of a Spring MVC application. This layering can be seen in many applications. The data access is at the bottom of the application, the presentation is on top, and the services (the actual business logic) are in the middle. In this chapter, we will take a look at this architecture and how everything is organized. Table 3-2 provides a brief description of the different layers.

Communication between the layers is from top to bottom. The service layer can access the data access layer, but the data access layer cannot access the service layer. If you see these kinds of circular dependencies creep into your application, take a few steps back and reconsider your design. Circular dependencies (or bottom to top dependencies) are almost always a sign of bad design and lead to increased complexity and a harder-to-maintain application.
![]() Note Sometimes, one might also encounter the term, tier. Many people use tier and layer interchangeably; however, separating the two helps when discussing the application architecture or its deployment. We like to use layer to indicate a conceptual layer in the application, whereas a tier indicates the physical separation of the layers on different machines at deployment time. Thinking in layers helps the software developer, whereas thinking in tiers helps the system administrator.
Note Sometimes, one might also encounter the term, tier. Many people use tier and layer interchangeably; however, separating the two helps when discussing the application architecture or its deployment. We like to use layer to indicate a conceptual layer in the application, whereas a tier indicates the physical separation of the layers on different machines at deployment time. Thinking in layers helps the software developer, whereas thinking in tiers helps the system administrator.
Although Figure 3-3 gives a general overview of the layers for a web application, we could break it down a little further. In a typical web application, we can identify five conceptual layers (see Figure 3-4). We can split the presentation layer into a web and user interface layer, but the application also includes a domain layer (see the “Spring MVC Application Layers” section later in this chapter). Typically, the domain layer cuts across all layers because it is used everywhere from the data access layer to the user interface.

Figure 3-4. Web MVC application layers
![]() Note The layered architecture isn’t the only application architecture out there; however, it is the most frequently encountered architecture for web applications.
Note The layered architecture isn’t the only application architecture out there; however, it is the most frequently encountered architecture for web applications.
If we look at the sample application, the architecture shown in Figure 3-4 is made explicit in the package structure. The packages can be found in the bookstore-shared project (see Figure 3-5). The main packages include the following:
com.apress.prospringmvc.bookstore.domain: the domain layercom.apress.prospringmvc.bookstore.service: the service layercom.apress.prospringmvc.bookstore.repository: the data access layer
The other packages are supporting packages for the web layer and the com.apress.prospringmvc.bookstore.config package contains the configuration classes for the root application context. The user interface and web layer we over the course of this book, and these layers will be in the com.apress.prospringmvc.bookstore.web package and in Java Server Pages where needed for the user interface.
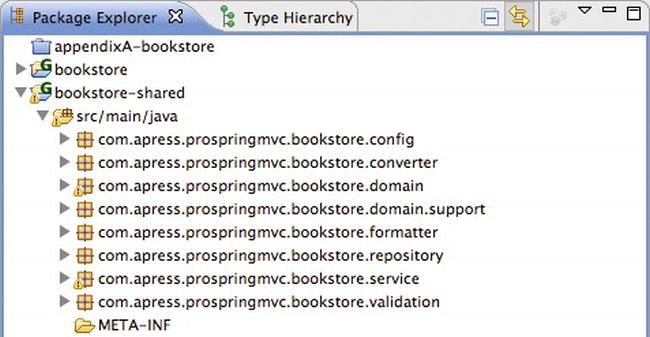
Figure 3-5. The Bookstore packages overview
Separation of Concerns
As we mentioned in Chapter 2, it is important to have a clear separation of concerns. If we look at the architecture from Figure 3-4, the separation of concerns is present in the layers. Separating the concerns into different layers helps us achieve a clean design, as well as a flexible and testable application.
Creating or detecting layers can be hard. A rule of thumb is that, if a layer has too many dependencies with other layers, we might want to introduce another layer that incorporates all the dependencies. On the other hand, if we see a single layer throughout different layers, we might want to reconsider this layer and make it an aspect of the application. In this case, we can use the AOP functionality from the Spring Framework to apply these aspects at runtime (see Chapter 2).
Coupling layers—for example, the service layer will need to talk to the data access layer—is done by defining clear interfaces. Defining interfaces and programming to interfaces reduces the actual coupling to concrete implementations. This reduced coupling and reduced complexity results in an easier-to-test and easier-to-maintain application. Another benefit of using interfaces is that Spring can use JDK Dynamic Proxies2 to create proxies and apply AOP.
![]() Note Spring can also apply AOP on class-based proxies; however, this requires the
Note Spring can also apply AOP on class-based proxies; however, this requires the cglib library (http://cglib.sourceforge.net) on the classpath.
The point is this: layering in an application leads to a more maintainable and testable application. A clear separation of concerns also leads to good application architecture.
Spring MVC Application Layers
You might wonder how all the layers fit into a Spring MVC application, as well as how all the different layers help us build our Spring MVC application. In this section, we will take a look at the five layers depicted in Figure 3-4. We will pay particular attention to the roles the different layers play and what should be in each.
The Domain Layer
The domain is the most important layer in an application. It is the code representation of the business problem we are solving, and it contains the business rules of our domain. These rules might check whether we have sufficient funds to transfer money from our account or ensure that fields are unique (e.g., usernames in our system).
A popular technique to determine the domain model is to use the nouns in use case descriptions as domain objects (e.g., Account or Transaction). These objects contain both state (e.g., the username for the Account) and behavior (e.g., a credit method on the Account). These methods are typically more fine-grained then the methods in the service layer. For example, in the money transfer sample in Chapter 2, the com.apress.prospringmvc.moneytransfer.domain.Account object has a debit and credit method. The credit method contains some business logic for checking whether we have sufficient money in our account to transfer the money.
____________
In Chapter 2, the implementations of the com.apress.prospringmvc.moneytransfer.service.MoneyTransferService used these supporting methods to implement a use case (in the sample, it transferred money from one account to another account). This is not to be confused with an anemic domain model3, in which our domain objects only hold state and have no behavior.
In general, your domain model will not need dependencies injected; however, it is still possible to do this. For example, it’s possible to use the Spring Framework and AspectJ to enable dependency injection in our domain objects. In that circumstance, we would give our domain classes the org.springframework.beans.factory.annotation.Configurable annotation. Next, we would need to set up load-time weaving or compile-time weaving, and we would have our dependencies injected. For more detailed information on the subject, please see the Spring Reference Guide4.
![]() Note This is the setup used in Spring ROO5. It uses a rich domain model, as advocated by Eric Evans6.
Note This is the setup used in Spring ROO5. It uses a rich domain model, as advocated by Eric Evans6.
The User Interface Layer
The user interface layer presents the application to the user. This layer renders the response generated by the server into the type requested by the user’s client. For instance, a web browser will probably request an HTML document, a web service may want an XML document, and another client could request a PDF or Excel document.
We separated the presentation layer into a user interface and web layer because, notwithstanding the wide range of different view technologies, we wanted to reuse as much code as possible. Our goal is to reimplement only the user interface. There are many different view technologies out there, including JSP(X), JSF, Velocity, and Freemarker, to name a few. In an ideal world, we would be able to switch our user interface without changing the backend of our application.
Spring MVC helps us in isolating the user interface from the rest of the system. In Spring, the view is represented by an interface: org.springframework.web.servlet.View. This interface is responsible for transforming the result of the action from the user (the model) into the type of response the user requested. The View interface is generic, and it has no dependencies on a particular view technology. For each supported view technology, there is an implementation provided either by the Spring Framework itself or by the view technologies themselves. Out of the box, Spring supports the following view technologies:
- JSP
- Excel
____________
The user interface in general has a dependency on the domain layer. Sometimes, it is convenient to directly expose and render the domain model. This can be especially useful when we start to use forms in our application. For example, this would let us work directly with the domain objects instead of an additional layer of indirection. Some argue that this creates an unnecessary or unwanted coupling between layers. However, the creation of another layer for the sole purpose of decoupling the domain from the view leads to unnecessary complexity and duplication. In any case, it is important to keep in mind that Spring MVC doesn’t requires us to directly expose the domain model to the view—whether we do so is entirely up to us.
The Web Layer
The web layer has two responsibilities. The first responsibility is to guide the user through the web application. The second is to be the integration layer between the service layer and HTTP.
Navigating the user through the website can be as simple as mapping a URL to views or a full-blown page flow solution like Spring Web Flow. The navigation is typically bound to the web layer only, and there isn’t any navigation logic in the domain or service layer.
As an integration layer, the web layer should be as thin as possible. It should be the layer that converts the incoming HTTP request to something that can be handled by the service layer, and then transforms the result (if any) from the server into a response for the user interface. The web layer should not contain any business logic—that is the sole purpose of the service layer.
The web layer also consists of cookies, HTTP headers, and possibly an HTTP session. It is the responsibility of the web layer to manage all these things consistently and transparently. The different HTTP elements should never creep into our service layer. If they do, the whole service layer (and thus our application) becomes tied to the web environment. Doing this makes it harder to maintain and test the application. Keeping the service layer clean also allows us to reuse the same services for different channels. For example, it enables us to add a web service or JMS-driven solution. The web layer should be thought of as a client or proxy that connects to the service layer and exposes it to the end users.
In the early days of Java web development, servlets or Java Server Pages mainly implemented this layer. The servlets had the responsibility of processing and transforming the request into something the service layer could understand. More often than not, the servlets wrote the desired HTML directly back to the client. This kind of implementation quickly became hard to maintain and test. After a couple of years, the Model 2 MVC pattern emerged, and we finally had advanced MVC capabilities for the Web.
Frameworks like Spring MVC, Struts, JSF, and Tapestry provide different implementations for this pattern, and they all work quite differently. However, we can identify two main types of web layer implementations: request/response frameworks (e.g., struts and Spring MVC) and component-based frameworks (e.g., JSF and Tapestry). The request/response frameworks operate on javax.servlet.ServletRequest and javax.servlet.ServletResponse objects. Thus, the fact that they operate on the Servlet API isn’t really hidden from the user. The component-based frameworks offer a completely different programming model. They try to hide the Servlet API from the programmer and offer a component-based programming model. Using a component-based framework feels a lot like working with a Swing desktop application.
Both approaches have their advantages and disadvantages. Spring MVC is quite powerful, and it strikes a good balance between the two. It can hide the fact that one works with the Servlet API; however, when needed, it is quite easy to access that API (among other things).
The web layer depends on the domain layer and service layer. In most cases, you want to transform the incoming request into a domain object and call a method on the service layer to do something with that domain object (e.g., update a customer or create an order). Spring MVC makes it easy to map incoming requests to objects, and we can use dependency injection to access the service layer.
In Spring MVC, the web layer is represented by the org.springframework.web.servlet.mvc.Controller interface or classes with the org.springframework.stereotype.Controller annotation. The interface-based approach is historic, and it has been part of the Spring Framework since its inception; however, it is now considered dated. Regardless, it remains useful for simple use cases, and Spring provides some convenient implementations out of the box. The new annotation-based approach is more powerful and flexible than the original interface-based approach. The main focus in this book is on the annotation-based approach.
After the execution of a controller, the infrastructure (see Chapter 4 for more information on this topic) expects that there is an instance of the org.springframework.web.servlet.ModelAndView class. This class incorporates the model (in the form of org.springframework.ui.ModelMap) and the view to render. This view can be an actual org.springframework.web.servlet.View implementation or the name of a view.
![]() Caution Don’t use the
Caution Don’t use the Controller annotation on a class with the Controller interface. These are handled differently, and mixing both strategies can lead to surprising and unwanted results!
The Service Layer
The service layer is a very important layer in the architecture of an application. It can be considered the heart of our application because it exposes the functionality (the use cases) of the system to the user. It does this by providing a coarse-grained API (as mentioned in Table 3-2). Listing 3-1 describes a coarse-grained service interface.
Listing 3-1. A coarse-grained service interface
package com.apress.prospringmvc.bookstore.service;
import com.apress.prospringmvc.bookstore.domain.Account;
public interface AccountService {
Account save(Account account);
Account login(String username, String password) throws AuthenticationException;
Account getAccount(String username);}
This listing is considered coarse grained because it takes a simple method call from the client to complete a single use case. This is in contrast to the code in Listing 3-2 (fine-grained service methods), which requires a couple of calls to perform a use case.
Listing 3-2. A fine-grained service interface
package com.apress.prospringmvc.bookstore.service;
import com.apress.prospringmvc.bookstore.domain.Account;
public interface AccountService {
Account save(Account account);
Account getAccount(String username);
void checkPassword(Account account, String password);
void updateLastLogin(Account account);
}
If at all possible, we should not call a sequence of methods to execute a system function. In fact, we should shield the user from data access and POJO interaction as much as possible. In an ideal world, a coarse-grained function should represent a single unit of work that either succeeds or fails. The user can use different clients (e.g., web application, web service, or desktop application); however, these clients should execute the same business logic. Hence, the service layer should be our single point of entry for the actual system (i.e., the business logic).
The added benefit of having a single point of entry and coarse-grained methods on the service layer is that we can simply apply transactions and security at this layer. We don’t have to burden the different clients of our application with the security and transactional requirements. It is now part of the core of the system and generally applied through the use of AOP.
In a web-based environment, we probably have multiple users operating on the services at the same time. The service must be stateless, so it is a good practice to make the service a singleton. In the domain model, state should be kept as much as possible. Keeping the service layer stateless provides an additional benefit: it also makes the layer thread safe.
Keeping the service layer to a single point of entry, keeping the layer stateless, and applying transactions and security on that layer enable us to use other features of the Spring Framework to expose the service layer to different clients. For example, we could use configuration to easily expose our service layer over RMI or JMS. For more information on the remoting support of the Spring Framework, we suggest Pro Spring 3 (Apress, 2012) or the online Spring Reference Guide (www.springsource.org/documentation).
In our bookstore sample application, the com.apress.prospringmvc.bookstore.service.BookstoreService interface (see Listing 3-3) serves as the interface for our service layer (there are a couple of other interfaces, but this is the most important one). This interface contains several coarse-grained methods. In most cases, it takes a single method call to execute a single use case (e.g., createOrder).
Listing 3-3. The BookstoreService interface
package com.apress.prospringmvc.bookstore.service;
import java.util.List;
import com.apress.prospringmvc.bookstore.domain.Account;
import com.apress.prospringmvc.bookstore.domain.Book;
import com.apress.prospringmvc.bookstore.domain.BookSearchCriteria;
import com.apress.prospringmvc.bookstore.domain.Cart;
import com.apress.prospringmvc.bookstore.domain.Category;
import com.apress.prospringmvc.bookstore.domain.Order;
public interface BookstoreService {
List<Book> findBooksByCategory(Category category);
Book findBook(long id);
Order findOrder(long id);
List<Book> findRandomBooks();
List<Order> findOrdersForAccount(Account account);
Order store(Order order);
List<Book> findBooks(BookSearchCriteria bookSearchCriteria);
Order createOrder(Cart cart, Account account);
List<Category> findAllCategories();
}
As Listing 3-3 demonstrates, the service layer depends on the domain layer to execute the business logic. However, it also has a dependency on the data access layer to store and retrieve data from our underlying data store. The service layer can serve as the glue between one or more domain objects to execute a business function. The service layer should coordinate which domain objects it needs and how they interact together.
The Spring Framework has no interfaces that help us implement our service layer; however, this shouldn’t come as a surprise. The service layer is what makes our application; in fact, it is specialized for our application. Nevertheless, the Spring Framework can help us with our architecture and programming model. We can use dependency injection and apply aspects to drive our transactions. All of this has a positive influence on our programming model.
The Data Access Layer
The data access layer is responsible for interfacing with the underlying persistence mechanism. This layer knows how to store and retrieve objects from the datastore. It does this in such a way that the service layer doesn’t know which underlying datastore is used. (The datastore could be a database, but it could also consist of flat files on the file system.)
There are several reasons for creating a separate data access layer. First, we don’t want to burden the service layer with knowledge of the kind of datastore (or datastores) we use; we want to handle persistency in a transparent way. In our sample application, we use an in-memory database and JPA (Java Persistence API) to store our data. Now imagine that, instead of coming from the database, our com.apress.prospringmvc.bookstore.domain.Account comes from an Active Directory Service. We could simply create a new implementation of the interface that knows how to deal with Active Directory—all without changing our service layer. In theory, we could swap out implementations quite easily; for example, we could switch from JDBC to Hibernate without having to change the service layer. It is quite unlikely that this will happen, but it is nice to have this ability.
The most important reason for this approach is that it simplifies testing our application. In general, data access is slow, so it is important that we keep our tests running as fast as possible. A separate data access layer makes it quite easy to create a stub or mock implementation of our data access layer.
The Spring Framework has great support for data access layers. For example, it provides a consistent and transparent way to work with a variety of different data access frameworks (e.g., JDBC, JPA, Hibernate, iBATIS, and JDO). Each of these technologies Spring provides extensive support for the following abilities:
- Transaction Management
- Resource Handling
- Exception Translation
The transaction management is transparent for each technology it supports. There is a transaction manager that handles the transactions, and it even has support for JTA (Java Transaction API), which enables distributed or global transactions. This excellent transaction support means that the transaction manager can also manage the resources for us. We no longer have to worry that a database connection or file handle might be closed; this is all handled for us. The supported implementations can be found in the org.springframework.jdbc and org.springframework.orm packages.
![]() Tip The Spring Data project (
Tip The Spring Data project (www.springsource.org/spring-data) provides even deeper integration with several technologies. For several use cases, it can even eliminate the need to write our own implementation of a data access object (DAO) or repository.
The Spring Framework includes another powerful feature as part of its data access support: exception translation. Spring provides extensive exception translation support for all its supported technologies. This feature transforms technology-specific exceptions into a subclass of org.springframework.dao.DataAccessException. For database-driven technologies, it can even take into account the database vendor, version, and error codes received from the database. The exception hierarchy extends from RuntimeException; and as such, it doesn’t have to be caught because it isn’t a checked exception. For more information on data access support, please see Pro Spring 3 (Apress, 2012) or the online Spring Reference Guide (www.springsource.org/documentation).
Listing 3-4 shows how a data access object or repository might look. Note that the interface doesn’t reference or mention any data access technology we use (we use JPA for the sample application). Also, the service layer doesn’t care how or where the data is persisted; it simply wants to know how to store or retrieve it.
Listing 3-4. A sample AccountRepository
package com.apress.prospringmvc.bookstore.repository;
import com.apress.prospringmvc.bookstore.domain.Account;
public interface AccountRepository {
Account findByUsername(String username);
Account findById(long id);
Account save(Account account);
}
More Roads to Rome
As noted previously, the architecture discussed here isn’t the only application architecture out there. Which architecture is best for a given application depends on the size of the application, the experience of the development team, and the lifetime of the application. The larger a team or the longer an application lives, the more important a clean architecture with separate layers becomes.
A web application that starts with a single static page probably doesn’t require any architecture. However, as the application grows, it becomes increasingly important that we don’t try to put everything in that single page because that would make it very difficult to maintain or understand the app, let alone test it.
As an application grows in size and age, we need to refactor its design and keep in mind that each layer or component should have a single responsibility. If we detect some concern that should be in a different layer or touches multiple components, then we should convert it into an aspect (crosscutting concern) of the application and use AOP to apply this aspect to the code.
When deciding how to structure our layers, we should try to identify a clear API (exposed through Java interfaces) for our system. Thinking of an API for our system makes us think about our design, as well as a useful and useable API. In general, if an API is hard to use, it is also hard to test and maintain. Therefore, a clean API is important. In addition, using interfaces between the different layers allows for the separate layers to be built and tested in isolation. This can be a great advantage in larger development teams (or in teams that consists of multiple smaller teams). It allows us to focus on the function we’re working with, not on the underlying or higher level components.
When designing and building an application, it’s also important to use good OO practices and patterns to solve problems. For example, we should use polymorphism and inheritance to our advantage, and we should use AOP to apply system-wide concerns. The Spring Framework can also help us wire our application together at runtime. Taken as a whole, the features and approaches described in this chapter can help us to keep our code clean and to achieve the best architecture for our applications.
Summary
In this chapter, we covered the MVC pattern, including its origins and what problems it solves. We also briefly discussed the three components of the MVC pattern: the model, view, and controller. Next, we touched on the Model 2 MVC pattern and how using a front controller distinguishes it from the Model 1 MVC pattern. In Spring MVC, this front controller is org.springframework.web.servlet.DispatcherServlet.
Next, we briefly covered web application architecture in general. We identified the five different layers generally available in a web application: domain, user interface, web, service, and data access. All of these layers play an important role in our application, and we discussed both what these roles are and how they fit together. We also covered how Spring can help us out in the different layers of an application.
The main take away from this chapter is that the various layers and components in the MVC pattern can help us separate the different concerns. Each layer should have a single responsibility, be it business logic or the glue between the HTTP world and the service layer. Separation of concerns helps us both achieve a clean architecture and create maintainable code. Finally, clean layering makes it easier to test our application.
In the next chapter, we will drill down on the Spring MVC. Specifically, we will explore the DispatcherServlet servlet, including how it works and how to configure it. We will also take a closer look at how the different components described in this chapter work in a Spring MVC application.