
The high availability of any application is critical because of the global model of organizations. Also, with high throughput, multiple servers are required to support an application. This is where the clustering of nodes comes into the picture.
The typical requirements of high availability architectures are the following:
- Business continuity (up and running 24/7)
- Avoiding the single point of failure
- Hot backup
- Disaster recovery
In this chapter, we will discuss the ways of clustering in Alfresco and the backup restore process that supports the high availability of Alfresco.
By the end of this chapter, you will have learned about:
- Clustering Alfresco servers
- The backup process of Alfresco
- The restore process of Alfresco
Clustering refers to collections of multiple nodes combined together in a server as a single application to end users. With clustering, you can achieve scalability, server redundancy, and performance improvement of the application.
Let's consider a global financial organization that has multiple teams working for it across the globe. Alfresco is used as an enterprise content repository to store all the financial assets, like contracts. Now, these assets are very time-critical, and therefore the contracts should be accessible to all teams working on it at any time. There are thousands of users using the application, which also requires high server performance. High throughput is required for the server for users accessing assets in the system.
To satisfy these requirements, you will need to build a robust and highly available system by creating a clustered environment of Alfresco so the load on the server can be distributed. You also need a redundant and scalable environment so if one server goes down, you have another server up and running. This allows users to access the contracts from the application at any time. Moreover, you would have minimal downtime for the application.
There are various ways in which you can divide the servers in multiple tiers as per your requirements.
This approach is a straightforward approach where you create a replica of a complete stack and enable the clustering in Alfresco. The database and content store are being shared between all the nodes. Using a load balancer in front of this stack allows requests to be divided among servers. You can use any load balancer like Apache, Nginx, etc.
With this approach, if one node goes down, the other node is capable enough to serve the request independently.

As the database and content store are shared among the servers, they are single points of failure. In addition to this, we have to manage the indexes in two Solr instances. For this, we would need a proper backup for the database and content store. More details on backup and restore will be covered later on in this chapter.
Each component of Alfresco can be divided into multiple tiers like Share, Repository, Database, and Solr. Use a load balancer to communicate between each tier. Share can either talk to the Alfresco Repository using the load balancer or an individual server. You can also have a common Solr server shared among all the nodes. Refer to the clustering diagram below for a visualization.
The database and content store are shared among the servers. This approach would be useful when you have to divide the load on the web-tier and increase the throughput of the application. In addition, indexes are available on the common Solr server, so there is no need to manage multiple instances. The Solr server can also be clustered together, which allows for easy scalability of the server.
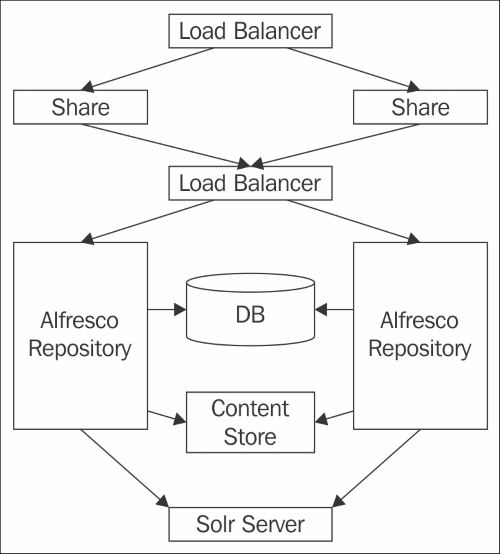
Now we will understand the process required to cluster Alfresco nodes. As Share and Repository are different components, both require different configuration to bring them into the cluster.
First, identify what kind of clustering approach is required. Set up each node and make sure that each node as a single entity is working properly, such as being able to connect to the database and content store. Now follow the steps below to set up clustering between Alfresco nodes.
- With Alfresco v 5.0, Hazelcast is used for clustering the web-tier nodes. Hazelcast sends multicast messaging between share node instances. Enable Hazelcast for Share.
- Configure the
custom-slingshot-application-context.xmlfile located at<Tomcat_home>/shared/classes/alfresco/web-extension. The sample file is already located in this location. - Rename the
.samplefile to a .xmlfile and uncomment the related Hazelcast configuration. Refer to the sample code with the book. - Configure the interface IP address based on your network.
- Make sure that your Share instance communicates with Alfresco, which can either be via a load balancer or by hard-wiring the Alfresco instance in the Share configuration. If a load balancer is used then it should maintain a sticky session with the Alfresco instance.
- Install and deploy Alfresco on multiple servers depending on the number of nodes you need.
- Configure
alfresco-global.propertieslocated at<Tomcat_home>/shared/classes/on all nodes to point to the same database. Refer to Chapter 3, Alfresco Configuration, for configuring databases. - Make sure
dir.rootin thealfresco-global.propertiesfile is pointing to same content store on all nodes. Mount the content store file system on all the nodes with the proper permission rights. - Set up the Solr instance and configure all Alfresco nodes to point to the common Solr instance.
- Verify each node by starting them so that all configurations are correct, including Database, Solr, and Content Store. Once verified, stop the servers.
- Now configure the clustering related properties below in the
alfresco-global.propertiesfile and restart all Alfresco nodes. Also make sure that the default clustering port5701is open on all nodes:alfresco.cluster.enabled=trueSet this value to
trueto enable clustering, if you set it tofalse, this node would not be part of clustering.alfresco.cluster.interface=10.208.*.*This is the network interface to be used for clustering. You can define a wildcard value, so the system will try to bind with all interfaces having this IP address.
alfresco.cluster.nodeType= Scheduler ServerEnter a human readable node name which helps to distinguish the servers. It is mostly useful for nodes which are not part of cluster, but which share the same database and content store.
alfresco.hazelcast.password= clusterpasswdDefine the password used by clustered nodes to join or access the
hazelcastcluster. From a security standpoint, always configure this property.alfresco.hazelcast.max.no.heartbeat.seconds=15Configure the maximum node heartbeat timeout in seconds to assume it is dead.
- Verifying clustering with Alfresco v5.0 is very easy. Log in to the Alfresco Standalone Administration Page at
http://<server_name>:<port>/alfresco/service/enterprise/admin. - Navigate to the Repository Server section and Click Repository Server Clustering. This page will provide you with the list of all cluster members. Click Validate Cluster to validate that all configurations are correct.
Another way to manually verify clustering is by uploading and searching content or a folder in the repository. Considering we have two Alfresco servers, NODE1 and NODE2, in the clustered environment:
- Log in to
NODE1and upload some content. - Now log into
NODE2and verify you are able to see the content. - Search for uploaded content in
NODE2and verify you are able to search it. - Edit some metadata of the content or folder and verify that it has been updated on the other node.
Enable debug logs for the class files listed below to troubleshoot in more detail. Make an entry in the log4j.properties file located at <Tomcat_home>/webapps/alfresco/WEB-INF/classes and restart the server:
log4j.logger.org.alfresco.enterprise.repo.cluster=infoThis is the main package for clustering related classes.
log4j.logger.org.alfresco.enterprise.repo.cluster.core.ClusteringBootstrap=DEBUGThis provides detail about cluster startup, shutdown, whether it is disabled or if the license is invalid.
log4j.logger.org.alfresco.enterprise.repo.cluster.core.MembershipChangeLogger=DEBUGThis provides details about the cluster members.
log4j.logger.org.alfresco.enterprise.repo.cluster.cache=DEBUGlog4j.logger.org.alfresco.repo.cache=DEBUGlog4j.logger.com.hazelcast=infoEnable this if logging is required for core
hazelcastpackages.
The Hazelcast mancenter is a standalone application which allows you to monitor and manage all the servers using Hazelcast. This dashboard enables you to browse through the cluster data structure and provides you with details about the cluster. You can use this dashboard to get more details about the cluster node.
To set up this Hazelcast mancenter, follow these steps:
- Install the Tomcat application server.
- Download the Hazelcast mancenter WAR file and deploy in Tomcat.
- Set up the data directory by adding the property below to the
CATALINA_OPTSenvironment variable:-hazelcast.mancenter.home=/home/<tomcat_directory>/mancenter_data - Configure the Alfresco server to use this mancenter by adding the properties below in the
alfresco-global.propertiesfile. Make sure that from the Alfresco server, this mancenter service is accessible:alfresco.hazelcast.mancenter.enabled=true alfresco.hazelcast.mancenter.url=http://<tomcat-erveraddress>:<port>/mancenter
Note
To get more details about the Hazelcast mancenter, refer to http://hazelcast.com/products/management-center/.