
Now, we presume that you are aware of R, what it is, how to install it, what it's key features are, and why you may want to use it. Now we need to know the limitations of R (this is a better introduction to Hadoop). Before processing the data; R needs to load the data into random access memory (RAM). So, the data needs to be smaller than the available machine memory. For data that is larger than the machine memory, we consider it as Big Data (only in our case as there are many other definitions of Big Data).
To avoid this Big Data issue, we need to scale the hardware configuration; however, this is a temporary solution. To get this solved, we need to get a Hadoop cluster that is able to store it and perform parallel computation across a large computer cluster. Hadoop is the most popular solution. Hadoop is an open source Java framework, which is the top level project handled by the Apache software foundation. Hadoop is inspired by the Google filesystem and MapReduce, mainly designed for operating on Big Data by distributed processing.
Hadoop mainly supports Linux operating systems. To run this on Windows, we need to use VMware to host Ubuntu within the Windows OS. There are many ways to use and install Hadoop, but here we will consider the way that supports R best. Before we combine R and Hadoop, let us understand what Hadoop is.
Tip
Machine learning contains all the data modeling techniques that can be explored with the web link http://en.wikipedia.org/wiki/Machine_learning.
The structure blog on Hadoop installation by Michael Noll can be found at http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/.
Hadoop is used with three different modes:
- The standalone mode: In this mode, you do not need to start any Hadoop daemons. Instead, just call
~/Hadoop-directory/bin/hadoopthat will execute a Hadoop operation as a single Java process. This is recommended for testing purposes. This is the default mode and you don't need to configure anything else. All daemons, such as NameNode, DataNode, JobTracker, and TaskTracker run in a single Java process. - The pseudo mode: In this mode, you configure Hadoop for all the nodes. A separate Java Virtual Machine (JVM) is spawned for each of the Hadoop components or daemons like mini cluster on a single host.
- The full distributed mode: In this mode, Hadoop is distributed across multiple machines. Dedicated hosts are configured for Hadoop components. Therefore, separate JVM processes are present for all daemons.
Hadoop can be installed in several ways; we will consider the way that is better to integrate with R. We will choose Ubuntu OS as it is easy to install and access it.
- Installing Hadoop on Linux, Ubuntu flavor (single and multinode cluster).
- Installing Cloudera Hadoop on Ubuntu.
To install Hadoop over Ubuntu OS with the pseudo mode, we need to meet the following prerequisites:
- Sun Java 6
- Dedicated Hadoop system user
- Configuring SSH
- Disabling IPv6
Follow the given steps to install Hadoop:
- Download the latest Hadoop sources from the Apache software foundation. Here we have considered Apache Hadoop 1.0.3, whereas the latest version is 1.1.x.
// Locate to Hadoop installation directory $ cd /usr/local // Extract the tar file of Hadoop distribution $ sudo tar xzf hadoop-1.0.3.tar.gz // To move Hadoop resources to hadoop folder $ sudo mv hadoop-1.0.3 hadoop // Make user-hduser from group-hadoop as owner of hadoop directory $ sudo chown -R hduser:hadoop hadoop
- Add the
$JAVA_HOMEand$HADOOP_HOMEvariables to the.bashrcfile of Hadoop system user and the updated.bashrcfile looks as follows:// Setting the environment variables for running Java and Hadoop commands export HADOOP_HOME=/usr/local/hadoop export JAVA_HOME=/usr/lib/jvm/java-6-sun // alias for Hadoop commands unalias fs &> /dev/null alias fs="hadoop fs" unalias hls &> /dev/null aliashls="fs -ls" // Defining the function for compressing the MapReduce job output by lzop command lzohead () { hadoopfs -cat $1 | lzop -dc | head -1000 | less } // Adding Hadoop_HoME variable to PATH export PATH=$PATH:$HADOOP_HOME/bin
- Update the Hadoop configuration files with the
conf/*-site.xmlformat.
Finally, the three files will look as follows:
conf/core-site.xml:<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> <description>The name of the default filesystem. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming theFileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property>
conf/mapred-site.xml:<property> <name>mapred.job.tracker</name> <value>localhost:54311</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property>
conf/hdfs-site.xml:<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description>
After completing the editing of these configuration files, we need to set up the distributed filesystem across the Hadoop clusters or node.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
We learned how to install Hadoop on a single node cluster. Now we will see how to install Hadoop on a multinode cluster (the full distributed mode).
For this, we need several nodes configured with a single node Hadoop cluster. To install Hadoop on multinodes, we need to have that machine configured with a single node Hadoop cluster as described in the last section.
After getting the single node Hadoop cluster installed, we need to perform the following steps:
- In the networking phase, we are going to use two nodes for setting up a full distributed Hadoop mode. To communicate with each other, the nodes need to be in the same network in terms of software and hardware configuration.
- Among these two, one of the nodes will be considered as master and the other will be considered as slave. So, for performing Hadoop operations, master needs to be connected to slave. We will enter
192.168.0.1in the master machine and192.168.0.2in the slave machine. - Update the
/etc/hostsdirectory in both the nodes. It will look as192.168.0.1 masterand192.168.0.2 slave.Tip
You can perform the Secure Shell (SSH) setup similar to what we did for a single node cluster setup. For more details, visit http://www.michael-noll.com.
- Updating
conf/*-site.xml: We must change all these configuration files in all of the nodes.conf/core-site.xmlandconf/mapred-site.xml: In the single node setup, we have updated these files. So, now we need to just replacelocalhostbymasterin the value tag.conf/hdfs-site.xml: In the single node setup, we have set the value ofdfs.replicationas1. Now we need to update this as2.
- In the formatting HDFS phase, before we start the multinode cluster, we need to format HDFS with the following command (from the master node):
bin/hadoop namenode -format
Now, we have completed all the steps to install the multinode Hadoop cluster. To start the Hadoop clusters, we need to follow these steps:
- Start HDFS daemons:
hduser@master:/usr/local/hadoop$ bin/start-dfs.sh - Start MapReduce daemons:
hduser@master:/usr/local/hadoop$ bin/start-mapred.sh - Alternatively, we can start all the daemons with a single command:
hduser@master:/usr/local/hadoop$ bin/start-all.sh - To stop all these daemons, fire:
hduser@master:/usr/local/hadoop$ bin/stop-all.sh
These installation steps are reproduced after being inspired by the blogs (http://www.michael-noll.com) of Michael Noll, who is a researcher and Software Engineer based in Switzerland, Europe. He works as a Technical lead for a large scale computing infrastructure on the Apache Hadoop stack at VeriSign.
Now the Hadoop cluster has been set up on your machines. For the installation of the same Hadoop cluster on single node or multinode with extended Hadoop components, try the Cloudera tool.
Cloudera Hadoop (CDH) is Cloudera's open source distribution that targets enterprise class deployments of Hadoop technology. Cloudera is also a sponsor of the Apache software foundation. CDH is available in two versions: CDH3 and CDH4. To install one of these, you must have Ubuntu with either 10.04 LTS or 12.04 LTS (also, you can try CentOS, Debian, and Red Hat systems). Cloudera manager will make this installation easier for you if you are installing a Hadoop on cluster of computers, which provides GUI-based Hadoop and its component installation over a whole cluster. This tool is very much recommended for large clusters.
We need to meet the following prerequisites:
- Configuring SSH
- OS with the following criteria:
- Ubuntu 10.04 LTS or 12.04 LTS with 64 bit
- Red Hat Enterprise Linux 5 or 6
- CentOS 5 or 6
- Oracle Enterprise Linux 5
- SUSE Linux Enterprise server 11 (SP1 or lasso)
- Debian 6.0
The installation steps are as follows:
- Download and run the Cloudera manager installer: To initialize the Cloudera manager installation process, we need to first download the
cloudera-manager-installer.binfile from the download section of the Cloudera website. After that, store it at the cluster so that all the nodes can access this. Allow ownership for execution permission ofcloudera-manager-installer.binto the user. Run the following command to start execution.$ sudo ./cloudera-manager-installer.bin - Read the Cloudera manager Readme and then click on Next.
- Start the Cloudera manager admin console: The Cloudera manager admin console allows you to use Cloudera manager to install, manage, and monitor Hadoop on your cluster. After accepting the license from the Cloudera service provider, you need to traverse to your local web browser by entering
http://localhost:7180in your address bar. You can also use any of the following browsers:- Firefox 11 or higher
- Google Chrome
- Internet Explorer
- Safari
- Log in to the Cloudera manager console with the default credentials using
adminfor both the username and password. Later on you can change it as per your choice. - Use the Cloudera manager for automated CDH3 installation and configuration via browser: This step will install most of the required Cloudera Hadoop packages from Cloudera to your machines. The steps are as follows:
- Install and validate your Cloudera manager license key file if you have chosen a full version of software.
- Specify the hostname or IP address range for your CDH cluster installation.
- Connect to each host with SSH.
- Install the Java Development Kit (JDK) (if not already installed), the Cloudera manager agent, and CDH3 or CDH4 on each cluster host.
- Configure Hadoop on each node and start the Hadoop services.
- After running the wizard and using the Cloudera manager, you should change the default administrator password as soon as possible. To change the administrator password, follow these steps:
- Click on the icon with the gear sign to display the administration page.
- Open the Password tab.
- Enter a new password twice and then click on Update.
- Test the Cloudera Hadoop installation: You can check the Cloudera manager installation on your cluster by logging into the Cloudera manager admin console and by clicking on the Services tab. You should see something like the following screenshot:
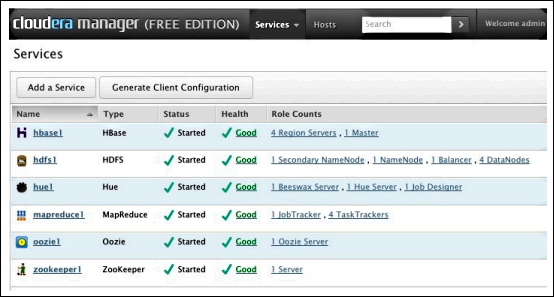
Cloudera manager admin console
- You can also click on each service to see more detailed information. For example, if you click on the hdfs1 link, you might see something like the following screenshot:

Cloudera manger admin console—HDFS service
Tip
To avoid these installation steps, use preconfigured Hadoop instances with Amazon Elastic MapReduce and MapReduce.
If you want to use Hadoop on Windows, try the HDP tool by Hortonworks. This is 100 percent open source, enterprise grade distribution of Hadoop. You can download the HDP tool at http://hortonworks.com/download/.