
Recommendation is a machine-learning technique to predict what new items a user would like based on associations with the user's previous items. Recommendations are widely used in the field of e-commerce applications. Through this flexible data and behavior-driven algorithms, businesses can increase conversions by helping to ensure that relevant choices are automatically suggested to the right customers at the right time with cross-selling or up-selling.
For example, when a customer is looking for a Samsung Galaxy S IV/S4 mobile phone on Amazon, the store will also suggest other mobile phones similar to this one, presented in the Customers Who Bought This Item Also Bought window.
There are two different types of recommendations:
- User-based recommendations: In this type, users (customers) similar to current user (customer) are determined. Based on this user similarity, their interested/used items can be recommended to other users. Let's learn it through an example.

Assume there are two users named Wendell and James; both have a similar interest because both are using an iPhone. Wendell had used two items, iPad and iPhone, so James will be recommended to use iPad. This is user-based recommendation.
- Item-based recommendations: In this type, items similar to the items that are being currently used by a user are determined. Based on the item-similarity score, the similar items will be presented to the users for cross-selling and up-selling type of recommendations. Let's learn it through an example.
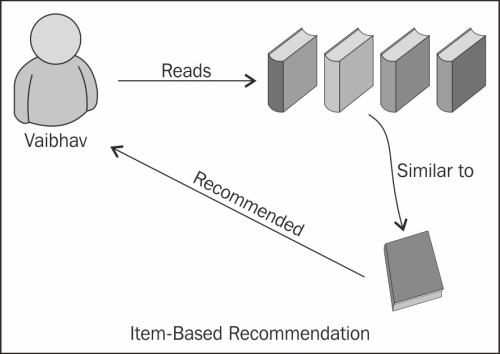
For example, a user named Vaibhav likes and uses the following books:
- Apache Mahout Cookbook, Piero Giacomelli, Packt Publishing
- Hadoop MapReduce Cookbook, Thilina Gunarathne and Srinath Perera, Packt Publishing
- Hadoop Real-World Solutions Cookbook, Brian Femiano, Jon Lentz, and Jonathan R. Owens, Packt Publishing
- Big Data For Dummies, Dr. Fern Halper, Judith Hurwitz, Marcia Kaufman, and Alan Nugent, John Wiley & Sons Publishers
Based on the preceding information, the recommender system will predict which new books Vaibhav would like to read, as follows:
- Big Data Analytics with R and Hadoop, Vignesh Prajapati, Packt Publishing
Now we will see how to generate recommendations with R and Hadoop. But before going towards the R and Hadoop combination, let us first see how to generate it with R. This will clear the concepts to translate your generated recommender systems to MapReduce recommendation algorithms. In case of generating recommendations with R and Hadoop, we will use the RHadoop distribution of Revolution Analytics.
To generate recommendations for users, we need to have datasets in a special format that can be read by the algorithm. Here, we will use the collaborative filtering algorithm for generating the recommendations rather than content-based algorithms. Hence, we will need the user's rating information for the available item sets. So, the small.csv dataset is given in the format user ID, item ID, item's ratings.
# user ID, item ID, item's rating 1, 101, 5.0 1, 102, 3.0 1, 103, 2.5 2, 101, 2.0 2, 102, 2.5 2, 103, 5.0 2, 104, 2.0 3, 101, 2.0 3, 104, 4.0 3, 105, 4.5 3, 107, 5.0 4, 101, 5.0 4, 103, 3.0 4, 104, 4.5 4, 106, 4.0 5, 101, 4.0 5, 102, 3.0 5, 103, 2.0 5, 104, 4.0 5, 105, 3.5 5, 106, 4.0
The preceding code and datasets are reproduced from the book Mahout in Action, Robin Anil, Ellen Friedman, Ted Dunning, and Sean Owen, Manning Publications and the website is http://www.fens.me/.
Recommendations can be derived from the matrix-factorization technique as follows:
Co-occurrence matrix * scoring matrix = Recommended Results
To generate the recommenders, we will follow the given steps:
- Computing the co-occurrence matrix.
- Establishing the user-scoring matrix.
- Generating recommendations.
From the next section, we will see technical details for performing the preceding steps.
- In the first section, computing the co-occurrence matrix, we will be able to identify the co-occurred item sets given in the dataset. In simple words, we can call it counting the pair of items from the given dataset.
# Quote plyr package library (plyr) # Read dataset train <-read.csv (file = "small.csv", header = FALSE) names (train) <-c ("user", "item", "pref") # Calculated User Lists usersUnique <-function () { users <-unique (train $ user) users [order (users)] } # Calculation Method Product List itemsUnique <-function () { items <-unique (train $ item) items [order (items)] } # Derive unique User Lists users <-usersUnique () # Product List items <-itemsUnique () # Establish Product List Index index <-function (x) which (items %in% x) data<-ddply(train,.(user,item,pref),summarize,idx=index(item)) # Co-occurrence matrix Co-occurrence <-function (data) { n <-length (items) co <-matrix (rep (0, n * n), nrow = n) for (u in users) { idx <-index (data $ item [which(data$user == u)]) m <-merge (idx, idx) for (i in 1: nrow (m)) { co [m$x[i], m$y[i]] = co[m$x[i], m$y[i]]+1 } } return (co) } # Generate co-occurrence matrix co <-co-occurrence (data) - To establish the user-scoring matrix based on the user's rating information, the user-item rating matrix can be generated for users.
# Recommendation algorithm recommend <-function (udata = udata, co = coMatrix, num = 0) { n <- length(items) # All of pref pref <- rep (0, n) pref[udata$idx] <-udata$pref # User Rating Matrix userx <- matrix(pref, nrow = n) # Scoring matrix co-occurrence matrix * r <- co %*% userx # Recommended Sort r[udata$idx] <-0 idx <-order(r, decreasing = TRUE) topn <-data.frame (user = rep(udata$user[1], length(idx)), item = items[idx], val = r[idx]) # Recommended results take months before the num if (num> 0) { topn <-head (topn, num) } # Recommended results take months before the num if (num> 0) { topn <-head (topn, num) } # Back to results return (topn) } - Finally, the recommendations as output can be generated by the product operations of both matrix items: co-occurrence matrix and user's scoring matrix.
# initializing dataframe for recommendations storage recommendation<-data.frame() # Generating recommendations for all of the users for(i in 1:length(users)){ udata<-data[which(data$user==users[i]),] recommendation<-rbind(recommendation,recommend(udata,co,0)) }
Tip
Generating recommendations via Myrrix and R interface is quite easy. For more information, refer to https://github.com/jwijffels/Myrrix-R-interface.
To generate recommendations with R and Hadoop, we need to develop an algorithm that will be able to run and perform data processing in a parallel manner. This can be implemented using Mappers and Reducers. A very interesting part of this section is how we can use R and Hadoop together to generate recommendations from big datasets.
So, here are the steps that are similar to generating recommendations with R, but translating them to the Mapper and Reducer paradigms is a little tricky:
- Establishing the co-occurrence matrix items.
- Establishing the user scoring matrix to articles.
- Generating recommendations.
We will use the same concepts as our previous operation with R to generate recommendations with R and Hadoop. But in this case, we need to use a key-value paradigm as it's the base of parallel operations. Therefore, every function will be implemented by considering the key-value paradigm.
- In the first section, establishment of the co-occurrence matrix items, we will establish co-occurrence items in steps: grouped by user, locate each user-selected items appearing alone counting, and counting in pairs.
# Load rmr2 package library (rmr2) # Input Data File train <-read.csv (file = "small.csv", header = FALSE) names (train) <-c ("user", "item", "pref") # Use the hadoop rmr format, hadoop is the default setting. rmr.options (backend = 'hadoop') # The data set into HDFS train.hdfs = to.dfs (keyval (train$user, train)) # see the data from hdfs from.dfs (train.hdfs)The key points to note are:
train.mr: This is the MapReduce job's key-value paradigm information- key: This is the list of items vector
- value: This is the item combination vector
# MapReduce job 1 for co-occurrence matrix items train.mr <-mapreduce ( train.hdfs, map = function (k, v) { keyval (k, v$item) } # for identification of co-occurrence items , Reduce = function (k, v) { m <-merge (v, v) keyval (m$x, m$y) } )The co-occurrence matrix items will be combined to count them.
To define a MapReduce job,
step2.mris used for calculating the frequency of the combinations of items.Step2.mr: This is the MapReduce job's key value paradigm information- key: This is the list of items vector
- value: This is the co-occurrence matrix dataframe value (
item,item,Freq)
# MapReduce function for calculating the frequency of the combinations of the items. step2.mr <-mapreduce ( train.mr, map = function (k, v) { d <-data.frame (k, v) d2 <-ddply (d,. (k, v), count) key <- d2$k val <- d2 keyval(key, val) } ) # loading data from HDFS from.dfs(step2.mr) - To establish the user-scoring matrix to articles, let us define the
Train2.mrMapReduce job.# MapReduce job for establish user scoring matrix to articles train2.mr <-mapreduce ( train.hdfs, map = function(k, v) { df <- v # key as item key <-df $ item # value as [item, user pref] val <-data.frame (item = df$item, user = df$user, pref = df$pref) # emitting (key, value)pairs keyval(key, val) } ) # loading data from HDFS from.dfs(train2.mr)Train2.mr: This is the MapReduce job's key value paradigm information- key: This is the list of items
- value: This is the value of the user goods scoring matrix
The following is the consolidation and co-occurrence scoring matrix:
# Running equi joining two data – step2.mr and train2.mr eq.hdfs <-equijoin ( left.input = step2.mr, right.input = train2.mr, map.left = function (k, v) { keyval (k, v) }, map.right = function (k, v) { keyval (k, v) }, outer = c ("left") ) # loading data from HDFS from.dfs (eq.hdfs)eq.hdfs: This is the MapReduce job's key value paradigm information- key: The key here is null
- value: This is the merged dataframe value
- In the section of generating recommendations, we will obtain the recommended list of results.
# MapReduce job to obtain recommended list of result from equijoined data cal.mr <-mapreduce ( input = eq.hdfs, map = function (k, v) { val <-v na <-is.na (v$user.r) if (length (which(na))> 0) val <-v [-which (is.na (v $ user.r)),] keyval (val$kl, val) } , Reduce = function (k, v) { val <-ddply (v,. (kl, vl, user.r), summarize, v = freq.l * pref.r) keyval (val $ kl, val) } ) # loading data from HDFS from.dfs (cal.mr)Cal.mr: This is the MapReduce job's key value paradigm information- key: This is the list of items
- value: This is the recommended result dataframe value
By defining the result for getting the list of recommended items with preference value, the sorting process will be applied on the recommendation result.
# MapReduce job for sorting the recommendation output result.mr <-mapreduce ( input = cal.mr, map = function (k, v) { keyval (v $ user.r, v) } , Reduce = function (k, v) { val <-ddply (v,. (user.r, vl), summarize, v = sum (v)) val2 <-val [order (val$v, decreasing = TRUE),] names (val2) <-c ("user", "item", "pref") keyval (val2$user, val2) } ) # loading data from HDFS from.dfs (result.mr)result.mr: This is the MapReduce job's key value paradigm information- key: This is the user ID
- value: This is the recommended outcome dataframe value
Here, we have designed the collaborative algorithms for generating item-based recommendation. Since we have tried to make it run on parallel nodes, we have focused on the Mapper and Reducer. They may not be optimal in some cases, but you can make them optimal by using the available code.