
In the previous chapter, we learned how to integrate R and Hadoop with the help of RHIPE and RHadoop and also sample examples. In this chapter, we are going to discuss the following topics:
- Understanding the basics of Hadoop streaming
- Understanding how to run Hadoop streaming with R
- Exploring the HadoopStreaming R package
Hadoop streaming is a Hadoop utility for running the Hadoop MapReduce job with executable scripts such as Mapper and Reducer. This is similar to the pipe operation in Linux. With this, the text input file is printed on stream (stdin), which is provided as an input to Mapper and the output (stdout) of Mapper is provided as an input to Reducer; finally, Reducer writes the output to the HDFS directory.
The main advantage of the Hadoop streaming utility is that it allows Java as well as non-Java programmed MapReduce jobs to be executed over Hadoop clusters. Also, it takes care of the progress of running MapReduce jobs. The Hadoop streaming supports the Perl, Python, PHP, R, and C++ programming languages. To run an application written in other programming languages, the developer just needs to translate the application logic into the Mapper and Reducer sections with the key and value output elements. We learned in Chapter 2, Writing Hadoop MapReduce Programs, that to create Hadoop MapReduce jobs we need Mapper, Reducer, and Driver as the three main components. Here, creating the driver file for running the MapReduce job is optional when we are implementing MapReduce with R and Hadoop.
This chapter is written with the intention of integrating R and Hadoop. So we will see the example of R with Hadoop streaming. Now, we will see how we can use Hadoop streaming with the R script written with Mapper and Reducer. From the following diagrams, we can identify the various components of the Hadoop streaming MapReduce job.

Hadoop streaming components
Now, assume we have implemented our Mapper and Reducer as code_mapper.R and code_reducer.R. We will see how we can run them in an integrated environment of R and Hadoop. This can be run with the Hadoop streaming command with various generic and streaming options.
Let's see the format of the Hadoop streaming command:
bin/hadoop command [generic Options] [streaming Options]
The following diagram shows an example of the execution of Hadoop streaming, a MapReduce job with several streaming options.
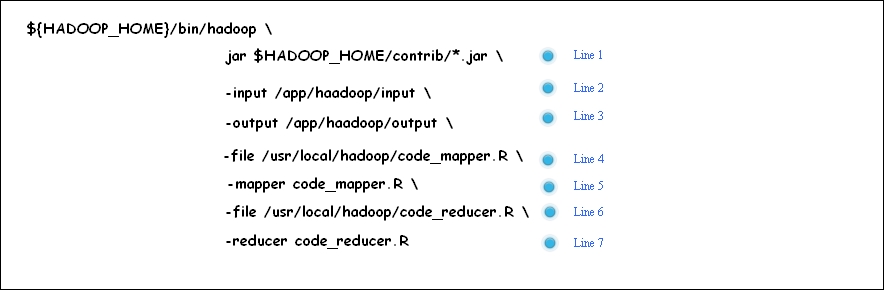
Hadoop streaming command options
In the preceding image, there are about six unique important components that are required for the entire Hadoop streaming MapReduce job. All of them are streaming options except jar.
The following is a line-wise description of the preceding Hadoop streaming command:
- Line 1: This is used to specify the Hadoop jar files (setting up the classpath for the Hadoop jar)
- Line 2: This is used for specifying the input directory of HDFS
- Line 3: This is used for specifying the output directory of HDFS
- Line 4: This is used for making a file available to a local machine
- Line 5: This is used to define the available R file as Mapper
- Line 6: This is used for making a file available to a local machine
- Line 7: This is used to define the available R file as Reducer
The main six Hadoop streaming components of the preceding command are listed and explained as follows:
- jar: This option is used to run a jar with coded classes that are designed for serving the streaming functionality with Java as well as other programmed Mappers and Reducers. It's called the Hadoop streaming jar.
- input: This option is used for specifying the location of input dataset (stored on HDFS) to Hadoop streaming MapReduce job.
- output: This option is used for telling the HDFS output directory (where the output of the MapReduce job will be written) to Hadoop streaming MapReduce job.
- file: This option is used for copying the MapReduce resources such as Mapper, Reducer, and Combiner to computer nodes (Tasktrackers) to make it local.
- mapper: This option is used for identification of the executable
Mapperfile. - reducer: This option is used for identification of the executable
Reducerfile.
There are other Hadoop streaming command options too, but they are optional. Let's have a look at them:
inputformat: This is used to define the input data format by specifying the Java class name. By default, it'sTextInputFormat.outputformat: This is used to define the output data format by specifying the Java class name. By default, it'sTextOutputFormat.partitioner: This is used to include the class or file written with the code for partitioning the output as (key, value) pairs of the Mapper phase.combiner: This is used to include the class or file written with the code for reducing the Mapper output by aggregating the values of keys. Also, we can use the default combiner that will simply combine all the key attribute values before providing the Mapper's output to the Reducer.cmdenv: This option will pass the environment variable to the streaming command. For example, we can passR_LIBS = /your /path /to /R /libraries.inputreader: This can be used instead of theinputformatclass for specifying the record reader class.verbose: This is used to verbose the output.numReduceTasks: This is used to specify the number of Reducers.mapdebug: This is used to debug the script of theMapperfile when the Mapper task fails.reducedebug: This is used to debug the script of theReducerfile when the Reducer task fails.
Now, it's time to look at some generic options for the Hadoop streaming MapReduce job.
conf: This is used to specify an application configuration file.-conf configuration_fileD: This is used to define the value for a specific MapReduce or HDFS property. For example:-D property = value or to specify the temporary HDFS directory.-D dfs.temp.dir=/app/tmp/Hadoop/or to specify the total number of zero Reducers:
-D mapred.reduce.tasks=0fs: This is used to define the Hadoop NameNode.-fs localhost:portjt: This is used to define the Hadoop JobTracker.-jt localhost:portfiles: This is used to specify the large or multiple text files from HDFS.-files hdfs://host:port/directory/txtfile.txtlibjars: This is used to specify the multiple jar files to be included in the classpath.-libjars /opt/ current/lib/a.jar, /opt/ current/lib/b.jararchives: This is used to specify the jar files to be unarchived on the local machine.-archives hdfs://host:fs_port/user/testfile.jar