
In the previous chapter, we learned how to set up the R and Hadoop development environment. Since we are interested in performing Big Data analytics, we need to learn Hadoop to perform operations with Hadoop MapReduce. In this chapter, we will discuss what MapReduce is, why it is necessary, how MapReduce programs can be developed through Apache Hadoop, and more.
In this chapter, we will cover:
- Understanding the basics of MapReduce
- Introducing Hadoop MapReduce
- Understanding the Hadoop MapReduce fundamentals
- Writing a Hadoop MapReduce example
- Understanding several possible MapReduce definitions to solve business problems
- Learning different ways to write Hadoop MapReduce in R
Understanding the basics of MapReduce could well be a long-term solution if one doesn't have a cluster or uses Message Passing Interface (MPI). However, a more realistic use case is when the data doesn't fit on one disk but fits on a Distributed File System (DFS), or already lives on Hadoop-related software.
Moreover, MapReduce is a programming model that works in a distributed fashion, but it is not the only one that does. It might be illuminating to describe other programming models, for example, MPI and Bulk Synchronous Parallel (BSP). To process Big Data with tools such as R and several machine learning techniques requires a high-configuration machine, but that's not the permanent solution. So, distributed processing is the key to handling this data. This distributed computation can be implemented with the MapReduce programming model.
MapReduce is the one that answers the Big Data question. Logically, to process data we need parallel processing, which means processing over large computation; it can either be obtained by clustering the computers or increasing the configuration of the machine. Using the computer cluster is an ideal way to process data with a large size.
Before we talk more about MapReduce by parallel processing, we will discuss Google MapReduce research and a white paper written by Jeffrey Dean and Sanjay Ghemawat in 2004. They introduced MapReduce as simplified data processing software on large clusters. MapReduce implementation runs on large clusters with commodity hardware. This data processing platform is easier for programmers to perform various operations. The system takes care of input data, distributes data across the computer network, processes it in parallel, and finally combines its output into a single file to be aggregated later. This is very helpful in terms of cost and is also a time-saving system for processing large datasets over the cluster. Also, it will efficiently use computer resources to perform analytics over huge data. Google has been granted a patent on MapReduce.
For MapReduce, programmers need to just design/migrate applications into two phases: Map and Reduce. They simply have to design Map functions for processing a key-value pair to generate a set of intermediate key-value pairs, and Reduce functions to merge all the intermediate keys. Both the Map and Reduce functions maintain MapReduce workflow. The Reduce function will start executing the code after completion or once the Map output is available to it.
Their execution sequence can be seen as follows:
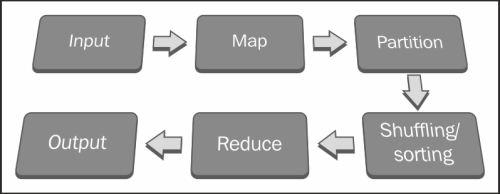
MapReduce assumes that the Maps are independent and will execute them in parallel. The key aspect of the MapReduce algorithm is that if every Map and Reduce is independent of all other ongoing Maps and Reduces in the network, the operation will run in parallel on different keys and lists of data.
A distributed filesystem spreads multiple copies of data across different machines. This offers reliability as well as fault tolerance. If a machine with one copy of the file crashes, the same data will be provided from another replicated data source.
The master node of the MapReduce daemon will take care of all the responsibilities of the MapReduce jobs, such as the execution of jobs, the scheduling of Mappers, Reducers, Combiners, and Partitioners, the monitoring of successes as well as failures of individual job tasks, and finally, the completion of the batch job.
Apache Hadoop processes the distributed data in a parallel manner by running Hadoop MapReduce jobs on servers near the data stored on Hadoop's distributed filesystem.
Companies using MapReduce include:
- Amazon: This is an online e-commerce and cloud web service provider for Big Data analytics
- eBay: This is an e-commerce portal for finding articles by its description
- Google: This is a web search engine for finding relevant pages relating to a particular topic
- LinkedIn: This is a professional networking site for Big Data storage and generating personalized recommendations
- Trovit: This is a vertical search engine for finding jobs that match a given description
- Twitter: This is a social networking site for finding messages
Apart from these, there are many other brands that are using Hadoop for Big Data analytics.