
HadoopStreaming is an R package developed by David S. Rosenberg. We can say this is a simple framework for MapReduce scripting. This also runs without Hadoop for operating data in a streaming fashion. We can consider this R package as a Hadoop MapReduce initiator. For any analyst or developer who is not able to recall the Hadoop streaming command to be passed in the command prompt, this package will be helpful to quickly run the Hadoop MapReduce job.
The three main features of this package are as follows:
- Chunkwise data reading: The package allows chunkwise data reading and writing for Hadoop streaming. This feature will overcome memory issues.
- Supports various data formats: The package allows the reading and writing of data in three different data formats.
- Robust utility for the Hadoop streaming command: The package also allows users to specify the command-line argument for Hadoop streaming.
This package is mainly designed with three functions for reading the data efficiently:
hsTableReaderhsKeyValReaderhsLineReader
Now, let's understand these functions and their use cases. After that we will understand these functions with the help of the word count MapReduce job.
The hsTableReader function is designed for reading data in the table format. This function assumes that there is an input connection established with the file, so it will retrieve the entire row. It assumes that all the rows with the same keys are stored consecutively in the input file.
As the Hadoop streaming job guarantees that the output rows of Mappers will be sorted before providing to the reducers, there is no need to use the sort function in a Hadoop streaming MapReduce job. When we are not running this over Hadoop, we explicitly need to call the sort function after the Mapper function gets execute.
Defining a function of hsTableReader:
hsTableReader(file="", cols='character', chunkSize=-1, FUN=print, ignoreKey=TRUE, singleKey=TRUE, skip=0, sep=' ', keyCol='key', FUN=NULL, ,carryMemLimit=512e6, carryMaxRows=Inf, stringsAsFactors=FALSE)
The terms in the preceding code are as follows:
file: This is a connection object, stream, or string.chunkSize: This indicates the maximum number of lines to be read at a time by the function.-1means all the lines at a time.cols: This means a list of column names as "what" argument to scan.skip: This is used to skip the first n data rows.FUN: This function will use the data entered by the user.carryMemLimit: This indicates the maximum memory limit for the values of a single key.carryMaxRows: This indicates the maximum rows to be considered or read from the file.stringsAsFactors: This defines whether the strings are converted to factors or not (TRUEorFALSE).
For example, data in file:
# Loading libraries Library("HadoopStreaming") # Input data String with collection of key and values str <- " key1 1.91 key1 2.1 key1 20.2 key1 3.2 key2 1.2 key2 10 key3 2.5 key3 2.1 key4 1.2 "cat(str)
The output for the preceding code is as shown in the following screenshot:
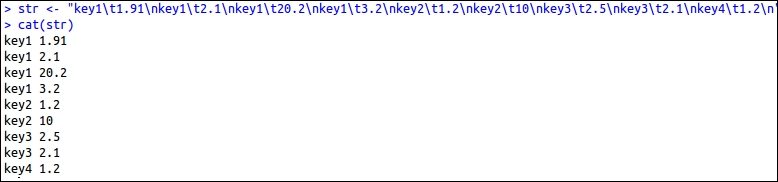
The data read by hsTableReader is as follows:
# A list of column names, as'what' arg to scan cols = list(key='',val=0) # To make a text connection con <- textConnection(str, open = "r") # To read the data with chunksize 3 hsTableReader(con,cols,chunkSize=3,FUN=print,ignoreKey=TRUE)
The output for the preceding code is as shown in the following screenshot:
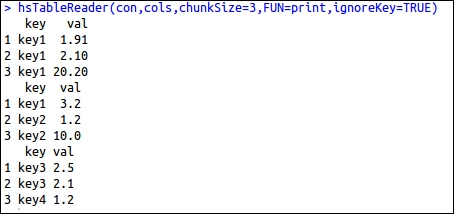
The hsKeyValReader function is designed for reading the data available in the key-value pair format. This function also uses chunkSize for defining the number of lines to be read at a time, and each line consists of a key string and a value string.
hsKeyValReader(file = "", chunkSize = -1, skip = 0, sep = " ",FUN = function(k, v) cat(paste(k, v))
The terms of this function are similar to hsTablereader().
Example:
# Function for reading chunkwise dataset printkeyval <- function(k,v) {cat('A chunk: ')cat(paste(k,v,sep=': '),sep=' ')} str <- "key1 val1 key2 val2 key3 val3 " con <- textConnection(str, open = "r") hsKeyValReader(con, chunkSize=1, FUN=printFn)
The output for the preceding code is as shown in the following screenshot:
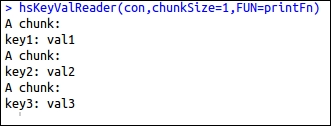
The hsLineReader function is designed for reading the entire line as a string without performing the data-parsing operation. It repeatedly reads the chunkSize lines of data from the file and passes a character vector of these strings to FUN.
hsLineReader(file = "", chunkSize = 3, skip = 0, FUN = function(x) cat(x, sep = "
"))
The terms of this function are similar to hsTablereader().
Example:
str <- " This is HadoopStreaming!! here are, examples for chunk dataset!! in R ?" # For defining the string as data source con <- textConnection(str, open = "r") # read from the con object hsLineReader(con,chunkSize=2,FUN=print)
The output for the preceding code is as shown in the following screenshot:
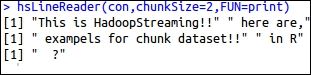
You can get more information on these methods as well as other existing methods at http://cran.r-project.org/web/packages/HadoopStreaming/HadoopStreaming.pdf.
Now, we will implement the above data-reading methods with the Hadoop MapReduce program to be run over Hadoop. In some of the cases, the key-values pairs or data rows will not be fed in the machine memory; so reading that data chunk wise will be more appropriate than improving the machine configuration.
Problem definition:
Hadoop word count: As we already know what a word count application is, we will implement the above given methods with the concept of word count. This R script has been reproduced here from the HadoopStreaming R package, which can be downloaded along with the HadoopStreaming R library distribution as the sample code.
Input dataset: This has been taken from Chapter 1 of Anna Karenina (novel) by the Russian writer Leo Tolstoy.
R script: This section contains the code of the Mapper, Reducer, and the rest of the configuration parameters.
File: hsWordCnt.R
## Loading the library library(HadoopStreaming) ## Additional command line arguments for this script (rest are default in hsCmdLineArgs) spec = c('printDone','D',0,"logical","A flag to write DONE at the end.",FALSE) opts = hsCmdLineArgs(spec, openConnections=T) if (!opts$set) { quit(status=0) } # Defining the Mapper columns names mapperOutCols = c('word','cnt') # Defining the Reducer columns names reducerOutCols = c('word','cnt') # printing the column header for Mapper output if (opts$mapcols) { cat( paste(mapperOutCols,collapse=opts$outsep),' ', file=opts$outcon ) } # Printing the column header for Reducer output if (opts$reducecols) { cat( paste(reducerOutCols,collapse=opts$outsep),' ', file=opts$outcon ) } ## For running the Mapper if (opts$mapper) { mapper <- function(d) { words <- strsplit(paste(d,collapse=' '),'[[:punct:][:space:]]+')[[1]] # split on punctuation and spaces words <- words[!(words=='')] # get rid of empty words caused by whitespace at beginning of lines df = data.frame(word=words) df[,'cnt']=1 # For writing the output in the form of key-value table format hsWriteTable(df[,mapperOutCols],file=opts$outcon,sep=opts$outsep) } ## For chunk wise reading the Mapper output, to be feeded to Reducer hsLineReader(opts$incon,chunkSize=opts$chunksize,FUN=mapper) ## For running the Reducer } else if (opts$reducer) { reducer <- function(d) { cat(d[1,'word'],sum(d$cnt),' ',sep=opts$outsep) } cols=list(word='',cnt=0) # define the column names and types (''-->string 0-->numeric) hsTableReader(opts$incon,cols,chunkSize=opts$chunksize,skip=opts$skip,sep=opts$insep,keyCol='word',singleKey=T, ignoreKey= F, FUN=reducer) if (opts$printDone) { cat("DONE "); } } # For closing the connection corresponding to input if (!is.na(opts$infile)) { close(opts$incon) } # For closing the connection corresponding to input if (!is.na(opts$outfile)) { close(opts$outcon) }
Since this is a Hadoop streaming job, it will run same as the executed previous example of a Hadoop streaming job. For this example, we will use a shell script to execute the runHadoop.sh file to run Hadoop streaming.
Setting up the system environment variable:
#! /usr/bin/env bash HADOOP="$HADOOP_HOME/bin/hadoop" # Hadoop command HADOOPSTREAMING="$HADOOP jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.3.jar" # change version number as appropriate RLIBPATH=/usr/local/lib/R/site-library # can specify additional R Library paths here
Setting up the MapReduce job parameters:
INPUTFILE="anna.txt" HFSINPUTDIR="/HadoopStreaming" OUTDIR="/HadoopStreamingRpkg_output" RFILE=" home/hduser/Desktop/HadoopStreaming/inst/wordCntDemo/ hsWordCnt.R" #LOCALOUT="/home/hduser/Desktop/HadoopStreaming/inst/wordCntDemo/annaWordCnts.out" # Put the file into the Hadoop file system #$HADOOP fs -put $INPUTFILE $HFSINPUTDIR
Removing the existing output directory:
# Remove the directory if already exists (otherwise, won't run) #$HADOOP fs -rmr $OUTDIR
Designing the Hadoop MapReduce command with generic and streaming options:
MAPARGS="--mapper" REDARGS="--reducer" JOBARGS="-cmdenv R_LIBS=$RLIBPATH" # numReduceTasks 0 # echo $HADOOPSTREAMING -cmdenv R_LIBS=$RLIBPATH -input $HFSINPUTDIR/$INPUTFILE -output $OUTDIR -mapper "$RFILE $MAPARGS" -reducer "$RFILE $REDARGS" -file $RFILE $HADOOPSTREAMING $JOBARGS -input $HFSINPUTDIR/$INPUTFILE -output $OUTDIR -mapper "$RFILE $MAPARGS" -reducer "$RFILE $REDARGS" -file $RFILE
Extracting the output from HDFS to the local directory:
# Extract output ./$RFILE --reducecols > $LOCALOUT $HADOOP fs -cat $OUTDIR/part* >> $LOCALOUT
We can now execute the Hadoop streaming job by executing the command, runHadoop.sh. To execute this, we need to set the user permission.
sudo chmod +x runHadoop.sh
Executing via the following command:
./runHadoop.sh
Finally, it will execute the whole Hadoop streaming job and then copy the output to the local directory.