
To produce a better fit of the training data, we can use regularization to avoid the problem of overfitting our data. The value ![]() of a given model must be appropriately selected depending on the behavior of the model. Note that a high regularization parameter could result in a high training error, which is an undesirable effect. We can vary the regularization parameter in a formulated machine learning model to produce the following plot of the error values over the value of the regularization parameter in our model:
of a given model must be appropriately selected depending on the behavior of the model. Note that a high regularization parameter could result in a high training error, which is an undesirable effect. We can vary the regularization parameter in a formulated machine learning model to produce the following plot of the error values over the value of the regularization parameter in our model:
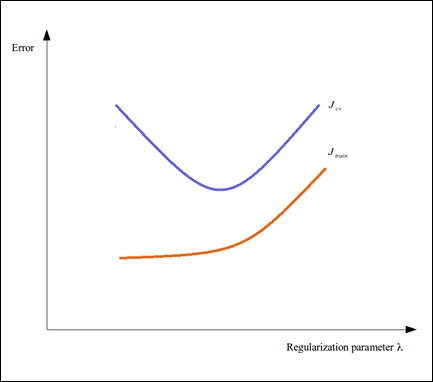
Thus, as shown in the preceding plot, we can also minimize the training and cross-validation error in the model by changing the regularization parameter. If a model exhibits a high value for both these error values, we must consider reducing the value of the regularization parameter until both the error values are significantly low for the supplied sample data.