
Chapter 15
Data Governance Concepts: Ensuring a Baseline
This chapter covers Objective 5.1 (Summarize important data governance concepts) of the CompTIA Data+ exam and includes the following topics:
 Data governance concepts
Data governance concepts- Access requirements
- Security requirements
- Storage environment requirements
- Use requirements
- Entity relationship requirements
- Data classification
- Jurisdiction requirements
- Data breach reporting
For more information on the official CompTIA Data+ exam topics, see the Introduction.
This chapter focuses on data governance concepts. Data governance ensures that there is an established baseline that covers multiple aspects, such as data security requirements, storage requirements, data classification, and more. This chapter covers specifics related to data access, data security, data use, and data storage environment requirements. It also describes entity relationship requirements such as record link restrictions, data constraints, and cardinality. This chapter also covers data classification, which forms the basis for classifying and segregating different types of data, such as personally identifiable information (PII), personal health information (PHI), and Payment Card Industry (PCI) information. The impacts of industry and government regulations are discussed, as are jurisdiction requirements. In addition, this chapter covers data breach reporting.
Data governance is all about ensuring that there is a baseline to uphold the quality, security, accessibility, availability, integrity, and usefulness of data—throughout the data life cycle. Data governance offers bases to define:
 Who is allowed to access data within or from outside an organization
Who is allowed to access data within or from outside an organization- Who has control to update data assets within the organization
- What sort of reporting mechanisms must be in place to ensure appropriate regulatory and compliance reporting
Data governance is not a solo effort by one body within an organization; rather, it is a cumulative effort by the whole organization. While there are well-defined roles such as data custodian, data owner, and data steward that empower data governance, within an organization, ensuring data governance requires participation from all lines of business and from all stakeholders. Following is a summary of these three key roles:
- Data owner: Usually represented by a stakeholder in higher leadership, this role looks into the data classification, data protection, data quality, and data use in an organization. This role is responsible for maintaining data quality.
- Data custodian: As the name implies, a data custodian is responsible for enforcement of security controls based on an organization’s data governance standards. Sometimes data custodians are also known as data operators.
- Data steward: Sometimes also known as data architects, data stewards are responsible for day-to-day data management. They are the subject matter experts for different data domains (for example, supply chain management, business processes).
Data governance ensures that quality data is available at all times for organizational use and that all the right users of data can make decisions based on quality data. Following are a few merits of implementing proper data governance:
- Better and faster decision making for the organization: When quality data is available throughout the organization, better data-driven insights can be derived, which leads to faster decision making.
- Compliance adherence: Good data governance automatically leads to better reporting for both internal and external bodies and ensures compliance at all levels.
- Better customer service: Good quality data implies that customer records are updated and customers can get more personalized service.
- Regulated data management: Using data governance frameworks, an organization can decide between regulated and unregulated data, and it can classify and manage the data that is subject to various regulations.
Figure 15.1 provides insight into how seriously organizations are taking data governance and consent to use data.
Figure 15.1 Data Consent Request
Access and Security Requirements
Access Requirements
Organizations have to control data access in order to limit data exposure to only authorized users. In order to do that, they may leverage technical or administrative controls, as well as physical controls in some cases. There are also requirements around how data can be transferred and used between two organizations or the type of data that can be released based on the data being protected or unprotected data.
Role-Based and User Group–Based Access
The two major categories of data access requirements or data access control covered in this section are role-based access control and user group–based access control.
Role-Based Access Control
Role-based access control (RBAC) is an established approach to data security whereby the system permits or restricts access based on an individual’s role within the organization. Data consumers (that is, the users looking to access data) can only access the data that pertains to their specific job functions. To contextualize this, let’s look at an example.
Think of an organization where there are multiple departments, such as sales, services, marketing, HR, and finance. Say that you don’t want HR to look at sales specifics and give data access from services department to finance, as these roles are not dependent on each other’s data. The organization would create a role-based access control whereby any employee from HR doesn’t have access to sales dataset(s) and, similarly, any employee from services doesn’t have any access to finance dataset(s). This will ensure that anyone not entitled to data they’re trying to access is shunted out; in addition, it will ensure that the right set of people have access to the right data to perform their job roles effectively.
Note
Role-based access control makes it possible to manage access to the database tables, columns, and fields/cells leveraging access control lists (ACLs).
An access management team/group enables RBAC by adding people to predetermined roles and determining the privileges associated with each role.
User Group–Based Access Control
The major difference between role-based and user group–based access control is that while in RBAC, a user can be assigned to one role explicitly, in user group–based access control, a user can be assigned to multiple groups, thereby gaining access to multiple datasets.
For example, consider a user from leadership who needs access to sales, finance, marketing, and HR datasets in order to compile a report on how each group did over the past 12 months. This user can be part of the executives group by definition of their role; however, to give cross-group privileges to this user, you can assign the user to a group called org_executives that has access to all organizational datasets they need access to. This assignment simplifies the problem of assigning one-to-one mapping on a user-to-role basis. Based on the user group assignment, this user would now have access to multiple datasets.
Data Use Agreements and Release Approvals
Now, let’s look more closely at two data access requirements:
- Data use agreements
- Release approvals
A data use agreement (DUA) is brought into practice when moving protected data from one party to another. Specifically, a DUA is a contractual agreement between a data user or requester of access to information and the data provider or the organization or body offering the data. Protected data includes:
- Personally identifiable information (PII)
- Personal health information (PHI)
- Financial data
A DUA encompasses important topics such as right to use data (also called permitted use), liability arising from the use of data, privacy rights associated with the data, intellectual property rights, and obligations to use data properly. Some of the key aspects covered by a DUA are:
- Who has ownership of the data, and what are the terms of agreement?
- What type of data will be shared between the two parties (that is, the user and the provider)?
- What data will be shared outside of the two parties?
- What is the purpose for which the data will be used?
- Who is responsible for handling any violations of the agreement?
- What type of data security will be adopted?
Now that you understand DUAs, let’s focus on data release approvals.
Any private and confidential data (that is, protected data) that is to be released must have certain approvals aligned to it. These approvals are based on policies of an organization—and are often in line with local legislation. If an organization collects data about your health, for example, it should ask for your consent to release it to another organization for processing or analysis; in addition, it must follow the requirements of state and other bodies that govern how such data can be released to the organization’s wider network.
There are typically several requirements:
- The data must be managed as described in a data management plan.
- Any applications managing data and data flows must be well documented.
- Unique identifiers that identify an individual must be masked in transit/storage.
- The data repository must be well documented and adhere to applicable standards.
Note
This list of release approvals is not comprehensive.
Security Requirements
Data security is an important topic for many reasons. The majority of organizations are aware that they handle data from different parts of the world and that a variety of different security requirements apply. For example, the European General Data Protection Regulation (GDPR) ensures consumer rights regarding the protection and privacy of their data. Following are some of the key aspects that GDPR protects:
- Basic identity information such as name, address, and ID numbers
- Health and genetic data
- Biometric data
- Racial or ethnic data
- Political opinions
- Sexual orientation
Note
There are many privacy and security requirements globally. Some of the most prominent ones in the United States are the California Consumer Privacy Act (CCPA), the Colorado Privacy Act, and the Virginia Consumer Data Privacy Act (Virginia CDPA).
Many data leaks and hacking attempts have left organizations with huge losses in terms of reputation and finances. Security of data in motion and at rest plays an important role, and we will discuss these aspects shortly.
Before we get into the nuts and bolts of data governance, however, it is important to understand a very basic construct called the CIA triad that guides all data security and governance principles. The CIA triad has three pillars:
- Confidentiality: Confidentiality enables organizations to deploy the right security measures (physical, technical, or administrative) to protect sensitive information from unauthorized access attempts.
- Integrity: Integrity enables organizations to ensure that data is consistent and accurate over its entire life cycle and is not altered by an unauthorized entity.
- Availability: Availability implies that the data is always accessible in a consistent way for authorized users.
The CIA triad is frequently used to guide information security policies in organizations.
Now that you know some of the basics of data security, you’re ready to move on to the concept of data encryption—at rest and in transit.
Data Encryption
ExamAlert
Data security is a very popular topic, and you should expect to see questions on data security—and especially data encryption—on the CompTIA Data+ exam.
Simply put, encryption is the process of converting plaintext or readily readable information into ciphertext—scrambled randomized characters that cannot be interpreted easily by someone who is not supposed to have access to the information. Keys are used to encrypt and decrypt data, and only the appropriate users (that is, the users who should have access to the data/information) can use them.
Note
The study of cryptography covers topics such as data encryption and decryption.
Further, encryption can be broadly classified as symmetric and asymmetric. With symmetric encryption, the same key is used for encryption (scrambling) and decryption (unscrambling). In contrast, when using asymmetric encryption, the encrypting key is different from the decrypting key. Symmetric key encryption is also known as shared key encryption, and asymmetric encryption is also known as public key cryptography. Figure 15.2 shows the processes of symmetric and asymmetric encryption.
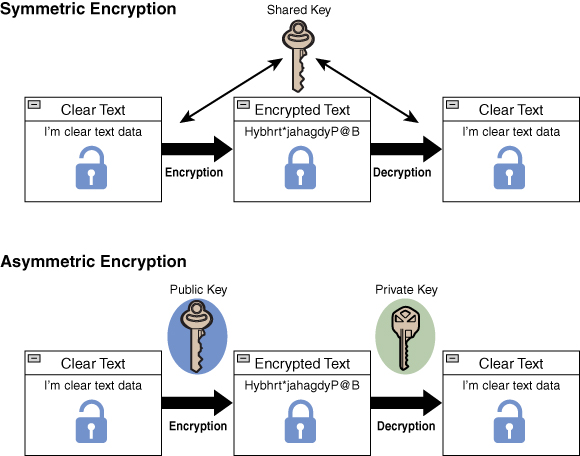
Figure 15.2 Symmetric vs. Asymmetric Encryption Overview
Symmetric and asymmetric encryption can be implemented by leveraging algorithms such as:
- Blowfish: Blowfish is a symmetric cipher that has a variable key length from 32 to 448 bits. Blowfish is a block cipher, which means it divides data into fixed blocks (of 64 bits each) when encrypting data.
- Advanced Encryption Standard (AES): AES, which was established by the U.S. government as a standard for encryption, is a symmetric key algorithm that uses block cipher methods. AES is available in 128-bit, 192-bit, and 256-bit forms, with increasing numbers of rounds of encryption (so that 256-bit AES is more secure than 128-bit and 192-bit AES).
- RSA: RSA is a public key algorithm, and RSA-based asymmetric encryption is used extensively throughout the Internet. For example, security protocols such as SSH, S/MIME, and SSL/TLS leverage RSA.
- Elliptic Curve Cryptography (ECC): ECC is an asymmetric cipher that offers better security than RSA, with significantly shorter key lengths.
Why is it important to encrypt data? It is important to keep customer and organizational data private and safe from misuse. Data is more accessible than ever before, and the attack surface (that is, the touchpoints that a hacker can misuse to access data) is ever increasing, thanks to ubiquitous connectivity and access mechanisms. Just storing data in a database that is accessible via username and password is not enough to protect it. Someone who’s not supposed to get access to data may get it, but if the data is encrypted, the hacker will end up reading gibberish rather than what they came for. And without the right key, it’s very difficult to decrypt the data. Encryption protects valuable data and also helps organizations comply with data-related regulations.
Data encryption can be used for data that is being stored (that is, data at rest) and for data as it is being transmitted (that is, data in motion). Keys are only provided to authorized users.
Data encryption at rest encrypts data when it resides on a storage device and is not actively being used or transferred. Compared to data in motion, data at rest is much less susceptible to attacks and data exfiltration. However, data at rest is not immune to hacking attempts. Encrypting data at rest improves the security posture by reducing accidental or malicious exposure of data due to stolen devices, ransomware attacks, privilege escalation, credential theft, and so on.
Data Transmission
Data is considered in transit or in motion when it is moving between devices or from one database, data warehouse, or data lake to another database, data warehouse, or data lake. This movement might be over an insecure medium such as the Internet or over a more secure medium, such as a virtual private network (VPN) or Multiprotocol Label Switching (MPLS). Sometimes data is even moved from personal or corporate devices, such as from a laptop to a USB drive or from a DVD to a laptop.
It is easy to see why data is at such great risk during transfer: It has to pass through potentially insecure media and may be exposed to an unintended audience. Sometimes, security concerns might be with the vulnerabilities of the transfer method (for example, an Internet session being hijacked).
Encrypting data during transfer (sometimes also referred to as end-to-end encryption) safeguards data that is being moved from source to destination through one or more media. There are various ways to protect data during transmission, including:
- Encryption algorithms: A longer encryption key length offers stronger protection. Hence, when you’re selecting an encryption algorithm such as AES, consider going for AES-192 or AES-256.
- Mobile device management (MDM): It is pretty common today for organizations to allow employees to bring their own devices to work and to have corporate data such as emails or presentations on their personal devices. Data moving between corporate assets and these devices needs to be encrypted, and the security posture of such a device must be appropriate. This can be achieved by using a bring-your-own-device (BYOD) policy and MDM solutions.
- Secure wireless access: Almost everybody is on wireless networks at home or at an office, and wireless connectivity needs to be secure. Earlier wireless protocols such as Wired Equivalent Privacy (WEP) are considered to be very weak and are not recommended for use today. Wi-Fi Protected Access 2 (WPA2) and Wi-Fi Protected Access 3 (WPA3) are preferred protocols, and WPA2-AES and WPA3-AES offer maximum security for wireless clients. Further, rogue access points (APs) should not be allowed in a wireless network.
- Secure wired access: Servers are always hardwired, and sometimes you have to plug in a laptop to a corporate network. To secure the connectivity points (that is, switch ports) on these machines, you can deploy switch port security combined with Layer 2 and Layer 3 access control lists (ACLs), which allow only the relevant traffic to traverse.
- Data loss prevention (DLP): DLP can be used to ensure that any classified and protected data cannot be exfiltrated from the organization without proper approval. This helps ensure that any deliberate or unknown attempts to expose sensitive data are automatically thwarted.
Every organization should focus on encryption of both data at rest and data in motion as a baseline for good governance and ensuring that data integrity is maintained.
De-identifying Data/Data Masking
Many regulatory compliance requirements require data to be masked (or de-identified) before it can be transmitted or stored. Data de-identification/masking is different from encryption, where data is changed from its original form. With data masking, some fields or parts of fields may be masked to hide explicit information. An organization’s databases might contain personal and sensitive data, and one of the most effective ways to prevent exposure of the data is to mask it before it is used for analysis.
Data masking is important to satisfy multiple regulatory requirements, such as:
- Payment Card Industry Data Security Standard (PCI–DSS): Masking payment card data
- Health Insurance Portability and Accountability Act (HIPAA): Masking health data
- General Data Protection Regulation (GDPR): Masking personal data
- Family Educational Rights and Privacy Act (FERPA): Masking student data
- Sarbanes-Oxley Act (SOX): Masking U.S. public company and accounting firm data
Data masking can take two main forms: static data masking or dynamic data masking. Whereas static data masking masks data at rest, dynamic data masking is focused on data in motion (also known as on-the-fly data masking). Data de-identification is a form of dynamic data masking.
ExamAlert
Data masking is an important concept to know for the CompTIA Data+ exam, and you should know the difference between static and dynamic data masking.
Figure 15.3 shows an example of static data masking.
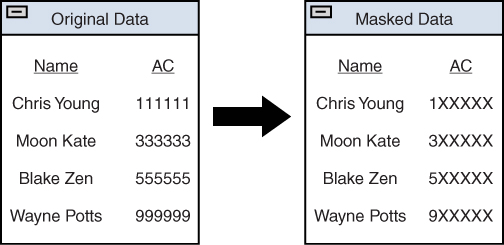
Figure 15.3 Static Data Masking
It should be apparent from Figure 15.3 that all data that is deemed sensitive (that is, the account numbers) is masked. Any user trying to access this information will see only the masked data, regardless of the user’s role.
Static masking might not be useful when you have multiple users who should have different access to data based on their roles. For example, say that your organization wants to give full access to customer account information to sales and minimal access to IT. This can be achieved with dynamic data masking, illustrated in Figure 15.4.

Figure 15.4 Dynamic Data Masking
As you can see in Figure 15.4, sales users have full access to customer data, whereas IT users only have access to customers’ names and part of the account information.
You can use services such as AWS Lake Formation to provide access to data for users in your organization based on their roles/functions. AWS Athena can also anonymize datasets by masking specified fields.
Storage Environment Requirements
Data can be stored in multiple locations—from on-premises data stores or data lakes to cloud-based data lakes. Moreover, data sharing within and between organizations is required for many business transactions. This section covers data governance from the perspective of where data is stored.
Shared Drives
It is not unusual to see multiple copies of a dataset or a table when multiple users are trying to access data and generating reports or executing queries. Business problems such as redundant and multiple copies of datasets and piles of documents or images, in addition to ever-growing storage requirements, can be resolved by sharing datasets or documents via shared drives.
Note
Shared drives can be both on premises and in the cloud. Windows CIFS shares were the earliest shared drives. Modern collaboration workspaces such as Google Drive and Microsoft OneDrive enable users to collaborate and share documents.
Adopting a shared drive can enable an organization to simplify sharing of documents with intended recipients within and outside the organization. Shared drives can also help resolve storage space issues by reducing the number of duplicate copies of documents flying around in emails. However, it is important to understand that with a shared drive, document ownership gets shifted to the person who is sharing the document with others who have edit or copy rights, and the organizational security policy or governance may not provide appropriate protection. When a single person is the owner of data, they can deauthorize or authorize permissions for every user performing data transactions or edits on that dataset. Without appropriate security controls and data classification as well as user education, shared drives can become messy to manage from a data governance point of view.
On the other hand, shared drives are a boon if managed and deployed correctly. For example, Microsoft SharePoint automatically provides a history of changes and allows users to go back to a point in time and recover critical changes that may have been overwritten. In addition, most shared drives track changes to a document, making it clear who changed critical data and when.
ExamAlert
Shared and local storage are commonly used for data acquisition and post processing storage. These are an important topic for CompTIA Data+ exam.
Local Storage
Local storage refers to data stored on a drive (such as a hard disk drive, solid-state drive, zip drive) in a computer network on an organization’s own premises. While it is easier to apply organizational security policies on local storage than in the cloud and to maintain any data egress from protected systems, an organization needs to continue investing in storage systems and must make the information available by performing backups. Table 15.1 covers the advantages and disadvantages of local storage.
TABLE 15.1 Advantages and Disadvantages of Local Storage
Advantages | Disadvantages |
|---|---|
Local storage offers maximum security as document and file access as well as permissions are maintained by the internal IT staff. | If an end-user device (such as a laptop or phone) is stolen or server access is compromised, the data present on the local drive is compromised or lost. |
The organization has physical possession of files and data. | If the systems are down, unless there is a good backup and restore strategy in place, users do not have access to data. |
Data access is quick as data is stored locally. | Remote users may find that there is latency when accessing data as it is stored centrally. |
The organization has full control of data assets and the way they are shared with external organizations. | Malware such as viruses may be able to destroy or steal data unless there are appropriate security controls and a good data protection/backup system in place. |
Cloud-Based Storage
With cloud-based storage, users are able to store data in cloud provider storage (for example, AWS S3 or EBS, Azure Blobs, GCP Cloud Storage). Many cloud providers offer free storage up to a few gigabytes of data, and more storage space can be bought on a subscription basis so that you pay for what is used.
Again, unless there is governance around what type of data can be stored in cloud-based storage as well as how it is managed, it can be quite a task to keep track of documents flowing from cloud storage to external entities. Hence, it is a good idea to develop data classification and security policies, segregate sensitive and internal data, and take other measures to ensure that data quality and security are maintained.
Table 15.2 outlines the advantages and disadvantages of cloud-based storage.
TABLE 15.2 Advantages and Disadvantages of Cloud-Based Storage
Advantages | Disadvantages |
|---|---|
Users can access data from any anywhere and from any device, which enables them to collaborate and work with data on the go. | Internet access is required to access the data and to update records. |
Data loss can be minimized by using native cloud services, and any user or local server hardware crashes or stolen laptops do not impede data access. | Cloud-based data is an easy target for hackers, given the larger attack surface. |
Hardware costs are reduced when you move from the up-front investment required for on-premises storage solutions to pay-as-you-go (PAYG) cloud storage solutions. | A data security and governance baseline must be established to ensure that data is accessible only by legitimate users. |
Capacity can be extended easily to provide additional storage space when required. | Privacy and security of data stored in the cloud are special considerations. |
Use and Entity Relationship Requirements
Use Requirements
Data is a valuable resource; in fact, it is a lifeline for many organizations. When an organization collects user or consumer data, it must understand the implications of handling the data, from the data use policy to data processing to data deletion. This section starts by covering the basics of acceptable use policies and then discusses data processing, data deletion, and data retention.
Acceptable Use Policies
An organization wants its users to abide by security policies and other policies, such as data protection policies, when using organizational IT assets. An acceptable use policy (AUP) spells out what end users can and cannot do with the organization’s assets and information. Organizations typically ask new organizational members and/or vendors as well as suppliers to sign an AUP before giving them permissions for the internal systems or information.
ExamAlert
AUPs are commonly used in enterprises, and you can expect to see questions around this topic on the CompTIA Data+ exam.
An AUP clearly defines the following:
- What end users can or cannot do with the corporate assets and information
- What happens when there is a breach of the AUP
- How to report any breach of the AUP
- Any compliance and other requirements associated with the AUP
The following are some of the aspects that can be expected to be covered in an AUP:
- Internet use
- Spam and email
- Clear desk
- Mobile device use
- Software use
- Monitoring
- Passwords
It is important for users to understand and accept the AUP before they are given access to organizational data and start leveraging it for analytics or reports. Their use of corporate data is based on their acceptance of the AUP.
Data Processing
Key aspects of data processing are related to data governance. For example, from data acquisition to data processing to data-driven insights, everything should be geared around leveraging data securely and respecting the privacy of personal and identifiable information. This applies to any data processing that is done either manually or using advanced algorithms, including artificial intelligence (AI). A good example of manual data processing would be processing data in multiple spreadsheets and creating pivot tables to reflect information in a primary sheet. A good example of AI-driven data processing would be to leverage metadata and process the most likely outcomes of a set of transactions (via predictive analysis).
Both data and the algorithms used to refine insights may change during their respective life cycles, and it is important for the personnel responsible for creating and using data and algorithms to be accountable. Moreover, as more and more data is collected by organizations, governments, and citizen charter services, the data will be processed by multiple entities using various algorithms. From a governance perspective, dependencies grow, and accountability may gradually be lost. Hence, it is crucial to set up a process in which any data processing mechanism has a clearly stated RACI matrix, which lists the following roles:
- Responsible
- Accountable
- Consulted
- Informed
This helps to dictate who owns which part of data processing and what security and privacy controls they should be using.
Data Deletion
Many privacy regulations require that when an organization collects personally identifiable data, the organization must have a good data deletion policy/guideline in place. While on the business side, stakeholders may want to keep the data forever to drive decision making and prevent the need to collect the data again (which can be costly and time-consuming), on the security and privacy side, regulations limit data usage and retention.
Note
Data deletion can occur in a number of ways. A data deletion policy can specify how an organization deletes the data of users securely and ensure that this deletion is in line with local and international regulations.
Data deletion can be primarily of two types:
- User request based: Data deletion is usually mandatory when a user whose data was previously collected by the organization initiates a data deletion request. Such a request requires that certain types of data be deleted, such as user contact details or any transactional data. There may be some exceptions to data deletion requirements, including things like retaining data that is required for compliance and legal reasons.
- Regulation enforced: This type of data deletion, sometimes known as data purging, is commonly based on local or international privacy regulations. Data retention (covered in the next section) should be closely related to the organizational and regulatory requirements, and after the data retention cycle is over, data must be deleted/purged in accordance with compliance and/or regulatory requirements.
Cloud providers have formed user request–based deletion processes that are easy to understand and follow. For example, Google Cloud Platform (GCP) has clearly laid out a process for data deletion on Google Cloud (see https://cloud.google.com/docs/security/deletion).
The four stages of a data deletion request in GCP are as follows:
- Stage 1: Request for deletion
- Stage 2: Soft deletion of data
- Stage 3: Logical deletion of data from active systems
- Stage 4: Expiration of data from backup systems
You can review the stages of Google Cloud’s deletion pipeline at https://cloud.google.com/docs/security/deletion.
The data deletion process can be very easy or very complex, depending on the organizational data use requirements as well as global or local requirements about safe disposal of customer data.
Data Retention
As briefly mentioned in the previous section, data retention guidelines define how long user/consumer data can be retained as well as how the data should be stored (for example, whether it needs encryption, who can access it and how). In other words, a data retention policy defines how long data can be kept by an organization before it can be securely disposed of or purged.
To simplify the process of data retention, an organization may create a data retention policy that provides directions for storing, holding, and deleting data. A data retention policy should be managed and owned by defined stakeholders within an organization and should meet both organizational needs and regulatory requirements.
Some of the key elements of a data retention policy are as follows:
- The time period for keeping each type of data
- The regulations that apply to the information collected
- Details of data acquisition, such as from whom, where, and why the data was collected
- Details on how the organization will store, secure, back up, and purge the information
- Directions on what should be done in the event of data breaches or policy violations
In the United States, there are a number of data retention regulations. For example, the Health Insurance Portability and Accountability Act of 1996 (HIPAA) protects individuals’ health data, and the Gramm-Leach-Bliley (GLB) Act places a duty on financial service providers to explain to their customers how their information is shared.
Entity Relationship Requirements
This section details data governance as it pertains to entity relationship requirements, such as record link restrictions, data constraints, and cardinality.
Before we get into specifics of data governance pertinent to entity relationship (ER), let’s first take a brief look at what entity relationships are and how they can be useful. An ER is a visual method of explaining the relationships among the various entities in a database. Essentially, if you already have a database and wish to derive relationships or are looking to create a relationship based on relationships between the entities, an ER is the ideal solution. Figure 15.5 shows an ER for a simple sales relationship between a seller, a product being sold, and a customer.
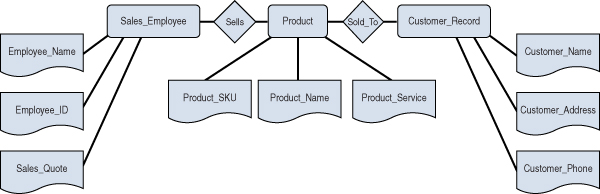
Figure 15.5 ER Model for Product Sales
In Figure 15.5, the entities are Sales_Employee, Product, and Customer_Record, and the relationships are Sells and Sold_To. Every entity has certain attributes, and an ER uses them to make everything come together.
ER models give a data governance team a bird’s-eye view into systems that contain data so they can more easily apply data classifications and provide valuable information to the teams that are required to protect and store the data.
Record Link Restrictions
Not all data is created equal, and organizations often need to combine data from various sources to get a better picture. In such cases, linking multiple datasets can help alleviate data quality issues. In many cases, linking multiple records can lead to better data quality as well as a better sample size (for statistical analysis). Record linking can be performed by identifying a unique identifier across datasets to be linked.
Note
Record linkage can be done using rule-based as well as probabilistic approaches.
From a governance point of view, it is important to note that records that might contain personally identifiable sensitive information should not be exposed to unauthorized personnel. Linkage from within the organization or from outside the organization (for example, with vendors or suppliers) should be controlled based on a need-to-access basis. Every record must have a security classification that determines who can access (or link to) the record. The most commonly used levels are public, private, and restricted, but an organization can set its own levels.
A more sophisticated way to ensure that record linkage works properly is to apply digital rights management (DRM) restrictions to the records. DRM restrictions can be attached to records and move wherever the records go or are linked. DRM solutions offer encryption of information and controls such as time-based deletion or automatic deletion of records, disabling of saving or printing, and inability to change records without the appropriate security level.
Data Constraints
It is important to protect data from unauthorized changes or deletions. You can use data constraints (that is, rules) to effectively enforce the type of data that can be inserted, updated, or deleted from a table or a column. Whereas table-level constraints apply to a whole table, column-level constraints apply to a specific column.
Why would you apply constraints instead of using access rights or data encryption? While the right level of access (based on the classification level) blocks unauthorized users and encryption keeps prying eyes off the data, neither of these solutions protects against human error or sabotage. Constraints prevent accidental and intentional change of data and offer a way to increase the accuracy and reliability of the data in a database.
Note
Constraints can be applied during creation of a database table or afterward.
The following constraints are typically used by database administrators:
- Primary key: Ensures that each record has unique values—and no null values.
- Foreign key: Enforces binding between two tables and verifies the existence of one table’s data in the other table.
- Uniqueness: Ensures that columns have unique values.
- Default value: Assigns a default value to a column when there is no value provided.
- Check: Ensures valid entries for a given column by restricting the range of values, types of values, and format of values for the fields.
Cardinality
In the context of data modeling, cardinality (or relationship cardinality) refers to how one table relates to another table. For example, 1:1 implies that one row in Table 1 relates to one row in Table 2. In addition, there are other relationships, such as 1:N (that is, one-to-many), N:1 (that is, many-to-one), and N:N (that is, many-to-many).
ExamAlert
Cardinality refers to the maximum number of relationships, whereas ordinality refers to the minimum number of relationships.
Using our earlier example, Figure 15.6 shows the cardinality between the seller, the product, and the customer.

Figure 15.6 Cardinality Overview
Mapping relationships is great when it is done and leveraged by the intended audience; however, to properly implement governance around who can map what across databases, you should consider access-based and constraint-based controls. You want to ensure that only personnel with the proper level of access and ability to change constraints can amend data in a database and map it across other databases.
Data Classification, Jurisdiction Requirements, and Data Breach Reporting
Data Classification
In an ideal world, all data resources would be available to all legitimate users, and any illegitimate users would be blocked from accessing a data resource. Data classification is a key step in helping ensure that the governance and protection of data from unauthorized access is executed as required and helping ensure that there is no unintentional alteration, disclosure, or damage to the data. There are industry standards that help indicate what information should be classified. The following are examples of common data classifications:
- Public
- Private
- Confidential
- Controlled
- Restricted
- Sensitive
- Internal use only
The typical data classification scheme that organizations use is a basic classification that includes three levels: public, private, and restricted (or confidential). Government classification tends to include many more levels, such as secret, top secret, controlled, and sensitive.
Personally Identifiable Information (PII)
It is important for an organization to choose a data classification methodology and use it to classify and categorize/prioritize software according to the kinds of data that the software handles. One of the ways to classify software based on the data it uses is to focus on personally identifiable information (PII).
ExamAlert
PII is a very key topic related to data governance, and the CompTIA Data+ exam will focus on this topic.
PII is regulated data that could possibly identify a specific individual. It includes the following:
- First and last names
- Physical addresses
- Personal and corporate email addresses
- Credit card numbers
- Birthdates
- Passport numbers
- Social Security number (SSNs)
- Driver’s license and plate numbers
- Biometric data (such as fingerprints, voice prints)
- Medical records
PII can be classified as sensitive or non-sensitive. Sensitive PII is information that, upon disclosure to an unsanctioned person/entity, might result in maltreatment of the person whose data has been shared. On the other hand, the disclosure of non-sensitive PII is not likely to result in maltreatment of the person whose data has been shared.
In classifying PII data, at least the following data classifications would be required:
- Private: This classification includes data that a user or consumer does not wish to disclose. The disclosure of this data would result in a moderate level of risk to the individual. This data may include information such as home address and date of birth, and it would only be found in customer-specific databases, such as e-commerce records or survey records. This is the type of data that the organization would need to preserve and keep away from prying eyes (such as hackers). This classification requires security controls and access methods, including the ones discussed earlier—such as network security controls, access controls (for example, role-based access control), and masking—to ensure that only authorized individuals can access the data and that the data is not exchanged with another organization without prior approval of the user/consumer.
- Public: This classification refers to data that the user or consumer agrees can be used in the public domain or publicly. The disclosure of this data would result in minimal to no risk to the individual. Public data may include data such as a person’s name, email address, and designation in an organization. This is data that can usually be found in public records, on social media, in telephone and/or business directories, and in blogs. Because this data is available publicly and anyone can access it, an organization must apply appropriate security access controls to prevent the unauthorized alteration or destruction of this user/consumer data.
- Restricted: This classification includes data that is strictly limited to use within the organization that collected it; under no circumstances should it be disclosed to anyone except people who should have access to it. The disclosure of this data would result in a very high level of risk to the individual. This data includes highly sensitive information such as SSNs, credit card numbers, medical data, and license details. A leak of data classified as restricted would disclose information that could easily identify an individual and allow hackers or other attackers to harm the individual by hacking their accounts or identity or by harming them physically or emotionally. This data requires the highest level of security to ensure that it is not even accessible by employees of the organization unless they have the right or need to access it.
Personal Health Information (PHI)
Personal health information (PHI) is protected by the Health Insurance Portability and Accountability Act of 1996 (HIPAA). HIPAA helped establish baseline security controls and safeguards to administratively, technically, and physically uphold the CIA triad for health and medical data.
Electronic protected health information (ePHI) is any PHI that is created, stored, received, and transmitted electronically, using electronic media such as computer disk drives, memory cards, optical discs, or health care networks.
Note
HIPAA requires organizations to ensure the integrity of PHI/ePHI by protecting it from being altered or destroyed in an unauthorized way.
PHI is very similar to PII in that PHI is any individually identifiable health information, such as the following:
- Patient’s name
- Patient’s physical address
- Patient’s SSN
- Patient’s general health history
- Patient’s healthcare services
- Patient’s mental health history
- Patient’s medical record number
- Patient’s health insurance beneficiary number
- Patient’s license plate number
- Patient’s biometric identifiers (fingerprints, voice prints, and so on)
Note
There is some overlap in the information considered PII and PHI because both focus on personally identifiable individual and health information.
PHI is typically classified using the same three classifications as PII: public, private, and restricted.
Payment Card Industry (PCI)
Much as PII and PHI focus on personally identifiable individual and health information, PCI focuses on an individual’s payment card information, such as:
- Card numbers
- Card expiration dates
- Card verification value (CVV2) codes
- PINs
The Payment Card Industry Data Security Standard (PCI-DSS) applies to organizations that process, store, or transmit cardholder data, including:
- Merchants
- Card-issuing banks
- Payment processors
- Point-of-sale machine providers
Note
PCI-DSS was created jointly by American Express, MasterCard, Visa, Discover Financial Services, and JCB International to protect cardholders against misuse of their personal and card information.
At a minimum, the PCI-DSS security standard requires that an organization that processes, stores, or transmits cardholder data meet the following conditions:
- The organization secures and protects cardholder data.
- The organization maintains an information security policy.
- The organization builds and maintains a secure network.
- The organization maintains a vulnerability management program.
- The organization regularly monitors and tests networks for vulnerabilities.
- The organization implements strong access control measures.
PCI-DSS requires data classification to reduce the risks associated with unauthorized disclosure and access. PCI-DSS directs organizations to perform regular risk assessments and to review the security classification process. Cardholder data must be classified by type of data, the retention permissions, and the level of protection. The levels of classification are the same as those of PII and PHI:
- Public
- Private
- Restricted
Jurisdiction Requirements
Data is omnipresent, and keeping track of what is being stored where and who has access to it is becoming increasingly difficult. While industry verticals and governments are trying to regulate the way data is used across countries and states, data security and sovereignty are important issues for all organizations that leverage consumer data in any shape or form.
Impact of Industry and Government Regulations
It is important to understand that data can be stored just about anywhere, and where it is stored sometimes dictates how it can be used. Data sovereignty governs how data can be accessed if it is stored within the country of origin vs. if it is stored in a different country; different laws and governance may apply to the data use.
If an organization operating outside the United States hosts its data in a data center such as an AWS or Azure data center in the United States, the U.S. government has access to that data. Many organizations and their stakeholders may not even be aware of the fact that their data is hosted in another country, and they may be at risk of losing all access to their data or having their data used by the local government without their permission.
For example, according to the U.S. Patriot Act, the U.S. government has access to any data held within its borders as well as all data of companies that operate within the United States.
As another example, the General Data Protection Regulation (GDPR) has had a huge influence on those doing business with EU members as well as on EU members in other jurisdictions. Basically, any organization that has a business or handles transactions in the EU with EU members needs to abide by the GDPR; in addition, any other organization worldwide needs to consider its dealings with a person of EU origin in accordance with the GDPR. The GDPR is perhaps the single most significant regulation affecting businesses in the EU and the rest of the world.
Regulations have a big impact on businesses. The challenge that businesses face is that they do not have to deal with just a couple of simple local or international regulatory requirements that do not change over time; rather, they have to deal with multiple ever-changing and complex local and international regulations in multiple jurisdictions. This complication can impact the velocity with which businesses innovate and grow.
On the flip side, once customers realize that they are in control of how their data will be managed, they are often willing to share more and more data, knowing that it will benefit them as organizations work to make new solutions and offerings available to suit their needs. For example, Apple recently started giving users a choice about how apps can track their activity across other apps on iOS (see Figure 15.7). This is exactly what many consumers want—control over the way their information is used and shared. Such options instill confidence in consumers and allow them to share more information as they see fit.

Figure 15.7 Permission to Track Activity on an iPhone
While this isn’t a direct regulation that Apple has enforced on all Apple Store apps, it is a way to show that the company cares about customers’ privacy.
Data Breach Reporting
In a data breach, an individual’s (or a set of individuals’) information is unlawfully disclosed and, perhaps, leaked. A data breach may be caused by human error (for example, an appropriate security control not being applied) or may be due to hacking of targeted systems (where the hackers are after specific data).
Escalating to the Appropriate Authority
When a data breach occurs, it is crucial to be able to respond to it in a timely manner. An organization might have a data breach management committee, and the members of the committee should respond to a breach appropriately and make any regulatory bodies aware if the breach leads to the loss of sensitive, confidential, or restricted data. The following high-level steps should be taken in responding to a data breach:
Try to contain the breach: Sever the hacker’s connections or take critical systems off the affected network segments.
Evaluate the risks: Ensure that the risk management plan helps identify the type of data that was lost.
Start recovery: Ensure that any critical systems are back online and are secured.
Escalate to senior management and relevant bodies: Ensure that all local bodies and organizational executives who should be informed are aware of the situation.
Notify affected individuals: Reach out to the individuals who were or could be affected by the data breach.
Investigate the cause of the breach: Try to determine the cause of the breach and how similar attempts can be thwarted in future.
It is crucial to contain a breach and to notify the appropriate local bodies so they can help with the remediation as well as manage the next steps.
In the United States, all 50 states have passed breach notification laws that require organizations to notify state residents of security breaches. These laws apply to sensitive categories of information, such as SSNs, credit card information, financial account numbers, health or medical information, birthdates, online account credentials, and digital signatures and/or biometrics. Moreover, U.S. federal laws require notification in the event of a breach of healthcare information, telecom usage information from service providers, information from financial institutions, and government agency information. Almost every aspect of sensitive, restricted, confidential, or higher tiers of classification requires some kind of reporting.
To contain data breaches, an organization may have a data breach policy that is managed by a data breach management committee. A data breach policy should include details about:
- Responding to a breach of data, including managing a data breach
- Notification of individuals whose privacy may be affected by a breach
- Documentation of a breach and the appropriate reporting (both internal and external)
- Organizational communications during and after a breach
What Next?
If you want more practice on this chapter’s exam objective before you move on, remember that you can access all of the Cram Quiz questions on the Pearson Test Prep software online. You can also create a custom exam by objective with the Online Practice Test. Note any objective you struggle with and go to that objective’s material in this chapter.