
This chapter brings us to the end of our journey of reviewing machine learning Java libraries and discussing how to leverage them to solve real-life problems. However, this should not be the end of your journey by all means. This chapter will give you some practical advice on how to start deploying your models in the real world, what are the catches, and where to go to deepen your knowledge. It also gives you further pointers about where to find additional resources, materials, venues, and technologies to dive deeper into machine learning.
This chapter will cover the following topics:
- Important aspects of machine learning in real life
- Standards and markup languages
- Machine learning in the cloud
- Web resources and competitions
Papers, conference presentations, and talks often don't discuss how the models were actually deployed and maintained in production environment. In this section, we'll look into some aspects that should be taken into consideration.
In practice, data typically contains errors and imperfections due to various reasons such as measurement errors, human mistakes, errors of expert judgment in classifying training examples, and so on. We refer to all of these as noise. Noise can also come from the treatment of missing values when an example with unknown attribute value is replaced by a set of weighted examples corresponding to the probability distribution of the missing value. The typical consequences of noise in learning data are low prediction accuracy of learned model in new data and complex models that are hard to interpret and to understand by the user.
Class unbalance is a problem we come across in Chapter 7, Fraud and Anomaly Detection, where the goal was to detect fraudulent insurance claims. The challenge is that a very large part of the dataset, usually more than 90%, describes normal activities and only a small fraction of the dataset contains fraudulent examples. In such a case, if the model always predicts normal, then it is correct 90% of the time. This problem is extremely common in practice and can be observed in various applications, including fraud detection, anomaly detection, medical diagnosis, oil spillage detection, facial recognition, and so on.
Now knowing what the class unbalance problem is and why is it a problem, let's take a look at how to deal with this problem. The first approach is to focus on measures other than classification accuracy, such as recall, precision, and f-measure. Such measures focus on how accurate a model is at predicting minority class (recall) and what is the share of false alarms (precision). The other approach is based on resampling, where the main idea is to reduce the number of overrepresented examples in such way that the new set contains a balanced ratio of both the classes.
Feature selection is arguably the most challenging part of modeling that requires domain knowledge and good insights into the problem at hand. Nevertheless, properties of well-behaved features are as follows:
- Reusability: Features should be available for reuse in different models, applications, and teams
- Transformability: You should be able to transform a feature with an operation, for example,
log(),max(), or combine multiple features together with a custom calculation - Reliability: Features should be easy to monitor and appropriate unit tests should exist to minimize bugs/issues
- Interpretability: In order to perform any of the previous actions, you need to be able to understand the meaning of features and interpret their values
The better you are able to capture the features, the more accurate your results will be.
Some models might produce an output, which is used as the feature in another model. Moreover, we can use multiple models—ensembles—turning any model into a feature. This is a great way to get better results, but this can lead to problems too. Care must be taken that the output of your model is ready to accept dependencies. Also, try to avoid feedback loops, as they can create dependencies and bottlenecks in pipeline.
Another important aspect is model evaluation. Unless you apply your models to actual new data and measure a business objective, you're not doing predictive analytics. Evaluation techniques, such as cross-validation and separated train/test set, simply split your test data, which can give only you an estimate of how your model will perform. Life often doesn't hand you a train dataset with all the cases defined, so there is a lot of creativity involved in defining these two sets in a real-world dataset.
At the end of the day, we want to improve a business objective, such as improve ad conversion rate, get more clicks on recommended items, and so on. To measure the improvement, execute A/B tests, measure differences in metrics across statistically identical populations that each experience a different algorithm. Decisions on the product are always data-driven.
Note
A/B testing is a method for a randomized experiment with two variants: A, which corresponds to the original version, controlling the experiment; and B, which corresponds to a variation. The method can be used to determine whether the variation outperforms the original version. It can be used to test everything from website changes to sales e-mails to search ads.
Udacity offers a free course, covering design and analysis of A/B tests at https://www.udacity.com/course/ab-testing--ud257.
The path from building an accurate model in a lab to deploying it in a product involves collaboration of data science and engineering, as shown in the following three steps and diagram:
- Data research and hypothesis building involves modeling the problem and executing initial evaluation.
- Solution building and implementation is where your model finds its way into the product flow by rewriting it into more efficient, stable, and scalable code.
- Online evaluation is the last stage where the model is evaluated with live data using A/B testing on business objectives.

Another aspect that we need to address is how the model will be maintained. Is this a model that will not change over time? Is it modeling a dynamic phenomenon requiring the model to adjust its prediction over time?
The model is usually built in an of offline batch training and then used on live data to serve predictions as shown in the following figure. If we are able to receive feedback on model predictions; for instance, whether the stock went up as model predicted, whether the candidate responded to campaign, and so on, the feedback should be used to improve the initial model.
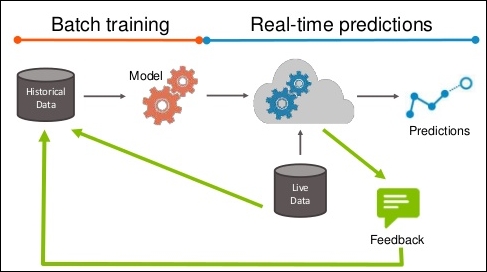
The feedback could be really useful to improve the initial model, but make sure to pay attention to the data you are sampling. For instance, if you have a model that predicts who will respond to a campaign, you will initially use a set of randomly contacted clients with specific responded/not responded distribution and feature properties. The model will focus only on a subset of clients that will most likely respond and your feedback will return you a subset of clients that responded. By including this data, the model is more accurate in a specific subgroup, but might completely miss some other group. We call this problem exploration versus exploitation. Some approaches to address this problem can be found in Osugi et al (2005) and Bondu et al (2010).