
Chapter Two. Relations Versus Types
The title of this chapter is Relations Versus Types, but most of it has to do with types. The point is, the relational model certainly requires a supporting type system, but it has very little to say about the nature of that system. Why does it require it? Because relations (and relvars) are defined in terms of types; that is, every attribute of every relation (and of every relvar) is defined to be of some type. For example, attribute STATUS of the suppliers relvar S might be of type INTEGER. If it is, then every relation s that’s a possible value for relvar S must also have a STATUS attribute of type INTEGER—which means in turn that every tuple in such a relation s must have a STATUS value that’s an integer.
I’ll be discussing such matters in more detail later in this chapter. For now, let me just say that—with certain important exceptions, which I’ll also be discussing later—relational attributes can be defined on any types whatsoever (implying among other things that those types can be as complex as we like, as we’ll see later as well). In particular, such attributes can be defined on either system-defined (that is, built-in) or user-defined types. For our running example, I’ll assume the attributes have types as follows (note that some of the attributes have the same name as the types they’re defined on and others don’t):
Suppliers Parts Shipments
SNO : SNO PNO : PNO SNO : SNO
SNAME : NAME PNAME : NAME PNO : PNO
STATUS : INTEGER COLOR : COLOR QTY : QTY
CITY : CHAR WEIGHT : WEIGHT
CITY : CHARI’ll also assume, where it makes any difference, that types INTEGER (integers) and CHAR (character strings of arbitrary length) are system-defined and the others are user-defined.
By the way, SQL in particular does have a built-in type called INTEGER, as I’m sure you know. It also has a built-in type called CHAR, but (a) that type denotes fixed-length strings, not arbitrary-length ones, and (b) the length in question, n say, usually has to be specified along with the CHAR specification, like this: CHAR(n).[*] (CHAR without such a length specification is shorthand for CHAR(1)—not a very useful default, it might be thought.) SQL also allows users to define their own types.
In the interests of historical accuracy, I should now say that when Codd first defined the relational model, he said relations were defined over domains, not types. In fact, however, domains and types are exactly the same thing. Now, you can take this claim as a position statement on my part, if you like, but I want to present arguments in the next two sections to support that position. I’ll start with the relational model as Codd originally defined it; thus, I’ll use the term domain , not type, until further notice. There are two major topics I want to discuss, one per section:
- Domain-constrained comparisons and “domain check override”
I hope this part of the discussion will persuade you that domains really are types.
- Data value atomicity and first normal form
And I hope this part will persuade you that those types can be arbitrarily complex.
Domain-Constrained Comparisons
Everyone knows (or should know!) that, in the relational model, two values can be tested for equality only if they come from the same domain. In the case of suppliers and parts, for example, the following comparison—which might be part of a WHERE clause—is obviously valid:
SP.SNO = S.SNO /* OK */
By contrast, the following one is not:
SP.PNO = S.SNO /* not OK */
The reason is that part numbers and supplier numbers are different kinds of things, and they correspond to different domains. So the general idea is that the database management system (DBMS)[*] should reject any attempt to perform any relational operation—join, union, divide, or whatever—that calls, explicitly or implicitly, for a comparison between values from different domains. For example, here’s an SQL query where the user is trying to find suppliers who supply no parts:
SELECT S.SNO, S.SNAME, S.STATUS, S.CITY
FROM S
WHERE NOT EXISTS
( SELECT SP.PNO
FROM SP
WHERE SP.PNO = S.SNO ) /* not OK */(There’s no terminating semicolon because this is an expression, not a statement. See Exercise 2-24 at the end of the chapter.)
As the comment says, this query is not OK. The reason is that, in the last line, the user presumably meant to say WHERE SP.SNO = S.SNO, but by mistake—probably just a slip of the typing fingers—he or she said WHERE SP.PNO = S.SNO instead. And, given that we’re indeed talking about a simple typo (probably), it would be a friendly act on the part of the DBMS to interrupt at this point, highlight the error, and ask if the user would like to correct it before proceeding.
Now, I don’t know any commercial product that actually behaves in the way I’ve just suggested; in today’s products, depending on how you’ve set up the database, either the query will simply fail or it’ll give the wrong answer. Well . . . not exactly the wrong answer, perhaps, but the right answer to the wrong question. (Does that make you feel any better?)
To repeat, therefore, the DBMS should reject a comparison like SP.PNO = S.SNO if it isn’t valid. Codd proposed, however, that there should be a way for the user to force the DBMS to go ahead and do the comparison anyway, even if it isn’t valid, on the grounds that sometimes the user will know more than the DBMS does. Now, it’s a little hard for me to do justice to this proposal, because I don’t agree with it—but let me try.
Suppose it’s your job to design a database involving, say, customers and suppliers, and you decide therefore to have a domain of customer numbers and another domain of supplier numbers. You build your database that way and load it, and everything works just fine for a year or two. Then, one day, one of your users comes along with a query you never heard before, namely: “Are any of our customers also suppliers to us?” Observe that this is a perfectly reasonable query; observe too that it might involve a comparison between a customer number and a supplier number (a cross-domain comparison), to see if they’re equal. And if it does, well, certainly the system mustn’t prevent you from doing it; certainly the system mustn’t prevent you from asking a reasonable query.
In light of the foregoing, Codd proposed what he called domain check override (DCO) versions of certain of his algebraic operators. A DCO version of join, for example, would perform the join even if the joining attributes were defined on different domains. In SQL terms, we might imagine this proposal being realized by means of a new clause, IGNORE DOMAIN CHECKS, that could be included in an SQL query, as here:
SELECT ...
FROM ...
WHERE CUSTNO = SNO
IGNORE DOMAIN CHECKSAnd this new clause would be separately authorizable—most users wouldn’t be allowed to use it at all; perhaps only the database administrator (DBA) would be allowed to use it.
Before analyzing the DCO idea in detail, I want to look at a simpler example. Consider the following two queries:
SELECT ... | SELECT ...
FROM P, SP | FROM P, SP
WHERE P.WEIGHT = SP.QTY | WHERE P.WEIGHT - SP.QTY = 0Assuming, reasonably enough, that weights and quantities are defined on different domains, the query on the left is clearly invalid. But what about the one on the right? According to Codd, that one’s valid! In his book The Relational Model for Database Management Version 2(Addison-Wesley, 1990), he says that in such a situation “the DBMS [merely] checks that the basic data types are the same”; in the case at hand, the “basic data types” are all numbers, loosely speaking, and so the check succeeds.
To me, this conclusion seems unreasonable. The semantics of an expression should not depend on the arbitrary choice of syntax we use to formulate it! Thus, I believe the expressions P.WEIGHT = SP.QTY and P.WEIGHT - SP.QTY = 0 must either both be valid or both be invalid; the suggestion that they have different semantics is unacceptable. So it seems to me there’s something strange about Codd-style domain checks in the first place, before we even get to “domain check override.” (In essence, in fact, Codd-style domain checks apply only in the very special case where both comparands are specified as relational attributes and not as anything else, such as an operational expression like P.WEIGHT - SP.QTY.)
Let’s look at some even simpler examples. Consider the following comparisons (each of which might appear as part of an SQL WHERE clause, for example):
S.SNO = 'X4' P.PNO = 'X4' S.SNO = P.PNO
I hope you agree that it’s at least possible that the first two are valid and the third not. But if so, then I hope you also agree there’s something strange going on; apparently, we can have three values a, b, and c such that a = c is true and b = c is true, but as for a = b . . . well, we can’t even do the comparison, let alone have it come out true! So what is going on?
I return now to the fact that attributes S.SNO and P.PNO are defined on domains SNO and PNO, respectively, and to my claim that domains are really types; in fact, I said in the introduction that domains SNO and PNO in particular were user-defined types. Now, it’s likely that both types are physically represented in terms of the built-in type CHAR—but physical representations are part of the implementation, not the model; they’re irrelevant to the user, and in fact they’re hidden from the user (or should be), as we saw in Chapter 1. In particular, the operators that apply to supplier numbers and part numbers are the operators defined in connection with those types, not the operators that happen to be defined in connection with type CHAR. For example, we can concatenate two character strings, but we probably can’t concatenate two supplier numbers (we could do this latter only if concatenation was an operator defined in connection with type SNO).
Now, when we define a type, one operator we must define is what’s called a selector operator, which allows us to select, or specify, an arbitrary value of the type in question.[*] The selector for type SNO, for example (which, as we’ll see in Chapter 6, will probably also be called SNO), allows us to select the particular SNO value that has some specified CHAR representation. Here’s an example:
SNO('S1')This expression is an invocation of the SNO selector, and it returns a certain supplier number: namely, the one that’s conceptually represented by the character string value ‘S1’. Likewise, the expression:
PNO('P1')is an invocation of the PNO selector, and it returns a certain part number: namely, the one that’s conceptually represented by the character string value ‘P1’. As you can see, therefore, the SNO and PNO selectors effectively work by converting a certain CHAR value to a certain SNO value and a certain PNO value, respectively.
Returning now to the comparison S.SNO = ‘X4’: What happens here is that the system notices that the left and right comparands are of different types (SNO and CHAR, to be specific). Since they’re of different types, they certainly can’t be equal. However, the system also knows there’s an operator—the SNO selector—that effectively performs CHAR-to-SNO conversions. So it can invoke that operator implicitly to convert the right comparand to a supplier number, thereby effectively replacing the original comparison with this one:
S.SNO = SNO('X4')Now we’re comparing two supplier numbers, which is legitimate.
In the same kind of way, the system effectively replaces the comparison P.PNO = ‘X4’ with this one:
P.PNO = PNO('X4')But in the case of the comparison S.SNO = P.PNO, there’s no conversion operator known to the system (at least, let’s assume not) that will convert a supplier number to a part number or the other way around, and so the comparison fails on a type error: the comparands are of different types, and there’s no way to make them be of the same type.
Terminology: Implicit conversion is often called coercion in the literature. In the first example, therefore, the character string ‘X4’ is coerced to type SNO; in the second it’s coerced to type PNO.
To continue with the example, another operator you must define when you define a type like SNO or PNO is what’s called, generically, a THE_ operator, which effectively converts a given SNO or PNO value to the character string (or whatever else it is) that’s used to represent it.[*] Assume for the sake of the example, not unreasonably, that the THE_ operators for types SNO and PNO are both called THE_CHAR. Then, if we really did want to compare S.SNO and P.PNO, the only sense I can make of that requirement is that we want to see if the character-string representations are the same, which we might do like this:
THE_CHAR ( S.SNO ) = THE_CHAR ( P.PNO )
In other words: convert the supplier number to a string, convert the part number to a string, and compare the two strings.
As I’m sure you can see, the mechanism I’ve sketched above effectively provides both (a) the domain checking we want, in the first place, and (b) a way of overriding that checking when we want, in the second place. Moreover, it does all this in a clean, fully orthogonal, non ad hoc manner. By contrast, “domain check override” doesn’t really do the job; in fact, it doesn’t really make sense at all, because it confuses types and representations (as noted previously, types are a model concept, representations are an implementation concept).
Now, you might have realized that what I’m really talking about is here is what’s known in language circles as strong typing . Different writers have slightly different definitions for this term, but basically it means that (a) everything—in particular, every value and every variable—has a type, and (b) whenever we try to perform some operation, the system checks that the operands are of the right types for the operation in question.[*] Observe too that this mechanism works for any operation, not just for the comparison operations we’ve been discussing; the emphasis on comparison operations in discussions of domain checking is sanctified by historical usage but is in fact misplaced. For example, consider the following expressions:
P.WEIGHT * SP.QTY
P.WEIGHT + SP.QTYThe first of these is probably valid (it yields another weight: namely, the total weight of the pertinent shipment). The second, by contrast, is probably not valid (what could it mean to add a weight and a quantity?).
Data Value Atomicity
I hope the previous section succeeded in convincing you that domains are indeed types, no more and no less. Now I want to turn to the issue of data value atomicity and the related notion of first normal form (1NF for short). In Chapter 1, I said that 1NF meant that every tuple in every relation contains just a single value (of the appropriate type, of course) in every attribute position—and it’s usual to add that those “single values” are supposed to be atomic. But this latter requirement raises the obvious question: what does it mean for data to be atomic?
Well, on page 6 of the book mentioned earlier, Codd defines atomic data as data that “cannot be decomposed into smaller pieces by the DBMS (excluding certain special functions).” But even if we ignore that parenthetical exclusion, this definition is a trifle puzzling, and not very precise. For example, what about character strings? Are character strings atomic? Every product I know provides several operators on such strings—LIKE, SUBSTR (substring), “||” (concatenate), and so on—that clearly rely on the fact that character strings in general can be decomposed by the DBMS. So are those strings atomic? What do you think?
Here are some other examples of values whose atomicity is at least open to question and yet we would certainly want to be able to include as attribute values in tuples in relations:
Integers, which might be regarded as being decomposable into their prime factors (I know this isn’t the kind of decomposability we usually consider in this context—I’m just trying to show that the notion of decomposability itself is open to a variety of interpretations)
Fixed-point numbers, which might be regarded as being decomposable into integer and fractional parts
Dates and times, which might be regarded as being decomposable into year/month/day and hour/minute second components, respectively
Now I’d like to move on to a potentially more startling example. Refer to Figure 2-1. Relation R1 in that figure is a reduced version of the shipments relation from our running example; it shows that certain suppliers supply certain parts, and it contains one tuple for each legitimate SNO-PNO combination. For the sake of the example, let’s agree that supplier numbers and part numbers are indeed “atomic”; then we can presumably agree that R1, at least, is in 1NF.

Now suppose we replace R1 by R2, which shows that certain suppliers supply certain groups of parts (attribute PNO in R2 is what some would call multivalued, and values of that attribute are groups of part numbers). Then most people would surely say that R2 is not in 1NF; in fact, it looks like an example of “repeating groups,” and repeating groups are the one thing that almost everybody agrees 1NF is supposed to prohibit (because such groups are obviously not atomic, right?).
Well, let’s assume for the sake of the argument that R2 isn’t in 1NF. But suppose we now replace R2 by R3. Then I claim that R3 is in 1NF! [*] For consider:
First, note that—of course deliberately—I’ve renamed the attribute PNO_SET, and I’ve shown the groups of part numbers that are PNO_SET values enclosed in set braces “{” and “}”, to emphasize the fact that each such group is indeed a single value: a set value, to be sure, but a set is still, at a certain level of abstraction, a single value.
Second (and regardless of what you might think of my first argument), the fact is that a set like {P2,P4,P5} is no more and no less decomposable by the DBMS than a character string is. Like character strings, sets do have some inner structure; as with character strings, however, it’s convenient to ignore that structure for certain purposes. In other words, if character strings are compatible with the requirements of 1NF—that is, if character strings are atomic—then sets must be, too.
The real point I’m getting at here is that the notion of atomicity has no absolute meaning;it just depends on what we want to do with the data. Sometimes we want to deal with an entire set of part numbers as a single thing, and sometimes we want to deal with individual part numbers within that set—but then we’re descending to a lower level of detail (a lower level of abstraction). The following analogy might help. In physics (which after all is where the terminology of atomicity comes from) the situation is exactly parallel: sometimes we want to think about individual physical atoms as indivisible things, and sometimes we want to think about the protons, neutrons, and electrons that go to make up those atoms. What’s more, protons and neutrons, at least, aren’t really indivisible, either—they contain a variety of “subsubatomic” particles called quarks. And so on, possibly.
Let’s return for a moment to relation R3. In Figure 2-1, I showed PNO_SET values as general sets. But it would be more useful in practice if they were, more specifically, relations (see Figure 2-2, where I’ve changed the attribute name to PNO_REL). Why would it be more useful? Because relations, not general sets, are what the relational model is all about.[*] As a consequence, the full power of the relational algebra immediately becomes available for the relations in question—they can be restricted, projected, joined, and so on. By contrast, if we use general sets instead of relations, then we need to introduce new operators (set union, set intersection, and so on) for dealing with those sets. Much better to get as much mileage as we can out of the operators we already have!
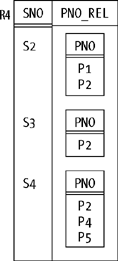
Attribute PNO_REL in Figure 2-2 is an example of a relation-valued attribute (RVA). Of course, the underlying domain is relation-valued too (that is, the values it’s made up of are relations). I’ll have more to say about RVAs in Chapters 5 and 7; here let me just note that SQL doesn’t support them. (More precisely, it doesn’t support what would be its analog of RVAs, table-valued columns—though oddly enough it does support both (a) columns whose values are arrays and (b) columns whose values are “multisets of rows.” A multiset , also known as a bag , is like a set except that it permits duplicates. Columns whose values are multisets of rows thus do look a bit like “table-valued columns” in some respects; however, they aren’t table-valued columns, because the values they contain can’t be operated upon by means of SQL’s regular table operators.)
Now, I chose the foregoing example deliberately, for its shock value. After all, relations with RVAs do look rather like relations with repeating groups, and you’ve probably always heard that repeating groups are a no-no in the relational world. But I could have used any number of different examples to make my point: I could have shown attributes (and therefore domains) that contained arrays; or bags; or lists; or photographs; or audio or video recordings; or X rays; or fingerprints; or XML documents; or any other kind of value, “atomic” or “nonatomic,” that you might care to think of. Attributes, and therefore domains, can contain anything (any values, that is). All of which goes a long way, incidentally, toward explaining why a true “object/relational" system would be nothing more nor less than a true relational system—which is to say, a system that supports the relational model, with all that such support entails. After all, the whole point of an “object/relational” system is precisely that we can have attribute values in relations that are of arbitrary complexity. Perhaps a better way to say it is this: a proper object/relational system is just a relational system with proper type support—which just means it’s a proper relational system, no more and no less.
So What’s a Type?
From this point forward I’ll switch to the term type in preference to domain. What is a type, exactly? In essence, it’s a named, finite set of value s[*]—all possible values of some specific kind: for example, all possible integers, or all possible character strings, or all possible supplier numbers, or all possible XML documents, or all possible relations with a certain heading (and so on). Moreover:
Every value is of some type—in fact, of exactly one type, except possibly if type inheritance is supported, a concept that’s beyond the scope of this book. Note, therefore, that types are disjoint or nonoverlapping. (To elaborate briefly: as one reviewer said, surely types WarmBloodedAnimal and FourLeggedAnimal overlap? Indeed they do; but what I’m saying is that if types overlap, then for a variety of reasons we’re getting into the realm of type inheritance—in fact, into multiple inheritance. Since those reasons, and indeed the whole topic of inheritance, are independent of the context we’re in, be it relational or something else, I’m not going to discuss them in this book.)
Every variable, every attribute, every operator that returns a result, and every parameter of every operator is declared to be of some type. And to say that (for example) variable V is declared to be of type T means, precisely, that every value v that can legally be assigned to V is itself of type T.
Every expression denotes some value and is therefore of some type: namely, the type of the value in question, which is to say the type of the value returned by the outermost operator in the expression (where by “outermost” I mean the operator that’s executed last). For example, the type of the expression (A+B)*(X-Y) is the declared type of the operator “*”, whatever that happens to be.
The fact that parameters in particular are declared to be of some type touches on an issue that I’ve mentioned but haven’t properly discussed yet: namely, the fact that every type has an associated set of operators for operating on values and variables of the type in question. For example, integers have the usual arithmetic operators; dates and times have special calendar arithmetic operators; XML documents have what are called “XPath” operators; relations have the operators of the relational algebra; and every type has the operators of assignment (“:=”) and equality comparison (“=”). Thus, any system that provides proper type support—and “proper type support” here certainly includes allowing users to define their own types—must provide a way for users to define their own operators, too, because types without operators are useless.
It’s important to understand also that values and variables of a given type can be operated upon solely by means of the operators defined for that type. For example, in the case of the system-defined type INTEGER:
The system provides an assignment operator “:=” for assigning integer values to integer variables.
It also provides comparison operators “=”, “<”, and so on, for comparing integer values.
It also provides arithmetic operators “+”, “*”, and so on, for performing arithmetic on integer values.
It does not provide string operators “||” (concatenate), SUBSTR (substring), and so on, for performing string operations on integer values; in other words, string operations on integer values are not supported.
By contrast, in the case of the user-defined type SNO, we would certainly define assignment and comparison operators (“:=”, “=”, “≠”, possibly “>”, and so on); however, we probably wouldn’t define operators “+”, “*”, and so on, which would mean that arithmetic on supplier numbers wouldn’t be supported (why would we ever want to add or multiply two supplier numbers?).
From everything I’ve said so far, then, it should be clear that defining a new type involves at least all of the following:
Specifying a name for that type (obviously enough).
Specifying the values that make up that type. I’ll discuss this aspect in more detail in Chapter 6.
Specifying the hidden physical representation for values of that type. As noted earlier, this is an implementation issue, not a model issue, and I won’t discuss it further in this book.
Specifying the operators that apply to values and variables of that type (see below).
For those operators that return a result, specifying the type of that result (again, see below).
Observe that points 4 and 5 taken together imply that the system knows precisely which expressions are legal, as well as the type of the result for each such legal expression.
By way of example, suppose we have a user-defined type POINT, representing geometric points in two-dimensional space. Here then is the Tutorial D definition[*] for an operator called REFLECT which, given a point P with cartesian coordinates (x,y), returns the “reflected” or “inverse” point with cartesian coordinates (-x,-y):
1 OPERATOR REFLECT ( P POINT ) RETURNS POINT ;
2 RETURN ( POINT ( - THE_X ( P ) , - THE_Y ( P ) ) ) ;
3 END OPERATOR ;Explanation:
Line 1 shows that the operator is called REFLECT, takes a single parameter P of type POINT, and returns a result also of type POINT (so the declared type of the operator is POINT).
Line 2 is the operator implementation code. It consists of a single RETURN statement. The value to be returned is, of course, a point, and it’s obtained by invoking the POINT selector operator; that invocation has two arguments, corresponding to the X and Y coordinates of the point in question. Each of those arguments involves a THE_ operator invocation; those invocations yield the X and Y coordinates of the point argument corresponding to parameter P, and negating those coordinates leads us to the desired result.
Line 3 marks the end of the definition.
Now, for the most part, I’ve been talking so far about user-defined types specifically. For a system-defined or built-in type, similar considerations apply, of course, but in this case the definitions are furnished by the system instead of by some user. For example, if INTEGER is a built-in type, then it’s the system that defines the name, specifies legal integers, defines the hidden representation, and defines the corresponding operators. Of course, to someone who merely makes use of some user-defined type that’s been defined by somebody else, that type looks just like a system-defined type anyway; indeed, in many ways that’s the whole object of the exercise.
I don’t propose to go into much more detail regarding type and operator definitions, because they aren’t specifically relational topics, for the most part.
Scalar Versus Nonscalar Types
It’s usual to think of types as being either scalar or nonscalar. Loosely, a type is scalar if it has no user-visible components and nonscalar otherwise—and the values, variables, attributes, operators, parameters, and expressions of some type T are scalar or nonscalar according as type T itself is scalar or nonscalar. For example:
Type INTEGER is a scalar type; hence, values, variables, and so on of type INTEGER are also all scalar, meaning they have no user-visible components.
Tuple and relation types are nonscalar—the pertinent user-visible components being, of course, the corresponding attributes—and hence tuple and relation values, variables, and so on are also all nonscalar.
That said, I must now stress the point that these notions are quite informal. Indeed, we’ve already seen that the concept of atomicity has no absolute meaning, and “scalarness” is just the concept of atomicity by another name. Thus, the relational model nowhere formally relies on the scalar versus nonscalar distinction. In this book, however, I do rely on it informally; to be specific, I use the term scalar in connection with types that are neither tuple nor relation types, and the term nonscalar in connection with types that are either tuple or relation types.
Let’s look at an example. Here’s a Tutorial D definition for the base relvar S (suppliers):
1 VAR S BASE
2 RELATION { SNO SNO, SNAME NAME, STATUS INTEGER, CITY CHAR }
3 KEY { SNO } ;Explanation:
The keyword VAR in line 1 means this is a variable definition; the keyword BASE means the variable is a base relvar specifically.
Line 2 specifies the type of this variable. The keyword RELATION shows it’s a relation type; the rest of the line specifies the set of attributes that make up the corresponding heading (where, as you’ll recall from Chapter 1, an attribute is an attribute-name:type-name pair). The type is, of course, a nonscalar type. No significance attaches to the order in which the attributes are specified.
Line 3 defines {SNO} to be a candidate key for this relvar.
In fact, the example also illustrates another point—namely, that the type:
RELATION { SNO SNO, SNAME NAME, STATUS INTEGER, CITY CHAR }is an example of a generated type. In general, a generated type is one that’s obtained by invoking some type generator (in the example, the type generator is RELATION). You can think of a type generator as a special kind of operator; it’s special because (a) it returns a type instead of (for example) a scalar value, and (b) it’s invoked at compile time instead of run time. For instance, most programming languages support a type generator called ARRAY, which lets users define a variety of specific array types. For the purposes of this book, however, the only type generators we need to consider are TUPLE and, of course, RELATION. Here’s an example involving the TUPLE type generator:
VAR SINGLE_SUPPLIER
TUPLE { STATUS INTEGER, SNO SNO, CITY CHAR, SNAME NAME } ;The value of variable SINGLE_SUPPLIER at any given time is a tuple with the same heading as that of relvar S. (I’ve specified the attributes in a different sequence deliberately, just to show that the sequence doesn’t matter.) Thus, we might imagine a code fragment that, first, extracts a one-tuple relation (perhaps the relation containing just the tuple for supplier S1) from the current value of relvar S; then extracts the single tuple from that one-tuple relation; and, finally, assigns that tuple to the variable SINGLE_SUPPLIER. In Tutorial D:
SINGLE_SUPPLIER := TUPLE FROM ( S WHERE SNO = SNO('S1') ) ;By the way, note carefully that a tuple t and a relation r that contains just that tuple t aren’t the same thing. In particular, they’re of different types—t is of some tuple type and r is of some relation type (though of course they do have the same heading).
Note
I don’t want you to misunderstand me here. While a variable like SINGLE_SUPPLIER might well be needed in some application program that accesses the suppliers-and-parts database, I’m not saying that such a variable can appear inside the database itself. A relational database contains variables of exactly one kind—namely, relation variables (relvars); that is, relvars are the only kind of variable allowed in a relational database. I’ll revisit this point in Chapter 8, in connection with what’s called The Information Principle.
There’s just one more thing I want to say about tuple and relation types: even though such types do obviously have user-visible components (namely, their attributes), there’s no suggestion that those components have to be physically stored as such. In fact, the physical representation of values of such types should be hidden from the user, just as it is for scalar types.
Summary
It’s a very common misconception that the relational model deals only with rather simple types: numbers, strings, perhaps dates and times, and not much else. In this chapter, I’ve tried to show that this is indeed a misconception. Rather, relations can have attributes of any type whatsoever—the relational model nowhere prescribes what those types must be, and in fact they can be as complex as we like (except as noted in just a moment). In other words, the question as to what types are supported is orthogonal to the question of support for the relational model itself. Or (less precisely but more catchily): types are orthogonal to tables.
I also remind you that the foregoing state of affairs in no way violates the requirements of first normal form. First normal form just means that every tuple in every relation contains a single value, of the appropriate type, in every attribute position. Now that we know those types can be anything, we also know that all relations are in first normal form by definition.
Finally, I mentioned in the introduction to this chapter that there are certain important exceptions to the rule that relational attributes can be of any type whatsoever. In fact, there are two. The first—which I’ll simplify just slightly for present purposes—is that if relation r is of type T, then no attribute of r can itself be of type T (think about it!). The second is that no relation in the database can have an attribute of any pointer type. As you probably know, prerelational databases were full of pointers, and access to such databases involved a lot of pointer-chasing: a fact that made application programming error-prone and direct end-user access impossible. Codd wanted to get away from such problems in his relational model, and of course he succeeded.
Exercises
Exercise 2-1
What’s a type? What’s the difference between a domain and a type?
Exercise 2-2
What do you understand by the term selector?
Exercise 2-3
What’s a THE_ operator?
Exercise 2-4
Physical representations are always hidden from the user: true or false?
Exercise 2-5
Elaborate on the following: argument versus parameter; database versus DBMS; generated type versus nongenerated type; scalar versus nonscalar; type versus representation; user-defined type versus system-defined type; user-defined operator versus system-defined operator.
Exercise 2-6
What do you understand by the term coercion? Why is coercion a bad idea?
Exercise 2-7
Why doesn’t “domain check override” make sense?
Exercise 2-8
What’s a type generator?
Exercise 2-9
Define first normal form.
Exercise 2-10
Let X be an expression. What’s the type of X? What’s the significance of the fact that X is of some type?
Exercise 2-11
Using the definition of the REFLECT operator in the body of the chapter as a pattern, define a Tutorial D operator that, given an integer, returns the cube of that integer.
Exercise 2-12
Use Tutorial D to define an operator that, given a point with cartesian coordinates x and y, returns the point with cartesian coordinates f(x) and g(y), where f and g are predefined operators.
Exercise 2-13
Give an example of a relation type. Distinguish between relation types, relation values, and relation variables.
Exercise 2-14
Use SQL or Tutorial D (or both) to define relvars P and SP from the suppliers-and-parts database. If you give both SQL and Tutorial D definitions, identify as many differences between them as you can. What’s the significance of the fact that relvar P (for example) is of a certain relation type?
Exercise 2-15
Given the types specified in the introductory section for attributes in the suppliers-and-parts database, which of the following scalar expressions are valid? For those that are, state the type of the result; for the others, show an expression that will achieve what appears to be the desired effect.
a. CITY = 'London' b. SNAME || PNAME c. QTY * 100 d. QTY + 100 e. STATUS + 5 f. 'ABC' < CITY g. COLOR = CITY h. CITY || 'burg'
Exercise 2-16
It’s sometimes suggested that types are really variables, in a sense. For example, employee numbers might grow from three digits to four as a business expands, so we might need to update “the set of all possible employee numbers.” Discuss.
Exercise 2-17
A type is a set of values, and the empty set is a legitimate set; thus, we might define an empty type to be a type where the set in question is empty. Can you think of any uses for such a type?
Exercise 2-18
In the body of the chapter, I said the equality comparison operator “=” applies to every type (though I didn’t spell out the semantics, which are that if v1 and v2 are values of the same type, then v1 = v2 evaluates to TRUE if and only if v1 and v2 are the very same value). As explained in more detail in Chapter 8, however, SQL doesn’t require “=” to apply to every type, nor does it prescribe the semantics in all of the cases where it does apply. What are the implications of this state of affairs?
Exercise 2-19
Following on from the previous exercise, we can say that v1 = v2 evaluates to TRUE if and only if executing some operator Op on v1 and executing that same operator Op on v2 always has exactly the same effect, for all possible operators Op. But this is another precept that SQL violates. Can you think of any examples of such violation? What are the implications?
Exercise 2-20
Why are pointers excluded from the relational model?
Exercise 2-21
The Assignment Principle—which is very simple, but fundamental—states that after assignment of the value v to the variable V, the comparison V = v evaluates to TRUE. Yet again, however, this is a precept that SQL violates (fairly ubiquitously, in fact). Can you think of any examples of such violation? What are the implications?
Exercise 2-22
Do you think that types “belong to” databases, in the same sense that relvars do?
Exercise 2-23
In the section “Domain-Constrained Comparisons,” I showed an SQL SELECT - FROM - WHERE expression that contained another such expression nested inside it (a “subquery”). Now, each of the SELECT clauses in the overall expression could have been replaced by the arguably simpler form SELECT* (“SELECT star”). But “SELECT *” suffers from certain problems, which is why I usually—not invariably—avoid using it in this book. Identify as many of those problems as you can. Can you think of any other constructs in SQL that suffer from similar problems?
Exercise 2-24
In the first example of an SQL SELECT expression in this chapter, I pointed out that there was no terminating semicolon because the SELECT expression was an expression and not a statement. But what’s the difference?
[*] SQL does have a varying-length character-string type, called VARCHAR, but even there a maximum length has to be specified.
[*] By the way, what’s the difference between a DBMS and a database? (This isn’t an idle question, because the industry very commonly uses the term database when it means either some DBMS product, such as Oracle, or the particular copy of such a product that happens to be installed on a particular computer. The problem is, if you call the DBMS a database, what do you call the database?)
[*] This observation is valid regardless of whether we’re in an SQL context (as in the present discussion) or otherwise. I omit the details of what’s involved in defining selectors in SQL, since they’re a little messy—but I’ll assume, here and throughout this book, that such operators have indeed been defined.
[*] Again this observation is valid regardless of whether we’re in an SQL context or some other context, though SQL doesn’t use the terminology of “THE_ operators” as such. (Actually, it doesn’t use the terminology of “selectors” either.)
[*] Or, possibly, are coercible to those right types. For reasons not directly connected with the current topic, however, I would argue that all type conversions should be explicit. Coercions are a well-known source of error.
[*] I don’t claim it’s well designed—indeed, it probably isn’t—but that’s a separate issue. I’m concerned here with what’s legal, not with questions of good design. The design of R3 is legal.
[*] In case you’re wondering, the crucial difference is that general sets can contain anything, whereas relations contain tuples specifically. Note, however, that a relation certainly resembles a general set in that it too can be regarded as a single value.
[*] Finite because we’re dealing with computers, which are finite by definition. Also, note that qualifier named; types with different names are different types.
[*] I could have used SQL, but operator definitions in SQL involve a number of details that I don’t want to get into here.