
2
Classification modeling methodology
2.1 An overview of the methodology for classification modeling
In this chapter, we present the methodological steps for classification modeling. Classification modeling is a form of supervised modeling in which the analytical task is to classify new instances in known classes. Historical data are used for model training. Classified cases are presented to the model which analyzes the data patterns and the associations of the input attributes (predictors) with the observed outcome. When the model is applied to new, unseen (unlabeled) cases, it assigns them to a class based on the predictors’ values and the identified data patterns associated with each class. Along with the class prediction, the model also estimates prediction confidence which denotes the likelihood of prediction. Many marketing applications can be “translated” to classification problems and be tackled with classification modeling, including optimization of targeted marketing campaigns for acquiring new customers, cross-/up-/deep-selling, and attrition prevention. Since the scope of this book is to be used as a guide for real analytical applications in marketing, in this chapter, we try to go beyond a generic presentation of the classification methodology. Therefore, we dedicate a large part of this chapter in explaining how classification modeling can be applied to support and optimize specific marketing applications in all major industries.
The following are the five main steps of the classification modeling procedure, in accordance with the main CRISP-DM phases presented in Section 1.2:
- Understand and design
- Explore, prepare, and enrich the data
- Build model(s)
- Evaluate model(s)
- Deploy to new cases
The first task is to understand the marketing needs and objectives and design the appropriate mining process. Then, the data should be understood, transformed, and enriched with informative predictors which could boost the predictive accuracy of the model. After data are appropriately prepared, the classification model is build and evaluated before being used for scoring new, unlabeled instances. The close collaboration of analysts and marketers in all these phases is required for the success of the project since the analytical skills and capabilities should be guided by in-depth domain knowledge. The classification methodology steps are presented in a more refined way in Table 2.1, and they are thoroughly explained in the next paragraphs.
Table 2.1 The classification methodology
| I. Business understanding and design of the process | II. Data understanding, preparation, and enrichment | III. Classification modeling | IV. Model evaluation | V. Model deployment |
| I.1. Understanding of the business situation: definition of the business objective | II.1. Investigation of data sources | III.1. Trying different models and parameter settings | IV.1. Thorough evaluation of the model accuracy | V.1. Scoring customers to roll the marketing campaign |
| I.2. Definition of the mining approach and of the data model | II.2. Selecting the data sources to be used | III.2. Combing models: ensemble/Boosting/Bagging/Random forests | IV.1.1. Confusion matrix and accuracy measures | V.1.1. Building propensity segments |
| I.3. Design of the modeling process | II.3. Data integration and aggregation | III.3. Proceed to a first rough evaluation of the models | IV.1.2. Gains/Response/Lift charts | V.2. Designing a deployment procedure and disseminating the results |
| I.3.1. Definition of the modeling population | II.4. Data exploration, validation, and cleaning | IV.1.3. ROC curves | ||
| I.3.2. Determining the modeling level (analysis level) | II.5. Data transformations and enrichment | IV.1.4. Profit/ROI charts | ||
| I.3.3. Definition of the target event and populationI.3.4. Deciding on time frames | II.6. Applying a validation techniqueII.7. Dealing with imbalanced outcomes | IV.2. Evaluating a deployed model: test/control groups |
2.2 Business understanding and design of the process
In the first phase of the project, the business need should be understood and translated into a tangible data mining goal. More specifically, the tasks typically carried out in this phase include the following.
2.2.1 Definition of the business objective
| I. Business understanding and design of the process | I.1. Understanding of the business situation: definition of the business objective |
Before designing the data mining approach, the business situation should be understood, and the marketing goal should be defined. In this preliminary step of the process, the project team of marketers and data miners, through a series of meetings and in-depth discussions, should share their business and technical knowledge and achieve thorough understanding of the current business situation, including solutions in place, available data resources, and possible limitations.
In this phase, the business objective should also be defined. In many situations, the analysts may face very ambitious and/or vague business objectives set by the marketers of the organization who may regard data mining as the silver bullet to magically eliminate all their problems at once. Therefore, in order to avoid overexpectations, it is important for the analysts to clearly define the business questions to be addressed by the subsequent mining models, translate the marketing problem to data mining tasks, and communicate right from the start what can be achieved by data mining.
Apart from setting expectations and defining the business and the corresponding data mining objective, in this phase, the project team should also be appointed with a clear task assignment and a plan for coworking. Finally, the expected data mining deliverables should be made clear from the start to everyone involved as well as the method for measuring the success of the project and the success criteria.
2.2.2 Definition of the mining approach and of the data model
| I. Business understanding and design of the process | I.2. Definition of the mining approach and of the data model |
The marketing application and the business target call for a certain mining approach and a corresponding data model. However, there are different mining approaches applicable for the same marketing application, and the project team has to decide on the one to be used according to the business situation, the priorities, and the available resources.
Although the appropriate mining approaches for targeted marketing campaigns (customer acquisition, cross-/up-/deep-selling, and customer churn) are presented in detail and with examples by industry later in this chapter, we briefly introduce the main concepts here to outline the significance of this step which defines the entire project.
Consider, for example, an organization that wants to promote a specific product to existing customers. It plans to carry out a cross-selling campaign to stimulate customers to uptake this product and decides to rely on data mining models to target the campaign. The thing is that there are numerous different classification mining approaches for the specific marketing objective, all with their pros and cons. For instance, an approach could be to run a test campaign on a sample of customers. Then, “go after” actual responders, analyze their defining characteristics, and try to identify customers with the same profile among the entire customer base. This “pilot campaign” approach, although highly effective since it simulates the exact planned customer interaction, is time consuming and requires resources for the test campaign. An alternative mining approach could be to consider as the target population those customers who purchased the product of interest in the near past, the so-called “product uptake” approach. Instead, due to the difficulties of the aforementioned approaches, the organization may decide to simply build a profile of the customers who currently own the product of interest and then identify their “clones” among those customers who don’t have the product. This “product possession” approach seems attractive due to its simplicity. However, its effectiveness is limited since the respective models are analyzing data patterns and behaviors that may be the result and not the “cause” of the event of interest.
Each of the aforementioned mining approaches requires different data sources and data setup. They define from the start the entire procedure and the data model of the project, hence deciding which one to follow is critical.
The mining approaches for classification in support of targeted marketing campaigns can be grouped according to the need of historical data. Although more complicated, the ones using an observation and a different outcome period tend to stand out in terms of validity and predictive ability compared to the simple profiling approaches. Another group of effective, yet demanding in terms of resources, mining setups includes the ones that are based on pilot campaigns or other interactions with the customers, for instance, a communication for information request.
2.2.3 Design of the modeling process
| I. Business understanding and design of the process | I.3. Design of the modeling process |
After selecting the appropriate mining approach, the next step is the design of the modeling process. Having discussed and understood the specific business situation and goal, a number of key decisions should be made concerning:
- The modeling population
- The modeling/analysis level
- The target event and population
- The attributes to be used as predictors
- The modeling time frames
All these substeps are presented in detail in the following paragraphs.
2.2.3.1 Defining the modeling population
| I.3 Design of the modeling process | I.3.1. Definition of the modeling population |
The modeling population is comprised of the instances (customers) to be used for model training. Since the goal is to build a classification model for a targeted marketing campaign, the modeling population also corresponds to the customers who’ll be reached by the marketing action. The decision on who to include should be made with the final goal in mind. Thus, the question that mainly determines the modeling population is “how results will be used.” For instance, which customers do we want to contact to promote a product, or which customers do we want to prevent from leaving? Do we want to reach all customers or only customers of a specific group? For a voluntary churn prevention campaign, for example, we should decide if we want the model and the campaign to cover the entire customer base or just the group of valuable customers.
Usually, not-typical customers such as staff members of VIP customers should be identified and excluded from both the training and the scoring processes.
Quite often, the modeling population is based on the organization’s core segments. In retail banking, for example, customers are typically grouped in segments like affluent, mass, and inactive according to their balances, product ownership, and total number of transactions. These segments contain customers of different characteristics and are usually managed by different marketing teams or even departments. For operational as well as analytical reasons, a cross-segment classification model and marketing campaign would be unusual and probably ineffective. On the other hand, a separate approach and the development of distinct models for each segment may enhance the classification accuracy and the campaign’s effect.
Sometimes, it is worthwhile to go beyond the core business segments and build separate models for subsegments identified by cluster analysis. The cluster model in this approach is a preparatory step which can identify customer groups with different characteristics. The training of separate models for each cluster is an extra workload but might also significantly improve the performance of subsequent classification models due to the similar profiles of the analyzed instances.
In churn modeling, the “customer” status is taken into account (active, inactive, dormant) in the definition of the modeling population. A churn model is usually trained on cases that were active at the end of the observation period. These cases comprise the training population, and their behavior in the outcome period, after the observation period, is examined to define the target event.
In cross-selling, the modeling population is typically defined based on the ownership of products/services. According to the “product uptake” mining approach presented in Section 2.9.1.2, the cross-selling modeling population typically includes all customers not in possession of a product in the observation period who purchased or not the product in the outcome period that followed.
2.2.3.2 Determining the modeling (analysis) level
| I.3. Design of the modeling process | I.3.2. Determining the modeling level |
A decision tightly connected with the selection of the modeling population is the one concerning the level of the model. Apart from deciding whom to analyze, the project team should also agree on the appropriate analysis level which in turn defines the aggregation level and granularity of the modeling file—in plain words, what each record of the modeling file summarizes: customers, accounts, contracts, telephone lines, etc.
Once again, this choice depends on the type of the subsequent marketing campaign. Typically, a customer has a composite relationship with an organization, owning, for instance, more than one credit cards or telephone lines or insurance contracts. The modeling level depends on the specific campaign’s objective. For instance, if the plan is to target customers taking into account their entire relationship with the bank instead of cardholders of individual cards, then a customer-level approach should be followed.
Obviously, the selected modeling level and population delineate the form of the final modeling file and the relevant data preparation procedures that have to be carried out. For a customer-level campaign, all collected data, even if initially retrieved at lower levels, should be aggregated at the desired level for model training and scoring. Original information should be transformed at the granularity level necessary for answering the business question and addressing the specific business objective.
2.2.3.3 Definition of the target event and population
| I.3. Design of the modeling process | I.3.3. Definition of the target event and population |
In classification modeling, the task is to assign new cases to known classes by using a model which had been trained on preclassified cases. The goal is to predict an event with known outcomes. Hence, in the design of the modeling process, it is necessary to define the target event and its outcomes in terms of available data—in other words, to reach a decision about the target, also known as the output or label or class attribute of the subsequent model. As explained in Chapter 2, the target attribute in classification modeling is a categorical/symbolic field recording class membership.
Although still at an early stage of the process, it is necessary to outline the target event to be predicted. Obviously, this selection should be made in close cooperation with the marketers of the organization that might already have their definitions for relative processes.
The target population includes the instances belonging to the target event outcome, the target class. These instances are typically the customers we are trying to identify since they belong in the class of special interest. Most of the times, the model’s target attribute is a flag (dichotomous or binary) field denoting membership (Yes/No or True/False) into the target population. In a churn model, for example, the target population is consisted of those that have voluntary churned within the event outcome period, as opposed to those who stayed loyal. In a cross-selling model, those that purchased a product or responded in a promotional campaign comprise the target population.
The definition of the target event should take into account the available data. The analysts involved should also ensure that the designed data model will allow the construction of the target field.
Although a disconnection event might be an obvious and well-defined target for most churn applications, in some cases, it is not applicable. In the case of prepaid customers in mobile telephony, for example, there isn’t a recorded disconnection event to be modeled. The separation between active and churned customers is not evident. In such cases, a target event could be defined in terms of specific customer behavior. This handling requires careful data exploration and cooperation between the data miners and the marketers. For instance, prepaid customers with no incoming or outgoing phone usage within a certain time period could be considered as churners. In a similar manner, certain behaviors or changes in behavior, for instance, substantial decrease in usage or a long period of inactivity, could be identified as signals of specific events and then be used for the definition of the respective target.
Moreover, the same approach could also be followed when analysts want to act proactively. For instance, even when a churn/disconnection event could be directly identified through a customer’s action, a proactive approach would be to analyze model behaviors before the typical attrition by identifying early signals of defection and not waiting for the official termination of the relationship with the customer.
When using behavioral information to build the target event, it is crucial to analyze relevant data and come up with a stable definition. For instance, preliminary analysis and descriptive statistics might reveal the inactivity time period which signifies permanent churn and trivial chances of “revival.” A simple graph will most probably show that the percentage of returning customers becomes insignificant after a specific number of inactivity months. This information can reveal the appropriate time window for defining a stable, behavioral churn event.
2.2.3.4 Deciding on time frames
| I.3. Design of the modeling process | I.3.4. Deciding on time frames |
Most classification models make use of historical, past data. Customer profiles are examined in the observation period before the occurrence of the target event, and input data patterns are associated with the event which follows, whether purchase of an add-on product or churn.
This approach requires the examination of the customer view in different points in time. Therefore, the analyzed data should cover different time frames. The time frame refers to the time period summarized by the relevant attributes. The general strategy is to have at least two distinct time frames. The first time frame, the observation window (also known as the historical period), is a past snapshot of the customer, used for constructing predictors which summarize the customer profile before the event occurrence. The second time frame, referred as event outcome period, is used for recording the event outcome and building the target attribute. Typically, an additional time period, in between the observation and the event outcome period, is taken into account, corresponding to the time needed to gather the data, prepare the model, score new cases, and roll out the targeted marketing campaign. Apparently, this approach requires that predictors should come from a time frame preceding the one used for examining the target event.
Let’s consider, for example, a typical classification model trained on historical data. The data setup is presented in Figure 2.1.

Figure 2.1 The data setup and time frames in a classification model trained on historical data.
Source: Tsiptsis and Chorianopoulos (2009). Reproduced with permission from Wiley
The respective time frames are:
- Observation (historical) period: Used for building the customer view in a past time period, before the occurrence of the target event. It refers to the distant past, and corresponds to the time frame used for building the model inputs (predictors).
- Latency period: It refers to the gap between the observation and the event outcome period, reserved for taking into account the time needed to collect all necessary information, score new cases, predict class assignment, and execute the relevant campaign. A latency period also ensures that the model is not trained to identify “immediate” event occurrence, for instance, immediate churners. Even if we manage to identify those customers, chances are that by the time they are contacted, they could already be gone or it will be too late to change their minds. The goal of the model should be long term: the recognition of early churn signals and the identification of customers with increased likelihood to churn in the near but not in the immediate future, since for them there is a chance of retention.
- Event outcome period: Used for recording the target event and the class assignment. It follows the observation and the latency period, and it is only used for defining the target (output) attribute of the classification model. Predictors should not extend in this time period.
The model is trained by associating input data patterns of the observation period with the event outcomes recorded in the event outcome period.
Typically, in the validation phase, the model’s classification accuracy is evaluated in disjoint time periods. Yet again, the observation period, used for constructing predictors, should precede the event outcome period. In the deployment phase, the generated model scores new cases according to their present view. Now, the observation period covers the period right before the present, and the event outcome period corresponds to the future. The event outcome is unknown and its future value is predicted.
A more specific example of a voluntary churn model setup is illustrated in Figure 2.2.

Figure 2.2 The data setup and time frames in a churn model.
Source: Tsiptsis and Chorianopoulos (2009). Reproduced with permission from Wiley
In this example, the goal of a mobile telephony network operator is to set up a model for the early identification of potential voluntary churners. This model will be the base for a respective targeted retention campaign and predicts voluntary attrition 1 month ahead. We assume that the model is built in October:
- The model is trained on a 6-month observation window covering January to June. The inputs summarize all the aspects of the customer relationship with the organization in that period providing an integrated customer view also referred to as the customer signature. Yet, they come strictly from the historical period, and they do not overlap with the target event which is defined in the outcome period.
- The model is trained on customers that were active at the end of the observation window (end of the 6-month historical period). These customers comprise the modeling population.
- 1 month has been reserved in order to allow for scoring and campaign preparation. This month is shown as a grayed box in the respective illustrations and it corresponds to the latency period. No inputs were used from the latency period (July).
- The target event is attrition, recorded as application for disconnection in the event outcome period, that is, within August.
- The target population is consisted of those that have voluntary churned in August.
- The model is trained by identifying the input data patterns associated with voluntary churn.
- The generated model is validated on a disjoint data set of a different time period, before being deployed for classifying currently active customers.
- In the deployment phase, customers active in September, are scored according to the model. Remember that the model is built in October which is the current month.
- The profile of customers is built using information from the 6 most recent months, from April to September. The model predicts who will leave in November. If October churners become known in the meantime, they are filtered-out from the target list before the execution of the campaign.
- The presented time frames used in this example are purely indicative. A different time frame for the observation or the latency period could be used according to the specific task and business situation.
The length of the observation window should be long enough to capture and represent a stable customer profile as well as seasonal variations. However, it should not be extended that much to also capture outdated behaviors. Typically a time span of 12–24 months, depending on the specificities of the organization, is adequate.
For the length of the event outcome period, we should consider a possible periodicity of the target event as well as the size of the target population. Apparently, for a target event with seasonal patterns, this seasonality should be taken into account when selecting the event outcome period. In terms of the size of the target population, ideally, we’d prefer to have at least some hundreds of customers for model training. This might not be the case if the target event is rare. Although there are methods for boosting the number of target population cases and they are discussed later in this chapter, sometimes we can capture more positive cases by simply extending the time span of the event outcome period obviously at a cost of using and analyzing more data.
An advisable approach for training a classification model is to incorporate multiple time windows. With this approach, we can capture a more extended view of customer behaviors. Furthermore, we can also capture possible seasonal effects, avoiding the pitfall of using data from a particular season to train the model.
In the setup illustrated in Figure 2.3, 18 months of history are analyzed with three overlapping observation windows. In each setup, 6 months of historical data are used to predict churn 1 month ahead, and a single month is reserved as the latency period.
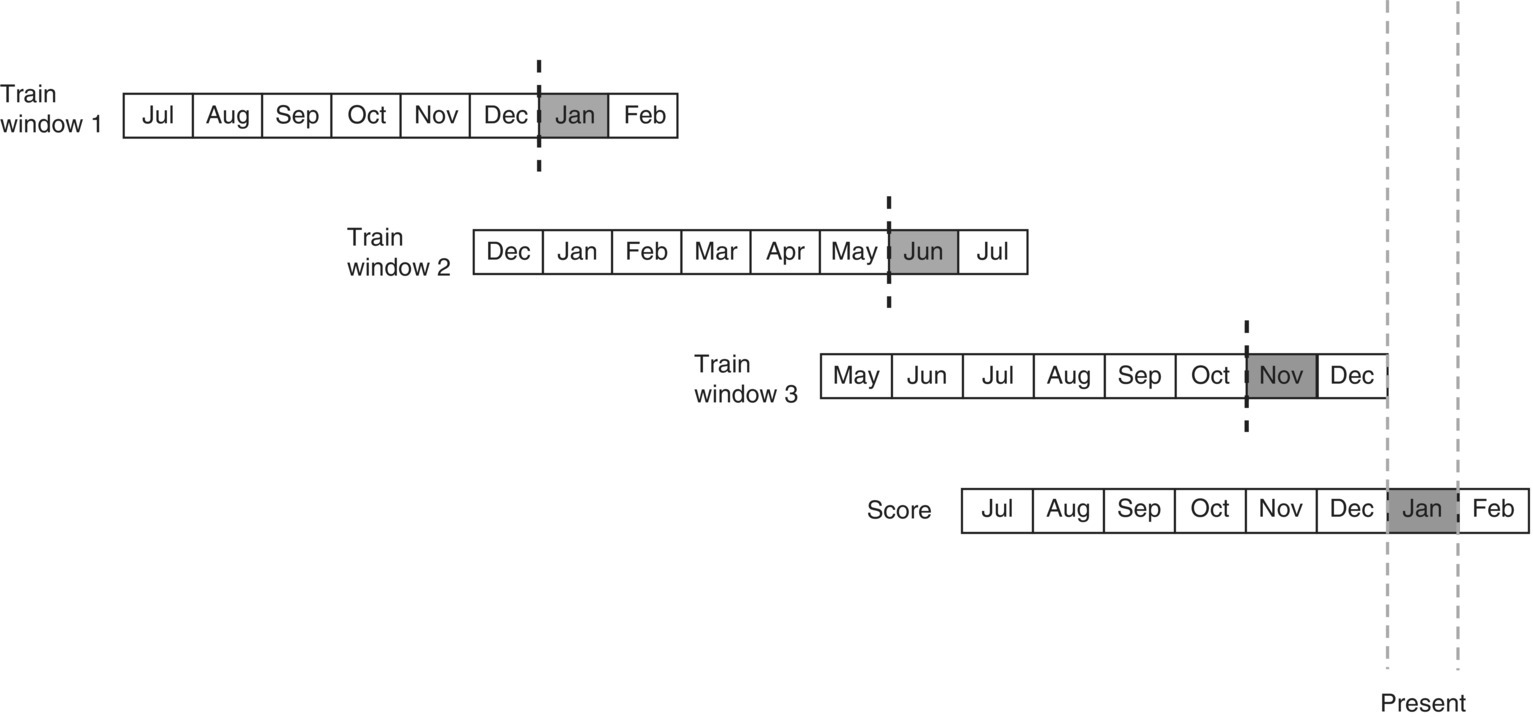
Figure 2.3 Using multiple time frames in model training
In the first time window, input data patterns recorded in past year’s July to December are used to predict February churners. The second time window is shifted 5 months ahead. This time, the customer profiles are based on the period from December to May, and the target population includes July’s churners. Finally, December’s churners are predicted from historical data covering May to October. With this approach, available data are partitioned to build the three data setups allowing a broader capturing of behaviors. The patterns captured by the model do not reflect a single period. Moreover, this approach increases the number of cases in the model set and the frequency of the target population, a desirable result, especially in the case of limited training instances.
2.3 Data understanding, preparation, and enrichment
The second phase of the classification project covers the demanding and time-consuming phase of data preparation which, is critical for the success of the application. By data preparation, we refer to all the tasks necessary for transforming raw data to attributes ready to be included as inputs or output in the subsequent classification model.
These tasks include:
- Evaluating exiting sources of data for inclusion in the process
- Merging data from different sources
- Aggregating data to the appropriate modeling level
- Exploring and validating data
- Enriching existing attributes with informative indicators
- Reducing data dimensionality by retaining only informative predictors
- Incorporating a data validation procedure to avoid an overoptimistic evaluation of the accuracy of the classification model
- Tackling class imbalances
In classification modeling, all pieces of information outlining customer profiles are used to predict the target attribute. The final modeling file has the form of a one-dimensional flat table with a set of attributes, as inputs and a single target output. But preparing the modeling file might prove a heavy burden, especially when starting from raw data. This is where the mining datamart, described in Section 1.4.1, comes in. Having in place a mining datamart facilitates the data preparation procedure. However, each classification project has its particularities, calling for special data handling.
2.3.1 Investigation of data sources
| II. Data understanding, preparation, and enrichment | II.1. Investigation of data sources |
The prior action of data preparation is the investigation of available data sources in order to select the ones relevant to the project’s scope. All data sources, even those not covered in the mining datamart, should be considered as candidates for inclusion. Data understanding should be followed by an initial, rough exploration of data in terms of availability, quality, and usefulness for the specific project.
2.3.2 Selecting the data sources to be used
| II. Data understanding, preparation, and enrichment | II.2. Selecting the data sources to be used |
A good classification model is trained on attributes providing a complete view of the customer. The retrieved data should adequately and thoroughly summarize all relevant aspects of the relationship of the customer with the organization. In brief, all essential resources should be lined up from all sources and systems. All information that could contribute in enriching what we know about the customers and enhance the predictive ability of the model, whether residing in the mining datamart, stored in the organization’s data warehouse, collected from market research surveys, or logged from web visits, should be retrieved and prepared for analysis.
2.3.3 Data integration and aggregation
| II. Data understanding, preparation, and enrichment | II.3. Data integration and aggregation |
Required data, usually residing at different locations or even systems, should be brought together and be integrated to form the modeling file. For instance, for the needs of the cross-selling model of the retail case study presented in Chapter 7, two types of data were used. Transactional data were used to summarize customer purchase behaviors as well as customer demographics. Purchase data were collected at point of sales (POS), and they were used to summarize customer spending habits. Customer information on the other hand was recorded upon registration of a customer at the loyalty program of the retailer. When combined, the aforementioned data sources provided an integrated view of the customer. Since information from both sources is critical for training the model, the first data preparation task was their consolidation to a single modeling file.
Additionally, input data should be transformed at the selected modeling level. This typically requires the aggregation of the original inputs into the appropriate granularity. By aggregation, multiple detailed data records are replaced with summarized records. Returning to the retail cross-selling example of Chapter 7, the business objective was to identify customers with increased probability to uptake an add-on product. The final modeling file should be at the customer level. However, purchase data were at a transactional level. Each original POS data record corresponded to a purchased item with information regarding price of the item, day/time, and location of purchase. Therefore, transactional records had to be grouped by customer to designate customer purchase patterns. Besides merging and aggregating data, the data preparation phase also involves the creation of informative KPIs from the original attributes.
2.3.4 Data exploration, validation, and cleaning
| II. Data understanding, preparation, and enrichment | II.4. Data exploration, validation, and cleaning |
After all relevant data are consolidated into the modeling file, it is time for exploring and inspecting the retrieved fields. Data are explored with reports and graphs of basic statistical information.
Continuous (range) attributes are typically explored with:
- Measures of central tendency, such as:
- The mean: The standard arithmetic average of values.
- The median: The middle data value which separates the data into two sets of equal size after data have been rank ordered. The median is a measure robust to extreme values.
- Measures of variability (dispersion of values), such as:
- The minimum and maximum data values.
- The range: The difference of the maximum minus the minimum value.
- The variance: The variance is a measure of the variability of the attribute. It summarizes the dispersion of the field values around the mean. It is calculated by summing the squared deviations from the mean and dividing them to the total number of records minus 1.
- The standard deviation which is the square root of the variance. It expresses variability in the units of the attribute.
The distribution of continuous attributes is graphically investigated with histograms. In histograms, continuous attributes are binned into bands of equal width, and bars depict the frequency of each band. By studying histograms, analysts can explore the shape of a distribution and spot potential outliers. The skewness measure can also provide an indication about the shape of the distribution. Skewness is a measure of the symmetry of a distribution. Positive skewness indicates large values and a longer tail on the right, while negative skewness indicates the reverse pattern.
The distribution of categorical attributes is typically explored with tables and charts (pie charts, bar charts) of frequencies.
Figure 2.4 presents the output of the main data exploration tool of IBM SPSS Modeler, the Data Audit, which provides a first, quick exploration of the data.

Figure 2.4 The Data Audit node of IBM SPSS Modeler for data exploration
Initial data exploration should be supplemented with an assessment of data quality. A health check on data should be performed looking for:
- Fields with too many nulls (missing values). Analysts should be very cautious with missing values since some algorithms exclude incomplete records (records with null values in any of the input fields) from model training as well as scoring.
Fields with too many missing values can be omitted from model training. Furthermore, missing values can be imputed with simple statistics like the mean or median for a continuous attribute or the mode, the modal category, for a categorical attribute. A more sophisticated approach is to impute nulls with estimations generated by respective supervised models trained on the rest of the attributes.
- Categorical fields with too many categories. An extreme example of such a field is the customer ID field which has a unique value for each customer and hence has nothing to contribute in pattern finding. In general, categorical fields with a large number of categories are hard to manage and add complexity to the model. Moreover, if used as predictors, their relationship with the target event would be hard to interpret and communicate. Therefore, the grouping of their categories is advisable.
Categories can be regrouped with conceptual criteria by merging categories that are considered similar. An even better approach is the supervised or “optimal” grouping of the categories. With this approach, categories which are similar in respect to the target attribute are merged. This handling of categorical predictors is inherent in some classification techniques such as Decision Trees which may decide to merge the categories of a splitting categorical attribute before branching.
- Categorical fields with unfixed categories which frequently change. Categorical predictors with categories that change over time can produce unstable models. The customer view and the predictor attributes used for scoring should correspond to the attributes used for model training. If in the meantime the categories of a predictor are replaced with new ones, a new training of the model is required to associate the new categories with the event outcomes.
Such predictors can be replaced with continuous ones denoting the historical relationship of the categories with the outcome. For instance, in a churn model developed for a mobile telephony operator, analysts can use the churn rate per rate plan, calculated over a specific period of time, instead of using the unstable rate plan information itself. Likewise, for the needs of a cross-selling model, the rate plan predictor can be substituted by the cross-selling index of each rate plan, denoting the average number of add-on services for each rate plan.
- Categorical fields with all cases in a single category. These “constant” fields present no variation. Since both members and nonmembers of the target population share the same value, such an attribute has no discriminating power and should be omitted from model training.
- Outlier values. Data should be scanned for odd outlier values. Outliers need special handling. They may represent unexpected, but interesting, explainable, and acceptable patterns. In fact, in many applications such as in fraud detection, they may indicate a data pattern associated with the target population. However, in many cases, outlier values may just be inexplicable, noisy data, observed only in the specific modeling dataset. A model built to identify general patterns may be misguided by such data. In such cases, a more active approach is needed in terms of outliers.
Outlier values can be coerced with the minimum or the maximum of the “normal” values. For example, if an outlier is defined as three standard deviations above the overall mean, then all values above this threshold are replaced with the highest value within this range. Other ways of handling outliers include discretization and standardization. With discretization or binning, the values of a continuous attribute are grouped into bands. A standardized attribute with the z-score method is derived by subtracting the overall average from each value and dividing with the standard deviation. We must stress however that specific classification algorithms such as the Decision Trees are robust to outliers as well as skewed distributions since they internally discretize the continuous predictors or identify an optimal split point before branching.
The data validation process should also include exploring the data for the identification of logical inconsistencies which might indicate a problematic input or even errors in the data integration and aggregation.
2.3.5 Data transformations and enrichment
| II. Data understanding, preparation, and enrichment | II.5. Data transformations and enrichment |
Classification modeling requires preclassified instances and hence the presence of an output, also known as label or target attribute. Assuming that all relevant information is lined up, the target attribute should be constructed to denote class membership in accordance with the target event definitions discussed in Section 2.2.3.3 and the modeling time frames discussed in Section 2.2.3.4. For example, by appropriately transforming information concerning disconnection applications such as application type and date data, a binary target attribute can be derived to designate customers who churned within the event outcome period. Similarly, by working on data about product openings/purchases, a cross-selling target attribute can be derived which discriminates recent purchasers.
Besides building a target attribute, analysts should finalize the customer view by appropriately transforming and enriching predictors. One thing should be outlined before discussing predictors. Predictors should by no means be confounded with the target attribute. Predicting a target event using attributes directly related with it is pointless. For instance, using the usage of a product to predict its ownership might lead to a model with astonishingly but erroneously high classification accuracy since we use a variant of the target attribute as a predictor. This pitfall is common in the case of models with distinct periods for observation and outcome. In such cases, it is crucial not to build predictors which extend in the event outcome period. This might also erroneously boost the classification accuracy of the model; however, the best predictors won’t be available for deployment. Take, for example, a churn model in which predictors also extend in the event outcome period. These predictors may mistakenly appear significant; however, when trying to predict ahead in the future and score unseen cases, they’ll be unavailable and impossible to reconstruct.
A transformation usually applied for increasing the predictive power of the inputs is “optimal” discretization or binning. “Optimal” binning is applied to continuous inputs and may attain significantly higher predictive accuracy when using algorithms such as logistic regression which calls for a linear relationship among the predictor and the probability (logit) of the target outcome.
But above all, the data preparation phase is about data enrichment. By data enrichment, we refer to the derivation of new, informative KPIs which intelligently summarize the customer behavior. It is the art of constructing new attributes which convey significant information and portray the customer profile. Common data transformations applied for data enrichment include calculations of sums and averages to summarize continuous attributes over time, ratios to denote relative preference/usage, flags to denote ownership/usage, and deltas to capture trends of behaviors over time. Deltas might prove especially useful predictors when using historical data since changes in behavior might signify a subsequent action such as a purchase or a decision to terminate the relationship with the organization. They denote the relative change in the most recent compared to the overall or the most distant observation period, and they indicate if the usage is increasing or decreasing over time.
Domain expertise is required for efficient data enrichment. To understand the logic and the significance of this step, let’s consider the example of a retailer who plans to use purchase data recorded at POS to identify prospects for its new house and furniture department. In fact, this is the case study presented in Chapter 7. The input data records all purchase details including purchase date, store, payment method, item bought, and amount spent. After properly transforming the data, the retailer constructed a series of KPIs for each customer indicating:
- Relative spending per product group
- Preferred stored
- Preferred payment method
- Preferred time zone
- Preferred day of the week
- Purchases at special occasions such as in sales periods
- Frequency of visits
- Monthly average spending amount
- Recency of visits, indicating time since last visit
- Basket size defined as the average amount spent per visit
The above fields summarize all major aspects of purchase habits, they define the customer signature, and they are appropriate for intelligent reporting as well as modeling.
In most classification applications, analysts end up with tens or even hundreds of candidate predictors. However, some or even most of them turn out to be unrelated to the target event and of trivial predictive efficiency. Specific classification algorithms, such as Decision Trees, integrate internal screening mechanisms to select and use only those attributes which are relevant to the target event. Other algorithms such as neural networks, Bayes networks, or Support Vector Machines lack this feature. Feeding these complex algorithms with wide datasets and a large number of potential inputs consumes unnecessary resources and may hinder or even prevent the model training. In such situations, a field screening preprocessing step, also known as feature selection, is recommended. It includes the application of a feature selection algorithm to assess all the available inputs, find those with marginal predictive power, and exclude them from model training.
The dimensionality of data and the number of inputs can also be reduced with the application of a data reduction algorithm. The principal component analysis (PCA), for instance, identifies sets of continuous fields and extracts components which can be used as inputs in subsequent classification. Apart from simplification, PCA also offers an additional benefit. The extracted components are uncorrelated, a great advantage when dealing with statistical models such as logistic regression which are sensitive to multicollinearity (the case of correlated predictors).
Finally, here is a note about the naming of the attributes. In most cases when using time series fields, the role of each attribute may vary according to the data setup and the used time frame. For the application illustrated in Figure 2.2, for example, data from June refer to the most recent month of the observation period during model training. In deployment however which takes place in October, June corresponds to the fourth month of the observation period. Instead of naming all June attributes with a month-name indicator (prefix or suffix), it is recommended to follow a naming typology which indicates the time sequence of the month. Such a naming typology is consistent, indicates the role of the attribute in the model, and can be easily shifted in time. For example, using names such as balance_m1, balance_m2, etc. is preferred instead of using names such as balance_Jan, balance_Feb, etc.
2.3.6 Applying a validation technique
| II. Data understanding, preparation, and enrichment | II.6. Applying a validation technique |
The model is trained on instances with known outcome. Before deployed on new, unseen cases, its accuracy is evaluated with a series of measures. However, the evaluation of the classification model is optimistic when based on the dataset used for training. We want to be sure that the model will correctly classify unseen cases and the performance on the training set is not a good indicator for future performance. We have to test the model on cases that played no role in the creation of the model. An independent testing file for validation purposes is required. Therefore, before training the model, a validation technique should be applied to ensure an unbiased, subsequent model evaluation.
In this chapter, we present three widely used validation techniques: the Split (Holdout) validation, the Cross- or n-fold validation, and the Bootstrap validation method.
2.3.6.1 Split or Holdout validation
A Split (Holdout) validation method works by partitioning the modeling file into two distinct, exhaustive, and mutually exclusive parts with random sampling. The training part usually contains the majority of training instances, and it is used for model training. The testing part is reserved for model evaluation. Its instances do not take part in model training. A common practice is to use a split ratio of about 70–75% for the training file and hence allocate approximately 70–75% of the cases in the training dataset and hold out about 25–30% of instances for evaluation.
Apparently, analysts should mainly focus on the examination of performance metrics in the testing dataset. A model underperforming in the testing dataset should be reexamined since this is a typical sign of overfitting and of memorizing the specific training data. Models with this behavior do not provide generalizable results. They provide solutions that only work for the particular data on which they were trained.
To better illustrate the logic of Split validation, let’s have a look at Table 2.2 which presents a simple modeling file for 20 customers. A pilot cross-selling campaign has been carried out, and an indicative list of inputs is used to classify customers to responders and nonresponders. The modeling file is partitioned in training and testing files through random sampling. The rightmost column of the table denotes allocation to the two partitions. Roughly 70% of the training instances are assigned to the training partition, leaving about 30% of the instances (six customers) for model evaluation.
Table 2.2 A modeling dataset partitioned into training and testing samples
| Input fields | Output field | Split validation | ||||
| Customer ID | Gender | Occupation | Average monthly number of SMS | Average monthly number of voice calls | Response to pilot campaign | Training/testing file |
| 1 | Female | Blue collar | 28 | 134 | No | Testing |
| 2 | Male | Blue collar | 45 | 54 | No | Training |
| 3 | Female | Blue collar | 57 | 65 | No | Training |
| 4 | Male | White collar | 134 | 156 | Yes | Testing |
| 5 | Female | White collar | 87 | 87 | No | Training |
| 6 | Male | Blue collar | 143 | 28 | Yes | Training |
| 7 | Female | White collar | 150 | 140 | Yes | Training |
| 8 | Male | Blue collar | 56 | 67 | No | Testing |
| 9 | Female | Blue collar | 67 | 32 | No | Training |
| 10 | Male | Blue collar | 75 | 78 | No | Training |
| 11 | Female | White collar | 87 | 145 | Yes | Training |
| 12 | Male | Blue collar | 32 | 45 | No | Testing |
| 13 | Male | Blue collar | 80 | 90 | No | Training |
| 14 | Female | Blue collar | 120 | 130 | Yes | Training |
| 15 | Female | White collar | 40 | 70 | No | Testing |
| 16 | Male | Blue collar | 120 | 126 | Yes | Training |
| 17 | Female | White collar | 130 | 160 | Yes | Testing |
| 18 | Male | Blue collar | 15 | 62 | No | Training |
| 19 | Female | White collar | 77 | 45 | No | Training |
| 20 | Male | Blue collar | 71 | 51 | No | Training |
The distribution of the target attribute should be analogous into both the training and the testing dataset. Normally, a partitioning based on simple random sampling will not distort the overall distribution of the target attribute. However, for even more accurate representation of all classes in the partitions, a Split validation with proportionate stratified sampling can be applied. With this approach, random samples are drawn independently from each class. The same sample ratios are used for each class, ensuring that a proportionate number of cases from all outcomes is allocated in the both the training and testing data files.
Some analysts split the modeling file into three distinct parts. Alongside the training and the testing files, an additional partition, the validation dataset is drawn. The training file is used for model training. The parameters of the generated model are refined on the validation file. Finally, the fine-tuned model is evaluated on the testing dataset.
2.3.6.2 Cross or n-fold validation
Although in most data mining applications we normally have enough training instances, there may be situations with data limitations. In such cases, we’d like to use all instances for model training without reserving a part for evaluation. This is what Cross- or n-fold validation does.
Initially, the cases are split into n distinct random subsamples or folds approximately of equal size. The process includes n iterations. In the first iteration, one of the folds is set apart, and the model is trained on the remaining training instances. The generated model is evaluated on the holdout fold. This process is repeated n times. In each iteration, a different fold is hold out for evaluation, and the model is trained on the other (n − 1) folds. In the end, all folds have been used (n − 1) times for model training and once for model evaluation.
Finally, the number of correct classifications and misclassified cases is counted across all the testing folds, and they are divided by the total number of cases to calculate the accuracy (percentage of correct classifications) and the error rate (percentage of misclassifications) of the full model. In general, the individual evaluation measures calculated on each fold are combined, typically averaged, to assess the performance of the full model.
Cross validation is the preferred validation in cases with data limitations. But it also has another advantage. The model evaluation is not based on a single random subsample as in Split validation. It is repeated n times on n different folds, providing a more reliable and unbiased evaluation of the model.
The standard approach is to use a 10-fold Cross validation. Table 2.3 presents a modeling file of 20 instances on which a fourfold Cross validation has been applied. Each fold contains five customers. In the first iteration, customers 1, 11, 14, and 18 of Fold 1 are hold out for assessing the performance of the classification model trained on Folds 2, 3, and 4. The procedure is repeated for three more times, each time with a different fold holdout for validation.
Table 2.3 A modeling dataset with fourfold for Cross Validation
| Input fields | Output field | Cross Validation | ||||
| Customer ID | Gender | Occupation | Average monthly number of SMS | Average monthly number of voice calls | Response to pilot campaign | Folds |
| 1 | Female | Blue collar | 28 | 134 | No | Fold-1 |
| 2 | Male | Blue collar | 45 | 54 | No | Fold-2 |
| 3 | Female | Blue collar | 57 | 65 | No | Fold-4 |
| 4 | Male | White collar | 134 | 156 | Yes | Fold-3 |
| 5 | Female | White collar | 87 | 87 | No | Fold-4 |
| 6 | Male | Blue collar | 143 | 28 | Yes | Fold-2 |
| 7 | Female | White collar | 150 | 140 | Yes | Fold-3 |
| 8 | Male | Blue collar | 56 | 67 | No | Fold-4 |
| 9 | Female | Blue collar | 67 | 32 | No | Fold-4 |
| 10 | Male | Blue collar | 75 | 78 | No | Fold-2 |
| 11 | Female | White collar | 87 | 145 | Yes | Fold-1 |
| 12 | Male | Blue collar | 32 | 45 | No | Fold-2 |
| 13 | Male | Blue collar | 80 | 90 | No | Fold-2 |
| 14 | Female | Blue collar | 120 | 130 | Yes | Fold-1 |
| 15 | Female | White collar | 40 | 70 | No | Fold-3 |
| 16 | Male | Blue collar | 120 | 126 | Yes | Fold-4 |
| 17 | Female | White collar | 130 | 160 | Yes | Fold-3 |
| 18 | Male | Blue collar | 15 | 62 | No | Fold-1 |
| 19 | Female | White collar | 77 | 45 | No | Fold-3 |
| 20 | Male | Blue collar | 71 | 51 | No | Fold-4 |
2.3.6.3 Bootstrap validation
Bootstrap validation uses sampling with replacement; hence, a training case can be included more than once in the resulting training file.
More specifically, the initial modeling file of size n is sampled n times with replacement to give a training file of size n. Due to the sampling with replacement, the bootstrap sample will include more than one instance of some of the original n cases, while other cases will not be picked at all. In fact, it turns out (and it can be shown if we calculate the probabilities of selection) that with the method described here, referred to as the 0.632 bootstrap, on average 63.2% of the original cases, will be included in the bootstrap sample and around 36.8% will not be picked at all. These cases comprise the testing file for model evaluation.
Although the number of total cases of the resulting training file (the bootstrap sample) remains equal to the original size n, the fact is that it contains less “unique” cases compared, for instance, with a 10-fold cross validation training file. Using only the bootstrap testing file for evaluation would lead to pessimistic measures of classification accuracy. To compensate for that, the estimated error rate (misclassification percentage) of the full model is also taking into account the training cases of the bootstrap sample, and it is calculated as follows:
The overall bootstrap procedure can be repeated for k times and the results can be averaged over iterations. The Bootstrap validation method works well with very small datasets.
2.3.7 Dealing with imbalanced and rare outcomes
| II. Data understanding, preparation, and enrichment | II.7. Dealing with imbalanced outcomes |
Most classification algorithms work better when analyzing data with a balanced outcome distribution. However, in real-world applications, the distributions of the output classes differ substantially, and the target class is rare and underrepresented. Ideally, we’d prefer a percentage of about 20–50% for the target class and nonetheless above 10%, but this is rarely the case. Two widely used methods to tackle this issue are the balancing of the distribution of the target classes and the application of case weights to the training file. The “adjustment” of class distribution helps the classifier to discover hot spots consisting of very high concentrations of the target class.
Apart from the distribution, there may be an issue with the target class frequency. Ideally, we’d like sufficient instances of the target class, at least a few hundreds; if this is not the case, a simple extension of the event outcome period might prove sufficient to improve the situation. For example, by increasing the span of the event outcome period to 6 instead of 3 months, we can capture more actual churners for our target class.
2.3.7.1 Balancing
Balancing is the application of disproportionate stratified sampling on the training file to adjust class imbalances. Balancing changes the distribution of the training file. The frequent classes, typically denoting nonmembers of the target population, are undersampled. A random percentage of these instances is included in the balanced training file by applying a sample ratio, also referred to as balance factor, less than 1.0. Therefore, the frequency of the common cases is reduced. In the end, the training file will include all target class cases and a fraction of the other cases. Additionally or alternatively, the density of the rare class can be “inflated” by oversampling with a sample ratio higher than 1.0. Target class cases are resampled and may be included in the training file with more than one instance.
Either way, the rare class is “boosted in the balanced training file and its frequency is increased. Therefore, models should be evaluated on unbalanced data. Additionally, when scoring with a model trained on balanced data, we should be cautious with the generated scores. When a model is applied to new cases, along with the class prediction, it estimates its confidence and hence the propensity, the likelihood of the target outcome. If balanced data are used for training, the resulting propensities do not correspond to the actual probabilities of belonging to the target class. However, propensities are comparable and can be used to rank customers according to their likelihood of belonging to the target class.
The calculated probabilities for a binary target field can be adjusted for oversampling using the formula below:

where ![]() is the adjusted probability estimate of class i,
is the adjusted probability estimate of class i, ![]() the unadjusted probability estimate, πi the actual population proportion of class i in the original training dataset, and ρi the observed proportion of class i in the balanced sample. The adjusted probabilities can be used as estimates of the actual class probabilities.
the unadjusted probability estimate, πi the actual population proportion of class i in the original training dataset, and ρi the observed proportion of class i in the balanced sample. The adjusted probabilities can be used as estimates of the actual class probabilities.
IBM SPSS Modeler offers an interesting solution to this issue. A generated model estimates adjusted propensities. These propensities are based on the unbalanced testing file (partition), and they are not affected by the balance.
The recommended balancing approach is to reduce the common outcomes through undersampling instead of boosting the rare ones with oversampling. The scope is to attain a target class percentage of about 25–50%.
Table 2.4 presents a class-imbalanced dataset for cross-selling. Three out of 30 customers have responded to the pilot campaign and were classified in the target class. Since the target class percentage is a poor 10%, the file was adjusted with balancing.
Table 2.4 A class-imbalanced modeling file for cross-selling
| Input fields | Output field | ||||
| Customer ID | Gender | Occupation | Average monthly number of SMS | Average monthly number of voice calls | Response to pilot campaign |
| 1 | Male | White collar | 28 | 140 | No |
| 2 | Male | Blue collar | 32 | 54 | No |
| 3 | Female | Blue collar | 57 | 30 | No |
| 4 | Male | White collar | 143 | 140 | Yes |
| 5 | Female | White collar | 87 | 81 | No |
| 6 | Male | Blue collar | 143 | 28 | No |
| 7 | Female | White collar | 150 | 140 | No |
| 8 | Male | Blue collar | 15 | 60 | No |
| 9 | Female | Blue collar | 85 | 32 | No |
| 10 | Male | Blue collar | 75 | 32 | No |
| 11 | Female | White collar | 42 | 140 | No |
| 12 | Male | Blue collar | 32 | 62 | No |
| 13 | Female | Blue collar | 80 | 20 | No |
| 14 | Female | White collar | 120 | 130 | Yes |
| 15 | Female | White collar | 40 | 70 | No |
| 16 | Male | Blue collar | 120 | 30 | No |
| 17 | Female | White collar | 130 | 95 | No |
| 18 | Male | Blue collar | 15 | 62 | No |
| 19 | Female | White collar | 78 | 45 | No |
| 20 | Male | Blue collar | 71 | 51 | No |
| 21 | Male | Blue collar | 20 | 15 | No |
| 22 | Male | White collar | 62 | 52 | No |
| 23 | Male | Blue collar | 72 | 52 | No |
| 24 | Female | Blue collar | 70 | 50 | No |
| 25 | Female | Blue collar | 90 | 110 | Yes |
| 26 | Female | White collar | 40 | 30 | No |
| 27 | Male | Blue collar | 30 | 20 | No |
| 28 | Female | Blue collar | 80 | 40 | No |
| 29 | Male | Blue collar | 75 | 68 | No |
| 30 | Female | White collar | 63 | 43 | No |
The training file after balancing is listed in Table 2.5. A balance factor of 1.0 was used for the target class, and all responders were retained. On the other hand, nonresponders were undersampled with a sample ratio of 0.26, and a random sample of seven nonresponders was selected for model training. After balancing, the proportion of the target class has been raised to 30% (3 out of 10).
Table 2.5 The balanced modeling file
| Input fields | Output field | ||||
| Customer ID | Gender | Occupation | Average monthly number of SMS | Average monthly number of voice calls | Response to pilot campaign |
| 3 | Female | Blue collar | 57 | 30 | No |
| 4 | Male | White collar | 143 | 140 | Yes |
| 8 | Male | Blue collar | 15 | 60 | No |
| 13 | Female | Blue collar | 80 | 20 | No |
| 14 | Female | White collar | 120 | 130 | Yes |
| 19 | Female | White collar | 78 | 45 | No |
| 23 | Male | Blue collar | 72 | 52 | No |
| 25 | Female | Blue collar | 90 | 110 | Yes |
| 28 | Female | Blue collar | 80 | 40 | No |
| 29 | Male | Blue collar | 75 | 68 | No |
2.3.7.2 Applying class weights
An alternative approach to deal with class imbalances is with the application of class weights. The contribution of each case to the model training is defined by its weighting factor. This method has the advantage of using all of the available training data, provided of course that the modeling algorithm supports case weights. In the end, estimated propensities should be adjusted to correspond to the actual probabilities of the target class.
A recommended approach is to assign a weight of 1.0 to the rare class and a weight lower than 1.0 to the frequent class to give extra importance to the underrepresented cases. This weighting is shown in Table 2.6. A weighting factor of 1.0 is assigned to responders of the pilot cross-selling campaign and a weight of 0.26 to the 27 nonresponders, adjusting the distribution of the target class to 30–70%.
Table 2.6 A class-imbalanced modeling file with weights
| Input fields | Output field | |||||
| Customer ID | Gender | Occupation | Average monthly number of SMS | Average monthly number of Voice calls | Response to pilot campaign | Weight |
| 1 | Male | White collar | 28 | 140 | No | 0.26 |
| 2 | Male | Blue collar | 32 | 54 | No | 0.26 |
| 3 | Female | Blue collar | 57 | 30 | No | 0.26 |
| 4 | Male | White collar | 143 | 140 | Yes | 1.0 |
| 5 | Female | White collar | 87 | 81 | No | 0.26 |
| 6 | Male | Blue collar | 143 | 28 | No | 0.26 |
| 7 | Female | White collar | 150 | 140 | No | 0.26 |
| 8 | Male | Blue collar | 15 | 60 | No | 0.26 |
| 9 | Female | Blue collar | 85 | 32 | No | 0.26 |
| 10 | Male | Blue collar | 75 | 32 | No | 0.26 |
| 11 | Female | White collar | 42 | 140 | No | 0.26 |
| 12 | Male | Blue collar | 32 | 62 | No | 0.26 |
| 13 | Female | Blue collar | 80 | 20 | No | 0.26 |
| 14 | Female | White collar | 120 | 130 | Yes | 1.0 |
| 15 | Female | White collar | 40 | 70 | No | 0.26 |
| 16 | Male | Blue collar | 120 | 30 | No | 0.26 |
| 17 | Female | White collar | 130 | 95 | No | 0.26 |
| 18 | Male | Blue collar | 15 | 62 | No | 0.26 |
| 19 | Female | White collar | 78 | 45 | No | 0.26 |
| 20 | Male | Blue collar | 71 | 51 | No | 0.26 |
| 21 | Male | Blue collar | 20 | 15 | No | 0.26 |
| 22 | Male | White collar | 62 | 52 | No | 0.26 |
| 23 | Male | Blue collar | 72 | 52 | No | 0.26 |
| 24 | Female | Blue collar | 70 | 50 | No | 0.26 |
| 25 | Female | Blue collar | 90 | 110 | Yes | 1.0 |
| 26 | Female | White collar | 40 | 30 | No | 0.26 |
| 27 | Male | Blue collar | 30 | 20 | No | 0.26 |
| 28 | Female | Blue collar | 80 | 40 | No | 0.26 |
| 29 | Male | Blue collar | 75 | 68 | No | 0.26 |
| 30 | Female | White collar | 63 | 43 | No | 0.26 |
Class weights should be ignored in the model evaluation procedure, and the model should be tested on unweighted data.
2.4 Classification modeling
Modeling is a trial-and-error phase which involves experimentation. A number of different models should be trained and examined. Additionally, in a procedure called meta-modeling, multiple models can be combined to improve the classification accuracy. The initial examination of the derived models is followed by a formal and thorough evaluation of their predictive accuracy.
2.4.1 Trying different models and parameter settings
| III. Classification modeling | III.1. Trying different models and parameter settings |
Each attribute has a specific role in the training of the classifier. A set of selected attributes should be set as inputs for predicting the target attribute. Note that the target attribute is also referred to as the label or the output attribute. Then, at last, it is time for model training. Multiple classifiers with different parameter settings should be trained and examined before selecting the one for deployment.
The role of each attribute in IBM SPSS Modeler is specified with a Type node which should precede the model training node. Similarly, a Set Role operator can be used in RapidMiner to assign roles to attributes. In Data Mining for Excel, the attribute roles are specified in one of the steps of the Classify Wizard.
2.4.2 Combining models
| III. Classification modeling | III.2. Combining models |
Individual models can be combined to improve the predictive accuracy. This approach, referred to as meta-modeling or ensemble modeling, involves the training of multiple base classifiers and the development of a composite classifier for scoring new cases. Imagine the different models as experts who vote for a decision. Instead of consulting a single expert, we might select to take into account the decisions of the individual classifiers and pool their predictions for scoring new customers. The ensemble classifier can often attain substantially better predictive accuracy and present more stable performance than the original models.
The meta-modeling techniques can be grouped in two main classes:
- Those which combine models of different types, but all based on the original modeling file.
- Those which combine models of the same type, for instance, Decision Trees. These techniques involve multiple iterations and training of models on different samples of the modeling file. Bagging, Boosting and Random Forests are meta-modeling techniques of this type.
The application of the first type of ensemble modeling is straightforward. Multiple models are developed as usual, and then the individual predictions are combined with a voting procedure.
There are various methods of combining the predictions of individual models. Below, we list some of the most common ones:
- (Majority) Voting. For each instance, the number of times each class is predicted across the base models is tallied. The prediction of the ensemble model for each instance is the class selected by the majority of base learners. The prediction’s confidence, that is, the likelihood of prediction, is calculated as the percentage of base models which returned that prediction. For example, if 2 out of 3 models predict no for a given instance, then the final prediction for this instance is no with 66.7% (2/3) confidence. This voting approach is incorporated by RapidMiner’s Vote operator.
- Highest confidence. This method selects as the prediction for each instance the class which presents the single highest confidence across all base models.
- Average propensity (for two-class problems). The class with the highest value when each class’ propensities (likelihoods) are averaged across base models is selected as the prediction.
- Confidence-/propensity weighted voting. With simple voting, if two out of three models predict yes, then yes wins by a vote of two to one. In the case of confidence-weighted voting, the votes are weighted based on the confidence value of each prediction. Thus, if one model predicts no with a higher confidence than the two yes predictions summed, then no wins. In other words, the yes votes, the confidences of models predicting yes, are summed and compared with the sum of votes (confidences) of models predicting no. The predicted class for each instance is the class with the highest total votes. The sum of weights (confidences) divided by the total number of base learners is the prediction’s confidence.
2.4.2.1 Bagging
With Bagging (Bootstrap Aggregation), multiple models of the same type are trained on different replicates of the original training file. A set of n bags, n bootstrap samples, typically of the same size as the original dataset, are drawn with replacement. Due to the resampling applied to the original training data, some training instances may be omitted, while others replicated. This technique involves n iterations. In each iteration, a different model is built on each bag. The set of n models generated are combined and vote to score new cases.
Bagging can improve the classification accuracy compared to individual models (although not as dramatically as Boosting which is presented immediately after). Additionally, since the ensemble model is based on more than one datasets, which unfortunately are not independent, it can be more robust to noisy data and hence more reliable and stable.
2.4.2.2 Boosting
Boosting involves the training of a sequence of models of the same type which complement one another. In the first iteration, a classifier is built the usual way. The second model though depends on the first one as it focuses on the instances which the first model failed to classify correctly. This procedure is continued for n iterations with each model aiming at the “hard cases” of the previous models.
Adaptive Boosting (AdaBoost), a popular Boosting technique, works as follows: Each record is assigned a weight denoting its “hardness” to be classified. In the first iteration, all records are assigned equal weights. After the first model run, these weights are adjusted so that misclassified instances yield higher weights and correctly classified ones lower weights. The subsequent base model is trained on the weighted instances. Assuming the base learner supports case weights, the contribution of each case to the model training is defined by its weight. That’s why each base model starts from where the previous models stopped.
Even in the case of a type of classifier which does not support case weights, the AdaBoost technique can be employed by using samples with replacement for each iteration. On the contrary to Bagging though, the inclusion probability of each instance should be proportional to its estimated weight.
A weighted voting procedure is finally applied for scoring with the boosted model. The weight of the vote of each base model depends on its error rate. Hence, more accurate classifiers have stronger influence on the prediction. The Boosting can substantially improve predictive accuracy; however, it is demanding in terms of training time and prone to overfitting.
2.4.2.3 Random Forests
Random Forests use Bagging and bootstrap samples to generate n different Decision Trees in n iterations. The Decision Tree models differ not only on their training instances but also on the used predictors. A random subset of predictors is considered for partition at each node. The predictor for the best split is chosen, according to the tree’s attribute selection method, on the random list of attributes. A voting procedure is applied for scoring with the ensemble classifier.
Random Forests are faster than Bagging and Boosting and can improve the classification accuracy, especially if the different tree models are diverse and not highly correlated. This can be achieved by keeping the subset ratio relatively low.
2.5 Model evaluation
Before deploying the classifier on unseen cases, its predictive accuracy should be thoroughly evaluated. In general, the assessment of the predictive ability of the model is based on the comparison between the actual and the predicted event outcome. The model evaluation is carried out in two phases: before and after the rollout of the respective campaign.
The precampaign model validation typically includes a series of metrics and evaluation graphs which estimate the model’s future predictive accuracy in unseen cases, for example, in the holdout testing dataset. After the direct marketing campaign is executed, the deployed model’s actual performance and the campaign design itself are evaluated with test–control groups. In Section 2.5.1, we focus on the precampaign evaluation.
2.5.1 Thorough evaluation of the model accuracy
| IV. Model evaluation | IV.1. Thorough evaluation of the model accuracy |
In the precampaign evaluation, preclassified cases are scored and two new fields are derived: the predicted class and the prediction’s confidence which denotes the likelihood of the prediction. In practice, all models make mistakes. There are always errors and misclassifications. The comparison of the predicted with the actual values is the first step for evaluating the model’s performance.
The model should not be validated on the training instances since this would lead to optimistic assessment of its accuracy. Therefore, analysts should always employ a validation technique as those presented in Section 2.3.6 and focus on the examination of performance in the testing dataset(s). This is called the out-of-sample validation since it is based on cases not present in the training sample. If possible, an out-of-time validation should also be performed. In the out-of-time validation, the model is tested on a disjoint dataset from a different time period.
As discussed in Section 2.3.7, class imbalances are quite common in actual business problems. Balancing and case weighting are two common techniques to tackle this situation. In such cases, analysts should evaluate the model accuracy on unbalanced/unweighted cases.
Common evaluation techniques include:
- Confusion matrix and accuracy measures
- Gains/Lift/Response chart
- ROC curves
- Return on investment (ROI) curves
2.5.1.1 Accuracy measures and confusion matrices
| IV.1. Thorough evaluation of the model accuracy | IV.1.1. Confusion matrix and accuracy measures |
One of the most common ways to summarize the model accuracy is through a Confusion (also known as misclassification or coincidence) matrix such as the one presented in Table 2.7 for a two-class target attribute. Positive refers to the target event instances, for example, churned customers or responders to a direct marketing campaign.
Table 2.7 Confusion matrix
| Predicted values | ||||
| Positive | Negative | Total | ||
| Actual values | Positive | TP = true positive record count (correct prediction) | FN = false negative record count (misclassification) | P = total positive records |
| Negative | FP = false positive record count (misclassification) | TN = true negative record count (correct prediction) | N = total negative records | |
| Total | P′ = total records predicted as positive | N′ = total records predicted as negative | P + N = P′ + N′ | |
A Confusion matrix is a simple cross-tabulation of the predicted by the actual classes. It is the base for the calculation of various accuracy measures including the accuracy and the error or misclassification rate.
The accuracy denotes the percentage of instances correctly classified and is calculated as
In other words, it sums the table percentages of the Confusion matrix across the diagonal. In binary classification problems, a 50% estimated probability threshold is used to classify an instance as positive or negative. The error rate is the off-diagonal percentage—the proportion of records misclassified—and is calculated as
Since some mistakes are more costly than others, accuracy percentages are also estimated for each category of the target field. The percentage of actual positives (target instances) correctly captured by the model defines sensitivity:
The percentage of negative instances correctly classified is the specificity:
while
The false positive rate denotes the proportion of negative (nontarget) instances misclassified as positive (target). Remember the false positive rate when we discuss the ROC curve later in this section.
The aforementioned measures are very useful especially in the case of class-imbalanced problems where the target event is rare. In such cases, a model may present an acceptable accuracy rate while failing to identify the target instances. Imagine, for example, an organization with an overall churn rate of about 2%. A naïve model classifying all customers as nonchurners would yield an astonishingly high accuracy of 98%. Obviously, this model has no practical value as it fails to capture any churner as denoted by its 0 sensitivity.
Other accuracy measures include Precision, Recall, and the F-measure which stems from their combination.
The Precision measure represents the percentage of the predicted positives which were actual positives and can be thought of as a measure of exactness:
The Recall measure is the same as sensitivity.
The F-measure is the harmonic mean of Precision (a measure of exactness) and Recall (a measure of completeness). It ranges from 0 to 1 with larger values corresponding to better models. It is defined as
2.5.1.2 Gains, Response, and Lift charts
| IV.1. Thorough evaluation of the model accuracy | IV.1.2. Gains, Response, and Lift charts |
Many times, in the real world of classification modeling, we end up with models with moderate accuracy, especially in cases with a rare target event. Does this mean that the model is not adequate? Remember that in order to estimate the accuracy and the error rate of a model in a binary classification problem, we typically use a default propensity threshold of 50% for classifying an instance as positive. In problems with a rare target class, an increased FN rate and therefore an increased error rate may simply mean that the estimated propensities are often below 50% for actual positives. Does this mean that the model is not useful? To answer that, we must examine whether the positive instances yield higher estimated propensities compared to the negative ones. In other words, we must examine if the model propensities rank well and if they discriminate the actual positives from the actual negatives. The Gains, Response, and Lift/Index tables and charts are helpful evaluation tools that summarize the model’s performance and discrimination power. In this paragraph, we’ll present these charts and the measure of Lift which denotes the improvement in concentration of the target class due to the model. To illustrate the basic concepts and usage of these charts, we will present the results of a hypothetical churn model that was built on a binary target field which flagged churners.
The first step for the creation of such charts is to select the target class of interest, also referred to as the hit category. For Gains/Response/Lift charts as well for ROI and Profit charts which will presented immediately after, we assume that the classifier can estimate the probability of belonging at each class and hence the hit propensity which is the likelihood of the target class. Records/customers can then be sorted in descending order according to their hit propensities and binned into groups of equal size, typically of 1% each, named percentiles. The model accuracy is then evaluated within these percentiles.
In our hypothetical example, the target class is the category of churners, and the hit propensity is the churn propensity—in other words, the estimated likelihood by the churn model. Customers are split into 10 tiles of 10% each (deciles). The 10% of customers with the highest churn propensities comprise tile 1, and those with the lowest churn propensities, tile 10. In general, we expect high propensities to correspond to actual members of the target population. Therefore, we hope to find large concentrations of actual churners among the top model tiles.
The cumulative Table 2.8 evaluates our churn model in terms of the Gain, Response, and Lift measures.
Table 2.8 The gains, response, and lift table
| Model tiles | Cumulative % of customers | Propensity threshold (minimum value) | Gain (%) | Response (%) | Lift (%) |
| 1 | 10 | 0.150 | 37.1 | 10.7 | 371.4 |
| 2 | 20 | 0.100 | 56.9 | 8.2 | 284.5 |
| 3 | 30 | 0.070 | 69.6 | 6.7 | 232.1 |
| 4 | 40 | 0.065 | 79.6 | 5.7 | 199.0 |
| 5 | 50 | 0.061 | 87.0 | 5.0 | 174.1 |
| 6 | 60 | 0.052 | 91.6 | 4.4 | 152.7 |
| 7 | 70 | 0.043 | 94.6 | 3.9 | 135.2 |
| 8 | 80 | 0.039 | 96.4 | 3.5 | 120.6 |
| 9 | 90 | 0.031 | 98.2 | 3.1 | 109.2 |
| 10 | 100 | 0.010 | 100.0 | 2.9 | 100.0 |
But what exactly do these performance measures represent and how they are used for model evaluation? A brief explanation is as follows:
- Response %: “How likely is the target class within the examined quantiles?” It denotes the likelihood of the target outcome, the percentage of the actual churners (positives) within the tiles. It is a measure of exactness and is the same as the Precision measure discussed in Section 2.5.1.1.
In our example, 10.7% of the customers of the top 10% model tile were actual churners, yielding a Response % of the same value. Since the overall churn rate was about 2.9%, we expect that a random list would also have an analogous churn rate. However, the estimated churn rate for the top model tile was 3.71 times (or 371.4%) higher. This is called the Lift. Analysts have achieved about four times better results than randomness in the examined model tile. As we move from the top to the bottom tiles, the model exactness decreases. The concentration of the actual churners is expected to decrease. Indeed, the first two tiles, which jointly account for the top 20% of the customers with the highest estimated churn scores, have a smaller percentage of actual churners (8.2%). This percentage is still 2.8 times higher than randomness.
- Gain %: “Which percentage of the target class falls in the tiles?” Gain % is defined as the percentage of the total target population that belongs in the tiles. It is the same as Sensitivity and Recall presented in Section 2.5.1.1; hence, it is a measure of completeness. It denotes the true positive rate, the percentage of true positives (actual churners) included in the tile.
In our example, the top 10% model tile contains 37.1% of all actual churners, yielding a Gain % of the same value. A random list containing 10% of the customers would normally capture about 10% of all observed churners. However, the top model tile contains more than a third (37.1%) of all observed churners. Once again, we come upon the Lift concept. The top 10% model tile identifies about four times more target customers than a random list of the same size.
- Lift: “How much better is the classifier compared to randomness?” The Lift or Index assesses the factor of improvement in response rate due to the model. It is defined as the ratio of the model Response % (or equivalently Gain %) to the Response % of a random model. In other words, it compares the model quantiles with a random list of the same size. Therefore, it represents how much a trained classifier exceeds the baseline model of random selection.
The Gain, Response, and Lift evaluation measures can also be depicted in corresponding charts such as the ones shown in the following. The two added reference lines correspond to the top 5% and the top 10% tiles. The diagonal line in the Gains chart represents the baseline model of random guessing.
According to the cumulative Gains chart shown in Figure 2.36, when scoring an unseen customer list, data miners should expect to capture about 40% of all potential churners if they target the customers of the top 10% model tile. Narrowing the list to the top 5% percentile decreases the percentage of potential churners to be reached to approximately 25%. As we move to the right of the X-axis, the expected number of total churners (true positives) to be identified increases. But this comes at a cost of increased error rate and false positives. On the contrary, left parts of the X-axis lead to smaller but more targeted campaigns.

Figure 2.36 Gains chart
What we hope to see in a real model evaluation is a Gains curve steeply and smoothly rising above the diagonal along the top tiles before gradually easing off after a point.
Analysts can study Gains charts and compare the accuracy of models. A model closer to the diagonal line of random guessing is less accurate. A Gains chart typically also includes an Optimal or Best line which corresponds to the ideal model that classifies all records correctly.
Although we’d like a Gains curve to be close to the Optimal line, extreme proximity and absolute accuracy might indicate a problem with the model training such as using a predictor directly related with the target attribute.
By studying the Gains charts, analysts assess the model’s discriminating power. They also gain valuable insight about its future predictive accuracy on new records. These charts can be used for deciding the optimal size of the respective campaign by choosing the top propensity-based tiles to target. Hence, they may choose to conduct a small campaign, limited to the top tiles, in order to address only customers with very high propensities and minimize the false positive cases. Alternatively, especially if the cost of the campaign is small compared to the potential revenue, they may choose to expand their list by including more tiles and more customers with relatively lower propensities.
Figure 2.37 presents the cumulative Response chart for our hypothetical example.
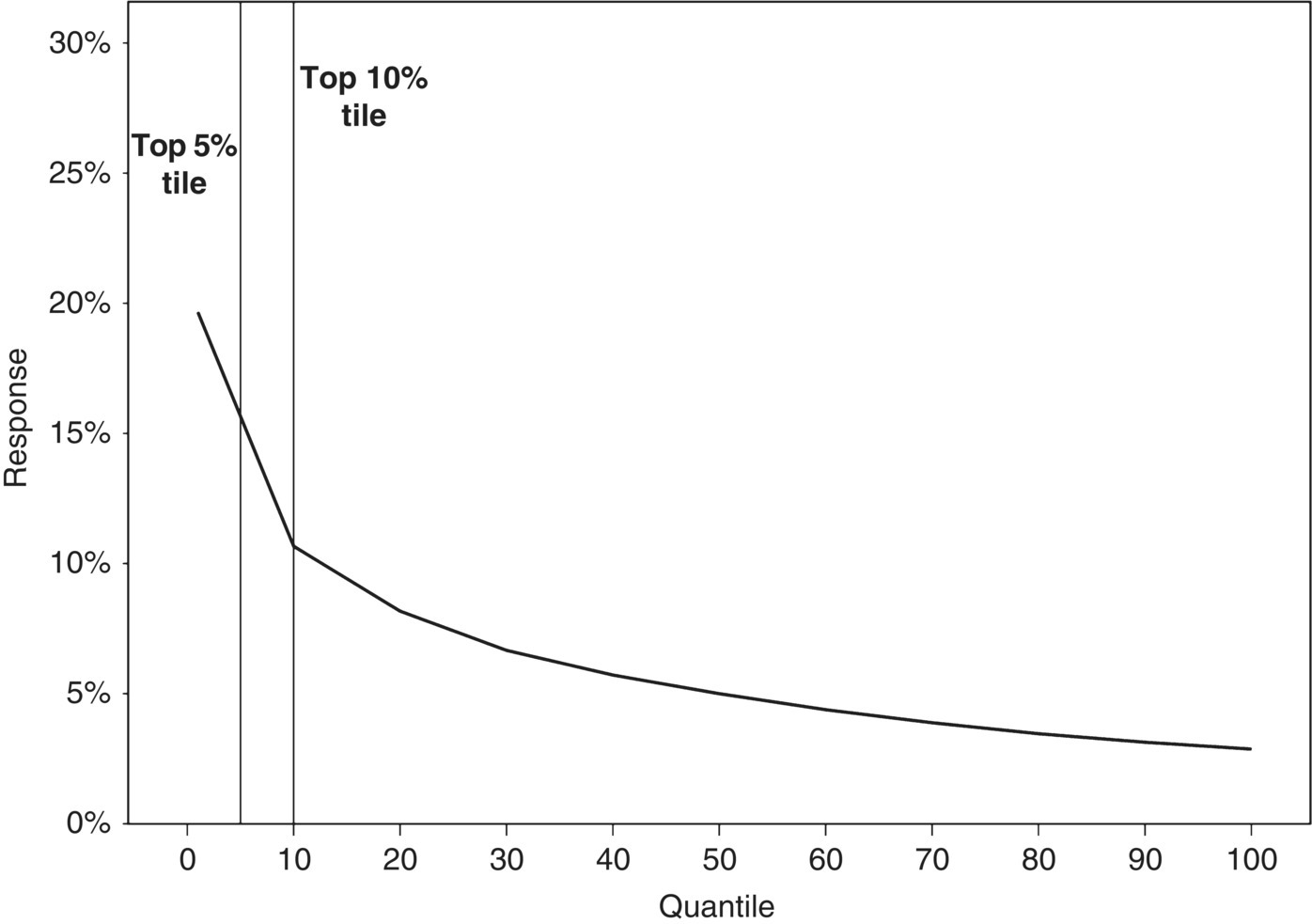
Figure 2.37 Response chart
It illustrates the estimated churn likelihood along the model tiles. As we move to the left of the X-axis and toward the top tiles, we have increased churn probabilities. These tiles would result more targeted lists and smaller error rates. Expanding the list to the right part of the X-axis, toward the bottom model tiles, would increase the expected false positive error rate by including in the targeting list more customers with low likelihood to churn.
The cumulative Lift or Index chart (Figure 2.38) directly compares the model predictive performance with the baseline model of random selection. The concentration of churners is estimated to be four times higher than randomness among the top 10% customers and about six times higher among the top 5% customers.
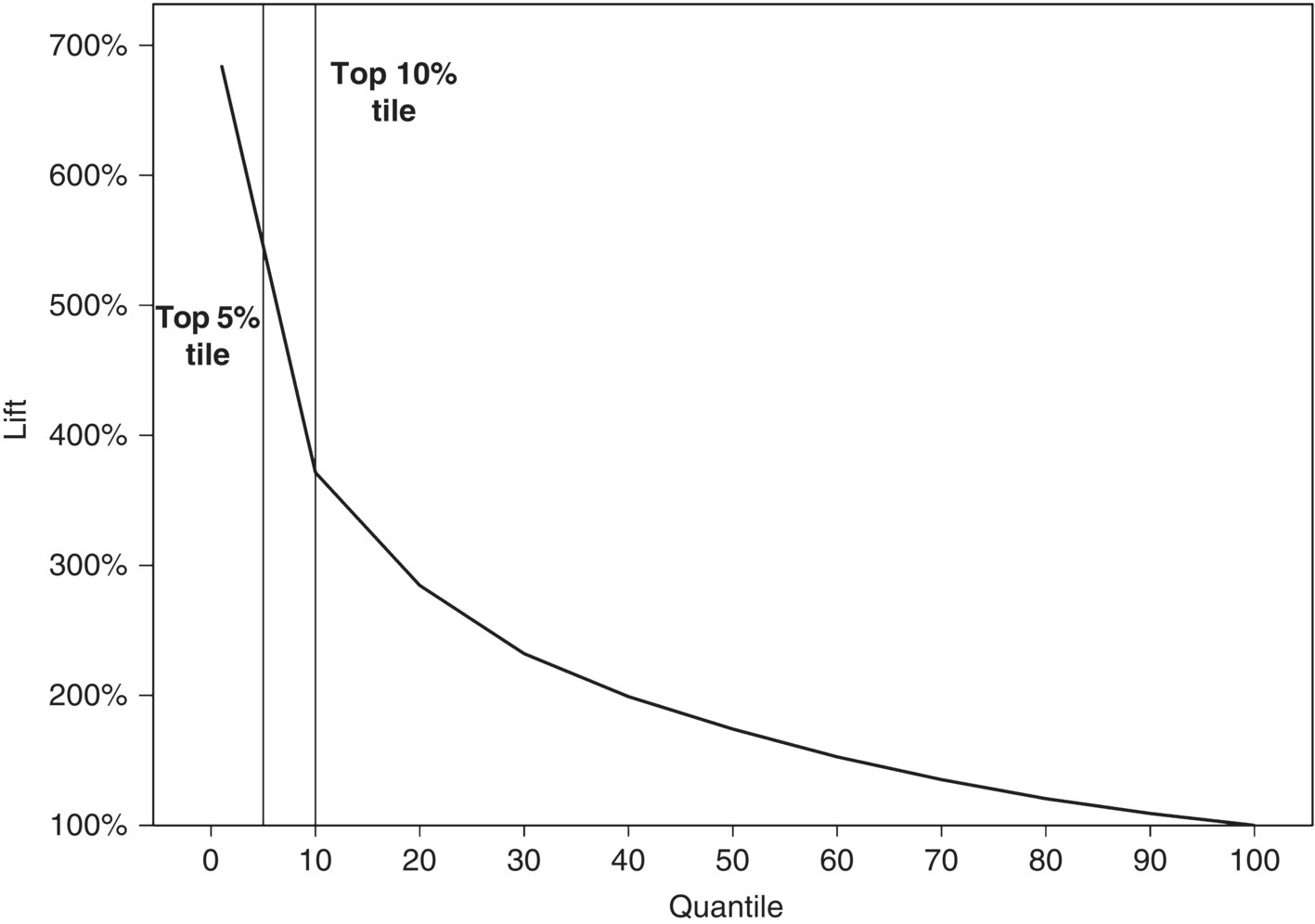
Figure 2.38 Lift chart
2.5.1.3 ROC curve
| IV.1. Thorough evaluation of the model accuracy | IV.1.3. ROC curve |
The ROC curve also visualizes the performance and the discriminating power of the classifier. It plots the model’s true positive rate, the sensitivity, in the vertical axis. Its horizontal axis corresponds to the false positive rate (1—specificity), the proportion of negative (nontarget) instances misclassified as positive. Therefore, the ROC curve depicts the trade-off between capturing more positives but with an increased cost of false positives.
Just as the Gains chart, the ROC curve is based on the rank ordering of the test instances in decreasing order according to their propensities. The Gains chart and the ROC curve also have the same vertical axis, the true positive percentage. Their difference is at the horizontal axis. In Gains charts, it plots the percentage of the total test population, while in ROC curves, the proportion of false positives. That’s why the ROC curve shape does not depend on the overall distribution of the target category, and hence, it is unaffected by oversampling. However, since in many real-world applications the density of the target category is small (for instance, below 1%), there is little difference between the proportion of the total test population and the proportion of total negatives, and hence, the ROC curve and the Gains chart have similar shapes.
If the model is adequate, its ROC curve will rise sharply near the vertical axis before easing off. In the case of a trivial model, the curve will approximate a diagonal line from the lower left to the upper right corner of the graph. A measure of the accuracy of the model is the area under the curve (AUC) which is equivalent to the c-statistic. It ranges between 0 and 1.0. The closer the AUC is to 1.0, the better the model. A model with AUC close to 0.5 is not better than random guessing. An ideal model will have a value of 1.0, while values above 0.7 can be considered adequate.
The AUC measure is also equivalent to the Gini index. The Gini index is calculated as the area between the ROC curve and the diagonal line of the random model divided by the area between the optimal curve and the diagonal. It ranges between 0 and 1.0 with values above 0.4 denoting acceptable efficiency. In fact:
2.5.1.4 Profit/ROI charts
| IV.1. Thorough evaluation of the model accuracy | IV.1.4. Profit/ROI charts |
Profit and ROI charts are extensions of the Gains/Response charts which incorporate cost and revenue information to help marketers decide their target lists based on estimated revenue.
The model estimated target probabilities are combined with expected cost and revenue information to calculate the probabilistic Profit and/or ROI for the model percentiles.
Marketers must specify:
- Cost: The estimated cost per offer (for each customer included in the campaign)
- Revenue: The anticipated revenue associated with each hit, that is, for each customer accepting the offer
Customers are sorted in descending order according to their hit propensities and then binned into percentiles as presented in Section 2.5.1.2. Then, the estimated (cumulative) profit per offer is calculated for each model percentile as follows:
Obviously, revenues concern only responders (hits), while costs apply to all records/offers.
By multiplying the profit per offer with the number of customers of the tile, we have the total (cumulative) profit for the tile. In case of an overhead cost, it should be subtracted from the total profit.
The estimated ROI per offer, expressed as the percentage return on cost, is calculated as
Hence, the ROI per offer is the ratio of the average profit to average cost for each record of the tile. Negative values indicate loss per offer and correspond to negative profit per offer.
Table 2.9 The Profit report generated by Data Mining for Excel
| Percentile (%) | Random guess profit | Classify CHURN population correct (%) | Classify CHURN profit | Classify CHURN probability (%) |
| 0 | (€1 000.00) | 0.00 | (€1 000.00) | 100.00 |
| 1 | (€2 044.54) | 3.23 | €1 203.61 | 44.38 |
| 2 | (€3 089.08) | 7.68 | €5 170.12 | 35.27 |
| 3 | (€4 133.62) | 11.11 | €7 667.55 | 26.72 |
| 4 | (€5 178.16) | 13.54 | €8 695.90 | 26.72 |
| 5 | (€6 222.70) | 17.98 | €12 662.41 | 19.49 |
| 6 | (€7 267.24) | 21.82 | €15 747.47 | 19.49 |
| 7 | (€8 311.78) | 25.66 | €18 832.53 | 19.49 |
| 8 | (€9 356.32) | 28.69 | €20 742.32 | 17.75 |
| 9 | (€10 400.86) | 31.72 | €22 652.12 | 17.75 |
| 10 | (€11 445.40) | 33.94 | €23 386.66 | 13.94 |
| 11 | (€12 489.94) | 35.96 | €23 827.38 | 13.94 |
| 12 | (€13 534.47) | 37.98 | €24 268.11 | 13.94 |
| 13 | (€14 579.01) | 40.20 | €25 002.64 | 13.94 |
| 14 | (€15 623.55) | 42.42 | €25 737.18 | 13.94 |
| 15 | (€16 668.09) | 44.85 | €26 765.54 | 13.94 |
| 16 | (€17 712.63) | 48.08 | €28 969.15 | 13.94 |
| 17 | (€18 757.17) | 51.31 | €31 172.76 | 13.94 |
| 18 | (€19 801.71) | 53.54 | €31 907.30 | 13.94 |
| 19 | (€20 846.25) | 54.75 | €31 172.76 | 9.44 |
| 20 | (€21 890.79) | 55.56 | €29 850.59 | 9.44 |
| 21 | (€22 935.33) | 56.57 | €28 822.24 | 9.44 |
| 22 | (€23 979.87) | 57.78 | €28 087.70 | 9.44 |
| 23 | (€25 024.41) | 59.39 | €27 940.80 | 9.44 |
2.5.2 Evaluating a deployed model with test–control groups
| IV. Model evaluation | IV.2. Evaluating a deployed model: test–control groups |
After the rollout of the direct marketing campaign, the model should be reevaluated in terms of actual response. The campaign responses should be stored as they may be used as the training dataset for subsequent, relevant marketing actions. Besides the model predictability, the effectiveness of the marketing intervention and the design of the campaign should also be tested. Hence, all parameters of the campaign (offer, message, and channel) should also be assessed.
A common schema used for testing both the model and the campaign is displayed in Table 2.10. It involves the grouping of customers according to whether they have been selected by the model and whether they have been finally included in the campaign list.
Table 2.10 The schema used for testing both the model and the offer of a direct marketing campaign
| Selected by model | |||
| Yes | No | ||
| Marketing intervention | Yes | Test group: model group—targeted | Control group: random group—targeted |
| No | Model Holdout group | Random Holdout group | |
The Test group includes those customers selected by the model to be included in the campaign. So, they are the customers of the top percentiles, with the higher propensities, which were chosen to be targeted.
Normally, the campaign list would not contain anyone else. However, we typically also add a Control group to evaluate the model predictability. The Control group is formed by a random sample of nonselected customers with lower scores.
Finally, two additional holdout groups are formed. These groups are not included in the final campaign list and are not reached by the offer. The Model Holdout group is a sample of model-selected probable responders which was sacrificed for our evaluation purposes. The Random selected holdout group is a sample of customers with lower propensities.
The pairwise comparison of groups allows us to evaluate all aspects of both the model and the marketing intervention as shown in Figure 2.52 which presents the recorded response rate of a hypothetical cross-selling campaign.
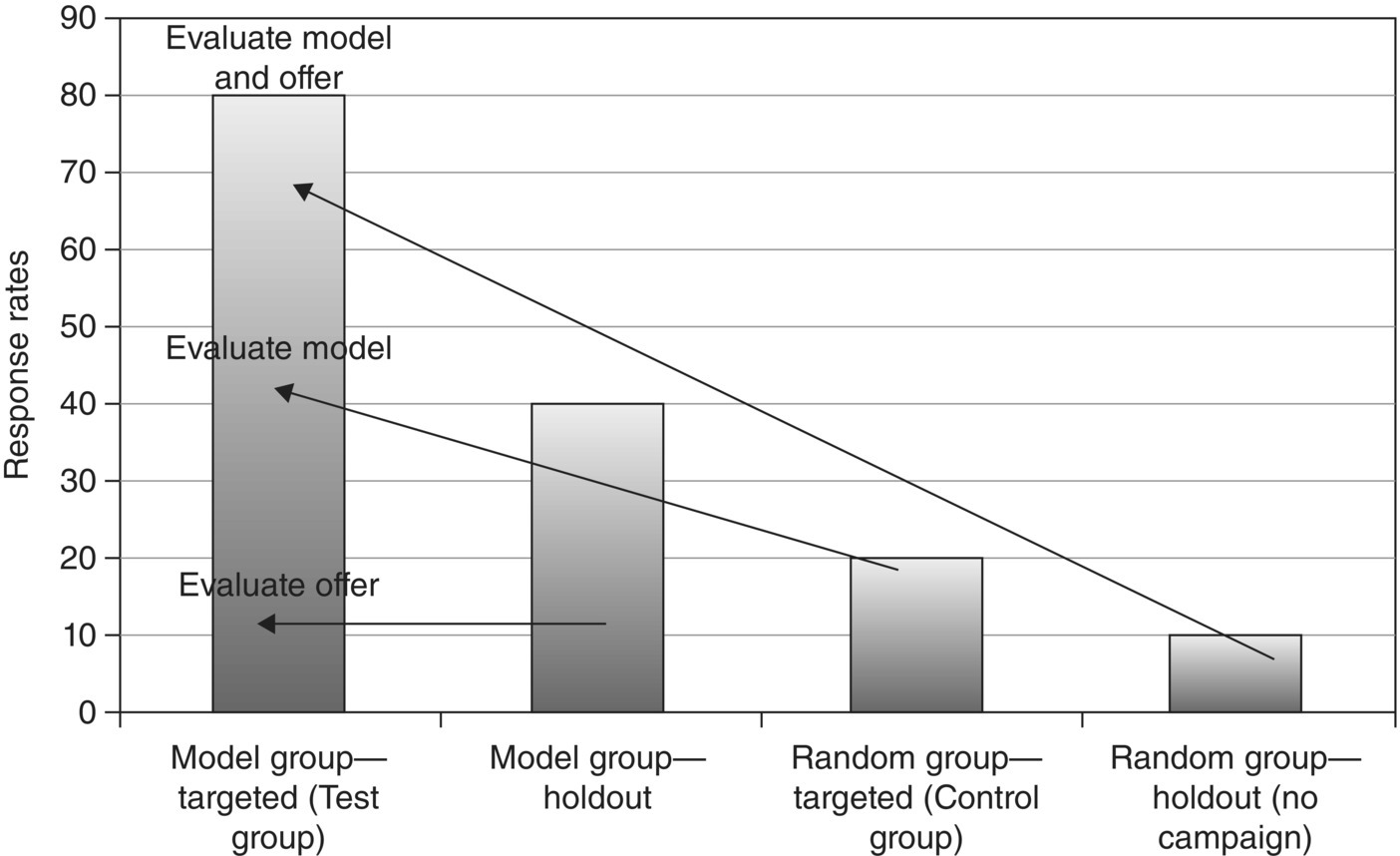
Figure 2.52 The measured response rate of a cross-selling campaign by group
The comparison of the Test versus the Control group assesses the model’s performance on those who received the offer. The data miner hopes to see substantially higher responses in the Test group.
The comparison of the Test group versus the Model Holdout group shows the intervention’s influence/appeal on those scored as probable buyers. The marketer responsible for the campaign design hopes to see a significant higher response percentage in the Test group.
Finally, the comparison of the Test group versus the Random Holdout group reveals the compound effect of both the model and the offer.
The situation is different in the case of a churn model and a retention campaign with offering of incentives to prevent attrition. Churn rates by group are presented in Figure 2.53.

Figure 2.53 The measured churn rate of a retention campaign by group
The model, with no marketing intervention, can be evaluated by comparing the Model Holdout with the Random Holdout group. The offered incentive on high-risk customers can be assessed by comparing the Model targeted group with the Model Holdout group.
2.6 Model deployment
The deployment phase is the last phase of propensity modeling for direct marketing campaigns. Each model, apart from offering insight through the revealed data patterns, can also be used as a scoring engine. The evaluated classifier scores new cases and classifies unseen instances according to their input patterns. Customers predicted to belong to the target class are included in the campaign list. Obviously, all model inputs should also be available in the scoring dataset.
2.6.1 Scoring customers to roll the marketing campaign
| V. Model deployment | V.1. Scoring customers to roll the marketing campaign |
When new data are scored by a classifier, the class prediction along with its confidence, the prediction probability, is estimated. Probabilistic classifiers such as logistic regression and Bayesian networks can estimate the probability of belonging at each class. Most other classifiers can also be modified to return class probabilities. For instance, in the case of Decision Tree models, the class probabilities can be estimated by the class distribution of the terminal nodes.
Hence, classifiers are able to estimate the propensity score for each customer/record. The propensity score denotes the likelihood of belonging to the target class. In binary classification problems, it equals the prediction confidence, if the prediction is the target class, or 1 minus the prediction confidence, if the prediction is the negative class.
The ability to estimate propensities provides the great advantage of being able to rank order customers according to their “response” likelihood. Therefore, instead of focusing on the predicted class, we can study the estimated propensities and use them to tailor the final marketing list. The common approach is to target selected top propensity tiles for our marketing campaigns. By examining the Gains/Profit/ROC charts and tables presented in Section 2.5, marketers can choose the tiles to target. The selected tiles correspond to a specific propensity threshold, a propensity cutoff which is the boundary of the selected tiles. The tiles to target can be tailored to the campaign scope and resources, resulting in widened or more focused lists. This procedure is equivalent to “tweaking” the propensity threshold until we reach the desired campaign size.
IBM SPSS Modeler offers a great tool for campaign selection. After studying a Gains/Profit chart, users can insert a vertical line at the selected tile which automatically determines the underlying propensity threshold. This feature enables the generation of a Select node to filter the records with propensity values above the threshold to be included in the target list.
Here is a word of caution on the use and the interpretation of propensities. As noted in Section 2.3.7, when balancing or case weighting has been applied in the model training phase, the propensity values do not correspond to the actual probabilities. However, propensities are still comparable and can be used to rank customers according to their target likelihood.
2.6.1.1 Building propensity segments
| V.1. Scoring customers to roll the marketing campaign | V.1.1. Building propensity segments |
Estimated propensities can be used for grouping customers in segments, in propensity pools, according to their target class likelihood. For instance, customers can be divided into groups of low, medium, and high churn likelihood as follows:
- High Churn Risk
Comprised of scored customers with churn scores above a selected propensity threshold with business meaning, for example, at least n times higher than the total population churn rate. This segment will be the basic pool for customers to be included in a retention campaign.
- Medium Churn Risk
Includes the customers with churn propensities lower than the cutoff value for the high-risk group but higher than the observed overall population churn rate.
- Low Churn Risk
Includes the customers with the lowest churn propensities, for example, below the observed overall population churn rate.
If the propensity segmentation is based on specific propensity cutoff values (“hard” thresholds) and it is monitored over time, then possible changes in the distribution of the pools should be tracked, investigated, and explained. If alternatively the grouping is based on frequency bins and propensity percentiles (“soft” thresholds, e.g., top 10%, medium 40%, low 50%), then the boundaries of the pools should be monitored over time to identify changes in the propensity distribution.
Propensity scores and respective segmentations can also be combined with other standard segmentation schemes such as value-based segments. For instance, when value segments are cross-examined with churn probability segments, we have the value-at-risk segmentation, a compound segmentation which can help in prioritizing the retention campaign according to each customer’s value and risk of defection.
2.6.2 Designing a deployment procedure and disseminating the results
| V. Model deployment | V.2. Designing a deployment procedure and disseminating the results |
The final stage of propensity modeling includes the design of the deployment procedure and the dissemination of the results and findings. The deployment procedure must be a scheduled, automated, and standardized process which should:
- Gather the required model inputs from the mining datamart and/or all necessary data sources
- Prepare the predictors and apply the generated model to refresh the predictions and scores
- Load the predictions and propensity scores to the appropriate systems of the organization (e.g., data warehouse, campaign management systems) from which they can be accessible and usable for marketing campaigns and insight on the customer base
2.7 Using classification models in direct marketing campaigns
Marketing applications aim at establishing a long-term and profitable relationship with the customers throughout the whole customer lifetime. Classification models can play a significant role in marketing, specifically in the development of targeted marketing campaigns for acquisition, cross-/up-/deep-selling, and retention. Table 2.11 presents a list of these applications along with their business objective.
Table 2.11 Marketing applications and campaigns that can be supported by classification modeling
| Business objective | Marketing application |
| Getting customers | • Acquisition: finding new, profitable customers to increase penetration and to expand the customer base |
| Developing customers | • Cross-selling: promoting and selling additional products/services to existing customers, for instance, selling investment accounts to savings-only customers |
| • Up-selling: switching customers to premium products. By the term premium products, we refer to products more profitable than the ones they already have. An example is the offering of a hold credit card to holders of a normal credit card | |
| • Deep-selling: selling more, increasing usage of the products/services that customers already have. For instance, increasing the balance of existing savings accounts | |
| Retaining customers | • Retention: prevention of voluntary churn, with priority given to presently or potentially valuable customers |
All the aforementioned applications can be supported by classification modeling. A classification model can be applied to identify the target population and recognize customers with increased likelihood for churning or additional purchases. In other words, the target event can be identified and an appropriate classifier can be trained to identify the target class. Targeted campaigns can then be conducted with contact lists based on the generated models.
Setting up a data mining procedure for the needs of these applications requires special attention and cooperation between data miners and marketers. In the next paragraphs, we’ll try to outline the modeling process for the aforementioned applications by tackling issues such as:
- How to identify the modeling population
- Which mining approach to follow
- How to define the target and the scoring population
2.8 Acquisition modeling
Acquisition campaigns aim at the increase of the market share through the expansion of the customer base with customers new to the market or drawn from competitors. In mature markets, there is a fierce competition for acquiring new customers. Each organization incorporates aggressive strategies, massive advertisements, and discounts to attract prospects.
Predictive models can be used to guide the customer acquisition efforts. However, a typical difficulty with acquisition models is the availability of input data. The amount of information available for people who do not yet have a relationship with the organization is generally limited compared to information about existing customers. Without data, you cannot build predictive models. Thus, data on prospects must be available.
The mining approaches which can be applied for the needs of acquisition modeling include the following.
2.8.1.1 Pilot campaign
Mining approach: This approach involves the training of a classification model on a random sample of prospects. We assume that a list of prospects is available with sufficient profiling information. A test campaign is run on a random sample of prospects; their responses are recorded and analyzed with classification modeling in order to identify the profiles associated with increased probability of offer acceptance. The trained models can then be used to score all prospects in terms of acquisition probability. The tricky part in this method is that it requires the rollout of a test campaign to record prospect responses in order to be able to train the respective models.
Modeling population: The modeling population of this approach is the random sample of prospects included in the pilot campaign.
Target population: The target population includes those who responded in the campaign.
Scoring population: The scoring population is consisted of all prospects who didn’t participate in the campaign.
Hints:
- All marketing parameters of the pilot campaign—such as product, message, and channel—must be the same with the ones of the actual designed campaign.
- A problem with pilot campaigns is that you may need large random samples and hence they are expensive. To build a good model, you need at least 100 respondents (positive responses). With an estimated response rate of around 1%, you need at least 10 000 prospects to achieve this.
The modeling phase of this approach is outlined in Figure 2.63.
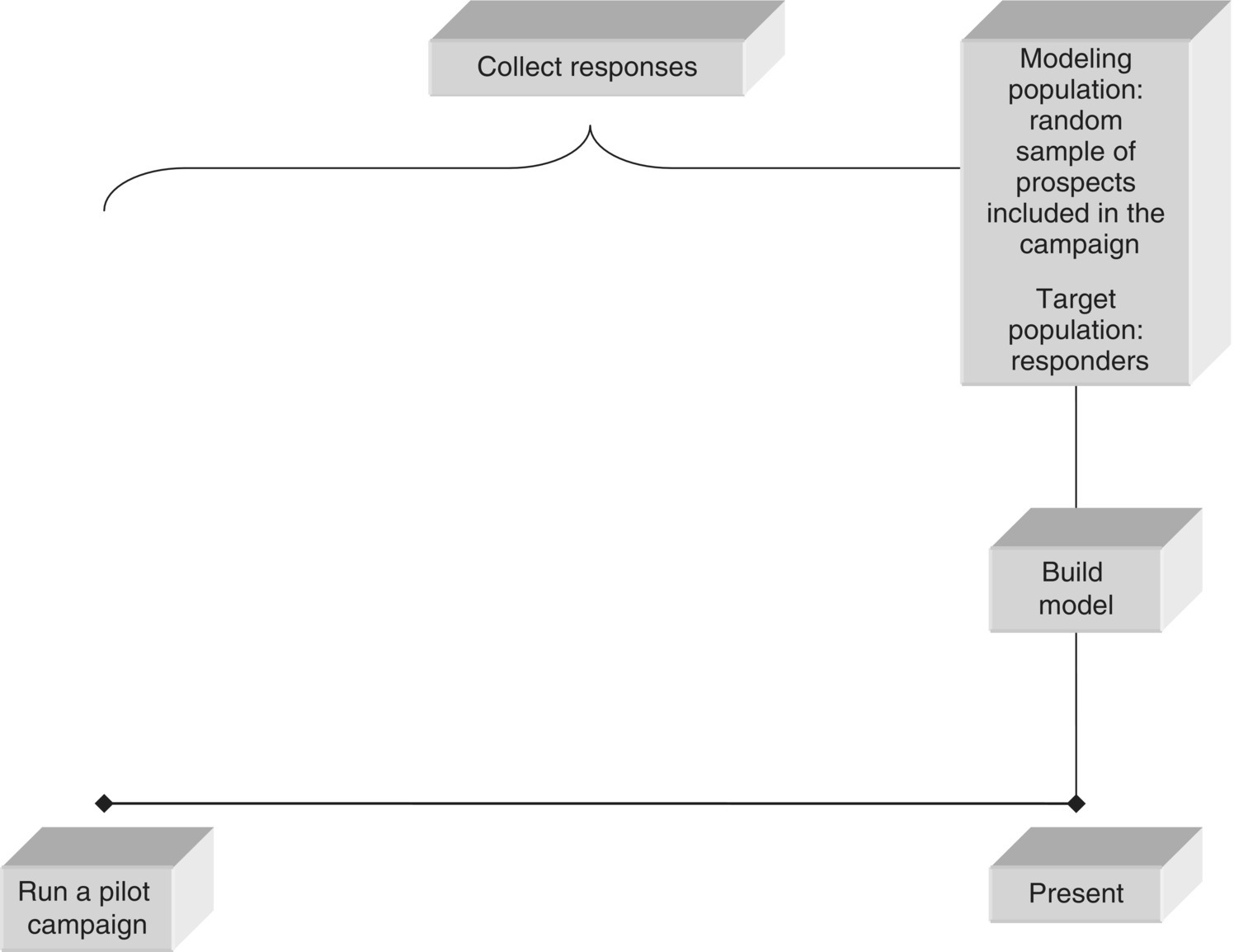
Figure 2.63 The pilot campaign approach for acquisition modeling
2.8.1.2 Profiling of high-value customers
Mining approach: An alternative approach, often combined with the one described earlier, is to mine the list of prospects looking for potentially valuable customers. According to this approach, a classifier is trained on existing customers to identify the key characteristics of the high-value customers. The trained model is then deployed on the prospects to discern the ones with similar characteristics. Propensities now indicate similarity to high-value customers and not likelihood to uptake an acquisition offer.
Modeling population: The model training in this approach is based on existing customers.
Target population: The target population is comprised of high-value customers, for instance, customers belonging to the highest value segments.
Scoring population: The model rules are applied to the list of prospects.
Hints:
- The key to this process is to build a model on existing customers using only fields which are also available for prospects.
- For example, if only demographics are available for prospects, the respective model should be trained only with these data. Acquisition marketing activities could target new customers with the “valuable” profile, and new products related to these profiles could be developed, aiming to acquire new customers with profit possibilities.
The modeling phase of this approach is illustrated in Figure 2.64.
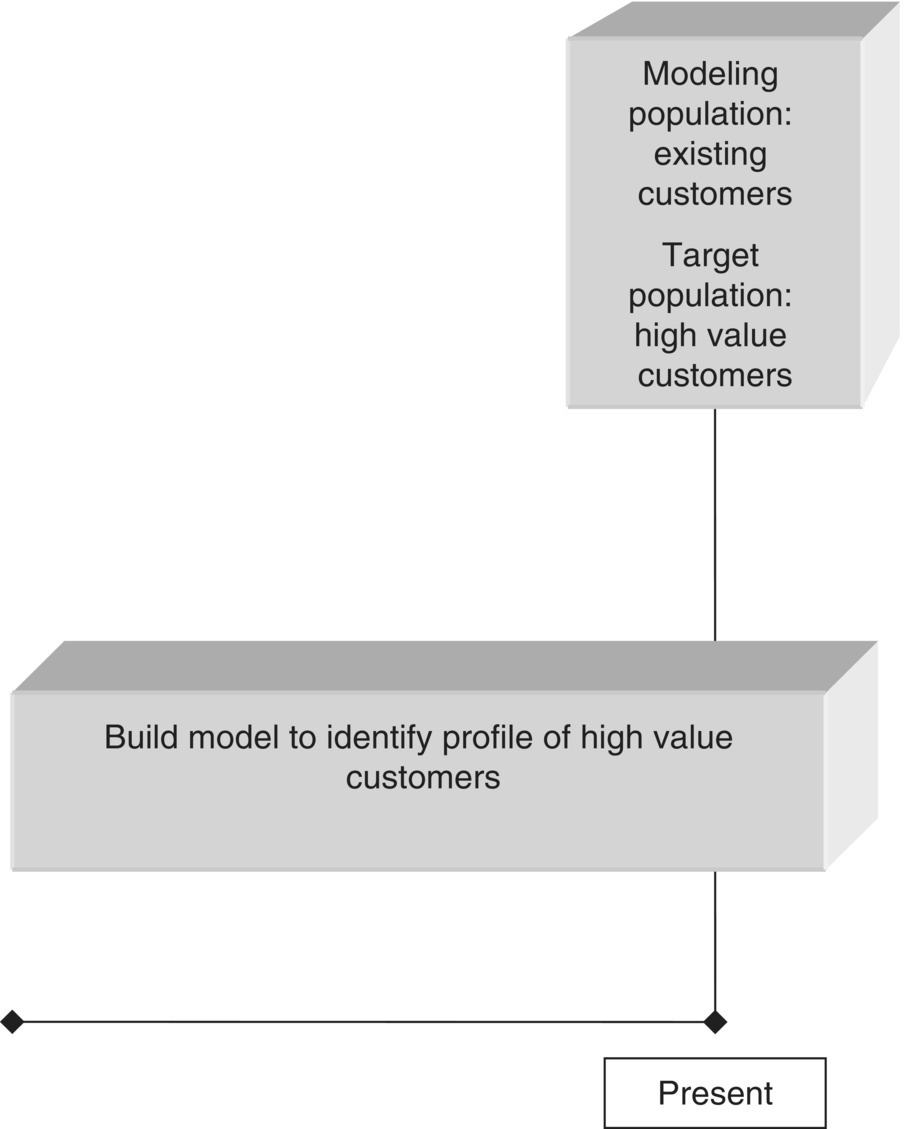
Figure 2.64 The profiling approach for acquisition modeling
2.9 Cross-selling modeling
Cross-selling campaigns aim at selling additional products to existing customers, for instance, promoting investment products to savings-only bank customers or persuading voice-only callers to start using other mobile phone services. These campaigns can be targeted with the use of classification models. The models can estimate the relevant propensities based on the identified data patterns associated with offer acceptance/product uptaking.
The mining approaches which can be used for the identification of probable buyers include the following.
2.9.1.1 Pilot campaign
Mining approach: An outbound test campaign is rolled out on a random sample of existing customers who do not own the product. Responses are mined with classification modeling and the profiles of responders are analyzed. The generated model is then applied to existing customers who do not own the target product/service and hadn’t participated in the test campaign. Customers with increased probability to uptake the offer are identified and included in the large-scale campaign that follows.
Modeling population: The modeling population of this approach is the random sample of existing customers, not owners of the target product, included in the pilot campaign.
Target population: The target population includes those responded positively in the campaign offer and bought the product.
Scoring population: The scoring population includes current customers who do not own the product.
Hints:
- This approach can also be followed in the case of an inbound campaign. During a test period, a test inbound campaign is carried out on a sample of incoming contacts. Their responses are recorded and used for the development of a classifier which then targets incoming cross-selling campaigns.
- As mentioned previously, this approach is demanding in terms of time and resources. However, it is highly effective since it is a simulation of the actual planned campaign, provided of course all aspects—namely, product, message, channel, and direction (inbound/outbound)—are the same with the ones of the designed campaign.
The modeling phase of this approach is outlined in Figure 2.65.
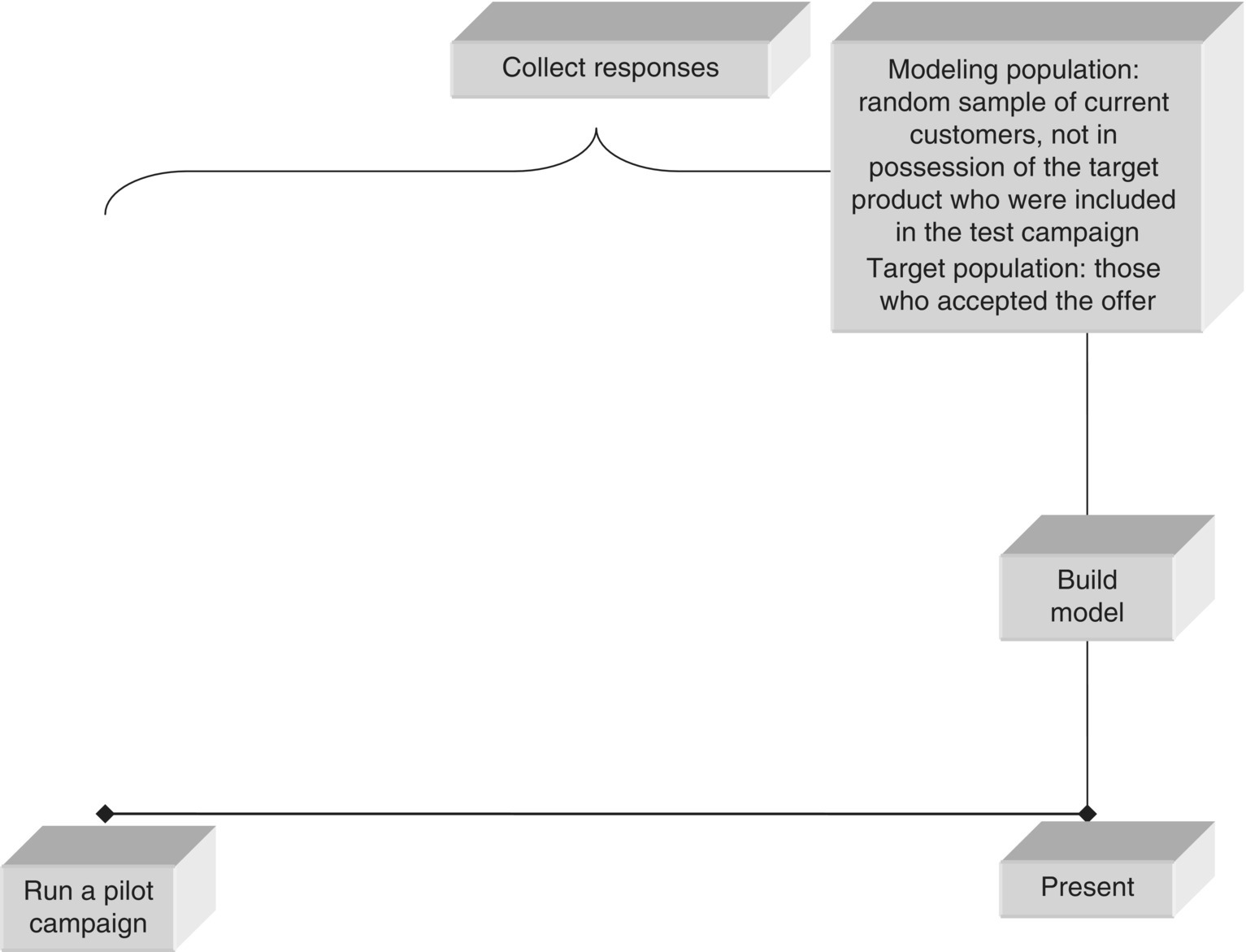
Figure 2.65 The pilot campaign approach for cross-selling modeling
2.9.1.2 Product uptake
Mining approach: Historical data are used and a classifier is trained on customers who did not own the target product at a specific time point in the recent past. The characteristics of the recent “buyers” are identified, and customers with the same outlook who do not currently own the product are selected for inclusion in the campaign.
The “product uptake” approach is effective since it tries to identify the behavioral patterns in the observation period which were followed by the occurrence of the target event, in this case product purchase. However, it requires the building of a customer view in more than one time points. In order to build the model, we must go back and use historical data which summarize the customer behavior at a past time period before the event occurrence. And then we have to move forward in time and use the current customer view in order to score customers with the generated model and estimate their likelihood to uptake the product.
Modeling population: All active customers not owning the target product at the end of the analyzed observation period.
Target population: Those customers who acquired the product in the recent past, within the examined event outcome period.
Scoring population: All active customers not currently owning the product.
Hints:
- This approach is effective; however, it is demanding in terms of data preparation since it involves different time frames. In model training, the customer “signature” is built in the observation period, and it is associated with subsequent product purchase. Then, current “signatures” are used for model deployment.
- The model propensities of this approach denote the likelihood of buying the product in the near future and can be used for targeting a planned cross-selling campaign. However, they are not estimates of offer acceptance probabilities as the ones calculated with the pilot campaign method.
The modeling phase of this approach is illustrated in Figure 2.66.
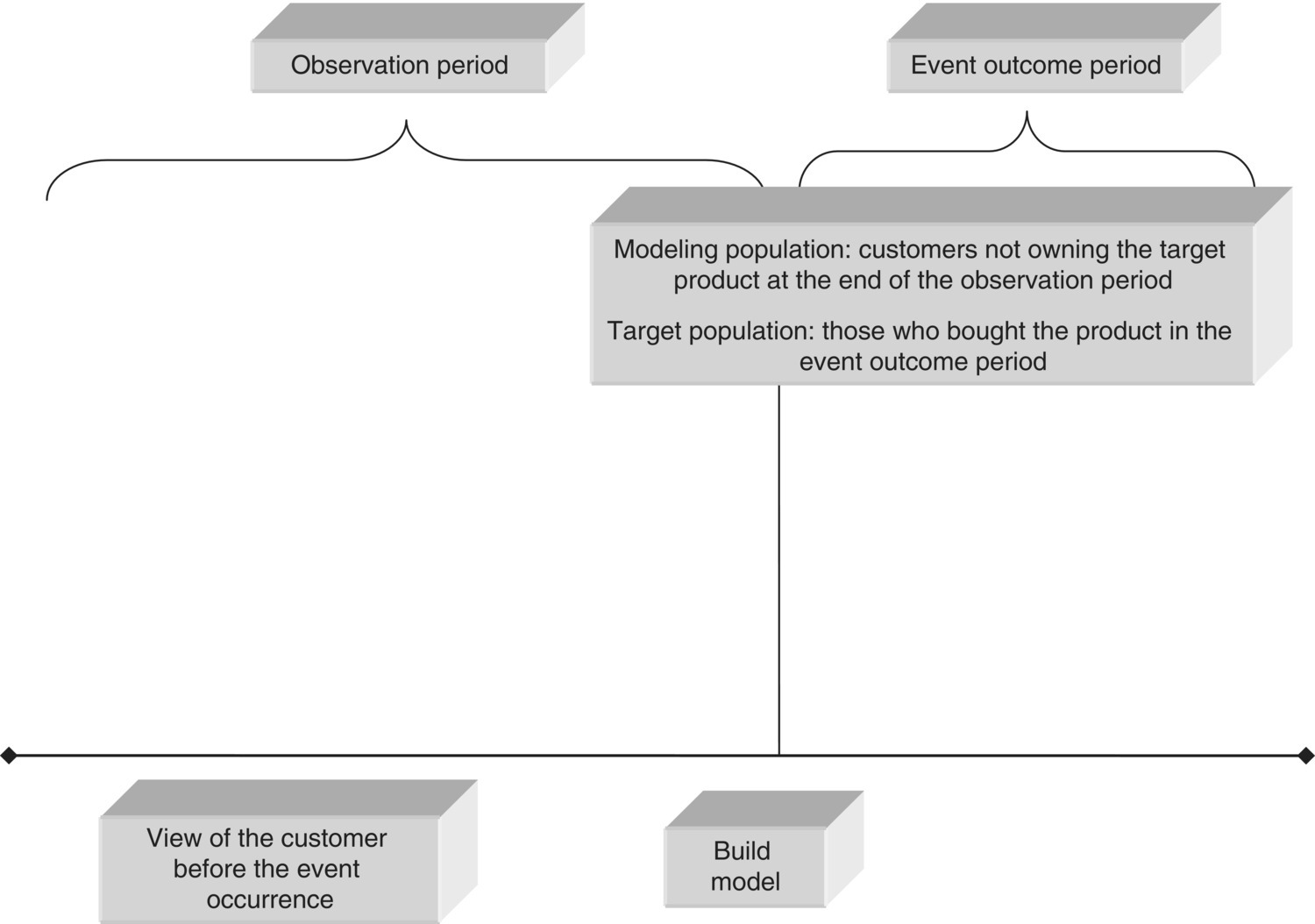
Figure 2.66 The product uptake approach for cross-selling modeling
2.9.1.3 Profiling of owners
Mining approach: A model is trained on all active customers and identifies the data patterns and characteristics associated with ownership of the target product. The profile of owners (and preferably heavy users) of the target product is outlined. Customers with the same profile are identified among the population of nonowners, and they are included in the planned cross-selling campaign.
Modeling population: All currently active customers.
Target population: Customers owning (and preferably heavily using) the product to be promoted.
Scoring population: All nonowners of the product.
Hints:
- This approach is appealing due to its straightforwardness and simple data preparation. It does not require distinct observation and outcome windows and the examination of the customer view in different time periods. However, this comes at a cost. The predictive efficiency of this approach is limited since it takes into account the current profile of customers instead of the characteristics prior the purchase event who most likely leaded to the purchase decision.
The modeling phase of this approach is presented in Figure 2.67.
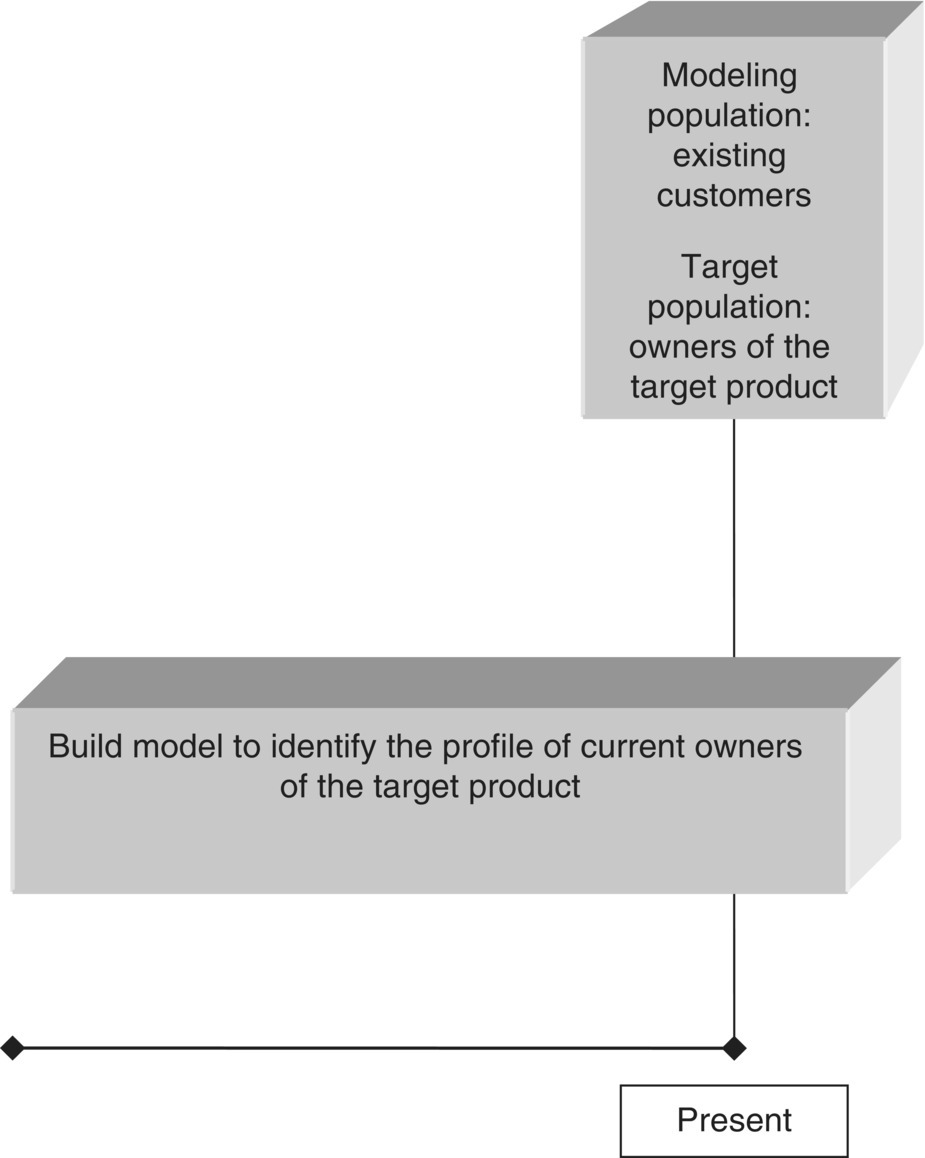
Figure 2.67 The profiling of owners approach for cross-selling modeling
2.10 Offer optimization with next best product campaigns
When planning an outbound or an inbound cross-selling campaign, the marketers of the organization should take into account the customer eligibility for the promoted product. Customers who already have the product or have stated that they are not interested in it will have to be left out. So are customers with a bad risk score.
But what happens when customers are eligible for more than one product? How should the organization choose the best product to offer them? The answer is through offer optimization. Offer optimization refers to using analytics and propensity models to identify the products or services that customers are most likely to be interested in for their next purchase. But that’s only half the equation. The next best offer strategy should also determine the best offer which will improve the customer lifetime value and will provide value to the organization.
In simple words, each customer should be contacted with the most profitable and most likely to accept product which currently does not own.
This approach requires the development of individual cross-selling models for the different products/product groups. Propensities are combined with the projected net present value (NPV) of each product to estimate the propensity value of each offer as shown in the formula below:
The offer cost is the sum of all costs related with the promotion of the product including incentives, cost of the mail piece, etc.
The product uptake propensity is estimated with a respective cross-selling model based on the approach described in Section 2.9.
The projected NPV should be estimated by the product manager. A product-level average NPV is based on the average profits of existing customers. It is calculated as the sum of the NPV over n years divided by the number of initial customers.
The best offer for each customer is simply the one which maximizes the estimated propensity value as shown in Figure 2.68.
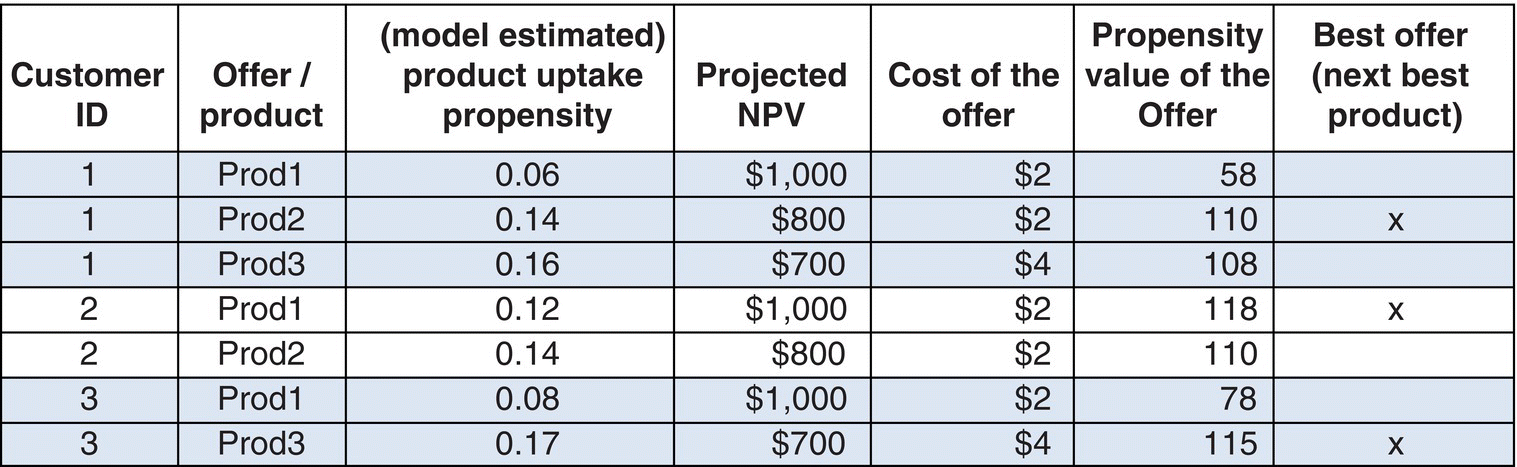
Figure 2.68 The next best offer approach
2.11 Deep-selling modeling
The scope of deep-selling campaigning is to increase the usage of existing products. In other words, they aim at selling more of the same product/service to the customer. As an example, consider the case of a mobile phone network operator which tries to increase the outgoing phone usage (number of minutes of outgoing calls) of its customer base or a bank who targets infrequent users of credit cards, intending to increase their usage. The mining approaches which can be used for the development of deep-selling models are similar to the ones presented in Section 2.9 for cross-selling.
2.11.1.1 Pilot campaign
Mining approach: Customers owning but not heavily using the promoted product are identified, and a random sample of them is drawn to be included in the test campaign. Those selected receive an offer which promotes the usage increase, and their responses are collected and analyzed. Those who increased their usage comprise the target population. The trained model is then deployed on “infrequent” users who were left out of the pilot campaign, and those scored with propensities above the selected threshold are targeted.
Modeling population: The modeling population of this approach is the random sample of owners but “infrequent” users of the target product, included in the pilot campaign.
Target population: The target population includes those who increased their usage after receiving the respective offer.
Scoring population: “Infrequent” users who didn’t participate in the test campaign.
Hints:
- As in the case of cross-selling models, this approach can also be followed in the case of inbound campaigns.
The modeling phase of this approach is outlined in Figure 2.69.

Figure 2.69 The pilot campaign approach for deep-selling modeling
2.11.1.2 Usage increase
Mining approach: A historical view of the customers is assembled, and customers owning but not heavily using the deep-sell product at the end of the observation period are analyzed. Those who substantially increased their usage in the event outcome period are flagged as “positive” cases and form the target class of the classification model. The model is then deployed on current owners/low users of the product. Those scored with high deep-selling propensities are included in the campaign that follows. The “usage increase” approach, as all approaches based on “historical views” of customers, is effective, yet it presents difficulties in its implementation compared to plain profiling approaches.
Modeling population: All owners/low users of the target product at the end of the observation period.
Target population: Those customers who increased their product usage in the outcome period that followed.
Scoring population: All active customers currently owning but infrequently using the deep-sell product.
Hints:
- An issue which deserves attention and the close collaboration of data miners with the marketers is, as always, the definition of the modeling population and of the target event and/class—in other words, the definition of what constitutes low and heavy usage and what signifies a substantial usage increase. The usage increase can be defined in terms of absolute or relative increase compared to the historical period analyzed.
The modeling phase of this approach is illustrated in Figure 2.70.
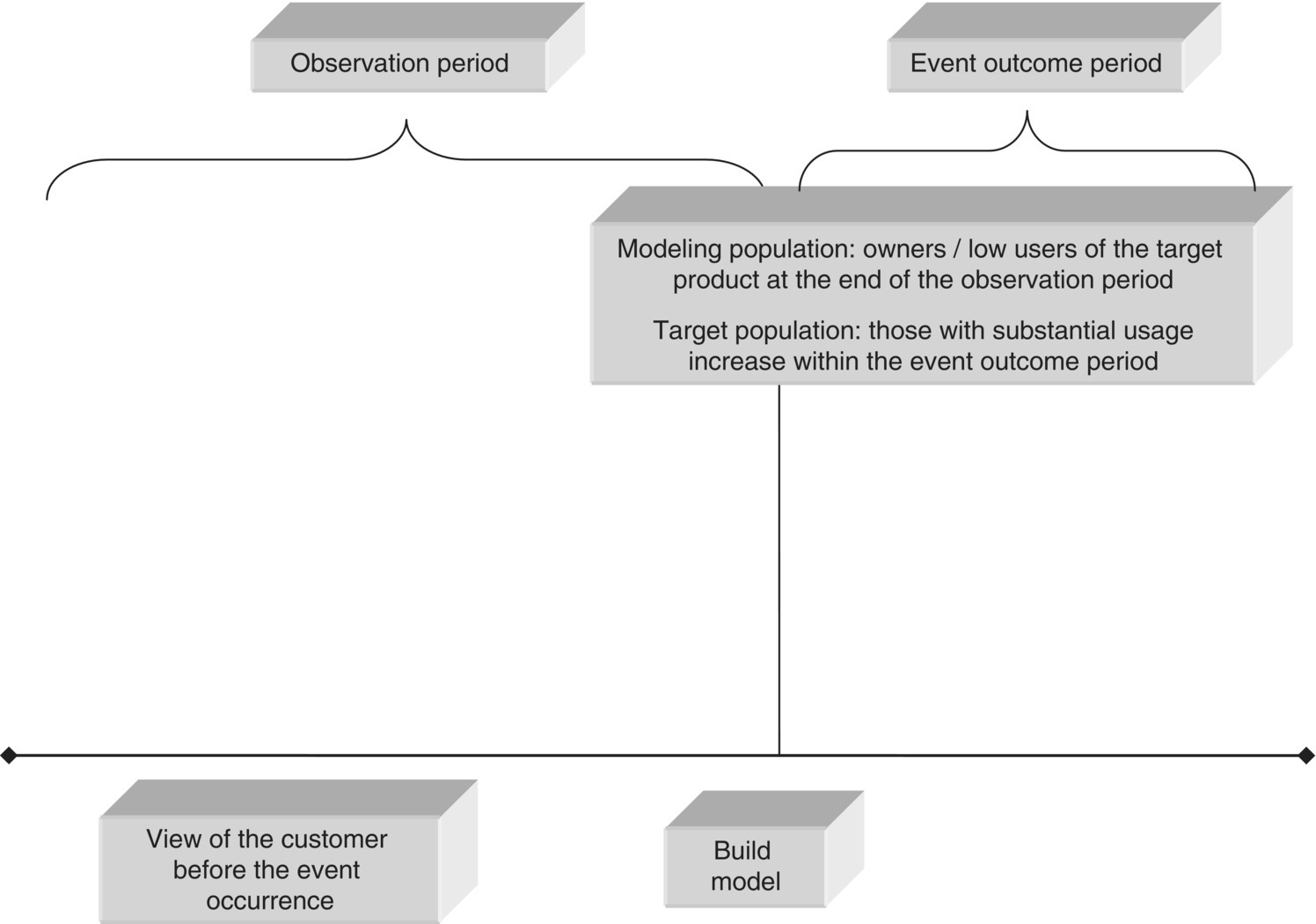
Figure 2.70 The product usage increase approach for deep-selling modeling
2.11.1.3 Profiling of customers with heavy product usage
Mining approach: A model is built on all owners of the deep-sell product which is trained to discern heavy from low users. The drivers of heavy product usage are discovered and clones of heavy users are identified among low users. These customers (low users predicted as heavy users) are targeted by the deep-selling campaign.
Modeling population: All active customers currently owning the target product.
Target population: Those heavily using the product/service to be promoted.
Scoring population: All low users of the product.
The modeling phase of this approach is illustrated in Figure 2.71.
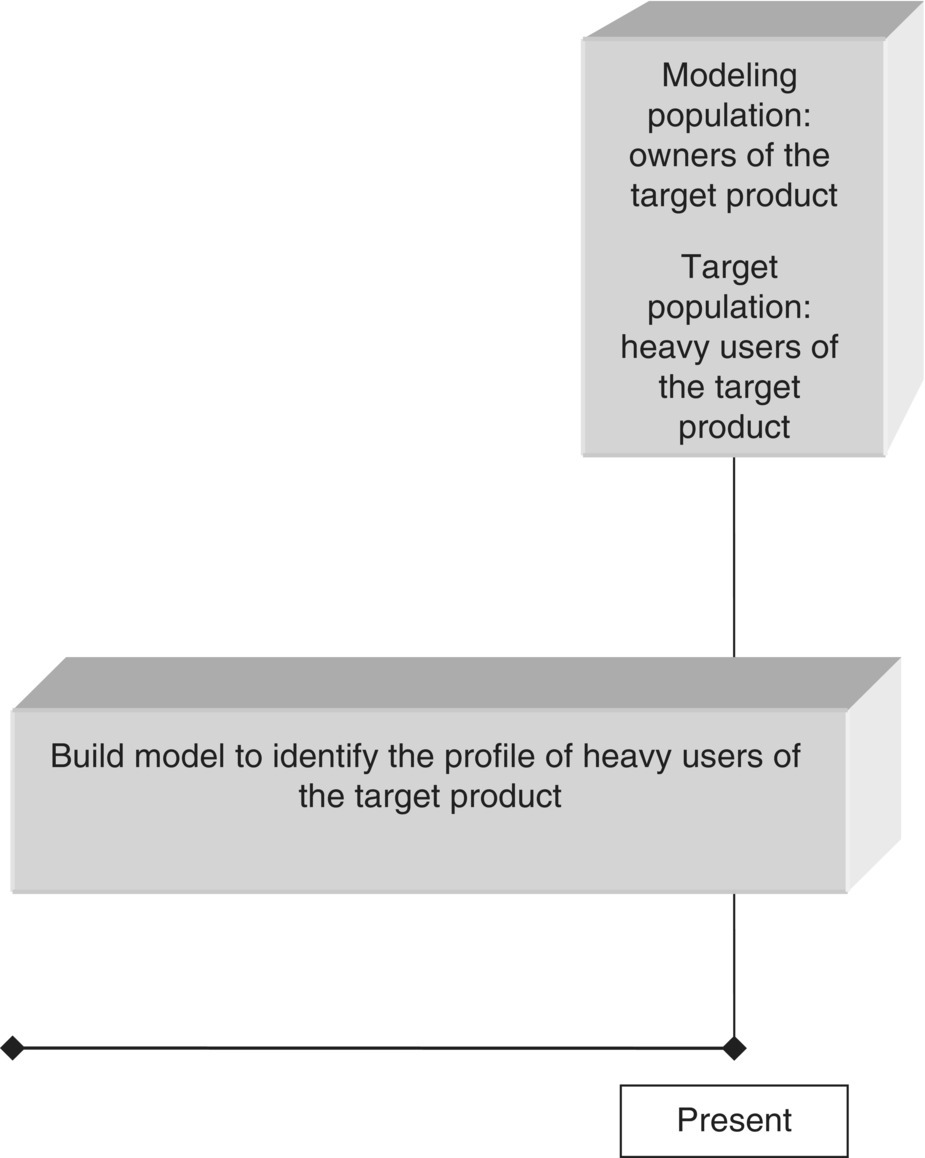
Figure 2.71 The profiling of customers with high usage approach for deep-selling modeling
2.12 Up-selling modeling
The goal of an up-selling campaign is the upgrading of owned products. Existing customers are offered a better and more profitable product than the one they already own. Hence, these campaigns aim at switching customers to “premium” products, and they can be supported by corresponding classification models which estimate the “upgrade” propensities.
For instance, an up-selling campaign of a mobile network operator might address prepaid or basic rate plan customers, trying to promote a postpaid contract or an upgraded rate plan. Ideally, the offered rate plan should be tailored to the customer behaviors and therefore satisfy their needs. At the same time, it should aim at growing and tightening the customer—operator relationship, allowing an immediate or prospect profit increase. Likewise, a gold credit card can be offered to basic cardholders of a bank.
The mining approaches appropriate for the design of up-selling models are once again similar to the ones presented in Section 2.9 for cross-selling.
2.12.1.1 Pilot campaign
Mining approach: A classifier is built on a sample of “basic” customers who were randomly chosen and received an up-selling offer for the target “premium” product. The model is trained on the recorded responses of the test-campaign list. Those who “switched” to the “premium” product are the positive instances and comprise the target population. The data patterns associated with offer acceptance are identified and captured by the generated model which is then deployed on the mass population of “basic” product owners. An “upgrade” propensity is estimated for all the scored customers, and a large-scale up-selling campaign is then conducted using these propensities.
Modeling population: The modeling population of this approach is the random sample of owners of the “basic” product.
Target population: The target population is comprised of those who accepted the offer and agreed to “upgrade” their product.
Scoring population: “Basic” product owners who didn’t participate in the test campaign and who obviously don’t have the “premium” product.
Hints:
- As in the case of cross-selling models, this approach can also be modified and applied in the case of inbound campaigns.
- As opposed to deep- and cross-selling, up-selling campaigns aim at widening the relationship with existing customers by upgrading their current products instead of selling more of the same product or additional products.
The modeling phase of this approach is outlined in Figure 2.72.

Figure 2.72 The pilot campaign approach for up-selling modeling
2.12.1.2 Product upgrade
Mining approach: This approach requires historical data and a historical view of the customers. A classifier is built on customers who owned the “basic” product/service at a specific time point in the recent past (observation period). The generated model is trained to identify the data patterns associated with upgrading to the premium product during the event outcome period. The scoring phase is based on the current view of the customers. The generated model is deployed on current owners of the entry-level product, and those with relatively high upgrade propensities are included in the campaign list. The “product upgrade” approach is analogous to the “product uptake” and the “usage increase” approaches presented for cross-/deep-selling models.
Modeling population: All owners of the “basic” product/service at the end of the observation period.
Target population: Those customers who upgraded to the “premium” target product within the event outcome period.
Scoring population: All customers who currently own the “basic” but not the “premium” product.
The modeling phase of this approach is illustrated in Figure 2.73.

Figure 2.73 The product upgrade approach for up-selling modeling
2.12.1.3 Profiling of “premium” product owners
Mining approach: A classification model is built on the current view of both the “basic” and the “premium” product owners. The generated model discerns the data patterns associated with ownership of the target up-sell product. The scoring population is consisted of all owners of the “basic” product. The final campaign list includes all the “basic” product owners who are “clones” of the “premium” product owners. That is, although they do not own the target product, they present similar characteristics with its owners, and consequently, they are scored with increased “premium” product ownership propensities.
Modeling population: All current owners of the “basic” and the “premium” target product.
Target population: Owners of the “premium” target product.
Scoring population: All owners of the “basic” product.
The modeling phase of this approach is presented in Figure 2.74.
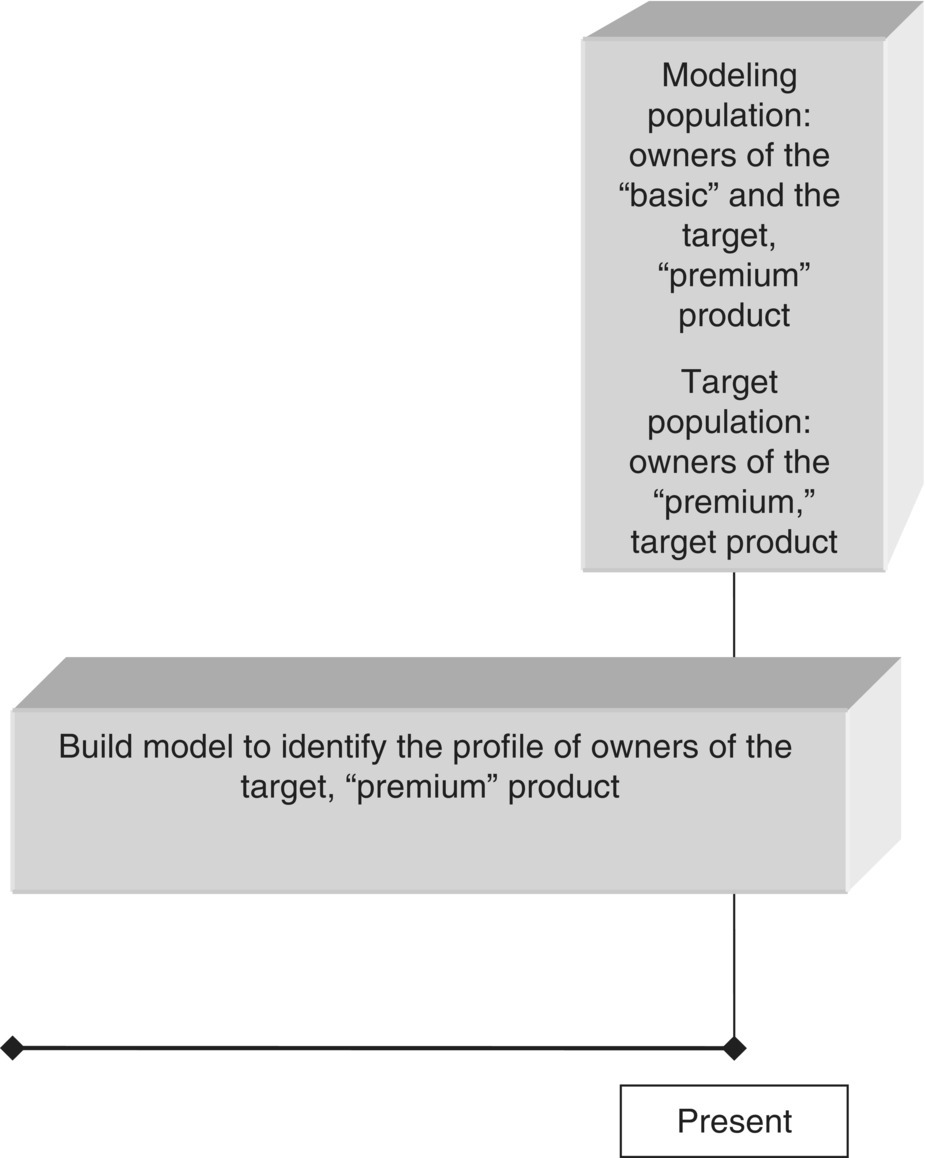
Figure 2.74 The profiling of “premium” product owners approach for up-selling modeling
2.13 Voluntary churn modeling
The CRM scope is to establish, grow, and retain the organization–customer relationship. Acquisition campaigns cover the part of attracting customers, while cross/deep/up-selling campaigns deal with widening and upgrading the relationship with existing customers. Retention campaigns, on the other hand, target at preventing the leak of customers to the competition. The prevention of voluntary churn is typically focused on currently or potentially valuable customers. These campaigns can be targeted with the development of data mining models, known as churn or attrition models, which analyze the behavior of churned customers and identify data patterns and signals associated with increased probability to leave.
These models should be based on historical data which should adequately summarize the customer behavior and characteristics at an observation period preceding the churn event.
Mining approach: A classification model is trained on customers that were active at the end of the observation period analyzed. These customers comprise the training population. The target population is consisted of those that have voluntary churned (for instance, applied for disconnection) within the event outcome period. The current view of the customers is used in the model deployment phase in which customers presently active are scored according to the model and their churn propensities are estimated.
Modeling population: Customers active at the end of the observation period.
Target population: Those who left within the event outcome period.
Scoring population: All presently active customers.
The modeling phase of this approach is outlined in Figure 2.75.
Hints:
- A more sophisticated approach would limit the training and consequently the scoring population only to customers with substantial value for the organization. With this approach, trivial customers are excluded from the retention campaign.
- Typically, a latency period of 1-3 months is reserved for scoring and campaign preparation as described in 2.2.3.4. Data from the latency period are not used as inputs in the model.

Figure 2.75 The approach for building a voluntary churn model
2.14 Summary of what we’ve learned so far: it’s not about the tool or the modeling algorithm. It’s about the methodology and the design of the process
Classification modeling requires more than a good knowledge of the respective algorithms. Its success strongly depends on the overall design instead of the selected software and algorithm. The conclusion after experimenting with the software tools presented in this book (IBM SPSS Modeler, Data Mining for Excel, and RapidMiner) is that it’s mainly a matter of the roadmap than of the selected vehicle. All three tools provide excellent modeling algorithms to accurately classify unseen cases, but in the end, classification modeling, and analytics in general, is more than identification of data patterns. It’s about the design of the process.
That’s why in this chapter we’ve tried to present a concise and clear step-by-step guide on designing a classification modeling process. We outlined the significance of selecting the appropriate mining approach and focused on the design of the modeling process, dealing with critical issues such as selecting the modeling/analysis level, the target event and population, and the modeling time frames. We provided an overview of the data management tasks typically required to prepare the data for modeling. And we explained the three modeling phases, namely, model training, evaluation, and deployment.
But above all, since this book is mainly addressed to data mining practitioners who want to use analytics for optimizing their everyday business operations, we’ve concluded this chapter by linking the proposed methodology with real-world applications. We tried to show how this proposed methodology can be applied in real business problems by providing examples for specific direct marketing applications.