
Now we will move forward with MapReduce by learning a very common and easy example of word count. The goal of this example is to calculate how many times each word occurs in the provided documents. These documents can be considered as input to MapReduce's file.
In this example, we already have a set of text files—we want to identify the frequency of all the unique words existing in the files. We will get this by designing the Hadoop MapReduce phase.
In this section, we will see more on Hadoop MapReduce programming using Hadoop MapReduce's old API. Here we assume that the reader has already set up the Hadoop environment as described in Chapter 1, Getting Ready to Use R and Hadoop. Also, keep in mind that we are not going to use R to count words; only Hadoop will be used here.
Basically, Hadoop MapReduce has three main objects: Mapper, Reducer, and Driver. They can be developed with three Java classes; they are the Map class, Reduce class, and Driver class, where the Map class denotes the Map phase, the Reducer class denotes the Reduce phase, and the Driver class denotes the class with the main() method to initialize the Hadoop MapReduce program.
In the previous section of Hadoop MapReduce fundamentals, we already discussed what Mapper, Reducer, and Driver are. Now, we will learn how to define them and program for them in Java. In upcoming chapters, we will be learning to do more with a combination of R and Hadoop.
Tip
There are many languages and frameworks that are used for building MapReduce, but each of them has different strengths. There are multiple factors that by modification can provide high latency over MapReduce. Refer to the article 10 MapReduce Tips by Cloudera at http://blog.cloudera.com/blog/2009/05/10-mapreduce-tips/.
To make MapReduce development easier, use Eclipse configured with Maven, which supports the old MapReduce API.
Let's see the steps to run a MapReduce job with Hadoop:
- In the initial steps of preparing Java classes, we need you to develop a Hadoop MapReduce program as per the definition of our business problem. In this example, we have considered a word count problem. So, we have developed three Java classes for the MapReduce program; they are
Map.java,Reduce.java, andWordCount.java, used for calculating the frequency of the word in the provided text files.Map.java: This is the Map class for the word count Mapper.// Defining package of the class package com.PACKT.chapter1; // Importing java libraries import java.io.*; importjava.util.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; // Defining the Map class public class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>{ //Defining the map method – for processing the data with // problem specific logic public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { // For breaking the string to tokens and convert them to lowercase StringTokenizer st = new StringTokenizer(value.toString().toLowerCase()); // For every string tokens while(st.hasMoreTokens()) { // Emitting the (key,value) pair with value 1. output.collect(new Text(st.nextToken()), new IntWritable(1)); } } }Reduce.java: This is the Reduce class for the word count Reducer.// Defining package of the class package com.PACKT.chapter1; // Importing java libraries import java.io.*; importjava.util.*; import org.apache.hadoop.io.*; importorg.apache.hadoop.mapred.*; // Defining the Reduce class public class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { // Defining the reduce method for aggregating the //generated output of Map phase public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException { // Setting initial counter value as 0 int count = 0; // For every element with similar key attribute, increment its counter value by adding 1. while(values.hasNext()) { count += values.next().get(); } // Emitting the (key,value) pair output.collect(key, new IntWritable(count)); } }WordCount.java: This is the task of Driver in the Hadoop MapReduce Driver main file.//Defining package of the class package com.PACKT.chapter1; // Importing java libraries import java.io.*; importorg.apache.hadoop.fs.*; import org.apache.hadoop.io.*; importorg.apache.hadoop.mapred.*; importorg.apache.hadoop.util.*; importorg.apache.hadoop.conf.*; //Defining wordcount class for job configuration // information public class WordCount extends Configured implements Tool{ publicint run(String[] args) throws IOException{ JobConfconf = new JobConf(WordCount.class); conf.setJobName("wordcount"); //For defining the output key format conf.setOutputKeyClass(Text.class); //For defining the output value format conf.setOutputValueClass(IntWritable.class); // For defining the Mapper class implementation conf.setMapperClass(Map.class); // For defining the Reducer class implementation conf.setReducerClass(Reduce.class); // For defining the type of input format conf.setInputFormat(TextInputFormat.class); // For defining the type of output format conf.setOutputFormat(TextOutputFormat.class); // For defining the command line argument sequence for // input dataset path FileInputFormat.setInputPaths(conf, new Path(args[0])); // For defining the command line argument sequence for // output dataset path FileOutputFormat.setOutputPath(conf, new Path(args[1])); // For submitting the configuration object JobClient.runJob(conf); return 0; } // Defining the main() method to start the execution of // the MapReduce program public static void main(String[] args) throws Exception { intexitCode = ToolRunner.run(new WordCount(), args); System.exit(exitCode); } }
- Compile the Java classes.
// create a folder for storing the compiled classes hduser@ubuntu:~/Desktop/PacktPub$ mkdir classes // compile the java class files with classpath hduser@ubuntu:~/Desktop/PacktPub$ javac -classpath /usr/local/hadoop/hadoop-core-1.1.0.jar:/usr/local/hadoop/lib/commons-cli-1.2.jar -d classes *.java
- Create a
.jarfile from the compiled classes.hduser@ubuntu:~/Desktop/PacktPub$ cd classes/ // create jar of developed java classes hduser@ubuntu:~/Desktop/PacktPub/classes$ jar -cvf wordcount.jar com
- Start the Hadoop daemons.
// Go to Hadoop home Directory hduser@ubuntu:~$ cd $HADOOP_HOME // Start Hadoop Cluster hduser@ubuntu:/usr/local/hadoop$ bin/start-all.sh
- Check all the running daemons.
// Ensure all daemons are running properly hduser@ubuntu:/usr/local/hadoop$ jps
- Create the HDFS directory
/wordcount/input/.// Create Hadoop directory for storing the input dataset hduser@ubuntu:/usr/local/hadoop$ bin/Hadoop fs -mkdir /wordcount/input
- Extract the input dataset to be used in the word count example. As we need to have text files to be processed by the word count example, we will use the text files provided with the Hadoop distribution (
CHANGES.txt,LICENSE.txt,NOTICE.txt, andREADME.txt) by copying them to the Hadoop directory. We can have other text datasets from the Internet input in this MapReduce algorithm instead of using readymade text files. We can also extract data from the Internet to process them, but here we are using readymade input files. - Copy all the text files to HDFS.
// To copying the text files from machine's local // directory in to Hadoop directory hduser@ubuntu:/usr/local/hadoop$ bin/hadoopfs -copyFromLocal $HADOOP_HOME/*.txt /wordcount/input/
- Run the Hadoop MapReduce job with the following command:
// Command for running the Hadoop job by specifying jar, main class, input directory and output directory. hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar wordcount.jar com.PACKT.chapter1.WordCount /wordcount/input/ /wordcount/output/
- This is how the final output will look.
// To read the generated output from HDFS directory hduser@ubuntu:/usr/local/hadoop$ bin/hadoopfs -cat /wordcount/output/part-00000
Tip
During the MapReduce phase, you need to monitor the job as well as the nodes. Use the following to monitor MapReduce jobs in web browsers:
- localhost:50070: NameNode Web interface (for HDFS)
localhost:50030: JobTracker Web interface (for MapReduce layer)localhost:50060: TaskTracker Web interface (for MapReduce layer)
In this section, we will learn how to monitor as well as debug a Hadoop MapReduce job without any commands.
This is one of the easiest ways to use the Hadoop MapReduce administration UI. We can access this via a browser by entering the URL http://localhost:50030 (web UI for the JobTracker daemon). This will show the logged information of the Hadoop MapReduce jobs, which looks like following screenshot:

Map/Reduce administration
Here we can check the information and status of running jobs, the status of the Map and Reduce tasks of a job, and the past completed jobs as well as failed jobs with failed Map and Reduce tasks. Additionally, we can debug a MapReduce job by clicking on the hyperlink of the failed Map or Reduce task of the failed job. This will produce an error message printed on standard output while the job is running.
In this section, we will see how to explore HDFS directories without running any Bash command. The web UI of the NameNode daemon provides such a facility. We just need to locate it at http://localhost:50070.
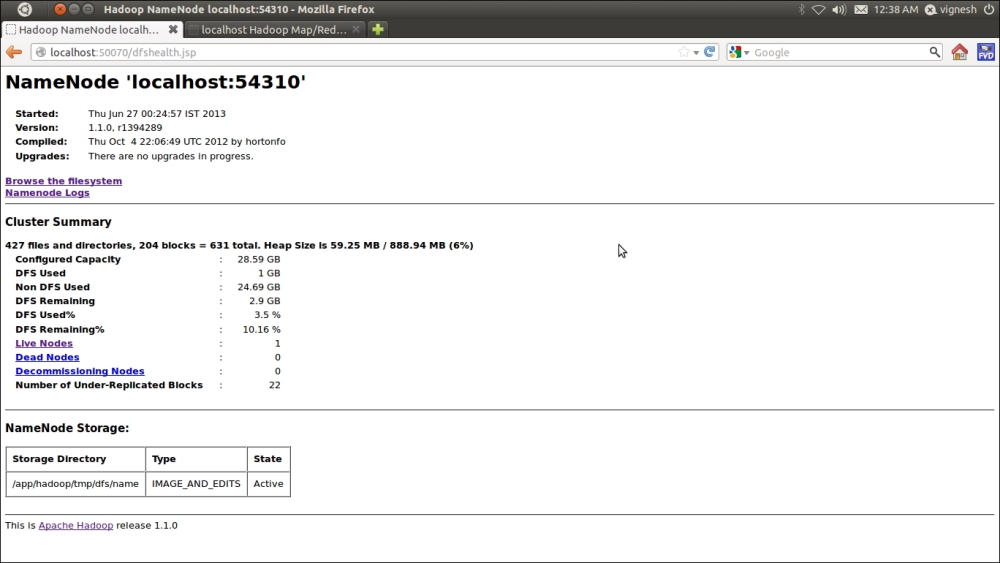
NameNode administration
This UI enables us to get a cluster summary (memory status), NameNode logs, as well as information on live and dead nodes in the cluster. Also, this allows us to explore the Hadoop directory that we have created for storing input and output data for Hadoop MapReduce jobs.
Until now we have learned what MapReduce is and how to code it. Now, we will see some common MapReduce problem definitions that are used for business analytics. Any reader who knows MapReduce with Hadoop will easily be able to code and solve these problem definitions by modifying the MapReduce example for word count. The major changes will be in data parsing and in the logic behind operating the data. The major effort will be required in data collection, data cleaning, and data storage.
- Server web log processing: Through this MapReduce definition, we can perform web log analysis. Logs of the web server provide information about web requests, such as requested page's URL, date, time, and protocol. From this, we can identify the peak load hours of our website from the web server log and scale our web server configuration based on the traffic on the site. So, the identification of no traffic at night will help us save money by scaling down the server. Also, there are a number of business cases that can be solved by this web log server analysis.
- Web analytics with website statistics: Website statistics can provide more detailed information about the visitor's metadata, such as the source, campaign, visitor type, visitor location, search keyword, requested page URL, browser, and total time spent on pages. Google analytics is one of the popular, free service providers for websites. By analyzing all this information, we can understand visitors' behavior on a website. By descriptive analytics, we can identify the importance of web pages or other web attributes based on visitors' addiction towards them. For an e-commerce website, we can identify popular products based on the total number of visits, page views, and time spent by a visitor on a page. Also, predictive analytics can be implemented on web data to predict the business.
- Search engine: Suppose we have a large set of documents and want to search the document for a specific keyword, inverted indices with Hadoop MapReduce will help us find keywords so we can build a search engine for Big Data.
- Stock market analysis: Let's say that we have collected stock market data (Big Data) for a long period of time and now want to identify the pattern and predict it for the next time period. This requires training of all historical datasets. Then we can compute the frequency of the stock market changes for the said time period using several machine-learning libraries with Hadoop MapReduce.
Also, there are too many possible MapReduce applications that can be applied to improve business cost.