
Now, we understood what Hadoop streaming is and how it can be called with Hadoop generic as well as streaming options. Next, it's time to know how an R script can be developed and run with R. For this, we can consider a better example than a simple word count program.
The four different stages of MapReduce operations are explained here as follows:
- Understanding a MapReduce application
- Understanding how to code a MapReduce application
- Understanding how to run a MapReduce application
- Understanding how to explore the output of a MapReduce application
Problem definition: The problem is to segment a page visit by the geolocation. In this problem, we are going to consider the website http://www.gtuadmissionhelpline.com/, which has been developed to provide guidance to students who are looking for admission in the Gujarat Technological University. This website contains the college details of various fields such as Engineering (diploma, degree, and masters), Medical, Hotel Management, Architecture, Pharmacy, MBA, and MCA. With this MapReduce application, we will identify the fields that visitors are interested in geographically.
For example, most of the online visitors from Valsad city visit the pages of MBA colleges more often. Based on this, we can identify the mindset of Valsad students; they are highly interested in getting admissions in the MBA field. So, with this website traffic dataset, we can identify the city-wise interest levels. Now, if there are no MBA colleges in Valsad, it will be a big issue for them. They will need to relocate to other cities; this may increase the cost of their education.
By using this type of data, the Gujarat Technological University can generate informative insights for students from different cities.
Input dataset source: To perform this type of analysis, we need to have the web traffic data for that website. Google Analytics is one of the popular and free services for tracking an online visitor's metadata from the website. Google Analytics stores the web traffic data in terms of various dimensions ad metrics. We need to design a specific query to extract the dataset from Google Analytics.
Input dataset: The extracted Google Analytics dataset contains the following four data columns:
date: This is the date of visit and in the form of YYYY/MM/DD.country: This is the country of the visitor.city: This is the city of the visitor.pagePath: This is the URL of a page of the website.
The head section of the input dataset is as follows:
$ head -5 gadata_mr.csv 20120301,India,Ahmedabad,/ 20120302,India,Ahmedabad,/gtuadmissionhelpline-team 20120302,India,Mumbai,/ 20120302,India,Mumbai,/merit-calculator 20120303,India,Chennai,/
The expected output format is shown in the following diagram:

The following is a sample output:

In this section, we will learn about the following two units of a MapReduce application:
- Mapper code
- Reducer code
Let's start with the Mapper code.
Mapper code: This R script, named ga-mapper.R, will take care of the Map phase of a MapReduce job.
The Mapper's job is to work on each line and extract a pair (key, value) and pass it to the Reducer to be grouped/aggregated. In this example, each line is an input to Mapper and the output City:PagePath. City is a key and PagePath is a value. Now Reducer can get all the page paths for a given city; hence, it can be grouped easily.
# To identify the type of the script, here it is RScript #! /usr/bin/env Rscript # To disable the warning massages to be printed options(warn=-1) # To initiating the connection to standard input input <- file("stdin", "r") Each line has these four fields (date, country, city, and pagePath) in the same order. We split the line by a comma. The result is a vector which has the date, country, city, and pathPath in the indexes 1,2,3, and 4 respectively.
We extract the third and fourth element for the city and pagePath respectively. Then, they will be written to the stream as key-value pairs and fed to Reducer for further processing.
# Running while loop until all the lines are read while(length(currentLine <- readLines(input, n=1, warn=FALSE)) > 0) { # Splitting the line into vectors by "," separator fields <- unlist(strsplit(currentLine, ",")) # Capturing the city and pagePath from fields city <- as.character(fields[3]) pagepath <- as.character(fields[4]) # Printing both to the standard output print(paste(city, pagepath,sep=" "),stdout()) } # Closing the connection to that input stream close(input)
As soon as the output of the Mapper phase as (key, value) pairs is available to the standard output, Reducers will read the line-oriented output from stdout and convert it into final aggregated key-value pairs.
Let's see how the Mapper output format is and how the input data format of Reducer looks like.
Reducer code: This R script named ga_reducer.R will take care of the Reducer section of the MapReduce job.
As we discussed, the output of Mapper will be considered as the input for Reducer. Reducer will read these city and pagePath pairs, and combine all of the values with its respective key elements.
# To identify the type of the script, here it is RScript #! /usr/bin/env Rscript # Defining the variables with their initial values city.key <- NA page.value <- 0.0 # To initiating the connection to standard input input <- file("stdin", open="r") # Running while loop until all the lines are read while (length(currentLine <- readLines(input, n=1)) > 0) { # Splitting the Mapper output line into vectors by # tab(" ") separator fields <- strsplit(currentLine, " ") # capturing key and value form the fields # collecting the first data element from line which is city key <- fields[[1]][1] # collecting the pagepath value from line value <- as.character(fields[[1]][2])
The Mapper output is written in two main fields with as the separator and the data line-by-line; hence, we have split the data by using to capture the two main attributes (key and values) from the stream input.
After collecting the key and value, the Reducer will compare it with the previously captured value. If not set previously, then set it; otherwise, combine it with the previous character value using the combine function in R and finally, print it to the HDFS output location.
# setting up key and values # if block will check whether key attribute is # initialized or not. If not initialized then it will be # assigned from collected key attribute with value from # mapper output. This is designed to run at initial time. if (is.na(city.key)) { city.key <- key page.value <- value } else { # Once key attributes are set, then will match with the previous key attribute value. If both of them matched then they will combined in to one. if (city.key == key) { page.value <- c(page.value, value) } else { # if key attributes are set already but attribute value # is other than previous one then it will emit the store #p agepath values along with associated key attribute value of city, page.value <- unique(page.value) # printing key and value to standard output print(list(city.key, page.value),stdout()) city.key <- key page.value <- value } } } print(list(city.key, page.value), stdout()) # closing the connection close(input)
After the development of the Mapper and Reducer script with the R language, it's time to run them in the Hadoop environment. Before we execute this script, it is recommended to test them on the sample dataset with simple pipe operations.
$ cat gadata_sample.csv | ga_mapper.R |sort | ga_reducer.R
The preceding command will run the developed Mapper and Reducer scripts over a local machine. But it will run similar to the Hadoop streaming job. We need to test this for any issue that might occur at runtime or for the identification of programming or logical mistakes.
Now, we have Mapper and Reducer tested and ready to be run with the Hadoop streaming command. This Hadoop streaming operation can be executed by calling the generic jar command followed with the streaming command options as we learned in the Understanding the basics of Hadoop streaming section of this chapter. We can execute the Hadoop streaming job in the following ways:
- From a command prompt
- R or the RStudio console
The execution command with the generic and streaming command options will be the same for both the ways.
As we already learned in the section Understanding the basics of Hadoop streaming, the execution of Hadoop streaming MapReduce jobs developed with R can be run using the following command:
$ bin/hadoop jar {HADOOP_HOME}/contrib/streaming/hadoop-streaming-1.0.3.jar -input /ga/gadaat_mr.csv -output /ga/output1 -file /usr/local/hadoop/ga/ga_mapper.R -mapper ga_mapper.R -file /usr/local/hadoop/ga/ga_ reducer.R -reducer ga_reducer.R
Being an R user, it will be more appropriate to run the Hadoop streaming job from an R console. This can be done with the system command:
system(paste("bin/hadoop jar”, “{HADOOP_HOME}/contrib/streaming/hadoop-streaming-1.0.3.jar",
"-input /ga/gadata_mr.csv",
"-output /ga/output2",
"-file /usr/local/hadoop/ga/ga_mapper.R",
"-mapper ga_mapper.R",
"-file /usr/local/hadoop/ga/ga_reducer.R",
"-reducer ga_reducer.R"))
This preceding command is similar to the one that you have already used in the command prompt to execute the Hadoop streaming job with the generic options as well as the streaming options.
After completing the execution successfully, it's time to explore the output to check whether the generated output is important or not. The output will be generated along with two directories, _logs and _SUCCESS. _logs will be used for tracking all the operations as well as errors; _SUCCESS will be generated only on the successful completion of the MapReduce job.
Again, the commands can be fired in the following two ways:
- From a command prompt
- From an R console
To list the generated files in the output directory, the following command will be called:
$ bin/hadoop dfs -cat /ga/output/part-* > temp.txt $ head -n 40 temp.txt
The snapshot for checking the output is as follows:

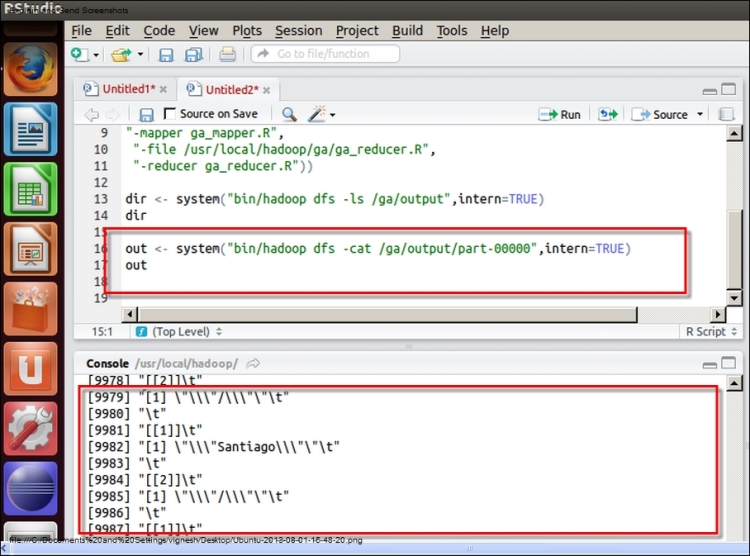
Now, we will see some basic utility functions used in Hadoop Mapper and Reducer for data processing:
file: This function is used to create the connection to a file for the reading or writing operation. It is also used for reading and writing from/tostdinorstdout. This function will be used at the initiation of the Mapper and Reducer phase.Con <- file("stdin", "r")write: This function is used to write data to a file or standard input. It will be used after the key and value pair is set in the Mapper.write(paste(city,pagepath,sep=" "),stdout())print: This function is used to write data to a file or standard input. It will be used after the key and value pair is ready in the Mapper.print(paste(city,pagepath,sep=" "),stdout())close: This function can be used for closing the connection to the file after the reading or writing operation is completed. It can be used with Mapper and Reducer at the close (conn) end when all the processes are completed.stdin: This is a standard connection corresponding to the input. Thestdin()function is a text mode connection that returns the connection object. This function will be used in Mapper as well as Reducer.conn <- file("stdin", open="r")stdout: This is a standard connection corresponding to the output. Thestdout()function is a text mode connection that also returns the object. This function will be used in Mapper as well as Reducer.print(list(city.key, page.value),stdout()) ## where city.key is key and page.value is value of that key
sink:sinkdrives the R output to the connection. If there is a file or stream connection, the output will be returned to the file or stream. This will be used in Mapper and Reducer for tracking all the functional outputs as well as the errors.sink("log.txt") k <- 1:5 for(i in 1:k){ print(paste("value of k",k)) }sink() unlink("log.txt")
A small syntax error in the Reducer phase leads to a failure of the MapReduce job. After the failure of a Hadoop MapReduce job, we can track the problem from the Hadoop MapReduce administration page, where we can get information about running jobs as well as completed jobs.
In case of a failed job, we can see the total number of completed/failed Map and Reduce jobs. Clicking on the failed jobs will provide the reason for the failing of those particular number of Mappers or Reducers.
Also, we can check the real-time progress of that running MapReduce job with the JobTracker console as shown in the following screenshot:
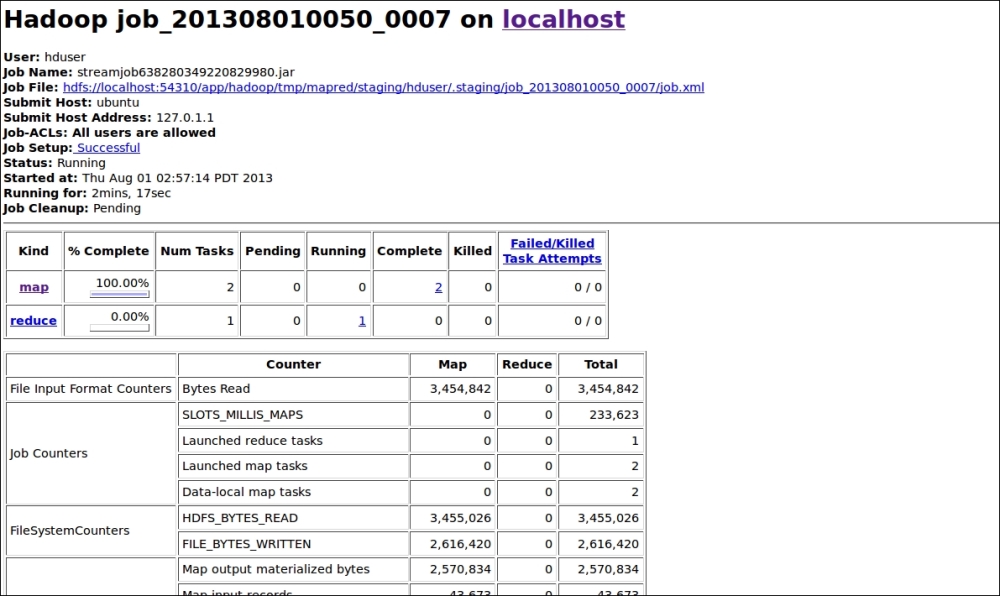
Monitoring Hadoop MapReduce job
Through the command, we can check the history of that particular MapReduce job by specifying its output directory with the following command:
$ bin/hadoop job –history /output/location
The following command will print the details of the MapReduce job, failed and reasons for killed up jobs.
$ bin/hadoop job -history all /output/location
The preceding command will print about the successful task and the task attempts made for each task.