
Case study from British Telecom: supporting a distributed sales force
British Telecom (BT) is one of the world’s leading providers of communications solutions and services, operating in 170 countries around the globe. BT’s principal activities include networked IT services, local, national and international telecommunications services, and higher value broadband and Internet products and services. Servicing many customers in the fast-moving telecommunications industry requires a large and dispersed sales and support force, with excellent access to up-to-date knowledge and information. In this chapter, John Davies, Ian Thurlow and Paul Warren describe ongoing research to improve this access.
Introduction
This chapter is about using knowledge management tools to help people working directly with customers. In fact, our user community are not all salespeople; some are technical consultants and specialists, and others are managers. However, they are all concerned with presenting and selling products and services to customers, and with ensuring that those products and services provide satisfaction to the customer and help sustain a longterm relationship.
These users are part of BT Business, a division of BT that provides for the information and communication technology (ICT) needs of a wide range of businesses in the UK. They are distributed across the country. They spend a lot of time with customers, but when not with customers they usually work from home. Because of their geographical spread, getting them together to share experiences is rare, so that electronic knowledge-sharing becomes very important. Apart from the problem of sharing knowledge, they suffer from the problems of information overload common to most of us. Moreover, they spend a great deal of their time navigating informal processes. These are not processes formally defined by the organisation, but processes created by themselves and their colleagues, and often not written down. They need help in being guided through those processes and in being provided with the right information at each stage. They also need to share and to improve those processes.
The intuition behind our work was that meeting these three challenges of knowledge-sharing, coping with information overload and using informal processes are fundamental to improving productivity – not just of sales people but of everyone who deals with information. We are developing a set of tools and technologies to provide solutions to these challenges.
For knowledge-sharing we are using a Web 2.0 approach, i.e. one that is lightweight and user-friendly. However, we are merging this with more formal, and in some senses more powerful, technologies developed within the computer science community. In doing this, we are creating powerful yet user-friendly tools.
We believe that a key to coping with information overload is managing information according to its context, that is, to how it relates to the user’s activities. We imagine that for a sales person, context would often be defined by the particular customer he or she is currently thinking about. When the user is concerned with a particular context (or customer) the information provided needs to be prioritised according to its relevance to that context.
Finally, our approach to process management is, on the one hand, to provide easy tools to help the user describe those processes, so that they can be shared and improved. On the other hand, we are experimenting with techniques for learning common process patterns, so that when a user repeats those patterns, he or she can be helped to complete the process without having to remember the detailed process steps. Software is also being developed to improve on existing processes, i.e. to make them more streamlined.
All this work is being carried out as part of the ACTIVE project.1 ACTIVE is a collaborative European research project running from 1 March 2008 until 28 April 2011. The project has twelve partners from across Europe. The BT case study described here is one of three case studies in the project. The case studies have been designed to use the project’s results to benefit real users, while at the same time validating those results with the users. The project partners are listed below and more information can be found on the project website. An overview of the project is given in Warren et al. (2009).
ACTIVE has a number of partner organisations. The ACTIVE case study partners are Accenture (www.accenture.com), BT (www.bt.com) and Cadence (www.cadence.com). The technical partners are European Microsoft Innovation Centre (www.microsoft.com/emic), iSOCO (www.isoco.com), Hermes SoftLab (www.hermes-softlab.com), Jozef Stefan Institute (www.ijs.si), Innsbruck University (www.uibk.ac.at) and Karlsruhe Institute of Technology (www.kit.edu). The partners responsible for validation are Forschungsinstitut für Rationalisierung (FIR) (www.fir .rwth-aachen.de), kea-pro (www.keapro.net) and Project Management Eurescom (www.eurescom.eu).
In the next section we describe our users’ requirements as well as the techniques we used to understand those requirements. Each of the following three sections then describes how we are applying the three aspects of ACTIVE to help our users in their daily work. After this we describe the users’ initial reaction to our approach. Finally, we talk about some next steps.
Understanding the users’ requirements
We started our work at the beginning of ACTIVE in the spring of 2008 by talking to a sample of people whom we hoped would benefit from our approach.
When we talked to the senior managers, their needs were clear. First, proposals need to be with customers more quickly. The quicker a proposal gets to the customer, the higher the chance of closing the sale. This must not be at the expense of quality; the need is to rapidly generate high-quality proposals. This means reusing information from previous proposals, but it must be the right information. It also means putting the individual or team writing the proposal in touch with those who have the expertise to help – perhaps specialist expertise in a particular technology applicable to that proposal.
Second, customer-facing people needed to be helped to be more proactive in interacting with customers. Rather than waiting for a customer to present their requirements, they need to anticipate those requirements. One way to do that is by understanding how a solution for one customer could be applicable to another.
With the technical specialists themselves, our work was organised in three phases. First, we undertook interviews with a sample of our customer-facing specialists. This was followed by ‘job shadowing’ to really understand how they use current technology and what their problems were. To save time, because our users were spread across the UK, this job-shadowing was done remotely. We were able to observe the user’s computer screen and hear his or her conversations from our own office. Apart from the saving in travelling time, this technique had the advantage that our presence was less intrusive than if we had been physically present in the same room as the user. Finally, we presented our ideas to some of this community to get their feedback.
This work confirmed the message that we were receiving from senior management: that finding and reusing information and getting hold of the right people to help are important to success. We also found that some of our users are frequently switching context. We confirmed that context for most equated to the customer currently under consideration. Besides customers, other contexts may be relevant, e.g. a context for ‘administration’. Some of the people to whom we spoke asked for the ability to download to their laptop everything (as far as is realistic) held centrally about a particular customer (i.e. context) before going out to meet that customer. They also thought it would be valuable to take account of their context when searching for information, both within the organisation and on the Web. The sharing of contexts was also seen as valuable. If contexts can be shared, this supports knowledge-sharing.
When we talked to the senior managers about informal processes, they were concerned with the proposal-creation process with which many of their people were involved. Creating good-quality proposals rapidly is seen as a significant challenge. Steps in the process include locating previous similar proposals, identifying relevant information and key experts, and getting the proposal adequately reviewed. A big challenge is to ensure consistency across a large multi-authored document.
Web 2.0 for knowledge-sharing
Our approach to knowledge-sharing is based on Web 2.0, the essence of which is that the consumers and producers of information are one and the same. From Web 2.0 we have adopted the technique of user-tagging and the tool of the MediaWiki.
User tagging – from folksonomies to ontologies
Knowledge-and information-sharing has been recognised as a significant problem by many organisations for several decades. Formal systems have been developed in which people place information in a repository, and at the same time classifying the information against a pre-agreed schema to encourage easy retrieval. While useful, such systems can be time-consuming to use since they require knowledge of the schema.
In the world outside the organisation an easier approach to informationsharing has been enormously successful. The use of tags to create so-called ‘folksonomies’ or tag clouds has enabled the sharing of web pages (e.g. with delicious2) and photographs (e.g. with Flickr3).The same approach is now being adopted within organisations and there are also attempts to achieve a synergy of the formal and informal approaches (see Hayman 2007). In ACTIVE, we are achieving this synergy by using lightweight ontologies to describe knowledge. An ontology is a formal knowledge model and the use of ontologies has been developed by the artificial intelligence community. Ontologies are formally defined and hence allow not just the description of knowledge, but also reasoning about that knowledge. The use of this approach greatly enhances information retrieval. For more information about the use of ontologies in knowledge management, see Davies et al. (2005).
By restricting ourselves to lightweight, relatively simple ontologies we are combining the benefits of the formal and informal approaches. Lightweight ontologies do not enjoy the full descriptive power that more complex ontologies have. However, they are computationally simpler and they are adequate for our purposes. We are providing an easy-to-use editor to create and edit these lightweight ontologies. The editor is intuitive to use and all the detail of what an ontology is and how it is used is hidden from the user. Moreover, if the user just wants to tag, they are free to do so. The system will learn simple ontological structures from the way in which tags are created and used.
Figure 8.1 shows a user tagging a document. The user can create their own tag. The system also suggests some tags based on the content of the document and tags used by others for related documents. Users can search on these tags, on document content, or on both. Figure 8.2 shows this.

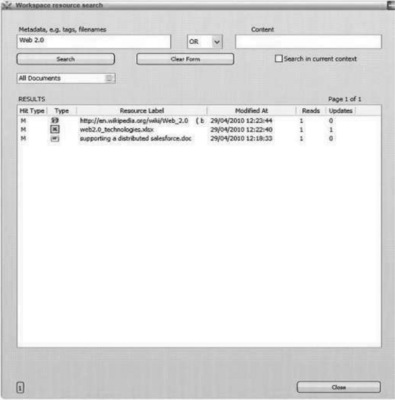
There are a number of advantages to creating tags and searching on tags, rather than simply searching on content. A user is able to select as tags, words or phrases that are not in the document but that are particularly meaningful to that user and their colleagues. Even where a tag already exists in the document, the choice of this particular word or phrase as a tag gives it a particular significance that may aid document recovery. The use of recommended tags that have been used by others helps users converge on a common set of document descriptions, which creates an increased understanding of the relationship between documents.
Knowledge-sharing with the Semantic MediaWiki
As we have already observed, one area where sharing knowledge is particularly important is in creating proposals. Proposal writers need to find product information quickly and also appropriate text from previous proposals for reuse. The quality of proposals is also important. For example, where product information is used it must be the most up-to-date product information. A simple search on the intranet can often result in finding information that has been superseded. It is also important to find the right people who can contribute their expertise to developing the proposal.
Our solution to this is the use of a Semantic MediaWiki (Krötzsch et al., 2006). This is an extension of MediaWiki4 that incorporates ‘informal’ semantics. In creating a link between two pages, authors may associate semantics with the link. In our example we will have a set of pages describing products, a set of pages describing technologies and a set of pages describing people. We can then, for example, have links from the people pages to the products and technologies in which they have expertise. We talk about ‘informal’ semantics because authors can make up their own relationships (e.g. ‘is expert in’) without reference to any predefined ontology. Of course, there is value in people using the same terms and they can be encouraged to reuse existing relationships; and it is possible to define equivalences between different terminologies (e.g. ‘knows about’ can be equated to ‘is expert in’).
Once such semantically annotated links exist they can be queried by the user, e.g. through a form-based interface. In our example above we can imagine querying the Semantic MediaWiki to provide information on everyone who is an expert in a particular technology or product. A query language can also be used to query the semantics to create HTML pages, for example a page listing technologies and the people who are experts in those technologies.
Where reference needs to be made to large documents, either a URL link can be used, for example to connect to the company intranet, or else a document can be uploaded to the wiki and made available from the appropriate page. In this way, documents, spreadsheets, multimedia objects, etc., can be accessed from the wiki.
The Semantic MediaWiki uses the capability of wiki technology to encourage collaboration. To have a community collaborating on text in a wiki is simply more effective than working with long e-mail threads. Moreover, the addition of semantic technology enables more powerful querying of the wiki than is possible with simple text search. It does this in a way that is informal and easy to use. Of course, text search is still available to complement the semantic features.
Delivering information in context
We have talked about the importance of being able to switch context easily, for example when a phone call or e-mail diverts us onto a different area of work. Figure 8.3 shows how a user can change context manually, by selecting a context from a drop-down menu. We are also using machine intelligence techniques to find out when the user has changed the focus of his or her work and thus when it would be appropriate for the system to switch context. This could be learned from the files they are accessing or the people with whom they are interacting via e-mail or instant messaging. While we believe some users will be happy to control their contexts manually, we feel the real value of our approach is realised with the use of these machine intelligence techniques.

Figure 8.4 shows how context can influence the delivery of information to the user. The user is opening a file within the word processor and specifying ‘open in current context’. The five files shown are the most recently accessed files relating to the current context. Below this, the user is able to access files in other contexts. The user can also ‘open’ a file in the conventional way and see the most recent files irrespective of context.

Understanding and improving processes
The third theme of our project is that of informal processes. Other researchers have observed the use of such processes by knowledge workers, in fact across a wide spectrum of professions (Hill et al., 2006). We similarly observed such informal processes amongst our users. These varied from relatively long processes, such as the creation of a proposal document that can take weeks, to relatively short processes that took minutes. Many of these short processes were to do with interoperating between different systems, e.g. copying and pasting from a spreadsheet to a CRM system.
As with the other aspects of work in ACTIVE, we are combining a top-down with a bottom-up approach. The former means we are providing a simple interface for people to create their own processes to be shared and reused. The bottom-up approach means we are using machine intelligence to learn processes and present these learned processes to the user for editing, sharing and reuse. The two approaches will, of course, be compatible. Specifically, learned processes will be editable through the same interface as is used to create processes top-down.
In fact, when we spoke to our users, their view was that generally they knew what step to take next but the issue for them was having the information they needed for that next step. So one aspect of our current work is designing a tool to present the user with the information objects they are most likely to need next.
The users’ response
Before implementing our ideas we spoke to users to get initial feedback. Certainly our widely distributed users saw knowledge-sharing as a problem. Our users were familiar with the ideas of Web 2.0, although they generally did not participate in websites such as flickr that use tagging, nor did they contribute to wikis. Nevertheless, they saw tagging and the use of the Semantic MediaWiki as powerful ways to share information.
They also liked the idea of using context to deliver information, although as already noted, most felt that to obtain the real benefit from this requires the use of machine intelligence techniques to automate context detection and learning.
Turning to processes, the view of our users was that the real problem was not knowing the next step to take, but rather having the right information at each step in the process. Predicting what information is needed as the user works through a process is a key research goal for our project. We also found that people wanted to optimise their processes. As a first step to this, they wanted to understand what their actual processes are, as compared with what they are thought to be.
Next steps
As we write, our users are currently trialling the first prototype of our system. This will provide us with further feedback to inform our development activities. Later in 2010 we shall be trialling a more advanced system, with machine intelligence techniques for context detection and learning.
During 2010 we used the Semantic MediaWiki to assist knowledgesharing, in particular for the preparation of customer proposals. When we talked to the people who prepare these proposals we were told that usually the core team writing a proposal could answer most of the questions posed by the customer in an invitation to tender. However, they would typically be left with half a dozen difficult technical questions for which they needed expert advice. Finding the right experts and getting that advice is frequently really difficult. The Semantic MediaWiki, with its semantic querying facilities, will help with information retrieval. One other feature we plan to incorporate is a publish facility, whereby those few questions for which there is no answer in the knowledge base will appear on the company intranet, inviting responses from across the company.
Perhaps the most ambitious of our features are to do with process learning and optimisation. These are still under development and will also be trialled later in 2010. The goal here is to really understand what our users’ processes are and to streamline those processes.
The last six months of our project will involve extensive user validation. We hope this will further verify our intuitions. We also hope that this validation will enable us to improve our tools as a basis to encourage further take-up within and outside BT.
Acknowledgement
The work described in this chapter has been funded by the IST–2007–215040 EU project, ACTIVE.
References
Davies, J., Studer, R., Sure, Y., Warren, P., Next generation knowledge management. BT Technology Journal. 2005;23(3):175–190 July. http://www.btplc.com/lnnovation/Journal/BTTJ/archive/ArchiveHome.aspx
Hayman, S. Folksonomies and tagging. Ark Group Conference: Developing and Improving Classification Schemes, Sydney, Australia, June, 2007. http://www.educationau.edu.au/jahia/webdav/site/myjahiasite/shared/papers/arkhayman.pdf
Hill, C., Yates, R., Jones, C., Kogan, S., Beyond predictable workflows: Enhancing productivity in artful business processes. IBM Systems Journal. 2006;45(4). http://www.research.ibm.com/journal/sj/454/hill.html
Krötzsch, M., Vrandecic, D., Völkel, M., Semantic MediaWiki. Cruz, I., Decker, S., Allemang, D., Preist, C., Schwabe, D., Mika, P., Uschold, M., Aroyo, L., ed. Proceedings of the 5th International Semantic Web Conference, 2006. [(ISWC–06). Springer 2006].
Warren, P.W., Kings, N., Thurlow, I., Davies, J., Ruiz, C., Gómez-Pérez, J.M., Simperl, E., Bürger, T., Ermolayev, V., Tilly, M., Bösser, T., Imtiaz, A., Improving knowledge worker productivity – the ACTIVE integrated approach’. BT Technology Journal. 2009 February;26(2). http://www.btplc.com/lnnovation/Journal/BTTJ/BTTJHome.aspx
1.http://www.btplc.com/innovation/journal/BTTJ/current/HTMLArticles/Volume26/26lmproving/Default.aspx
4.MediaWiki (http://www.mediawiki.org) is a free wiki software package, originally written to support Wikipedia.