
In the previous chapters, we looked at the different types of models and how to create models for our problems. We also saw how the probabilities of variables change when we change the probabilities of some other variables. In this chapter, we will be discussing the various algorithms that can be used to compute these changes in the probabilities. We will also see how to use these inference algorithms to predict the values of variables of new data points based on our model, which was trained using our previous data.
In this chapter, we will cover:
- Using inference to answer queries about the model
- Variable elimination
- Understanding the belief propagation algorithm using a clique tree
- MAP inference using variable elimination
- MAP inference using belief propagation
- Comparison between variable elimination and belief propagation
Inferring from a model is the same as finding the conditional probability distribution over some variables, that is, ![]() , where
, where ![]() and
and ![]() . Also, if we think about predicting values for a new data point, we are basically trying to find the conditional probability of the unknown variable, given the observed values of other variables. These conditional distributions can easily be computed from the joint probability distribution of the variables, by marginalizing and reducing them over variables and states.
. Also, if we think about predicting values for a new data point, we are basically trying to find the conditional probability of the unknown variable, given the observed values of other variables. These conditional distributions can easily be computed from the joint probability distribution of the variables, by marginalizing and reducing them over variables and states.

Fig 3.1: The restaurant model
Let's consider the restaurant example once again, as shown in the preceding figure. We can think of various inference queries that we can try on the model. For example, we may want to find the probability of the quality of a restaurant being good, given that the location is good, the cost is high, and the number of people coming is also high, which would result in the probability query ![]() . Also, if we think of a machine learning problem, where we want to predict the number of people coming to a restaurant given other variables, it would simply be an inference query over the model, and the state having higher probability would be the prediction by the model. Now, let's see how we can compute these conditional probabilities from the model.
. Also, if we think of a machine learning problem, where we want to predict the number of people coming to a restaurant given other variables, it would simply be an inference query over the model, and the state having higher probability would be the prediction by the model. Now, let's see how we can compute these conditional probabilities from the model.
From the product rule of probability, we know the following:
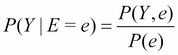
So, to find each value of the distribution P(Y, e), we could simply do a summation of the joint probability distribution over the variables ![]() :
:
Now, to find P(e), we can simply do another summation over ![]() , which we just computed:
, which we just computed:
Using these values of ![]() and P(e), we can easily find the value of
and P(e), we can easily find the value of ![]() as follows:
as follows:

Performing a similar calculation for each state ![]() of the random variable Y, we can calculate the conditional distribution over Y, given E = e.
of the random variable Y, we can calculate the conditional distribution over Y, given E = e.
In the previous section, we saw how we can find the conditional distributions over variables when a joint distribution is given. However, computing the joint probability distribution will give us an exponentially large table, and avoiding these huge tables was the whole point of introducing probabilistic graphical models. We will be discussing the various algorithms that can help us avoid the complete probability distributions while computing the conditional distribution, but first, let's see what the complexity of computing these inferences is.
If we think about the worst case scenario, we cannot avoid the exponential size of the tables in graphical models, which makes inference an NP-hard problem, and unfortunately, even the approximate methods to compute conditional distributions are NP-hard. Proofs of these results are beyond the scope of this book.
However, these results are for the worst case scenario. In real life, we don't always have the worst case. So, let's discuss various algorithms for the inference.