
In the preceding section, we discussed the method of estimating parameters using the maximum likelihood, but as it turns out, our maximum likelihood method has a lot of drawbacks. Let's consider the case of tossing a fair coin 10 times. Let's say that we got heads three times. Now, for this dataset, if we go with maximum likelihood, we will have the parameter, ![]() , but our prior knowledge says that this should not be true. Also, if we get the same results of tossing with a biased coin, we will have the same parameter values. Maximum likelihood fails in accounting for the situation where, because of our prior knowledge, the probability of getting a head in the case of a fair coin should be more or less than in the case of a biased coin, even if we had the same dataset.
, but our prior knowledge says that this should not be true. Also, if we get the same results of tossing with a biased coin, we will have the same parameter values. Maximum likelihood fails in accounting for the situation where, because of our prior knowledge, the probability of getting a head in the case of a fair coin should be more or less than in the case of a biased coin, even if we had the same dataset.
Another problem that occurs with a maximum likelihood estimate is that it fails to distinguish between the cases when we get three heads out of 10 tosses and when we get 30000 heads out of 100000 tosses. In both of these cases, the parameter, ![]() , will be 0.3 according to maximum likelihood, but in reality, we should be more confident of this parameter in the second case.
, will be 0.3 according to maximum likelihood, but in reality, we should be more confident of this parameter in the second case.
So, to account for these errors, we move on to another approach that uses Bayesian statistics to estimate the parameters. In the Bayesian approach, we first create a probability distribution representing our prior knowledge about how likely are we to believe in the different choices of parameters. After this, we combine the prior knowledge with the dataset and create a joint distribution that captures our prior beliefs, as well as information from the data. Coming back to the example of coin flipping, let's say that we have a prior distribution, ![]() . Also, from the data, we define our likelihood as follows:
. Also, from the data, we define our likelihood as follows:
Now, we can use this to define a joint distribution over the data, D, and the parameter, ![]() :
:

Here, ![]() is the number of heads in the data and
is the number of heads in the data and ![]() is the number of tails. Using the preceding equation, we can compute the posterior distribution over
is the number of tails. Using the preceding equation, we can compute the posterior distribution over ![]() :
:

Here, the first term of the numerator is known as the likelihood, the second is known as the prior, and the denominator is the normalizing factor.
In the case of Bayesian estimation, if we take a uniform prior, it will give the same results as the maximum likelihood approach. So, we won't be selecting any particular value of ![]() in this case. We will try to predict the outcome of the next coin toss, when all the previous data samples are given:
in this case. We will try to predict the outcome of the next coin toss, when all the previous data samples are given:
In simple words, here we are integrating our posterior distribution over ![]() to find the probability of heads for the next toss.
to find the probability of heads for the next toss.
Now, applying this concept of the Bayesian estimator to our coin tossing example, let's assume that we have a uniform prior over ![]() , which can take values in the interval, [0, 1]. Then,
, which can take values in the interval, [0, 1]. Then, ![]() will be proportional to the likelihood,
will be proportional to the likelihood, ![]() . Let's put this value in the integral:
. Let's put this value in the integral:

Solving this equation, we finally get the following equation:

This prediction is known as the Bayesian estimator. We can clearly see from the preceding equation that as the number of samples increase, the parameters comes closer and closer to the maximum likelihood estimate. The estimator that corresponds to a uniform prior is often referred to as Laplace's correction.
In the preceding section, we discussed the case when we have uniform priors. As we saw, in the case of uniform priors, the estimator is not very different from the maximum likelihood estimator. Therefore, in this section, we will move on to discuss the case when we have a non-uniform prior. We will show an example over our coin tossing example, using our prior to be a Beta distribution.
A Beta distribution is defined in the following way:
Here, ![]() and
and ![]() are the parameters, and the constant,
are the parameters, and the constant, ![]() , is a normalizing constant, which is defined as follows:
, is a normalizing constant, which is defined as follows:
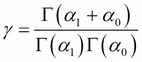
Here, the gamma function, ![]() , is defined as follows:
, is defined as follows:
For now, before we start our observations, let's consider that the hyper parameters, ![]() and
and ![]() , correspond to the imaginary number of tails and heads. To make our statement more concrete, let's consider the example of a single coin toss and assume that our distribution,
, correspond to the imaginary number of tails and heads. To make our statement more concrete, let's consider the example of a single coin toss and assume that our distribution, ![]() . Now, let's try to compute the marginal probability:
. Now, let's try to compute the marginal probability:

So, this conclusion shows that our statement about the hyper parameters is correct. Now, extending this computation for the case when we saw M[1] heads and M[0] tails, we get the following equation:

This equation shows that if the prior distribution is a Beta distribution, the posterior distribution also turns out to be a Beta distribution. Now, using these properties, we can easily compute the probability over the next toss:

Here, ![]() , and this posterior represents that we have already seen
, and this posterior represents that we have already seen ![]() heads and
heads and ![]() tails.
tails.
Again, let's take our simple example of the network, ![]() , and our training data,
, and our training data, ![]() . We also have unknown parameters,
. We also have unknown parameters, ![]() and
and ![]() . We can think of a dependency network over the parameters and data, as shown in Fig 5.2.
. We can think of a dependency network over the parameters and data, as shown in Fig 5.2.
This dependency structure gives us a lot of information about datasets and our parameters. We can easily see from the network that different data instances are independent of each other if the parameters are given. So, ![]() and
and ![]() are d-separated from
are d-separated from ![]() and
and ![]() when
when ![]() and
and ![]() are given.
are given.
Also, when all the ![]() and
and ![]() values are observed, the parameters,
values are observed, the parameters, ![]() and
and ![]() , are d-separated. We can very easily prove this statement, as any path between
, are d-separated. We can very easily prove this statement, as any path between ![]() and
and ![]() is in the following form:
is in the following form:
When ![]() and
and ![]() are observed, influence cannot flow between
are observed, influence cannot flow between ![]() and
and ![]() . So, if these two parameters are independent a priori then they will also be independent a posteriori. This d-separation condition leads us to the following result:
. So, if these two parameters are independent a priori then they will also be independent a posteriori. This d-separation condition leads us to the following result:
This condition is similar to what we saw in the case of the maximum likelihood estimation. This will allow us to break up the estimation problem into smaller and simpler problems, as shown in the following figure:

Fig 5.2: Network structure of data samples and parameters of the network
Now, using the preceding results, let's formalize our problem and see how the results help us solve it. So, we are provided with a network structure, G, whose parameters are ![]() . We need to assign a prior distribution over the network parameters,
. We need to assign a prior distribution over the network parameters, ![]() . We define the posterior distribution over these parameters as follows:
. We define the posterior distribution over these parameters as follows:

Here, the term, ![]() , is our prior distribution,
, is our prior distribution, ![]() is the likelihood function,
is the likelihood function, ![]() is our posterior distribution, and P(D) is the normalizing constant.
is our posterior distribution, and P(D) is the normalizing constant.
As we had discussed earlier, we can split our likelihood function as follows:

Also, let's consider that our parameters are independent:

Combining these two equations, we get the following equation:

In the preceding equation, we can see that each of the product terms is for a local parameter value. With this result, let's now try to find the probability of a new data instance given our previous observations:
As we saw earlier, all the data instances are independent. If the parameter is given, we get the following equation:

We can also decompose the posterior probability as follows:
Now, using this equation, we can solve the prediction problem for each of the variables separately.
Now, let's see some examples of the network's learning parameters using this Bayesian approach on the late-for-school model:
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: from pgmpy.models import BayesianModel
In [4]: from pgmpy.estimators import BayesianEstimator
# Generating some random data
In [5]: raw_data = np.random.randint(low=0, high=2,
size=(1000, 6))
In [6]: print(raw_data)
Out[6]:
array([[1, 0, 1, 1, 1, 0],
[1, 0, 1, 1, 1, 1],
[0, 1, 0, 0, 1, 1],
...,
[1, 1, 1, 0, 1, 0],
[0, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 1, 1]])
In [7]: data = pd.DataFrame(raw_data, columns=['A', 'R', 'J',
'G', 'L', 'Q'])
# Creating the network structures
In [8]: student_model = BayesianModel([('A', 'J'), ('R', 'J'),
('J', 'Q'), ('J', 'L'),
('G', 'L')])
In [9]: student_model.fit(data, estimator=BayesianEstimator)
In [10]: student_model.get_cpds()
Out[10]:
[<TabularCPD representing P(A: 2) at 0x7f92892304fa>,
<TabularCPD representing P(R: 2) at 0x7f9286c9323b>,
<TabularCPD representing P(G: 2) at 0x7f9436c9833b>,
<TabularCPD representing P(J: 2 | A: 2, R: 2) at 0x7f9286s23a34>,
<TabularCPD representing P(L: 2 | J: 2, G: 2) at
0x7f9286a932b30>,
<TabularCPD representing P(Q: 2 | J: 2) at 0x7f9286d12904>]
In [11]: print(student_model.get_cpds('D'))
Out[11]:
╒═════╤═════╕
╘═════╧═════╛
╒═════╤═════╕
│ D_0 │ 0.44│
├─────┼─────┤
│ D_1 │ 0.56│
╘═════╧═════╛Therefore, to learn the data using the Bayesian approach, we just need to pass the estimator type BayesianEstimator.