
In this chapter, we aim to focus on how processes in your team and company can help rather than hinder your productivity. Many of these topics are not specific to CSS (Cascading Style Sheets), but to write CSS that is scalable and shared among many teams or websites it is vital to have solid processes and consistency. We willtalk about development methodologies, how to ensure consistent code styles, source control, tools, and naming conventions. Because we aim to give you useful practical examples, we will present an example process at the end of this book.
In this chapter, we will look at:
The team and its parts
Scaling a business
Dealing with loss of staff
Consistency of code
Tools
Version control
Backup
Prototyping
Development methodologies
Arguably, the most important element in CSS development is the team that supports the developer. Every team is different, not just the personalities of the members or the sizes of the teams but also the disciplines and skills within it. Some teams include a few server-side developers and a single front-end developer, some include the entire skillset required to build a web solution: designers, front-end developers, server-side developers, database specialists, testers, and so on.
A team this size has the benefit of rapid communication between its component parts but has the disadvantage of size; larger teams are slower to respond to requirements for various reasons. The primary reason for this is something researchers call "diffusion of responsibility." This means that in larger teams, members assume that someone else is doing any given task at any given point rather than taking it upon themselves to do it. Without clear guidelines in place, it can be difficult to be sure of who is or should be responsible for unexpected problems or tasks, so even though these issues are noticed, they are forgotten. In smaller teams, besides communications being more immediate and effective, more attention is on each individual, and members will assume responsibility and be more proactive. This issue, however, can be overcome with good project management. If you have all your tasks mapped out with clear areas of responsibility, there is no room for confusion.
Note
There are many terms that describe people that write CSS: front-end developers, client-side developers, web developers, and web designers are just a few.
The processes within your company change dramatically depending on the type of team you have. For teams that do not include designers, if the requirements fed to your team already include complete designs and specifications, there is little room or time to feed back any issues to the designers or information architects and the development is more siloed away from the requirement creation process. If the teams do not include testers, and the user testing process is outside of your team, errors or problems they find are fed back to you after you have finished developing, which is the least efficient time to fix them.
It also makes a big difference who writes your CSS. If it is written by web designers (hopefully the same people who made the designs for what you are developing), then as long as they are good at what they do they will have taken into account things like accessibility, usability, and templating. If the designers are separate from your team, you may find the designs they provide do not intrinsically consider these things. The worst case is where the CSS is written by those who don't specialize in front-end code at all because they are not expert in what they are doing, and may do more harm than good. CSS is deceptively simple, and it is easy to write inefficient bloated code that quickly becomes legacy code. However, companies' processes are often based in legacy and not that easy to change.
The project manager is responsible for getting the most out of the team and dealing with these issues. One of the most important pieces of a process is defining areas of responsibility. These areas need to be mapped out clearly before a team is even put together, so you know who to include in the team. A simple example is as follows:
Project Manager: The project manager is responsible for representing his team to the business (as well as the business to the team), ensuring that everything is recorded correctly, facilitating meetings, and making sure that the members of his team know what they should be doing and have everything they need to do it (including helping to remove any obstacles that prevent them from doing it). As far as the team goes, the buck stops here; if a project fails, it is likely to be the project manager that is held accountable.
Team Lead/Technical Lead: Team leads are responsible for the technical delivery of the product. They need to ensure they understand the general direction the project is going in as well as the methods being used to address technical challenges, and to communicate with members of their team to find any potential risks or pitfalls, and suggest ways to resolve them.
Developer: The term developer is a broad term. For the sake of this example, the developer is the person undertaking the actual tasks within the project (writing the CSS). He is responsible for giving estimates and details necessary to record the tasks, feeding back technical issues to the team lead and logistical issues to the project manager, and completing the tasks.
With these roles clearly defined, it becomes obvious who should be doing what. With regular meetings any problems should be located and dealt with quickly.
We have not mentioned designers or testers because they are not always within the team that develops the project, but if they are members of your team it is important to also list their responsibilities. If your team includes web designers who can write HTML and CSS, you can consider them developers for the sake of this nomenclature.
Once you have your team planned out, it is easy for your company to begin using that template for every team you have and for every project you have. We encourage you to continue to consider how your team is formed on a project-by-project basis. Although strict processes are a good thing, if you don't change them on occasion you may never discover better ways to run your development.
Figure 1-1 shows an example hierarchical diagram of a team setup.
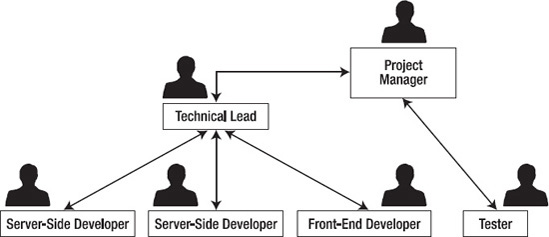
Once you have your process in place and all the members of the team know it inside out, there should be very few surprises. In smaller companies or teams, though, strict processes are thought to be less important. Assuming that everyone is a useful and hard-working contributor (in smaller companies they will be caught out quickly if this is not the case), communications can be facilitated with quick spontaneous meetings and face-to-face conversation. Because interaction between staff is more intimate, training new employees is a much more hands-on task. Policies can be changed day to day, and although processes are still useful for efficient performance, a little chaos can, in fact, help with creativity.
As companies and teams grow larger, this becomes less of a luxury and more of a cumbersome chore. Trying to train all your new staff as they are recruited becomes a mammoth task requiring dedicated space and further staff. Keeping communication open and flowing between teams becomes more difficult and more time-consuming. The carefully crafted CSS styles and verbally agreed-to methods of working and keeping your website consistent and clean start to get lost between the increasing number of teams. If your team grows larger, more and more time is taken up in the administration of the individuals, and even just waiting your turn to speak in meetings. If you have off-site resources, the meetings become even less productive as they morph from in-person conversations into conference calls and e-mail.
There are clear and obvious advantages to off-site resources, in that you only use (and pay!) them when you need them, and they are often dramatically cheaper—but this comes at a loss of personal communication.
The benefits of face-to-face communication are as follows:
Gestures
Facial expressions
Body language
Whiteboards
Immediacy
Clarity
The disadvantages of remote communication are the following:
Technical difficulties
Loss of meaning and intent
Loss of focus
Loss of priority
Lesser comprehension
Wasted time and resources
Note
Using video conferencing, screen-sharing and whiteboarding software can allay some of these concerns, but they introduce new technical difficulties and a loss of immediacy and instant gratification.
If you have members of teams that are in different countries, time zone differences and potential language barriers further compound these issues. However, the reduction of cost in using remote developers in countries like India or Estonia is often too attractive to the business to overlook and potentially for good reason.
It is clear that the previously acceptable methods when the company was small and growing of sticking hastily scribbled post-it notes to a big whiteboard and shouting important messages across the room are no longer effective means of management. A solid process that everyone in the team (and hopefully, the company) has bought into and agreed upon will help to alleviate many of these concerns. As mentioned before, if it is clear what tasks everyone should be performing and when, it becomes more difficult for misunderstandings to occur.
If what everyone is doing is recorded in a trackable and consistent manner, any remaining misunderstandings can be uncovered and addressed. More so, whereas in a smaller company it is difficult for neglectful, incompetent, or unproductive members of the team to go unnoticed—writing CSS inconsistent with legacy code, modifying code without due diligence or causing bugs and defects in dependent pieces of code—in larger companies these costly individuals can creep under the radar for months. The processes that we willcover in this chapter can surface and expose their activities (or lack of them) much more quickly.
In smaller companies, every individual has a voice. However, in larger companies this voice can get drowned out by the crowd or simply have no route to the ears of those who need to hear it. Great ideas and improvements can go unheard, and staff members are less invested in a company on which they can leave no impression or mark. Simple processes like feedback sessions, company meetings, available line managers, and fewer levels of hierarchy can help ensure that every staff member has an opportunity to participate and contribute.
If these processes can become ingrained in the company's way of thinking from the start, they will be much easier to implement and a good base for growth.
Many larger companies tend to have a high rate of employee turnover—people come and go more frequently, taking their knowledge and the skills invested in them. This is especially true for front-end developers; they are very much in demand in today's markets and often work as contractors with short notice periods, and as such can jump from role to role with little warning. Although company founders want to think that their employees will stay loyal to them forever, the truth is that most people will at some point leave and move on. For smaller companies, a lot is invested into each employee financially and sometimes even emotionally. Every new employee taken on (whether replacing an employee that has left or filling roles that have become necessary due to growth) requires induction and training. These employees help shape the company, and choosing the right people is something that must be considered carefully. In a larger company this becomes even more important. Larger companies gain their own personalities and characteristics and there is more to learn to fit in. New employees must almost be assimilated into the company's behaviors. It can take quite a while to start being productive and longer still to reach the level of productivity that comes with being comfortable in your environment. More-complicated processes mean more user accounts and passwords to set up, documentation to read, policies to learn, and larger premises to find their way around. This means that inducting your staff and training them is paramount to efficiency—you are still paying staff during their unproductive periods, after all.
Tip
It is important to do whatever you can to get new staff up and running as quickly as possible.
Something else you should be exploring is how to retain these employees more effectively. Every staff member imposes costs on the business, but the knowledge they acquire over time builds exponentially, as does the value of a good team member. First, consider whether you are offering salary and benefit packages that stand up well against those of your competitors. Evidence has been found in many studies that indicate that the simple concept of increasing monetary reward to increase performance only holds true when considering manual labor. In the instance of more cerebral pursuits, it is more important that staff members feel challenged and valued. To this end, it is important to pay them enough that money is not the concern, but you don't have to pay above market rates to get good loyal people. Nonmonetary rewards to increase the individual's happiness in the workplace are valuable also. Things like flexible working hours, training, vacation time, and even just providing a bowl of fruit each morning all serve to add to an employee's level of satisfaction in the workplace. A good canteen doesn't just make your staff happy and well fed—it also keeps them closer to their desk and thus quicker to get back to work!
Another thing that will help retain staff is to demonstrate appreciation for their contributions. Awards ceremonies or other forms of recognition, parties, and nights out demonstrate an appreciation of their commitment to the company and further strengthen the team as a whole.
Although you want your staff to meet your deadlines and requirements and be as productive as possible, you also do not want them to suffer burnout. Ensuring that your deadlines are as realistic as possible (by involving staff in the estimation process and basing estimation accuracy on previous estimates) and that your employees are content in the workplace will help sustain a good work ethic and rate of achievement.
Finally, you want to ensure that your staff members are proud of what they do and feel invested in it. Doing your best to give everyone a voice will help with that. Some companies like Google give their employees opportunities to work on their own products, and support and recognize them if they develop something of value to the company as a whole. Every Friday at Google is "Google Friday," when developers are encouraged to play with new technologies. This playing has resulted in Gmail, Google News, Orkut, the Google logo becoming a fully functional Pacman game, and other internal innovations. At Atlassian, once every three months their employees are allowed to do whatever development they like for a day, as long as they present their results to the company afterward. Developers take pride in their work, and this is demonstrated in the items the developers choose to work on when given free reign. Bugs that are important to developers (but not the business) are fixed, spelling mistakes are rectified, vital refactoring takes place, issues with process are isolated, and solutions appear for existing business problems during this time. The result is that you have better software, but more than that, you have happier and prouder people.
All these suggestions apply just as well to CSS developers as other members of staff. However, the web development world progresses and changes rapidly, and it can be difficult to keep up. If staff members are passionate about what they do, they will want to keep their skills up to date, and if the company wants them to be happy, it will help them achieve this. Although newer CSS techniques might not be ready for prime time due to patchy browser support, time should be allocated for the CSS developers to read about and become familiar with these techniques. Allowing your web developers opportunities to attend conferences (and perhaps even speak at them to represent your company) demonstrates a commitment to the employee and to the technologies they care about. Keeping a good library of reference books (like this one!) and considering subscriptions to magazines helps, too, as does giving the developers time to read them as well as blogs and other articles online. Allowing them to present their own findings online via a company blog is often something they will appreciate, but this may depend upon your company's public stance and policies.
Keeping staff happy should be a primary concern and will help retain them longer, but employees resigning should be planned for, not a cause for panic.
When hiring new staff, you should always strive to hire high-caliber individuals. You want people who know their stuff, and have things to share with the rest of the team. However, particularly in the realms of programming and coding, different people have different styles of writing.
Inconsistency of code is a cost, both in terms of time and resources. Although writing CSS selectors in a particular way may be more efficient and clever, due to the potentially high churn of staff, if this code is unusual or more difficult to understand it becomes difficult to share among the team members. Writing your own CSS framework is a good thing, as long as it is not too complicated to pick up. You should also consider some of the already available CSS frameworks that we talk about in Chapter 4. If the process of implementing your own CSS framework requires complicated build scripts and makes debugging difficult, perhaps the solution is being over-engineered. We are not suggesting at all that build scripts (which you can read about in Chapter 9) should not be employed for reasons of performance and efficiency, but the process should be simple. CSS developers typically work very fast, often flicking between their text editor and a browser many times a minute. Any processes required to get your code to run should be implemented in an unobtrusive manner. A build process that hinders that has a much larger hit on the developer's efficiency than many might think. Entering a CSS debugging mode should be just as simple, so in the case of CSS being minified upon reaching production, the CSS developers can see their code as they wrote it instead of a CSS/DOM inspector reporting the selector as being on line 1, where there is only one line.
A single developer hoarding all the knowledge of how certain parts of your code work should be an obvious red flag. If this developer chooses to leave the company, or for some reason cannot work for them anymore, there is an immediate knowledge deficit. New developers may have trouble understanding the code, and a period of stagnation begins, while these developers struggle to come to grips with the complexity of the code. Without the previous CSS developer there to mentor them, huge areas of CSS may just be left in place for years because no other developer is brave enough to remove them for fear of causing issues elsewhere in the site. This kind of stagnation of legacy code is very common and is difficult and costly to resolve.
To that end, it must be preferable to have simpler and clearer code wherever possible so that knowledge hoarding remains at a minimum. Some companies choose to frequently rotate their developers onto different pieces of their projects at particular intervals to combat this. In fact, despite the obvious cost in time, this methodology has some considerable benefits, in that every team member has a good idea of how the project works as a whole and may consider factors that could otherwise have been overlooked without this holistic view. Problems found during development rather than during planning are always more costly to overcome. The main downside to this methodology is that developers are constantly moving from one piece of the puzzle to another and may find it difficult to "get into the zone," which can be frustrating and a further cost.
The value of consistency in these scenarios cannot be overstated. As a very basic example, one individual may compose their CSS code in this fashion:
/* Main Heading */
#mainHeading {
font-size: 2em;
font-weight: bold;
color: red;
}Another may write it like this:
/*========================================================================
Main Heading
========================================================================*/
#main-heading {font-size:20px;font-weight:bold;color:#ff0000}Both of these are completely valid and technically correct ways of writing CSS. However, if these two individuals both worked on the same CSS file at different times, you could end up with a mixture of these two very different coding styles in the same document. This leads to a document that is hard to scan and read. Many developers, upon finding the style of code that was different to their own, may reformat it in a way they find is preferable to them. The original developer may then format it back the same way. This is both inefficient and unnecessary.
CSS suffers from this problem more than most coding languages. It is so easy to just throw lines of code into a file until something renders correctly, and it is very difficult to isolate the pieces that you can safely remove or that are no longer in use. To that end, strictly formatting your CSS documents and keeping the selectors and rules in the right place is paramount to avoiding a big mess of code with legacy and leftover pieces that are difficult to locate. Code that is badly or hastily written is known as "technical debt", a term coined by Ward Cunningham in 1992. A little debt is okay as long as you pay it back (refactor and fix the code), but the longer you wait, the more the interest builds up (code built on top of and dependent upon the initial code) until you go bankrupt (have to start all over again).
To solve this problem, it is important to have standards predefined in a guide so everyone knows that CSS is written in a particular way in your organization. Most companies of any size have some kind of wiki (see following) or company handbook, which is an appropriate place to store a guide like this. Although outdated, the BBC makes its CSS Guide available online at www.bbc.co.uk/guidelines/futuremedia/technical/css.shtml.
We don't recommend having rigid guidelines that are enforced strictly (for example, you should not use !important,[3] but there may be situations where it is the most appropriate thing to do). However, we do recommend some form of guidelines exist. Here is an example of a section of a CSS formatting guide:
All related blocks of CSS should be prefixed with a comment in this format to aid visual scanning and searchability of the CSS document:
/*======================================================================== Main Heading ========================================================================*/
All colors should be in hexadecimal format (
#123456).All CSS selectors and rules should be on a single line to save space and to fit more selectors on a screen simultaneously.
These points serve as an example, not necessarily steps that we recommend you take. We will present you with an example CSS formatting guide at the end of this book. For this guide, it is useful to employ MoSCoW (a common method for prioritization). MoSCoW (in this context) means the following:
Must do this
This rule must be followed at all times, with no exceptions.
Should do this
This rule should be followed at all times, unless there is an acceptable reason not to that has been justified.
Could do this
This is more of a tip than a rule that can be employed where appropriate.
Won't do this now but Would like to in the future
This is something you can't do now (perhaps because of a lack of browser support), but might consider in the future.
Using this method is useful because it means all CSS topics are captured to demonstrate they have already been considered, and previous conclusions can be kept for future discussions.
It is also important wherever possible, and where it is not clear, to explain the reasons for the rules in our guide.
From the business perspective, creating clean and well-written CSS is very hard to justify. It's not that the business wants bad or messy code to be written, it is that our work is typically based upon business requirements. The business wants those requirements delivered and for the team to be ready to move onto other pieces of work as soon as possible. To that end, you need a good compromise. You want good clean code—you know it makes life easier in the future and it allows you to take pride in your work. But perhaps complicated and terse code (which is not always the same as good code) is more of a hindrance than a benefit. If you have a solid and rigid structure and methodology that you stick to, our new staff can adjust to our in-house coding style with the minimum of fuss and get straight to being productive. If you know which styles go in which files and how to locate the blocks of CSS in those files, you can find the pieces you need to amend straight away, with no need for endless debates (with very little business value) about which location to use.
Of course—taking this to the extreme—excessively verbose and overly commented code is just as hard to work with. Selectors may become too specific, and comments may take up all our screen estate, making it difficult to scan the document. We willbe looking at comment usage in Chapter 2.
This does not mean using newer technologies is a bad thing or that you should not debate techniques. It does mean, however, that these debates should have an appropriate forum at set intervals as part of our process. You can amend documents as and when you need to, as long as you communicate the changes to everyone who needs to know. If you keep your CSS guide in a wiki (see the section on Wikis under the Tools heading below), they will typically support some kind of notification mechanism via "watched pages" or similar means. This means that upon any revision that is not specifically marked as minor, a list of subscribers will be alerted to the change. Anyone working on the CSS within the organization should be a member of this list. They should also have the ability to modify the guide themselves (and, in turn, notify the others). It is very important however, that someone owns this document—that is, that someone is responsible for the changes that occur within it—and makes sure the others are aware of any changes made to it.
Let's say that the RGBA (Red Green Blue Alpha) method of declaring colors has recently found favor among our CSS developers. In our imaginary organization, Igloo Refrigerator Parts Inc, we have a monthly meeting between all our front-end developers. It is proposed and agreed at this month's meeting that this method has value, and we want to start using it. Using RGB (Red Green Blue) as a flat-out replacement for hexadecimal code is found to have good support in the browsers in which we look to maintain adequate functionality (see "Graded Browser Support" in Chapter 6), and RGBA gives us a capability we did not have before (notably alpha transparency), so we want to add it to our CSS Formatting Guide and amend our previous recommendation. Again, this is an example, not our suggestion.
Before, we had this line:
All colors should be in hexadecimal format:
#123456.
We can now amend it like so:
All colors should be in RGB format:
rgb(100,100,100).Where colors need to support alpha transparency, we should use the RGBA format:
rgba(100,100,100,0.5).
Tip
Always declare a non-alpha RGB color first and don't rely on the alpha transparency for older browsers.
At the meeting, someone is given the responsibility to make these amendments, and to make sure that everyone is notified about them. Note that this does not mean we should immediately revisit all our CSS code and convert all hexadecimal colors to RGB, but it does mean that any future colors should be in RGB. The next time we have an opportunity to refactor is an opportunity to convert the rest of the legacy code across to satisfy the new guidelines.
Often, in larger organizations, different departments will not communicate with each other, and the business may be so large that indeed they never even know the others exist. We would encourage you to reach out to everyone in your business that writes CSS, and try to get everyone speaking the same language and working together.
Many tools exist to help us develop our website and manage our processes. There are myriad pieces of software to manage our tasks, store our files, store documentation, create mock-ups, share files, develop our code, communicate with each other, and so on. This section discusses some of the types of software that are likely to be useful to your process and mentions a few examples of each type. It is impossible to mention (and have used) everything, so please consider these tools a list of potential candidates with notes on important features, and not a complete overview. Review the options available before deciding on particular choices.
A wiki is a piece of software (almost always based in a web browser) that serves as a repository for documents, and allows particular groups of people to edit them. They often include features such as "watched" pages that allow users to be sent notifications when they change, and storing version information on previous revisions of documents. The most famous example of a wiki is, of course, the famous www.wikipedia.org. Having all of your documentation stored centrally in a well-organized fashion has many benefits:
Easy to back up
Obvious where to locate particular kinds of data
Data does not go stale or get into conflict (everyone works on the same piece of information rather than having multiple versions in multiple places)
Potentially available remotely
Platform-independent
Previous revisions of documents are not lost
It is very easy for a wiki to get out of control. Ensure someone is responsible for owning the wiki, enforcing a sensible, structured taxonomy, and performing housekeeping. Many examples of wiki software exist. Some are hosted, some you can host yourself, many are free, many are paid for... They employ many different languages for formatting.[4]
Here are some of the most prolific and well known.
Arguably the most famous wiki software—this is the wiki behind Wikipedia. MediaWiki (www.mediawiki.org) is open source, highly configurable, and simple to set up. It supports most databases and is written in PHP. Plugins are available. Some authentication features are built in, but they feel unfinished and untested. MediaWiki also has a reputation for being very slow. As is often the case, the benefit of using open source software (it is free!) is tempered by the downside, which is that it feels like open-source software.
Confluence (www.atlassian.com/software/confluence) is not free, but it is one of the more polished and full-featured wikis out there with a great WYSIWYG (What You See Is What You Get) interface. There is a hosted solution as well as one you can run internally. Confluence is written in Java and supports most common databases. Confluence can be neatly integrated with Atlassian's other products, and has some basic social networking capabilities. A large plugin library is available. You can (at the time of writing) purchase a license for up to 10 users for $10, but it quickly becomes more expensive when your needs exceed that (which they are likely to in large environments).
If you are running OS X Server (from version 10.5 upward), you already have this wiki installed (www.apple.com/server/macosx/). Every user group gets its own wiki by default, but you can build more. The authentication features work well. Mac OS X Server Wiki uses HTML behind the user interface to format data, but has a very strict white list to control which tags and attributes are available, which can quickly become a hindrance. You can modify this list, but it's not much fun to do so. It is very attractive, polished, and simple to set up and use, but it is a bit limited on functionality.
Trac (http://trac.edgewall.org/) includes a bug/issue tracker and is a dedicated wiki specifically for software development projects. Trac combines a bug tracker and wiki into one, which might simplify your workflow. It is open source and free, but it does not feel as polished as some others on this list.
Bug reporting software serves the purpose of giving us a centralized place to record any bugs or defects that are found in your software. As in the case of wikis, some are hosted, some can be self-hosted, some are expensive, and some are free. Bug trackers are used for testers to raise bugs with different priorities.[5]
Some examples of dedicated bug reporting software are discussed in the following sections.
Lighthouse (http://lighthouseapp.com/) is software as a service (SaaS) that offers a clean and simple interface that runs in your browser. It is not free, but is reasonably priced.
Bugzilla (www.bugzilla.org/) is a free open-source bug tracker from Mozilla. It is full-featured, mature, and has great support for version control systems. It is written in Perl and supports user interfaces using Web, e-mail, RSS, web service, and command line. MySQL and PostgreSQL are both supported as databases.
JIRA (www.atlassian.com/software/jira/) is not free, but has a huge feature set. The administration of it may be a bit daunting, but it is flexible enough to handle pretty much any process or workflow. Installation and maintenance (particularly upgrades) are not as simple as they could be, but the caliber of plugins available goes a long way toward making up for this.
Task management software lets us record tasks we expect our team to undertake. It may include functionality like resource/time management and comprehensive reporting capabilities. The role of this kind of software is to present a simple and unintrusive interface for entering and reviewing tasks. Enterprise task management software (which can also be called project management software) is often built around agile processes.
Some examples are shown in the following sections.
A desktop application for OS X, Things (http://culturedcode.com/things/) is really for managing tasks at an individual level rather than sharing them between the team. Many people find this extra level of self-management useful. An iPhone app is also available that syncs with the desktop version over wifi (sadly, not via the cloud).
Rally (www.rallydev.com/) is a hosted and paid-for solution. Although unintuitive and lacking in some features, it deals very well with resource and time management when your staff may be working on several projects concurrently.
Mingle (www.thoughtworks-studios.com/mingle-agile-project-management) is developed by ThoughtWorks, which is well known for its contributions to the agile movement within the IT industry. Mingle includes a polished web-based interface, with a built-in wiki. The user interface works solely on the metaphor of cards on a whiteboard, and the processes are very customizable. The pricing is on a per-user basis and unlikely to be cheap, although a free 1 year trial is available for up to five users.
Rather than keeping these two systems disparate, some solutions exist that cover both of these requirements. This makes good sense—our bugs need to be fixed, and the fixing of them is of course a task. In a good process, these things can be managed together. The fewer pieces of software to maintain the better, and the training costs will decrease if there is only one application your developers need to learn.
Here are a few examples of pieces of software that combine task management with bug tracking:
Green Hopper (www.atlassian.com/software/greenhopper) turns JIRA into a full-featured agile task tracker. It is very configurable, and easy to make JIRA resemble the whiteboards and cards that many of us are used to. Kanban (a less common agile development methodology) is also supported well. It's hard to find a setup that improves upon this, but (for larger teams) it is not cheap, or easy to administer, install, and maintain.[6]
Agilo (www.agile42.com/cms/pages/agilo/) is based upon and supports integration with Trac to provide a full-featured solution for SCRUM (an agile development methodology). A free alternative is available as well as a paid for version. Installers are provided, as well as a Python Egg if you are familiar with Python, which it is written in.
Originally an internal bug-tracking tool for Fog Creek Software, Fogbugz (www.fogcreek.com/fogbugz/) was first released in 2000. It has since expanded to include wikis, forums, and task management. It supports Evidence-Based Scheduling (EBS)[7] and has a built-in API for connecting to your own software. It is available as a hosted solution (with a 45-day free trial) or installable on your own servers, and is reasonably priced.
It is very easy to reach software overload. Many companies have three or four wikis running simultaneously as well as different versions of task- or bug-tracking software. This kind of situation is so inefficient and detrimental to processes that it must be avoided at all costs. Make a decision about which software to use in your business and then apply it. Try to use strict and enforceable rules how to organize your information without making it too complicated.
Tip
Where your tools send e-mail, if you are able to configure it as such, it is important to keep this e-mail to a minimum, relevant, and to the point. If your developers are overwhelmed, the e-mail will not be read.
Source control comes in many flavors, but at the heart of every one is the concept of maintaining a history of every file in your project (stored in a repository) with the ability to roll back to previous versions of any file. There is also (typically) the concept that one file may have been worked on by many people, and thus needs to be "merged" to include everyone's changes.
The main copy of the files in our project is called the trunk. When a version of software is released (considered safe to put in a production environment), it is very common to tag the current state of the repository, or branch the repository (which means to create a duplicate version of the current state of the repository). We do this so that if problems are found with the version on production, we can make amendments to that code without worrying about more recent changes that might conflict or not be ready for release. Typically we should work in the trunk where possible because merging the changes between branches can be problematic.
Some examples of source control systems are shown in the following sections.
VSS (www.microsoft.com/visualstudio) is now widely considered a legacy and outdated method of source control. When one user chooses to work on a file (by checking it out), that file is locked from being worked on by any other user until it is committed back into the repository (checked in).
There is a benefit of this methodology: files almost never need to be merged because they are always left in a state the developer is happy with. However, this means that developers can never simultaneously work on the same file and often forget to commit their files, thereby locking the file away from other users.
CVS (www.nongnu.org/cvs/) was developed by Dick Grune in July 1986. Although other versioning systems similar to CVS existed before (this was the first that allowed files to be modified by multiple people simultaneously) to gain widespread acceptance. The CVS model keeps all files in a centralized repository on a server, and clients check out and commit files from and to that repository.
CVS had many shortcomings, and although it is still in common use today, Subversion (http://subversion.apache.org/) was created by CollabNet in 2000 as an attempt to fix many of the bugs in CVS and to add many of the much requested "missing features." As such, it operates in a very similar manner to CVS. Due to its relative stability and maturity, it is one of the most common version control systems in companies today.
Git[8] (http://git-scm.com/) is a form of distributed version control. This means that the developer has a repository on his own machine as well as one (or many) stored centrally. Rather than "hoarding changes" for fear of committing faulty code (and therefore increasing the potential for data loss due to crashes or hardware failure), users commit their code to their local repository and can manage revisions from there. Instead of being a single library, Git is actually formed from a series of individual tools with which it is possible to come up with pretty much any version control process you might like. Although the merging algorithm used in Git is well respected and has been proven by merging 12 Linux kernel patches simultaneously, Git is a complicated system to get your head around and may well be overkill for your projects.[9]
Another distributed version control system, Mercurial (http://mercurial.selenic.com/), is sometimes known by its command-line name: hg. It was developed by Matt Mackall and released in 2005. Git and Mercurial were developed concurrently because the free version of BitKeeper—the source control software used at that time by the Linux kernel project—was withdrawn by its developer, BitMover. Although Git was ultimately used by the Linux kernel project, Mercurial is still championed by many in the industry. Less full-featured than Git, Mercurial is still very functional and fast, and simpler to use—particularly for those migrating from Subversion.
Note
BitBucket (http://bitbucket.org/) is a service similar to GitHub for Mercurial projects.
Almost all version control systems ship with command-line interfaces, but many graphical user interfaces (GUIs) exist as well as plugins to enable integrated development environments (IDEs) and other pieces of software to communicate with them. To mention them all would be beyond the scope of this book, but it is worth mentioning the Tortoise family of shell extensions for the Windows platform (TortoiseCVS, TortoiseSVN, TortoiseHG, and so on). They integrate tightly within Windows, adding functionality to the right-click menu within the file system explorer as well as icons signifying state, which is the most intuitive place for them to be. Copycat versions have been attempted for OS X and Linux, but none have (at time of writing) been integrated as tightly and intuitively as Tortoise.
When working with source control, when you are happy with what you have done, you commit the file to the repository. This updates the central code with the version you are working on. If you are using distributed version control, you should commit to the local repository often, and only commit to the central repository when you are confident your code is working correctly. You can see a visual comparison between version control and distributed version control in Figures 1-2 and 1-3.

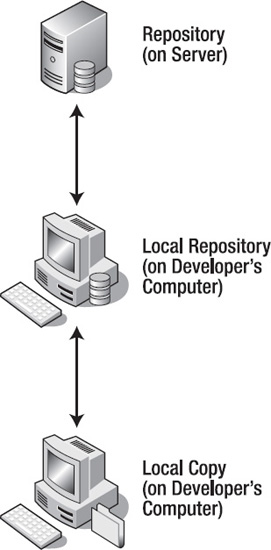
Using version control systems is vital when you work on CSS in teams. It gives you the added confidence to work on files that other developers may be working on, as well as the reassurance of a restorable history for each change we commit. When we work with CSS, we often work in small chunks. We make small changes, switch to our browser, refresh the page, change, switch, F5, and so on. We should remember to commit our changes often, so that we have a good history of everything we have been doing.
When committing your changes, most version control systems will ask you for a comment describing what you have changed. When your version control system is further embedded in your processes, these comments become invaluable. It is therefore of utmost importance that your comments are relevant, descriptive and helpful.
A comment like this is of very little value:
Changed some bits and pieces.
But a comment like this describes exactly what happened within the file:
Changed hex colors to RGB colors.
When things go wrong (which they will), you will find yourself viewing the commit history of the files with the problem and useful comments will be very helpful in clarifying what changed in each revision.
Typically, you are encouraged to update a file by hand before beginning work on it. This means to fetch the latest version from the repository. If you fail to update and begin work on an outdated version of the file, or if another developer has committed changes after you began work, you are required to merge the files. Because two developers have been working on it simultaneously, the changes between your local copy and the version in the repository are non-linear. It is impossible to work out which pieces to keep and which to replace in an automatic fashion; this results in the files being in conflict. To resolve the conflict, it is necessary to locate the differences, edit the file appropriately, and then mark the conflict as resolved so that you can commit the amended version of the file.
To deal with these conflicts, you will want to see exactly what the differences are between the two files. A special type of application exists that does just this: a Diff program. Again, lots of them exist, and we don't intend to promote one over the other. The purpose of these programs is to compare two similar files and show the differences between them.
The intention is to make it easy to recognize and resolve the conflicts between two versions of the same file. Because CSS is often less modular than we would like it to be (or can have effects in unexpected places), and although conflicts can be resolved, we should still avoid them wherever possible. The best way to do this is to communicate effectively with your team and let everyone know exactly which files you are working on at any one time.
Where these conflicts exist, we must merge and resolve them. Resolving conflicts and merging changes are some of the biggest headaches of having multiple individuals working on the same file. Older style command-line Diff programs show only the differences between the files, similar to the output shown in Figure 1-4.

More modern Diff programs ease this pain by letting you view two documents side by side. Differences between the two documents are highlighted, and any section that is different can be copied from either document to the other document (see Figure 1-5).

Often simple versions of Diff tools will be available within your IDE or version control system, but the following sections describe examples of other dedicated Diff programs.
The standard version of Araxis Merge (www.araxis.com) can compare two documents, but the professional version can compare and merge three separate documents simultaneously. It is reasonably priced, and available for both Windows and Mac platforms with great performance on both platforms.
WinDiff (http://support.microsoft.com/kb/159214) is included with Microsoft Visual Studio, so it is free if you already develop with that platform. You can also download it from www.microsoft.com/downloads/details.aspx?familyid=49ae8576-9bb9-4126-9761-ba8011fabf38&displaylang=en if you are running Windows XP, but it is included on the CD for versions of Windows including Windows 2000 and later.
WinMerge (http://winmerge.org/), as the name suggests, is a Windows application. It is open source, available for free, and performs well.
Beyond Compare (www.scootersoftware.com/) is developed by Scooter Software and on its third revision. It is available for Windows and Linux. It is reasonably priced, and has a great reputation and feature set.
Changes (http://connectedflow.com/changes/) is a Mac-based application that integrates well with other apps on OS X. Figure 1-5 shows Changes in action. It is inexpensive and can compare folders as well as files.
Kaleidoscope (http://kaleidoscopeapp.com/) deserves a mention as a very attractive and intuitive Diff tool. It is made by Sofa (which also makes the Versions SVN client for OS X at http://versionsapp.com) and is a great example of beautiful and intuitive software at a low price. Unfortunately, as of version 1 (the current version at time of writing), it includes no merging capability, which may limit its usefulness to you.
A more complete list of Diff tools is available at http://en.wikipedia.org/wiki/Comparison_of_file_comparison_tools.
Let's demonstrate how to resolve an SVN conflict. We willuse the Versions SVN client and Changes Diff tool, both on OS X. For the sake of example, we are working on a file specifically for Internet Explorer 8 called ie8.css. We have updated our local repository and then worked on the file locally. The contents of the file initially were the following:
#imagePath {
filter: alpha(opacity=0);
}
#tryit-form .input-file {
height:18px;
width:217px;
}We have added an extra selector and changed the height and width for #triyit-form .input-file, so the file now looks like this:
#imagePath {
filter: alpha(opacity=0);
}
img.example {float:left;}#tryit-form .input-file { height:22px; width:220px; }
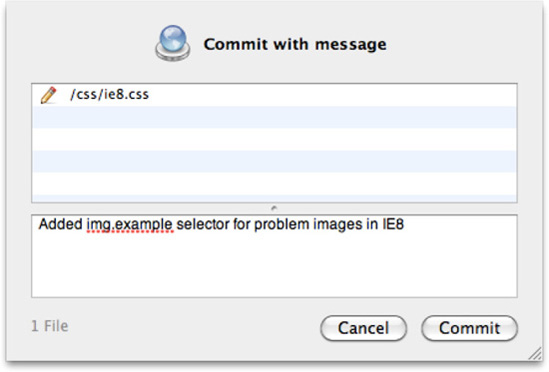
We tested these changes and they work fine, so we go to commit the file with an appropriate comment (see Figure 1-6).
The result is shown in Figure 1-7.
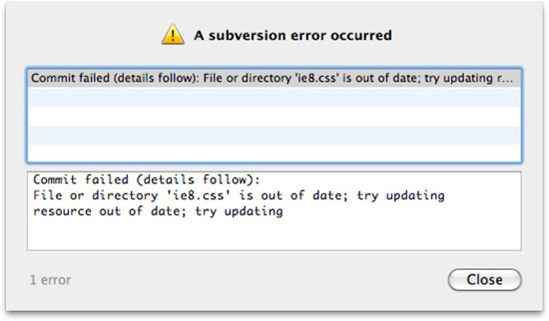
This figure tells us that this file has been modified and committed since we last updated it. As suggested, we will now perform another update of our local copy to pull down the latest changes (see Figure 1-8).

Versions now shows several new files and icons. ie8.css has an exclamation mark next to it, which indicates it is currently in conflict. But three brand-new files have appeared, too:
ie8.css.r313ie8.css.r312ie8.css.mine
Each of these files has a purpose:
ie8.css.r313is the latest version of this file in the repository.ie8.css.r312is the version of the file we downloaded from the repository when we last updated.ie8.css.mineis the version of the file we just tried to commit.ie8.cssnow contains markers, the version we created, and the changes in the repository.
The contents look like this:
#imagePath {
filter: alpha(opacity=0);
}
img.example {
float:left;
}
#tryit-form .input-file {
<<<<<<<.mine
height: 22px;
width: 220px;
=======
height: 24px;
width: 320px;
float: left;
}
.clearfix {
zoom: 1;
>>>>>>> .r313
}The markers show what has changed. Everything between <<<<<<< .mine and ======= were changed since updating, and everything between ======= and >>>>>>> .r313 were changed by someone else. Notice that SVN is not suggesting that our img.example selector and rules are in conflict because it is clever enough to resolve and merge those changes itself.
To resolve this, let's compare our version and the latest version from the repository. First, we open both of those files in Changes (see Figure 1-9). We need to consider that one of these files as the master file, so we willuse the .mine file and make sure that file is selected first so it appears on the left.

The result is shown in Figure 1-10.
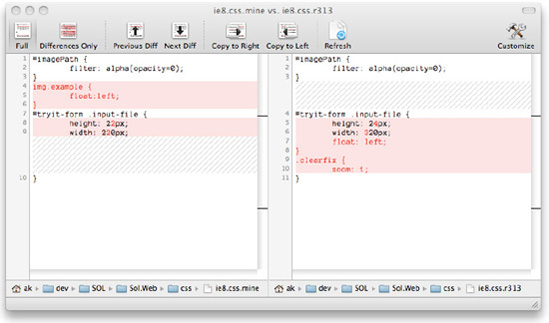
The differences in the files are now very obvious. We added a section for the selector img.example, someone else has added .clearfix, and the contents of the other selector have been modified. We check the logs quickly, and find out who has changed this file and read their commit comment. If necessary, we can then contact them to ask them about their changes. It turns out that a change in design required the change to height and width of a particular element, and that our changes to them are no longer necessary. Using the left file in Changes as our master, we now merge our changes. We just want the bottom part of the file, so we click anywhere in that section in the document on the right and click Copy to Left (see Figure 1-11).

The file on the left is now how we intend the file to be. We copy and paste the contents into ie8.css file, and in Versions mark it as "resolved" (see Figure 1-12).

Finally, we do another update from the repository, and test the file to ensure that it works correctly. It does (hopefully!), so we commit it to SVN.[10]
It goes without saying that backups are a vital element of any development process. It is of huge importance that you back up your repository and other important data. Where possible, versions of these backups should be stored in several discrete locations. Hardware failure, data corruption, and fire or flood damage can destroy months or even years of work in a moment.
A backup should be treated like insurance. You almost never need it, but if and when you do, it is potentially hugely more valuable than the cost to implement it. You should also have backups of different days—something like one backup a day for the last seven days at any point, and possibly even monthly backups going farther back. Sometimes we find we want to revert to a version that was lost a few days ago or look at a legacy version of a product, and not everything will be stored in source control.
It is important to ensure that your backups actually work. It is all well and good to religiously remember to take different backup tapes home, but if you don't run a test restore, you could find out at the worst possible time that all that hard work has gone to waste.
Developers' machines are less vital than your repository and servers. A simple hard drive backup should be adequate; the goal is to be able to get a developer back up and running as fast as possible when the hard drive fails (which is inevitable).
Warning
Hard drives do fail. It is not a matter of if, but when. Be prepared.
Several online backup examples are available, often with free and paid-for offerings. Some examples include the following:
Each of them supports Windows and OS X (and Linux in many cases), and allows you to share your content with other users. Some kind of scripted action can copy to each of them from your local machine, and if you don't have much data (developers typically only need one or two folders on their machine backed up), they are usually free. Being able to share big files is often very useful if any of your staff are working from home or remotely, although many large companies don't like any of their files to be on other companies' servers.
If you want a more automated out-of-the-box solution, there are many of these available, too:
Microsoft NTBackup/Windows Backup and Restore Center/Windows Server Backup (free with some Windows versions)
www.microsoft.com/athome/setup/backupdata.aspx
Time Machine (free with recent versions of OS X)
www.apple.com/support/leopard/timemachine/
www.symantec.com/business/products/family.jsp?familyid=backupexec
Roxio Retrospect
www.retrospect.com/
There are in fact more backup options than we can list here by a long margin. A more complete list and comparison of backup software can be found at http://en.wikipedia.org/wiki/List_of_backup_software.
As part of the scoping process, it often becomes necessary to create a basic version of what we are going to build to give a hands-on example of what may otherwise be a complicated concept to explain. The considerations we would give to production-quality code—things like accessibility, file size, browser support, and so on—are not important here. The code we are developing is to be seen in-house only, and we can specify browser requirements. Any frameworks (read more about frameworks in Chapter 4) and shortcuts to speed up development are completely acceptable when creating prototypes.
Often the completed prototype is considered good enough and becomes production code, despite not being written as well as other code. This should be avoided because it encourages code bloat and technical debt, as well as other CSS sins. To that end, it is often a good idea to cripple the prototype somehow, so that we will definitely be given an opportunity to refactor and rewrite it later on.
If it is something purely visual we want to prototype, like a layout or user journey through a site, many tools exist to help us with this. A great example is Balsamiq Mockups (www.balsamiq.com/products/mockups), which has the benefit of creating diagrams that can be functional, but still look like sketches (one of the only valid uses for Comic Sans!). They cannot be mistaken for production imagery, and the discussions focus on the content and layout rather than things like fonts and color.
Spikes are similar to prototypes. A spike is named as such because it is a visual description of a tangent from our current path. If during development we find something we need to develop, and we're unsure of the best path to follow, we can "spike" development at that point. We would create a very rough example to demonstrate our intended path and to prove that it works. This example wouldn't include anything but the pieces necessary to demonstrate that our approach will achieve what we want it to, and would by definition (unless it is something very visual we are spiking) be unattractive and limited. Although a prototype is something we would copy and paste and modify to our needs, a spike will pretty much always be discarded after it has been proven (or failed to be).
Many development methodologies and processes exist. Each of them warrants a book of its own, but we will touch quickly on the two most popular kinds (by a long way), Waterfall and Agile.
The waterfall model has its roots in manufacturing. Although the word waterfall was never used, the first official description of this model is commonly thought to have come from an article Winston W. Royce wrote in 1970. Royce was actually writing about the model in order to point out that it is, in his opinion, a flawed and problematic way of working.
Waterfall (in software) describes a legacy development methodology, although still in use in many organizations. In its most basic form, it is the process of producing a technical specification for what we intend to deliver, giving details of the levels of effort (time periods) required by our resource (staff) and very granular descriptions of the exact details of the solution we will be building. Once the specification is agreed upon, the developers work on delivering exactly what is in the specification until it is complete, at which point it is presented to the business or client. It is at this point either rejected and then amended, or signed off and marked as approved.
The phases can be described like so (see Figure 1-13):
Requirement Gathering (or Scoping)
Design
Implementation (or Build)
Verification (or Testing)
Maintenance (or Support)
The term waterfall was coined because of the concept that once we have reached a phase, it is impossible to change the output of (or return to) the phase previous to that one. That is, we can only flow in one direction.

As with all methodologies, there are pros and cons of waterfall development:
Pros
The business/client has a clear indication of expected costs and timescales.
There is a definition of exactly what is being built.
Cons
The specification is often incomplete or has errors that are too low level to isolate before the build commences. This results in the development team and client arguing over whether particular pieces of the solution were included in the original costings. Without making the specification ridiculously fine and detailed, items that may be obvious, implicit, and intuitive to the client/business could be misunderstood by the developers.
There is a paradox: to write a perfectly accurate specification requires the author to have already built the solution.
The specification leaves no allowance for change during the process; if the business/client finds another requirement that has to be included, it is necessary to wait until the "waterfall" runs dry before that requirement can even be considered.
Regardless of which development methodology you employ, it is rare to find a business or client that does not inherently work in a waterfall manner. When we as a business need something built, we need to know how much it will cost and how long it will take. To that end, it is common to treat the project from their perspective as a waterfall, but to use different methodologies internally during the project lifecycle.
Agile development has been gaining popularity for 10–15 years now. At the heart of agile development is the concept that the team should be agile, that is, that the team should be able to switch and change their processes, concepts and tasks with ease. Agile methods are based on iterative development, and allow teams to reflect on successes or failures within each block of time and modify their processes and respond quickly to changes in requirements. Many earlier agile workflows such as SCRUM and extreme programming are now referred to as agile methodologies, after the publication in 2001 of the Agile Manifesto.
The Agile Manifesto can be found at http://agilemanifesto.org/, but we include it here for clarity:
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Here are some pros and cons of agile development:
Pros
The team is fast to change and react to new or changing requirements.
The process is always evolving, and every member of the team can have a voice and a part to play in that evolution.
Cons
It is often difficult or impossible to commit to fixed deadlines.
The specification can be left too loose and missing features discovered too late.
Although many agile development methods exist, they all promote collaboration and easy-to-adapt processes. The following sections show examples of agile practices.
Test-driven development (TDD) is the process of writing automatable tests (based on our requirements and acceptance criteria) before we write our code, and only writing code that helps us pass these tests. This helps minimize scope creep (the creation of new requirements) and unnecessary code. Whenever bugs in the software are found, we can immediately add a test to re-create these bugs. If this test remains within our test suite, we can be sure that we will not regress without knowing about it. You can read more about testing in Chapter 10.
Refactoring our code means to revisit it and ensure that it is as efficient, fast, and clean as possible, and no potential code smells are left behind.
Note
Code smell is a term that resulted from a discussion between Martin Fowler and Kent Beck while Fowler was writing his book Refactoring: Improving the Design of Existing Code. A code smell is a piece of code that indicates a deeper problem.
Any notes of "To do: Fix this!" should be addressed during the refactoring of code. Code reviews can occur to help promote knowledge sharing among the team. Code refactoring is often a luxury; if you get the chance to do it, make sure you make the most of it. This could also be considered as paying off your technical debt. Try to get rid of any legacy code and consider whether there are other ways you can format your CSS in order to get the most out of a minimization algorithm or better rendering performance within the browser.
Continuous integration (CI) servers build and test our code, and perform other automated tasks in response to a commit into the version control repository or at predefined intervals. We cover this further in Chapter 9.
Many companies now advocate the pair programming process: working beside another developer to avoid knowledge hoarding, mentor, and help other members of the team, as it reduces the chances of bugs in the finished product. Two heads are better than one. Some other companies believe having two developers work on the same piece of work simultaneously is inefficient. We suggest that where a piece of work is complex enough, pair programming can be invaluable, but usually code reviews are enough. Cycling developers between teams is an alternative effective method of avoiding knowledge hoarding.
Planning poker (sometimes called the planning game) is a method of gathering resource estimates against tasks. It is called a game of poker because it uses cards or tokens to represent votes. After the task to be estimated for is described in reasonable detail, every person of a particular discipline (be it server-side development, client-side development, testers, designers, and so on) holds up a card showing the amount of time they would expect one person to take to complete the task. The person with the highest value justifies their choice, the person with the lowest value justifies their choice, and we repeat the process until we have a unanimous decision.
Planning poker can be a very time-consuming exercise and may not be right for all companies, but it has the benefit of ensuring that every member of the team has a good understanding of what we are delivering and may consider and think of bugs that might slip into the implementation phase otherwise. Often the time estimate is represented by cards or tokens in different ways; for example, as story points or as numbers of days reflecting the Fibonacci sequence (1,2,3,5,8,13, and so on).
Note
The Fibonacci sequence actually begins with 0, 1, 1, but obviously that would be counterproductive in this instance.
Code reviews are similar to pair programming in that they provide other developers a chance to comment on code that has already been written. Often the learning goes in both directions, with the reviewer asking why things were done in a particular way as well as providing feedback. It is less costly than pair programming in terms of time and is a more efficient way of assuring the quality of code in smaller teams.
These meetings occur every day, as soon as the entire team is available. In these meetings we use the concept of chickens and pigs. This terminology comes from an old joke:
A pig and a chicken are chatting one day when the chicken says, "Hey, I was thinking we should start a restaurant together!"
"We should? What would we call it?" asks the pig.
"How about 'Ham and Eggs'?" the chicken suggests.
"No thanks!" exclaims the pig. "I'd be committed, but you'd only be involved!"
A pig is someone actually building the project. A chicken is someone involved in the project. A chicken (project manager, or scrum master) should facilitate the daily standup, but only the pigs should contribute. This helps because the chicken should be interested in the project being successful as a whole, whereas each pig may have his own bias or agenda. Typically the pigs are the developers, and the chickens are everyone else. During the daily standup, in turn, each pig should say the following:
What they were doing yesterday
What they are doing today
If there are any issues affecting their ability to work
To avoid long conversations, there is a very useful question we can ask at any point: "Does everyone care?"
If there are issues that affect everyone at the daily standup, they should explain them, and the facilitator should encourage discussions to resolve the issue.
If there are issues that only affect certain people, the facilitator should ask those people to stay afterward to discuss them further. This is often called taking the conversation offline.
The daily standup should typically be very fast—no more than one or two minutes per person contributing.
At specific points in our process, it is very useful to have a retrospective. This is a chance to review our processes up until this point, and improve or change them where necessary. There are many different formats for retrospectives, but each team can decide for itself. Any interested parties may attend the retrospective, but only pigs (see daily standup meetings previously) may contribute. The important components of a retrospective are as follows:
The scrum master or project manager should facilitate the retrospective.
Every pig should contribute to the retrospective.
The team should recognize successful individuals and processes.
The team should determine areas in the process that could be improved or problems that were encountered previously.
For every negative point raised, the facilitator must define an action to resolve the problem and assign this action to an individual or themselves.
There is no bad feedback! All of the team must feel able and welcome to participate.
An example of a typical process might be:
Every pig has a pile of post-it notes.
In one minute, every pig notes down a positive point about the previous iteration on a single note each.
The facilitator arranges these notes on the wall, grouping similar items together. The more similar are the items, the more the team as a whole feel positive about something. Individuals should be recognized and commended if the team has said positive things about them.
In one minute, every pig notes down a negative point about the previous iteration on a single note each.
For every negative item, the facilitator discusses potential solutions (actions).
When an action is found, the facilitator assigns it the relevant person.
The retrospective is one of the most important parts of any process. There needs to be a way for developers to feed back their thoughts. Often they will have very useful and intelligent suggestions; sometimes they might want to rant or vent about something (providing a forum for this is important). If possible, it's nice to arrange a retrospective to be in an outside environment and combined with a more social affair like a team lunch. Relaxed individuals will give more honest criticism and feedback.
Many, many books have been written on development methodologies, and we have really only skimmed the surface in this section.
This chapter focused on processes and tools that we can use to help us develop in the most efficient manner possible. Although processes change from company to company, and tools are often developed in-house, the basic tenets we have discussed still apply. Our processes must be strict to ensure that they are followed, and we must always ensure there is a "feedback loop" so our staff can highlight any failings in our processes and they can be changed to reflect this.
If possible, the team as a whole should pick and choose from all the styles and methodologies available and continue to perfect them over time. These processes apply to all kinds of development disciplines as well as to CSS development specifically, but they form the base of your working environment. To build a good team and write the best and most efficient CSS you can, you need a solid underpinning.
The next chapter will focus on CSS formatting guides and rules we can apply specifically to how we write and structure our style sheets. We willalso begin to look at best practices and discuss what you need to consider when working on high-traffic websites.
[4] A markup language known as Creole aims to standardize the languages used in wikis and has been adopted (though not necessarily as the default language) by many of the less well-known wikis. You can read about Creole at www.wikicreole.org/
[5] You can read about Antony's standardized method of recording and prioritizing bugs called SEERS (Screenshot, Environment, Expected/Actual Behaviour, Reproduction, Severity) on his blog at http://zeroedandnoughted.com/standardised-bug-reporting-with-seers/
[6] We do not work for Atlassian. We just really like their stuff.
[7] A method of estimating tasks more accurately, created by Joel Spolsky. Read more about it at www.joelonsoftware.com/items/2007/10/26.html
[8] Git is an unpleasant thing to call someone equally unpleasant in British English slang. Linus Torvalds, the creator of Git, said, "I'm an egotistical bastard, and I name all my projects after myself. First Linux, now git."
[9] GitHub (http://github.com/) provides free public repositories that might be appropriate for your projects.
[10] It was actually quite difficult to create a conflict for this example, which demonstrates that SVN does a pretty good job of merging files on its own, except when you want it to.