
Creating an interlanguage of the social web
The discursive practice of markup
Untagged digital text is a linear data-type, a string of sequentially ordered characters. Such a string is regarded as unmarked text. Markup adds embedded codes or tags to text, turning something which is, from the point of view of computability, a flat and unstructured data-type, into something which is potentially computable (Buzzetti and McGann 2006).
Tagging or markup does two things. First, it does semantic work. It notates a text (or image, or sound) according to a knowledge representation of its purported external referrents. It connects a linear text with a formal conceptual scheme. Second, it does structural work. It notates a text with one particular semantics, the semantics of text itself, referring specifically to the text’s internal structures.
In the first, semantic agenda, a tag schema constitutes a controlled vocabulary describing a particular field in a formally defined and conceptually rigorous way. The semantics of each tag is defined with as little ambiguity as possible in relation to the other tags in a tag schema. Insofar as the tags relate to each other—they are indeed a language—they can be represented by means of a tag schema making structural connections (a < Person > is named by < GivenNames > and < Surname >) and counter distinctions against each other (the < City > Sydney as distinct from the < Surname > of the late eighteenth-century British Colonial Secretary after which the city was named). Schemas define tags paradigmatically.
To take Kant’s example of the willow and the linden tree, and express it the way a tagging schema might, we could mark up these words semantically as < tree > willow </tree > and < tree > linden tree </tree >. The tagging may have a presentational effect if these terms need highlighting, if they appear as keywords in a scientific text, for instance; or it may assist in search. This markup tells us some things about the structure of reality, and with its assistance we would be able to infer that a < tree > beech </tree > falls into the same category of represented meaning. Our controlled vocabulary comes from somewhere in the field of biology. In that field, a < tree > is but one instance of a < plant >. We could represent these structural connections visually by means of a taxonomy. However, < tree > is not an unmediated element of being; rather, it is a semantic category. How do we create this tag-category? How do we come to name the world in this way?
Eco (1999) provides Kant’s answer:
I see, for example, a willow and a linden tree. By comparing these objects, first of all, I note they are different from each other with regard to the trunk, branches, leaves etc.; but then, on reflecting only upon what they have in common: the trunk, branches and the leaves themselves, and by abstracting from their size, their shape, etc., I obtain the concept of a tree.
What follows is a process Kant calls ‘the legislative activity of the intellect’. From the intuition of trees, the intellect creates the concept of tree. ‘[T]o form concepts from representations it is… necessary to be able to compare, reflect, and abstract; these three logical operations of the intellect, in fact, are the essential and universal conditions for the production of any concept in general’ (quoted in Eco 1999, pp. 74–75).
Trees exist in the world. This is unexceptionable. We know they exist because we see them, we name them, we talk about them. We do not talk about trees because they are mere figment of conceptual projection, the result of a capricious act of naming. There is no doubt that there is something happening, ontologically speaking. However, we appropriate trees to thought, meaning, representation and communication through mental processes which take the raw material of sensations and from these construct abstractions in the form of concepts and systems of concepts or schemas. These concepts do not transparently represent the world; they represent how we figure the world to be.
And how do we do this figuring? When we use the concept ‘tree’ to indicate what is common to willows, linden trees and beeches, it is because our attention has been fixed on specific, salient aspects of apprehended reality—what is similar (though not the same) between the two trees, and what is different from other contiguous realities, such as the soil and the sky. But equally, we could have fixed our attention on another quality, such as the quality of shade, in which respect a tree and a built shelter share similar qualities.
Tags and tag schemas build an account of meaning through mental processes of abstraction. This is by no means an ordinary, natural or universal use of words. Vygotsky and Luria make a critical distinction between complex thinking and conceptual thinking. Complex thinking collocates things that might typically be expected to be found together: a tree, a swing, grass, flower beds, a child playing and another tree—for their circumstantial contiguity, the young child learns to call these a playground. From the point of view of consciousness and language, the world hangs together through syncretic processes of agglomeration. A playground is so named because it is this particular combination of things. The young child associates the word ‘playground’ with a concrete reference point. Conceptual thinking also uses a word, and it is often the same word as complex thinking. However, its underlying cognitive processes are different. Playground is defined functionally, and the word is used ‘as a means of actively centring attention, of abstracting certain traits, and symbolising them by the sign’ (Vygotsky 1962; also referred to in Cope and Kalantzis 1993 and Luria 1981).
Then, beyond the level of the word-concept, a syntax of abstraction is developed in which concept relates to concept. This is the basis of theoretical thinking, and the mental construction of accounts of a reality underlying what is immediately apprehended, and not even immediately visible (Cope and Kalantzis 1993). The way we construct the world mentally is not just a product of individual minds; it is mediated by the acquired structures of language with all its conceptual and theoretical baggage—the stuff of socialised worldviews and learned cultures.
Conceptual thinking represents a kind of ‘reflective consciousness’ or metaconsciousness. Markup tags are concepts in this sense and tag schemas are theories that capture the underlying or essential character of a field. When applied to the particularities of a specific piece of content, they work as a kind of abstracting metacommentary, relating the specifics of a piece of content to the generalised nature of the field. Academic, disciplinary work requires a kind of socio-semantic activity at a considerable remove from commonsense associative thinking.
Markup tags do not reflect reality in an unmediated way, as might be taken to be the case in a certain sense of the word ‘ontology’. Nor do they represent it comprehensively. Rather, they highlight focal points of attention relevant to a particular expressive domain or social language. In this sense, they represent worldviews. They are cultural artefacts. A tag does not exhaustively define the meaning function of the particular piece of content it marks up. Rather, it focuses on a domain-specific aspect of that content, as relevant to the representational or communicative purposes of a particular social language. In this sense ‘schema’ is a more useful concept than ‘ontology’, which tends to imply that our representations of reality embody unmediated truths of externalised being.
Notwithstanding these reservations, there is a pervasive underlying reality, an ontological grounding, which means that schemas will not work if they are mere figments of the imagination. Eco characterises the relationship between conceptualisation and the reality to which it refers as a kind of tension. On the one hand
being can be nothing other than what is said in many ways… every proposition regarding that which is, and that which could be, implies a choice, a perspective, a point of view… [O]ur descriptions of the world are always perspectival, bound up with the way we are biologically, ethnically, psychologically, and culturally rooted in the horizon of being (Eco 1999).
But this does not mean that anything goes. ‘We learn by experience that nature seems to manifest stable tendencies… [S]omething resistant has driven us to invent general terms (whose extension we can always review and correct)’ (Eco 1999). The world can never be simply a figment of our concept-driven imaginations. ‘Even granting that the schema is a construct, we can never assume that the segmentation of which it is the effect is completely arbitrary, because… it tries to make sense of something that is there, of forces that act externally on our sensor apparatus by exhibiting, at the least, some resistances’ (Eco 1999). Or as Latour says of the work of scientists, the semantic challenge is to balance facticity with social constructivism of disciplinary schemata (Latour 2004).
Structural markup
Of the varieties of textual semantic markup, one is peculiarly self-referential, the markup of textual structure, or schemas which represent the architectonics of text. A number of digital tagging schemas have emerged, which provide a functional account of the processes of containing, describing, managing and transacting text. They give a functional account of the world of textual content. Each tagging schema has its own functional purpose. A number of these tagging schemas have been created for the purpose of describing the structure of text, and to facilitate its rendering to alternative formats. These schemas are mostly derivatives of SGML, HTML and XHTML, and are designed primarily for rendering transformations through web browsers. Created originally for technical documentation, DocBook structures book text for digital and print renderings. The Text Encoding Initiative is ‘an international and interdisciplinary standard that helps libraries, museums, publishers, and individual scholars represent all kinds of literary and linguistic texts for online research and teaching’ (http://www.tei-c.org/).
Although the primary purpose of each schema may be a particular form of rendering, this belies the rigorous separation of semantics and structure from presentation. Alternative stylesheet transformations could be applied to render the marked up text in a variety of ways on a variety of rendering devices.
These tagging schemas do almost everything conceivable in the world of the written word. They can describe text comprehensively, and they support the manufacture of variable renderings of text on the fly by means of stylesheet transformations. The typesetting and content capture schemas provide a systematic account of structure in written text, and through stylesheet transformations they can render text to paper, to electronic screens of all sizes and formats, or to synthesised audio.
Underlying this is a fundamental shift in the processes of text work, described in Chapter 4, ‘What does the digital do to knowledge making?’. A change of emphasis occurs in the business of signing—broadly conceived as the design of meaning—from configuring meaning form (the specifics of the audible forms of speaking and the visual form of written text) to ‘marking up’ for meaning function in such a way that alternative meaning forms, such as variable visual (written) and audio forms of language, can be rendered by means of automated processes from a common digital source.
In any digital markup framework that separates the structure from presentation, the elementary unit of meaning function is marked by the tag, specifying the meaning function for the most basic ‘chunk’ of represented content. Tags, in other words, describe the meaning function of a unit of content. For instance, a word or phrase may be tagged as < Emphasis >, < KeywordTerm > or < OtherLanguageTerm >. These tags describe the peculiar meaning function of a piece of content. In this sense, a system of tags works like a functional grammar; it marks up key features of the information architecture of a text. Tags delineate critical aspects of meaning function, and they do this explicitly by means of a relatively consistent and semantically unambiguous metalanguage. This metalanguage acts as a kind of running commentary on meaning functions which are otherwise embedded, implicit or to be inferred from context.
Meaning form follows mechanically from the delineation of meaning function, and this occurs in a separate stylesheet transformation space. Depending on the stylesheet, for instance, each of the three functional tags < Emphasis >, < KeywordTerm > and < OtherLanguageTerm > may be rendered to screen or print either as boldface or italics, or as an audible intonation in the case of rendering as synthesised voice.
Given the pervasiveness of structural markup, one might expect that an era of rapid and flexible transmission of content would quickly dawn. But this has not occurred, or at least not yet, and for two reasons. The first is the fact that, although almost all content created over the past quarter of a century has been digitised, the formats are varied and incompatible. Digital content is everywhere, but most of it has been created, and continues to be created, using typographically oriented markup frameworks. These frameworks are embedded in software packages that provide tools for working with text which mimic the various trades of the Gutenberg universe: an author may use Word; a desktop publisher or latter-day typesetter may use inDesign; and a printer will use a PDF file as if it were a virtual forme or plate. The result is sticky file flow and intrinsic difficulties in version control and digital repository maintenance. How and where is a small correction made to a book that has already been published? Everything about this relatively simple problem, as it transpires, remains complex, slow and expensive. However, in a fully comprehensive, integrated file flow, things that are slow and expensive today should become easier and cheaper—a small change by an author to the source text could be approved by a publisher so that the very next copy of that work could include that change.
To return to the foundational question of the changed means of production of meaning in semantic and structural text-work environment, we want to extend the distinction of ‘meaning form’ from ‘meaning function’. Signs are the elementary components of meaning. And ‘signs’, say Kress and Leeuwen, are ‘motivated conjunctions of signifiers (forms) and signifieds (meanings)’ (Kress and van Leeuwen 1996). Rephrasing, we would call motivated meanings, the products of the impulse to represent the world and communicate those representations, ‘meaning functions’. The business of signing, motivated as it is by representation (meaning interpreted oneself) and communication (meaning interpreted by others), entails an amalgam of function (a reason to mean) and form (the use of representational resources which might adequately convey that meaning).
The meaning function may be a flower in a garden on which we have fixed our focus for a moment through our faculties of perception and imagination. For that moment, this particular flower captures our attention and its features stand out from its surroundings. The meaning function is our motivation to represent this meaning and to communicate about it. How we represent this meaning function is a matter of meaning form. The meaning form we choose might be iconic—we could draw a sketch of the flower, and in this case, the act of signing (form meets function) is realised through a process of visual resemblance. Meaning form—the drawing of the flower—looks like meaning function, or what we mean to represent: the flower. Or the relation between meaning form and function may be, as is the case for language, arbitrary. The word ‘flower’, a symbolic form, has no intrinsic connection with the meaning function it represents. In writing or in speech the word ‘flower’ conventionally represents this particular meaning function in English. We can represent the object to ourselves using this word in a way which fits with a whole cultural domain of experience (encounters with other flowers in our life and our lifetime’s experience of speaking about and hearing about flowers). On the basis of this conventional understanding of meaning function, we can communicate our experience of this flower or any aspect of its flower-ness to other English speakers.
This, in essence, is the stuff of signing, the focal interest of the discipline of semiotics. It is an ordinary, everyday business, and the fundamental ends do not change when employing new technological means. It is the stuff of our human natures. The way we mean is one of the distinctive things that makes us human.
One of the key features of the digital revolution is the change in the mechanics of conjoining meaning functions with meaning forms in structural and semantic markup. We are referring here to a series of interconnected changes in the means of production of signs. Our perspective is that of a functional linguistics for digital text. Traditional grammatical accounts of language trace the limitlessly complex structures and patterns of language in the form of its immediately manifest signs. Only after the structure of forms has been established is the question posed, ‘what do these forms mean?’. In contrast, functional linguistics turns the question of meaning around the other way: ‘how are meanings expressed?’. Language is conceived as a system of meanings; its role is to realise or express these meanings. It is not an end in itself; it is a means to an end (Halliday 1994). Meaning function underlies meaning form. An account of meaning form must be based on a functional interpretation of the structures of meaning. Meaning form of a linguistic variety comprises words and their syntactical arrangement, as well as the expressive or presentational processes of phonology (sounding out words or speaking) and graphology (writing). Meaning form needs to be accounted for in terms of meaning function.
Structural and semantic markup adds a second layer of meaning to the process of representation in the form of a kind of meta-semantic gloss. This is of particular value in the deployment of specialised disciplinary discourses. Such discourses rely on a high level of semantic specificity. The more immersed you are in that particular discourse—the more critical it is to your livelihood or identity in the world, for instance—the more important these subtle distinctions of meaning are likely to be. Communities of practice identify themselves by the rigorous singularity of purpose and intent within their particular domain of practice, and this is reflected in the relative lack of terminological ambiguity within the discourse of disciplinary practice of that domain. In these circumstances semantic differences between two social languages in substantially overlapping domains is likely to be absolutely critical. This is why careful schema mapping and alignment is such an important task in the era of semantic and structural markup.
Metamarkup: developing markup frameworks
We now want to propose in general terms an alternative framework to the formalised semantic web, a framework that we call an instance of ‘semantic publishing’. The computability of the web today is little better than the statistical frequency analyses of character clusters that drive search algorithms, or the flat and featureless world of folksonomies and conceptual popularity rankings in tag clouds. Semantic publishing is a counterpoint to these simplistic modes of textual computability. We also want to advocate a role for conceptualisation and theorisation in textual computability, against an empiricism which assumes that the right algorithms are all we need to negotiate the ‘data deluge’—at which point, it is naively thought, all we need to do is calculate and the world will speak for itself (Anderson 2009). In practical terms, we have been working through and experimenting with this framework in the nascent CGMeaning online schema making and schema matching environment.
Foundations to the alternative framework to the formalised semantic web
The framework has five foundations.
Foundation 1 Schema making should be a site of social dialectic, not ontological legislation
Computable schemas today are made by small groups of often nameless experts, and for that are inflexibly resistant to extensibility and slow to change. The very use of the word ‘ontology’ gives an unwarranted aura of objectivity to something that is essentially a creature of human-semantic configuration.
Schemas, however, are specific constructions of reality within the frame of reference of highly particularised social languages that serve disciplinary, professional or other specialised purposes. Their reality is a social reality. They are no more and no less than a ‘take’ on reality, which reflects and represents a particular set of human interests. These interests are fundamentally to get things done—funnels of commitment, to use Scollon’s words (Scollon 2001)—rather than mere reflections of inert, objectified ‘being’. Schemas, in other words, are ill served by the immutable certainty implied by the word ‘ontology’. Reality does not present itself through ontologies in an unmediated way. Tagging schemas are better understood to be mediated relationships of meaning rather than static pictures of reality.
However, the socio-technical environments of their construction today do not support the social dialectic among practitioners that would allow schemas to be dynamic and extensible. CGMeaning attempts to add this dimension. Users can create or import schemata—XML tags, classification schemes, database structures—and establish a dialogue between a ‘curator’ who creates or imports a schema ready for extension or further schema alignment—and the community of users which may need additional tags, finer or distinctions or new definitions of tag content, and clarifications of situations of use by exemplification. In other words, rather than top-down imposition as if any schema ever deserved the objectifying aura of ‘ontology’, and rather than the fractured failure to discuss and refine meanings of ‘folksonomies’, we need the social dialectic of curator-community dialogue about always provisional, always extensible schemata. This moves the question of semantics from the anonymous hands of experts into the agora of collective intelligence.
Foundation 2 From a one-layered linear string, to a double-layered string with meta-semantic gloss
Schemas should not only be sites of social dialectic about tag meanings and tag relations. Semantic markup practices establish a dialectic between the text and its markup. These practices require that authors mark up or make explicit meanings in their texts. Readers may also be invited to mark up a text in a process of computable social-notetaking. A specialised text may already be some steps removed from vernacular language. However, markup against a schema may take these meanings to an even more finely differentiated level of semantic specificity. The text-schema dialectic might work like this: an instance mentioned in the text may be evidence of a concept defined in a schema, and the act of markup may prompt the author or reader to enter into critical dialogue in their disciplinary community about the meanings as currently expressed in the tags and tag relations. The second layer, in other words, does not necessarily and always formally fix meanings, or force them to be definitive. Equally, at times, it might open the schema to further argumentation and clarification, a process Brandom calls ‘giving and asking for reasons’ (Brandom 1994). ‘Such systems develop and sustain themselves by marking their own operations self-reflexively; [they] facilitate the self-reflexive operations of human communicative action’ (Buzzetti and McGann 2006).
In other words, we need to move away from the inert objectivity of imposed ontologies, towards a dialogue between text and concept, reader and author, specific instance and conceptual generality. Markup can stabilise meaning, bring texts into conformance with disciplinary canons. Equally, in the dialogical markup environment we propose here, it can prompt discussions about concepts and their relations which have dynamically incremental or paradigm-shifting consequences on the schema.
In this process, we will also move beyond the rigidities of XML, in which text is conceived as an ‘ordered hierarchy of content objects’, like a nested set of discrete Chinese boxes (Renear, Mylonas and Durand 1996). Meaning and text, contrary to this representational architecture, ‘are riven with overlapping and recursive structures of various kinds just as they always engage, simultaneously, hierarchical as well as non-hierarchical formations’ (Buzzetti and McGann 2006). Our solution in CGMeaning is to allow authors and readers to ‘paint’ overlapping stretches of text with their semantic tags.
Foundation 3 Making meanings explicit
Markup schemas—taxonomies as well as folksonomies—rarely have readily accessible definitions of tag meanings. In natural language, meanings are given and assumed. However, in the rather unnatural language of scholarly technicality, meanings need to be described with higher degree of precision, to novices and also for expert practitioners at points of conceptual hiatus or questionable applicability. For this reason, CGMeaning provides and infrastructure for dictionary-formation, but with some peculiar ground rules.
Dictionaries of natural language capture the range of uses, nuances, ambiguities and metaphorical slippages. They describe language as a found object, distancing themselves from any normative judgement about use (Jackson 2002). However, even for their agnosticism about the range of situations of use, natural language dictionaries are of limited value given discourse and context-specific range of possible uses. Fairclough points out that ‘it is of limited value to think of a language as having a vocabulary which is documented in “the” dictionary, because there are a great many overlapping and competing vocabularies corresponding to different domains, institutions, practices, values and perspectives’ (Fairclough 1992). Gee calls these domain-specific discourses ‘social languages’ (Gee 1996). The conventional dictionary solution to the problem of ambiguity is to list the major alternative meanings of a word, although this can only reflect gross semantic variation. No dictionary could ever capture comprehensively the never-ending subtleties and nuances ascribed differentially to a word in divergent social languages.
The dictionary infrastructure in CGMeaning is designed so there is only one meaning per concept/tag, and this is on the basis of a point of salient conceptual distinction that is foundational to the logic of the specific social language and the schema that supports it, for instance: ‘Species are groups of biological individuals that have evolved from a common ancestral group and which, over time, have separated from other groups that have also evolved from this ancestor.’ Definitions in this dictionary space shunt between natural language and unnatural language, between (in Vygotsky’s psychological terms) complex association and the cognitive work of conceptualisation. In the unnatural language of disciplinary use, semantic saliences turn on points of generalisable principle. This is how disciplinary work is able at times to uncover the not-obvious, the surprising, the counter-intuitive. This is when unnatural language posits singularly clear definitions that are of strategic use, working with abstractions that are powerfully transferable from one context of application to another, or in order to provide a more efficient pedagogical alternative for novices than the impossible expectation of having to reinvent the world by retracing the steps of its every empirical discovery. Schemata represent the elementary stuff of theories and paradigms, the congealed sedimentations of collective intelligence.
Moreover, unlike a natural language dictionary, a dictionary for semantic publishing defines concepts—which may be represented by a word or a phrase—and not words. Concepts are not necessarily nouns or verbs. In fact, in many cases concepts can be conceived as either states or processes, hence the frequently easy transliteration of nouns into verbs and the proliferation in natural language of non-verb hybrids such as gerunds and particles. For consistency’s sake and to reinforce the idea of ‘concept’, we would use the term ‘running’ instead of ‘run’ as the relevant tag in a hypothetical sports schema. In fact, the process of incorporating actions into nouns, or ‘nominalisation’, is one of the distinctive discursive moves of academic disciplines and typical generally of specialised social languages (Martin and Halliday 1993). As Martin points out, ‘one of the main functions of nominalisation is in fact to build up technical taxonomies of processes in specialised fields. Once technicalised, these nominalisations are interpretable as things’ (Martin 1992). This, incidentally, is also a reason why we would avoid the belaboured intricacies of RDF (Resource Description Framework), which attempts to build sentence-like propositions in the subject - > predicate - > object format.
Moreover, this kind of dictionary accommodates both ‘lumpers’ (people who would want to aggregate by more general saliences) and ‘splitters’ (people who would be more inclined to make finer conceptual distinctions)—to employ terms used to characterise alternative styles of thinking in biological taxonomy. Working with concepts allows for the addition of phrases which can do both of these things, and to connect them, in so doing adding depth to the conceptual dialogue and delicacy to its semantics.
Another major difference is that this kind of dictionary is not alphabetically ordered (for which, in any event, in the age of digital search, there is no longer any need). Rather, it is arranged in what we call ‘supermarket order’. In this way, things can be associated according to the rough rule of ‘this should be somewhere near this’, with the schema allowing many other formal associations in addition to the best-association shelving work of a curator. There is no way you can know the precise location of the specific things you need purchase among the 110,000 different products in a Wal-Mart store, but mostly you can find them without help by a process of rough association. More rigorous connections will almost invariably be multiple and cross-cutting, and with varying contiguities according to the interest of the author or reader or the logic of the context. However, an intuitive collocation can be selected for the purpose of synergistic search.
Furthermore, this kind of dictionary does a rigorous job of defining concepts whose order of abstraction is higher (on what principle of salience is this concept a kind of or a part of a superordinate concept?), defining by distinction (what differentiates sibling concepts?) and exemplifying down (on what principles are subsidiary concepts instances of this concept?).
A definition may also describe essential, occasional or excluded properties. It may describe these using a controlled vocabulary of quantitative properties (integers, more than, less than, nth, equal to, all/some/none of, units of measurement etc.) and qualitative properties (colours, values). A definition may also shunt between natural language and more semantically specified schematic language by making semantic distinctions between a technical term and its commonsense equivalent in natural language.
Finally a definition may include a listing of some or all exemplary instances. In fact, the instances become part of the dictionary as well, thus (and once more, unlike a natural language dictionary) including any or every possible proper noun. This is a point at which schemata build transitions between the theoretical (conceptual) and the empirical (instances).
Foundation 4 Positing relations
A simple taxonomy specifies parent, child and sibling relations. However, it does this without the level of specificity required to support powerful semantics. For example, in parent–child relations we would want to distinguish hyponymy ‘a kind of’ from meronymy ‘a part of’. In addition, a variety of cross-cutting and intersecting relations can be created, including relations representing a range of semantic primitives such as ‘also called’, ‘opposite of’, ‘is not’, ‘is like but [in specified respects] not the same as’, ‘possesses’, ‘causes’, ‘is an example of’, ‘is associated with’, ‘is found in/at [time or place]’, ‘is a [specify quality] relation’ and ‘is by [specify type of] comparison’. Some of these relations may be computable using first order logic or description logics (Sowa 2000, 2006), others not.
Foundation 5 Social schema alignment
Schemata with different foci sometimes have varying degrees of semantic overlap. They sometimes talk, in other words, about the same things, albeit with varied perspectives and serving divergent interests. CGMeaning builds a social space for schema alignment, using an ‘interlanguage’ mechanism. Although initially developed in the case of one particular instantiation of problem of interoperability—for the electronic standards that apply to publishing (Common Ground Publishing 2003)—the core technology is applicable to the more general problem of interoperability characterised by the semantic publishing.
Developing an interlanguage mechanism
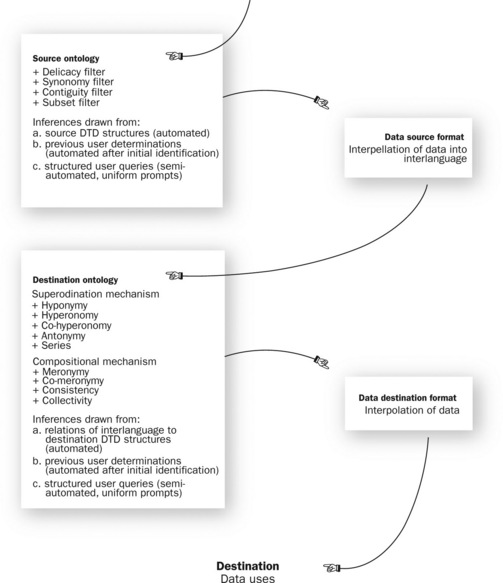
By filtering schemata through the ‘interlanguage’ mechanism, a system is created that allows conversation and information interchange between disjoint schemas. In this way, it is possible to create functionalities for data framed within the paradigm of one schema which extend well beyond those originally conceived by that schema. This may facilitate interoperability between schemas, allowing data originally designed for use in one schema for a particular set of purposes to be used in another schema for a different set of purposes.
The interlanguage mechanism means that metadata newly created through its apparatus to be interpolated into any number of metadata schemas. It also provides a method by means of which data harvested in one metadata schema can be imported into another. From a functional point of view, some of this process can be fully automated, and some the subject of automated queries requiring a human-user response.
The interlanguage mechanism, in sum, is designed to function in two ways:
![]() for new data, a filter apparatus provides full automation of interoperability on the basis of the semantic and syntactical rules
for new data, a filter apparatus provides full automation of interoperability on the basis of the semantic and syntactical rules
![]() for data already residing in an schema, data automatically passes through a filter apparatus using the interlanguage mechanism, and passes on into other schemas or ontologies even though the data had not originally been designed for the destination schema.
for data already residing in an schema, data automatically passes through a filter apparatus using the interlanguage mechanism, and passes on into other schemas or ontologies even though the data had not originally been designed for the destination schema.
The filter apparatus is driven by a set of semantic and syntactical rules as outlined below, and throws up queries whenever an automated translation of data is not possible in terms of those semantic rules.
The interlanguage apparatus is designed to be able to read tags, and thus interpret the data which has been marked up by these tags, according to two overarching mechanisms, and a number of submechanisms. The two overarching mechanisms are the superordination mechanism and the composition mechanism—drawing in part here on some distinctions made in systemic-functional linguistics (Martin 1992).
The superordination mechanism constructs tag-to-tag ‘is a…’ relationships. Within the superordination mechanism, there are the submechanisms of hyponymy (‘includes in its class…’), hyperonymy (‘is a class of…’), co-hyperonoymy (‘is the same as…’), antinomy (‘is the converse of…’) and series (‘is related by gradable opposition to…’).
The composition mechanism constructs tag-to-tag ‘has a.’ relationships. Within the composition mechanism, there are the submechanisms of meronymy (‘is a part of…’), co-meronymy (‘is integrally related to but exclusive of…’), consistency (‘is made of…’), collectivity (‘consists of…’).
These mechanisms can be fully automated in the case of new data formation within any schema, in which case, deprecation of some aspects of an interoperable schema may be required as a matter of course at the point of data entry. In the case of legacy data generated in schemas without anticipation of, or application of, the interlanguage mechanism, data can be imported in a partially automated way. In this case, tag-by-tag or field-by-field queries are automatically generated according to the filter mechanisms of:
![]() taxonomic distance (testing whether the relationships of composition and superordination are too distant to be necessarily valid)
taxonomic distance (testing whether the relationships of composition and superordination are too distant to be necessarily valid)
![]() levels of delicacy (testing whether an aggregated data element needs to be disaggregated and re-tagged)
levels of delicacy (testing whether an aggregated data element needs to be disaggregated and re-tagged)
![]() potential semantic incursion (identifying sites of ambiguity)
potential semantic incursion (identifying sites of ambiguity)
![]() the translation of silent into active tags or vice versa (at what level in the hierarchy of composition or superordination data needs to be entered to effect superordinate transformations).
the translation of silent into active tags or vice versa (at what level in the hierarchy of composition or superordination data needs to be entered to effect superordinate transformations).
The interlanguage mechanism (Figure 13.1) is located in CGMeaning, a schema-building and alignment tool. This software defines and determines:
![]() database structures for storage of metadata and data
database structures for storage of metadata and data
![]() synonyms across the tagging schemas for each schema being mapped
synonyms across the tagging schemas for each schema being mapped
![]() two definitional layers for every tag: underlying semantics and application-specific semantics; in this regard, CGMeaning creates the space for application-specific paraphrases can be created for different user environments; the underlying semantics necessarily generates abstract dictionary definitions which are inherently not user-friendly; however, in an application, each concept-tag needs to be described and defined in ways that are intelligible within that domain; it is these application-specific paraphrases that render to the application interface in the first instance
two definitional layers for every tag: underlying semantics and application-specific semantics; in this regard, CGMeaning creates the space for application-specific paraphrases can be created for different user environments; the underlying semantics necessarily generates abstract dictionary definitions which are inherently not user-friendly; however, in an application, each concept-tag needs to be described and defined in ways that are intelligible within that domain; it is these application-specific paraphrases that render to the application interface in the first instance
![]() export options into an extensible range of electronic standards expressed as XML schemas
export options into an extensible range of electronic standards expressed as XML schemas
![]() CGMeaning, which manages the superordination and compositional mechanisms described above, as well as providing an interface for domain-specific applications in which interoperability is required.
CGMeaning, which manages the superordination and compositional mechanisms described above, as well as providing an interface for domain-specific applications in which interoperability is required.
Following are some examples of how this mechanism may function. In one scenario, new data might be constructed according to a source schema which has already become ‘aware’ by means of previous applications of the interlanguage mechanism as a consequence of the application of the mechanism. In this case, the mechanism commences with the automatic interpellation of data, as the work of reading and querying the source schema has already been performed. In these circumstances, the source schema in which the new data is constructed becomes a mere facade for the interlanguage, taking the form of a user interface behind which the processes of subordination and composition occur.
In another scenario, a quantum of legacy source data is provided, marked up according to the schematic structure of a particular source schema. The interlanguage mechanism then reads the structure and semantics immanent in the data, interpreting this from schema and the way the schema is realised in that particular instance. It applies four filters: a delicacy filter, a synonymy filter, a contiguity filter and a subset filter. The apparatus is able to read into the schema and its particular instantiation an inherent taxonomic or schematic structure. Some of this is automated, as the relationships of tags is unambiguous based on the readable structure of the schema and evidence drawn from its instantiation in a concrete piece of data. The mechanism is also capable of ‘knowing’ the points at which it is possible there might be ambiguity, and in this case throws up a structured query to the user. Each human response to a structured query becomes part of the memory of the mechanism, with implications drawn from the user response and retained for later moments when interoperability is required by this or another user. On this basis, the mechanism interpellates the source data into the interlanguage format, while at the same time automatically ‘growing’ the interlanguage itself based on knowledge acquired in the reading of the source data and source schema.
Having migrated into the interlanguage format, the data is then reworked into the format of the destination schema. It is rebuilt and validated according to the mechanisms of superordination (hyponymy, hyperonymy, co-hyperonomy, antonymy and series) and composition (meronymy, co-meronymy, consistency, collectivity). A part of this process is automated, according to the inherent structures readable into the destination schema, or previous human readings that have become part of the accumulated memory of the interlanguage mechanism. Where the automation of the rebuilding process cannot be undertaken by the apparatus with assurance of validity (when a relation is not inherent to the destination schema, nor can it be inferred from accumulated memory in which this ambiguity was queried previously), a structured query is once again put to the user, whose response in turn becomes a part of the memory of the apparatus, for future use. On this basis, the data in question is interpolated into its destination format. From this point, it can be used in its destination context or schema environment, notwithstanding the fact that the data had not been originally formatted for use in that environment.
Key operational features of this mechanism include:
![]() the capacity to absorb effectively and easily deploy new schemas which refer to domains of knowledge, information and data that substantially overlap (vertical ontology-over-ontology integration); the mechanism is capable of doing this without the exponential growth in the scale of the task characteristic of the existing ‘crosswalk’ method
the capacity to absorb effectively and easily deploy new schemas which refer to domains of knowledge, information and data that substantially overlap (vertical ontology-over-ontology integration); the mechanism is capable of doing this without the exponential growth in the scale of the task characteristic of the existing ‘crosswalk’ method
![]() the capacity to absorb schemas representing new domains that do not overlap with the existing range of domains and ontologies representing these domains (horizontal ontology-beside-ontology integration)
the capacity to absorb schemas representing new domains that do not overlap with the existing range of domains and ontologies representing these domains (horizontal ontology-beside-ontology integration)
![]() the capacity to extend indefinitely into finely differentiated subdomains within the existing range of domains connected by the interlanguage, but not yet this finely differentiated (vertical ontology-within-ontology integration).
the capacity to extend indefinitely into finely differentiated subdomains within the existing range of domains connected by the interlanguage, but not yet this finely differentiated (vertical ontology-within-ontology integration).
In the most challenging of cases—in which the raw digital material is created in a legacy schema, and in which that schema is not already known to the interlanguage from previous interactions—the mechanism:
![]() interprets structure and semantics from the source schema and its instantiation in the case of the particular quantum of source data, using the filter mechanisms described above
interprets structure and semantics from the source schema and its instantiation in the case of the particular quantum of source data, using the filter mechanisms described above
![]() draws inferences in relation to the new schema and the particular quantum of data, applying these automatically and presenting structured queries in cases where the apparatus and its filter mechanism ‘knows’ that supplementary human interpretation is required
draws inferences in relation to the new schema and the particular quantum of data, applying these automatically and presenting structured queries in cases where the apparatus and its filter mechanism ‘knows’ that supplementary human interpretation is required
![]() stores any automated or human-supplied interpretations for future use, thus building knowledge and functional useability of this schema into the interlanguage.
stores any automated or human-supplied interpretations for future use, thus building knowledge and functional useability of this schema into the interlanguage.
These inferences then become visible to subsequent users, and capable of amendment by users, through the CGMeaning interface, which:
![]() interpellates the data into the interlanguage format
interpellates the data into the interlanguage format
![]() creates a crosswalk from new schema into a designated destination schema, for instance a new format for structuring or rendering text, using the superordination and composition mechanisms; these are automated in cases where the structure and semantics of the destination schema are self-evident, or they are the subject of structured queries where they are not, or they are drawn from the CGMeaning repository in instances where the same query has been answered by an earlier user
creates a crosswalk from new schema into a designated destination schema, for instance a new format for structuring or rendering text, using the superordination and composition mechanisms; these are automated in cases where the structure and semantics of the destination schema are self-evident, or they are the subject of structured queries where they are not, or they are drawn from the CGMeaning repository in instances where the same query has been answered by an earlier user
To give another example, the source schema is already known to the interlanguage, by virtue of automated validations based not only on the inherent structure of the schema, but also many validations against a range of data instantiations of that schema, and numerous user clarifications of queries. In this case, by entering data in an interface that ‘knowingly’ relates to an interlanguage which has been created using the mechanisms provided here, there is no need for the filter mechanisms nor the interpolation processes that are necessary in the case of legacy data and unknown source schemas; rather, data is entered directly into the interlanguage format, albeit through the user interface ‘facade’ of the source schema. The apparatus then interpolates the data onto the designated destination schema.
Schema alignment for semantic publishing: the example of Common Ground Markup Language
Common Ground Markup Language (CGML) is a schema for marking up and storing text as structured data, created in the tag definition and schema alignment environment, CGMeaning. The storage medium can be XML files, or it can be a database in which fields are named by tags, and from which exports produce XML files marked up for structure and semantics, ready for rendering through available stylesheet transformations. The result is text that is more easily located by virtue of the clarity and detail of metadata markup, and capable of a range of alternative renderings. CGML structures and stores data on the basis of a functional account of text, not just as an object but as a process of collaborative construction. The focal point of CGML is a functional grammar of text, as well as a kind of grammar (in the metaphorical sense of generalised reflection) of the social context of text work. However, with CGML, ‘functional’ takes on a peculiarly active meaning. The markup manufactures the text in the moment of rendering, through the medium of stylesheet transformation in one or several rendering processes or media spaces.
In CGML, as is the case for any digital markup framework that separates structure and semantics from presentation, the elementary unit of meaning function is marked by the tag. The tag specifies the meaning function for the most basic ‘chunk’ of represented content. Tags, in other words, describe the meaning function of a unit of content. For instance, a word or phrase may be tagged as < Emphasis >, < KeywordTerm > or < OtherLanguageTerm >. These describe the peculiar meaning function of a piece of content. In this sense, a system of tags works like a partial functional grammar: they mark up key features of the information architecture of a text. Tags delineate critical aspects of meaning function, and they do this explicitly by means of a relatively consistent and semantically unambiguous metalanguage. This metalanguage acts as a kind of running commentary on meaning functions, which are otherwise embedded, implicit or to be inferred from context.
Meaning form follows mechanically from the delineation of meaning function, and this occurs in a separate stylesheet transformation space. Depending on the stylesheet, each of the three functional tags < Emphasis >, < KeywordTerm > and < OtherLanguageTerm > may be rendered to screen or print either as boldface or italics, or as a particular intonation in the case of rendering as synthesised voice. Stylesheets, incidentally, are the exception to the XML rule strictly to avoid matters of presentation; meaning form is their exclusive interest.
CGML, in other words, is a functional schema for authorship and publishing. CGML attempts to align the schemas we will describe shortly, incorporating their varied functions. CGML is an interlanguage. Its concepts constitute a paradigm for representational work, drawing on a historically familiar semantics, but adapting this to the possibilities of the internet. Its key devices are thesaurus (mapping against functional schemas) and dictionary (specifying a common ground semantics). These are the semantic components for narrative structures of text creation, or the retrospective stories that can be told of the way in which, for instance, authors, publishers, referees, reviewers, editors and the like construct and validate text. The purpose of this work is both highly pragmatic (such as a description of an attempt to create a kind of functional grammar of the book) and highly theoretical (a theory of meaning function capable of assisting in the partially automated construction and publication of variable meaning forms).
In the era of digital media, the social language of textuality is expressed in a number of schemas. It is increasingly the case that these schemas perform a wide ranging, fundamental and integrated set of functions. They contain the content—the electronic files that provide structural and semantic shape for the data which will be rendered as a book. They describe the content—for the purposes of data transfer, warehousing and retrieval. They manage the content—providing a place where job process instructions and production data are stored. And they transact the content.
A number of digital tagging schemas have emerged which provide a functional account of these processes of containing, describing, managing and transacting text. More broadly, they provide a functional account of the world of textual content in general. Each tagging schema has its own functional purpose, or ‘funnel of commitment’, to use Scollon’s terminology. We will briefly describe a few of these below, categorising them into domains of professional and craft interest: typesetting and content capture, electronic rendering, print rendering, resource discovery, cataloguing, educational resource creation, e-commerce and digital rights management. The ones we describe are those we have mapped into CGML.
Typesetting and content capture
Unicode (http://www.unicode.org) appears destined to become the new universal character encoding standard, covering all major language and scripts (Unicode 2010), and replacing the American Standard Code for Information Interchange (ASCII), which was based solely on Roman script.
A number of tagging schemas have been created for the purpose of describing the structure of text, and to facilitate its rendering to alternative formats. These schemas are mostly derivatives of SGML. HTML (W3C 2010a) and XHTML (W3C 2010b) are designed primarily for rendering transformations through web browsers. The OASIS/UNESCO sanctioned DocBook standard is for structuring book text, which can subsequently be rendered electronically or to print (DocBook Technical Committee 2010). The Text Encoding Initiative is ‘an international and interdisciplinary standard that helps libraries, museums, publishers and individual scholars represent all kinds of literary and linguistic texts for online research and teaching’ (http://www.tei-c.org).
Although the primary purpose of each schema may be a particular form of rendering, this belies the rigorous separation of semantics and structure from presentation. Alternative stylesheet transformations could be applied to render the marked up text in a variety of ways. Using different stylesheets, it is possible, for instance, to render DocBook either as typesetting for print or as HTML.
Electronic rendering
Electronic rendering can occur in a variety of ways—as print facsimiles in the form of Portable Document Format (PDF), or as HTML readable by means of a web browser. Other channel alternatives present themselves as variants or derivatives of HTML: the Open eBook Standard for handheld electronic reading devices (International Trade Standards Organization for the eBook Industry 2003) and Digital Talking Book (ANSI/NISO 2002), facilitating the automated transition of textual material into audio form for the visually impaired or the convenience of listening to a text rather than reading it.
Print rendering
The Job Definition Format (JDF) appears destined to become universal across the printing industry (http://www.cip4.org/). Specifically for variable print, Personalised Print Markup Language (PPML) has also emerged (PODi 2003).
Created by a cross-industry international body, the Association for International Cooperation for the Integration of Processes in Pre-Press, Press and Post-Press, the JDF standard has been embraced and supported by all major supply-side industry participants (equipment and business systems suppliers). It means that one electronic file contains all data related to a particular job. It is free (in the sense that there is no charge for the use of the format) and open (in the sense that its tags are transparently presented in natural language; it is unencrypted, its coding can be exposed and it can be freely modified, adapted and extended by innovators—in sharp distinction to proprietary software).
The JDF functions as a digital addendum to offset print, and as the driver of digital print. Interoperability of JDF with other standards will mean, for instance, that a book order triggered through an online bookstore (the ONIX space, as described below) could generate a JDF wrapper around a content file as an automated instruction to print and dispatch a single copy.
The JDF serves the following functions:
![]() Pre-press—Full job specification, integrating pre-press, press and post-press (e.g. binding) elements, in such a way that these harmonise (the imposition matches the binding requirements, for example). This data is electronically ‘tagged’ to the file itself, and in this sense it actually ‘makes’ the ‘printing plate’.
Pre-press—Full job specification, integrating pre-press, press and post-press (e.g. binding) elements, in such a way that these harmonise (the imposition matches the binding requirements, for example). This data is electronically ‘tagged’ to the file itself, and in this sense it actually ‘makes’ the ‘printing plate’.
![]() Press—The job can then go onto any press from any manufacturer supporting the JDF standard (and most major manufacturers now do). This means that the press already ‘knows’ the specification developed at the pre-press stage.
Press—The job can then go onto any press from any manufacturer supporting the JDF standard (and most major manufacturers now do). This means that the press already ‘knows’ the specification developed at the pre-press stage.
![]() Post-press—Once again, any finishing is determined by the specifications already included in the JDF file, and issues such as page format and paper size are harmonised across all stages in the manufacturing process.
Post-press—Once again, any finishing is determined by the specifications already included in the JDF file, and issues such as page format and paper size are harmonised across all stages in the manufacturing process.
The effects of wide adoption of this standard by the printing industry include:
![]() Automation—There is no need to enter the job specification data from machine to machine, and from one step in the production process to the next. This reduces the time and thus the cost involved in handling a job.
Automation—There is no need to enter the job specification data from machine to machine, and from one step in the production process to the next. This reduces the time and thus the cost involved in handling a job.
![]() Human error reduction—As each element of a job specification is entered only once, this reduces waste and unnecessary cost.
Human error reduction—As each element of a job specification is entered only once, this reduces waste and unnecessary cost.
![]() Audit trail—Responsibility for entering specification data is pushed further back down the supply chain, ultimately even to the point where a customer will fill out the ‘job bag’ simply by placing an order through an online B-2-B interface. This shifts the burden of responsibility for specification, to some degree, to the initiator of an order, and records by whom and when a particular specification was entered. This leads to an improvement in ordering and specification procedures.
Audit trail—Responsibility for entering specification data is pushed further back down the supply chain, ultimately even to the point where a customer will fill out the ‘job bag’ simply by placing an order through an online B-2-B interface. This shifts the burden of responsibility for specification, to some degree, to the initiator of an order, and records by whom and when a particular specification was entered. This leads to an improvement in ordering and specification procedures.
![]() Equipment variations—The standard reduces the practical difficulties previously experienced using different equipment supplied by different manufacturers. This creates a great deal of flexibility in the use of plant.
Equipment variations—The standard reduces the practical difficulties previously experienced using different equipment supplied by different manufacturers. This creates a great deal of flexibility in the use of plant.
Resource discovery
Resource discovery can be assisted by metadata schemas that use tagging mechanisms to provide an account of the form and content of documents. In the case of documents locatable on the internet, Dublin Core is one of the principal standards, and is typical of others (Dublin Core Metadata Initiative 2010). It contains a number of key broadly descriptive tags: < title >, < creator >, < subject >, < description >, < publisher >, < contributor >, < date >, < resource type >, < format >, < resource identifier >, < source >, < language >, < relation >, < coverage > and < rights >. The schema is designed to function as a kind of electronic ‘catalogue card’ to digital files, so that it becomes possible, for instance, to search for Benjamin Disraeli as an author < creator > because you want to locate one of his novels, as opposed to writings about Benjamin Disraeli as a British prime minister < subject > because you have an interest in British parliamentary history. The intention of Dublin Core is to develop more sophisticated resource discovery tools than the current web-based search tools which, however fancy their algorithms, do little more than search indiscriminately for words and combinations of words.
A number of other schemas build on Dublin Core, such as the Australian standard for government information (Australian Government Locator Service 2003), and the EdNA and UK National Curriculum standards for electronic learning resources. Other schemas offer the option of embedding Dublin Core, as is the case with the Open eBook standard.
Cataloguing
The Machine Readable Catalog (MARC) format was initially developed in the 1960s by the US Library of Congress (MARC Standards Office 2003a; Mason 2001). Behind MARC is centuries of cataloguing practice, and its field and coding alternatives run to many thousands. Not only does MARC capture core information such as author, publisher or page extent. It also links into elaborate traditions and schemas for the classification of content such as the Dewey Decimal Classification system or the Library of Congress Subject Headings. MARC is based on ISO 2709 ‘Format for Information Exchange’. MARC has recently been converted into an open XML standard.
The original markup framework for MARC was based on nonintuitive alphanumeric tags. Subsequent related initiatives have included a simplified and more user-friendly version of MARC: the Metadata Object Description Schema (MARC Standards Office 2003c) and a standard specifically for the identification, archiving and location of electronic content, the Metadata Encoding and Transmission Standard (MARC Standards Office 2003b).
Various ‘crosswalks’ have also been mapped against other tagging schemas, notably MARC to Dublin Core (MARC Standards Office 2001) and the MARC to the ONIX e-commerce standard (MARC Standards Office 2000). In similar territory, although taking somewhat different approaches to MARC, are Biblink (UK Office for Library and Information Networking 2001) and Encoded Archival Description Language (Encoded Archival Description Working Group 2002).
Educational texts
Cutting across a number of areas—particularly rendering and resource discovery—are tagging schemas designed specifically for educational purposes. EdNA (EdNA Online 2000) and the UK National Curriculum Metadata Standard (National Curriculum Online 2002) are variants of Dublin Core.
Rapidly rising to broader international acceptance, however, is the Instructional Management Systems (IMS) Standard (IMS Global Learning Consortium 2003) and the related Shareable Content Object Reference Model (ADL/SCORM 2003). Not only do these standards specify metadata to assist in resource discovery. They also build and record conversations around interactive learning, manage automated assessment tasks, track learner progress and maintain administrative systems for teachers and learners. The genesis of IMS was in the area of metadata and resource discovery, and not the structure of learning texts. One of the pioneers in the area of structuring and rendering learning content (building textual information architectures specific to learning and rendering these through stylesheet transformations for web browsers) was Educational Modelling Language (OUL/EML 2003). Subsequently, EML was grafted into the IMS suite of schemas and renamed the IMS Learning Design Specification (IMS Global Learning Consortium 2002).
E-commerce
One tagging schema has emerged as the dominant standard for B-2-B e-commerce in the publishing supply chain—the ONIX, or the Online Information Exchange standard, initiated in 1999 by the Association of American Publishers, and subsequently developed in association with the British publishing and bookselling associations (EDItEUR 2001; Mason and Tsembas 2001). The purpose of ONIX is to capture data about a work in sufficient detail to be able automatically to upload new bookdata to online bookstores such as Amazon.com, and to communicate comprehensive information about the nature and availability of any work of textual content. ONIX sits within the broader context of interoperability with ebXML, an initiative of the United Nations Centre for Trade Facilitation and Electronic Business.
Digital rights management
Perhaps the most contentious area in the world of tagging is that of digital rights management (Cope and Freeman 2001). Not only does this involve the identification of copyright owners and legal purchasers of creative content; it can also involve systems of encryption by means of which content is only accessible to legitimate purchasers; and systems by means of which content can be decomposed into fragments and recomposed by readers to suit their specific needs. The < indecs > or Interoperability of Data in E-Commerce Systems framework was first published in 2000, the result of a two-year project by the European Union to develop a framework for the electronic exchange of intellectual property (< indecs > 2000). The conceptual basis of < indecs > has more recently been applied in the development of the Rights Data Dictionary for the Moving Pictures Expert Group’s MPEG-21 framework for distribution of electronic content (Multimedia Description Schemes Group 2002). From these developments and discussions, a comprehensive framework is expected to emerge, capable of providing markup tools for all manner of electronic content (International DOI Foundation 2002; Paskin 2003).
Among the other tagging schemas marking up digital rights, Open Digital Rights Language (ODRL) is an Australian initiative, which has gained wide international acceptance and acknowledgement (ODRL 2002); and Extensible Rights Markup Language (XrML) was created in Xerox’s PARC laboratories in Paulo Alto. Its particular strengths are in the areas of licensing and authentication (XrML 2003).
What tagging schemas do
The tagging schemas we have mentioned here do almost everything conceivable in the world of the written word. They can describe that world comprehensively, and to a significant degree they can support its manufacture. The typesetting and content capture schemas provide a systematic account of structure in written text, and through stylesheet transformations they can literally print text to paper, or render it electronically to screen or manufacture synthesised audio. Digital resource discovery and electronic library cataloguing schemas provide a comprehensive account of the form and content of non-digital as well as digital texts. Educational schemas attempt to operationalise the peculiar textual structures of traditional learning materials and learning conversations, where a learner’s relation to text is configured into an interchange not unlike the ATM conversation we described in Chapter 4, ‘What does the digital do to knowledge making?’. E-commerce and digital rights management schemas move texts around in a world where intellectual property rights regulate their flow and availability.
Tagging schemas and processes may be represented as paradigm (using syntagmatic devices such as taxonomy) or as narrative (an account of the ‘funnel of commitment’ and the alternative activity sequences or navigation paths in the negotiation of that commitment). Ontologies are like theories, except, unlike theories, they do not purport to be hypothetical or amenable to testing; they purport to tell of the world, or at the very least of a part of the world, like it is—in our case that part of the world inhabited by authors, publishers, librarians, bookstore workers and readers.
The next generation of ontology-based markup brings with it the promise of more accurate discovery, machine translation and, eventually, artificial intelligence. A computer really will be able to interpret the difference between Cope, cope and cope. Even in the case of the < author > with the seemingly unambiguous < surname > Kalantzis, there is semantic ambiguity that markup can eliminate or at least reduce, by collocating structurally related data (such as date of birth) to distinguish this Kalantzis from others and by knowing to avoid association with the transliteration of the common noun in Greek, which means ‘tinker’.
In the world of XML, tags such as < author > and < surname > are known as ‘elements’, which may well have specified ‘attributes’; and the ontologies are variously known as, or represented in, ‘schemas’, ‘application profiles’ or the ‘namespaces’ defined by ‘document type definitions’ or DTDs. As our interest in this chapter is essentially semantic, we use the concepts of ‘tag’ and ‘schema’. In any event, as mentioned earlier, ‘ontology’ seems the wrong concept insofar as tag schemas are not realities; they are specific constructions of reality within the frame of reference of highly particularised social languages. Their reality is a social reality. They are no more and no less than a ‘take’ on reality, which reflects and represents a particular set of human interests. These interests are fundamentally to get things done (funnels of commitment) more than they are mere reflections of objectified, inert being. Schemas, in other words, have none of the immutable certainty implied by the word ‘ontology’. Reality does not present itself in an unmediated way. Tagging schemas are mediated means rather than static pictures of reality.
Most of the tagging frameworks relating to authorship and publishing introduced above were either created in XML or have now been expressed in XML. That being the case, you might expect that an era of rapid and flexible transmission of content would quickly dawn. But this has not occurred, or at least not yet, and for two reasons. The first is the fact that, although almost all content created over the past quarter of a century has been digitised, most digital content has been created, and continues to be created, using legacy design and markup frameworks. These frameworks are embedded in software packages that provide tools for working with text which mimic the various trades of the Gutenberg universe: an author may use Word; a desktop publisher or latter-day typesetter may use Quark; and a printer will use a PDF file as if it were a virtual forme or plate. The result is sticky file flow and intrinsic difficulties in version control and digital repository maintenance (Cope 2001). How and where is a small correction made to a book that has already been published? Everything about this relatively simple problem, as it transpires, becomes complex, slow and expensive. However, in a fully comprehensive, integrated XML-founded file flow, things that are slow and expensive today should become easier and cheaper—a small change by an author to the source text could be approved by a publisher so that the very next copy of that book purchased online and printed on demand could include that change. Moreover, even though just about everything available today has been digitised somewhere, in the case of books and other written texts, the digital content remains locked away for fear that it might get out and about without all users paying for it when they should. Not only does this limit access, but what happens, for instance, when all you want is a few pages of a text and you do not want to pay for the whole of the printed version? And what about access for people who are visually impaired? It also puts a dampener on commercial possibilities for multichannel publishing, such as the student or researcher who really has to have a particular text tonight, and will pay for it if they can get it right away in an electronic format— particularly if the cost of immediate access is less than the cost of travelling to the library specially.
The second reason is that a new era of semantic text creation and transmission has not yet arrived. Even though XML is spreading quickly as a universal electronic lingua franca, each of its tagging schema describes its worlds in its own peculiar way. Tags may well be expressed in natural languages—this level of simplicity, openness, transparency is the hallmark of the XML world. But herein lies a trap. There is no particular problem when there is no semantic overlap between schemas. However, as most XML application profiles ground themselves in some ontological basics (such as people, place and time), there is nearly always semantic overlap between schemas. The problem is that, in everyday speech, the same word can mean many things, and XML tags express meaning functions in natural language.
The problem looms larger in the case of specialised social languages. These often develop a high level of technical specificity, and this attaches itself with a particular precision to key words. The more immersed you are in that particular social language—the more critical it is to your livelihood or identity in the world, for instance—the more important these subtle distinctions of meaning are likely to be. Communities of practice identify themselves by the rigorous singularity of purpose and intent within their particular domain of practice, and this is reflected in the relative lack of terminological ambiguity within the social language that characterises that domain. As any social language builds on natural language, there will be massive ambiguities if the looser and more varied world of everyday language is assumed to be homologous with a social language which happens to use some of the same terminology.
The semantic differences between two social languages in substantially overlapping domains are likely to be absolutely critical. Even though they are all talking about text and can with equal facility talk about books, it is the finely differentiated ways of talking about book that make authors, publishers, printers, booksellers and librarians different from each other. Their social language is one of the ways you can tell the difference between one type of person and another. These kinds of difference in social language are often keenly felt and defended. Indeed, they often become the very basis of professional identity.
This problem of semantics is the key dilemma addressed by this chapter, and the focal point of the research endeavour which has produced CGML. Our focus in this research has been the means of creation and communication of textual meaning, of which the book is an archetypical instance. Each of the schemas we have briefly described above channels a peculiar set of ‘funnels of commitment’ in relation to books—variously that of the author, typesetter, printer, publisher, bookseller, librarian and consumer. And although they are all talking about the same stuff—textual meaning in the form of books or journal articles—they talk about it in slightly different ways, and the differences are important. The differences distinguish the one funnel of commitment, employing its own peculiar social language to realise that commitment, from another. It is precisely the differences that give shape and form to the tagging schemas which have been the subject of our investigations.
The schemas we have identified range in size from a few dozen tags to a few thousand, and, the total number of tags across just these schemas would be in the order of tens of thousands. This extent alone would indicate that the full set of tags provides the basis for a near-definitive account of textual meaning. And although it seems as if these schemas were written almost yesterday, they merely rearticulate social languages that have developed through 500 years of working with the characteristic information architectures of mechanically reproduced writing, bibliography and librarianship, the book trade and readership. Given that they are all talking about authorship and publishing, the amount of overlap (the number of tags that represent a common semantic ground across all or most schemas) is unremarkable. What are remarkable are the subtle variations in semantics depending on the particular tagging schema or social language; and these variations can be accounted for in terms of the subtly divergent yet nevertheless all-important funnels of commitment.
So, after half a century of computing and a quarter of a century of the mass digitisation of text, nothing is really changing in the core business of representing the world using the electrical on/off switches of digitisation. The technology is all there, and has been for a while. The half-millennium-long shift is in the underlying logic behind the design of textual meaning. This shift throws up problems which are not at root technical; rather they are semantic. Interoperability of tagging schemas is not a technical problem, or at least it is a problem for which there are relatively straightforward technical solutions. The problem, and its solution, is semantic.
The commercial implications of the emergence and stabilisation of electronic standards are also enormous. These include:
![]() Efficiencies and cost reduction—Electronic standards facilitate cross-enterprise automation of file flow, including the process and commercial aspects of that flow—from the creator to the consumer. Efficiencies will also be created by B-2-B and B-2-C relationships based on standards, including error reduction, single entry of data and moves towards progressive automation of the production process.
Efficiencies and cost reduction—Electronic standards facilitate cross-enterprise automation of file flow, including the process and commercial aspects of that flow—from the creator to the consumer. Efficiencies will also be created by B-2-B and B-2-C relationships based on standards, including error reduction, single entry of data and moves towards progressive automation of the production process.
![]() Supply chain integration—Electronic standards also mean that closer relationships can and should be built between the links of the publishing supply chain. For instance, a publisher ordering a print run of books can enter data into the printer’s JDF via a web interface. It is also possible to transfer ONIX data automatically into this format, thus creating publisher-printer-bookseller supply chain integration. The key here is the creation trusted ‘most favoured supplier’ relationships and the development of a sense that the destinies of closely related enterprises are intertwined, rather than antithetical to each other’s interests.
Supply chain integration—Electronic standards also mean that closer relationships can and should be built between the links of the publishing supply chain. For instance, a publisher ordering a print run of books can enter data into the printer’s JDF via a web interface. It is also possible to transfer ONIX data automatically into this format, thus creating publisher-printer-bookseller supply chain integration. The key here is the creation trusted ‘most favoured supplier’ relationships and the development of a sense that the destinies of closely related enterprises are intertwined, rather than antithetical to each other’s interests.
![]() New business opportunities—These will occur as new, hybrid enterprises emerge, which create links across the supply chain, offering services such as the multipurposing of content (for instance, to the web, to handheld reading devices and to digital talking book) and data warehousing. This will be supported particularly by the emergence of supply chain wide product identification protocols such as the Digital Object Identifier.
New business opportunities—These will occur as new, hybrid enterprises emerge, which create links across the supply chain, offering services such as the multipurposing of content (for instance, to the web, to handheld reading devices and to digital talking book) and data warehousing. This will be supported particularly by the emergence of supply chain wide product identification protocols such as the Digital Object Identifier.
The key issue is the flow of business information and content between the various players in the text production and supply chain. Addressing this issue can produce efficiencies and competitive advantage for individual enterprises, and the whole industry. Many players are now arguing, in fact, that addressing this issue is not a choice—it is a necessity given the fact that standards are rapidly emerging, stabilising and gaining wide acceptance.
CGML is an attempt to address these semantic and commercial challenges. The aim of the CGML research and development endeavour has been to develop software that enables digital text production (electronic renderings and print renderings) using a markup language that offers stable and reliable interoperability across different standards. These standards include typesetting and text capture, electronic rendering, print rendering, B-2-B e-commerce, e-learning, digital rights management, internet resource discovery and library cataloguing.
CGML addresses one of the fundamental issues of the ‘semantic web’— the problem of interoperability between different but overlapping and related electronic standards. Commercially and functionally, the intended result is a software environment in which texts render simultaneously to electronic and print formats (for instance, a bound book, computer screen, handheld reading device or synthesised voice) from a common source file. Metadata generated by this software is simultaneously able to create a library cataloguing record, an e-commerce record (automated entry to Amazon, international bookdata databases etc.) and make a published text an e-learning object and conform to the current and emerging digital rights management protocols.
At the time of writing, CGML consists of approximately 1,000 tags, interpolated into an XML schema. These tags are defined in the Common Ground Dictionary of Authorship and Publishing, which currently runs to some 25,000 words. CGML and the Dictionary are published dynamically (without ‘editions’ or ‘versions’), with tags being constantly added and definitions refined as the Common Ground research endeavour proceeds. The Common Ground research and development team has created its own ontology-building software, CGMeaning, which houses CGML as well as providing a foundation for the export of data into a range of XML text and publishing schemas.
CGML takes the textual artefact of the written text as its point of departure. However, insofar as the digital medium also serves as a construction tool, repository and distributional means for audio, moving image, software, databases and the like, CGML also incorporates reference to these representational forms. CGML is designed to be fully extensible into all domains of creative media and cultural artefact.
From a technology point of view, CGML sets out to tackle one of the fundamental challenges of the ‘semantic web’—the problem of interoperability between overlapping and related electronic standards. To this end, Common Ground researchers developed the ‘interlanguage’ mechanism (Common Ground Publishing 2003). This mechanism has the potential to extend the useability of content across multiple standards, XML schemas, ontologies or database structures. The approach taken by CGML may begin to address the enormous problem of interoperability in general, not just in publishing but in other areas of semantic publishing. Stated simply, electronic files do not flow well along production and distribution supply chains, because file formats vary, as does the metadata which defines file content format and uses. In the case of published material, there are enormous inefficiencies in file flow from author to publisher to printer to electronic rendering formats as well as the e-commerce mechanisms that deliver content from enterprise to enterprise and finally to consumers.
Even though each electronic standard or schema has its own functional purposes, there is a remarkable amount of overlap between these standards. The overlap, however, often involves the use of tags in mutually incompatible ways. Our extensive mapping of 17 standards in various text- and publishing-related fields shows that, on average, each standard shares 70 per cent of its semantic range with neighbouring standards. Despite this, it is simply not possible to transfer data generated in one standard to a database or XML schema using another. Each standard has been designed as its own independent, stand-alone schema. This, in fact, points to one of the key deficiencies of XML as a metamarkup framework: it does not in itself suggest a way for schemas to relate to each other. In fact, the very openness of XML invites a proliferation of schemas, and consequently the problem of interoperability compounds itself.
This produces practical and commercial problems. In the book publishing and manufacturing supply chain, different links in the chain use different standards: typesetters, publishers, booksellers, printers, manufacturers of electronic rendering devices and librarians. This disrupts the digital file flow, hindering supply chain integration and the possibilities of automating key aspects of supply chain, manufacturing and distribution processes. Precisely the same practical problems of interoperability are now arising in other areas of the electronic commerce environment.
Although our main interest is the world of authorship and publishing, the longer term possibilities technologies of interoperability such as CGML are in the areas in which the semantic web has so much—as yet unfulfilled—promise. This includes: indexing, cataloguing and metadata systems; product identification systems; systems for the production, manufacture and distribution of copyright digital content; knowledge and content management systems; systems for multi-channelling content and providing for disability access; machine translation from one natural language to another; and artificial intelligence.
More practically, the challenge of interoperability is this: in a scenario where there are many more than two parties, where the information is not covered by a single standard, where the resources and skills of the parties cannot facilitate costly and time-consuming integration, an approach is needed that caters for the complexity of the messages, while providing tools that simplify the provision and extraction of data and metadata. This is the crux of semantic interoperability. Such an approach involves providing a systematic mapping of associated XML standards to a common XML ‘mesh’, which tracks semantic overlays and gaps, schema versioning, namespace resolution, language and encoding variances, and which provides a comprehensive set of rules covering the data transfer—including security, transactional and messaging issues.
The idea of a ‘meta-schema’—a schema to connect related schemas— was initially considered to be sufficient. Research has demonstrated, however, that this is not enough, being subject to many of the same problems as the individual schemas being mapped—versioning, terminological differences and so on.
The core operational principles of CGML are as follows: meaning form or rendering is rigorously separated from, yet reliably follows, markup tags expressing meaning function; interoperability of tagging schemas can be achieved by mapping through an interlanguage governed by a set of semantic and structural rules; a tag schema expresses paradigmatic relations; a tag thesaurus expresses relations between tagging schemas; a tag dictionary expresses semantics; interoperability mechanisms are automated or semi-automated; and tag narratives anticipate a range of activity sequences driven by funnels of commitment and realised through alternative navigation paths.
As a terminological aside, CGML deliberately recruits some quite ordinary concepts from the world of textual meaning, such as the ideas of a dictionary, thesaurus and narrative. If we are going to have what we have termed ‘text-made text’ in which markup is integral to textual reproduction, we might as well use these historically familiar devices—albeit with some refinement and levels of precision required by the logistics of digital meaning.
Interlanguage
Semantic publishing schemas promise to overcome two of the most serious limitations of the World Wide Web: searching involves simply identifying semantically undifferentiated strings of characters, and rendering alternatives is mostly limited by data entry methods—printed web pages do not live up to the historical standards of design and readability of printed text, and alternative non-visual renderings, such as digital talking books, are at best poor.
Specific schemas are designed to provide more accurate search results than is the case with computer or web-based search engines. Examples include the Dublin Core Metadata Framework and MARC electronic library cataloguing system. However, metadata harvested in one scheme cannot be readily or effectively used in another.
Specific schemas are also designed for a particular rendering option. For instance, among schemas describing the structure of textual content, HTML is designed for use in web browsers, DocBook for the production of printed books, Open eBook for rendering to handheld reading devices and Digital Talking Book for voice synthesis. Very limited interoperability is available between these different schemas for the structure of textual data, and only then if it has been designed into the schema and its associated presentational stylesheets. Furthermore, it is not practically possible to harvest accurate metadata from data, as data structuring schemas and schemas for metadata are mutually exclusive.
The field of semantic publishing attempts to improve on the inherent deficiencies in current digital technologies in the areas of resource discovery (metadata-based search functions) and rendering (defining structure and semantics in order to be able to support, via stylesheet transformations, alternative rendering options).
In support of semantic publishing, CGML attempts to inter-relate the principal extant in the tag schemas for the world of authorship and of publishing. However, unlike other tag schemas in this domain, it does not purport to be ontologically grounded. It does not attempt to name or rename the world. Rather, CGML builds a common ground between contiguous and overlapping tag schemas which already purport to name the world of authorship and publishing. It is not a language. It is an interlanguage (Figure 13.2).

The challenge of interoperability of tagging schemas (standards, application profiles or namespaces) has typically been addressed through schema-to-schema ‘crosswalks’. A crosswalk is a listing of tag-to-tag translations not dissimilar from a language-to-language dictionary. For instance, as mentioned earlier, crosswalks have been created between MARC and ONIX (MARC Standards Office 2000) and between MARC and Dublin Core (MARC Standards Office 2001). As Paskin notes, when there are N schemas (N/2)(N–1), mappings are required (Paskin 2003). For instance, as of writing, CGML maps to 17 schemas. For full interoperability, 136 ‘crosswalk’ mappings would be required. Or, to take a natural language analogy, if there are 60 languages in Europe, translation between all 60 languages can be achieved with 1,770 language-to-language dictionaries—Italian–Gaelic, Gaelic–Vlach, Vlach–Italian and so on.
In fact, things are more complicated even than this. Each dictionary is, in fact, two dictionaries. Italian–Gaelic and Gaelic–Italian are not mirror inversions of each other because each language frames the world in its own semantically peculiar way. Similarly, the MARC to ONIX exercise (MARC Standards Office 2000) is quite a different one from the ONIX to MARC exercise (EDItEUR 2003). MARC to ONIX translates a library cataloguer’s understanding of the nature and content of the book into a form intelligible to a publisher or a bookseller; and ONIX to MARC translates a publisher’s or bookseller’s understanding of the book into a form intelligible to a library cataloguer. In each case, the frame of reference or the starting point is defined in terms of a subtly distinctive social language. Each crosswalk is a separate intellectual and discursive exercise. So, we need to modify Paskin’s crosswalk formula as follows: the number of mappings to achieve interoperability between N tagging schemas is 2[(N/2)(N–1)]. In a terrain encompassed by the current version of CGML, 272 crosswalks would be required; Europe needs 3,540 dictionaries for comprehensive cross-translation of all its languages. (And, while we are on this train of thought and although it is tangential to our point, cross-translation of all the world’s estimated 6,000 languages would require a practically impossible 17,997,000 dictionaries.)
Creating a single crosswalk is a large and complex task. As a consequence, the sheer number of significant overlapping tagging schemas in a domain such as authorship and publishing presents a barrier to achieving interoperability—and this without taking into account the fact that the schemas are all in a state of continuous development. Every related crosswalk needs to be reworked with each new version of a single tagging schema. Moreover, new tagging schemas are regularly emerging and every new schema increases the scale of the problem exponentially. Five cross-translations require ten crosswalks; ten cross-translations require 90 crosswalks.
Paskin suggests that this level of complexity can be eased by mapping ‘through a central point or dictionary’ (Paskin 2003). This is precisely the objective of CGML, which is an intermediating language, or an interlanguage through which a full set of translations can be achieved. Tag by tag, it represents a common ground between tagging schemas. Tag < x > in the tagging schema A translates into tag < q > in CGML, and this in turn may be represented by < y > in tagging schema B and < z > in tagging schema C. The ‘common ground’ tag < q > tells us that < x >, < y > and < z > are synonyms. A theoretical 272 crosswalks are replaced by 17 thesauri of tag synonyms (Figure 13.3). If, by analogy, all European languages were to be translated through Esperanto, a language deliberately fabricated as a common ground language, 60 dictionaries would be needed to perform all possible translation functions instead of a theoretical 3,540. Even simpler, in theory just one dictionary would suffice, translated 60 times with 60 language-to-Esperanto thesauri. This is precisely what CGML does. It attempts to solve the semantic aspect of the interoperability problem by creating one dictionary and 17 thesauri of tag synonyms. (And, incidentally, returning to natural language for a moment, this technique can be used as a semantic basis for machine translation, bringing the inter-translatability of all human languages at least into the realm of possibility.)
Figure 13.4 shows the interlanguage approach—full interoperability between 17 schemas requires a thesaurus with just 17 sets of tag synonyms.
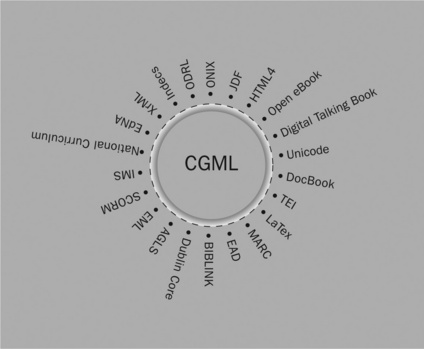
CGML has a number of distinguishing features, which means that it is constitutively a very different kind of tagging schema from all the others against which it maps. It is this constitutive character that defines it as an interlanguage, as distinct from a language.
An interlanguage has no life of its own, no independent existence, no relation to reality other than a mediated relationship through other languages. We will outline the operational principles for the construction of such an interlanguage through the subsequent subsections of this chapter.
Before this, however, we want to mention some of the unique characteristics of an interlanguage such as CGML. As an interlanguage, CGML is designed to be open to the possibility of mapping new schemas that may emerge within or substantially overlapping its general domain. It is also designed to be able to absorb tagging that finely distinguishes conceptual subsets of certain of its core interests. In the case of authorship and publishing this might include, for instance, geospatial tags to define precise location, or tags representing controlled subject vocabularies in specific field-domains. By comparison with the crosswalk alternative, this mapping is achieved with relative ease.
Full subsumption and overlap are both cases of vertical integration of tagging schemas into CGML. However, CGML is also designed to be amenable to horizontal integration of schemas defining contiguous or complementary domains, such as the integration of other digital media or museum objects with the world of books. After all, books are routinely made into movies, bookstores sell DVDs and printed books and libraries store individual copies of rare and unique books as artefacts.
As an interlanguage, CGML is infinitely extensible, absorbing subsidiary, overlapping and contiguous schemas to the extent that seems necessary and useful. A the time of writing, CGML consists of nearly 1,000 tags—and these happen to be the tags for which there is the greatest degree of semantic common ground identifiable as synonyms across the interlanguage. The tags that represent the greatest degree of overlap also happen to be the most fundamental to the representational and communicative activities of authorship and publishing. However, there is no reason why CGML should not extend to 10,000 or a 100,000 tags as it describes progressively more arcane bywaters in each tagging domain (vertical integration) or as it spreads its range of reference into contiguous domains of meaning (horizontal integration).
To reiterate, CGML is an interlanguage which maps against any other related schema (or, as they are variously termed, standards, namespaces or application profiles) in the domain of authorship and publishing. It works through tag-to-tag translation links between schemas—be they competing within a substantially overlapping domain or serving varied functions in divergent but still overlapping domains. The CGML term is an intermediary or interlanguage term. CGML is not a schema in and for itself. Rather, it is a way of talking to schemas.
The conventional approach to evaluating the efficacy of alternative tag schemas within a particular semantic domain is to undertake a process of comparison and contrast, the purpose of which is to select the one that would, it seems for the moment at least, be most appropriate to one’s expressive needs, or the one that appears to be the most internally coherent and robust, or the one that happens to be most widely used among the players within a particular community of practice.
As an interlanguage, however, CGML is entirely agnostic about the ontological validity of the schemas to which it maps. If they move a community of practice, or have the potential to move a community of practice, they are worth the trouble of mapping. New standards may emerge, and if they appear to be sufficiently cogent and practically useful, they are also worth the trouble.
CGML itself does not set out to be a competing or alternative standard. Rather CGML takes the approach that the prevailing uncertainty about which standards will predominate and the likelihood of the emergence of new standards is to a significant degree a diversion. In the interlanguage approach, standards are everything—CGML needs to talk with the main existing and emerging publishing standards from the pragmatic point of view of interoperability. Yet, in another sense, standards are nothing—it is immaterial if some standards fall into desuetude or if new standards emerge. Dogmatic debate about the value or lack of value of a particular schema or standard is of little value. Shoehorning social practices into ill-fitting received standards is also a fraught exercise. CGML cares about standards but eschews standardisation, or making things the same for the sake of sameness.
Our decision to take the interlanguage approach, paradoxically in the light of our scepticism about the ontological pretensions of tag schemas, is based on the stability inherent to the semantic ground, or a kind of ontological pragmatism. Behind the varied ‘takes’ on reality reflected by tag schemas, there is still a relatively stable and thus predictable material and social reality. The ‘resistances’ of which Eco speaks are at times insistent. Although we conceptualise the world paradigmatically through tag schemas and operationalise these schemas through activity narratives, these paradigms and narratives do have a reference point, and this reference point might reasonably be construed to be a matter of ontology. Ontology does not simply present itself; it is mediated by paradigms and narratives. However, ontology practically grounds paradigm and narrative. In fact, through language, paradigm and narrative make themselves integral to the ontological reality of society or culture.
This grounding provides stability and thus a certain predictability of paradigm and narrative within a particular semantic domain. If authorship and publishing is our domain of interest, for instance, this represents a set of social practices—practices of representation and communication—that have deep and only gradually changing roots. There are authors who write; these authors have names; their writings have titles; and these writings have characteristic generic structures and fields of representation or subjects. Any new tagging schema that turns up—no matter how fancy it is or how innovative its intentions and methodology (e-learning, digital rights management, variable rendering and the like)—is still going to have to name these insistent realities.
The basis of CGML, in other words, is in the semantic ground of publishing, and there is an essential stability in the everyday lifeworld of authorship and publishing. The technologies may be changing, but there are still creators (writers, editors, illustrators) creating works (books in print and electronic formats, chapters, articles and other written, visual and audio texts) that are subject to copyright agreements, which are then used by consumers (readers, learners). Schemas do no more than represent that lifeworld from a particular perspective—be that the perspective of the library, digital resource discovery, rights, commerce, education or rendering/production. Schemas may come and go, but the lifeworld they purport to represent and facilitate remains relatively stable. At most, it changes incrementally, despite even the large changes underway today in the new digital media.
The interlanguage approach of CGML also provides a tool for literature, science and curricula to be built in small languages and endangered languages, including, with the aid of Unicode, publication in any script. CGML can run in any language and any script, and this is achieved simply by translating the tags and tag definitions. This may seem a relatively small move in a practical sense. Conceptually, however, it is a huge move. In fact, it turns a linguistically expressed term into a mere ‘token’ of a core concept that exists above and beyond any particular language. And an indirect effect of this move is to add multilingual functionality to markup schemas which currently exist only in English. In addition, by virtue of its structural and semantic approach to markup, CGML could serve as an aid to effective and accurate human and machine translation. In other words, by these various means, CGML could literally find itself in the space of an interlanguage between various human languages.
In a globalised and multilingual world, Ron Scollon argues, social languages or discourses are more similar across languages than within languages (Scollon 1999). The way academics write for their particular discipline, for instance, whether it is in English or Japanese, is similar in terms of the structure of their texts and the ways those texts describe the world. A structural and semantic framework for structuring text such as CGML, which includes elaborate structural and semantic markup linked to controlled keyword vocabularies, will work across languages once the tags and the specialist vocabularies are translated, and this is because the most important thing about the discourse does not sit inside a particular language. Text structured and rendered in this way may become the platform for multilingual, multi-script publishing in communities more and more defined by their social language (what they want to do in the world, as expressed in peculiar ways of communicating about the world) than by the accident of mother tongue.
The CGML Dictionary does not purport to be about external referents as ‘meaning’; rather, it is built via the interlanguage technique from other languages which purport to have external referents. Moreover, insofar as the semantic ground of CGML is meaning itself (and its instantiation in the practices of authorship and publishing), it is a kind of metasemantics, a language of meaning. It happens to be centred on the realm of semantics in general—the meaning of meaning—and within that realm the social practices and technologies of representation and communication stabilised in the historical practices of representation.
Furthermore, CGML is not an ordinary dictionary insofar as it develops a specialised ‘take’ on the world it purports to describe, the world of meaning. Its meanings are not the commonsense meanings of the lifeworld of everyday experience, but derivative of specialised social languages which speak in the refined and particularistic way characteristic of the professionals and aficionados of that domain. To apply a pair of concepts of Husserl’s, commonsense language is shifting and ambiguous language of the lifeworld; social languages develop progressively refined (sedimented) and self-consciously reflective (bracketed) discourse more characteristic of science (Cope and Kalantzis 2000; Husserl 1970). CGML, in other words, derives from schemas developed in and for professions which have developed high levels of conceptual clarity about what authorship is and what publishing involves.
The CGML dictionary links a notation (the tag-concept), which may be used in practice as a label for a field in a database or as an XML tag, to a semantically explicit definition, as well as an annotation which explains and exemplifies the tag-concept in terms of subordinate tag-concepts in the taxonomy (the various logics of relation-inclusion discussed earlier), and provides advice where necessary on appropriate and well-formed data entry. The building blocks of the CGML dictionary are the other tag-concepts of the CGML schema, and these are connected by hyperlinks. The definition builds on parent tag-concepts; the annotation suggests the possible instantiations of a tag-concept by means of illustrative child tag-concepts. The dictionary is located in maintained in a purpose-build software application, CGMeaning. Figure 13.5 shows how it specifies the concepts of < creation > and < creator > .

Figure 13.5 Fragment of the CGML Dictionary of Authorship and Publishing specifying the concepts of < creation > and < creator >
The rules of CGML dictionary formation
The CGML Dictionary has been constructed using five semantic rules: minimised ambiguity, functional clarity, lowest common denominator semantics, the distinction of silent from active tag-concepts and comprehensive internal cross-reference.
Rule 1 Minimise ambiguity
Digital expression languages such those captured by XML (of which CGML is an instance) use natural language tags in the interest of transparency. The appearance of natural language, however, simulating as it does everyday semantics, is deceptive. The further removed from everyday language a digital expression language, the more functionally effective it is likely to be. For instance, a < Work > may involve some very different kinds of ‘editor’, obscured by the ambiguity of that word in everyday parlance. CGML defines one kind of < Editor > as a primary < CreatorRole > in relation to a < Work > —a person who pulls together a number of texts by various < Author > s into a coherent work, and maybe writes an introduction. From a presentational point of view, the < Editor > s name will appear (via the stylesheet transformation process) on the cover and title page of a < Book >. This < Editor > is distinct from other types of ‘editor’, such as a < CommissioningEditor > —typically a person who works for a < Publisher > and who instigates the process which leads to the < Publication > of a < Product >. < Editor > is also distinct from a < CopyEditor > who identifies textual errors. These latter two kinds of people, frequently simply called ‘editor’ in everyday parlance, play a < ContributorRole > in the < Creation > process, and need to be clearly and unambiguously distinguished from an < Editor > who clearly and consistently has a < CreatorRole > in the process. In this way, the Dictionary draws explicit boundaries of distinction–inclusion between other tag-concepts, usually positioned as alternatives to each other at the same level in the taxonomy. Figure 13.6 shows how the Dictionary specifies the concept of < editor > .

CGML attempts to achieve a balance between domain-specific concepts, which are relatively free of jargon, and the precision characteristic of and necessary to technical and scientific discourses. Except when referring specifically to computers and computer-generated files, publishing terminology is preferred over computer terminology. For instance, < Edition > and < Draft > are preferred over ‘version’, not only for their familiarity to authors and publishers, but because they reflect an important distinction which is sometimes unclear in version enumeration.
In this process of removing ambiguity, at the furthest reaches of its taxonomic structure CGML may also absorb international standards and controlled vocabularies defining key features of the semantic ground such as ISO 3166 Territory Codes, ISO 4217 Currency Codes, ISO 639 Language Codes, ISO 8601 Standard Formats for the Description of Time and UCUM Unit of Measure Codes (International DOI Foundation 2002).
Rule 2 Aim for functional clarity
The CGML Dictionary is not a description of things in themselves. Its purpose is functional—in a primary sense to provide an account of meaning functions, and in a secondary sense to provide a reliable basis for automated rendering through stylesheet transformation languages. Every definition and annotation explains in the first instance what an entity does, rather than what it is. Each tag-concept, moreover, can only do one thing. If a synonymous term in natural language does more than one thing, as was the case of ‘editor’ in the previous subsection, a specialised distinction needs to be made explicitly.
Rule 3 Use lowest common denominator semantics
As discussed earlier, CGML’s interlanguage approach means that it takes the ‘common ground’ position between broadly synonymous concepts in the tagging schemas against which it maps. Every CGML term or tag translates into an equivalent term in the various other schemas, if and where there is an equivalent. However, these concepts are not always the same. In the nature of social languages characterised by their own particularised ‘take’ on the world, tag-to-tag equivalents are often not true synonyms. This places a particular semantic burden on the intermediate, interlanguage term and its dictionary definition within CGML. In the case of tag synonyms with roughly equivalent but not identical semantics, CGML either takes the narrower definition in cases when one tag represents a subset of another; or in the case of overlap, creates a new definition restricted to the semantic intersection between the functional referents of the two equivalent tags. This guarantees that data will always be created from within CGML which can be validly exported as content into the database field or XML-tagged content spaces markup by equivalent tag synonyms within the mapped schemas.
The key to CGML’s functioning as an interlanguage, in other words, is its dictionary definition and data entry rules. If the rule of lowest common denominator semantics is rigorously applied, all data entered within the framework of this definition and data entry rules will produce valid data for each of the standards in which a synonymous term exists. Each interlanguage term represents a semantic common ground— defined in terms that are sufficiently narrow and precise to produce valid data for the tag synonyms in all other standards to which a particular term can be validly mapped at that particular semantic point.
Rule 4 Distinguish silent and active tag-concepts
Although certain tag concepts in CGML map against others successfully using the rule of lowest common denominator semantics, they cannot in practice be implemented at this level because they do not have a sufficient level of semantic delicacy to allow interoperability with schemas that require greater semantic delicacy than is possible at that level. Returning to the example provided in Figure 13.5, data cannot be entered at the CGML < Person > level even though that would be sufficient for certain schemas against which it is possible to map synonymous < Person > tag-concepts. Data entry must be broken up into the various name elements at the finest level of delicacy required by all of the mapped tag-schemas (active tag concepts); it can then automatically be recomposed to create valid data to populate the silent tag-concepts. Some of these silent concepts are purely theoretical. There will be very little practical need to ‘climb out’ to many of the highly abstracted first (root element), second and third level concepts. Indeed, some of them are well nigh useless in a practical sense. Their role is purely to provide an overall system and structure to the schema.
Rule 5 Develop a comprehensive internal cross-reference system
The key to building a resilient and functionally efficient tagging schema is to develop an interlocking system of cross-reference. This is rendered in the CGML Dictionary as hyperlinks. Every hyperlinked tag-concept in the dictionary definitions and annotations takes the user to a precise definition and annotation of that tag-concept. Cumulatively, the dictionary definitions and annotations build a systematic account of relations of relation-inclusion and distinction-exclusion, providing descriptive content to the abstract visual representation of paradigm in the taxonomy. The result is that the schema becomes less like a selection of concepts that seem useful to a domain, and more like a theory of that domain.
This is how CGML works as a functional schema of represented meaning. It attempts to create a sound basis for interoperability between the schemas it interconnects, incorporating their varied functions. CGML is an interlanguage. Its concepts constitute a paradigm for represented meaning, drawing on an historically familiar semantics, but adapting this to the possibilities of the internet. Its key devices are thesaurus (mapping against functional schemas) and dictionary (specifying a common ground semantics). These are the semantic components for narrative structures of text creation, or the retrospective stories that can be told of the way in which authors, publishers, referees, reviewers, editors and the like construct and validate text.
Paradigm
These, then, are the core concepts and principles of CGML: tags fit into schemas and these schemas function as paradigms. Tags mark up the narrative flow of activity sequences around the construction of meanings, and the architectures of meaning characteristic of specific social languages. Tagged narratives represent meaning functions and, in the rendering process, form follows function.
CGML’s field is the ongoing and now—despite the disruptions of the new, digital media— relatively stable historical tradition text work. It provides an account of the internal information architecture of the textualities. It is a theory of text structure and the social world of creators, their creations, the relation of their creations to other creations in the world, and the referents in the world to which their creations refer.
CGML has two primary forms of expression, a paradigmatic expression in the form of the taxonomy of reprsented meaning (supported by a dictionary and a thesaurus) and an open framework for the construction of creative and publishing activity narratives, which link the CGML tag-concepts into activity sequences focused on products (the lifecycle of a work, for instance) or roles (the activity structures of authoring, publishing or browsing, for instance) (Common Ground Publishing 2003).
In terms of current computer science terminology (and even though we might question the use of the term) CGML is an ontology (Denny 2002). In a philosophical context this term has been described as follows:
In philosophy, an ontology is a theory about the nature of existence, of what types of things exist; ontology as a discipline studies such theories. Artificial-intelligence and web researchers have co-opted the term for their own jargon, and for them an ontology is a document or file that formally defines the relations among terms. The most typical kind of ontology for the Web has a taxonomy and a set of inference rules (Berners-Lee, Hendler and Lassila 2001).
In this specialised sense, computer science sense, CGML is an ontology— even though we would question the application of the word to computer science in the light of its philosophical connotations.
Represented as a taxonomy, CGML relates its 1,000-odd tags into eight orders of concept, or eight levels linked by branch or parent–child relationship—whichever metaphor one might use to choose to describe taxonomy. As is required by XML expression languages, there is a single first order concept or ‘root element’ (Harold and Means 2002). This root element is < Meaning >. < Meaning > has two children: < Function > and < Form >. As CGML has little interest in < Form >, no children are noted, although children could be added if and when there appeared to be a need to develop a new account of the realm of presentation and stylesheet transformation. This realm is taken as given within the realm of < Form >. In CGML, this is a space where existing stylesheet transformations can be applied as designed for the various structural and semantic tagging schemas with which CGML interoperates. We nevertheless include < Form > as one of our two second order concepts because it is of fundamental importance. From a representational or communicative point of view, < Function > remains unexpressed without a material realisation as < Form >. < Function > has no practical existence without < Form > .
At a taxonomic third level, < Function > splits into three: a < SemanticGround >, a process of < Creation > and the means of < Distribution >. The < SemanticGround > consists at a fourth level of the activities of a < Party > (a < Person > or < Organisation > at the fifth level), in a specifiable < Location >, at or during a point of < DateAndTime > and a < Subject > indicating the material, social or metaphysical referent of the creative work, to which a reader’s or user’s attention may be directed. The process of < Creation > consists at a fourth level of primary < Creator > s, ancillary < Contributor > s, whose creative efforts have an inherent < Design > (which at a fifth level becomes a < Work > and a sixth level becomes a < Product > such as, at a seventh level, a < Book > or a < Map > for instance). The third level process of < Creation > may also involve ascribing a fourth level < Status > (such as < Proposal >, < Draft > or < Edition > at fifth level), providing a < Description >, noting the form of linguistic presentation in a natural < Language >, indicating < Relations > to encompassing or subsidiary < Works > or < Products >, naming a < Publisher >, defining < Rights >, ascribing a unique < Identifier > such as a product number or Digital Object Identifier, and describing < Format >. Still at a fourth level, the products of the < Creation > process have an inherent < Structure > or information architecture (covering everything from < MacroStructure > such as < Chapter > and < Index > and < LocalTextStructures > down to the level of < Paragraph > or < Emphasis > for words or phrases). These are supplemented by < Externals >, which refer to the < Work > in question, such as a < Review > or < RefereeReport >. The final third level concept < Distribution > provides a framework for the tagging of < Audience > (who a < Work > is meant for), < Availability > (where and how it can be found), < Consumer > (who reads or uses it), < Item > (an individual manifestation of a < Product >), < Transaction > (the legal basis of a particular < Consumer > use), < Delivery > (how the < Item > reaches the < Consumer >) and < Provenance > (where the < Item > has been during its life). This is the beginning of a paradigm which currently runs to 1,000 < Function > s within the field of < Meaning >, and whose main focus at this stage is the creative process of authorship and the publication of books. Figure 13.7 shows the CGML Taxonomy of Authorship and Publishing, first to fourth level concepts. The remaining approximately 1,000 tags add detail at the fifth level and beyond.

Within CGML, there are two types of tags: open tags and closed tags. Open tags mark up any content that they happen to enclose, for instance < MainTitle > Any Conceivable Title </Title >. In the XML expression format, these are called ‘elements’. Closed tags specify a strictly defined range of content alternatives, and these take the form of a predetermined list of secondary tags. For example, in CGML as it currently stands, < MeaningMode > can only be defined among the alternatives < LinguisticMode >, < VisualMode >, < AudioMode >, < GesturalMode >, < SpatialMode > and < Multimodal >. In the XML expression format, these are called ‘attributes’.
Paradigm is constructed in CGML by means of a number of taxonomic construction rules. Although CGML tags are written in natural language, this belies a level of precision not found in natural language. Natural language involves considerable semantic ambiguity, whereas a tagging schema needs to attempt to reduce this as much as practicable. It does this by rigorously applying two semantic logics that exist somewhat less rigorously in natural language: the logic of distinction-exclusion and the logic of relation-inclusion. The logic of distinction-exclusion exists with parallel branches (sibling relations) in a taxonomy. A < Person > is not an < Organisation > because an < Organisation > is defined as a legally or conventionally constituted group of < Persons >. On the other hand, the logic of relation-inclusion applies to the sub-branches that branch off superordinate branches in a taxonomy (parent–child relations). A < Party > to a creative or contractual relationship can be either a < Person > or an < Organisation > .
‘Meaning’, says Gee, ‘is always (in part) a matter of intended exclusions and inclusions (contrasts and lack of contrasts) within an assumed semantic field.’ In natural language, we use rough and ready ways of working out whether another person means the same thing as we do by a particular word or phrase. One way is what Gee calls ‘the guessing principle’—our judgement or ‘call’ on what a particular concept means. If we are in the same social, cultural or professional group or community of practice as the communicator of our particular concept, our guess is more likely to be congruent with the communicator’s understanding. Another way is ‘the context principle’, or to add precision to the meaning of a work or phrase by deciphering it in the context of the text and social situation in which it appears (Gee 1996).
Domain-specific paradigms in the form of tagging schemas are designed to reduce the guesswork and contextual inference required in natural language. The solution we have proposed here is to build a social language that clarifies the exclusions and inclusions. This is achieved in CGML by three overlapping visual and textual techniques: taxonomy, thesaurus and dictionary.
Concentrating for the moment on the general rules of taxonomy or paradigm formation, we need to make distinctions between taxonomic processes of superordination and composition (Martin 1992). Superordination relations perform the function of sub-classification. They express an ‘is a’ relationship between one level in the taxonomic hierarchy and another. < Book > is a < Product >, as is an < AudioRecording >. Composition relations, by contrast, connect parts into wholes. They express a ‘has a’ relation between levels in the taxonomic hierarchy. A < GlossaryItem > and a < GlossaryItemDefinition > are both parts of a < Glossary >. Indeed, a < Glossary > is not functional without both of these parts.
To the superordination and compositional principles identified by Martin, we add the capacity of taxonomies to make a distinction of immanence. This expresses an ‘underlies’ relationship between contiguous levels in the taxonomic hierarchy. A < Design > underlies a < Work > and a < Work > underlies a < Product >. In CGML, < Design > has just one child, < Work >. However, < Design > and < Work > cannot be conflated even though there are no multiple children with whom composition (part/whole) or sub-classification functions can be performed. A < Design > may encompass the full scope and essential character of a < Work >. This may be prefigured at the planning or < Proposal > stage. However, a < Design > may never become a < Work >. If it does, however, it does not disappear; rather it is applied and adapted and remains immanent within the < Work >. Similarly, a < Work > such as the lyrics for a song, remains immanent within its various instantiations as a < Product >, such as a < Book > or an < AudioRecording >, or as a < Performance > at an < Event >. This logic of immanence in a creative work builds on, modifies and extends the entity–definition work of the International Federation of Library Associations (IFLA Study Group on the Functional Requirements for Bibliographic Records 1998).
Finally, taxonomies need to be cohesive if they are to provide an effective paradigmatic role for a field of practice. Such cohesion is created to a large degree by the proximity of concepts in contiguous levels in the hierarchy. Between one level and another, relations need to be tested to see whether a tag-concept on one level is experientially close enough to be presumed by a tag-concept on another (Martin 1992). < PrintedBook > and < Design > are not experientially close concepts, and thus would not form a cohesive parent–child relationship. However, the < Design >, < Work >, < Product >, < Book >, < PrintedBook > hierarchy involves contiguous items sufficiently close in an experiential sense to ensure taxonomic cohesion.
Thesaurus
The CGML taxonomy maps synonymous concepts from related tag schemas.
In Figure 13.8, the CGML open-element tags and CGML fixed-attribute tags are underlined. For each tag, synonyms are identified in the various tagging schemas against which CGML is currently mapped. The underlined concepts indicate levels of implementation. < Person > data, for instance, can only be collected in the smallest granular units required by any of the mapped tagging schemes. A valid CGML < Person > record (and the IMS, ONIX, XrML, indecs, EAD and MARC synonyms) can only be generated from data recomposed from smaller granular units including, for instance, < GivenNames > and < Surname >.
Figure 13.8 Fragment of the CGML Taxonomy of Authorship and Publishing specifying the concept of < party > from the fourth to sixth levels
The CGML Thesaurus takes each tagging schema as its starting point, lists its tags and reproduces the definitions and examples as given by each tagging schema (Figure 13.9). In this way, CGML actually works with 17 thesauri, and each new mapping will require an additional thesaurus. Each thesaurus captures the way in which each tagging schema defines itself, and within its own terms. Against each tag, a direct CGML synonym is provided, whose semantics are coextensive with, or narrower than, the tag against which the mapping occurs. Unlike a conventional thesaurus, only one CGML equivalent is given for each mapped tag.

In combination with its dictionary, CGML uses what Martin identifies to be the two traditional approaches to the study of lexis in western scholarship: dictionary and thesaurus. Whereas dictionary ‘purports to unpack the “meaning” [of lexical items] by means of paraphrase and exemplars’, thesaurus is ‘organised around meaning’; it ‘purports to display the wordings through which meanings can aptly be expressed’. He concludes that ‘[b]ecause it is organised according to meaning, a thesaurus provides a more appropriate model of textual description for functional linguistics than a dictionary does’ (Martin 1992). In the case of CGML, an additional layer of rigour is added by mapping the 17 thesauri into the paradigm-constituting taxonomy.
The effect of these cross-cutting processes is the systematic mapping of existing and emerging tagging schemas against each other, and the stabilisation of synonyms between different markup languages through the medium of the CGML interlanguage tag. This has the potential to add functionality to existing schemas, not only by extension of new functionalities to otherwise separate schemas, but also by reinterpreting data created in one framework for (unanticipated) use in another. CGML thus has the potential to form the foundation for a broker software system within the domain of authorship and publishing.
Practically, this means that CGML provides a simple, transparent, clearly defined natural-language tagging framework, which will create data conforming to the schemas against which it is mapped. CGML data can be exported into any XML schema against which CGML has been mapped. The effect is to ensure interoperability between different data collection practices and frameworks—so, for instance, data collected with a CGML defined framework can simultaneously become a MARC library catalogue record and an ONIX record for a B-2-B e-commerce transaction. The reverse is only partly the case. Data formatted in any XML namespace against which CGML has been mapped can be imported into a CGML-defined database, and from this it can be exported into XML namespaces other than the one for which the data was originally defined, but only when that data enters CGML at the level granular delicacy required by the most delicately granular schema against which CGML has been mapped (identified by underlined tags, as illustrated in Figure 13.8). When a more granular mark up is required for interoperability than is available in imported data, this will usually have to be created manually—for example, breaking a < Person > ‘s name into < GivenNames > and < Surname >, part of which process will involve the complex and highly contextual business of interpreting whether the < Person > ‘s name appears in English or is structured in the traditional Chinese way.
In this sense, CGML is a resource for meaning, rather than a prescriptive activity sequence for authorship and publishing or a supplied structure of textual meaning. It is the basis for a process Kress calls transformation and design (Kress 2000, 2001). The design of meaning involves building on resources for meaning available in the world (the designed), appropriating and recombining the elements of those designs in a way that has never been done in quite the same way before (designing) and leaving a residue (the designed), which becomes a new set of resources for meaning, for the design process to begin afresh (Cope and Kalantzis 2000). This is also the way language itself works. Quoting Halliday, language is a ‘resource for meaning making’; it is therefore a system that is open to choice, ‘not a conscious decision made in real time but a set of possible alternatives’ (Halliday 1994). This brings us back to the distinction we made earlier, between formal linguistics, which regards language as a system of rules, and functional linguistics, in which language is understood as a resource for meaning (Martin 1992). As a scaffold, paradigm is not restricting or constraining. Rather it is an enabling tool for widening the domain of expressive choice, for creating any number of narrative alternatives.
References
< indecs >. 2000. ‘Interoperability Data in e-Commerce Systems’, vol. 2003, ‘<indecs > Framework Limited’.
ADL/SCORM. SCORM Overview: Shareable Content Object Reference Model. Advanced Distributed Learning. 2003, 2003.
Anderson, C. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete, 2009. [Wired, 16 July].
ANSI/NISO. Specifications for the Digital Talking Book; vol. 2003. 2002.
Australian Government Locator Service. AGLS Metadata Standard. National Archives of Australia. 2003, 2003.
Berners-Lee, T., Hendler, J., Lassila, O., The Semantic Web. Scientific American. 2001. [May].
Brandom, R. Making it Explicit: Reasoning, Representing and Discursive Commitment. Cambridge, MA: Harvard University Press; 1994.
Buzzetti, D., McGann, J. Electronic Textual Editing: Critical Editing in a Digital Horizon. In: Burnard L., O’Keeffe K.O.B., Unsworth J., eds. Electronic Textual Editing. New York: Modern Language Association of America, 2006.
Common Ground PublishingMethod and Apparatus for Extending the Range of Useability of Ontology Driven Systems and for Creating Interoperability between Different Mark-up Schemas for the Creation, Location and Formatting of Digital Content. Australia, US: Europe: Common Ground, 2003.
Cope, B. Making and Moving Books in New Ways, From the Creator to the Consumer. In: Cope B., Mason D., eds. Digital Book Production and Supply Chain Management: Technology Drivers Across the Book Production Supply Chain, from Creator to Consumer. Melbourne: Common Ground; 2001:1–20. [C-2-C Project book 2.3].
Cope, B., Freeman, R.Digital Rights Management and Content Development: Technology Drivers Across the Book Production Supply Chain, from Creator to Consumer. Melbourne: Common Ground, 2001. [C-2-C Project book 2.4].
Cope, B., Kalantzis, M. The Powers of Literacy: Genre Approaches to Teaching Writing. London: Pittsburgh: Falmer Press, 1993; 286. [(UK edition) and University of Pennsylvania Press (US edition),].
Cope, B. Designs for Social Futures. In: Cope B., Mary K., eds. Multiliteracies: Literacy Learning and the Design of Social Futures. London: Routledge; 2000:203–234.
Denny, M. Ontology Building: A Survey of Editing Tools. XML.com, 2002. [vol. 2002].
DocBook Technical CommitteeDocBook Home Page. OASIS, 2010.
Dublin Core Metadata Initiative. Dublin Core Metadata Registry, 2010.
Eco, U. Kant and the Platypus: Essays on Language and Cognition. London: Vintage; 1999.
EDItEUR. ONIX Product Information Standards 2.0, 2001. [vol. 2003, ‘International Group for Electronic Commerce in the Book and Serials Sectors’].
EDItEUR. ONIX Mappings to MARC, 2003. [vol. 2003, ‘International Group for Electronic Commerce in the Book and Serials Sectors].
EdNA Online. EdNA Metadata Standard, 2000. [vol. 2003, ‘Education Network Commonwealth of Australia’].
Encoded Archival Description Working Group. Encoded Archival Description Tag Library, 2002. [vol. 2003, ‘Society of American Archivists’].
Fairclough, N. Discourse and Social Change. Cambridge, UK: Polity Press; 1992.
Gee, J.P. Social Linguistics and Literacies: Ideology in Discourses. London: Taylor and Francis; 1996.
Halliday, M.A.K. An Introduction to Functional Grammar. London: Edward Arnold; 1994.
Harold, E.R., Means, W.S. XML. Sebastapol, CA: O’Reilly; 2002.
Husserl, E. The Crisis of European Sciences and Transcendental Phenomenology. Evanston: Northwestern University Press; 1970.
IFLA Study Group on the Functional Requirements for Bibliographic Records. Functional Requirements for Bibliographic Records. The Hague: International Federation of Library Associations and Institutions; 1998.
IMS Global Learning Consortium. IMS Learning Design Specification, 2002. [vol. 2003].
IMS Global Learning Consortium. Specifications, 2003. [vol. 2003].
International DOI Foundation. The DOI Handbook. Oxford: International DOI Foundation; 2002.
International Trade Standards Organization for the eBook Industry. Open eBook Home Page, 2003. [vol. 2003].
Jackson, H. Lexicography: An Introduction. London: Routledge; 2002.
Kress, G. Design and Transformation: New Theories of Meaning. In: Cope B., Kalantzis M., eds. Multiliteracies: Literacy Learning and the Design of Social Futures. London: Routledge; 2000:153–161.
Kress, G. Issues for a Working Agenda in Literacy. In: Kalantzis M., Cope B., eds. Transformations in Language and Learning: Perspectives on Multiliteracies. Melbourne: Common Ground; 2001:33–52.
Kress, G., van Leeuwen, T. Reading Images: The Grammar of Visual Design. London: Routledge; 1996.
Latour, B. Why Has Critique Run Out of Steam? From Matters of Fact to Matters of Concern. Critical Inquiry. 2004; 225–248.
Luria, A. Language and Cognition. New York: John Wiley and Sons; 1981.
MARC Standards Office. ONIX to MARC 21 Mapping. Library of Congress. 2003, 2000.
MARC Standards Office. MARC to Dublin Core Crosswalk. Library of Congress. 2003, 2001.
MARC Standards Office. MARC Standards. Library of Congress. 2003, 2003.
MARC Standards Office. Metadata Encoding and Transmission Standard. Library of Congress. 2003, 2003.
MARC Standards Office. Metadata Object Description Scheme. Library of Congress. 2003, 2003.
Martin, J.R. English Text: System and Structure. Philadelphia: John Benjamins; 1992.
Martin, J.R., Halliday, M.A.K. Writing Science. London: Falmer Press; 1993.
Mason, D. Cataloguing for Libraries in a Digital World. In: Cope B., Mason D., eds. Digital Book Production and Supply Chain Management: Technology Drivers Across the Book Production Supply Chain, from Creator to Consumer. Melbourne: Common Ground, 2001. [C-2-C Project book 2.3].
Mason, D., Tsembas, S. Metadata for eCommerce in the Book Industry. In: Cope B., Mason D., eds. Digital Book Production and Supply Chain Management: Technology Drivers Across the Book Production Supply Chain, from Creator to Consumer. Melbourne: Common Ground, 2001. [C-2-C Project book 2.3].
Multimedia Description Schemes Group. 2002. ‘ISO/IEC CD 21000 Part 6: Rights Data Dictionary’. International Organisation for Standardisation, ISO/IEG JTC 1/SC 29/WG 11: Coding of Moving Pictures and Audio.
National Curriculum Online. The National Curriculum Metadata Standard. London: Department for Education and Skills; 2002.
ODRL. Open Digital Rights Language, 2002. [IPR Systems].
OUL/EMLEducational Modelling Language. Heerlen: Open University of the Netherlands, 2003.
Paskin, N. DRM Technologies: Identification and Metadata. In: Becker E., Gunnewig D., Buhse W., Rump N., eds. Digital Rights Management: Technical, Economical, Juridical and Political Aspects. Berlin: Springer, 2003.
PODi. Podi: The Digital Printing Initiative, 2003.
Renear, A., Mylonas, E., Durand, D. Refining our Notion of What Text Really Is: The Problem of Overlapping Hierarchies. In: Ide N., Hockey S., eds. Research in Humanities Computing. Oxford: Oxford University Press, 1996.
Scollon, R. Multilingualism and Intellectual Property: Visual Holophrastic Discourse and the Commodity/Sign. 1999. [paper presented at GURT [Georgetown University Round Table] 1999].
Scollon, R. Mediated Discourse: The Nexus of Practice. London: Routledge; 2001.
Sowa, J.F. Knowledge Representation: Logical, Philosophical and Computational Foundations. Pacific Grove, CA: Brooks Cole; 2000.
Sowa, J.F. The Challenge of Knowledge Soup. In: Ramadas J., Chunawala S., eds. Research Trends in Science, Technology and Mathematics Education. Goa: Homi Bhabha Centre, 2006.
UK Office for Library and Information Networking. The Biblink Core Metadata Set, 2001. [vol. 2003, ‘Forum for Metadata Schema Implementers’].
Unicode. Unicode Consortium website. http://unicode.org/. 2010.
Vygotsky, L. Thought and Language. Cambridge, MA: MIT Press; 1962.
W3CHTML Specification. World Wide Web Consortium, 2010.
W3CXHTML Specification. World Wide Web Consortium, 2010.
XrML. Extensible Rights Markup Language, 2003. [Content Guard].