
Interoperability and the exchange of humanly usable digital content
Throughout this book, it has been clearly articulated that the emergence and use of schemas and standards are increasingly important to the effective functioning of research networks. What is also equally emphasised is the danger posed if the use of schemas and standards results in excessive and negative system constraints—a means of exerting unhelpful control over distributed research activities. But, how realistically can a balance be facilitated between the positive benefits derived from the centralised coordination through the use standards versus the benefits from allowing self-organisation and emergence to prevail at the edge of organisational networks?
In this chapter we set out to explore how differing approaches to such problems are actually finding expression in the world. To do this, we have engaged in a detailed comparison of three different transformation systems, including the CGML system discussed at length in the previous chapter. We caution against any premature standardisation on any system due to externalities associated with, for example, the semantic web itself.
Introduction
In exploring the theme of interoperability we are interested in the practical aspects of what Magee describes as a ‘framework for commensurability’ in Chapter 12, ‘A framework for commensurability’, and what Cope and Kalantzis describe as the ‘dynamics of difference’ discussed in Chapter 4, ‘What does the digital do to knowledge making?’. Magee suggests it is possible to draw on the theoretical underpinnings outlined in this book to construct a framework that embraces correspondence, coherentist and consensual notions of truth:
it ought now be possible to describe a framework which examines conceptual translation in terms of denotation—whether two concepts refer to the same objective things in the world; connotation—how two concepts stand in relation to other concepts and properties explicitly declared in some conceptual scheme; and use—or how two concepts are applied by their various users (Magee, Chapter 11, ‘On commensurability’).
Cope and Kalantzis suggest something that could be construed as similar when they say that the new media underpinning academic knowledge systems requires a new ‘conceptualising sensibility’.
But what do these things mean in the world of global interoperability? How are people currently affecting content exchanges in the world so that it proves possible to enter data once for one particular set of purposes, but be able to exchange this content for use related to another set of purposes in a different context?
In addressing this question, our chapter has four overarching objectives. The first is simple. We aim to make a small contribution to a culture of spirited problem solving in relation to the design and management of academic knowledge systems and the complex and open information networks that form part of these systems. For example, in the case of universities, there is the challenge of building information networks that contribute to two-way data and information flows. That is, a university information system needs to support a strategy of reflexivity by enabling the university to contribute to the adaptive capacity of the society it serves and enabling itself to adapt to the changes in society and the world.
The second objective is to facilitate debate about technical and social aspects of interoperability and content exchanges in ways that do not restrict this debate to information systems personnel only. As Cope, Kalantzis and Magee all highlight, this challenge involves the difficult task of constructively negotiating commensurability. This will require considerable commitment by all in order to support productive enagements across multiple professional boundaries.
The third objective is to highlight that new types of infrastructures will be required to mediate and harmonise the dynamics of difference. The reader will notice that a large part of the chapter draws on the emergence (and importance) of standards and a trend towards standardisation. A normative understanding of knowledge involves embracing the complex interplay between the benefits of both self-organisation and standardisation. Therefore, we think that a normative approach to knowledge now requires that the system patterns of behaviour emerge concurrently at different levels of hierarchy as has also been discussed extensively in Chapter 6, ‘Textual representations and knowledge support-systems in research intensive networks’, by Vines, Hall and McCarthy. Any approach to the challenge of interoperability has to take this matter very seriously—as we do.
The fourth objective is to highlight that in the design of new infrastructures, specific attention must be given to the distinctiveness of two types of knowledge—tacit and explicit knowledge. This topic has been well discussed throughout this book. We claim that an infrastructure that fails to acknowledge the difference between explicit and tacit knowledge will be dysfunctional in comparison with one that does. To this end, we are grateful to Paul David for suggesting the use of the phrase ‘human interpretive intelligence’, which we refer to extensively in this chapter. This phrase aims to convey that there is a dynamic interaction between tacit and explicit forms of knowledge representation. That is, explicit knowledge cannot exist in the first place without the application of human interpretative intelligence. We agree very much with Magee where in Chapter 3, ‘The meaning of meaning’, he expounds the idea that meaning is bound to the context within which content is constructed and conveyed.
The means by which we progress this chapter is by analysing one particular technical concern—the emerging explosion in the use of Extensible Markup Language (XML). The rise of XML is seen as an important solution to the challenges of automated (and semi-automated) information and data processing. However, the problem of interoperability between XML schemas remains a global challenge that has yet to be resolved. Thus this chapter focuses on how to achieve interoperability in the transformation of humanly usable digital content from one XML content storage system to another. We claim that it will be necessary to use human interpretive intelligence in any such transformation system and that a technology that fails to acknowledge this, and to make suitable provision for it, will be dysfunctional in comparison with one that does. We further claim that a choice about how such content is translated will have implications for whether the form of representation to which the content is transformed gives access to the meanings which users will wish to extract from it.
Our chapter examines three translation systems: Contextual Ontology_X Architecture (the COAX system), the Common Ground Markup Language (the CGML system) and OntoMerge (the Onto-Merge System). All three systems are similar to the extent that they draw on ‘merged ontologies’ as part of the translation process. However, they differ in the ways in which the systems are designed and how the translation processes work. The CGML and COAX systems are examples of XML to XML to XML based approaches. The OntoMerge system is an example of an XML to Ontology (using web based ontology languages such as OWL) to XML approach.
We think that the leading criterion for selecting any XML translation system is the ease of formulating expanded frameworks and revised theories of translation that create commensurability between source and destination XML content and merged ontologies. We discuss this criterion using three sub-criteria: the relative commensurability creation load in using each system, the system design to integrate the use of human interpretive intelligence, and facilities for the use of human interpretive intelligence in content translations.
In a practical sense this chapter addresses the challenge of how to achieve interoperability in the storage and transfer of humanly usable digital content, and what must be done to exchange such content between different systems in as automated a way as possible. Automated exchanges of content can assist with the searching for research expertise within a university. Such search services can be secured by linking together multiple and disparate databases. An example of this is the University of Melbourne’s ‘Find an Expert’ service hosted on the university’s website (University of Melbourne 2010).
In this chapter we are concerned with requirements for the automated exchange of content, when this content is specifically designed for human use. As described by Cope and Kalantzis elsewhere in this book, interoperability of humanly usable content allows such content, originally stored in one system for a particular set of purposes, to be transferred to another system and used for a different set of purposes. We are concerned with the design of an efficient converter system, or translator system, hereafter referred to as a transformation system, that makes possible a compatibility of content across different systems.
Our interest in this subject arises because there are substantial sunk costs associated with storing humanly usable content in particular ways. There are also significant costs of translating content from one system to another. These costs will, in due course, become sunk costs also. Therefore, in addressing this topic, our expectation is that, over time, the costs incurred in the storage and transfer of humanly usable digital content will not be regarded as sunk costs, but as investments to secure the continued access to humanly usable digital content, now and into the future.
Many people, who are focused on their own particular purposes, have described aspects of the challenges associated with the need for exchanges of humanly usable content. Norman Paskin, the first Director of the Digital Object Identifier (DOI) Foundation, has described difficulties which must be faced when trying to achieve interoperability in content designed for the defence of intellectual property rights. These include the need to make interoperability possible across different kinds of media (such as books, serials, audio, audiovisual, software, abstract works and visual material), across different functions (such as cataloguing, discovery, workflow and rights management), across different levels of metadata (from simple to complex), across semantic barriers, and across linguistic barriers (Paskin 2006). Rightscom describe the need to obtain interoperability in the exchange of content, including usage rights, to support the continued development of an e-book industry (2006, p. 40). McLean and Lynch describe the challenges of facilitating interoperability between library and e-learning systems (2004, p. 5). The World Wide Web Consortium (W3C) is itself promoting a much larger vision of this same challenge through the semantic web:
The semantic web is about two things. It is about common formats for integration and combination of data drawn from diverse sources, where on the original Web mainly concentrated on the interchange of documents. It is also about language for recording how the data relates to real world objects. That allows a person, or a machine, to start off in one database, and then move through an unending set of databases which are connected not by wires but by being about the same thing (W3C undated).
We argue that that there are two, deeper, questions relating to achieving interoperability of humanly usable content that have not been sufficiently discussed. The aim of this chapter is to show that these two challenges are interrelated.
First, we claim that it will not be possible to dispense with human intervention in the translation of digital content. A technology that fails to acknowledge this, and to make suitable provision for it, will be dysfunctional in comparison with one that does. The reason for this is that digital content is ascribed meaning by those people who use it; the categories used to organise content reflect these meanings. Different communities of activity ascribe different meanings and thus different categories. Translation of the elements of content from one set of categories to another cannot, we claim, be accomplished without the application of what we will call ‘human interpretive intelligence’. (We particularly acknowledge Paul David’s contribution and thank him for suggesting the use of this term, which we have adopted throughout this chapter.) In what follows, we will provide a detailed explanation of how this is achieved by one translation system, and will argue that any system designed to translate humanly usable content must make this possible.
Second, in order to achieve interoperability of digital content, we claim a choice about how such content is translated will have implications for whether the form of representation to which the content is transformed, gives access to the meanings that users will subsequently wish to extract from it. This has ramifications about the way in which translations are enacted. This, we argue, requires the application of human interpretive intelligence as described above in order that in the translation process content is mapped between the source and destination schemas.
We advance our general argument in a specific way—by comparing three existing systems which already exist for the abstracting of content to support interoperability. We have used this approach because these three different systems (a) make different assumptions about the use of interpretive intelligence, and (b) rely on different ontological and technical means for incorporating the use of this intelligence. The first system is the Common Ground Markup Language (CGML), whose component ontology has been used to construct the CGML interlanguage. We have termed this the CGML system. The second system is called the Contextual Ontology_X Architecture XML schema, whose component ontology is OntologyX. We have termed this the COAX system. The third system is called OntoMerge, whose architecture includes a means of merging and storing different ontologies (a feature referred to as the OntoEngine). We have termed this the OntoMerge System.
The ontological assumptions of these three different systems differ in that CGML system uses noun-to-noun mapping rules to link the underlying digital elements of content (we use the word ‘digital element’ in this chapter synonymously with the idea of a ‘digital entity’). In contrast, the COAX system uses verbs and the linkages between digital elements that are generated when verbs are used (as we shall see below, it uses what we have termed ‘verb triples’). OntoMerge also uses nouns, but these act as noun-predicates. In a way similar to the COAX system, these noun-predicates also provide linkages between digital elements in the same way as does the use of verb triples in the COAX system. The CGML system is built around the use of human interpretive intelligence, whereas the COAX and OntoMerge systems attempt to economise on the use of such intelligence.
We aim to show that points (a) and (b) above are related, in a way that has significant implications for how well exchanges of content can be managed in the three systems. We argue that choice of ontological and technical design in the COAX and the OntoMerge systems makes it much harder to apply human interpretive intelligence, and thus it is no surprise that these systems attempt to economise on the use of that intelligence. But we regard the use of such intelligence as necessary. We think this because explicit knowledge is reliant on being accessed and applied through tacit processes.
All three systems are still in their proof-of-concept stage. Because of this, a description of how all these systems abstract content is provided in the body of this chapter. We should not be understood as advancing the interests of one system over another. Rather, our purpose in analysing the systems is to highlight the possibility of locking into an inefficient standard. We agree with Paul David (2007a, p. 137) when he suggests that ‘preserving open options for a longer period than impatient market agenda would wish is a major part of such general wisdom that history has to offer public policy makers’.
The outline of the remainder of this chapter is as follows. In the next section, we discuss the translation problem and outline a generalised model for understanding the mechanisms for translating digital content. This model is inclusive of two different approaches to the problem: what we have called the XML-based interlanguage approach and the ontology-based interlanguage approach. In the following sections we discuss these different approaches in some detail, using the three different systems—CGML, COAX and OntoMerge—as case study illustrations. Then we provide some criteria for how we might choose any system that addresses the XML translation problem. In the final sections we highlight some emergent possibilities that might arise based on different scenarios that could develop and draw our conclusions.
The transformation of digital content
With current digital workflow practices, translatability and interoperability of content is normally achieved in an unsystematic way by ‘sticking together’ content originally created, so as to comply with separately devised schemas. Interoperability is facilitated manually by the creation of procedures that enable content-transfers to be made between the different end points of digital systems.
For example, two fields expressing similar content might be defined as ‘manager’ in one electronic schema and ‘supervisor’ in another schema. The local middleware solution is for an individual programmer to make the judgement that the different tags express similar or the same content and then manually to create a semantic bridge between the two fields— so that ‘manager’ in one system is linked with ‘supervisor’ in the other system. These middleware programming solutions then provide a mechanism for the streaming of data held in the first content storage system categorised under the ‘manager’ field to another content storage system in which the data will be categorised under the ‘supervisor’ field. Such programming fixes make translatability and interoperability possible within firms and institutions and, to a lesser extent, along the supply chains that connect firms, but only to the extent that the ‘bridges’ created by the programmer really do translate two tags with synonymous content. We can call this the ‘localised patch and mend’ approach. And we note both that it does involve ‘human interpretive intelligence’, the intelligence of the programmer formulating the semantic bridges, and also that the use of such intelligence only serves to formulate a model for translation from one schema to another. And as should be plain to everyone, such models can vary in the extent to which they correctly translate the content of one schema to another.
Such an approach is likely to be advocated by practical people, for an obvious reason. The introduction of new forms of information architecture is usually perceived as disruptive of locally constructed approaches to information management. New more systematic approaches, which require changes to content management systems, are often resisted if each local need can be ‘fixed’ by a moderately simple intervention, especially if it is perceived that these more systematic approaches don’t incorporate local human interpretive intelligence into information management architecture. We believe that such patch and mend approaches to translatability might be all very well for locally defined operations. But such localised solutions risk producing outcomes in which the infrastructure required to support the exchange of content within a global economy remains a hopeless jumble of disconnected fixes. This approach will fail to support translatability among conflicting schemas and standards.
The structure of the automated translation problem
In order to overcome the limitations of the patch and mend approach, we provide a detailed structure of the problem of creating more generalised translation/transformation systems. This is illustrated in Figure 14.1. This figure portrays a number of schemas, which refer to different ontological domains. For example, such domains might be payroll, human resources and marketing within an organisation; or they might include the archival documents associated with research inputs and outputs of multiple research centres within a university such as engineering, architecture or the social sciences.

Our purpose is to discuss the transfer of content from one schema to another—and to examine how translatability and interoperability might be achieved in this process. In Figure 14.1 we provide details of what we have called the ‘translation/transformation architecture’.
To consider the details of this translation/transformation architecture, it is first necessary to discuss the nature of the various schemas depicted in Figure 14.1. Extensible Markup Language (XML) was developed after the widespread adoption of Hypertext Markup Language (HTML), which was itself a first step towards achieving a type of interoperability. HTML is a markup language of a kind that enables interoperability, but only between computers: it enables content to be rendered to a variety of browser-based output devices like laptops and computers. However, HTML does this through a very restricted type of interoperability. XML was specifically designed to address the inadequacies of HTML in ways which make it, effectively, more than a markup language. First, like HTML it uses tags to define the elements of the content in a way that gives meaning to them for computer processing (but unlike HTML there is no limit on the kinds of tags which can be used). This function of XML is often referred to as the semantic function, a term which we will use in what follows. Second, in XML a framework of tags can be used to create structural relationships between other tags. This function of XML is often referred to as the syntactical function, a term which we will also use. In what follows we will call a framework of tags an XML Schema—the schemas depicted in Figure 14.1 are simply frameworks of tags. The extensible nature of XML—the ability to create schemas using it—gives rise to both its strength and weakness. The strength is that ever-increasing amounts of content are being created to be ‘XML compliant’. Its weakness is that more and more schemas are being created in which this is done.
In response to this, a variety of industry standards, in the form of XML schemas, are being negotiated in many different sectors among industry practitioners. These are arising because different industry sectors see the benefit of using the internet as a means of managing their exchanges (e.g. in managing demand-chains and value-networks) because automated processing by computers can add value or greatly reduce labour requirements. In order to reach negotiated agreements about such standards, reviews are undertaken by industry-standards bodies which define, and then describe, the standard in question. These negotiated agreements are then published as XML schemas. Such schemas ‘express shared vocabularies and allow machines to carry out rules made by people’ (W3C 2000). The advantage of the process just described is that it allows an industry-standards body to agree on an XML schema which is sympathetic to the needs of that industry and declares this to be an XML standard for that industry.
But the adoption of a wide range of different XML standards is not sufficient to address the challenge of interoperability in the way we have previously defined this. Obviously reaching negotiated agreements about the content of each XML standard does not address the problem of what to do when content must be transferred between two standards. This problem is obviously more significant, the larger the semantic differences between the ways in which different industry standards handle the same content. This problem is further compounded by the fact that many of these different schemas can be semantically incommensurable.
Addressing the problem of incommensurability
The problem of incommensurability lies at the heart of the challenges associated with the automated translation problem. Instances of XML schemas are characterised by the use of ‘digital elements’ or ‘tags’ that are used to ‘mark up’ unstructured documents, providing both structure and semantic content. At face value, it would seem that the translation problem and the problem of incommensurability could be best addressed by implementing a rule based tag-to-tag transformation of XML content. The translation ‘rules’ would be agreed through negotiated agreements among a number of localised stakeholders. This would make this approach similar, but slightly different from the ‘patch and mend’ approach discussed previously, where effectively the arbitrary use of the human interpretive intelligence of the programmer is used to resolve semantic differences.
However, in considering the possibility of either a patch and mend or a rule-based approach, we think there is a necessity to ask the question: do tags have content that can be translated from one XML-schema to another, through rule-based tag-to-tag transformations? Or put another way, do such transformations really provide ‘translations’ of ‘digital content’?
To answer this question we have to be clear about what we mean by ‘digital content’. This question raises an ontological issue in the philosophical, rather than the information technology, sense of this term. The sharable linguistic formulations about the world (claims and metaclaims that are speech-, computer- or artifact-based—in other words, cultural information used in learning, thinking, and acting) found in documents and electronic media have two aspects (Popper 1972, Chapter 3). The first is the physical pattern of markings or bits and bytes constituting the form of documents or electronic messages embodying the formulations. This physical aspect comprises concrete objects and their relationships. In the phrase ‘digital content’, ‘digital’ refers to the ‘digital’ character of the physical, concrete objects used in linguistic formulations.
The second aspect of such formulations is the pattern of abstract objects that conscious minds can grasp and understand in documents or other linguistic products when they know how to use the language employed in constructing it. The content of a document is the pattern of these abstract objects. It is what is expressed by the linguistic formulation that is the document (Popper 1972, Chapter 3). And when content is expressed using a digital format, rather than in print, or some other medium, that pattern of abstract objects is what we mean by ‘digital content’.
Content, including digital content, can evoke understanding and a ‘sense of meaning’ in minds, although we cannot know for certain whether the same content presented to different minds evokes precisely the same ‘understanding’ or ‘sense of meaning’. The same content can be expressed by different concrete objects. For example, different physical copies of Hamlet, with different styles of printing having different physical form, can nevertheless express the same content. The same is true of different physical copies of the American Constitution. In an important sense when we refer to the American Constitution, we do not refer to any particular written copy of it, not even to the original physical document, but rather to the pattern of abstract objects that is the content of the American Constitution and that is embodied in all the different physical copies of it that exist.
Moreover, when we translate the American Constitution, or any other document for that matter, from one natural language—English—to another, say German, it is not the physical form that we are trying to translate, to duplicate, or, at least, to approximate in German, but rather it is the content of the American constitution that we are trying to carry or convey across natural languages. This content cannot be translated by mapping letters to letters, or words to words across languages, simply because content doesn’t reside in letters or words. Letters and words are the tools we use to create linguistic content. But, they, themselves, in isolation from context, do not constitute content. Instead, it is the abstract pattern of relationships among letters, words, phrases and other linguistic constructs that constitutes content. It is these same abstract patterns of relationships that give rise to the linguistic context of the assertions expressed as statements in documents, or parts of documents. The notion of linguistic context refers to the language and patterns of relationships that surrounds the assertions contained within documents. The linguistic context is distinct from the social and cultural context associated with any document, because social and cultural context is not necessarily included in the content itself. Rather social and cultural context if it is captured can be included in metadata attached to that content.
We think that it is linguistic context, in this sense of the term, which makes the problem of translation between languages so challenging. This principle of translation between natural languages is inclusive of XML-based digital content. With XML content it is the abstract patterns of objects in documents or parts of documents—combining natural language expressions, relationships among the abstract objects, the XML tags, relationships among the tags, and relationships among the natural language expressions and the XML tags—that give rise to that aspect of content we call linguistic context. This need for sensitivity towards linguistic context we think forms part of what Cope and Kalantzis extol as the need for new ‘conceptualization sensibilities’. And we contend that a translation process that takes into account this sensitivity towards context involves what Cope and Kalantzis describe as the ‘dynamics of difference’.
Once a natural language document is marked up in an XML schema the enhanced document is a meta-language document, couched in XML, having a formal structure. It is the content of such a meta-language document, including the aspect of it we have called linguistic context that we seek to translate, when we refer to translating XML-based digital content from one XML language to another.
So, having said what we mean by ‘digital content’, we now return to the question: do XML tags have content that can be translated from one XML-language to another, through rule-based tag-to-tag transformations? Or, put another way, do such transformations really provide ‘translations’ of ‘digital content’? As a matter of general rule, we think not, because of the impact of linguistic context embedded in the content. We contend that this needs to be taken into account, and that tag-to-tag translation systems do not do this.
Therefore, we think something else is needed to alleviate the growing XML babel by means of a semi-automated translation approach. To address this matter and to set a framework for comparing three different transformation models and the way these different models cater for the application of human interpretive intelligence, we now analyse the details of the translation/transformation architecture outlined in Figure 14.1.
System components of a translation/transformation architecture
To address the challenge of incommensurability and linguistic context as described in the previous section, we argue that the design of effective transformation architecture must allow for the application of human interpretive intelligence. The fundamental concern of this chapter is to explore the means by which this can be achieved. Further details of the technical design choice outlined in Figure 14.1 are now summarised in Figure 14.2.

As a means of exploring aspects of the technical design choice when considering different transformation architectures, it is helpful to understand the ‘translation/transformation system’ as the underlying assumptions and rules governing the translation from one XML schema to another, including the infrastructure systems that are derived from these assumptions (see the later section where we discuss infrastructure systems in more detail). In turn, the transformation mechanisms are best understood as the ‘semantic bridges’ or the ‘semantic rules’ that create the connections between each individual digital elements within each XML schema and the translation/transformation system. In this chapter we refer to such connections as axioms. We now discuss the details of these concepts in turn.
The translation/transformation system
The design of a translation/transformation system involves the consideration of the means by which the entities that comprise multiple XML schemas are mapped together. This process is called ontology mapping. In this process, we think that in order to integrate incommensurable tags or fields and relations across differing XML schemas, human interpretive intelligence is required to create new ontological categories and hierarchical organisations and reorganisations of such categories. Importantly, when this happens, the ontology mapping process gives rise to the creation of an expanded ontology (ontology creation)—and results in what we will call a ‘merged ontology’. We call this merged ontology an interlanguage.
This idea of a merged ontology (or interlanguage) we think has important implications for the role of categories. We are aware that many might think that the reliance on categories can lead to excessive rigidity in thought processes. However, we think that the use of human interpretive intelligence as a means of addressing incommensurable tags or fields and relations across differing XML schemas addresses this problem. The important point is that in explicitly addressing incommensurability, expanded ontologies with different categories and hierarchies of categories evolve, through time, according to very specific contexts of occurrence and application. Therefore, through time, we think that the growth of an interlanguage is best understood as an evolutionary process because its continued existence and expansion is reliant on the continued critiquing of its function and relevance by the human-centric social system that surrounds it.
The interlanguage approach to translation follows the pattern of the translation/transformation architecture presented in Figure 14.1. This is because in that architecture, the transformation system is the interlanguage. The interlanguage comprises the framework of terms, expressions and rules, which can be used to talk about documents encoded using the different XML schemas that have been mapped into the transformation system.
A key point is that an interlanguage can only apply to schemas whose terms, entities and relationships have been mapped into it and therefore are modeled by it. The model includes both the relationships among terms in the interlanguage and the mapping relationships between these terms and the terms or other entities in the XML schemas that have been mapped. The model expresses a broader framework that encompasses the ontologies of the XML schemas whose categories and relationships have been mapped into it—thus the term merged ontology.
An interlanguage model will be projectable in varying degrees to XML schemas that have not been mapped into it, provided there is overlap in semantic content between the new schemas and previously mapped schemas. Speaking generally, however, an interlanguage will not be projectable to other schemas without an explicit attempt to map the new schema to the interlanguage. Since the new schema may contain terms and relationships that are not encompassed by the framework (model, theory) that is the interlanguage, it may be, and often is, necessary to add new terms and relationships, as well as new mapping rules to the interlanguage. This cannot be done automatically, and human interpretive intelligence must be used for ontology creation. As we will see when we compare three different systems analysed in this chapter, there is potential to make the ontology merging process a semi-automated activity. We shall see that the OntoMerge system is an example of this.
The transformation mechanisms
Transformation mechanisms provide the semantic bridges and semantic rules between individual XML schemas and each translation/transformation system. As we shall see, the design of different transformation mechanisms is shaped by the assumptions or rules governing the transformation system itself. This includes whether human interpretive intelligence is applied during the content translation process itself, or whether the content translation process is fully automated. One of the key themes highlighted in this chapter is the extent to which the translation of XML content can be fully automated. In the examples we discuss, the COAX and OntoMerge systems are designed to automate the content translation process. In contrast, the CGML system builds within it the capacity to apply human interpretive intelligence as part of the execution of the translation process.
An interlanguage as a theory of translation
One way to look at the problem of semi-automated translation of XML content is to recognise that an interlanguage is a theory or model of a meta-meta-language. The idea of a meta-meta language arises because each XML schema defines a meta-language which is used to markup text and when different XML schemas are mapped together the framework for cross mapping these schemas becomes a meta-meta-language. The interlanguage is supplemented with translation/transformation rules, and therefore is constantly being tested, refuted and reformulated in the face of new content provided by new XML schemas. This is a good way of looking at things because it focuses our attention on the idea that an interlanguage is a fallible theoretical construct whose success is contingent on its continuing ability to provide a means of interpreting new experiences represented by XML schemas not encountered in the past.
We now turn to two different examples of addressing the translation/transformation challenge—the XML-based transformation approach and the ontology-based transformation approach.
The XML-based interlanguage approach: two examples
In the XML-based interlanguage approach, the transformation system or interlanguage is itself a merged ontology expressed as an XML schema. The schema provides a linguistic framework that can be used to compare and relate different XML schemas. It can also be used along with the transformation mechanisms to translate XML documents marked up in one schema into XML documents using different schemas.
We will now supplement this general characterisation of XML-based interlanguages with an account of two examples: the Common Ground Markup Language (CGML) and the Contextual Ontology_X Architecture (COAX). The theoretical foundations of the CGML system have been written up elsewhere in this book. CGML forms part of an academic publishing system owned by Common Ground Publishing, formerly based in Australia and now based in the Research Park at the University of Illinois in Champaign, Illinois. The foundations of the COAX system have been written up by Rightscom (2006). The COAX system forms part of an approach to global infrastructure which is being pioneered by the International Digital Object Identifier (DOI) Foundation. It uses an ontology called Ontology_X, which is owned by Rightscom in the UK.
The difference in ontological structure between the CGML and the COAX systems is visualised in Figure 14.3.

The CGML translation/transformation architecture
With the CGML system, the digital elements that become part of this transformation system all emanate from the activities of practitioners as expressed in published XML standards. CGML uses semantics and syntax embodied in those standards. All digital tags in the CGML system define nouns or abstract nouns. But these are defined as a kind of a word. CGML tags can be understood as lexical items, including pairs or groups of words which in a functional sense combine to form a noun or abstract noun, such as < CopyEditor > .
A key element of the CGML system is the CGML ‘interlanguage’. This is an ‘apparatus’ that is used to describe and translate to other XML-instantiated languages (refer to Chapter 13 for details). In particular, the CGML application provides a transformation system through which the digital elements expressed in one XML standard can be transformed and expressed in another standard. As Cope and Kalantzis highlight in Chapter 13, ‘Creating an interlanguage of the social web’, the interlanguage is governed by two ‘semantic logics’. The first is that of distinction-exclusion. This helps identify tags whose meanings exist as parallel branches (sibling relations)—those tags which have synonymous meanings across different standards and, by implication, those that do not. For example, a < Person > is not an < Organisation > because an < Organisation > is defined as a legally or conventionally constituted group of < Persons >. The second logic is that of relation-inclusion. This determines tags contained within sub-branches (parent–child relations), which are semantically included as part of the semantics of the superordinate branch. For example, a < Party > to a creative or contractual relationship can be either a < Person > or an < Organisation > .
As outlined in Chapter 13, ‘Creating an interlanguage of the social web’, the impact of these two logics gives rise to the semantic and the syntactical rules that are embedded within the CGML tag dictionary and the CGML thesaurus. The CGML tag thesaurus takes each tag within any given schema as its starting point, reproduces the definitions and provides examples. Against each of these tags, a CGML synonym is provided. The semantics of each of these synonyms are coextensive with, or narrower than, the tag against which the mapping occurs. The CGML tag dictionary links the tag concept to a semantically explicit definition.
The CGML Dictionary does not purport to be about external referents as ‘meaning’; rather, it is built via the interlanguage technique from other languages that purport to have external referents. As a consequence, its meanings are not the commonsense meanings of the lifeworld of everyday experience, but derivative of specialised social languages. In one sense, therefore, the dictionary represents a ‘scaffold for action’ with the CGML Dictionary being more like a glossary than a normal dictionary. Its building blocks are the other tag-concepts of the CGML interlanguage. A rule of ‘lowest common denominator semantics’ is rigorously applied.
Obviously, the contents of the thesaurus and the dictionary can be extended, each time a new XML standard or even, indeed, a localised schema is mapped into the CGML interlanguage. Thus, the interlanguage can continuously evolve through time in a type of lattice of cross-cutting processes that map existing and emerging tagging schemas.
By systematically building on the two logics described above, Cope and Kalantzis highlight that the interlanguage mechanism (or apparatus, as they call it) does not manage structure and semantics per se. Rather they suggest (in Chapter 13) that it automatically manages the structure and semantics of structure and semantics. Its mechanism is meta-structural and meta-semantic. It is aimed at interoperability of schemas which purport to describe the world rather than reference the world.
How the CGML system works
The key requirement for the CGML system to work on a particular XML document or content is that the XML standard underlying the document has already been mapped into the CGML interlanguage. The mapping process requires a comparison of the noun tags in the XML standard with the nouns or abstract nouns in the existing CGML ontology at the time of the mapping. This process requires the application of human interpretive intelligence. Generally speaking, there will be considerable overlap in noun tags between the CGML system and the XML standard: the ‘common ground’ between them. For the remaining tags, however, it will be necessary to construct transformation rules that explicitly map the noun tags in the standard to noun and abstract noun tags in CGML. Where this can’t be done, new noun (or abstract noun) tags are taken from the standard and added to CGML, which means placing the new tags in the context of the hierarchical taxonomy of tags that is CGML, and also making explicit the translation rules between the tags in the standard and the new tags that have been added to the CGML system.
An overview of the resulting revised CGML translation/transformation system, as it is applied to XML content, is provided in Figure 14.4. We can describe how this system works on content as a two-stage process.
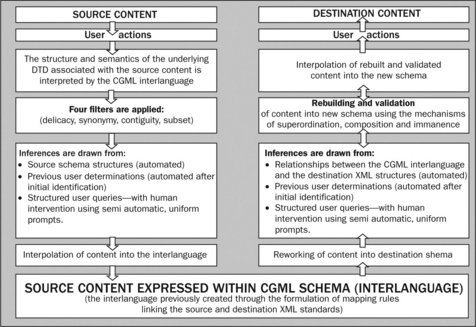
Stage 1 Merge the source XML content with the CGML XML schema
To begin with, the CGML interlanguage apparatus interprets the semantics and syntax of the source content. It is able to do this from the underlying XML standard (or schema) and the particular way the source content is expressed within the semantic and syntactic structure of the standard (or schema) itself. For this to be possible, it is, once again, necessary that each XML standard has already been mapped into the CGML interlanguage. The translation of the source content into the CGML interlanguage is then carried out by passing the source content through the delicacy, synonymn, contiguity and subset filters explained by Cope and Kalantzis in Chapter 13, ‘Creating an interlanguage of the social web’.
The translation can at times occur in automated ways, when inferences can be drawn from the underlying XML standard. Where it is not possible to construe any direct relationships between content elements from the source standard and the interlanguage, a structured query is thrown up for the user to respond to. It is in this process that human interpretive intelligence is applied to enable translation. User responses to these structured queries become part of the accumulated ‘recordings’ of semantic translations. These responses are then built up into a ‘bank’ of previous translations. The results stored in this bank can be used to refine the operation of the filters so that as the transformation process is repeated fewer and fewer structured queries are thrown up for the user to respond to. It is possible, in principle, for the filters to be ‘trained’, in a similar way to that in which voice recognition software is trained to recognise the speech of particular speakers. The user responses grow the knowledge about translation contained in the translation system, and also grow the ontology resident in CGML. This shows that ‘human interpretive intelligence’ is about solving problems that appear in the translation system, and raises the question of whether such a hybrid approach might have an advantage over other XML-based systems that do not provide for human intervention in problem solving and the growth of translation knowledge.
Stage 2 Transform CGML XML content into the destination standard
Once the content is interpolated into the CGML interlanguage, the content is structured at a sufficient level of delicacy to enable the CGML transformation system to function. Some reconfiguration of the content is necessary so that appropriate digital elements can be represented according to the semantic and syntactic structures of the destination XML standard. This process involves passing the content ‘backwards’ through only two of the filters but with the backwards filter constraints set according to the requirements of the destination standard. Only the contiguity and subset filters are required, because when content is structured within the CGML interlanguage apparatus, the content already exists at its lowest level of delicacy and semantic composition and thus the delicacy and synonymy filters are not needed. The three mechanisms associated with this backwards filtering process are superordination, composition and immanence and a number of other ‘sub-mechanisms’—as outlined by Cope and Kalantzis in Chapter 13, ‘Creating an interlanguage of the social web’.
This translation can also occur in automated ways when inferences can be drawn from the destination standard. In the case where the filter constraints prevent an automated passing of content, then a structured query is thrown up for the user to respond to. User responses are then built up into a bank of previous translations. The results stored in this bank can also be used to refine the operation of the filters so that, as the translation process is repeated, fewer and fewer structured queries are thrown up for the user to respond to in this second stage as well as in the first stage.
The COAX translation/transformation architecture
The COAX transformation system differs from the CGML system principally in the importance that verbs play in the way in which the COAX system manages semantics and syntax: ‘Verbs are… the most influential terms in the ontology, and nouns, adjectives and linking terms such as relators all derive their meanings, ultimately, from contexts and the verbs that characterize them’ (Rightscom 2006, p. 46).
Rightscom gives the reason for this:
COA semantics are based on the principle that meaning is derived from the particular functions which entities fulfil in contexts. An entity retains its distinct identity across any number of contexts, but its attributes and roles (and therefore its classifications) change according to the contexts in which it occurs (2006, p. 46).
The origins of this approach go back to the < indecs > metadata project. < indecs > was a project supported by the European Commission, and completed in 2000, which particularly focused on interoperability associated with the management of intellectual property. The project was designed as a fast track, infrastructure project aimed at finding practical solutions to interoperability affecting all types of rights-holders in a network, e-commerce environment. It focused on the practical interoperability of digital content identification systems and related rights metadata within multimedia e-commerce (Info 2000, p. 1).
The semantics and syntactical transformations associated with the COAX system depend on all tags within the source standard being mapped against an equivalent term in the COAX system. By working in this way, Rust (2005, slide 13) suggests that the COAX system can be understood as an ontology of ontologies. Rightscom explains the process by which an XML source standard is mapped into COAX:
For each schema a once-off specific ‘COA mapping’ is made, using Ontology_X. This mapping is made in ‘triples’, and it represents both the syntax and semantics of the schema. For example, it not only contains the syntactic information that element X is called ‘Author’ and has a Datatype of ‘String’ and Cardinality of ‘1-n’, but it contains the semantic information that ‘X IsNameOf Y’ and that ‘Y IsAuthorOf Z’. It is this latter dimension which is unusual and distinguishes the COAX approach from more simple syntactic mappings which do not make the semantics explicit (2006, p. 27).
Even though we are describing the COAX system as an XML to XML to XML translation system, it is entirely possible that this methodology could emerge into a fully fledged semantic web application that draws on RDF and OWL specifications.
The ways in which the COAX system specifies the triples it uses is in compliance with the W3C RDF standard subject–predicate–object triple model (Rightscom 2006, p. 16).
How the COAX transformation system works
The COAX transformation system works as a two-staged process (Figure 14.5).
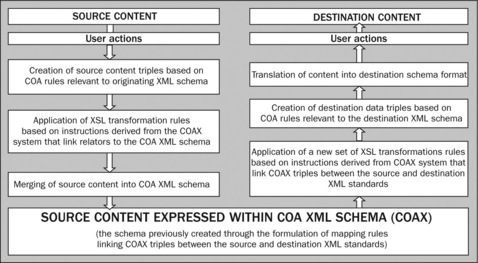
Stage 1 Merging the source XML content with the COA XML schema
To begin with, all ‘elements’ from the source content are assigned ‘relators’ using a series of rules which are applied using the COAX transformation system. A ‘relator’ is an abstraction expressing a relationship between two elements—the domain and range of the relator (Rightscom 2006, p. 57). The relators may be distinct for each different XML standard and all originate from the COAX dictionary. The relators and the rules for assigning relators will have been created when each XML standard is mapped into the COAX system. Obviously for a user to be able to proceed in this way, it is necessary that each XML standard has already been mapped into the COAX system.
The linked elements created by the assigning of relators are expressed as XML structured triples. The COA model is ‘triple’ based, because content is expressed as sets of domain–relator–range statements such as ‘A HasAuthor B’ or ‘A IsA EBook’ (Rightscom 2006, p. 25). This domain–relator–range is in compliance with the W3C RDF standard subject–predicate–object triple model (Rightscom 2006, p. 16). These triples contain the semantic and syntactic information which is required for content transformation. Notice that relators must be constructed to express relationships between every pair of digital elements if these elements are to be used within the COAX transformation system. The aggregation of triples form the basis of the COAX data dictionary. Data dictionary items are created when the elements in the source and destination XML schemas are mapped against each using relators as the basis for mapping COAX triples.
Once the content is specified as a set of triples, then the COAX system uses the Extensible Stylesheet Language (XSL). XSL is an XML-based language, which is used for the transformation of XML documents (Wikipedia 2006) to further transform the source content, now expressed as triples, into a form whose semantics and syntax are compliant with the COAX schema. The XSL transformations (XSLTs) used to do this contain within them rules generated by Rightscom that are specific to the transformation of the content from the set of triples into the COAX interlanguage. For a user to be able to do this requires that the necessary rules and XSLT instructions have been mapped into the COAX system. Unlike the CGML XML content translation process, the COAX process of merging XML content into COAX is completely automatic and there is no facility for user queries to determine how content not represented in COAX may be integrated into the merged COAX ontology. Thus the use of human interpretive intelligence in COAX is limited to the contributions of Rightscom experts who create the bridge mappings of XML standards to COAX.
Stage 2 Transform the COAX content into the destination standard
Once the content is structured according to the COAX schema requirements, a new set of XSLTs is applied to the content in order to transfer the content from the COAX schema format into a set of triples which contain the semantic and syntactic information needed to convert the content into a form compatible with the destination XML standard. The new XSLTs used to do this also contain within them rules generated by Rightscom, and are specific to the transformation of COAX-formatted content to the destination standard. Again, for a user to be able to do this it is necessary that each XML standard has already been mapped into the COAX system.
A further series of rules are then applied using the COAX transformation system to translate the content, expressed as a set of triples, into the format of the destination XML standard. These rules will be different for each destination XML standard and are created when each XML standard is mapped into the COAX system. Again, for a user to be able to proceed in this way, it is necessary that the destination XML standard has already been mapped into the COAX system.
The ontology-based interlanguage approach: OntoMerge
In the ontology-based interlanguage approach, the transformation system or interlanguage (see Figure 14.1) is different from what we have described with CGML and COAX. This difference in approach arises because an ontology-based interlanguage approach does not result in an XML to XML to XML translation. Rather, it is an XML to ontology to XML translation. Like in the XML-based interlanguage approach, the transformation system is itself a merged ontology. But unlike the XML-based interlanguage approach the merged ontology is not expressed as an XML schema. In contrast, it is expressed as semantic web ontology through the use of object-oriented modelling languages such as Ontology Web Language (OWL). OWL is designed for use by applications that need to process the content of information instead of just presenting information to humans (W3C 2004a). Processing the content of information includes the ability to lodge queries across differing information systems that might be structured using different schema frameworks.
In achieving the objective of ‘processing content’ these merged ontologies, in turn can be used in two ways. First, they can assist with the translation of different ontologies through the continuous expansion of the transformation system to create larger, more expansive merged ontologies. Second, they can be used in the translation of one XML document to another. This highlights that XML schemas and ontologies are not the same thing. An XML schema is a language for restricting the structure of XML documents and provides a means for defining the structure, content and semantics of these documents (W3C 2000). In contrast, ontology represents the meaning of terms in vocabularies and the inter-relationships between those terms (W3C 2004a).
But despite the differences in the way the interlanguage mechanisms work, the overall system architecture is the same as that outlined in Figure 14.1. That is, the transformation system is the interlanguage, but the interlanguage is expressed as a semantic web ontology using object-orientated modelling languages. The ontology comprises a framework of terms, expressions and rules, which can be used as a basis for analysing documents encoded using the different XML schema that have been mapped into the transformation system and for supporting queries between different information systems that have been structured across different ontologies. To work through the differences in the ways the semantic web interlanguage systems work, we now turn to one example of such a translation/transformation architecture—OntoMerge.
OntoMerge: an example of an ontology-based translation system
OntoMerge is an online service for ontology translation, developed by Dejing Dou, Drew McDermott and Peishen Qui (2004a, 2004b) located at Yale University. It is an example of a translation/transformation architecture that is consistent with the design principles of the semantic web. Some of the design principles of the semantic web that form part of the OntoMerge approach include the use of formal specifications such as Resource Description Framework (RDF), which is a general-purpose language for representing information in the web (W3C 2004b); OWL and the predecessor language such as DARPA Agent Markup Language (DAML), the objective of which has been to develop a language and tools to facilitate the concept of the semantic web; Planning Domain Definition Language (PDDL) (Yale University undated a); and the Ontology Inference Layer (OIL).
To develop OntoMerge, the developers have also built their own tools to do translations between the PDDL and DAML. They have referred to this as PDDAML (Yale University undated b).
serves as a semi-automated nexus for agents and humans to find ways of coping with notational differences between ontologies with overlapping subject areas. OntoMerge is developed on top of PDDAML (PDDL-DAML Translator) and OntoEngine (inference engine).
and produces the concepts or instance data translated to the target ontology (Yale University undated c).
More recently, OntoMerge has acquired the capability to accept DAML + OIL and OWL ontologies, as well. Like OWL, DAML + OIL is a semantic markup language for web resources. It builds on earlier W3C standards such as RDF and RDF Schema, and extends these languages with richer modelling primitives (W3C 2001). For it to be functional, OntoMerge requires merged ontologies in its library. These merged ontologies specify relationships among terms from different ontologies.
OntoMerge relies heavily on Web-PDDL, a strongly typed, first-order logic language, as its internal representation language. Web-PDDL is used to describe axioms, facts and queries. It also includes a software system called OntoEngine, which is optimised for the ontology-translation task (Dou, McDermott and Qui 2004a, p. 2). Ontology translation may be divided into three parts:
![]() syntactic translation from the source ontology expressed in a web language, to an internal representation, e.g., syntactic translation from an XML language to an internal representation in Web-PDDL
syntactic translation from the source ontology expressed in a web language, to an internal representation, e.g., syntactic translation from an XML language to an internal representation in Web-PDDL
![]() semantic translation using this internal representation; this translation is implemented using the merged ontology derived from the source and destination ontologies, and the inference engine to perform formal inference
semantic translation using this internal representation; this translation is implemented using the merged ontology derived from the source and destination ontologies, and the inference engine to perform formal inference
![]() syntactic translation from the internal representation to the destination web language.
syntactic translation from the internal representation to the destination web language.
In doing the syntactic translations, there’s also a need to translate between Web-PDDL and OWL, DAML or DAML + OIL. OntoMerge uses its translator system PDDAML to do these translations:
Ontology merging is the process of taking the union of the concepts of source and target ontologies together and adding the bridging axioms to express the relationship (mappings) of the concepts in one ontology to the concepts in the other. Such axioms can express both simple and complicated semantic mappings between concepts of the source and target ontologies (Dou, McDermott and Qi 2004a, pp. 7–8).
Assuming that a merged ontology exists, located typically at some URL, OntoEngine tries to load it in. Then it loads the dataset (facts) in and does forward chaining with the bridging axioms, until no new facts in the target ontology are generated (Dou, McDermott and Qi 2004a, p. 12).
Merged ontologies created for OntoMerge act as a ‘bridge’ between related ontologies. However, they also serve as new ontologies in their own right and can be used for further merging to create merged ontologies of broader and more general scope.
Ontology merging requires human interpretive intelligence to work successfully, because ontology experts are needed to construct the necessary bridging axioms (or mapping terms) from the source and destination ontologies. Sometimes, also, new terms may have to be added to create bridging axioms, and this is another reason why merged ontologies have to be created from their component ontologies. A merged ontology contains all the terms of its components and any new terms that were added in constructing the bridging axioms.
Dou, McDermott, and Qi themselves emphasise heavily the role of human interpretive intelligence in creating bridging axioms:
In many cases, only humans can understand the complicated relationships that can hold between the mapped concepts. Generating these axioms must involve participation from humans, especially domain experts. You can’t write bridging axioms between two medical-informatics ontologies without help from biologists. The generation of an axiom will often be an interactive process. Domain experts keep on editing the axiom till they are satisfied with the relation expressed by it. Unfortunately, domain experts are usually not very good at the formal logic syntax that we use for the axioms. It is necessary for the axiom-generating tool to hide the logic behind the scenes whenever possible. Then domain experts can check and revise the axioms using the formalism they are familiar with, or even using natural-language expressions (Dou, McDermott and Qi 2004b, p. 14).
OntoMerge and the translation of XML content
It is in considering the problem of XML translations that a distinguishing feature of the OntoMerge system is revealed when compared with the CGML and COAX approaches. OntoMerge is not reliant on the declaration of XML standards in order for its transformation architecture to be developed. This reflects OntoMerge’s semantic web origins and the objective of ‘processing the content of information’. Because of this, the OntoMerge architecture has developed as a ‘bottom up’ approach to content translation. We say this because with OntoMerge, when the translation of XML content occurs there is no need to reference declared in XML standards in the OntoMerge transformation architecture. Nor is there any assumption that content needs to be XML standards based to enact successful translation. In other words, OntoMerge is designed to start at the level of content and work upwards towards effective translation. We highlight this perceived benefit, because, in principle, this bottom-up approach to translation has the benefit of bypassing the need for accessing XML standards-compliant content. We say work upwards because, as we emphasise in the next paragraph, OntoMerge relies on access to semantic web ontologies to execute successful translations.
Within the OntoMerge system architecture there is a need to distinguish between a ‘surface ontology’ and a ‘standard (or deep) ontology’. A surface ontology is an internal representation of the ontology derived from the source XML content when the OntoEngine inference engine is applied to the source content. In contrast, a standard ontology focuses on domain knowledge and thus is independent of the original XML specifications (Qui, McDermott and Dou 2004, p. 7).
Thus surface and standard ontologies in the ontology-based interlanguage approach appear to be equivalent to XML schemas and standards in the XML-based interlanguage approach. So, whereas with the XML-based interlanguage approach, there is a reliance on declared XML standards, with the ontology-based interlanguage approach there is a need to draw on published libraries of standard ontologies or semantic web ontologies. In translating XML content using the OntoMerge system architecture the dataset is merged with the surface ontology into what we have called a surface ontology dataset. In turn, this is subsequently merged with the standard ontology to create what we have termed a standard ontology dataset. The details of how this merging takes place are described in the following section. Once the content is expressed in the standard ontology dataset it can then be translated into a standard ontology dataset related to the destination content schema. The choice of the standard ontology is determined by its relatedness to the nature of the source content. In executing such translations of XML content, the OntoMerge system also uses bridging axioms. These are required in the translation between different standard ontology datasets. Thus with the OntoMerge system bridging axioms act as the transformation mechanisms and are central to the translation of XML content (Qui, McDermott and Dou 2004, p. 13). With both the CGML and COAX systems, the transformation mechanisms play a similar role to that of the bridging axioms in OntoMerge. In CGML, we saw that rules associating noun-to-noun mappings were critical to performing translations. For COAX, we saw that COAX triple to COAX triple mappings were the most influential terms in the ontology. In OntoMerge, the key to translation are the bridging axioms that map predicates to predicates in the source and destination standard ontologies respectively.
Predicates are terms that relate subjects and objects and are central to RDF and RDF triples. In RDF, a resource or subject (or name) is related to a value or object by a property. The property, the predicate (or relator) expresses the nature of the relationship between the subject and the object (or the name and the value). The assertion of an RDF triple says that some relationship indicated by the triple holds between the things donated by the subject and the object of the triple (W3C 2004b). Examples of predicates include: ‘author’, ‘creator’, ‘personal data’, ‘contact information’ and ‘publisher’. Some examples of statements using predicates are:
Routledge is the publisher of All Life Is Problem Solving
John’s postal address is 16 Waverly Place, Seattle, Washington
With OntoMerge, then, predicates are nouns, and bridging axioms are mapping rules that use predicates to map nouns-to-nouns as in CGML. However, there are significant differences in approach because these nouns as predicates carry with them the inferred relationships between the subjects and objects that define them as predicates in the first place. This is the case even though the bridging axioms are not defined using triples mapped to triples as in the case of COAX.
The importance of predicates is fundamental to the OntoMerge inference engine, OntoEngine, because one of the ways of discriminating ‘the facts’ embedded within datasets loaded into OntoEngine is through the use of predicates. That is, predicates form the second tier of indexing structure of OntoEngine. This in turn provides the foundation for OntoEngine to undertake automated reasoning: ‘When some dataset in one or several source ontologies are input, OntoEngine can do inference in the merged ontology, projecting the resulting conclusions into one of several target ontologies automatically’ (Dou, McDermott and Qui 2004b, p. 8).
How the OntoMerge system works
There are some differences in the way OntoMerge is used to translate XML content versus how it is applied to translate ontologies. The general approach taken to XML content translation has been outlined by Dou, McDermott and Qi as follows:
We can now think of dataset translation this way: Take the dataset and treat it as being in the merged ontology covering the source and target. Draw conclusions from it. The bridging axioms make it possible to draw conclusions from premises some of which come from the source and some from the target, or to draw target-vocabulary conclusions from source-language premises, or vice versa. The inference process stops with conclusions whose symbols come entirely from the target vocabulary; we call these target conclusions. Other conclusions are used for further inference. In the end, only the target conclusions are retained; we call this projecting the conclusions into the target ontology. In some cases, backward chaining would be more economical than the forward-chain/project process… In either case, the idea is to push inferences through the pattern (2004b, p. 5).
The details of this approach to translating XML documents into other XML standards are outlined in Figure 14.6. As with the CGML and COAX approaches, we have also described how this system works as a two-staged process.
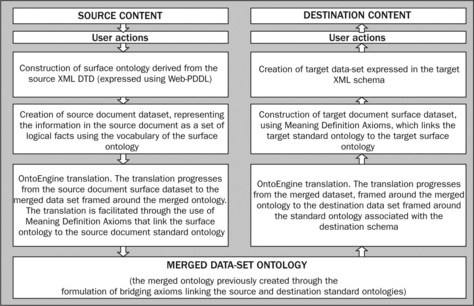
Stage 1 Transform source content schema into the merged ontology data set
To begin with the OntoEngine inference engine is used to build automatically a surface ontology from the source XML content’s Document Type Definition (DTD) file. A DTD defines the legal building blocks of an XML document and defines the document structure with a list of legal elements and attributes (W3 Schools undated). The surface ontology is the internal representation of the ontology derived from the source DTD file and is expressed using Web-PDDL (mentioned previously). Drawing on the vocabulary of the surface ontology, OntoEngine is used to extract automatically a dataset from the original XML content and the surface ontology. Though Qui, McDermott and Dou (2004, p. 5) don’t use this term, we call the new dataset the source document surface dataset.
This dataset represents the information in the source document ‘as a set of logical facts using the vocabulary of the surface ontology’. The need then is to merge this dataset further into a standard ontology dataset. In order to accomplish this merging, there is a requirement that the surface ontology has been merged with the standard ontology through the formulation of different types of bridging axioms called Meaning Definition Axioms (MDAs) (Qui, McDermott and Dou 2004, p. 2). According to Qui, McDermott and Dou, MDAs are required to assign meaning to the source XML content. This is achieved by relating the surface ontology to the particular standard ontology. As in the case of formulating bridging axioms, these MDAs are created with the help of human interpretive intelligence. Once these MDAs are formulated, the merging process can proceed with an automatic translation of the source document surface dataset to a dataset expressed in the standard ontology. The translation is also undertaken using the OntoEngine inference engine. The translation is able to proceed because of inferences derived from logical facts that are accessible from the use of MDAs that link the surface ontology dataset to the standard ontology. We now call this the source document merged ontology dataset.
Stage 2 Transform the source document merged ontology dataset into the destination XML schema
The source document merged ontology dataset is then translated to the destination document merged ontology. This translation is executed using OntoEngine and once again this translation is conditional on the formulation of bridging axioms that link the source and destination standard ontologies. The translation results in the creation of a destination document merged ontology dataset. In turn, this is translated into a destination document surface ontology dataset also using OntoEngine. This translation is conditional on MDAs being formulated that link the destination standard ontology with the destination surface ontology. The destination document surface ontology dataset is subsequently used along with the DTD file for the destination XML standard or schema, to create a destination dataset expressed in the destination XML standard (or schema). This completes the translation.
Differences in approach
The OntoMerge approach to XML translation is different from the CGML and COAX approaches in that it is pursued in a much more bottom-up rather than top-down manner. That is, when someone is faced with an XML translation problem and wants to use the OntoMerge approach, they don’t look to translate their surface ontologies to a single interlanguage model as represented by a model like the CGML or COAX systems. Rather, they first have to search web libraries to try to find a standard ontology (written in DAML, DAML + OIL or OWL) closely related to the knowledge domain of the surface ontology that has been merged with the surface ontology through the formulation of MDAs. Second, they also need to search web libraries for an earlier merged ontology that already contains bridging axioms linking the source standard ontology and the destination standard ontology. Third, they also need to search web libraries for previously developed ontologies that merge the destination standard ontology with the destination surface ontology through the formulation of meaning definition axioms. If no such merged ontologies exist, then no translation can be undertaken until domain experts working with OntoMerge can construct MDAs mapping the predicates in their surface ontologies to an ontology already available in DAML, DAML + OIL or OWL ontology libraries. Thus far, there appears to be no standard deep ontological framework that merges all the ontologies that have been developed in OntoMerge application work. There are many islands in the OntoMerge stream. But the centralised integration offered by CGML and COAX is absent.
Evaluating approaches to interoperability
In previous sections we have discussed the general nature of the transformation/translation problem from digital content expressed in one XML schema to the same digital content expressed in another. We have then reviewed three systems for performing such translations. Two of these systems originated in the world of XML itself and aim to transform the ad hoc ‘patch-and-mend’ and rule-based tag-to-tag approaches to transformation with something that would be more automatic, more efficient and equally effective. The third system originated in the world of the semantic web as a solution to the need for a software tool that would assist in performing ontology translations. The OntoMerge system was developed to solve this generalised problem and was found to be applicable to the problem of XML schema translations. As we have seen previously, all three systems rely on a merged ontology approach that creates either a generalised interlanguage, or in the case of OntoMerge a less generalised non-XML-based interlanguage that will work to translate one XML document to another.
In this section of the chapter we confront the problem of system choice. How do we select among competing architectures designed to enable XML translations? System selection, of course, requires one or more criteria, which we now proceed to outline and discuss. Then we illustrate the application of the criterion or criteria to the three illustrative systems reviewed earlier.
A generalised criterion for selecting among systems develops from the problem of semantic incommensurability that arises during the process of translating XML content between different schemas or standards. It is the criterion of ease of creating such commensurability (Firestone and McElroy 2003, p. 161; Popper 1970, pp. 56–57) where needed, so that transformations of XML content between one schema (or standard) and another can be implemented. In general, the system supporting the greatest relative ease and convenience in creating commensurability is to be preferred.
Another way to look at this arises from the recognition that the merged ontologies used in all three approaches may be viewed as fallible theories of transformation/translation among variant XML standards and schemas. Each time a dataset representing a new standard or schema is encountered that cannot be translated using a previously developed merged ontology, the theory of translation using that ontology is falsified by the new data that has been encountered, and there is a need to revise that theory of translation by creating an expanded merged ontology whether in CGML, COAX, OntoMerge or some other system.
Thus, to use such transformation/translation architectures, there is a continuing need to reformulate the embedded theories of translation and merged ontologies. Again, the system that makes it easiest to formulate expanded frameworks arising from revised theories of translation that create commensurability between source and destination XML content and merged ontologies is the system that should be selected among a number of competitors. We now apply this criterion to a comparison of the three transformation/translation systems reviewed above.
The commensurability creation load
We have coined the term commensurability creation load to describe the extent to which infrastructure is required to contribute to the means by which commensurability can be created between different ontologies. We are concerned here with the costs and complexity of establishing, administering and maintaining such infrastructure. In framing our discussions about such matters we recognise that different system architectures have significant impact on the nature of required infrastructure. Therefore, we discuss the issue of commensurability creation load under the headings of XML to XML to XML (CGML and COAX) and XML to ontology to XML (OntoMerge) infrastructure systems.
XML-based interlanguage infrastructure
With the two XML to XML to XML transformation architectures discussed in this chapter, the infrastructure requirements are similar to the extent that both require the creation, management and upgrading of interlanguage terms, including data dictionaries. In both cases, the origins of these terms are derived from declared XML standards. Therefore, one of the overarching infrastructure requirements of the XML-based transformation architectures is global agreements about protocols for the publishing of XML standards.
Beyond the publishing of XML standards we think that in the construction of interlanguage terms, including data dictionaries, the commensurability creation load of the CGML system architecture will prove to be significantly less than for the COAX system. We think this for two reasons. First, with CGML, all interlanguage terms are derived from published XML standards, with CGML’s focus on noun mappings. Therefore with the CGML approach, the transformation architecture is grounded in a familiar social language of declared standards. This is not completely the case with COAX, where the verb triples are designed to be machine readable and not necessarily easily read by people. Second, there will need to be fewer interlanguage terms and data dictionary entries in CGML compared with the number of relators and triples within the COAX system dictionary. This claim is supported by some of the early figures, comparing the sizes of the data dictionaries of the two systems, and also by some simple arguments. We use their early figures (2005) below to make generalised comparisons—we have not been able to access more up-to-date figures.
In 2005 the COAX system was reported to have a dictionary of 27,000 terms, of which 23,000 were relators. It also included around 500,000 triples with a dozen standards being mapped into the system (Rust 2005, slide 13). The first reason for this difference in scale of approach between the COAX and CGML systems is apparent just from looking at Figure 14.3. Let us assume that this figure refers to one simple XML standard (and not multiple metadata elements from several different standards). If there are n circular objects in each of the pictures, then this requires that n items be defined in the CGML Dictionary. By contrast, the COAX dictionary requires that up to n(n-1)/2 triples be defined for every relator which is used to join n objects in the ontology. If n equals 10 and there are five relators in an ontology, then ten dictionary entries would need to be defined for CGML. But for COAX, there could be 10(10-1)/2 or 45 triples for each of the five relators; altogether up to 225 triples that need to be mapped to the COAX system. As n increases linearly, the required number of COAX mappings explodes exponentially. Of course, not all objects will need relating to each other in triples, but the point that the number of COAX mappings necessary to create commensurability can explode compared to the number of CGML mappings remains a compelling one.
It is interesting to note that the infrastructure model related to the COAX system is continuing to evolve. For example, in December 2009 the University of Strathclyde Glasgow released a first stage report of a new Vocabulary Mapping Framework (VMF) project. The aim of this project, which includes proponents of the COAX system, is to:
provide a freely available tool which can be used to automatically compute the ‘best fit’ mappings between terms in controlled vocabularies in different metadata schemes and messages (both standard and, in principle, proprietary) which are of interest to the educational, bibliographic and content publishing sectors (University of Strathclyde Glasgow 2009).
It is reported that the initial scope of the project has been to map < Resource categories > (eg CD, Ebook, Photograph), < Resource-to-Resource relators > (eg IsVersionOf, HasTranslation), < Resource-to-Party relators > (e.g. Author, EditedBy), < Party-to-Party relators > (eg AffiliatedTo) and < Party categories > (University of Strathclyde Glasgow 2009).
The initial report highlights some of the challenges associated with the commensurability creation load:
As the VMF matrix will be freely available, there is no barrier to anyone attempting mappings or queries of their own for any purpose, and we encourage this to help in the development of the tool. However, it will not be sensible to allow mappings to be made in an ad hoc and unvalidated way if those mappings are going to be authoritative and used by others. A mapping represents a statement of equivalence between the concepts of two different parties or domains, and both parties, or representatives of the domains, should give their assent to them if at all possible (University of Strathclyde Glasgow 2009).
It also highlights that the VMF tool is not designed for human use:
The matrix is a tool for computer, not human, use. It is a mapping tool, not a cataloguing tool or a public vocabulary. It is a very large network of terms whose job is to provide paths by which other terms may be connected: it is therefore not necessary for it to be generally accessible or ‘user-friendly’ to users of metadata in general. It is also not a dictionary of the public meanings of words, or an attempt to provide definitive meanings for particular words. In the VMF matrix each term has one precise meaning, and so each word can be a label for only one VMF concept, whereas in the world at large the same name may be associated with a range of diverse or related meanings, as is reflected in the various controlled vocabularies being mapped to VMF. Names are invaluable clues to the meaning of a term, but the unique meaning of a term is built up, and therefore recognised, by its definition and the accumulation of logical relationships in the ontology. Because VMF must represent the sum of its parts, it also becomes necessary for term names in VMF (which have to be unique) to be more precise, and therefore less user-friendly, than in a smaller scheme (University of Strathclyde Glasgow 2009).
We think that this type of infrastructure is indicative of the type of commensurability creation load that the COAX system will require. That is, it appears to be moving in directions similar to the CGML approach, where the focus is on mapping the elements of published standards, but in the case of COAX it includes relators which can be expressed within the RDF framework and that as a result the notion of authority for cross-mappings will become an important consideration.
If the CGML system were to become a standard, in the way that the COAX system aspires to, it would be necessary to establish a governance infrastructure for such an approach. Institutionally, there is backing for the COAX approach through the International DOI Foundation. It has been a participant in and supporter of the < indecs > project and this vocabulary mapping framework.
Ontology-based interlanguage infrastructure
The infrastructure requirements associated with the XML to ontology to XML transformation architectures such as OntoMerge system will need to be consistent with the design principles of the semantic web. In order that functional outcomes are achieved, such requirements include the creation and publishing of, and access to, libraries of standard and merged ontologies: ‘Ontology mappings will need to be published on the semantic web just as ontologies themselves are’ (Bernstein and McDermott 2005, p. 1).
As we have also highlighted, the merged ontologies will need to reflect the underlying ontological structure of OntoMerge with its focus on semantic mappings of predicates and the formulation of bridging axioms and meaning definition axioms using these predicates. We think that the commensurability creation load of CGML will be less than for OntoMerge. This is because with CGML only the nouns are mapped from source and destination XML standards to the CGML interlanguage. In principle, once there are sufficient XML standards mapped into CGML, then possibilities associated with XML schema to XML schema translations could occur. In contrast, with OntoMerge the mapping and merging of ontologies involves the formulation of bridging axioms between the source and destination standard ontologies as well as the MDAs between the surface ontologies and the standard ontologies. On the other hand, OntoMerge does not require the mapping of triples and the creation and management of a large data dictionary as required by COAX. Therefore the commensurability creation load in OntoMerge should be much less than we find in COAX.
System provisions for the use of human interpretive intelligence for creating commensurability
Overlapping XML standards will all be ‘rich’ in their own distinctive ways. Some will be slightly different and some will be very different from each other, each for their own reasons. Because of this, judgements about semantic and syntactic subtleties of meaning will be required in order to revise and reformulate the interlanguages in all three systems. This means that human interpretive intelligence will, in principle, be necessary to enact the transformation of content from one storage system to another. So, a very important criterion for comparing transformation/translation architectures in general, and our three illustrative systems, in particular, is the provisions they make for incorporating the human interpretive intelligence needed for creating commensurability.
As we have seen, all three systems considered in this chapter incorporate human intelligence in the course of developing the various interlanguages. In the cases of CGML and COAX, human interpretive intelligence is incorporated when mapping rules are undertaken between the elements in different XML standards and the CGML or COAX interlanguages respectively. This principle could be extended beyond XML standards to XML schemas as well.
In the case of OntoMerge, human interpretive intelligence is central to the process of creating meaning definition axioms and bridging axioms. Therefore, even though the three systems are alike in that they all incorporate human interpretive intelligence in the creation of each transformation system, we have already seen that they are not alike in the ways in which their respective transformation mechanisms work. In order to create a transformation architecture that is capable of handling the problem of incommensurability, there is a need to make a technical design choice about how to execute the semantic mappings and rules between the source and destination schemas. The ontological assumptions of the three different systems differ. The CGML system uses noun-to-noun mapping rules to relate the underlying digital elements of content. In contrast, the COAX system uses verbs and the linkages between digital elements that are generated when verbs are used (we have described these as ‘verb triples’). Finally, OntoMerge also uses nouns, but these act as noun-predicates and thus the noun-to-noun mapping rules in OntoMerge are fundamentally different from CGML.
Facilities for the use of human interpretive intelligence in content translations
Facilities for human interpretive intelligence in COAX
The COAX system is not designed to facilitate human input. However, Rightscom admitted the problems associated with aspiring to a fully automated translation system by highlighting that the COAX system should (but by implication does not) facilitate what we perceive to be a type of human intervention:
there is a strong argument for establishing an (optional) human interface for the management of default assumptions, or the making of ad hoc choices in specific cases. In principle, it is bad practice for defaults to be applied ‘blindly’: at the very least the user should be aware of the assumptions that have been applied. Each user may have different preferences, in accordance with their own practices, and so the provision of ‘configurable’ defaults and choices would support transparency and respects genuine variation in practice (Rightscom 2006, pp. 31–32).
We agree with everything in this quotation, except the word ‘optional’. Note that this word has been placed in parentheses. The reasons for this are not clear.
To take this argument further, consider the right-hand side of Figure 14.3. If one circle is ‘dog’ and the other is ‘cat’ then a moment’s thought reveals that a number of triples could emerge (the line connecting the circles). The cat can ‘look at’, or indeed ‘spit at’, a dog. But will a cat ‘purr in the presence of’ a dog? In some cases, this might in fact happen, but it will depend on context. We would expect difficulties like these to arise repeatedly. We suggest, therefore, that it will be a much more difficult task to describe all the triples in the COAX system than it will be to create data dictionary entries for the CGML system. We believe that this complexity is likely to be so great that, in the final analysis, the COAX system will need to rely on a mechanism whereby somebody defines allowable triples and then mandates their use in a standard.
Not surprisingly, something like this approach has already been proposed as part of the COAX system. It was the < indecs > metadata framework and the focus on rights and permissions associated with intellectual property management that has given rise to the notion of ‘assertion’: ‘Assertions are the mechanisms in the < indecs > framework by which authority is established’ (Rust and Bride 2000, p. 35). Rust makes this point clear: ‘all triples are “asserted” by at least one authority’ (2005, slide 13). Such a process of ‘assertion’ becomes a means by which standards are established.
It might be no accident that the authors of the COAX system think that triples will need to be ‘asserted’. We think that defining triples will often—not always, but often—be difficult, and may require a great deal of human knowledge and judgement. Some human—indeed a whole team of humans—will, we think, probably need to manage the triple definition process. This essentially has become the role of the Motion Pictures Experts Group (MPEG-21) Rights Data Dictionary Registration (RDD) Authority (http://www.iso21000-6.net/). MPEG-21 is an open framework for multimedia delivery and consumption, developed under the joint standards framework of the International Standards Organisation (ISO) and International Electro-technical Commission (IEC) Joint Technical Committee. Two components of the MPEG-21 standards, a Rights Expression Language—REL—(ISO/IEC 21000-5) and Rights Data Dictionary (ISO/IEC 21000-6), provide the means for users to express rules about access and use of multimedia content. The REL provides the syntax and the RDD provides the semantics for the terms used in the REL. A methodology and structure for the (Rights Data) Dictionary is also standardised, along with the method by which further terms can be added to the dictionary through a registration authority. The methodology is based on a contextual ontology architecture, and was developed from earlier work on < indecs > (ISO/IEC 21000-6 Registration Authority 2007).
The World Intellectual Property Organisation has highlighted the importance of a rights expression language in the following way:
A rights expression language requires extremely precise terms (semantics) in order to create precise, unambiguous expressions. However, it has long been recognized that natural language and computer language are two different things. The language of the everyday is far from precise in computer terms and society is built on the notion that the interpretation of the nuance of language is essential. For instance, all law is framed on the basis that it cannot be so precise as to exclude interpretation. Computers, on the other hand, cannot deal with imprecision. Given an ambiguous expression, computers will either fail to work or will function in an unpredictable manner. For this reason, it is necessary to create a set of terms (words) specifically for use in a rights expression language (WIPO 2003, p. 1).
We conclude from this that assertions result in the pre-specification of relationships between entities (as reflected in the lines in Figure 14.3). This pre-specification results in some user actions being allowable and others not, based on the notion of authority. This is the very basis of a licensing agreement itself. But we claim that the mechanism used to achieve this result (the use of verb triples) has an unintended consequence of imposing a constraining effect on the entire system. This flies in the face of one of the guiding principles of the internet itself—the principle of minimal constraint. Berners-Lee highlighted the principle of minimal constraint:
as few things should be specified as possible (minimal constraint) and those specifications which had to be made should be made independent (modularity and information hiding). The independence of specifications would allow parts of the design to be replaced while preserving the basic architecture (1996).
Within this broad context, we believe that however important rights management issues are, they should not be allowed to dominate the interoperability agenda. In particular, a consequence of this view is that it will prove highly problematic to create a global interoperability architecture that is fully automated; we believe that any transformation system must build within it a provision to apply human interpretive intelligence, a point we will expand on below.
Rightscom has completed a project in which its transformation system has been piloted via real case studies. The published paper arising from this pilot project (Rightscom 2006) identifies a number of difficulties which the COAX system faces. The report is written in such a way that it appears that the authors are surprised by the difficulties they report. Indeed, they appear to believe that once teething problems are sorted out, all these difficulties will be eliminated. Rightscom found challenges associated with semantic incommensurability:
Transformation can only preserve semantics: it cannot add semantic content which is not there to begin with. Where the semantics of two standards are incompatible with, or orthogonal to, one another, no transformation methodology can bridge the gap, and meaning will be ‘lost’ in transformation because it has nowhere to go (2006, p. 28).
The point here is that no automatic transformation methodology can bridge the gap because no wholly rules-based approach can formulate new rules. It takes ‘human interpretive intelligence’, or human creativity, to come up with new solutions to transformation problems, or, more generally, to come up with new theories of transformation that create commensurability.
Rightscom (2006, p. 31) also finds challenges associated with semantic ambiguity:
Example 1: Dublin Core differentiates creator and contributor according to the importance of the role, whereas ONIX differentiates by the type of the creative role (for example, Author and EditedBy), so there is a semantic mismatch in mapping from ONIX to DC (though not vice versa).
Example 2: To know whether an ONIX contributor is a Person or an Organisation, it is necessary to look first at the PersonalName and OrganisationName fields to see which one is populated. In this particular example, Rightscom reports that conditional rules are required in some instances to determine the semantics of particular fields to ensure transformations are achieved. In such circumstances, relators are not resulting in an unambiguous expression of meaning; rather it is the conditional rules applied to determine the semantics of the particular fields.
Rightscom also highlights challenges which appear to us to be the same as semantic delicacy in the CGML system. The COAX system does not always handle the breaking down of different fields and managing the relationships between the hierarchies of these fields:
ONIX (like COA) separates out the quantity, the unit of measure and the type, so (for example) ‘Height 25 cms’ goes in three fields in ONIX (and COA) but only one (or sometimes two) in MARC and DC. Clearly, in one direction this is fine: accurate outputs for MARC and DC can be generated by producing a concatenated field from ONIX data within COAX. From the other end it is less straightforward, but where consistent practice is employed in MARC, it is possible to analyse ‘Height 25 cms’ into controlled value COAX fields. Comparable approaches can be taken for manipulating elements such as date/time variations, personal names and certain identifiers, with the likelihood of a high level of accuracy in results (2006, pp. 30–31).
In the COAX system, triples contain the semantic and syntactic information that is required for content transformation. It is clear that the use of triples was designed by the originators of the COAX system to store this kind of information, and so to automate content transformations as completely as possible. It is also clear that the use of triples is necessary to automate content transformations in COAX. Indeed, it is clear that triples will, in many cases, embody the kinds of information which would be stored in the four filters in the CGML system. As but one example, Rightscom (2006, pp. 54–55) stated:
A COA ontology is built by creating hierarchies of specialized classes of Entity in the form of SubClasses or SubRelators to the Primary EntityTypes. For example:
This set of triples embodies the kinds of information contained within the super-ordination filter within the CGML system. As Cope and Kalantzis stated in Chapter 13, ‘Creating an interlanguage of the social web’:
Superordination relations perform the function of sub-classification. They express an ‘is a’ relationship between one level in the taxonomic hierarchy and another. < Book > is a < Product >, as is an < AudioRecording > .
If the COAX system meets the ambitions of its designers, then it does not matter how easy or how difficult it is to apply human interpretive intelligence. This is because—by assuming success in achieving complete automation in translation—such requirements will not be necessary. It is our judgement that some form of human intervention will be necessary to accomplish the continuous evolution of COAX. Further, currently, as we’ll see below, COAX doesn’t have the capability to receive and respond to the continuous human calibration that would allow it to change to move closer to a true transformation system.
In the face of this probable need for applying human interpretive intelligence in COAX we now point to a fundamental difficulty in applying it in the COAX system. In the COAX system, the means by which semantic and syntactic interpretation occurs will be via a two staged process. First the user will need to choose an appropriate triple that contains the subtleties of the semantic and syntactic information to support transformation. And second, the appropriate XSLT transformation mechanism will need to be applied to enact the transformation. We think that such a mechanism is likely to result in user resistance for the same reason that we have discussed previously—the notion of intangible knowledge. When choosing an appropriate triple, users will have to draw parallels between their accrued experiences of the domain in question and the triples that contain the semantic and syntactical subtleties associated with the users’ interpretations of their experiences. But, triples used within the COAX system are not designed for human readability. Rightscom itself has highlighted this point:
The COAX XML schema is built on this model, which allows for any semantic relationship at any level of granularity to be represented. The result is much more verbose than a typical metadata record, but as the purpose is for storing data for interoperability, and not human readability, this is not a problem (2006, p. 26).
Since, by its account, COAX triples are not designed to be readable by people, but only by machines, we believe that this system will face serious user resistance, and also won’t be able to continuously incorporate the human interpretive intelligence needed to revise, maintain and recreate the merged ontology necessary for continuous successful translation of XML standards (and, by implication, XML schemas as well).
Facilities for human interpretive intelligence in OntoMerge
The OntoMerge system aims to maximise automation of ontology and content translations as much as possible. We choose the word maximise carefully because Dou, McDermott and Qui emphasise the importance of human interpretive intelligence: ‘Devising and maintaining a merged ontology must involve the contribution from human experts, both domain experts and “knowledge engineers”. Once the merged ontology is obtained, ontology translation can proceed without further human intervention’ (2004a, p. 2).
Equally, Dou et al. highlight that OntoEngine provides a mechanism for automated translations through its automated reasoning function: ‘We call our new approach ontology translation by ontology merging and automated reasoning. Our focus is on formal inference from facts expressed in one ontology to facts expressed in another’ (Dou, McDermott and Qui 2004a, p. 2).
The overall objective of this approach is to provide automated solutions in the translation of datasets and queries: ‘If all ontologies, datasets and queries can be expressed in terms of the same internal representation, semantic translation can be implemented by automatic reasoning’ (Dou, McDermott and Qui 2004a, p. 16).
This automated reasoning function of the OntoMerge system architecture makes it fundamentally different from CGML and COAX. At base level, it is the reliance on bridging and meaning definition axioms, as predicate to predicate mappings, that forms the basis of the functionality of OntoEngine. This is because predicates are an important part of the OntoEngine indexing structure that allows it to find formulas to be used in inference (Dou, McDermott and Qui 2004b, p. 8).
Given the automated reasoning functions of OntoEngine, and the heavy reliance on these, we think there is little provision to integrate the use of human interpretive intelligence during the content translation querying process. However, we also conclude that there would appear to be little perceived benefit in this for the developers of OntoEngine because it would be contrary to the ambitions of the developers of OntoMerge. We have previously highlighted their overall objective of processing the content of information and maximising possibilities associated with automation.
It would be a mistake to conclude from this, however, that OntoMerge is an example of a system or architecture that does not result in the falsification of the underlying translation theory that makes up the architecture. The OntoMerge system does rely on the continuous merging of new ontologies and datasets to create a broader ontological framework. The ontology merging process in principle provides a means of falsifying and continuously expanding the underlying ontology and results in new solutions to the content translation problem as outlined in this chapter.
A question therefore arises from this. How easy is it for human interpretive intelligence to be incorporated into attempts made to automate the formulation of meaning definition and bridging axioms on which the OntoMerge system relies? Dou et al. address this question in the following way: ‘We designed a semi-automatic tool which can help generate the bridging axioms to merge ontologies. It provides a natural-language interface for domain experts who are usually not good at logic formalism to construct and edit the axioms’ (Dou, McDermott and Qui 2004b, p. 17).
The reliance on a natural language interface to support the integration of human interpretive intelligence into the OntoMerge system exposes two key differences of approach as compared to CGML. First, the creation of bridging (and meaning definition) axioms requires that the domain experts understand that they are mapping noun-predicates to noun-predicates as compared to nouns (or abstract nouns) to nouns or abstract nouns). Second, the underlying Web-PPDL language used by OntoMerge is difficult for lay users to understand—thus the primary reason for developing a natural language interface.
The integration of human interpretive intelligence into the OntoMerge architecture will result in the need for domain experts to understand something about the principles of semantic web ontologies. We think this problem will become compounded by the need to generate a distributed library of semantic web and merged ontologies to support OntoMerge. We note that, in contrast, XML standards are already being negotiated, published and used by industry practitioners—even though more needs to be done to provide protocols for how such standards should be published.
Facilities for human interpretive intelligence in CGML
The difficulties in the use of human interpretive intelligence found in COAX and to a lesser extent in OntoMerge are largely dealt with in the CGML system. All CGML terms are defined drawing on the social languages of practitioners—because the CGML interlanguage terms are defined on the basis of their relatedness to digital elements of XML standards. The CGML filters—delicacy, synonymy, contiguity and subset—exist to expose areas of incommensurability that arise during XML content translations. When the filters expose areas of incommensurability, users are prompted via structured user queries to make choices and to take action. In other words they apply human interpretive intelligence during the content translation process.
With the application of such actions slight distinctions of semantic and syntactic differences between the tags within each XML standards become codified. If the ‘digital tracks’ of each transformation are archived, we have noted in the CGML system that the ‘filters’ can be ‘trained’ to respond appropriately to these differences. In this way, there will be a movement towards more successful automation, because human creativity is constantly being used to revise and improve the merged ontology underlying the translation system. However, such automation can only develop from the accumulation of digital tracks that develop from actions arising from human interpretation and choice. Over time, well-trained filters could, in principle, come much closer to automating the content transformation process.
Automation, in other words, will never be complete. Some human intervention in the form of semantic and syntactical interpretation will always be necessary. This follows from the idea that interlanguage is a theory about translation, and therefore is fallible and sooner or later will encounter a translation problem that is likely to falsify it. But since mediated actions revising such theories are part of the design of the CGML system itself, such design features allow many interpretive choices to be taken by users rather than programmers, and for the continuous revision of the transformation/translation theory that is at the heart of CGML.
We think that the need to apply human interpretive intelligence is also supported by another very important aspect of developing and revising theories of translation. This relates to the application of the user’s intangible knowledge. In making choices associated with the subtleties of the semantic and syntactic distinctions when content transformation takes place via human intervention, users must and will draw on their own experiences and subject matter expertise associated with the domain of practice (the industry that the XML standard relates to). In this way, the personal knowledge of users themselves is available to support the ‘intelligence’ of the CGML transformation system, and to incorporate the capability of the users to revise, extend and recreate merged ontologies.
Conclusions on facilities for using human interpretive intelligence
Of the three illustrative systems, CGML provides a facility for using human interpretive intelligence, in principle, in both the ontology merging and the content translation processes. These processes can be supported through the use of a friendly interface so that users can be queried in order to resolve semantic ambiguities that arise in constructing transformation rules or executing translations.
In COAX the content translation is fully automated, but human interpretive intelligence is used in creating mapping rules using triples. Up until now, it appears that the process of creating these rules involves the need to be able to understand the meaning of triples. However, COAX triples are not easily read and understood by humans. This effectively constrains those involved in the COAX mapping rules to technical personnel.
In OntoMerge, like COAX, content translation is fully automated and provides no opportunity for human intervention. However, formulating bridging axioms and MDAs employs human interpretive intelligence in the form of domain experts whose participation is facilitated by an axiom generating tool. This tool provides a natural language interface that ensures users do not have to learn the underlying Web-PPDL software language.
Addressing the translation problem: emergent possibilities
We think that the evolution of information architectures required to generate solutions to the problem of translatability or interoperability of different XML languages, as outlined in this chapter, depends on how different approaches deal with the need to apply human interpretive intelligence where it is needed. In our view, a number of different outcomes might emerge; we think it will prove impossible to predict what architectures are likely to prevail. However, we discuss some of the possibilities in turn below.
Possibility 1 No choice—a patch and mend architecture prevails
A patch and mend (or rule based tag-to-tag) outcome is likely to evolve if no systematic effort is made to address the key challenges to achieving translation of humanly usable content addressed in this chapter. This outcome will depend on the kinds of unsystematic and localised approaches to interoperability we have discussed earlier. But, as we have suggested, such localised solutions risk producing outcomes in which the infrastructure required to support the exchange of digital content and knowledge remains a hopeless jumble of disconnected fixes. The reason for exploring more systematic approaches is a pragmatic one. The costs of reconfiguring content to a sustainable data structure are substantial. A global architecture to support translation and interoperability objectives would help to address the challenge of ‘content sustainability’ and to avoid the cost of reconfigurations required to keep content accessible and usable.
Possibility 2 Choice to maximise the automation of translations
A choice to pursue the use of system architectures that aim to minimise the need for human intervention and thereby maximise the potential for automation is likely to prove attractive, for obvious reasons. Within this choice, we see three potential scenarios unfolding.
Scenario 1
Scenario 1 is to find a technical solution to the translation and interoperability challenge. A system architecture that successfully solves the translation and interoperability problem will emerge if such problems can be addressed for one, or for a number of particular industries or related academic disciplines. This would give such a system(s) a critical mass from which further advances could be built. This would especially be the case if this type of functionality would suit a certain group of stakeholders. In the case of COAX, for example, those players that have control over aggregated quantities of copyrighted content in the digital media industries, such as publishing and motion pictures, would likely benefit from the successful implementation of COAX. This solution could also benefit a wide range of end users of content as well, on the basis that access to such content could be delivered online. End users such as university students might be able to access customised content such as book chapters on demand. Or current consumers of motion picture products would benefit from increased online access to copyright content, thereby by-passing current distribution retail channels. Owners of copyright content could leverage and protect the value of their content. Everyone would win. But, for reasons outlined above, we believe that the introduction of such solutions is likely to be met with resistance by the users of the systems, because of the constraining impact on the system. We suggest that as a result of this two different scenarios could unfold.
Scenario 2
In Scenario 2, in the end, the systems do not work. It is possible that a significant amount of resources are allocated to the development and roll out of system architectures of the COAX or OntoMerge type. OntoMerge, for example, forms part of the network structure of the semantic web initiative (an initiative that has already consumed vast resources). But, the more resources are expanded, it might well be that there is a continuing need to justify the expenditure of such resources. An historical example of this type of waste already exists—namely the EDIFACT story. In the mid 1980s work was undertaken in a UN-sponsored initiative called EDIFACT (David and Foray 1994). The objective of EDIFACT was to create a global standard to support computer-to-computer exchange of business documents. Now, 20 years later, these aspirations have not been achieved and a paperless trading system, operating by means of computer-to-computer exchanges—which EDIFACT was meant to help set up—has not been realised. EDIFACT is widely regarded as having been a failure. We are grateful to Paul David for helpful insights associated with the material in this section.
What emerged during the period in which EDIFACT was championed was the rise of a plethora of different local standards. Traders used file transfer protocols (FTPs) for specialised documents transmitted, for example, between marine insurers and customs brokers and their clients. Initially, this was conceived as an overlay on the telex and telephone communications messages, but such transfers eventually replaced the use of these technologies. The document formats substituted for and enriched the key bits of data that were conveyed using previous technologies. The striking of deals, and the enforcing of them, would have been much more difficult without such localised standards with which to specify what information was needed to support a deal, and in what way.
EDIFACT aspired to create much more of a system than this. But it turned out to be impossible for EDIFACT to play a role in supporting business exchanges, for two reasons which are of relevance to this chapter.
First, as already noted, standards which enable computer-to-computer exchange of important business information need to be developed in ways that reflect highly localised requirements of specialists. EDIFACT tried to create a universal document that could describe all the possible variations of transactions. But it turned out that the EDIFACT system took too long to develop and became too cumbersome. As a result such efforts were evaded by the use of highly localised standards, which reduced the costs of transactions that were already occurring without support of electronic networks, but which did not make use of proposed universal approaches.
Second, computer-to-computer interoperability of content and information usually becomes entangled with exchanges between the actual human beings who are operating the computers themselves. EDIFACT was conceived in ways that did not make it sufficiently flexible for this to be possible. David and Foray summarise the implications of this failure:
According to our assessment of the European situation, the main mission of EDIFACT should not be that of displacing the local standards, but rather one of assisting their absorption within a unified framework. Increasing the flexibility of the language and tolerating a sacrifice of aspirations to rigorous universality may therefore prove to be the most effective long-run strategy. However, due to the persisting ambiguity that surrounds the goals of those charged with developing the standard, EDIFACT policy continues to oscillate between conflicting design criteria. This situation, in and of itself, should be seen to be working against the formation of greater momentum for EDIFACT’s adoption and the diffusion of EDI (1994, p. 138).
We see a very real possibility that an attempt to create a global translation and interoperability agenda, based on either the system like the COAX or the OntoMerge type system, might end up with an outcome of this kind.
Scenario 3
In Scenario 3, ongoing resource allocations are made to gain a minimum level of functionality. If the resistance of users was not sufficient to cause the system to become dysfunctional, an alternative outcome might develop. This could involve the continuous investment of resources in system architecture to gain a minimum level of functionality, to the extent that this prevented other, more suitable, architectures from being established. The result might be a lock-in to an inappropriate system. This is like the outcome in video recording software where the poorer tape-recording system prevailed (the VHS tape-system rather than the BETAMAX tape-system). There is a famous historical example of this lock-in story—namely the story of the QWERTY keyboard. This keyboard was designed for good reasons—very common letters were separated on the keyboard, in order to prevent the jammed keys which were likely to arise, in a manual keyboard, if keys next to each other were frequently pressed one after the other. In 1935 the Dvorak Simplified Keyboard (DSK) became available and was a superior standard for keyboard design, leading to potential significant productivity improvements. David summarises what can happen in these cases as follows:
Despite the presence of the sort of externalities that standard static analysis tells us would interfere with the achievement of the socially optimal degree of system compatibility, competition in the absence of perfect futures markets drove the industry prematurely into de facto standardization on the wrong system—and that is where decentralized decision-making subsequently has sufficed to hold it. Outcomes of this kind are not so exotic (1986, p. 14).
In the cases discussed in this chapter, where there is already a COAX or OntoMerge type architecture available, we argue that a similar story to the QWERTY one is a possible outcome. Suppose that a CGML type system has the potential to provide a better overall architecture. But such a system might not emerge unless enough users see the benefit of adopting it. However, this will not happen if translation or interoperability needs are already being met, more or less, by ongoing resource allocations to achieve minimum functionality requirements of competing type systems.
It is interesting to note that the COAX and OntoMerge systems are structured in ways that, in principle, form part of an approach to global interoperability infrastructure embedded within the semantic web vision. The semantic web vision is a significant one and already there are powerful networking effects arising from this global agenda. These network effects might provide a powerful rationale to persuade agents to adopt this approach. And they might do this, even if other approaches like the CGML system were superior. This type of constraining effects on standards setting has been described by David. His conclusion on the policy implications is as follows:
If there is one generic course that public policy should pursue in such situations, it would be to counter-act the ‘excess momentum’ of bandwagon movements in network product and service markets that can prematurely commit the future inextricably to a particular technical standard, before enough information has been obtained about the likely technological or organisational and legal implications of an early, precedent setting decision (2007b, p. 20).
Possibility 3 Embed human interpretive intelligence
A third possibility that could evolve is a system which systematically embeds the principle of human interpretive intelligence, such as the CGML system described in this chapter. The CGML transformation system architecture (for example) has the potential to evolve and develop because of its flexibility. This flexibility is derived from the fact that the system specifically contains within it a provision to facilitate the application of human interpretive intelligence during the content translation process via structured queries. We have argued that the ability to do this easily is linked to the technical design choice of focusing on nouns (in the case of CGML) versus verbs (in the case of COAX) and nouns as predicates (in the case of OntoMerge). User responses to structured queries become part of the accumulated ‘recordings’ of semantic translations. These responses might be built up into a ‘bank’ of previous translations. The results stored in this bank might then be used to refine the operation of the filters, which we have discussed previously, so that, as the transformation process is repeated, fewer and fewer structured queries are thrown up for the user to respond to. Thus, the more the system is used, the more automated the CGML system might become. This transformation system is premised on the principle of minimal constraint precisely because it aims to facilitate human intervention where necessary, but at the same time to do this in a way which might limit such intervention. And the flexibility of the design of the system is such that it also has the potential to be used as a universal application across multiple industries. This is because it would enable the absorption of the kinds of localised schemas within a unified framework.
There is, however, a significant challenge associated with the CGML system itself, or any other system that systematically takes into account the principle of human interpretive intelligence, which is that, at the current time, there are limited network externality effects available that would result in a widespread adoption of such an approach. Therefore, if such an approach to the problem of XML translation is to become widely adopted, the underlying theory of translation must not only withstand critical evaluation but also become a practical solution to the challenges of XML language translation and interoperability at both local and global levels.
In the case of Finland, for example, there are already efforts being made to respond to national cultural heritage challenges through the development of national semantic web content infrastructure. The elements of this infrastructure include shared and open metadata schemas, core ontologies and public ontology services:
In our view, a cross-domain semantic cultural heritage portal should be built on three pillars. First we need a cross-domain content infrastructure of ontologies, metadata standards and related services that is developed and maintained on a global level through collaborative local efforts. Second, the process of producing ontologically harmonised metadata should be organised in a collaborative fashion, where distributed content producers create semantically correct annotations cost-efficiently through centralised services. Third, the contents should be made available to human end users and machines thought intelligent search, browsing and visualisation techniques. For machines, easy to use mash-up APIs and web services should be available. In this way, the collaboratively aggregated, semantically enriched knowledge base can be exposed and reused easily as services in other portals and applications in the same vein as Google Ads or Maps (Hyvönen et al. 2009).
This type of emergent semantic web infrastructure provides an example of what the future holds, if the challenge of interoperability and the exchange of humanly usable digital content are to be advanced in practical and useful ways.
However, we conclude that the new types of conceptualising sensibilities advocated by Cope and Kalantzis in this book are complex, and that significant consideration of these theoretical matters is required before the possibility of over investment in any one type of architecture occurs. We have demonstrated how different choices about aspects of infrastructure design will (and already are) unlock the emergence of new forms of complexity, particularly in the relationship between tacit and more explicit expressions of knowledge. We have concluded that the application of human interpretive intelligence must become an essential feature of any translation system, because explicit knowledge can only be accessed and applied through tacit processes. Thus, we claim that it will not be possible to dispense with human intervention in the translation of digital content. An infrastructure that fails to acknowledge this, and to make suitable provision for it, will be dysfunctional compared with one that does.
Conclusions
This chapter has discussed how to achieve interoperability in the transformation of XML-based digital content from one XML language to another. It is our view that it will prove impossible to create a transformation system that is fully automated. Any transformation system—we believe—must build within it a provision to apply human interpretive intelligence.
We have also highlighted that it will also be necessary to make a technical design choice about the means by which the translation process between different XML languages is achieved. In making such a claim, we have examined three transformation systems that have three entirely different ontological approaches to address the same translation problem: the Common Ground Markup Language (the CGML system), Contextual Ontology_X Architecture (the COAX system) and the OntoMerge system.
The important feature of the CGML system is that it specifically contains within it a provision to facilitate the use of human interpretive intelligence during the translation process by using structured queries and action response mechanisms. We have identified that the categories used in CGML make use of published XML standards used by the relevant user communities, and have shown that elements of the CGML interlanguage apparatus are derived from these standards. This is important because different users generate different ways of organising content which reflect localised and specific activities. We have shown how this system ensures that users can draw on their own particular knowledge. In this way, choices associated with the subtleties of the semantic and syntactic distinctions, which happen when content transformation takes place via human intervention, can enable users to draw on their own experiences.
In contrast, we have shown how the COAX system relies on the use of triples to contain the semantic and syntactic information required for content transformation. But, because we conclude that human intervention is required, we have considered how difficult this process will be to implement within the COAX system. We conclude that because triples are used and because triples are not designed to be readable by people—only by machines—the COAX system rules will not easily be applied to support mechanisms for the application of human interpretive intelligence. We therefore argue that the system will become more constraining, which is likely to result in user resistance.
We have also highlighted that in the OntoMerge system, a situation exists somewhere between the CGML and COAX systems. That is, like COAX, content translation aims to be fully automatic and provides no opportunity for human intervention. However, in constructing bridging axioms and MDAs that are required for automated content translations, human interpretive intelligence is employed in the use of domain experts whose participation is facilitated by an axiom generating tool that provides a natural language interface for use by human domain experts.
We have suggested that the primary criterion for comparing alternative translation/transformation systems for XML standards and schemas is the ease of formulating expanded frameworks and revised theories of translation that create commensurability between source and destination XML content and the merged ontologies. We have discussed this criterion using three sub-criteria: the relative commensurability creation load in using each system, the system design to integrate the use of human interpretive intelligence, and facilities for the use of human interpretive intelligence in content translations.
We believe that the two claims of this chapter—about the need for human intervention and about the need to make a technical design choice about the way in which content is translated—have important implications for the development of any global interoperability architecture. The means by which we have developed our argument—by comparing three systems—should not be understood as advancing the interests of one over another. We do note that both the COAX and OntoMerge systems are conceived in ways that are congruent with the design features of the semantic web initiative. We suggest this might give these approaches certain advantages arising from the externality effects that arise as a result of this. But in advancing our central claims, we wish to caution against premature standardisation on any particular system, before all potential systems have been properly compared. Such standardisation might lead to premature lock-in to inappropriate global interoperability architecture.
Our comparison of the three systems has suggested that there are essentially three outcomes possible depending on the choices made. The first outcome is that no choice is made at all about the inter-related question of human intervention and ontology. We have suggested that the actions that arise from such a choice will lead to a patch and mend architecture, one that will develop from unsystematic and localised approaches to interoperability. But, we believe that searches for more systematic approaches will prevail for pragmatic reasons, primarily because the costs of reconfiguring content in all sorts of different ways will eventually prove to be too great. We therefore suggest that a global architecture to support interoperability objectives is likely to become increasingly desirable. This is partly because of the need to address the challenge of ‘content sustainability’ and avoid the cost of reconfigurations required to keep content accessible and usable.
The second outcome is a choice for working towards the benefits of automated translation systems as much as possible. In the case of the COAX system this draws on the use of triples; in the case of OntoMerge it draws on the use of predicates (which might in their own right be defined as nouns). With this second choice, we suggest three scenarios could develop. The first is that the use of triples and or predicates could result in a workable system, with widespread benefits. But we have highlighted why both the COAX and OntoMerge solutions are likely to be constraining and why they might be met by resistance from users. A second scenario is that many resources could be allocated to the development and roll out of the COAX and OntoMerge type architectures, but that such resources could be wasted—primarily because, in the end, the systems prove to be dysfunctional. We have discussed a historical example of this happening—the EDIFACT story. The third scenario is that the resistance of users might not be sufficient to cause the system to become dysfunctional. Combined with the network externality effects of the COAX and OntoMerge systems being part of the International DOI Foundation and semantic web infrastructure, this might result in agents being persuaded to adopt a less than effective system, even if it is less desirable than a CGML-like system.
The third outcome is for something like the CGML system architecture to emerge. We have shown that this architecture has potential—because it offers a generalised solution which, at the same time, would allow particularised solutions to emerge, giving it some flexibility. We have highlighted how this flexibility is derived from the fact that the CGML system specifically contains within it a provision to facilitate human interpretive intelligence during the content translation process via structured queries and action responses.
Finally we note that our findings should not be interpreted as a ‘product endorsement’ of the CGML system. The CGML system, like the COAX and OntoMerge systems, is not, in its current form, an open standard. This is problematic, because if such a transformation system is to offer a solution to support global interoperability objectives, the CGML system will at the very least need to be positioned as a type of standard in ways similar to those in which the COAX system has become part of the International Organization for Standardization’s umbrella framework.
Our aim in this chapter has been to suggest that there is a need for further thought before systems like the COAX and OntoMerge systems are adopted as the basis for any global interpretability architecture. Paul David has drawn out the lessons to be learned about the risks of premature lock-in to inappropriate standards. He suggests that: ‘preserving open options for a longer period than impatient market agenda would wish is a major part of such general wisdom that history has to offer public policy makers’ (2007a, p. 137).
We suggest that here too it would be desirable to preserve an open option for some time to come.
Acknowledgements
We are very grateful to Denis Noble and David Vines (Oxford University), Paul David (Oxford and Stanford Universities), David Cleevely (Chairman: CFRS—UK), Yorick Wilks (University of Sheffield) and Keith van Rijsbergen (University of Glasgow) for their helpful comments on early drafts of this chapter.
References
Berners-Lee, T. The World Wide Web: Past, Present and Future. http://www.w3.org/People/Berners-Lee/1996/ppf.html. 1996.
Bernstein, M., McDermott, D., Ontology Translation for Interoperability Among Semantic Web Services. AI Magazine . 2005; 26(1). http://tinyurl.com/6ompvh [Spring, pp. 71–82].
David, P. Understanding the Economics of QWERTY, or Is History Necessary? In: Parker W.N., ed. Economic History and the Modern Economist. Oxford: Basil Blackwell, 1986.
David, P. Path Dependence, its Critics and the Quest for Historical Economics. In: Hodgson G.M., ed. The Evolution of Economic Institutions: A Critical Reader. Cheltenham: Edward Elgar, 2007.
David, P. Path Dependence—A Foundation Concept for Historical Social Science. http://tinyurl.com/3ylffnx. 2007. [SIEPR Discussion Paper No. 06–08. Stanford Institute for Economic Policy Research, Stanford University, California,].
David, P., Foray, D. Percolation Structures, Markov Random Fields and the Economics of EDI Standards Diffusion. In: Pogorel G., ed. Global Telecommunications Strategies and Technological Changes. Amsterdam: North-Holland, 1994.
Dou, D., McDermott, D., Qui, P. Ontology Translation on the Semantic Web. http://www.cs.yale.edu/~dvm/daml/ontomerge_odbase.pdf. 2004.
Dou, D. Ontology Translation by Ontology Merging and Automated Reasoning. http://cs-www.cs.yale.edu/homes/ddj/papers/DouEtal-MAS.pdf. 2004.
Firestone, J., McElroy, M. Key Issues in the New Knowledge Management. Burlington, MA: KMCI Press and Butterworth Heinemann; 2003.
Hyvönen, E., et al, CultureSampo–Finnish Culture on the Semantic Web 2.0: Thematic Perspectives for the End-user. Museums and the Web International Conference for Culture and Heritage On-line. 2009. http://tinyurl.com/38u4qqd
Info 2000. <indecs>: Putting Metadata to Rights, Summary Final Report. http://www.doi.org/topics/indecs/indecs_SummaryReport.pdf. 2000.
ISO/IEC 21000-6 Registration Authority website, http://www.iso21000-6.net/
Kuhn, T. The Structure of Scientific Revolutions, 2nd ed. Chicago, IL: University of Chicago Press; 1970.
MARC. Marc Standards: Library of Congress—Network Development and Marc Standards Office. http://www.loc.gov/marc/. 2006.
McLean, N., Lynch, C. Interoperability between Library Information Services and Learning Environments—Bridging the Gaps: A Joint White Paper on Behalf of the IMS Global Learning Consortium and the Coalition for Networked Information. http://www.imsglobal.org/digitalrepositories/CNIandIMS_2004.pdf. 2004.
MPEG-21 Rights Data Dictionary Registration Authority website, http://www.iso21000-6.net/.
ONIX. Onix for Books. http://www.editeur.org/onix.html. 2006.
Paskin, N. Identifier Interoperability: A Report on Two recent ISO Activities. http://www.dlib.org/dlib/april06/paskin/04paskin.html. 2006. [D-Lib Magazine, April].
Popper, K. Normal Science and its Dangers. In: Lakatos I., Musgrave A., eds. Criticism and the Growth of Knowledge. Cambridge, UK: Cambridge University Press, 1970.
Popper, K. Objective Knowledge: An Evolutionary Approach. London: Oxford University Press; 1972.
Qui, P., McDermott, D., Dou, D. Assigning Semantic Meanings to XML. http://cs-www.cs.yale.edu/homes/dvm/papers/xmlMeaning.pdf. 2004.
Rightscom. Testbed for Interoperability of Ebook Metadata: Final Report. http://tinyurl.com/2ap4yt7. 2006.
Rust, G., Thoughts from a Different Planet. presentation to the Functional Requirements for Bibliographic Recrods (FRBR) Workshop, Ohio. 2005. http://tinyurl.com/2tsa9m
Rust, G., Bride, M. The <indecs> Metadata Framework: Principles, Model and Data Dictionary. http://www.indecs.org/pdf/framework.pdf. 2000.
University of Melbourne. http://tinyurl.com/38wnybw. 2010 [Find an Expert website].
University of Strathclyde Glasgow. The Vocabulary Mapping Framework: An Introduction. http://tinyurl.com/2vkeblb. 2009.
Victorian Council of Social Services. The Interoperability Challenge: A Draft Discussion Paper by the Interoperability Working Group. http://tinyurl.com/8fhfhg. 2008.
Schools. Undated. ‘Introduction to DTD’, http://tinyurl.com/dlx5tz.
Wikipedia. XSL Transformations. http://en.wikipedia.org/wiki/XSLT. 2006.
World Intellectual Property Organisation. Current Developments in the Field of Digital Rights Management, Standing Committee on Copyright and Related Rights. http://tinyurl.com/2do6apu. 2003.
W3C. Undated. ‘W3C Semantic Web Activity’, World Wide Web Consortium, http://www.w3.org/2001/sw/.
W3C. XML Schema. http://www.w3.org/XML/Schema. 2000. [World Wide Web Consortium].
W3C. DAML + OIL (March 2001) Reference Description. http://tinyurl.com/2bomon4. 2001. [World Wide Web Consortium].
W3C. OWL Web Ontology Language Overview. http://tinyurl.com/jgyd2. 2004. [World Wide Web Consortium].
W3C. Resource Description Framework: Concepts and Abstract Syntax. http://www.w3.org/TR/rdf-concepts. 2004. [World Wide Web Consortium].
Undated a. ‘Drew V. McDermott’, http://cs-www.cs.yale.edu/homes/dvm/.
Yale University Computer Science Department. Undated b. ‘PDDAML: An Automatic Translator Between PDDL and DAML’, http://www.cs.yale.edu/homes/dvm/daml/pddl_daml_translator1.html.
Yale University Computer Science Department. Undated c. ‘OntoMerge: Ontology Translation by Merging Ontologies’, http://tinyurl.com/399u3pv.