
5
Instruction Scheduling After Register Allocation
This chapter presents a postpass instruction scheduling technique suitable for just-in-time (JIT) compilers targeted to VLIW processors. Its key features are reduced compilation time and memory requirements, satisfaction of scheduling constraints along all program paths and the ability to preserve existing prepass schedules, including software pipelines. This is achieved by combining two ideas: instruction scheduling similar to the dynamic scheduler of an out-of-order superscalar processor and the satisfaction of inter-block scheduling constraints by propagating them across the control-flow graph until a fixed point. We implemented this technique in a Common Language Infrastructure JIT compiler for the ST200 VLIW processors and the ARM processors.
5.1. Introduction
Just-in-time (JIT) compilation of programs distributed as Java or .NET Common Language Infrastructure (CLI) byte-codes is becoming increasingly relevant for consumer electronics applications. A typical case is a game installed and played by the end user on a Java-enabled mobile phone. In this case, the JIT compilation produces native code for the host processor of the system-on-chip.
However, systems-on-chip for consumer electronics also contain powerful media processors that could execute software installed by the end user. Media processing software is usually developed in C or C++ and it exposes instruction-level parallelism. Such media processing software can be compiled to CLI byte-codes due to the Microsoft Visual Studio .NET compilers or the gcc/st/cli compiler branch contributed by STMicroelectronics [COR 08]. This motivates JIT compilation for embedded processors like the Texas Instruments C6000 VLIW-DSP family and the STMicroelectronics ST200 VLIW-media family1.
In the setting of JIT compilation of Java programs, instruction scheduling is already expensive. For instance, the IBM Testarossa JIT team reported that combined prepass and postpass instruction scheduling costs up to 30% of the compilation time [TAN 06] for the IBM zSeries 990 and the POWER4 processors. To lower these costs, the IBM Testarossa JIT compiler relies on profiling to identify the program regions where instruction scheduling is enabled. In addition, the register allocator tracks its changes to the prepass instruction schedules in order to decide where postpass instruction scheduling might be useful.
In the case of JIT compilation of media processing applications for very long instruction word (VLIW) processors, more ambitious instruction scheduling techniques are required. First, software pipelining may be applied in spite of higher compilation costs, as these applications spend most of their time in inner loops where instruction-level parallelism is available. However, software pipelines implement cyclic schedules that may be destroyed when the code is postpass scheduled using an acyclic scheduler. Second, JIT instruction scheduling techniques should accommodate VLIW processors without interlocking hardware [MUC 04, ABR 98], such as the TI C6000 VLIW-DSP family or the STMicroelectronics ST210 / Lx [FAR 00]. This means that JIT compilation must ensure that no execution path presents scheduling hazards.
To address these issues specific to JIT compilation on VLIW processors, we propose a new postpass instruction scheduling whose main features are:
The presentation is as follows. In section 5.2, we review local instruction scheduling heuristics and propose Scoreboard Scheduling. We then describe an optimized implementation of this technique. In section 5.3, we discuss inter-region instruction scheduling and introduce inter-block scoreboard scheduling. This technique relies on iterative scheduling constraint propagation and we characterize its fixed points. In section 5.4, we provide an experimental evaluation of our contributions, which are implemented in the STMicroelectronics CLI-JIT compiler that targets the ST200 VLIW and the ARM processors.
5.2. Local instruction scheduling
5.2.1. Acyclic instruction scheduling
Acyclic instruction scheduling is the problem of ordering the execution of a set of operations on a target processor micro-architecture, so as to minimize the latest completion time. Executions of operations are partially ordered to ensure correct results. Precisely, effects on registers must be ordered in the following cases: read after write (RAW), write after read (WAR), and write after write (WAW). Other dependences arise from the partial ordering of memory accesses and from control-flow effects. We assume that the resource requirements of each operation are represented by a reservation table [RAU 96], where rows correspond to scheduled resources and columns correspond to time steps relative to the operation start date.
Classic instruction scheduling heuristics fall into two main categories [BAL 95]:
Cycle scheduling: scan time slots in non-decreasing order. For each time slot, order the dependence-ready operations in non-increasing priority and try to schedule each operation in turn, subject to resource availability. Dependence-ready means that execution of the operation predecessors has completed early enough to satisfy the dependences. This is Graham list scheduling.
Operation scheduling: consider each operation in non-increasing priority order. Schedule each operation at the earliest time slot where it is dependence-ready and its required resources are available. In order to prevent deadlock, the priority list order must be a topological type of the dependence graph.
Cycle Scheduling is a time-tested instruction scheduling heuristic that produces high-quality code on simple instruction pipelines, given a suitable priority of operations [MUC 04]. One such priority is the “critical path” length from any operation to the dependence graph sink node. A refinement is the “backward scheduling” priority that ensures optimal schedules on homogeneous pipelines [LEU 01] and on typed pipelines [DIN 07] for special classes of dependence graphs.
For the proofs of section 5.2.2, we assume monotonic reservation tables, that is reservation tables whose entries in any row are monotonically non-increasing.
Single-column reservation tables, which are virtually always found on modern VLIW processors, are obviously monotonic. Monotonicity enables leverage of classic results from resource-constrained project scheduling problems (RCPSP) [SPR 95]:
Figure 5.1. Sample schedules for a two-resource scheduling problem (horizontal time)

Semi-active schedule: as in Figure 5.1(b). No operation can be completed earlier without changing some execution sequence. Equivalently, in a semi-active schedule, any operation has at least one dependence or resource constraint that is tight, preventing the operation from being locally left-shifted.
Active schedule: as in Figure 5.1(c). No operation can be completed earlier without delaying another operation. The schedule of Figure 5.1(b) is not active because operation 5 can be globally left-shifted to time slot 1, without delaying other operations. Operation scheduling generates active schedules.
Non-delay schedule: as in Figure 5.1(d). No execution resources are left idle if there is an operation that could start executing. The schedule of Figure 5.1(c) is not non-delay because operation 2 could start executing at time slot 0. Cycle Scheduling generates non-delay schedules.
The non-delay schedules are a subset of the active schedules, which are a subset of the semi-active schedules [SPR 95]. Active schedules and non-delay schedules are the same in the case of operations that require resources for a single time unit.
5.2.2. Scoreboard Scheduling principles
The main drawback of the classic scheduling heuristics is their computational cost. In the case of Cycle Scheduling, the time complexity contributions are:
1) constructing the dependence graph is O(n2) with n the number of operations, but can be lowered to O(n) with conservative memory dependences [VER 02];
2) computing the operation priorities is O(n+e) with e the number of dependences for the critical path, and it is as high as O(n2 log n + ne) in [LEU 01, DIN 07];
3) issuing the operations in priority order is O(n2) according to [MUC 04], as each time step has a complexity proportional to m (where m is the number of dependence- ready operations), and m can be O(n).
The complexity of operation issuing results from sorting the dependence-ready operations in priority order, and matching the resource availabilities of the current cycle with the resource requirements of the dependence-ready operations. The latter motivates the finite-state automata approach of Proebsting and Fraser [PRO 94], which was later generalized to Operation Scheduling by Bala and Rubin [BAL 95].
To reduce instruction scheduling costs, we rely on the following principles:
– Verbrugge [VER 02] replaces the dependence graph by an ADL), with one list per dependence record (see section 5.2.3). We show how Operation Scheduling can avoid the explicit construction of such lists.
– In the setting of JIT postpass scheduling, either basic blocks are prepass scheduled because their performance impact is significant, or their operations are in original program order. In either case, the order operations are presented to the postpass scheduler encodes a priority that is suitable for Operation Scheduling, since it is a topological ordering of the dependences. So (re)computing the operation priorities is not necessary.
– We limit the number of resource availability checks by restricting the number of time slots considered for issuing the current operation.
More precisely, we define Scoreboard Scheduling to be a scheduling algorithm that operates like Operation Scheduling, with the following additional restrictions:
– Any operation is scheduled within a time window of constant window_size.
– The window_start cannot decrease and is lazily increased while scheduling.
That is, given an operation to schedule, the earliest date considered is window_start. Moreover, if the earliest feasible schedule date issue_date of operation is greater than window_start + window_size, then the Scoreboard Scheduling window_start value is adjusted to issue_date – window_size.
THEOREM 5.1.– Scoreboard Scheduling an active schedule yields the same schedule.
PROOF.– By contradiction. Scheduling proceeds in non-decreasing time, as the priority list is a schedule. If the current operation can be scheduled earlier than it was, this is a global left shift so the priority list is not an active schedule.
COROLLARY 5.1.–Schedules produced by Operation Scheduling or Cycle Scheduling are invariant under Scoreboard Scheduling and Operation Scheduling.
5.2.3. Scoreboard Scheduling implementation
A dependence record is the atomic unit of state that needs to be considered for accurate register dependence tracking. Usually these are whole registers, except in cases of register aliasing. If so, registers are partitioned into subregisters, some of which are shared between registers, and there is one dependence record per subregister. Three technical records named Volatile, Memory and Control are also included in order to track the corresponding dependences.
Let read_stage![]() and write_stage
and write_stage![]() be processor-specific arrays indexed by operation and dependence record that tabulate the operand access pipeline stages. Let RAW
be processor-specific arrays indexed by operation and dependence record that tabulate the operand access pipeline stages. Let RAW![]() , WAR
, WAR![]() and WAW
and WAW![]() be latency tuning parameters indexed by dependence record. For any dependence record r and operations i and j, we generalize the formula of [WAH 03] and specify any dependence latencyi→j on r as follows:
be latency tuning parameters indexed by dependence record. For any dependence record r and operations i and j, we generalize the formula of [WAH 03] and specify any dependence latencyi→j on r as follows:

Assuming that write_stage[i][r] > read_stage[j][r] ∀i, j, r, that is operand write is no earlier than operand read in the instruction pipeline for any given r, the dependence inequalities (b) and (e) are redundant. This enables dependence latencies to be tracked by maintaining only two entries per dependence record r: the latest access date and the latest write date. We call access_actions and write_actions the arrays with those entries indexed by dependence record.
The state of scheduled resources is tracked by a resource_table, which serves as the scheduler reservation table. This table has one row per resource and window_size + columns_max columns, where columns_max is the maximum number of columns across the reservation tables of all operations. The first column of the resource_table corresponds to the window_start. This is just enough state for checking resource conflicts in [window_start, window_start + window_size].
Scoreboard scheduling is performed by picking each operation i according to the priority order and by calling add_schedule(i, try_schedule(i)), defined by:
emphtry_schedule: Given an operation i, return the earliest dependence- and resource-feasible issue_date such that issue_date ≥ window_start. For each dependence record r, collect the following constraints on issue_date:

The resulting issue_date is then incremented while there exists scheduled resource conflicts with the current contents of the resource_table.
emphadd_schedule: Schedule an operation i at a dependence- and resource-feasible issue_date previously returned by try_schedule. For each dependence record r, update the action arrays as follows:

In case issue_date > window_start + window_size, the window_start is set to issue_date – window_size and the resource_table is shifted accordingly. The operation reservation table is then added into the resource_table.
In Figure 5.2, we illustrate scoreboard scheduling of two ST200 VLIW operations, starting from an empty scoreboard. There are three scheduled resources: ISSUE, 4 units; MEM, one unit; and CTL, one unit. The window_start is zero and the two operations are scheduled at issue_date zero. We display access_actions[r] and write_actions[r] as strings of a and w from window_start to actions[r]. In Figure 5.3, many other operations have been scheduled since Figure 5.2, the latest being shl $r24 at issue_date 4. Then operation add $r15 is scheduled at issue_date 5, due to the RAW dependence on $r24. Because window_size is 4, the window_start is set to 1 and the resource_table rows ISSUE, MEM, CTL are shifted.
THEOREM 5.2.– Scoreboard Scheduling correctly enforces the dependence latencies.
Proof.– Calling add_schedule(i,issue_datei) followed by try_schedule (j, issue_datei + latencyi→j) implies that latencyi→j satisfies the inequalities (a),(c),(d),(f).
Figure 5.2. Scoreboard Scheduling within the time window (window_size = 4)

Figure 5.3. Scoreboard Scheduling and moving the time window (window_size = 4)

5.3. Global instruction scheduling
5.3.1. Postpass inter-region scheduling
We define the inter-region scheduling problem as scheduling the operations of each scheduling region such that the resource and dependence constraints inherited from the scheduling regions (transitive) predecessors, possibly including self, are satisfied. When the scheduling regions are reduced to basic blocks, we call this problem the inter-block scheduling problem. Only inter-region scheduling is allowed to move operations between basic blocks (of the same region).
The basic technique for solving the inter-region scheduling problem is to schedule each region in isolation, then correct the resource and latency constraint violations that may occur along control-flow transfers from one scheduling region to the other by inserting no-operation (NOP) operations. Such NOP padding may occur after region entries, before region exits, or both, and this technique is applied after postpass scheduling on state-of-the-art compilers such as the Open64.
Meld Scheduling is a prepass inter-region scheduling technique proposed by Abraham et al. [ABR 98] that minimizes the amount of NOP padding required after scheduling. This technique is demonstrated using superblocks, which are scheduled from the most frequently executed to the least frequently executed, however it applies to any program partition into acyclic regions.
Consider a dependence whose source operation is inside a scheduling region and whose target operation is outside the scheduling region. Its latency dangle is the minimum number of time units required between the exit from the scheduling region and the execution of the target operation to satisfy the dependence. For a dependence whose source operation is outside the scheduling region and whose target operation is inside, its latency dangle is defined in a symmetric way [ABR 98].
Meld Scheduling only considers dependence latency dangles, however, resource dangles can be similarly defined. Latency dangle constraints originate from predecessor regions or from successor regions, depending on the order the regions are scheduled. Difficulties arise with cycles in the control-flow graph, and also with latency dangles that pass through scheduling regions. These are addressed with conservative assumptions on the dangles.
Meld Scheduling is a prepass technique, so register allocation or basic block alignment may introduce extra code or non-redundant WAR and RAW register dependences. Also with JIT compilation, prepass scheduling is likely to be omitted on cold code regions. On processors without interlocking hardware, compilers must ensure that no execution path presents hazards. In the Open64 compiler, hazards are detected and corrected by a dedicated “instruction bundler”.
When focusing on postpass scheduling, the latency and resource dangles of Meld Scheduling are implied by the scoreboard scheduler states at region boundaries. Moreover, we assume that the performance benefits of global code motion are not significant during the postpass scheduling of prepass scheduled regions, so we focus on inter-block scheduling. Finally, we would like to avoid duplicate work between an “instruction bundler” and postpass scheduling.
Based on these observations, we propose the inter-block scoreboard scheduling technique to iteratively propagate the dependence and resource constraints of local scheduling across the control-flow graph until the fixed point. As we will prove, it is possible to ensure that this technique converges quickly and preserves prepass schedules, including software pipelines, that are still valid.
5.3.2. Inter-block Scoreboard Scheduling
We propagate the scoreboard scheduler states at the start and the end of each basic block for all program basic blocks by using a worklist algorithm, like in forward dataflow analysis [NIE 99]. This state comprises window_start, the action array entries and the resource_table. Each basic block extracted from the worklist is processed by Scoreboard Scheduling its operations in non-decreasing order of their previous issue_dates (in program order the first time). This updates the operation issue_dates and the state at the end of the basic block.
Following this basic block update, the start scoreboard scheduler states of its successor basic blocks are combined through a meet function (described below) with the end scoreboard scheduler state just obtained. If any start scoreboard scheduler state is changed by the meet function, this means new inter-block scheduling constraints need to be propagated so the corresponding basic block is put on the worklist. Initially, all basic blocks are in the worklist and the constraint propagation is iterated until the worklist is empty.
In order to achieve quick convergence of this constraint propagation, we enforce a non-decrease rule: the operation issue_dates do not decrease when rescheduling a basic block. That is, when scheduling an operation, its release date is the issue_date computed the last time the basic block was scheduled. This is implemented in try_schedule(i) by initializing the search for a feasible issue_datei to the maximum of the previous issue_datei and the window_start.
The meet function propagates the scheduling constraints between two basic blocks connected in the control-flow graph. Each control-flow edge is annotated with a delay that accounts for the time elapsed along that edge. Delay is zero for fall-through edges and is the minimum branch latency for other edges. Then:
THEOREM 5.3.– Inter-block scoreboard scheduling converges in bounded time.
PROOF.– The latest issue_date of a basic block never exceeds the number of operations plus one times the maximum dependence latency or the maximum span of a reservation table (whichever is larger). The issue_dates are also non-decreasing by the non-decrease rule, so they reach a fixed point in bounded time. The fixed point of the scoreboard scheduler states follows.
5.3.3. Characterization of fixed points
THEOREM 5.4.– Any locally scheduled program that satisfies the inter-block scheduling constraints is a fixed point of inter-block scoreboard scheduling.
PROOF.– By hypothesis, all operations have valid issue_dates with respect to basic block instruction scheduling. Also, the inter-block scheduling constraints are satisfied. By the non-decrease rule, each operation previous issue_date is the first date tried by Scoreboard Scheduling, and this succeeds.
A first consequence is that for any prepass region schedule which satisfies the inter-block scheduling constraints at its boundary, basic blocks will be unchanged by inter-block scoreboard scheduling, provided that no non-redundant instruction scheduling constraints are inserted into the region by later compilation steps. Interestingly, this holds for any prepass region scheduling algorithm: superblock scheduling, trace scheduling, wavefront scheduling and software pipelining.
A second consequence is that inter-block scoreboard scheduling of a program with enough NOP padding to satisfy the inter-block scheduling constraints will converge with only one Scoreboard Scheduling pass on each basic block. In practice, such explicit NOP padding should be reserved for situations where a high-frequency execution path may suffer from the effects of latency and resource dangles at a control-flow merge with a low-frequency execution path, such as entry to an inner loop header from a loop preheader.
5.4. Experimental results
In the setting of the STMicroelectronics CLI-JIT compiler, we implemented Scoreboard Scheduling as described in section 5.2.3 and also a Cycle Scheduling algorithm that closely follows the description of Abraham [ABR 00], including reference counting for detecting operations whose predecessors have all been scheduled.
We further optimized this cycle scheduling implementation for compilation speed. In particular, we replaced the dependence graph by a variant of the ADL of Verbrugge [VER 02] to ensure a O(n) time complexity of the dependence graph construction. This implies conservative memory dependences, however we assume such a restriction is acceptable for postpass scheduling.
Figure 5.4. Benchmark basic blocks and instruction scheduling results

We selected a series of basic blocks from STMicroelectronics media processing application codes and performance kernels compiled at the highest optimization level by the Open64-based production compiler for the ST200 VLIW family [DIN 04a]. The proposed CLI-JIT postpass scheduler was connected to this compiler.
These benchmarks are listed in the left side of Figure 5.4. Columns Size and IPC, respectively, give the number of instructions and of instructions per cycle after Cycle Scheduling. Column RCost is the ratio of compilation time between the cycle scheduler and the scoreboard scheduler at window_size = 15. Column RPerf is the relative performance of the two schedulers, as measured by inverse of schedule length. Column RQuery is the ratio of compilation time for resource checking between the cycle scheduler and the scoreboard scheduler. On the right side of Figure 5.4, we show the compilation time as a function of basic block size. Unlike the Cycle Scheduling, Scoreboard Scheduling clearly operates in linear time.
To understand how compilation time is spent, we show in Figure 5.5 the stacked contributions of the different scheduling phases normalized by the total instruction scheduling time; so their sum is 1. We also single out the cumulative time spent in resource checking, yielding the bars above one. For Cycle Scheduling (left side), the cost of computing the dependences ADL becomes relatively smaller, as it is linear with basic block size. The Priority computing phase is of comparable time complexity yet smaller than the operation Issuing phase. For Scoreboard Scheduling (right side), the Try schedule phase is consistently slightly more expensive than the Add schedule phase.
Figure 5.5. Time breakdown for cycle scheduling and scoreboard scheduling
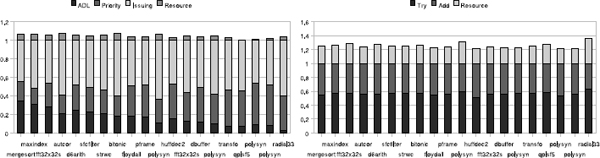
It also appears from Figure 5.5 that using finite state automata as proposed by Bala and Rubin [BAL 95] for speeding up resource checking is not always justified, in particular for processors whose reservation tables are single cycle. For more complex processors, it would be straightforward to replace the resource_table of a Scoreboard Scheduling implementation by such finite state automata.
5.5. Conclusions
In this chapter, we proposed a postpass instruction scheduling technique motivated by JIT compilation for VLIW processors. This technique combines two ideas: Scoreboard Scheduling, a restriction of classic Operation Scheduling that considers only the time slots inside a window that moves forward in time; and Inter-Block Scheduling, an iterative propagation of the scheduling constraints across the control-flow graph, subject to the non-decrease of the schedule dates. This inter-block scoreboard scheduling technique has three advantages:
Experiments with the STMicroelectronics ST200 VLIW production compiler and the STMicroelectronics CLI-JIT compiler confirm the significance of our approach.
Our results further indicated that compiler instruction schedules produced by Cycle Scheduling and Operation Scheduling are essentially unchanged by the hardware operation scheduler of out-of-order superscalar processors. Indeed, active schedules are invariant under Scoreboard Scheduling. Finally, the proposed non-decrease rule provides a simple way of protecting cyclic schedules, such as software pipelines, from the effects of rescheduling with an acyclic scheduler.
1 The ST200 VLIW architecture is based on the Lx technology [FAR 00] jointly developed by Hewlett-Packard Laboratories and STMicroelectronics.