
Appendix 4
Efficiency of Non-Positive Circuit Elimination in the SIRA Framework
A4.1. Experimental setup
These experiments were conducted by Sébastien Briais on the stand-alone data dependence graph (DDG) described in Appendix 1. We assume Τ = {GR, BR, FP}. We used a regular Linux workstation (Intel Xeon, 2.33 GHz, 9 GB of memory).
A4.1.1. Heuristics nomenclature
Our methods to avoid the creation of non-positive circuits are of three types:
A4.1.2. Empirical efficiency measures
For each heuristic of non-positive circuit elimination, for each DDG and for each initiation interval II between MII and L (L is a fixed upper bound on the admissible values for II), we measured the execution time taken by each heuristic (listed above) to minimize the register requirement; we also recorded the number of registers computed by the three methods (UAL, CHECK and SPE). We are going to examine these results in the next sections.
We have also considered three possible target architectures (small, medium and large) as described in A1.3. When the number of available registers is fixed in the architecture, we may need to iterate on multiple values for II in order to get a solution below the processor capacity; that is, since register minimization is applied for a fixed II, we may need to iterate on multiple values of II if the minimized register requirement is still above the number of available registers. The strategy for iterating over II for one of our heuristics (here, any of the three methods previously described can be used: UAL, CHECK, SPE) is the following:
For each architecture and for each DDG G, we determined whether the heuritic (UAL, CHECK or SPE) is able to find a solution that satisfies the architectural constraints. We thus measured:
–the elapsed time needed to determine whether a solution exists;
– the smallest II for which a solution exists (when applicable).
Regarding the iterative heuristic of non-positive circuit elimination (SPE), we arbitrarily fixed the maximal number of iterations to 3 and 5. In order to get an idea of how many iterations the iterative methods could take in the worst case before reaching a fixed point (convergence), we conducted the experiments by setting the maximum number of iterations allowed to 1,000 and recorded the number of iterations reached. Remember that if a fixed point (convergence) is detected, the iterative algorithm stops before reaching 1,000 iterations.
A4.2. Comparison between the heuristics execution times
In this section, we compare and discuss the execution times of the heuristics of non-positive circuits elimination.
A4.2.1. Time to minimize register pressure for a fixed II
In this section, we apply the three methods with all values of II. Figure A4.1 shows the distribution of execution times of UAL heuristic: MIN is the minimal value, FST is the value of first quartile (25% of the values are less than or equal to the FST value), THD is the value of the third quartile (75% of the values are less than or equal to the THD value) and MAX is the maximal value. We also use boxplot to graphically depict the values of MIN, FST, MEDIAN, THD and MAX.
Figure A4.1. Execution times of UAL (in seconds)
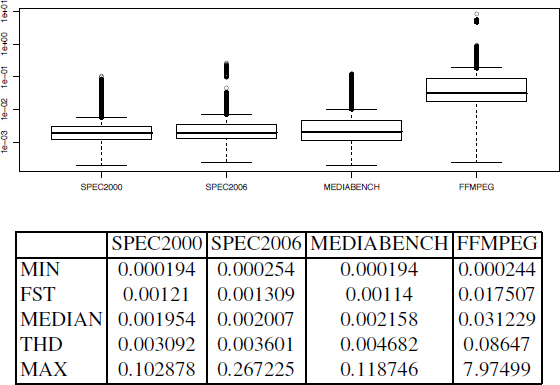
Figure A4.2 shows the distribution of CHECK heuristic execution times.
Figure A4.3 shows the distribution of SPEn heuristic execution times for n ∈ {5,1000}.
From the above results, we found that, as expected, UAL is the fastest heuristic. CHECK is between one and three times slower than UAL, which was also expected because it consists of running SIRALINA, performing a check and in the worst case running SIRALINA a second time.
Regarding our proactive heuristic, SPE heuristic seems to have quite a reasonable running time, but is still more expensive than UAL or CHECK (about 10 times slower).
Figure A4.2. Execution times of CHECK (in seconds)

Figure A4.3. a) Execution times of SPE (in seconds)
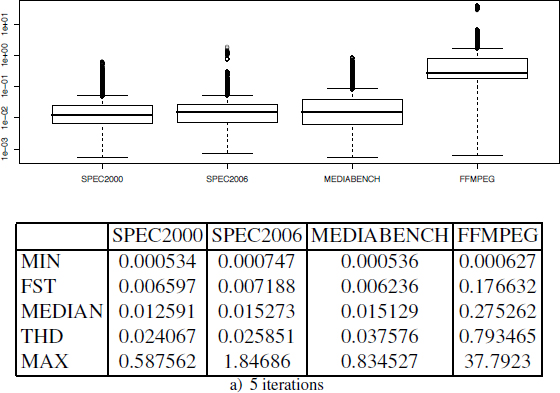
Figure A4.3. b) Execution times of SPE (in seconds)

A4.3. Convergence of the proactive heuristic (iterative SIRALINA)
In this section we study the speed of convergence (in terms of number of iterations) of SPE heuristic. Recall that *SPE* is said to converge when it reaches a fixed point, i.e. when the set of reuse edges does not change between two consecutive iterations of algorithm 10.1. All the values of II are tested; so the experiments we consider in this section are for all DDG and for all II values.
Figure A4.4 shows the distribution of the number of iterations of SPE heuristic (truncated at 1,000). We observe that on a small number of DDGs, the upper bound of 1,000 iterations has been reached by SPE heuristic. It is indeed well possible that the iterative process does not terminate in the general case. Note, finally, that this information may be used to set the upper bound in an industrial compiler on the maximal number of iterations: five iterations seems to be a satisfactory practical choice since it allows the convergence in 75% of the cases for SPEC2000, SPEC2006 and MEDIABENCH benchmarks.
A4.4. Qualitative analysis of the heuristics
In this section, we study the quality of the solution produced by the heuristics. The qualitative aspects include the number of registers needed to schedule the DDG and the loss of parallelism due to an increase of the MII resulted from * UAL, CHECK and SPE.
Figure A4.4. Maximum observed number of iterations for SPE

A4.4.1. Number of saved registers
In this section, we analyze the number of registers each heuristic manages to optimize. Our tests are for all DDG, for all II values. We graphically compare the heuristics: for each set of benchmarks, and each register type, we construct a partial order (lattice) as follows:
– the vertices are labeled with the name of the heuristic;
– a directed edge links an heuristic A to an heuristic B iff the number of registers (of considered type) computed by heuristic B is statistically greater (worse) than the number of registers (of the same type) computed by heuristic A: by statistically greater, we mean that we applied a one sided Student’s t-test between the alternatives A and B, and we report the risk level of this statistical test (between brackets in the edges). The edge is also labeled with the ratio  where RB is the number of registers (of considered type) computed by heuristic B and RA is the number of registers computed by heuristic A.
where RB is the number of registers (of considered type) computed by heuristic B and RA is the number of registers computed by heuristic A.
The lattices are given in Figures A4.5, A4.6, A4.7 and A4.8.
For instance, we read in Figure A4.5 that the number of registers of type branch register (BR) computed by UAL heuristic is 1.069, which is greater than the number of registers of type BR computed by CHECK heuristic.
Figure A4.5. Comparison of the heuristics’ ability to reduce the register pressure (SPEC2000)
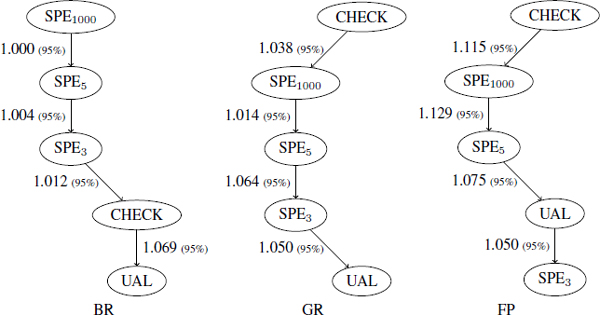
Figure A4.6. Comparison of the heuristics’ ability to reduce the register pressure (MEDIABENCH)

First, from these results, we observe that the ordering of the heuristics depends on the register type. Indeed, since the heuristics try to reduce register pressure of all types simultaneously, it happens that some perform better on one type that on the others.
Figure A4.7. Comparison of the heuristics’ ability to reduce the register pressure (SPEC2006)

Figure A4.8. Comparison of the heuristics’ ability to reduce the register pressure (FFMPEG)

Second, we see that UAL is the worst heuristic regarding register requirements. This is not surprising since this is the most naive way to eliminate non-positive circuits.
Finally, we observe that CHECK is sometimes the best heuristic (in particular for general register (GR) and floating point (FP) types on all benchmarks except FFMPEG). We can explain this by the fact that the proportion of DDG with non-positive circuits on SPEC2000, SPEC2006 and MEDIABENCH is low (less than 40%). Consequently, the reactive strategy (CHECK) is appropriate, since more than 60% of the DDG did not get a non-positive circuit from the beginning (so they did not require a correction step).
A4.4.2. Proportion of success when looking for a solution that satisfies the register constraints
In this section, we do not analyze the amount of registers needed as in the previous section. We assume an architecture with a fixed number of available registers, and we count the number of solutions that have a register requirement below the processor capacity. We decompose the solutions into three families: the DDGs that have been solved without MII increase, the DDGs that have been solved with MII increase and the DDG that was not solved with the heuristic (spilled). All the results are present in [BRI 10].
We noted that most of the time our heuristics found a solution that satisfies the register constraints. Of course, the percentage of success increased while the architecture constraints were relaxed. Apart from the FFMPEG benchmarks under the small architecture constraints (where the number of available registers is very small, so the constraints on register pressure are harder to satisfy), the percentage of success is above 95%. In these cases, all the heuristics give comparable results.
For the FFMPEG benchmarks, we see that SPE5 and SPE1000 give slightly better results than the naive UALheuristic (1% – 3% better). We observe that in most cases of success, the MII has not been increased at all.
A4.4.3. Increase of the MII when looking for a solution that satisfies the register constraints
We count the MII increase by the formula ![]() where MIIh(G) is the MII of the associated DDG computed by heuristic h. In other words MIIh is the smallest period II that satisfies the register constraints when we use heuristic h, where h ∈{UAL, CHECK, SPEn}. All the results are present in [BRI 10].
where MIIh(G) is the MII of the associated DDG computed by heuristic h. In other words MIIh is the smallest period II that satisfies the register constraints when we use heuristic h, where h ∈{UAL, CHECK, SPEn}. All the results are present in [BRI 10].
These results show that the increase of the MII is very low (less than 6% in the worst case). It is clearly negligible on SPEC2000, SPEC2006 and MEDIABENCH benchmarks. On FFMPEG benchmarks, we see that when dealing with small architecture, SPE heuristics tend to increase the MII more than UAL or CHECK heuristics, whereas for bigger architecture, SPE5 and SPE1000 give slightly better results than UAL or CHECK.
A4.5. Conclusion on non-positive circuit elimination strategy
The conclusions we can take from this extensive experimental study are contrasted. On the one hand, the results show that the proactive heuristic SPE allows us to save a little more registers than the two naive heuristics UAL and CHECK. On the other hand, these results also show that our proactive heuristic is more expensive regarding the execution times than the reactive one.
Thus, we advise the following policy: if the target architectures are embedded systems, where compilation time does not need to be interactive and where register constraints are strong, we recommend the use of the SPE proactive heuristic. As we have seen, it optimizes registers better than the reactive heuristic while still being quite cheap. On the contrary, if the target architecture is a general purpose computer (workstation, desktop or supercomputer), where register constraints are not too strong, it is probably sufficient to use the reactive heuristic CHECK, as it already gives good results in practice and it is only between one and three times slower than the UAL heuristic.