


Solution for financial services workloads
This chapter describes challenges that are faced by financial institutions, and how technical cloud computing can be used to help solve them. It also describes solution architecture topics, and provides use case scenarios to help solve financial workloads.
This chapter includes the following sections:
9.1 Overview
In today’s world, financial institutions are under increasing pressure to solve certain types of problems. Online transaction fraud has increased over time, and accounts for billions of dollars already. Money laundering costs governments to lose billions of tax dollars that could be invested in infrastructure or services for the country.
Simulation of scenarios based on past data or real-time analysis are in high demand. Today, institutions base their decisions much more on heavy data analysis and simulation than on feeling and experience alone. They need as much data as possible to guide these decisions to minimize risks and maximize return on investment.
Current regulatory requirements nowadays also push for a faster risk analysis such as Counterparty Credit Risk (CCR), which requires the use of real-time data. Regulations ALSO require comprehensive reports that are built from a large amount of stored data.
In essence, financial institutions must be able to analyze new data as quickly as it is generated, and also need to further utilize this data later on. These are only a few examples of problems that can be tackled by Platform Computing and business analytics solutions. These solutions can scale up their processing to synthesize, as quickly as required by the business, the amount of data that are generated by or available to these institutions.
9.1.1 Challenges
In addition to these problems and trends, this section provides an insight on some of the challenges that are currently faced by customers in the financial arena:
•Financial institutions face the need to model and simulate more scenarios (Monte-Carlo) to minimize uncertainty and make better decisions. The number of scenarios required for a certain precision can require very large amounts of data and processing time. Optimization of infrastructure sharing for running these multiple scenarios is also a challenge.
•Given the costs, it is prohibitive to think about having an isolated infrastructure to provide resources for each business unit and application. However, users fear that they might lose control of their resources and not meet their workload SLAs when using a shared infrastructure.
•Some problem types are more efficiently solved with the use of MapReduce algorithms. However, the business might require the results in a timely manner, so there is the need for a fast response from MapReduce tasks.
•Using programming languages such as R and Python to make use of distributed processing. R is a statistical language that is used to solve analytics problems. Python has been increasingly used to solve financial problems due to its high performance mathematics libraries. However, writing native code that is grid-distributed aware is still a difficult and time-consuming task for customers.
•For data intensive applications, the time to transfer data among compute nodes for processing can exceed calculation times. Also, network can get saturated as the number of data applications that need to be analyzed grows rapidly.
•Customers want to use the idle capacity of servers and desktops that are not part of the grid due to budgetary constraints. However, the applications that run on these off-grid systems cannot be affected.
IBM has a range of products that can be used to help solve these problems and challenges. These include BigData applications, Algorithmics, and IBM Platform Symphony along with its MapReduce capabilities.
9.1.2 Types of workloads
Workloads can be classified according to two different categories when it comes to the world of finance:
•Real-time versus long-running (batch)
•Data intensive versus computing intensive
Figure 9-1 depicts a diagram classifying some of the tasks that are run by a bank according to these categories.
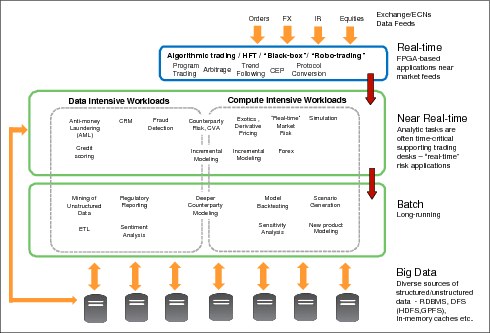
Figure 9-1 Diagram classifying tasks according to workload types at a bank
Notice in Figure 9-1 that the environment is constantly fed with data such as electronic orders, foreign exchange rates, interest rates, and equity values. This information is used to feed real-time applications such as algorithmic trading. This type of rapid, massive data analysis can be run with, for example, IBM InfoSphere Streams.
In the next layer, decreasing in terms of need for time-critical results, come the near real-time workloads. The acquired data, after they are analyzed by real-time applications, can be used to perform analysis such as fraud detection, run Anti-Money Laundering (AML) routines, near real-time market risk analysis, simulations, and others. In this layer, you can still split the workloads into two groups: Compute intensive and data intensive. Long running applications are not the only ones that must deal with large amounts of data. Near real-time ones such as AML need to be able to quickly detect fraud or laundering activities by analyzing large amounts of data generated by millions of financial transactions. Some workloads are mixed in that sense, such as counterparty risk analysis, which is both compute and data intensive.
Going down one layer, you reach the non-real-time, long-running, batch jobs responsible for creating reports, mining unstructured data, model back-testing, scenario generation, and others. Again, workloads can be classified as compute or data intensive, or both.
The lowest layer of Figure 9-1 on page 201 depicts a diverse set of hardware and technologies that are used as infrastructure for all of these workloads. Below them all lies a vast amount of data that was not able to be analyzed i until now. The finance world has become a truly BigData environment.
The following is a more comprehensive list of workloads that are commonly tackled by financial institutions:
•Value at risk (VaR)
•Credit value adjustments (CVAs) for counterparty CCR
•Asset liability modeling (ALM)
•Anti-money Laundering
•Fraud detection
•Sensitivity analysis
•Credit scoring
•Mortgage analytics
•Variable annuity modeling
•Model back testing
•Portfolio stress testing
•Extraction, transformation, and load (ETL)
•Strategy mining
•Actuarial analysis
•Regulatory reporting
•Mining of unstructured data
9.2 Architecture
The example software architecture to engage common financial workloads is shown in Figure 9-2. The architecture is based on BigData components that use IBM Platform Symphony’s ability to effectively manage resource grids and provide low latency to applications.
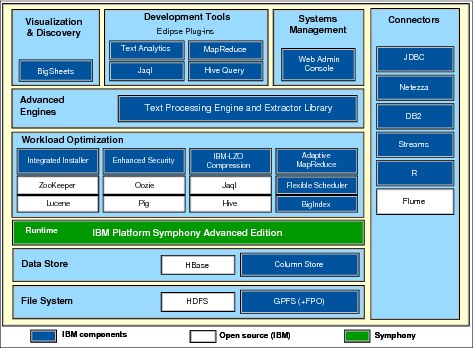
Figure 9-2 Platform Symphony-based software architecture for running financial workloads
The architecture depicted in Figure 9-2 is composed of multiple layers. Notice that some of the layers offer the option to use open source software, which are identified as white boxes. The blue boxes denote IBM components.
As a middleware, Platform Symphony appears in a middle layer of the architecture. It is able to control and schedule computational resources within the grid and effectively share them among applications. The software components underneath it are related to data handling such as file system software components and data store software components. For file systems, the architecture can be built using GPFS or Hadoop. Known technologies for storing data, especially in a BigData environment, are HBase and Column Store.
Above Platform Symphony is the application layer that uses its low-latency and enhanced MapReduce capabilities. As you can see in Figure 9-2, many technologies can be integrated into this Platform Symphony-based reference architecture.
Finally, the architecture uses connectors to allow communication with other data sources (Netezza®, IBM DB2®, Streams, and others) as depicted in Figure 9-2.
9.2.1 IBM Platform Symphony
IBM Platform Symphony can be applied as a middleware layer to accelerate distributed and analytics applications running on a grid of systems. It provides faster results and a better utilization of the grid resources.
With Platform Symphony, banking, financial markets, insurance companies, among other segments, can gain these benefits:
•Higher quality results are provided faster.
Run diverse business-critical compute and data intensive analytics applications on top of a high performance software infrastructure.
•Reduction of infrastructure and management costs.
A multi-tenant approach helps achieve better utilization of hardware, minimizing the costs of hardware acquisition, cost of hardware ownership, and simplifying systems management tasks.
•Quick responses to real-time demand.
Symphony uses push-based scheduling models that save time compared to polling-based schedulers, allowing it to respond almost instantly to time-critical businesses. This can provide a great boost to MapReduce based applications.
•Management of compute-intensive and data-intensive workloads under the same infrastructure.
Financial businesses workloads are diverse. However, you do not need to create separate environments to be able to process each type of workload separately. Symphony can efficiently schedule resources of the same computing grid to meet these workload requirements.
•Harvesting of desktop computers, servers, and virtual servers with idle resources.
Symphony can use desktop and server resources that are not part of the computing grid to process workloads without impacting their native applications. Tasks are pushed to these extra resources when they are found to be idle. Virtual servers such as VMware and Citrix Xen farms can also be harvested.
•Integration with widely used programming languages in the financial world, such as R and Python.
Through Symphony, customer written code can use the grid middleware to handle some aspects of distributed programming.
•Data-aware scheduling of compute and data intensive workloads.
Platform Symphony schedules tasks to nodes where the data is found to be local whenever possible, which improves performance and efficiency.
IBM Platform Symphony can suit both classifications that were introduced in 9.1.2, “Types of workloads” on page 201: Real-time versus long-running, and compute versus data-oriented workloads.
Figure 9-3 describes which layers Platform Symphony can act upon from a time-critical classification point of view. If you compare it to Figure 9-1 on page 201, you can see that there is a match between them. The second and third stages of data flow in Figure 9-3 correspond to the second and third layers (delimited by the green rectangles) in Figure 9-1 on page 201.
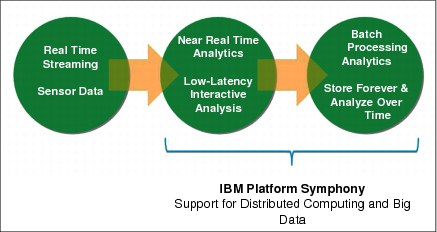
Figure 9-3 Platform Symphony’s support for time-critical data processing
Similarly, there is a match between Platform Symphony’s component architecture as depicted in Figure 9-4 with Figure 9-1 on page 201. Symphony can provide a low-latency service-oriented application middleware for compute intensive workloads, and also an enhanced, highly performing framework for massive data processing that is based on MapReduce algorithms. Notice that Platform Symphony is also able to provide both of these for workloads that are both compute and data intensive.

Figure 9-4 Platform Symphony middleware for compute and data intensive workloads
Details about Symphony’s internal components can be found in Chapter 9, “Solution for financial services workloads” on page 199 and Chapter 4, “IBM Platform Symphony MapReduce” on page 59.
IBM Platform Symphony MapReduce
IBM Platform Symphony contains its own framework for dealing with MapReduce processing. This framework allows multiple users to have access to the grid resources at the same time to run the MapReduce jobs of an application. This is an improvement over Hadoop’s MapReduce framework, where jobs are scheduled to run sequentially, one at a time, having a single job consume grid resources as much as possible. Platform Symphony can schedule multiple jobs to the grid at the same time by sharing the grid resources based on job priority, job lifetime (shorter, longer), user SLAs, and so on.
Another advantage of using Platform Symphony as an architecture component is that it can manage the co-existence of both MapReduce and non-MapReduce applications in the same grid. This characteristic avoids the creation of resource silos by allowing different workload types to use the grid resources. Therefore, a financial institution does not need to have different grids to process its variety of workloads. Instead, it can use a single analytics cloud to run all of its workloads as depicted in Figure 9-5.

Figure 9-5 Single financial services analytic cloud
9.2.2 General Parallel File System (GPFS)
With a large quantity of financial problems using MapReduce algorithms to get to results, many frameworks use the Hadoop Distributed File System (HDFS) to store data.
HDFS is well suited for what it is intended to do: Serve data intended for MapReduce tasks in a cluster of machines. However, HDFS lacks capabilities for file system operations, so it cannot be used as a multi-purpose file system:
•Data accessed through Java application programming interfaces (APIs).
To access data, users must interface their own code with APIs, or use a set of utilities for doing so (FS shell). In either case, there is no direct linkage between the files and the operating system.
•HDFS is not built with POSIX standards.
There is no direct linkage between the files within HDFS and the operating system. Consequently, users must load their HDFS space with the data before consuming it. The time required can be significant for large amounts of data. Also, users might end up with the data stored twice: Inside HDFS for consuming it with MapReduce applications, and on the operating system for manipulating the data easily.
User-space file systems technologies integrated to the Hadoop MapReduce framework might alleviate data handling operations, but then the performance of a user-space file system becomes a disadvantage.
•Single-purpose built file system.
HDFS was built to serve as Hadoop’s file system for providing data to MapReduce applications. It is not suited to be used as a file system for other purposes.
•Optimized for large data blocks only.
Small or medium sized files are handled in the same way as large files, making HDFS not so efficient at handling them. Because there are numerous sources of varying characteristics for BigData today, this also adds more disadvantages to the file system.
•HDFS metadata is handled in a centralized way.
Although it is possible to provide a certain level of metadata high availability with the primary and secondary name nodes for HDFS, this data is restricted to these nodes only.
To overcome these characteristics, GPFS with its new File Place Optimizer (FPO) feature can be considered as an enterprise-class alternative to HDFS. FPO makes GPFS aware of data locality, which is a key concept within Hadoop’s MapReduce framework. With that, compute jobs can be scheduled on the computing node for which the data is local. The new FPO feature is explained in 6.4.2, “File Placement Optimizer (FPO)” on page 129.
GPFS has an established reputation as a distributed file system compliant with POSIX standards. Therefore, it is part of the operating system, and applications can use it by using the same system calls used to manage data with any file system (open, close, read, write, and so on). There is no need to load data onto a MapReduce framework before consuming it. Captured BigData from multiple sources are stored in GPFS and are immediately available for consumption.
Also, GPFS is a multi-purpose file system. As such, different types of application can consume the same resident data on the storage devices. There is no need to replicate data depending on how it is supposed to be consumed. This means that you can have, for example, both MapReduce and non-MapReduce based applications of a workflow using the same set of data, avoiding the need for duplication.
GPFS provides data access parallelism, which represents an increase in performance when running multiple simulation scenarios that access the same data. This means that financial institutions can run more scenarios at once, increasing decision accuracy because more simulation results are available.
Support for both large and small blocks is available in GPFS, as well as support for various data access patterns, giving applications a high level of performance.
Finally, GPFS provides automated data replication to remote sites, thus being an integrated solution for both high performing data I/O and data backup to ensure business continuity.
9.2.3 IBM Platform Process Manager (PPM)
PPM can automate the execution of jobs by the creation of flow definitions. This helps organize tedious, repetitive tasks and their interconnections. Sophisticated flow logic, subflows, alarm conditions, and scriptable interfaces can be managed by PPM. By doing so, Process Manager minimizes the risk of human errors in processes and provides reliability to processes.
Platform Process Manager is part of the Platform LSF suite, and can be integrated on a grid that is managed by IBM Platform LSF, or a multiheaded grid that is managed by Platform LSF and Platform Symphony as described in Figure 9-6.

Figure 9-6 Platform Process Manager in an LSF and Symphony multiheaded grid architecture
Platform Process Manager is Platform LSF aware. That is, its internal components are able to understand Platform LSF constructs such as job arrays, and choose processing queues. PPM is deployed to work more with Platform LSF in most of the cases.
However, a PPM flow step can interact with Platform Symphony by starting a client that in turn connects to Platform Symphony for job execution. For example, imagine a flow in which the first step is the creation of simulation scenarios. A second step can then get these scenarios and pass them along to an application running on top of Platform Symphony so they can be run.
The flexibility of using both Platform LSF and other applications such as Platform Symphony-based applications, is suited to environments that are composed of both batch and service-oriented jobs. Platform LSF can be used to manage batch-oriented jobs, whereas Platform Symphony can be used to run MapReduce or other SOA framework-based applications.
For more information about how to create a multiheaded grid environment, see IBM Platform Computing Solutions, SG24-8073.
Platform Process Manager can use the advantages of a distributed grid infrastructure as it provides these benefits:
•Resource-aware workflow management.
Platform Process Manager works by qualitatively describing the resources that it needs to run a workflow. Therefore, jobs are not tied to particular host names. This creates a more efficient workflow execution because you can use resource schedulers, such as Platform Symphony or Platform LSF, to deploy jobs on other available grid nodes that can satisfy their execution instead of waiting for a particular node to become available.
•Built-in workflow scalability.
As your grid has its amount of resources increased, PPM can dynamically scale the workflow to use the added resources. No changes to the workflow definitions are required.
•Multi-user support.
Platform Process Manager can handle multiple flows from different users at the same time. Flow jobs are sent to the grid for execution, and each flow can use part of the grid resources.
The following bullets summarize the benefits of using PPM for automating flow control:
•Integrated environment for flow designing, publishing, and managing.
•Reliability provided by rich conditional logic and error handling.
– You can inspect variables status and define roll-back points in case of failure. Roll-back points are useful to avoid users having to treat errors that can be resolved by trying the particular task again.
•Modular management that provides flows and subflows with versioning control.
•Flow execution based on schedule or triggering conditions.
•Intuitive graphical interfaces as shown in Figure 9-7 on page 210.
– No programming skills required.
– Graphical dynamic flow execution monitoring.
•Self documenting of flows.
•XML-based format is used to save workflows.

Figure 9-7 Platform Process Manager flow editor.
For a comprehensive user guide on Platform Process Manager, see Platform Process Manager Version 9 Release 1 at:
9.3 Use cases
This section provides use case scenarios to complement the theoretical details described in previous sections.
9.3.1 Counterparty CCR and CVA
An active enterprise risk management strategy relies on having an up-to-date aggregate view of corporate exposures. These include accurate valuations and risk measurements, reflecting CVAs of portfolios and new transactions. To understand risks enterprise-wide, pricing and risk analytics can no longer be done in silos or in an ad hoc fashion. The need to apply accurate risk insights while making decisions throughout the enterprise is driving firms to consolidate risk systems in favor of a shared infrastructure.
The CVA system is an enterprise-wide system that needs to take input from both commercial and proprietary risk/trading systems (seeing what is in the portfolios). It then aggregates the input to determine the counterparty risk exposures. Monte Carlo simulations are the best way to do the CVA calculation. Platform Symphony grid middleware is particularly suited for running Monte Carlo because of its high scalability and throughput on thousands to tens of thousands of compute nodes. As new regulations and new financial products become available, the CVA system must adapt to respond to these changes.
Key requirements for enterprise risk management solutions
The following highlights these key considerations:
•Enterprise-scale, across asset classes and deal desks
•Provide full Monte Carlo Simulations
•Support proprietary and third-party risk/trading systems
•Aggregation of results with netting
•Intraday or faster with high throughput
•Cost efficient solution
•Agile by enabling change/update of new models
Applicable markets
This list highlights the applicable solution markets:
•Tier-one investment banks running predominantly in-house analytic models
•Tier-two banks running ISV applications and in-house models
•Hedge funds, pension funds, and portfolio managers
•Insurance companies and exchanges
IBM Platform Symphony for integrated risk management solution
An active risk management approach requires a highly scalable infrastructure that can meet large computing demands, and allow calculations to be conducted in parallel. Grid computing is a key enabling, cost-effective technology for banks to create a scalable infrastructure for active risk management. Grids are used in various areas, including pricing of market and credit risk, compliance reporting, pre-trade analysis, back testing, and new product development.
Past technical limitations with some applications and grid technologies often created multiple underused compute “silos”. This results in increased cost and management complexity for the entire organization. Newer applications and grid technologies have overcome these limitations, allowing for effective resource sharing by maximizing utilization while containing costs.
With effective grid management in place, grids should be available instantly and on demand to the users with the highest priority. The grid applications can dynamically borrow computing resources from lower priority work already in process, achieving a higher overall utilization. In addition, priority requests are served quickly at a lower overall cost.
The solution is based on IBM Platform Symphony, which provides a solution for data intensive and distributed applications such as pricing, sensitivity analysys, model back-testing, stress-testing, fraud-detection, market and credit risk, what-if analysis, and others.
Platform Symphony also uses its data affinity feature to optimize workload and data distribution to remove bottlenecks and maximize performance.
Another important feature of Platform Symphony is the ability to oversubscribe each computation slot to handle recursive type jobs over the data already available on a particular node. This parent-child relationship of created jobs prevents unnecessary data movement and is key to achieving maximum performance.
Using IBM Algorithmics as an example (Figure 9-8), the Algorithmics products and Platform Symphony are integrated to enable faster time-to-completion of complex analytics workloads such as CVA. This is particularly useful for compute intensive tasks such as simulation (integration of IBM RiskWatch® and Platform Symphony).

Figure 9-8 Risk management solution: Platform Symphony and IBM Algo One® software services
Platform Symphony also supports high availability. If a node fails, an automated failover restarts only the task that failed rather than the entire job. In testing, this integration has been proven to lower deployment risks and costs. Both Algorithmics and IBM Symphony support heterogeneous systems, allowing you a choice of where to run the integrated solution.
Benefits
This section describes the benefits of the solution:
Scalability CVA applications demand both scale and low latency. Platform Symphony enables higher fidelity simulations and better decisions making in less time.
Agility Platform Symphony is unique in its ability to respond instantly to changing real-time requirements such as pre-deal analysis and limit checks, and hedging.
Resource sharing Platform Symphony enables the same infrastructure to be shared between line of business (LOBs) and applications with flexible loaning and borrowing for sensitivity analysis, stress runs, convergence testing, and incremental CVA.
Smarter data handling The efficient built-in data distribution capability combined with intelligent data affinity scheduling meet data handling demands for risk exposures calculation across multiple LOBs.
Reliability Scheduling features and redundancy help ensure critical tasks are run within available time windows.
9.3.2 Shared grid for high-performance computing (HPC) risk analytics
The shared grid solution for risk analytics is a platform as a service (PaaS) infrastructure for scalable shared services. In today’s global economic scenario, where IT requirements are increasing but budgets are flat, the pressure to deploy more capability without incremental funding is always present in the financial services sector.
Here are some IT challenges the shared grid model aims to address:
•Internal customers need to self-provision infrastructure faster and cheaper.
•Costly and slow to deploy new applications.
•Need to preserve SLAs, leading to incompatible technology “silos” that are underused and costly to maintain.
•LOB peak demands are either unsatisfied or cause over-provisioning of infrastructure to meet demand and low utilization.
•Effective approach to share and manage resources across geographically dispersed data centers.
•Business units and application owners are reluctant to get onboard with a shared infrastructure project for fear of losing control and jeopardizing core functions.
Applicable markets
The following is a list of applicable markets:
•Financial organizations that seek to build a private cloud infrastructure to support risk analytics environments.
•Service providers that offer infrastructure as a service (IaaS) or software as a service (SaaS) solutions that are related to risk analytics.
•Banks, funds and insurance companies that seek to reduce internal IT costs.
Solution architecture
Platform Symphony helps to consolidate multiple applications and lines of business on a single, heterogeneous, and shared infrastructure. Resource allocations are flexible, but resource ownership is guaranteed. Resources are allocated to improve performance and utilization while protecting SLAs.
Platform Symphony can harvest off-grid resources such as corporate desktops, workstations, and virtual machine hypervisors to expand the available resource pool. Platform Symphony also supports the Platform Analytics plug-in for chargeback accounting and capacity planning to address IT-related risk.
Platform Symphony also supports a wide range of optimized application integrations, including IBM Algorithmics, Murex, R, SAS, and multiple third-party ISV applications.
Benefits
The following are the benefits of the solution:
Reliability Platform Symphony delivers critical software infrastructure to enable a PaaS for enterprise risk applications
Dynamic provisioning Application services are deployed rapidly based on real-time application demand and subject to policy.
Multi-tenancy Platform Symphony enables multiple LOBs with diverse workload to efficiently share resources with commercial applications, homegrown applications, Platform LSF, Platform MPI, Corba, JMS applications, and so on.
High utilization Symphony maximizes use of data center assets, and can opportunistically harvest capacity on desktops, production servers, and VMware or Citrix server farms without impacting production applications.
Instrumentation Clear visibility to assets and applications, and usage patterns within the data center or around the globe.
Heterogeneity Platform Symphony runs across multiple operating environments and supports multiple APIs including C, C++, C#/.NET, Java, R, and Python. It also supports popular IDEs, enabling rapid integration of applications at a lower cost than competing solutions.
9.3.3 Real-time pricing and risk
It is common that traders and analysts lack the simulation capacity needed to adequately simulate risk, thus leading them to use less-precise measures. This leads to missing market opportunities because of the inability to compute risk adequately and in a timely fashion. This inability to quickly simulate the impact of various hedging strategies on transactions reflects directly on reduced profitability.
An agile and flexible infrastructure for time critical problems based on real-time pricing and risk analysis is key for financial institutions struggling to maintain an up-to-date view of enterprise-wide risk.
Applicable markets
The following are the applicable markets for this solution:
•Investment banks
•Hedge funds
•Portfolio managers
•Pension funds
•Insurance companies
•Exchanges
Solution architecture
IBM Platform Symphony allocates target “shares” of resource by application and line of business, ensuring appropriate allocations based on business need. Each application can flex to consume unused grid capacity, enabling faster completion for all risk applications.
In a time-critical requirement, Platform Symphony can respond instantly, preempting tasks and reallocating over 1,000 service instances per second to more critical risk models, temporarily slowing (but not interrupting) less time critical applications.
Benefits
This solution provides the following benefits:
“Instant-on” Platform Symphony is unique in its ability to rapidly preempt running simulations and run time-critical simulations rapidly with minimal impact to other shared grids.
Low latency The combination of massive parallelism and ultra-low latency is critical to responding at market speed.
Rapid adjustments Symphony can rapidly run simulations and dynamically change resources that are allocated to running simulations. For urgent requirements, Platform Symphony can respond faster and get results faster.
9.3.4 Analytics for faster fraud detection and prevention
Due to the increasing growth of Internet-based and credit-card-related fraud, financial institutions have established strong measures to address loss prevention. This includes investing in data analytics solutions to help detect fraud and act as early as possible to record patterns to prevent fraud.
Analytics solution for credit card company
Figure 9-9 illustrates an architecture to provide an end-to-end analytics solution for credit card data. The major components in the colored boxed map are the software and hardware solutions in the IBM big data analytics portfolio.

Figure 9-9 Example use case for credit card fraud detection
IBM Platform Symphony and IBM InfoSphere BigInsights integrated solution
This sample use case was built by IBM for show at the Information On Demand (IOD) conference in October of 2012. It was based in a fictional credit card company and its solution for big data analytics workloads. The software was developed to generate synthetic credit card transactions.
A DB2 database stored details such as customer accounts, merchant accounts, and credit card transactions. To handle a high volume of transactions, IBM InfoSphere Streams was used to make real-time decisions about whether to allow credit card transactions to go through.
The business rules in Streams were updated constantly based on credit scoring information in the DB2 database, reflecting card holder history and riskiness of the locale where transactions were taking place.
To automate workflows, and transform data into needed formats, IBM InfoSphere DataStage® was used to guide key processes.
IBM InfoSphere BigInsights is used to run analysis on customer credit card purchases to gain insights about customer behaviors, perform credit scoring more quickly, improve models related to fraud detection, and to craft customer promotions. IBM InfoSphere BigInsights runs its big data workloads on a grid infrastructure that is managed by IBM Platform Symphony.
Continuous analysis run in the IBM InfoSphere BigInsights environment posts results back into the PureScale database. The results of the analytics jobs are also stored in a data mart where up-to-date information is accessible both for reporting and promotion delivery.
By using this less costly architecture, the business is able to gain insights about their operations, and use this knowledge for business advantage (Figure 9-10).

Figure 9-10 Back office integration
Description
The following are the labeled sections in Figure 9-10.
(A) Data generator generating transaction data
(B) Credit card transaction load to InfoSphere Streams
(C) InfoSphere Streams for transaction fraud detection
(D) DB2 PureScale for credit card transaction processing and storage
(E) DataStage transforms and enriches relational data:
– Update master data, unload promotion and reporting information from IBM InfoSphere BigInsights, load it to IBM PureData™ for Analytics
– Unload customer risk rating from IBM InfoSphere BigInsights, and update master data in DB2 IBM pureScale®
(F) IBM InfoSphere BigInsights Hadoop cluster for deep analysis of customer buying patterns to generate customer credit risk ratings and promotion offers using Platform Symphony for low-latency scheduling and optimal resource sharing
(G) BigSheets easy-to-use spreadsheet interface to build analytic applications
(H) IBM PureData data warehouse appliance for deep analysis of reporting data that sends out emails for promotions
Data flow
The following are the steps shown in Figure 9-10 on page 217:
1. The data generator generates credit card transactions
2. Credit card transaction approval requests
3. Streams add approved and rejected transactions into DB2 pureScale
4. DataStage unloads transaction data from DB2 pureScale
5. DataStage loads transformed and enriched transaction data into IBM InfoSphere BigInsights
6. DataStage unloads customer credit risk ratings from IBM InfoSphere BigInsights
7. DataStage updates DB2 pureScale with customer credit risk ratings
8. DataStage unloads promotion offers from BigInsights
9. DataStage loads transformed and enriched reporting data to IBM PureData for Analytics data warehouse appliance
10. BigSheets analytic applications access and process customer credit card transaction history
Benefits
The solution has the following benefits:
•Multi-tenancy
•Performance
•Heterogeneity
•Improved flexibility
9.4 Third-party integrated solutions
This section provides an overview of the independent software vendor (ISV) software that can be used to solve common financial workloads, and how it can be used with the reference architecture presented in 9.2, “Architecture” on page 203.
9.4.1 Algorithmics Algo One
Algorithmics is a company that provides software solutions to financial problems to multiple customers around the world through its ALGO ONE framework platform. Their goal is to allow users to simulate scenarios and understand risks that are associated with them so that a better decision can be made for minimizing risks.
The solutions that are provided by the ALGO ONE platform can be divided into four categories as shown in Table 9-1.
Table 9-1 Software services provided by the ALGO ONE platform
|
Scenario
|
Simulation
|
Aggregation
|
Decision
|
|
•Stress scenarios
•Historical scenarios
•Conditional scenarios
•Monte Carlo scenarios
|
•Riskwatch
•Specialized simulators
•Custom models
•Hardware acceleration
|
•IBM Mark-to-Future®
•Netting and collateral
•Portfolios
•Dynamic Re-balancing
|
•Risk & Capital Analytics
•Real Time Risks & Limits
•Optimization
•Business Planning and What-If
|
IBM Platform Symphony can be used as a middleware to the ALGO ONE platform of services to use Platform Symphony’s benefits as a multi-cluster, low-latency scheduler. As a result, all of Platform Symphony’s advantages that were presented in 9.2.1, “IBM Platform Symphony” on page 203 can be used by ALGO ONE services.
Figure 9-11 illustrates the interaction of ALGO ONE on a Platform Symphony managed grid.
|
Note: Other grid client applications (solutions other than Algorithmics) can also use the grid. Therefore, you do not need to create a separate computational silo to run ALGO ONE services on. It can be deployed on top of an existing Symphony grid.
|

Figure 9-11 A grid managed by Platform Symphony serving ALGO ONE and other client platforms
The following is a list of benefits of integrating ALGO ONE and Platform Symphony:
•Provides better resource utilization because the grid can be used for diverse multiple tasks at the same time, avoiding the creation of processing silos.
•Can flex grid resources depending on task priority (bigger, less critical tasks can be flexed down in terms of resources to give room to smaller, more critical tasks such as “What-If” workloads).
•Allows for the consolidation of risk analysis to provide enterprise-wide results.
•Can intelligently schedule jobs to nodes that are optimized for a particular task. This is good for credit-risk calculations that require the use of specific lightweight simulators (SLIMs) which require particular operating system and hardware configurations to run.
In summary, ALGO ONE and Platform Symphony allows financial institutions to run more rigorous simulations in shorter time and respond more quickly to time-critical events. They do this while using an easier to manage and flexible grid environment.
9.4.2 SAS
SAS is known for providing business analytics solutions. Financial institutions can use its portfolio of products to aid in decision making, credit-risk analysis, scenario simulation, forecasting of loan losses, probability of defaults on mortgages, and others.
These workloads are heavy due to the amount of data they work with, and can also be compute intensive. To address that, SAS offers its SAS Grid Computing framework for high performance analytics. SAS Grid gives you the flexibility of deploying SAS workloads to a grid of computing servers. It uses the same concept of job dispatching to a set of systems, and so it uses a resource scheduler and resource orchestrator.
SAS Grid is able to use a middleware layer composed of IBM Platform products that manages, and schedules the use of the computing resources. Figure 9-12 illustrates this architecture from a software point of view.
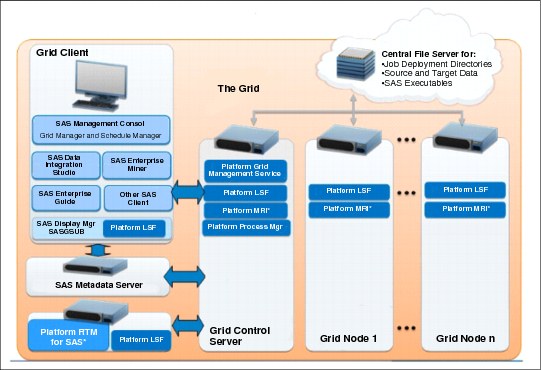
Figure 9-12 SAS Grid software architecture with IBM Platform Computing products
IBM Platform LSF is used as the job scheduler to spread jobs to the grid computing nodes. SAS workloads can make full use of Platform LSF by having it create a full session. They can also use it to, for example, query the load of a particular grid node. With this capability, it is possible for SAS applications to run workload balancing on the grid.
Platform RTM, another component in the architecture shown in Figure 9-12, can provide a graphical interface for controlling grid properties. Platform RTM can be used to perform these tasks:
•Monitor the cluster
•Determine problems
•Tune the environment performance by identifying idle capacity and eliminating bottlenecks
•Provide reporting
•Provide alerting functions specific to the Platform LSF environment
Platform Process Manager provides support for creating workflows across the cluster nodes. Platform Process Manager handles the flow management, but uses Platform LSF to schedule and run the steps of a workflow.
Lastly, GPFS can be used as a file server for job deployment directories, source and target data, and SAS executable files.
In summary, these are the benefits of using SAS Grid with the described architecture:
•Reduced complexity
•SAS workload management with sophisticated policy controls
•Improved service levels with faster analysis
•Provide high availability to SAS environments, which ensures reliable workflows and the flexibility to deploy SAS applications on existing infrastructure
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.