


IBM Platform Symphony MapReduce
This chapter describes Platform Symphony MapReduce and an outline of its benefits while running data-intensive Hadoop MapReduce workloads inside the Platform Symphony environment.
This chapter included the following sections:
4.1 Overview
This section introduces the MapReduce technology and the Hadoop architecture, and describes the IBM Platform Symphony MapReduce framework. This framework allows you to run data-intensive Hadoop MapReduce workloads inside the Platform Symphony environment. It works at high levels of performance and shared resource utilization, in a secure multi-tenant fashion, through a nice on-demand self-service web interface. This cloud-computing-specific function is provided by two sophisticated components: A scheduling engine and a resource manager that is used by an advanced management console.
4.1.1 MapReduce technology
A Hadoop MapReduce computing environment is built on top of two core components:
•Hadoop Distributed File System (HDFS) for data storage
•Hadoop MapReduce for data processing.
These two components provide affordable but performance distributed processing of large amounts of data on physical infrastructure made of low-cost commodity hardware. Such a grouping of nodes in the same data center or site and contributing together to the same computing purpose is usually referred to as a cluster. Because the infrastructure can scale out to thousands of nodes, the risk of hardware failures is high. The design addresses this situation by including automatic detection and recovery during hardware failures.
The Hadoop Distributed File System (HDFS)
HDFS is a specialized distributed file system that is optimized for files in the range between hundreds of megabytes and gigabytes, or even terabytes in size. It stores the data files on local disks in a specific format by using large file system blocks that are typically 64 MB or 128 MB. The goal behind this format is the optimization of the data processing while running the MapReduce algorithm. Consider, for example, a 10 GB file in an HDFS file system that has a 128 MB block size and is uniformly spread over 100 nodes. This file might be processed at today’s usual sequential sustained read speed of 70-80 MBps in less than 2 seconds (assuming fast enough processors, so no CPU-bound workload). For a specific application with a given average input file size and a wanted latency, you can estimate the required number of nodes for your cluster.
The data redundancy results from replication of these blocks on different nodes. The usual replication factor is three, and the nodes are chosen in such a way that not all three of them are in the same rack. HDFS implements a rack awareness feature for this purpose.
For more information about the architecture and execution environment of an HDFS file system, see 4.1.2, “Hadoop architecture” on page 62.
MapReduce algorithm
MapReduce implements a distributed algorithm that consists of separate fragments of work, each one running on a node in the cluster and processing a slice of data, preferably on that node, at the HDFS level. The processing involves phases, the most representative of which are the map phase and the reduce phase. Each of these phases consists of multiple parallel and similar fragments of work, called map tasks and reduce tasks.
Figure 4-1 shows an example of a MapReduce data flow that starts by reading its input from the HDFS and ends by writing the output results to the same file system.
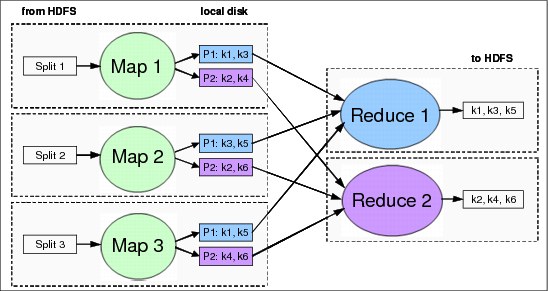
Figure 4-1 MapReduce data flow
The data in one input block (input split or just split in MapReduce terminology) does not depend on the data in any other block. Map tasks are instantiated on each node containing an input split, normally one task for each split. There might not be a perfect overlap between an input split and an HDFS block, but the framework does its best to match them. The small portion of the split that might be on a different node is transferred locally when needed.
A map function parses the records in the split and outputs an intermediate key-value pair for each processed record. The developer must incorporate the logic for the map function, considering the record format and the processing purpose. The output of the map function is written to the local file system (not to HDFS) for performance reasons.
The output of each map is partitioned to determine which part goes to each reduce task. By default, the framework hashes the keys to select the destination reduce task. All the intermediate pairs that have a particular key are sent to the single reduce task to which the hash function has associated the respective key.
Local aggregation of the intermediate outputs might also be specified by the user in a combiner operation. This minimizes the network traffic in the subsequent shuffle stage.
The number of reduce tasks is determined by the Hadoop framework. The series of intermediate key-value pairs can now be sent to the reduce tasks. This constitutes the shuffle stage.
Now that all intermediate data is partitioned and transferred to the reduce function, an extra merge operation is run by the framework before the data enters the final reduce tasks. As key-value pairs with the same key might have been delivered from different maps, this merge operation regroups and resorts them. A secondary sort by value might be specified here, before the final reduction, with a so-called comparator function.
The reduce tasks consolidate results for every key according to a user implemented logic, and these results are finally written to the HDFS.
4.1.2 Hadoop architecture
In this section, the two core components of the Hadoop MapReduce environment are put together in a functional architecture diagram. It also mentions some higher-level applications that make the environment truly usable in concrete situations.
Hadoop MapReduce execution environment
The execution environment for the involved tasks is presented in Figure 4-2. It introduces the entities that are involved and their operation in the workflow. A MapReduce job is a self-contained unit of work that a user wants to be performed on a set of input data, usually one ore more files, which are stored in the HDFS file system.
The job is initially specified by the user, and consists of the input data, the MapReduce application, an output directory, and possibly extra non-default Hadoop framework configuration information. The job is submitted to the MapReduce framework, which is a combination of the master node and the compute nodes. The master node runs a process called JobTracker that takes the request from the user and coordinates the job execution flow process. The JobTracker schedules other processes on compute nodes called TaskTrackers. As detailed in “MapReduce algorithm” on page 60, Hadoop runs the job by dividing it into two sets of tasks: Map tasks and reduce tasks. The TaskTracker processes start, each on its own compute node, and with its associated map and reduce tasks. They monitor the local data processing tasks, and send progress reports to the JobTracker.
The JobTracker monitors the overall progress of the execution flow. If a TaskTracker fails, the JobTracker reschedules its task to a different TaskTracker. The JobTracker maintains its state on the local drive.

Figure 4-2 MapReduce execution environment
The Hadoop framework initially processes the arguments of a job and identifies the nodes where the HDFS blocks containing the bulk input data are. Data splits are derived from the considered blocks on the identified nodes, and presented to the input of the map tasks. As explained in “MapReduce algorithm” on page 60, there might not be a perfect match between a MapReduce split and an HDFS data block. Limited network traffic might appear to feed the map task with the data fragments in the split that is not stored locally. The overall effect of the data locality is a significant optimization because valuable cluster network bandwidth is preserved.
This is the typical way that the framework schedules the map tasks on the chosen nodes. There might be situations when all of the three nodes that store the HDFS block replicas of an input split are already running map tasks for other splits. In this case, the JobTracker tries to allocate a node as close as possible to one of the replicas behind the input split, preferably in the same rack. If this is not possible, an available node in a different rack might be used, resulting in some inter-rack network data transfer.
In a typical Hadoop deployment, the JobTracker and NameNode processes run on the same node. If there is a lot of data or lots of files in the HDFS, separate the processes because the NameNode needs dedicated system memory. Similarly, for the SecondaryNameNode, you can typically run it on the same node as the NameNode. However, if memory requirements for the NameNode are high, it is more appropriate to choose a separate node for the SecondaryNameNode. The SecondaryNameNode does not play a direct failover role. It actually provides a service to manage HDFS state files in case recovery is needed.
High-level Hadoop applications
The MapReduce framework is written in Java programming language. Using it at the low level of the map and reducing Java class methods is a meticulous and time consuming activity. It is similar to assembly language, where you must write a lot of code to implement simple operations. However, technologies using this framework at a higher level of abstraction have been developed. The following open source tools are supported with Hadoop MapReduce in the Platform Symphony MapReduce framework: Pig, Hive, Hbase, and Zookeeper. Figure 4-3 shows them on top of the basic Hadoop MapReduce core components.

Figure 4-3 Hadoop system
4.1.3 IBM Platform Symphony MapReduce framework
The MapReduce framework is depicted in Figure 4-4 along with the other components of the Platform Symphony high-level architecture. The Platform Symphony MapReduce framework has been added as a core component and has been tightly integrated with the existing standard core components: SOA framework, scheduling engine, resource orchestrator, and management console.
Before adding the MapReduce functions, the standard Symphony product exposed its low-latency service-oriented architecture (SOA) framework to interactive compute-intensive applications. These were the kind of applications it was originally targeted to support. These are still valid and supported, but additionally, the same SOA framework can also support MapReduce data-intensive applications, which are similar in their workflow structure. The SOA framework implements this common workflow structure by running on top of the scheduling engine, which gets computing resources from the resource orchestrator. These core components are augmented to become a complete enterprise environment with the monitoring, administering, and reporting features of the management console. The core components are colored green in Figure 4-4 to make them more visible. For more information about all these components, see Chapter 3, “IBM Platform Symphony for technical cloud computing” on page 29.
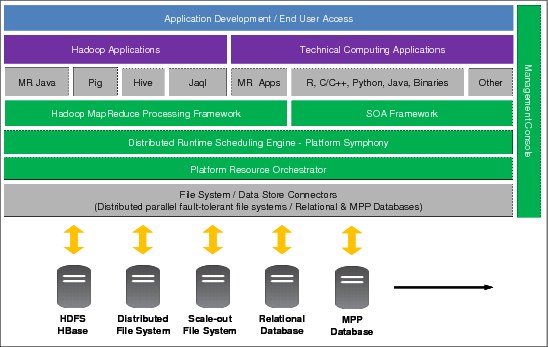
Figure 4-4 Platform Symphony MapReduce framework
With this new MapReduce layer, Platform Symphony can integrate and run external high-level Hadoop-related applications. These applications run on top of the MapReduce framework. These applications are not delivered with the Platform Symphony installation bundle, and must be installed separately. Platform Symphony supports both the Apache Hadoop open software bundle and commercial distributions that are based on it such as IBM InfoSphere® BigInsights.
At the bottom of Figure 4-4, you can also see a distinct layer of data storage connectors that are needed for the integration of various distributed file systems and other sources of data. The MapReduce data-intensive applications are going to use these systems while processing their considerable amounts of input data. The storage connectors integrate Platform Symphony with different file and database systems such as HDFS, GPFS, Network File System (NFS), and the local file system.
Integration with the underlying SOA middleware
Figure 4-5 shows the Platform Symphony MapReduce framework at a first level of detail, revealing its consistency with the Hadoop MapReduce logic flow. The important capability here is that more application managers, which each correspond to a JobTracker, can coexist in the same infrastructure. This means that distinct MapReduce job queues can run simultaneously and share infrastructure resources, each of them with its own set of MapReduce jobs. Another aspect highlighted in Figure 4-5 is that the various components involved in the case of a data-intensive MapReduce application must implement more functionality compared to the standard SOA compute-intensive case. This is required to provide access, when and where needed, to the data in the distributed shared storage.

Figure 4-5 Platform Symphony MapReduce framework
Each application manager corresponds to a distinct application registered on a distinct consumer in the hierarchy of consumers that are configured on the grid. Application manager is just another term that is used inside the MapReduce framework for the service session manager (SSM) at the SOA level. The map and reduce tasks are also simple tasks at the SOA level, each served by its own instance of the MapReduce service.
There are many SOA framework terms and notions, only some of which are covered in this chapter. Figure 4-6 depicts a generic view of the SOA framework with its main components. To run an application, a user submits a job to the grid through the client component of this application. The client-side code uses the SOA API to locate the session manager of the application. For this, the API contacts a system service or session director that is aware of all the configured applications in the grid. If not already available, the session manager is instantiated by the service director. There is only one session manager per application. The client communicates from now on with the session manager.

Figure 4-6 Service-oriented application middleware components
A session is created for the particular job submitted by the client. The client gets a handle for this session, and through this handle the client code requests a number of tasks to be scheduled on the grid. The objects that are created inside the SOA framework to manage a particular session are shown in Figure 4-7.

Figure 4-7 SOA application objects
The session manager transmits the scheduling request to the scheduling engine, which decides according to the resource distribution policy and other scheduling attributes associated with the application, the CPU slots, and their locations on the compute nodes, for the requested tasks. The session manager is then able to dispatch a corresponding number of session instance managers (SIM) and service instances of the service that is associated with the application involved. There is one service instance per task, that is locally monitored on the hosting compute node by an associated SIM. The session manager manages and monitors all the SIMs associated with any of its sessions. If another job of the same application is submitted in parallel, a new session is created by the same session manager, and the whole task scheduling process is repeated. Tasks in multiple sessions then compete for the resources that are allocated to the same application. A scheduling framework is available for the sessions of an application. This is a separate scheduling layer on top of the overall resource distribution layer that schedules the resources of the whole grid to the active applications registered by all the defined consumers.
Platform Symphony MapReduce work and data flow
The execution workflow of a MapReduce job in a Platform Symphony environment is shown in Figure 4-8. It has similarities and the differences compared with the Apache Hadoop approach as detailed in “Hadoop MapReduce execution environment” on page 62. Notice the SOA framework specific to Platform Symphony in which the client side of the MapReduce application interacts through a well-defined interface with the service component of the same MapReduce application and MRService deployed in the cluster. The mapping of the standard Hadoop MapReduce entities to the SOA middleware objects playing equivalent roles is also similar. The SSM is in the role of the JobTracker, while various SIMs act as TaskTrackers. Multiple instances of the Platform Symphony MapReduce service run concurrently on compute nodes in the cluster.
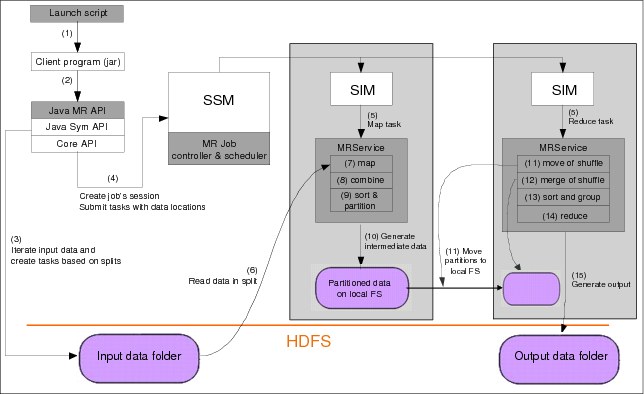
Figure 4-8 Symphony MapReduce work and data flow
When a MapReduce job is submitted by a client, preliminary processing is performed in the client’s local environment to identify the splits of the input files and the required map tasks. A session is then created by the session manager for that job, consisting of map tasks that are dispatched on compute nodes according to the split locations previously identified. Reduce tasks are also dispatched in the session, as required.
The computation entities providing either map or reduce logic, which is based on the received task type, are MRService service instances. The SSM creates one SIM for each task, and the SIM then instantiates a corresponding MRService instance. A SIM is responsible for managing the lifecycle of a service instance and for routing client messages between the session manager and its associated service instance.
Each MRService service instance loads the application .jar file received from the client and implements the logic for the configured task type. For the map task, the MRService reads data records from the split that is passed as task input, then starts the application Mapper (and optionally Combiner) functions. It finally stores its intermediate data output to local files. The intermediate data are partitioned depending on the way the intermediate keys are associated with the reduce tasks.
For the reduce task, the MRService instance asks the MapReduce shuffling service (MRSS) to get intermediate map output data for the related keys. It then merges and sorts the received data. The MapReduce shuffling service is a special MapReduce data transfer daemon that runs as a Symphony service on each host. The daemon optimizes local memory and disk usage to facilitate faster shuffling processes for map task output data to local and remote reduce tasks.
The reduce task then applies the user-defined Reducer logic to this merged and sorted data. The result is written to the output destination specified in the reduce task argument.
API adapter technology
The MapReduce framework allows Apache Hadoop MapReduce compatible applications to use Platform Symphony scheduling engine without any changes in the application code or any recompilation. This is obtained by inserting an application adapter layer in the original Hadoop MapReduce software stack as shown in Figure 4-9. The Hadoop MapReduce application calls the same Hadoop MapReduce and Hadoop Common Library APIs.

Figure 4-9 MapReduce application adapter
To route these calls through the MapReduce Application Adapter, preliminary configuration is needed before starting the applications. Normally, perform this configuration at installation time. The User Guide for the MapReduce Framework, GC22-5370-00, recommends that you completely install and configure the Hadoop distribution before you install Platform Symphony on the cluster nodes. This simplifies the steps of this integration configuration.
The initial step consists of some settings in the shell environment, and then at the MapReduce application level inside Platform Symphony.
As a second step, you might have to remove some system or platform dependencies at the Hadoop application level. Application classes and Hadoop base classes might come packaged into the same .jar (or .war) file. The Java class loader looks first at the classes in the .jar files that are already loaded in the JVM together with application classes. Therefore, you must repackage the application in its own .jar file, separating the Hadoop classes. This applies, for example, to Pig and Oozie applications.
For a complete list of the supported Apache Hadoop applications and their detailed repackage steps, see Integration Guide for MapReduce Applications, SC27-5071-00. The Platform Symphony documentation also contains details about integration with some commercial Hadoop distributions, including IBM InfoSphere BigInsights and Cloudera CDH. For examples of Apache Hadoop and IBM InfoSphere BigInsights integration with Platform Symphony see Chapter 5 - IBM Platform Symphony in IBM Platform Computing Solutions, SG24-8081, and Chapter 2 - Integration of IBM Platform Symphony and IBM InfoSphere BigInsights in IBM Platform Computing Integration Solutions, SG24-8081.
Figure 4-9 on page 69 shows that both the standard Hadoop stack and the application adapter use the Hadoop common library for HDFS, and for other file systems such as GPFS or NFS if configured. The MapReduce framework in Platform Symphony also provides storage connectors to integrate with different file systems and databases.
Figure 4-10 shows when and where in the workflow of a submitted MapReduce job the various portions of the code are used: From the application itself, from the core Hadoop components, or from the Platform Symphony application adapter.

Figure 4-10 Application adapter in the MapReduce workflow
4.2 Key advantages for Platform Symphony MapReduce
This section describes some of the advantages of the Symphony MapReduce framework compared to the standard open source Apache Hadoop environment, and other commercial distributions of the Hadoop environment. It also describes the advantages from a cloud-computing perspective because the Platform Symphony product offers multi-tenancy, resource sharing, low-latency scheduling, and heterogeneous features. For more information about these topics in the larger context of the Platform Symphony product, see 3.7.1, “Advantages of Platform Symphony in Technical Computing Cloud” on page 56. This section focuses on features that are directly related to the MapReduce component. The following key features make Platform Symphony MapReduce a good MapReduce framework option:
•Performance: A low latency architecture allows a much higher performance for certain workloads (jobs).
•Dynamic resource management: Slot allocation changes dynamically based on job priority and server thresholds, loaning, and borrowing.
•Sophisticated scheduling engine: A fair share scheduling scheme with 10,000 priority levels can be used for multiple jobs of the same application. Also, pre-emptive and resource threshold-based scheduling is available with runtime change management.
•Management tools: Platform Symphony provides a comprehensive management capability for troubleshooting alerting and tracking jobs, and rich reporting capabilities.
•Reliability: Platform Symphony makes all MapReduce and HDFS-related services highly available such as name nodes, job trackers, and task trackers.
•Application lifecycle: There is support for rolling upgrades for Platform Symphony. Also, multiple versions of Hadoop can coexist in the same cluster.
•Open: Platform Symphony supports multiple APIs and languages. It is fully compatible with Java, Pig, Hive, and other MapReduce applications. Platform Symphony also supports multiple data sources, including HDFS and GPFS.
The following sections present these features in more detail.
4.2.1 Higher performance
Significant performance improvement for the Symphony MapReduce framework is expected for most of the MapReduce jobs when compared with the open source Hadoop framework, especially for the short-run jobs. This improvement is based mainly on the low latency and the immediate map allocation plus the job startup design features of the SOA framework. Platform Symphony also has some performance optimizations for specific components of the Symphony MapReduce framework such as the intermediate data shuffling operation run between the map and reduce phases.
For more information about performance comparison tests and benchmarks that are run on IBM Platform Symphony, see:
Low latency
Low-latency is one of the key features of the Platform Symphony MapReduce framework. It comes directly from the approach that is used in SOA, which was designed as a low latency architecture for managing compute-intensive applications. The demand for such an architecture came from the financial services space, particularly from the investment banking. Such analytics infrastructure was needed to run jobs such as Monte Carlo simulations, risk analysis, and credit validations, in a more interactive, near real-time manner.
The latency of the open source Hadoop engine is determined by the broker logic it uses. The broker, which is the JobTracker, runs as a service that is waiting for notifications and requests from the individual TaskTrackers.
A heartbeat mechanism is implemented between the JobTracker and its monitored TaskTrackers. All TaskTrackers must signal to the JobTracker that they are alive by sending periodical heartbeat messages to the JobTracker. The JobTracker declares a TaskTracker as 'lost' if it does not receive heartbeats during a specified time interval (default is 10 minutes). Tasks in progress that belong to that TaskTracker are then rescheduled.
Extra information is piggybacked on the heartbeat messages for various other purposes. For example, task status information is conveyed from the TaskTracker to the JobTracker. When task reports progress, status flags and progress counters are updated inside the TaskTracker. These flags and counters are sent more or less frequently through these heartbeat messages to the JobTracker. The JobTracker uses them to produce a global view with the status of all the running jobs and their constituent tasks.
A TaskTracker indicates when one of its tasks finishes and whether it is ready to receive a new task through the same heartbeat messages. If the JobTracker allocates a task, it communicates this to the TaskTracker by a heartbeat return value.
In initial versions of open source Hadoop, the task trackers sent heartbeats at 10 second intervals. Later versions made the heartbeat interval variable. It became dependent on the size of the cluster and had to be calculated dynamically inside the JobTracker. A minimum heartbeat interval limit of 3 seconds was enforced by this computation. For larger clusters, the computed interval was longer, as intended. But for short run map tasks, this still resulted in an underused cluster. To improve latency on small clusters, the default minimum heartbeat interval has been lowered, starting with release 1.1, from 3 seconds to 300 ms. Reducing this interval even more is problematic, though, because the higher the heartbeat rate, the more processor load the JobTracker must handle, so it might become unresponsive at high load.
A new option was also introduced to allow the TaskTrackers to send an out of band heartbeat on task completion. For jobs with short tasks, the JobTracker can get flooded with too many heartbeats completions, so there is an out of band heartbeat option to mitigate too many completion heartbeats.
Overall, these heartbeat interval changes were meant to improve the scheduling throughput. But the polling logic and the minimum limit of the heartbeat interval determine the job latency. The heartbeat exchange between the JobTracker and the TaskTrackers uses the HTTP protocol as a communication vehicle, and slow, heavy-weight XML data for encoding text messages. This affects the scalability because the JobTracker cannot respond if the heartbeat interval is too small.
Therefore, the polling window approach used in Hadoop has this disadvantage of wasted time, which becomes more critical in the case of short run jobs. The polling window takes a significant amount of time to allocate work to the individual tasks or the individual TaskTrackers, compared with the duration of the task itself.
The Platform Symphony deal with this problem in a much more efficient way. Symphony uses a different approach, called the push model, which is an interrupt-based type of logic. When a service instance completes a piece of work, the SSM immediately pushes a new piece of work to that instance. This results in milliseconds of response time in terms of latency. Platform Symphony encodes data in a more compact binary format and uses an optimized proprietary binary protocol to communicate between the SSM and the service instances. Being implemented in C++, the protocol allows fast workload allocation and minimal processor load to start jobs when compared to the Hadoop open source approach, which is written in Java.
For more information about this core feature of the SOA framework, see Figure 3-2 on page 32 and 3.2.1, “Compute intensive applications” on page 31.
Optimized shuffling
For the shuffling phase, MapReduce framework uses a Symphony service that runs on each host as a special MapReduce data transfer daemon (shuffling service-MRSS). The daemon optimizes local memory and disk usage to facilitate faster shuffling processes for map task output data to local and remote reducer tasks. This optimized shuffling works especially well for jobs where map output data can be kept mostly in memory and retrieved by reducers before the next rounds of mapper tasks generate more output.
The shuffling optimization has potential of improving the things by this memory leveraging on the individual nodes in three related areas. The map tasks basically run on the input split data and have as output an intermediate data set. This intermediate data set is kept in memory as much as possible instead of running it out to the local disk, reducing the number of I/O cycles that are associated with writes. If it is too large for the available memory, it goes to disk. When, during the shuffle phase, this data must traverse the network, they is retrieved from memory rather than from disk. Similarly, on the reducer side, instead of writing them to disk, they are stored in memory, if possible. When, finally, the reducer reads these data, they are there in memory, again saving I/O cycles.
This works well for a significant number of MapReduce jobs because their map outputs are not large compared with the current affordable memory sizes in typical technical computing nodes. The generated output tends to be much smaller, in the order of GB, for example, or even less. As shown in Figure 4-11, intermediate data is kept in memory if possible, contributing to the overall performance advantages brought by fast low-latency scheduling and data movement. All these explain how Platform Symphony can improve the speed of even workloads like TeraSort that are not overly sensitive to scheduling latency.

Figure 4-11 Speeding up iterative MapReduce patterns
There exists, also, a class of MapReduce jobs where the overall output is minimal as well and can be kept in memory. Loop-invariant data is kept in memory, if possible, between iterations, further improving the performance speed. As an example, Platform Symphony behaves well on workloads like K-Means that are iterative and use the output of one MapReduce workload as inputs to the next.
The last class of MapReduce jobs are those that repeatedly read common data input splits. By caching the input splits at the first iteration of a job, subsequent iterations reuse the cached input split as input. This process avoids fetching the same data from the HDFS repeatedly. Analytics applications that support iterative algorithms and interactive data mining benefit from this feature.
Data input splits of a map task are mapped to system memory and to a file on the local disk (specified as the PMR_MRSS_CACHE_PATH environment variable). If this cache is not accessed for a time period (specified as PMR_MRSS_INPUTCACHE_CLEAN_INTERVAL) or exceeds the maximum memory limit (specified as PMR_MRSS_INPUTCACHE_MAX_MEMSIZE_MB), the least recent split and its associated local disk files are deleted. You must adapt these specified parameters to the available memory. To enable a job to get its input split from the cache, you must set these caching options in the shuffle service (mrss) definition file before you submit the job.
4.2.2 Improved multi-tenant shared resource utilization
In Platform Symphony Advanced Edition, up to 300 MapReduce runtime engines (job trackers) can coexist and use the same infrastructure. Users can define multiple MapReduce applications and associate them with resource consumers by “cloning” the default MapReduce application. Each application has its separate and unique Job Tracker (SSM). When multiple SSMs are instantiated, they are balanced on the available management nodes. Furthermore, inside each application, simultaneous job management is possible because of the special design that implements sophisticated scheduling of multiple sessions on the resources that are allocated for an application. This function is obtained by separating the job control function (workload manager) from the resource allocation and control (Enterprise Grid Orchestrator). The new YARN, Apache Hadoop 2, has a similar feature, but this release is still in alpha stage. The stable release of Hadoop MapReduce offers only one Job Tracker per cluster.
Moreover, multi-tenancy is much more than just multiple job trackers. It is about user security, shared and controlled access to the computing resources and to the whole environment, monitoring and reporting features, and so on. These multi-tenancy features are addressed as they are implemented by the Platform Symphony product.
Users and security
To allow users to use resources when running their applications in a managed way, Platform Symphony implements a hierarchical model of consumers. This tree of consumers allows association of users and roles on one hand with applications and grid resources on the other. Policies for the distribution of resources among multiple applications run by different users can be configured this way to share the resources in the grid.
MapReduce applications, and other non-MapReduce applications such as standard SOA compute-intensive applications, inside Platform Symphony can use the same infrastructure. In addition, a multi-head installation of both Platform LSF and Platform Symphony is supported. This installation allows batch jobs from LSF, and compute-intensive and data-intensive applications from Symphony to share the hardware grid infrastructure.
A security model is enforced for the authentication and authorization of various users to the entitled applications and to isolate them when they try to access the environment. You can create user accounts inside the Platform Symphony environment, as shown in Figure 4-12, then assign to them either predefined or user created roles. User accounts include optional contact information, a name, and a password.

Figure 4-12 Creating user accounts
Symphony has four predefined user roles that can be assigned to a user account:
•Cluster administrator
A user with this role can perform any administrative or workload-related task, and has access to all areas of the Platform Management Console and to all actions within it.
•Cluster administrator (read only)
This user role allows read-only access to any cluster information, but cannot perform any add, delete, or change action.
•Consumer administrator
Users with this role are assigned to a top-level consumer in the consumer hierarchy, and can administer all subconsumers in that branch of the tree.
•Consumer user
Consumer users are assigned to individual consumers on the tree, and have access and control only over their own workload units.
You can also create customized user roles and use them in addition to the predefined roles. You can choose from a set of predefined permissions and apply them to new or existing user roles. There are cluster-wide permissions or per consumer permissions, for one or more consumers in the hierarchy as shown in Figure 4-13.
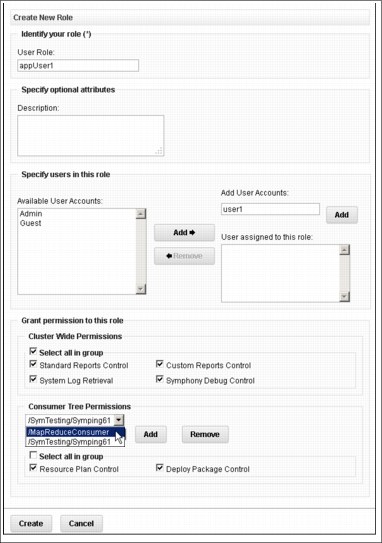
Figure 4-13 Creating user roles
To submit a workload for an enabled application, a user must have appropriate roles and permissions. When a user account is added to more roles, the permissions are merged. To configure such a setup, you need an administrator role with the correct permissions.
Sharing resources
An application can be used only after it is registered and enabled. You can only register an application at a leaf consumer (a consumer that has no subconsumers). Only one application can be enabled per consumer.
Before you can register an application, you must create at least one consumer, and deploy the service package of the application to the intended consumer. You can deploy the service package to a non-leaf consumer so that all applications registered to child leaf consumers are able to share the service package. A service package is created that puts all developed and compiled service files and any dependent files associated with the service in a package.
Resource distribution plan
In this step, you relate the resources themselves to the consumer tree and introduce the resource distribution plan that details how the cluster resources are allocated among consumers. The resource orchestrator distributes the resources at each scheduling cycle according to this resource distribution plan. The resource plan takes into account the differences between consumers and their needs, resource properties, and various policies about consumer ranking or prioritization when allocating resources.
You must initially assign bulk resources to consumers in the form of resource groups to simplify their management. Later you can change this assignment. Resource groups are logical groups of hosts. A host in a resource group is characterized by a number of slots. The number of slots is a variable parameter. When you choose a value for it, the value must express the degree of specific workload that the host is able to serve. A typical slot assignment is, for example, the allocation of one slot per processor core.
After it is created, a resource group can be added to each top-level consumer to make it available for all the other subconsumers underneath. Figure 4-14 shows an example of a consumer tree with all its top-level consumers and their assigned resource groups and users. Platform Symphony provides a default top-level consumer, MapReduceConsumer, and a leaf-consumer, MapReduceversion, which in this example is MapReduce61.
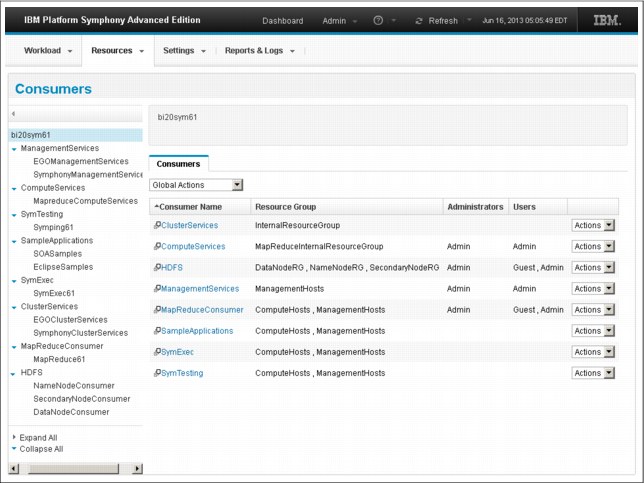
Figure 4-14 Consumer tree
The concepts that are used inside a resource distribution plan, as shown in Figure 4-15, are ownership, borrowing and lending, sharing, reclaiming of borrowed resources, and rank:
•Ownership: The guaranteed allocation of a minimum number of resources to a consumer.
•Borrowing and lending: The temporary allocation of owned resources from a lending consumer to a consumer with an unsatisfied demand.
•Sharing: The temporary allocation of unowned resources from a “share pool” to a consumer with an unsatisfied demand.
•Reclaiming: Defines the criteria under which the lender reclaims its owned resources from borrowers. The policy can specify a grace period before starting the resource reclaim, or the policy can specify to stop any running workload and reclaim the resources immediately.
•Rank: The order in which policies are applied to consumers. Rank determines the order in which the distribution of resources is processed. The highest ranking consumer receives its resources first, borrows resources first, and returns borrowed resources last.

Figure 4-15 Resource plan
The first allocation priority is to satisfy each consumer's reserved ownership. Remaining resources are then allocated to consumers that still have demand. Unused owned resources from consumers willing to lend them are then allocated to demanding consumers that are entitled to borrow. The resource orchestrator then allocates the unowned resources from the share pool to consumers with unsatisfied demand and entitled to this type of resources.The resources from the “family” pool (any unowned resources within a particular branch in the consumer tree) are allocated first. After the family pool is exhausted, the system distributes resources from other branches in the consumer tree. The free resources in the shared pools are distributed to competing consumers according to their configured share ratio. A consumer that still has unsatisfied demand and has lent out resources, reclaims them back at this stage. Owned resources are reclaimed first, followed by the entitled resources from the shared pool currently used by consumers with a smaller share-ratio. This is the default behavior. The default behavior can be changed such that owned resources are recalled first before trying to borrow from other consumers.
The resource orchestrator updates the resource information at a frequency cycle that is determined by EGO_RESOURCE_UPDATE_INTERVAL in ego.conf. Its default value is 60 seconds. At each cycle, the resource orchestrator detects any newly added resource or unavailable resource in the cluster, and any changes in workload indexes for the running jobs.
As shown in Figure 4-15 on page 79, each resource group must have its own plan. Also, you can define different resource plans for distinct time intervals of the day, allowing you to better adapt them to workload patterns. At the time interval boundary, the plan change might determine important resource reclaiming.
For more information about sharing resources, see 3.4, “Advanced resource sharing” on page 42. For in-depth coverage, see Cluster and Application Management Guide, SC22-5368-00.
MapReduce scheduling policies
In addition to the sophisticated hierarchical sharing model of resources among consumers and applications, you can also schedule resources of an application among the multiple sessions that can run simultaneously, and also, at the session level, among the tasks of a session. For more information about the general scheduling approach within an application of the Platform Symphony SOA framework, see 3.3.5, “Job scheduling algorithms” on page 39. Two of the SOA framework scheduling policies are used by MapReduce applications: Priority scheduling and proportional scheduling. These policies are further tailored for MapReduce workload, and are introduced here with some of these specific MapReduce extensions.
After it is allocated to a running MapReduce application, its resources are further split into the map pool and the reduce pool. This split is based on the map-to-reduce ratio parameter that is specified in the application profile. Each pool is divided among the jobs (sessions) of the application depending on the configured policy type:
•For priority scheduling, the job with the highest priority gets as many slots from each pool as it can use before other jobs get resources. The allocation then continues with the next jobs, in decreasing order of their priority.
•For proportional scheduling, each job gets a share in each pool that is proportional to its relative priority compared to the priorities of the other jobs.
Up to 10,000 levels of prioritization are supported for the jobs of an application, 1 being the lowest priority level, and 5000 the default value. The priority can be modified while the job is running from the console GUI or from the command line. Hadoop’s priorities (mapred.job.priority) are directly mapped to values in this range as follows:
VERY_LOW=1
LOW=2500
NORMAL=5000
HIGH=7500
VERY_HIGH=10000
At each scheduling cycle, resources that are already assigned might be reassigned from one job to another based on a preemption attribute of each job, which can take a true or a false value. If true, the session can reclaim resources from other overusing sessions. If the deserved share of resources of a demanding job is not available and the preemption value is false (the default), that job must wait for a current running task to finish before resources can be served.
When a preemptive job reclaims resources and the system finds multiple sessions or tasks that can provide slots, even after considering preemption ranks or session priorities, other attributes can be used to decide which task to interrupt to reclaim a resource. You can use the “enableSelectiveReclaim” and “preemptionCriteria” attributes. Jobs notified that their tasks will be interrupted get the chance to clean up and finish its involved tasks in a configurable timeout interval. If this grace period expires, the tasks are ended and requeued to pending state.
For more information about this scheduling topic and related attributes and policies, see the Version 6 Release 1.0.1 product manuals of the User Guide for the MapReduce Framework and Platform Symphony Reference, GC22-5370-00.
Data locality
The map tasks input data splits (in more replicas, usually three) are pseudo-randomly distributed on the HDFS nodes, which are also compute nodes in the Platform Symphony cluster. The nodes themselves are commonly spread across many racks and, can be spread across different data centers, as shown in Figure 4-16.
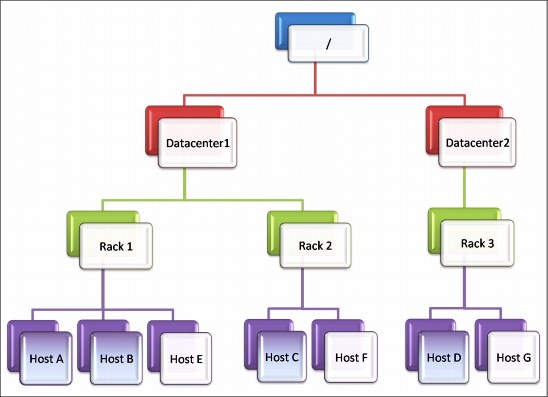
Figure 4-16 Network topology tree
Communication between two nodes in the same rack goes usually through a top rack switch. Communication between nodes in distinct racks might involve expensive bandwidth in external core switches and other networking resources. If you organize hosts while scheduling resources in such a way that the traffic between nodes in the same rack is favored over the traffic between nodes in different racks, performance and resource utilization improves. Platform Symphony implements this function through a rack-aware scheduling feature. A network topology of the cluster in the form of a tree (Figure 4-16 on page 81) is derived from physical location information that is provided by user-defined topology scripts. This tree provides a network “distance” concept between compute nodes as the sum of their distances to their closest common ancestor node in the tree.
When a MapReduce job is submitted, the SSM produces a list of preferred hosts that consists of those that store the replicas of the input data splits. This information is submitted to Enterprise Grid Orchestrator (EGO) along with the appropriate allocation request of slots for the map tasks. For each input split and preferred host apart, a check is then made by EGO, looking for available slots. If they are not available, EGO checks for slots on hosts that are closest to the preferred host by searching breadthwise across the preferred host's parent in the topology tree. If slots are still not available, it looks up the parent's parent, and so on. In the same request, the SSM also provides preferences for reduce tasks to be placed on the same resources as related map tasks, or as close as possible. This minimizes the network traffic during shuffling of intermediate data.
EGO tries to satisfy all the allocation requests from multiple applications by taking into account extra data locality preferences in the case of the MapReduce applications. Upon receiving the allocated slots, the SSM schedules the map tasks with the “closest” input data locality using the same “distance” between hosts. At the same time, the SSM also tries to schedule reduce tasks evenly among allocated hosts, and place reduce tasks closer to related map tasks.
When reclaiming resources from a MapReduce application, SSM first tries to reclaim resources from a map task with the farthest input data distance or, depending on the ratio between the total number of map and reduce tasks, from a reduce task running farther from any related map task.
After the tasks are dispatched to the hosts, use the console GUI to view the type of match, whether node-local, rack-local, or off-rack, on the task's Summary tab.
Interactive management
All the management tasks can be performed from either the web-based Platform Management Console GUI or from the command line.
This section addresses some of the most interesting management tasks, emphasizing the high level of interactivity with the running jobs and applications. For example, the resource distribution plan that was introduced in “Resource distribution plan” on page 78 can be modified online, while applications are running their workloads. The EGO resource manager takes care of all changes and controls all the reassignment and reclaiming tasks that might be performed.
Another related feature is the administrative control of running jobs. Actions like Suspend, Resume, and Kill can be performed at Job and Task level, on top of the usual Monitoring, Monitoring, Troubleshooting, and Reporting features. Even the priority attributes of running MapReduce jobs can be changed online, making the environment highly interactive when this kind of prioritization requirement is needed.
4.2.3 Improved scalability
The scalability of an enterprise MapReduce grid computing environment is an important feature as business requirements usually grow. You must make sure that the continuously increasing workload does not saturate your application, middleware, and hardware infrastructure. However, just building a larger cluster is not enough because you also need to be able to keep the cluster fully busy and to operate all these resources efficiently. The following critical performance and scalability limits are supported by the Platform Symphony 6.1 as a whole, and by its MapReduce runtime engine:
•10,000 physical servers per cluster
•40,000 cores per cluster
•10,000 cores per application
•100,000 cores in multicluster configurations
•40,000 service instances (concurrent tasks) per cluster
•1,000,000 of pending tasks per cluster
•1 ms delivered latency for grid services
•17,000 tasks per second as enabled throughput
•1,000 instances per second as rate of service instances reallocation
•300 MapReduce applications (SSMs, JobTrackers) per cluster
•1000 concurrent jobs per MapReduce application
•10,000 discrete priorities for the jobs of a MapReduce application
•20,000 slots per SSM
These values are taken from the product manuals and the availability announcement of IBM Platform Symphony 6.1 software product:
4.2.4 Heterogeneous application support
Platform Symphony provides an open application architecture that is based on the SOA framework that allows compute-intensive and data-intensive applications to run simultaneously in the same cluster. Up to 300 separate MapReduce applications (Job Trackers) can share the grid resources with other types of distributed applications, simultaneously. This allows customers to use both existing and new resources, and maximize their IT infrastructure while maintaining a single management interface.
The MapReduce framework in Platform Symphony is built on an open architecture that provides 100% Hadoop application compatibility for Java based MapReduce jobs. The application adapter technology that is built into the product delivers seamless integration of Hadoop applications with Platform MapReduce so that jobs built with Hadoop MapReduce technology (Java, Pig, Hive, and others) require no changes to the programming logic for their execution on a grid platform. For more information about the integration of third-party applications to the MapReduce framework, see “API adapter technology” on page 69.
This Symphony MapReduce open architecture also provides methods for using multiple file system types and database architectures. Storage connectors, as they are called, allow integration with IBM General Parallel File System (GPFS), Network File System (NFS), local file system, and other distributed file system types and data types. In addition, for MapReduce processes, the input data source file system type can be different from the output data source file system. This provides support for many uses, including extract, transformation, and load (ETL) workflow logic.
Well-documented SOA APIs allow seamless integration of applications that are written in other languages and software environments:
•C++
•C#, .NET
•JavaTM
•Excel COM
•Native binaries
Platform Symphony also supports other languages and environments that are commonly used in distributed computing, including Python. Plug-ins that are provided for Microsoft Visual Studio Professional support compilation-free integration of .NET assemblies. Developers can use a step-by-step wizard to integrate and test applications end-to-end without needing to be expert in the Platform Symphony APIs. For Java developers, the Eclipse integrated development environment (IDE) is supported as well.
For more information about the integration with various languages and development environments, check the product manual Application Development Guide.
4.2.5 High availability and resiliency
A Platform Symphony cluster is a mission critical environment in most cases. The grid should never go down as a whole. Components such as management nodes or compute nodes that run critical system services or application workloads might fail, so cluster resiliency mechanisms such as automatic failure recovery must be available.
Automatic failure recovery can be configured for all the workload management (service-oriented application middleware) and resource management (EGO) components that run on master hosts. The master host fails over to an available master candidate host in a list of master candidates. To work properly, the master candidate failover requires that the master host and the master candidates share a file system that stores the cluster configuration information. The shared file system also must be highly available, such as a Highly Available Network File System (HA-NFS) or an IBM GPFS file system.
Figure 4-17 presents in more detail some of the involved entities and a recovery approach for the failure case of a host running a service instance. For an in-depth presentation for the roles and functions of the involved system daemons, see Platform Symphony Version 6 Release 1.0.1 Application Development Guide, SC27-5078-01.

Figure 4-17 System level resiliency
Part of this recoverability is in place for the Symphony MapReduce framework as well. Open source Hadoop itself has by design recovery mechanisms for a failed TaskTracker. However, the JobTracker in the stable releases is still a single point of failure (SPOF). In Platform Symphony, the whole MapReduce framework runs on top of the SOA framework. The Application Manager (SSM) and the service instances replace the JobTracker and the TaskTrackers. The high availability of these two components is embedded in the Platform Symphony design.
Within the MapReduce framework, the HDFS component can also be configured as highly available by automating a failover process for all the involved daemons on any of the nodes (the NameNode, the SecondaryNameNode, and the data nodes). The HDFS daemons are integrated as MapReduce framework system services into the EGO system. The EGO system monitors them and restarts them on the same or another management host if a failure occurs. A built-in EGO DNS service running a Linux 'named' daemon is used to register any system service name as a well-known host name mapped to the IP address of the host where the service instance is running.
The NameNode is configured with such a well-known host name on which it accepts requests from the SecondaryNameNode, data nodes, and HDFS clients like MapReduce applications. When a NameNode daemon fails over from a failed host to a working host, the EGO DNS service reassigns the well-known NameNode host name to the IP address of the working host. This way, all of the involved entities can ask for NameNode services at the same well-known host name. The whole failover mechanism is shown in Figure 4-18.
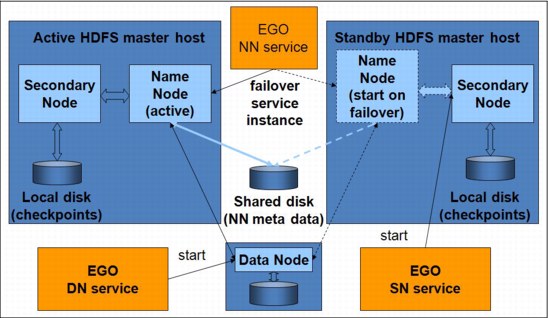
Figure 4-18 HDFS high-availability setup
The disk space that is required by the NameNode for its metadata files must be provided as a shared file system. Make this system highly available as either an HA-NFS or an IBM GPFS file system. Although this HDFS failover logic maintains the metadata on the shared disk and the node is brought up quickly, the HDFS NameNode service must go through the whole recovery logic. The HDFS recovery logic can take a long time (minutes or even more) because each individual DataNode must reregister its data chunks with the NameNode. The the NameNode must build a namespace image into memory for performance reasons and resynchronize the persistent state that it keeps on the shared disk. This is a limitation of the current Hadoop HDFS design. The problem might be solved by avoiding the centralized metadata management, which might also eliminate the need for the failover logic.
A good candidate for such an approach is GPFS with its new FPO feature, which has been recently announced. For more information about the new GPFS FPO feature, see 6.4.2, “File Placement Optimizer (FPO)” on page 129.
4.3 Key benefits
This section provides a summary of the key benefits of using the Platform Symphony technology:
•High resource utilization
– Single pool of shared resources across applications
– Eliminates silos and single purpose clusters
•Performance
– Low latency architecture
– Many jobs across many applications simultaneously
•Flexibility
– Compatible with open source and commercial APIs
– Supports open source and commercial file systems
•Reliability and availability
– Ensures business continuity
– Enterprise-class operations
•Scalability
– Extensive customer base
– 40000 cores per cluster/300 simultaneous MapReduce applications
•Manageability
– Ease of management, monitoring, reporting, and troubleshooting
•Predictability
– Drives SLA-based management
Maybe the most significant benefit from these is the resource utilization. You can use Platform Symphony to organize the computing resources in shared pools and then allocate guaranteed portions of them to specific applications. Furthermore, you can borrow and lend in specified amounts from these allocated resources between specified applications. You can also use a shared pool approach that allows resource utilization by multiple applications according to configurable share ratios. All of these factors enable a sophisticated shared services model among applications and lines of business, which drives a high degree of resource utilization. This maximizes the use of assets on the grid, so you obtain an important efficiency benefit from a business perspective.
Performance is a key differentiator from other Hadoop distributions. The low-latency architecture and the sophisticated scheduling engine bring higher levels of performance and deeper analysis, which provide a business advantage. The scheduler allows you to do more with less infrastructure. Platform Symphony enables significant TCO reductions and better application performance.
In terms of flexibility, Platform Symphony offers heterogeneous application support by providing an open application architecture. This is based on the SOA framework, and allows compute-intensive and data-intensive applications to run simultaneously in the same cluster. The MapReduce framework in Platform Symphony is built on an open architecture that provides 100% Hadoop application compatibility for Java based MapReduce jobs. This Symphony MapReduce open architecture also provides methods for using multiple file system types and database architectures. With well-documented APIs, Platform Symphony integrates well with various languages and development environments. All these contribute to reducing development costs and new application deployment time, saving time and improving the overall quality.
In an enterprise environment, where mission critical implementation is the rule, the reliability and high availability features are common ingredients. With the automatic failure recovery for all the workload management (service-oriented application middleware) and resource management (EGO) components, Platform Symphony fulfills these mandatory requirements for an enterprise product. All MapReduce framework services, including the HDFS daemons, are integrated within the automatic failure recovery functionality. They can be easily deployed in resilient and highly available configurations.
The scalability of an enterprise MapReduce grid computing environment is an important feature because business requirements usually grow. You must make sure that the continuously increasing workload does not saturate your grid. Platform Symphony has an extended customer base, with huge enterprise deployments in many cases. The product has grown and matured over many years, with new features and scalability limits being developed as responses to customer requirements for increasingly compute-intensive and data-intensive workloads.
The management tasks can be performed both from the web-based Platform Management console GUI, and from the command line. The GUI is a modern, web-based portal for management, monitoring, reporting, and troubleshooting purposes. It offers a high level of interactivity with the running jobs. For example, you can Suspend, Resume, and Kill jobs and tasks, and even change the priority of a running job.
Predictability is an important feature when you want to ensure that specific jobs will run according to an SLA. If you have 1000 jobs running at once, you might care about how all of them interact and are run so that you meet the SLA. You want to avoid the situation of a dominant job consuming all the resources, or many small jobs being stuck behind a large job. Platform Symphony, through its ownership and guaranteed allocation of a minimum number of resources to a consumer, handles this effectively. This drives predictability, which gives you the ability to manage and fulfill sophisticated SLA requirements when allocating and using resources.
In conclusion, shared services for big data are possible now. Hadoop is just another type of workload for a Platform Symphony grid. You do not have to deploy separate grids for different applications anymore. Platform Symphony MapReduce enables IT data centers running shared-service grids to achieve improved resource utilization, simplified infrastructure management, faster performance, and high availability. This provides reduced infrastructure and management costs, and an increased return on infrastructure investments.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.