


IBM Platform Load Sharing Facilities for technical cloud computing
This chapter describes the advantages and features of IBM Platform LSF for technical computing clusters workload management in a cloud-computing environment.
This chapter includes the following sections:
2.1 Overview
IBM Platform Load Sharing Facility (LSF) is a powerful workload manager for demanding, distributed, and mission-critical high-performance computing (HPC) environments. Whenever you want to address complex problems, simulation scenarios, extensive calculations, or anything that needs compute power and run them as jobs, submit them to Platform LSF through commands in a technical cloud-computing environment.
Figure 2-1 shows a Platform LSF cluster with a master host (server-01), a master candidate (server-02) host, and other hosts that communicate with each other through the Internet Protocol network.

Figure 2-1 IBM Platform LSF cluster structure
The master host is required by the cluster and is also the first host installed. When server-01 fails, server-02 takes over server-01’s work as a failover host. Jobs wait in queues until the available resources are ready. The submission host, which can be in a server host or a client host, submits a job with the bsub command. A basic unit of work is assigned into a job slot as a bucket in the Platform LSF cluster. Server hosts not only submit but also run the jobs. As shown in Figure 2-1, server04 can act as an execution host and run the job.
2.2 IBM Platform LSF family features and benefits
The Platform LSF family is composed of a suite of products that address many common customer workload management requirements. IBM Platform LSF boasts the broadest set of capabilities in the industry. What differentiates IBM Platform LSF from many competitors is that all of these components are tightly integrated and fully supported. The use of an integrated family also reduces strategic risk because although you might not need a capability today, it is available as your needs evolve. These are the core benefits of an integrated, fully supported product family. The purpose of the IBM Platform LSF family (Figure 2-2) is to address the many challenges specific to Technical Computing environments.

Figure 2-2 IBM Platform LSF product family
The IBM Platform LSF family includes these products:
The following sections describe each optional add-on product in the IBM Platform LSF family.
2.2.1 IBM Platform Application Center (PAC)
IBM Platform Application Center is an optional add-on product to IBM Platform LSF that enables users and administrators to manage applications more easily through a web interface. This add-on product allows cloud to switch environments to run different types of workloads. IBM Platform Application Center is integrated with IBM Platform License Scheduler, IBM Platform Process Manager, and IBM Platform Analytics. Users can access cluster resources locally or remotely with a browser, monitor cluster health, and customize application to meet cloud-computing needs.
IBM Platform Application Center offers many benefits for clients who implement cloud-computing solutions:
•Easy-to-use web-based management for cloud environments
•Enhanced security especially for remote cloud users
•Interactive console support, configurable workflows and application interfaces that are based on role, job notification, and flexible user-accessible file repositories
IBM Platform Application Center offers many benefits for users in cloud:
•Helps increase productivity
•Improves ability to collaborate on projects with peers
•Provides an easier interface that translates into less non-productive time interacting with the help desk
•Helps reduce errors, which translates into less time wasted troubleshooting failed jobs
2.2.2 IBM Platform Process Manager (PPM)
IBM Platform Process Manager is a powerful interface for designing and running multi-step HPC workflows in a Technical Computing cloud. The process manager is flexible to accommodate complex and real-world workflows. Often similar workflows have submodules shared between flows. Thus, by supporting subflows, modularity is promoted, making flows much easier to maintain.
The process manager enables grid-aware workflows or individual Platform LSF jobs to be triggered based on complex calendar expressions of external events. The process manager can improve process reliability and dramatically reduce administrator workloads with support for sophisticated flow logic, subflows, alarms, and scriptable interfaces.
Process flows can be automated over a heterogeneous, distributed infrastructure. Because the hosts to run individual workflow steps on are chosen at run time, processes automated by using the process manager inherently run faster and more reliably. This is because the process manager interacts with Platform LSF to select the best available host for the workload step.
The IBM Platform Process Manager provides the following benefits for managing workloads in a cloud-computing environment:
•Provides a full visual environment. This means that flows can be created quickly and easily, and they are inherently self-documenting. Someone else can look at a flow and easily understand the intent of the designer, making workflow logic much easier to manage and maintain.
•Helps capture repeatable best practices. Process that are tedious, manual, and error-prone today can be automated, saving administrator time and helping get results faster.
•Makes it much faster to design and deploy complex workflows, enabling customers to work more efficiently.
•Enables repetitive business processes such as reporting or results aggregation to run faster and more reliably by making workflows resilient and speeding their execution.
•Scales seamlessly on heterogeneous clusters of any size.
•Reduces administrator effort by automating various previously manual workflows.
2.2.3 IBM Platform License Scheduler
IBM Platform License Scheduler allocates licenses based on flexible sharing policies. Platform License Scheduler helps ensure that scarce licenses are allocated in a preferential way to critical projects. It also enables cross-functional sharing of licenses between departments and lines of business.
In many environments, the cost of software licenses exceeds the cost of the infrastructure. Monitoring how licenses are being used, and making sure that licenses are allocated to the most business critical projects is key to containing costs. The Platform License Scheduler can share application licenses according to policies.
The IBM Platform License Scheduler provides many benefits for clients who implement cloud-computing solutions:
•Improves license utilization. This is achieved by breaking down silos of license ownership and enabling licenses to be shared across clusters and departments.
•Designed for extensibility, supporting large environments with many license features and large user communities with complex sharing policy requirements.
•Improves service levels by improving the chances that scarce licenses are available when needed. This is especially true for business critical projects.
•Improves productivity because users do not need to wait excessive periods for licenses.
•Enables administrators to get visibility of license usage either by using license scheduler command line tools, or through the integration with the IBM Platform Application Center.
•Improves overall license utilization, thus removing the practical barriers to sharing licenses and ensuring that critical projects have preferential access to needed licenses.
2.2.4 IBM Platform Session Scheduler
IBM Platform Session Scheduler implements a hierarchical, personal scheduling paradigm that provides a low-latency execution. With low latency per job, Platform Session Scheduler is ideal for running short jobs, whether they are a list of tasks, or job arrays with parametric execution.
Scheduling large numbers of jobs reduces run time. With computers becoming ever faster, the execution time for individual jobs is becoming vert short. Many simulations such as designs of experiments or parametric simulations involve running large numbers of relatively short-running jobs. For these types of environments, cloud users might need a different scheduling approach for efficient running of high-volumes of short running jobs.
IBM Platform Session Scheduler can provide Technical Computing cloud users with the ability to run large collections of short duration tasks within the allocation of a Platform LSF job. This process uses a job-level task scheduler that allocates resources for the job once, and then reuses the allocated resources for each task.
The IBM Platform Session Scheduler makes it possible to run large volumes of jobs as a single job. IBM Platform Session Scheduler provides many benefits for clients who implement cloud-computing solutions:
•Provides higher throughput and lower latency
•Enables superior management of related tasks
•Supports over 50,000 jobs per user
•Particularly effective with large volumes of short duration jobs
2.2.5 IBM Platform Dynamic Cluster
IBM Platform Dynamic Cluster turns static Platform LSF clusters into a dynamic cloud infrastructure. By automatically changing the composition of the clusters to meet ever-changing workload demands, service levels are improved and organizations can do more work with less infrastructure. Therefore, Platform Dynamic Cluster can transform static, low utilization clusters into highly dynamic and shared cloud cluster resources.
In most environments, it is not economically feasible to provision for peak demand. For example, one day you might need a cluster of 100 Windows nodes, and the next day you might need similar sized Linux cluster. Ideally, clusters flex on demand, provisioning operating systems and application environments as needed to meet changing demands and peak times. IBM Platform Dynamic Cluster can dynamically expand resources on demand, which enables jobs to float between available hardware resources.
Platform Dynamic Cluster can manage and allocate the cloud infrastructure dynamically through these mechanisms:
•Workload driven dynamic node reprovisioning
•Dynamically switching nodes between physical and virtual machines
•Automated virtual machines (VMs) live migration and checkpoint restart
•Flexible policy controls
•Smart performance controls
•Automated pending job requirement
The IBM Platform Dynamic Cluster provides many benefits for clients who implement cloud-computing solutions:
•Optimizes resource utilization
•Maximizes throughput and reduces time to results
•Eliminates costly, inflexible silos
•Increases reliability of critical workloads
•Maintains maximum performance
•Improves user and administrator productivity
•Increases automation, decreasing manual effort
2.2.6 IBM Platform RTM
As the number of nodes per cluster, and the number of clusters increases, management becomes a challenge. Corporations need monitoring and management tools that enable administrator time to scale and manage multiple clusters globally. With better tools, administrators can find efficiencies, reduce costs, and improve service levels by identifying and resolving resource management challenges quickly.
IBM Platform RTM is the most comprehensive workload monitoring and reporting dashboard for Platform LSF cloud environments. It provides monitoring, reporting, and management of clusters through a single web interface. This enables Platform LSF administrators to manage multiple clusters easily while providing a better quality of service to cluster users.
IBM Platform RTM provides many benefits for clients who implementing cloud-computing solutions:
•Simplifies administration and monitoring. Administrators can monitor both workloads and resources for all clusters in their environment using a single monitoring tool.
•Improves service levels. For example, you can monitor resources requirements to make sure that Platform LSF resources requests are not “over-requesting” resources relative to what they need and leaving idle cycles.
•Resolves issues quickly. Platform RTM monitors key Platform LSF services and quickly determine reasons for pending jobs.
•Avoids unnecessary service interruptions. With better cluster visibility and cluster alerting tools, administrators can identify issues before the issues lead to outages. Examples of issues include a standby master host that is not responding, and a file system on a master host that is slowly running out of space in the root partition. Visibility of these issues allows them to be dealt with before serious outages.
•Improves cluster efficiency. Platform RTM gives administrators the tools they need to measure cluster efficiency, and ensure that changes in configuration and policies are steadily improving efficiency-related metrics.
•Realizes better productivity. User productivity is enhanced for these reasons. The cluster runs better, more reliably and at a better level of utilization with higher job throughput because administrators have the tools they need to identify and remove bottlenecks. Administrators are much more productive as well because they can manage multiple clusters easily and reduce the time that they spend investigating issues.
2.2.7 IBM Platform Analytics
HPC managers also need to deal with the business challenges around infrastructure, planning capacity, monitoring services levels, apportioning costs, and so on. HPC managers need tools that translate raw data that are gathered from their environments into real information on which they can base decisions.
IBM Platform Analytics is aimed specifically at business analysts and IT managers because the tool translates vast amount of information collected from multiple clusters into actionable information. Business decisions can be based on this information to provide better utilization and performance of the technical computing environments.
IBM Platform Analytics provides many benefits for clients who implement cloud-computing solutions:
•Turns data into decision making. Organizations can transform vast amounts of collected data into actionable information based on which they can make decisions.
•Identifies and remove bottlenecks.
•Optimizes asset utilization. By understanding the demand for different types of assets exactly, you can use assets more efficiently.
•Gets more accurate capacity planning. You can spot trends in how asset use is changing to make capacity planning decisions that will intercept future requirements.
•Generates better productivity and efficiency. By analyzing cluster operations, administrators often find “low-hanging-fruit” where minor changes in configuration can yield substantial improvements in productivity and efficiency.
2.3 IBM Platform LSF job management
This section provides information about how to handle jobs in Platform LSF. The following topics are addressed in this section:
•Submit/modify jobs
•Manipulate (such as stop, resume) jobs
•View detailed job information
2.3.1 Job submission
The command bsub is used to submit jobs. bsub runs as an interactive command or can be part of a script. The jobs can be submitted using a host to define the jobs and set the job parameters.
If the command runs without any parameters, the job starts immediately in the default queue (usually the normal queue) as shown in Example 2-1.
Example 2-1 Submitting the job to the Platform LSF queue
bsub demo.sh
Job <635> is submitted to default queue <normal>.
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 RUN normal HostA HostB demo.sh Jul 3 11:00
To specify a queue, the -q flag must be added as shown in Example 2-2.
Example 2-2 Specifying a queue to run the job
bsub -q priority demo.sh
Job <635> is submitted to queue <priority>.
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 RUN priority HostA HostB demo.sh Jul 3 11:13
Example 2-3 Starting a job in a suspended state
bsub -H demo.sh
Job <635> is submitted to default queue <normal>.
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 PSUSP normal HostA demo.sh Jul 3 11:00
For a list of all flags (switches) supported by the bsub command, see Running Jobs with IBM Platform LSF, SC27-5307, at the following website or by using the online manual by typing the man bsub on the command line:
2.3.2 Job status
The command bjobs shows the status of jobs defined. Jobs keep changing status until they reach completion. Jobs can have one of following statuses:
Normal state:
PEND: Waiting in queue for scheduling and dispatch
RUN: Dispatched to host and running
DONE: Finished normally
Suspended state:
PSUSP: Suspended by owner or LSF Administrator while pending
USUSP: Suspended by owner or LSF Administrator while running
SSUSP: Suspended by the LSF system after being dispatched
2.3.3 Job control
Jobs can be controlled by using following commands:
The bsub command is used to start the submission of a job as shown in Example 2-4.
Example 2-4 Initial job submission
bsub demo.sh
Job <635> is submitted to default queue <normal>.
bjobs -d
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 DONE priority HostA HostB demo.sh Jul 3 10:14
The bstop command is used to stop a running job (Example 2-5).
Example 2-5 Stopping a running job
bstop 635
Job <635> is being stopped
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 USUSP normal HostA HostB demo.sh Jul 3 10:14
The bresume command is used to resume a previously stopped job (Example 2-6).
Example 2-6 Starting a previously stopped job
bresume 635
Job <635> is being resumed
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 RUN normal HostA HostB demo.sh Jul 3 10:14
The bkill command is used to end (kill) a running job (Example 2-7).
Example 2-7 Ending a running job
bkill 635
Job <635> is being terminated
bjobs
No unfinished job found
bjobs -d
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 EXIT normal HostA HostB demo.sh Jul 3 10:41
2.3.4 Job display
The command bjobs is used to display the status of jobs. The command can be used with a combination of flags (switches) to check for running and completed jobs. If the command is run without any flags, the output of the command shows all running jobs of a particular user as shown in Example 2-8.
Example 2-8 Output of the bjobs command
bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 RUN normal HostA HostB demo.sh Jul 3 10:14
Example 2-9 Viewing the completed jobs
bjobs -d
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 EXIT normal HostA HostB demo.sh Jul 3 10:41
To view details of a particular job, the job_id must be specified after the bsub command as shown in Example 2-10.
Example 2-10 Viewing details of a job
bjobs 635
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
635 user1 EXIT normal HostA HostB demo.sh Jul 3 10:41
To check the details of a particular job, the -l flag must be specified after the bsub command as shown in Example 2-11.
Example 2-11 Showing the details of a particular job
bjobs -l
Job <635>, User <user1>, Project <default>, Status <EXIT>, Queue <normal>, Comm
and <demo.sh>
Wed Jul 3 10:41:43: Submitted from host <HostA>, CWD <$HOME>;
Wed Jul 3 10:41:44: Started on <HostB>, Execution Home </u/user1>, Execution
CWD </u/user1>;
Wed Jul 3 10:42:05: Exited with exit code 130. The CPU time used is 0.1 second
s.
Wed Jul 3 10:42:05: Completed <exit>; TERM_OWNER: job killed by owner.
MEMORY USAGE:
MAX MEM: 2 Mbytes; AVG MEM: 2 Mbytes
SCHEDULING PARAMETERS:
r15s r1m r15m ut pg io ls it tmp swp mem
loadSched - - - - - - - - - - -
loadStop - - - - - - - - - - -
adapter_windows poe nrt_windows
loadSched - - -
loadStop - - -
RESOURCE REQUIREMENT DETAILS:
Combined: select[type == local] order[r15s:pg]
Effective: select[type == local] order[r15s:pg]
A complete list of flags can be found in the man pages of the bjobs command (man bjobs).
2.3.5 Job lifecycle
Each job has a regular lifecycle in a Technical Computing cloud. In the lifecycle, the command bjobs shows the status of jobs defined. Jobs keep on changing status until they reach completion. The lifecycle process of the job is shown in Figure 2-3.
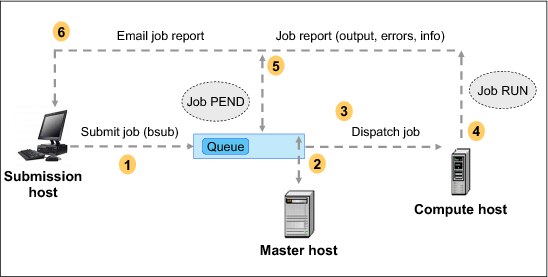
Figure 2-3 Job lifecycle
A host can submit a job by using the bsub command. The job’s state in a waiting queue is PEND. Then, mbatchd at some point sends the jobs to mbschd for scheduling so that the job to compute host can be dispatched. When the compute host finishes running, the job is handled by sbatchd. There is a job report that indicates success or failure. Finally, the job report is sent by email back to the submission host, including CPU use, memory use, job output, errors, and so on. For more information about job lifecycle, see Running Jobs with Platform LSF, Version 7.0 Update 6 at:
2.4 Resource management
Individual systems are grouped into a cluster to be managed by Platform LSF. One system in the cluster is selected as the “master” for LSF. Each subordinate system in the cluster collects its own “vital signs” periodically and reports them back to the master. Users then submit their jobs to LSF and the master decides where to run the job based on the collected vital signs.
Platform LSF uses built-in and configured resources to track resource availability and usage. The LSF daemons on subordinate hosts in the cluster report resource usage periodically to the master. The master host collects all resource usage from all subordinate hosts. Users submit jobs with the resource requirements to LSF. The master decides where to dispatch the job for execution based on the resource required and current availability of the resource.
Resources are physical and logical entities that are used by applications to run. Resource is a generic term, and can include low-level things such as shared memory segments. A resource of a particular type has attributes. For example, a compute host has the attributes of memory, CPU utilization, and operating system type.
Platform LSF has some considerations to be aware of for the resources:
•Runtime resource usage limits. Limit the use of resources while a job is running. Jobs that consume more than the specified amount of a resource are signaled.
•Resource allocation limits. Restrict the amount of a resource that must be available during job scheduling for different classes of jobs to start, and which resource consumers the limits apply to. If all of the resource has been consumed, no more jobs can be started until some of the resource is released.
•Resource requirements. Restrict which hosts the job can run on. Hosts that match the resource requirements are the candidate hosts. When LSF schedules a job, it collects the load index values of all the candidate hosts and compares them to the scheduling conditions. Jobs are only dispatched to a host if all load values are within the scheduling thresholds.
For more information about resource limitations, see Administering Platform LSF at:
2.5 MultiCluster
This section describes the multiclustering features of IBM Platform LSF.
2.5.1 Architecture and flow
Within an organization, sites can have separate, independently managed LSF clusters. LSF MultiCluster can address scalability and ease of administration on different geographic locations.
In a multicluster environment, multiple components (submission cluster mbschd/mbatchd, execution cluster mbschd/mbatchd) work independently and asynchronously. Figure 2-4 shows the architecture and work flow of a MultiCluster.

Figure 2-4 MultiCluster architecture and flow
Figure 2-4 on page 26 shows the submission cluster and the execution cluster with mbschd/mbatchd. The following is the workflow in the MultiCluster:
1. The user submits the job to a local submission cluster mbatchd.
2. The local submission cluster mbschd fetches newly submitted jobs.
3. The MultiCluster (MC) plug-in submission cluster makes the decision based on scheduling policies, and mbschd publishes the decision to the submission cluster mbatchd.
4. The submission cluster mbatchd forwards the job to the remote execution cluster mbatchd.
5. The execution cluster mbschd fetches newly forwarded jobs.
6. The execution cluster mbschd and the plug-ins make the job dispatch decision and publish the decision to the execution cluster mbatchd.
Resource availability information includes available slots, host type, queue status, and so on. After this workflow, the execution cluster mbatchd periodically collects its resource availability snapshot and sends it to the submission cluster. The execution cluster mbatchd triggers the call. Then, the submission cluster mbatchd receives resource availability information from the execution cluster mbatchd and keeps them locally until the next update interval to refresh the data. The submission cluster mbschd fetches resource availability information from the submission cluster mbatchd after every scheduling cycle and schedules the jobs based on it.
2.5.2 MultiCluster models
For a Technical Computing clouds environment, IBM Platform LSF MultiCluster provides two different types of share resources between clusters. The following section describes the two types: Job forwarding model and resource leasing model.
Job forwarding model
In this model, the cluster that is starving for resources sends the jobs over to the cluster that has resources to spare. To work together, the two clusters must set up compatible send-jobs and receive-jobs queues. With this model, scheduling of MultiCluster jobs is a process with two scheduling phases. The submission cluster selects a suitable remote receive-jobs queue, and forwards the job to it. The execution cluster then selects a suitable host and dispatches the job to it. This method automatically favors local hosts. A MultiCluster send-jobs queue always attempts to find a suitable local host before considering a receive-jobs queue in another cluster.
Resource leasing model
In this model, the cluster that is starving for resources takes resources away from the cluster that has resources to spare. To work together, the provider cluster must “export” resources to the consumer, and the consumer cluster must configure a queue to use these resources. In this model, each cluster schedules work on a single system image, which includes both borrowed hosts and local hosts.
These two models can be combined. For example, Cluster1 forwards jobs to Cluster2 using the job forwarding model, and Cluster2 borrows resources from Cluster3 using the resource leasing model. For more information about these types and how to select a model, see:
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.