


Solution for business analytics workloads
This chapter provides an architecture reference for business analytics clusters to be deployed in a technical computing cloud. The solution uses IBM InfoSphere BigInsights as the environment for the cluster.
This chapter includes the following sections:
•IBM InfoSphere BigInsights advantages for business analytics
•Deploying a BigInsights environment within a PCM-AE managed cloud
•The concepts behind NoSQL databases
11.1 MapReduce
MapReduce defined a methodology that enables the analysis of large amounts of data by the use of parallel computing. This method is used by most BigData applications. It consists basically of having each node analyze the amount of data that is local to it to avoid the transfer of data among nodes. This is referred to as the “map” phase of the analysis. Then, the results of each node are checked against each other to drop duplicate results, as data chunks processed on different nodes might have the same value. This is referred to as the “reduce” phase of the methodology.
The spreading of data analysis throughout the nodes of a grid without the need for data transfer, then the verification of a much smaller set of data to create a final result, allows MapReduce to provide answers to BigData analysis much faster. For more information about MapReduce, see Chapter 4, “IBM Platform Symphony MapReduce” on page 59.
Applications currently exist that use the MapReduce paradigm to analyze lots of unstructured data. IBM InfoSphere BigInsights is one of them.
11.1.1 IBM InfoSphere BigInsights
In a world that is heading towards an increasing amount of data generated at a fast rate every minute, technologies to analyze large volumes of data of varied types are being engaged. These include the MapReduce paradigm explained in the previous section. Today, frameworks such as Apache’s Hadoop use MapReduce to extract meaningful information from tons of unstructured data.
IBM InfoSphere BigInsights is a software platform that is based on the Hadoop architecture. It is the IBM solution for companies wanting to analyze their big data. The combination of IBM-developed technologies and Hadoop, packaged in an integrated fashion, provide an easy-to-install solution that is enterprise ready. Other technology components such as Derby, Hive, Hbase, and Pig are also packaged within IBM InfoSphere BigInsights.
The following are the benefits of an IBM InfoSphere BigInsights solution for your business or big data environment:
•Easy, integrated installation
The installation of IBM InfoSphere BigInsights is performed through a graphical user interface (GUI), and does not require any special skills. A check is run at the end of installation to ensure the correct deployment of the solution components. All of the integrated components have been exhaustively tested to ensure compatibility with the platform. You have support for a multi-node installation approach, thus simplifying the task of creating a large IBM InfoSphere BigInsights cluster.
•Compatible with other data analysis solutions
IBM InfoSphere BigInsights can be used with existing infrastructure and solutions for data analysis such as the IBM PureData System for Analytics (Netezza family) of data warehouse appliances, IBM Smart Analytics Systems, and IBM InfoSphere DataStage for ETL jobs.
Also, a Java Database Connectivity (JDBC) connector allows you to integrate it with other database systems such as Oracle, Microsoft SQL Server, MySQL, and Teradata.
•Enterprise class support
Enterprise class support means that you get assistance for your BigData analytics environment when you need it. There are two types of support, depending on the edition type acquired for IBM InfoSphere BigInsights: Enterprise and basic editions.
The enterprise edition provides a 24-hour support service and uses worldwide knowledge. The basic edition allows you to get the software for no extra fee for data environments up to 10 TB and still get access to online support.
•Enterprise class functionality
Businesses and research entities need highly available systems. This is why IBM InfoSphere BigInsights can be deployed on top of hardware that helps eliminate any single points of failure such as IBM servers.
Also, it provides you interfaces to manage and visualize jobs that are submitted to the cluster environment and to perform other administration tasks such as user management, authority levels, and content views.
•BigSheets
A browser-based analytic tool that enables business users and users with no programming knowledge to explore and analyze data in the distributed file system. Its interface is presented in a spreadsheet format so that you can model, filter, combine, and create charts in a fashion you are already familiar with. The resulting work can be exported to various formats such as HTML, CSV, RSS, Jason, and Atom.
•Text analytics
IBM InfoSphere BigInsights allows you to work with unstructured text data. You can store your data as it is acquired, and use this BigInsights component to directly analyze it without having to spend time preprocessing your text data.
•Workflow scheduling
IBM InfoSphere BigInsights can work with its own job scheduler for running MapReduce jobs. This brings advantages over Hadoop’s Fair scheduler that works by providing equal processing shares to jobs. It allows you, for example, to prioritize some jobs over others or ensure that small jobs are run faster (users typically expect smaller jobs to finish quickly as they hope to use the results right away).
In addition, IBM InfoSphere BigInsights can be integrated with IBM Platform Symphony to control job scheduling. Platform Symphony brings a more efficient job management to the BigInsights solution. It is able to accelerate parallel applications, resulting in faster results and better utilization of the cluster, even under dynamically changing workloads. Also, Platform Symphony is able to scale to very large cluster configurations that reach up to thousands of processor cores.
For more information about IBM InfoSphere BigInsights features, components, and integration with other software, see Implementing IBM InfoSphere BigInsights on System x, SG24-8077, and Integration of IBM Platform Symphony and IBM InfoSphere BigInsights, REDP-5006.
11.1.2 Deploying a BigInsights workload inside a cloud
Customers that have diverse technical computing workloads can use the IBM technical computing clouds technology to quickly deploy a data analytics cluster. This can be done in a simple and user-oriented manner.
This section provides information about the hardware architecture and components, and also the software architecture and components used to run a quick BigInsights data analysis. The basic foundations shown here can be used to deploy either a permanent or temporary BigInsights cluster with multi-user support. In the example scenario, the BigInsights cluster is limited to a single user, but its definition can be suited for a multi-user environment.
The following sections address the hardware and software layers that are used to build up the environment, how you interact with this architecture to create a BigInsights cluster, and a demonstration on how to access and use the created cluster. These references do not constrain how you can design your solution. For more information and other architecture references, see Implementing IBM InfoSphere BigInsights on System x, SG24-8077.
Hardware architecture
This section provides a description of a hardware architecture reference for deploying a BigInsights cluster inside of a Platform Cluster Manager - Advanced Edition (PCM-AE) managed cloud. This architecture provides you with the benefits and flexibility of dynamically creating a BigInsights cluster. This cluster can be later expanded or reduced based on workload demand, or even destroyed in the case of running temporary workloads.
Figure 11-1 illustrates how the hardware components were set up for this use case.

Figure 11-1 Lab hardware setup: PCM-AE environment to deploy other cloud solutions
The InfiniBand network serves as a high-speed connection between the nodes. The 1 Gbps network serves as a public gateway network for users to access the PCM-AE environment and the clouds within it.
The following is the hardware used for this use case:
•8 iDataPlex M4 servers
•13 iDataPlex M2 servers
•4 iDataPlex servers with NVIDIA Quadro 5000 adapters
•2 x3450 servers
•1 Mellanox 6536 InfiniBand FDR10 switch
•1 IBM BNT® G8152 Gigabit Ethernet switch
•2 TB of shared storage for the IBM General Parallel File System (GPFS) (SAS disks)
This infrastructure was put together to create the PCM-AE managed cloud. Multiple high-performance computing (HPC) environments are running concurrently in this example scenario. One of the iDataPlex servers hosts the PCM-AE management server, one x3450 hosts the xCAT management node, and the other x3450 handles the 2 TB SAS disk storage area.
For this BigInsights use case, use two of the physical iDataPlex servers to host the master and compute nodes as explained in “Deploying a BigInsights cluster and running BigInsights workloads” on page 238.
Software architecture
This section provides a description of the software components architecture used to run the example r BigInsights use case scenario. Although there are multiple possible architectures to integrate all of the software pieces depending on the user’s needs, only the one used as an illustration is described.
Figure 11-2 depicts the software components of the example cloud environment.

Figure 11-2 IBM InfoSphere BigInsights software components of the use case
IBM Platform Cluster Manager - Advanced Edition (PCM-AE) is used to orchestrate the creation and management of the BigInsights cluster. In the example scenario, the BigInsights servers (master and compute nodes) are physical machines. PCM-AE uses xCAT to deploy physical machines.
The BigInsights cluster is composed of the product itself, the Hadoop file system underneath it, and the analytics applications that are deployed inside BigInsights. However, Hadoop’s Fair scheduler is replaced with Platform Symphony.
Notice that in Figure 11-2 on page 237, the user interacts with the environment through an HTTP browser connection at two entry points, and optionally a third entry point:
•The PCM-AE environment
Users connect to PCM-AE to create the IBM InfoSphere BigInsights cluster, size it, and optionally resize it according to workload demands. This entry point is at number 1 in Figure 11-2 on page 237.
•The IBM InfoSphere BigInsights environment
After a cluster for BigInsights is active in the PCM-AE cloud environment, you can connect to it directly through the public network as explained in “Hardware architecture” on page 236. You can start analytics applications hosted within BigInsights. This entry point is at 2 in Figure 11-2 on page 237.
•The Platform Symphony environment
Optionally you can access Platform Symphony directly to check its configurations or use any of its report capabilities. This entry point is at 3 in Figure 11-2 on page 237.
|
Tip: Platform Symphony’s services run on port 18080, and can be accessed at address http://<ip>:18080/platform.
|
Deploying a BigInsights cluster and running BigInsights workloads
This section describes the process of deploying a BigInsights cluster from within PCM-AE and running bog data analysis on the provisioned cluster.
Log in to the PCM-AE web portal by pointing your browser to port 8080 on the management node. After logging in, click Clusters → Cockpit area as shown in Figure 11-3.

Figure 11-3 PCM-AE: Clusters tab (left side tab menu), cockpit area
To deploy a cluster, your PCM-AE environment needs to contain a cluster definition for the type of workload you want to deploy. A cluster definition holds information about operating system and basic network configuration. It provides the ability to install extra software on the top of a base environment by using postscripts.
From an user point of view, after the PCM-AE administrator publishes the cluster definition for use, they just have to follow a guided wizard to create a cluster. In essence, the administrators have the knowledge to define the clusters whereas a user, simply has to know how to go through the simple creation wizard. Figure 11-4 shows the cluster definition of the test environment. It is based on the Red Hat Enterprise Linux operating system version 6.2, IBM InfoSphere BigInsights 2.0, and Platform Symphony 6.1. For more information about creating cluster definitions in PCM-AE, see IBM Platform Computing Solutions, SG24-8073.

Figure 11-4 Cluster definition inside PCM-AE: Master and subordinate nodes
Click New as depicted in Figure 11-3 on page 238, then choose the appropriate cluster definition for the scenario as shown in Figure 11-5. Click Instantiate.
Figure 11-5 Instantiating a BigInsights and Platform Symphony cluster
The next wizard step is the definition of processor and memory parameters for the master and compute nodes, and also how many compute nodes to include in the cluster. In the example, just one compute node is defined as shown in Figure 11-6, plus the mandatory master node to create a non-expiring cluster.

Figure 11-6 Cluster creation wizard in PCM-AE: Resource definition
After you click Create, the cluster status is displayed as Active (Provisioning) on the Clusters → Cockpit interface of PCM-AE. Figure 11-7 shows the cluster in the provisioning state.

Figure 11-7 PCM-AE: cluster provisioning
After the process is complete, you can check the IP address and host name of the master and compute nodes for accessing the IBM InfoSphere BigInsights cluster. This information is available in the cluster cockpit interface as shown Figure 11-7.
To verify the newly deployed BigInsights cluster, deploy and run the simple word count application. Access BigInsights user interface by pointing your web browser to the IP address of the master tier node on the deployed cluster using port 8080. Then, click the Applications tab and deploy the Word Count application as shown in Figure 11-8.

Figure 11-8 Deploying the word count application for use within IBM InfoSphere BigInsights
BigInsights users can now create Word Count jobs by clicking the Welcome tab and clicking Run an application as shown in Figure 11-9.
Figure 11-9 Running applications in IBM InfoSphere BigInsights
Figure 11-10 shows a simple input and output directory setup created for running this test case. The input directory contains a text file of an IBM publication.

Figure 11-10 Running a word count job in IBM InfoSphere BigInsights
After the job is finished, check its output for the results as depicted in Figure 11-11.

Figure 11-11 BigInsights results of counting the words of a text file
Essentially, this use case demonstrates the simplicity of running an analytics workload inside of a cloud environment. Notice that no programming skills are required of the user, and the deployment of the computing cloud is straightforward after a working cluster definition exists within PCM-AE.
11.2 NoSQL
The current trend is for more people gaining access to the internet and using services such as blog posting, personal web pages, and social media. This has created an explosion of data that needs to be handled. As a consequence, companies that provide these services need to be able to scale in terms of data handling.
Now, imagine that all of the above happen continuously. It is not uncommon to read statements that mention that most of today’s data have been created in the past two years or so. How can the service providers keep up with this pace, and gain business advantages over their competitors? Part of the answer to that lies in the mix of Cloud Computing and BigData.
Computer grids have been commonly used to solve BigData problems. Distributed computing (grids) are the standard infrastructure that is used to solve these problems. They use cheap hardware, apply massive virtualization, and use modern technologies that are able to scale and process at the rate that new data is generated. Clouds are an excellent choice to host these grid environments because cloud characteristics makes them a good fit for this scenario. This is because clouds offer flexible scalability (grow, shrink), self-service, automated and quick provisioning, and multi-tenancy.
To address today’s needs for being able to analyze more data, including unstructured data, researchers have proposed models that work in a different manner than a standard relational database management system (RDBMS).
Relational databases are based on ensuring that transactions are processed reliably. They rely on the atomicity, consistency, isolation, and durability (ACID) properties of a single transaction. However, these databases can face great challenges when it comes to analyzing huge amounts of, for example, unstructured BigData data.
As a solution to this, and following the trend of distributed computing that the cloud provides, a new paradigm of databases is proposed: NoSQL, recently referred to as Not only SQL databases. NoSQL is based on the concepts of low cost and performance. The following is a list of its characteristics:
•Horizontal data scaling
•Support for weaker consistency models
•Support for flexible schemas and data models
•Able to use simple, low-level query interfaces
As opposed to RDMS databases that rely on the ACID concepts of a transaction, NoSQL databases reply on the basic availability, soft-state, eventual consistency (BASE) paradigm.
BASE databases do not provide the full fault-tolerance that an ACID database does. However, it is being proven to be suitable for use within large grids of computers that are analyzing data. If a node fails, the whole grid system does not come down. Just the amount of data that was accessible through that node becomes unavailable.
The eventual consistency characteristic means that changes are propagated to all nodes if enough time has passed. In an environment where data is not updated often, this is an acceptable approach. This weaker consistency model results in higher performance of data processing. Some businesses, such as e-commerce, prefer to prioritize high performance to be able to attend thousands or millions of customers with less processing delay and eventually deal with an inconsistency than to ensure a full data consistency that requires delays in merchandise purchase processes.
The soft-state characteristic is related to the eventual consistency of a data. Because eventual consistency relies on the statement that data is probably consistent when enough time has passed, inconsistencies might occur during that time. This is then handled by the application rather than by the database. In a real world scenario, this means that an e-commerce site that sold the last inventory item of a product to two customers might need to cancel one of them and offer that customer some kind of trade-off in return. They might determine that this as a more profitable approach over slowing down sales to enforce data consistency.
NoSQL databases can be based on different data models to manage data:
•Key-value pairs
•Row storage
•Graph oriented
•Document oriented
Multiple solutions today are based on the concepts presented here. Hadoop and HBase are open source examples. IBM offers support for NoSQL within DB2 as well.
11.2.1 HBase
HBase is an example of a database implementation that follows the NoSQL concepts. It is included in Apache’s Hadoop and its development is supported by IBM.
HBase is a column-oriented database that runs on top of data that are stored on HDFS. As such, the complexity of handling with distributed computing is abstracted from the database itself. As the data is organized in columns, a group of columns forms a row. Next, a set of rows form a table. Data is indexed by a row key, column key, and time stamp. The keys map to a value, which is an uninterpreted array of bytes.
To provide more performance and allow the manipulation of tons of data, HBase data is not updated in place. Updating occurs by adding a data entry with a different time stamp. This follows the “Eventual consistency” characteristic of the BASE paradigm mentioned for NoSQL databases.
The following is a list of characteristics that make HBase useful for business analytics:
•Supported in IBM InfoSphere BigInsights
– Enables users to use MapReduce algorithms of BigInsights
•Lower cost compared to other RDBMS databases
•Is able to scale up to the processing of very large data sets (terabytes, petabytes)
•Supports flexible data models of sparse records
•Supports random access and read/write support for Hadoop applications
•Automatic sharing without the corresponding penalties of an RDBMS database
Table 11-1 compares some aspects of HBase with other RDBMS databases.
Table 11-1 Comparison of HBase and RDBMS databases
|
Characteristic
|
HBase
|
RDBMS databases
|
|
Data layout
|
Column Family-oriented
|
Row or column-oriented
|
|
Transactions
|
Single row only
|
Yes
|
|
Query language
|
get/put/scan
|
SQL
|
|
Security
|
Authentication/ACL
|
Authentication/Authorization
|
|
Indexes
|
Row/Column/Timestamp only
|
Yes
|
|
Maximum data size
|
Petabytes and up
|
Terabytes
|
|
Read/write throughput limits
|
Millions of queries per second
|
Thousands of queries per second
|
An HBase implementation is characterized by a layout of a few interconnected components as shown in Figure 11-12.
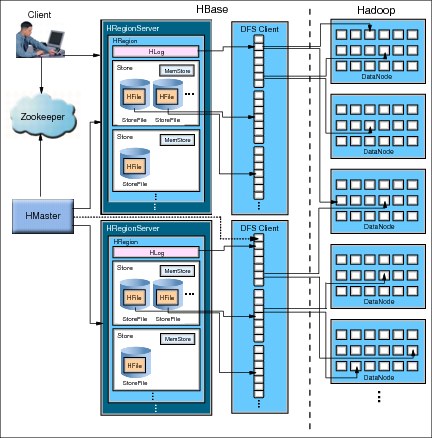
Figure 11-12 HBase component architecture
The architecture shown in Figure 11-12 is composed of these components:
Region A subset of table rows. Automatically shared upon growth.
Region servers Host tables. Run read operations and buffered write operations. Clients talk to region servers to have access to data.
Master Coordinates the region servers, detects their status, and runs load balance among them. It also assigns regions to region servers. Multiple master servers are supported starting with IBM InfoSphere BigInsights 1.4 (active master, one or more passive master backups).
Zookeeper Part of the Hadoop system. Ensures that the master server is running, provides bootstrap locations for regions, registers region servers, handles region and master server failures, and provides fault tolerance to the architecture.
Hadoop data nodes Nodes that store data using the Hadoop file system. Communication with region servers happens through a distributed file system (DFS) client.
For more information about HBase, see the following publications:
•George, Lars. HBase The Definitive Guide (O’ Reilly 2011)
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.