


IBM Platform Symphony for technical cloud computing
This chapter presents an overview of IBM Platform Symphony applied to the world of cloud computing. It includes a description of the role of IBM Platform Symphony in a grid environment, and an outline of IBM Platform Symphony’s benefits. Also, this chapter includes a description of the IBM Platform Symphony characteristics that make it a good scheduler for Technical Computing cloud environments.
This chapter includes the following sections:
3.1 Overview
One of the characteristics of a cloud environment is to provide better resource utilization of the hardware within it in the following ways:
•Allowing multiple workloads to be run on it.
•Allowing multiple users to access the software within it.
•Managing the resources with a middleware that is capable of quickly and effectively dispatching users’ workloads to the cloud hardware.
Without these characteristics, clouds would not be dynamic nor effective for running most types of workloads, including ones that are close to real-time processing. Thus, the software controlling hardware resources of a cloud must be able to address these points. IBM Platform Symphony is a middleware layer that is able to tackle these points.
In a nutshell, Platform Symphony is a job scheduler that assigns resources to applications. An application sends the grid scheduler a load to be run. The grid scheduler then determines how to best dispatch that load onto the grid. This is where Platform Symphony fits into the overall cloud architecture for technical computing.
IBM Platform Symphony fits well in a cloud-computing environment because it fulfills the need for optimizing its resource utilization. The following are IBM Platform Symphony characteristics:
•Platform Symphony is based on a service-oriented architecture (SOA), serving hardware resources to applications when they have the need.
•Platform Symphony provides multi-tenancy support, which means it provides hardware resources to multiple applications simultaneously.
•Platform Symphony is a low-latency scheduler that can quickly and optimally distribute load to nodes based on workload needs and based on grid nodes utilization levels. This makes Platform Symphony capable of better using the hardware resources of a cloud and increase utilization levels.
All IBM Platform Symphony editions feature low-latency high-performance computing (HPC) SOA, and agile service and task scheduling. The editions range in scalability from one or two hosts for the developer edition to up to 5,000 hosts and 40,000 cores for the advanced edition. The following section explains the different editions:
•IBM Platform Symphony Developer Edition: Builds and tests applications without the need for a full-scale grid (available for download at no cost).
•IBM Platform Symphony Express Edition: For departmental clusters, where this is an ideal cost-effective solution.
•IBM Platform Symphony Standard Edition: This version is for enterprise class performance and scalability.
•IBM Platform Symphony Advanced Edition: This is the best choice for distributed compute and data intensive applications, including Hadoop MapReduce.
The next sections provide an overview of which types of workloads can be managed by IBM Platform Symphony, how applications interact with it, and some characteristics that makes Platform Symphony an effective scheduler for managing cloud resources. For more information about IBM Platform Symphony, see IBM Platform Computing Solutions, SG24-8073.
3.2 Supported workload patterns
IBM Platform Symphony is able to centralize two workload types that were usually managed separately in older HPC grids: Compute intensive and data intensive workloads. Instead of creating different grids for each type of workload, Platform Symphony can manage hardware resources for simultaneous access by both workload types. This is possible because Platform Symphony has software modules that can handle and optimize job execution for both of them. Figure 3-1 shows the high-level architecture of the IBM Platform Symphony components.

Figure 3-1 Platform Symphony components architecture
There are also other components outlined in Figure 3-1 such as the Platform Management Console and the Platform Enterprise Reporting Framework. This chapter describes Platform Symphony characteristics from the point of view of effectively managing resources in a cloud. For insight into Platform Symphony itself, see IBM Platform Computing Solutions, SG24-8073.
The next sections describe in more detail the characteristics of Platform Symphony for compute and data intensive workload types.
3.2.1 Compute intensive applications
Compute intensive workloads use processing power by definition. Two aspects come into play when it comes to optimizing this type of workload:
•Able to quickly provide computational resources to a job.
•Able to scale up the amount of computational resources that are provided to a job.
IBM Platform Symphony uses a different approach than other schedulers when it comes to job dispatching. Most schedulers receive input data from clients through slow communication protocols such as XML over HTTP. Platform Symphony, however, avoids text-based communication protocols and uses binary formats such as Common Data Representation (CDR) that allows for compacting data. This results in shorter transfer rates.
In addition to, and most importantly, Platform Symphony has a service session manager (SSM) that uses a different approach to deal with engines associated to for resource scheduling. Instead of waiting for the engines to poll the session manager for work, the state of each engine is known by the service session manager. Therefore, polling is not needed, which avoids significant delays in the dispatch of a job to the grid. Platform Symphony simply dispatches the job to engines that are available for processing it immediately. This behavior makes Platform Symphony a low-latency scheduler, which is a characteristic that is required by compute intensive workloads. Also, the service session manager itself runs faster as a result of a native HPC C/C++ implementation as opposed to the Java based implementations found in other schedulers.
Figure 3-2 compares IBM Platform Symphony’s dispatch model with other scheduler’s dispatch models.

Figure 3-2 Platform Symphony’s push-based scheduling versus other poll-based methods
The push-based scheduling allows Platform Symphony to provide low-latency and high throughput service to grid applications. Platform Symphony provides submillisecond responses, and is able to handle over 17,000 tasks per second. This is why it is able to scale much more than other schedulers as depicted in Figure 3-3.

Figure 3-3 Symphony push-based scheduling allows it to scale up more than other schedulers
The second aspect is of great benefit to compute intensive workloads. Platform Symphony is able to scale up to 10,000 processor cores per application, 40,000 processor cores per individual grid, or it can reach up to 100,000 processor cores with its advanced edition version. Platform Symphony can therefore provide quick responses as a scheduler, and can provide application workloads with a large amount of computing power at once. When these two characteristics are combined, applications can compute their results much faster.
Besides low latency and large scaling capabilities of Platform Symphony, the following is a list of characteristics that makes it attractive for managing compute intensive workloads:
•Cost efficient and shared services:
– Multi-tenant grid solution
– Helps meet service level agreements (SLAs) while encouraging resource sharing
– Easy to bring new applications onto the grid
– Maximizes use of resources
•Heterogeneous and open:
– Supports AIX, Linux, Windows, Windows HPC, Solaris
– Provides connectors for C/C++, C#, R, Python, Java, Excel
– Provides smart data handling and data affinity
HPC SOA model
Symphony is built on top of a low-latency, service-oriented application middleware layer for serving compute intensive workloads as depicted in Figure 3-1 on page 31. In this type of model, a client sends requests to a service, and the service generates results that are given back to the client. In essence, a SOA-based architecture is composed of two logic parts:
•Client logic (the client)
•Business logic (the service)
In this paradigm, there is communication between the client and the business logic layers constantly. The better the communication methods are, the quicker the responses are provided. This is where the ability of Platform Symphony to communicate with clients efficiently as explained in 3.2.1, “Compute intensive applications” on page 31 provides immediate benefits.
Clients can create multiple requests to the service, in which case multiple service instances are created to handle the requests as shown in Figure 3-4.

Figure 3-4 The SOA model
Platform Symphony works with this SOA model. Moreover, Platform Symphony can provide this type of service to multiple independent applications that require access to the grid resources. It does so through its SOA middleware, which can manage the business logic of these applications. It dispatches them to the grid for execution through the scheduling of its resources. This characterizes Platform Symphony as a multi-tenancy middleware, a preferred characteristic for grid and cloud environments.
Figure 3-5 shows the relationship among application clients, application business logic, and grid resources for serving the business logic.

Figure 3-5 Client logic, business logic, and resource layers
Internally, the way that Platform Symphony handles SOA-based applications is shown in the abstraction hierarchy in Figure 3-6.

Figure 3-6 Abstraction hierarchy for the Platform Symphony SOA model
The following section is a brief description of each of the abstractions in Figure 3-6:
Grid The grid is an abstraction for all of the environment resources, which includes processors, memory, and storage units. Users and applications need to gain access to the grid resources to perform work.
Consumer This is the abstraction that organizes the grid resources in a structured way so that applications can use them. An application can only use the resources of the consumer it is assigned to. Consumers can be further organized hierarchically. This organization creates resource boundaries among applications and dictates how the overall grid resources are shared among them.
Application Uses resources from the grid through consumers. Each application has an application profile that defines every aspect of itself.
Client This is the client logic as presented in Figure 3-4 on page 34. It interacts with the grid through sessions. It sends requests to and receive results from the services.
Service This is the business logic as presented in Figure 3-4 on page 34. It accepts requests from and returns responses to a client. Services can run as multiple concurrent instances, and they ultimately use computing resources.
Session Abstraction that allows clients to interact with the grid. Each session has a session ID generated by the system. A session consists of a group of tasks that are submitted to the grid. Tasks of a session can share common data.
Task The basic unit of computational work that can be processed in parallel with other tasks. A task is identified by a unique task ID within a session that is generated by the system.
3.2.2 Data intensive applications
Data intensive workloads consume data by definition. These data can, and usually are in a cloud or grid environment, be spread among multiple grid nodes. Also, these data can be in the scale of petabytes of data. Data intensive workloads must be able to process all of these data in a reasonable amount of time to produce results, otherwise there is little use for doing so. Therefore, a cloud or grid environment must have mechanisms that efficiently perform and process all of the data in a reasonable amount of time.
As depicted in Figure 3-1 on page 31, Platform Symphony has a component that specializes in serving data intensive workloads. It has a module that is composed of an enhanced MapReduce processing framework that is based on Hadoop MapReduce. MapReduce is an approach to processing large amounts of data in which nodes analyze data that are local to them (the map phase). After the data from all nodes is mapped, a second phase starts (the reduce phase) to eliminate duplicate data that might have been processed on each individual node. Platform Symphony’s ability to use MapReduce algorithms makes it a good scheduler for serving data intensive workloads.
As an enterprise class scheduler, Platform Symphony includes extra scheduling algorithms when compared to a standard Hadoop MapReduce implementation. Symphony is able to deploy simultaneous MapReduce applications to the grid, with each one consuming part of the grid resources. This is as opposed to dispatching only one at a time and have it consume all of the grid resources. The Platform Symphony approach makes it easier to run data workloads that have SLAs associated with it. Shorter tasks whose results are expected sooner can be dispatched right away instead of being placed in the processing queue and having to wait until larger jobs are finished.
This integrated MapReduce framework brings the following advantages to Platform Symphony:
•Higher performance: Short MapReduce jobs run faster.
•Reliable and highly available rolling upgrades: Uses the built-in highly available components that allow dynamic updates.
•Dynamic resource management: Grid nodes can be dynamically added or removed.
•Co-existence of multiple MapReduce applications: You can have multiple applications based on the MapReduce paradigm. Symphony supports the co-existence of up to 300 of them.
•Advanced scheduling and execution: A job is not tied to a particular node. Instead, jobs have information about its processing requirements. Any node that meets the requirements is a candidate node for execution.
•Fully compatible with other Hadoop technologies: Java MR, Pig, Hive, HBase, Oozie, and others.
•Based on open data architecture: Has support for open standards file systems and databases.
For more information about Symphony’s MapReduce framework, see Chapter 4, “IBM Platform Symphony MapReduce” on page 59.
Data affinity
Because data in a cloud or grid can be spread across multiple nodes, dispatch data consuming jobs to the nodes on which data is found to be local. This prevents the system from having to transfer large amounts of data from one node to another across the network. This latter scenario increases networking traffic and insert delays in the analysis of data due to data transfers.
Platform Symphony is able to minimize data transfers among nodes by applying the concept of data affinity. This applies to dispatching jobs that are supposed to consume the resulting data of a previous job to the same node of the previous job. This is different from the MapReduce characteristic of having each node process its local data. Here, data affinity is related to dispatching jobs that consume data that are related to one another onto the same node. This is possible because the SSM collects metadata about the data that are being processed on each node of a session.
For more information about data affinity, see 3.6, “Data management” on page 52.
3.3 Workload submission
Platform Symphony provides multiple ways for workload submission:
•Client-side application programming interfaces (APIs)
•Commercial applications that are written to the Platform Symphony APIs
•The symexec facility
•The Platform Symphony MapReduce client
These methods are addressed in the next sections.
3.3.1 Commercial applications that are written to the Platform Symphony APIs
Some applications use the Platform Symphony APIs to get access to the resource grid. This can be accomplished through .NET, COM, C++, Java, and other APIs. The best example is Microsoft Excel.
It is not uncommon to find Excel spreadsheets created to solve analytics problems, especially in the financial world, and in a shared calculation service approach that makes use of multiple computers. Symphony provides APIs that can be called directly by Excel for job submission. By doing so, calculations start faster and be completed faster.
There are five well-known patterns for integrating Excel with Symphony by using these APIs:
•Custom developed services: Uses Symphony COM API to call for distributed compute services.
•Command line utilities as tasks: Excel client calls Platform Symphony services that run scripts or binary files on compute nodes.
•Excel instances on the grid: Run parallel Excel instances that are called by client spreadsheets or other clients.
•Excel services by using user-defined functions (UDFs): Web-based client access that uses UDFs to distribute computations to the grid.
•Hybrid deployment scenarios: Combined UDF with Java, C++ services.
For more information, see the Connector for Microsoft Excel User Guide, SC27-5064-01.
3.3.2 The symexec facility
Symexec enables workloads to be called using the Platform Symphony service-oriented middleware without explicitly requiring that applications be linked to Platform Symphony client- and service-side libraries.
Symexec behaves as a consumer within Platform Symphony SOA model. With it, you can create execution sessions, close them, send a command to an execution session, fetch the results, and also run a session (create, execute, fetch, close, all running as an undetachable session).
For more information about symexec, see Cluster and Application Management Guide, SC22-5368-00.
3.3.3 Platform Symphony MapReduce client
MapReduce tasks can be submitted to Platform Symphony by either using the command line with the mrsh script command, or through the Platform Management Console (PMC).
It is also possible to monitor MapReduce submitted jobs by using command line through soamview, or also within the PMC.
For more information about how to submit and monitor MapReduce jobs to Symphony, see User Guide for the MapReduce Framework in IBM Platform Symphony - Advanced Edition, GC22-5370-00.
3.3.4 Guaranteed task delivery
Platform Symphony is built with redundancy of its internal components. Automatic fail-over of components and applications provide a high level of middleware availability. Even if the Enterprise Grid Orchestrator (EGO) fails, only the new requests for resource allocation are compromised. What had already been scheduled continues to work normally. EGO is a fundamental software piece that Platform Symphony uses to allocate resources in the grid.
A Platform Symphony managed grid infrastructure counts with a Platform Symphony master node that does grid resource management. If it fails, this service fails-over to other master candidate nodes. A similar fail-over strategy can be implemented for the SSM. A shared file system among the nodes facilitates the fail-over strategy, although it is also possible to achieve a degree of high availability without it through the management of previous runtime states.
As for the compute nodes, high availability is ensured by deploying application binary files and configuration to the local disk of the compute nodes themselves.
Figure 3-7 demonstrates the concepts presented.

Figure 3-7 Platform Symphony components high availability
All of this component design can be used to ensure a guaranteed task delivery. That is, even if a component fails, tasks are deployed and run by spare parts of the solution.
Guaranteed task delivery is configurable, and depends on whether workloads are configured to be recoverable. If workloads are configured as recoverable, the applications do not need to resubmit tasks even in the case of an SSM failure. Also, reconnecting to another highly available SSM happens transparently and the client never notices the primary SSM has failed. The workload persists on the shared file system.
3.3.5 Job scheduling algorithms
Platform Symphony is equipped with algorithms for running workload submission to the grid. The algorithm determines how much resources and time each task is given. Job scheduling is run by the SSM, which can be configured to use the following algorithms to allocate resources slots (for example, processors) to sessions within an application:
Proportional scheduling Allocates resources to a task based on its priority. The higher the priority, the more resources a task gets. Priorities can be reassigned dynamically. This is the default scheduling algorithm for workload submission.
Minimum service scheduling Ensures a minimum number of service instances are associated with an application. Service instances do not allow resources to go below the minimum defined level even if there are no tasks to be processed.
Priority scheduling All resources are scheduled to the highest priority session. If this session cannot handle them all, the remaining resources are allocated to the second highest priority session, and so on. Sessions with the same priority use creation time as tie-breaker: A newer session is given higher priority.
For more information about the concept of session and related concepts, see “High performance computing (HPC) SOA model” on page 31 and Figure 3-6 on page 33.
Preemption
Sometimes it is necessary to stop the execution of a task and free up its resources for other tasks. This process is called preemption.
Preemption occurs when under-allocated sessions must get resources from over-allocated tasks. It takes into consideration the algorithm in use and changes to that algorithm, and happens immediately. Preempted tasks are queued once again for dispatching. Task preemption is configurable and is not turned on by default.
|
Note: Task preemption is not turned on by default in the Platform Symphony scheduling configuration.
|
3.3.6 Services (workload execution)
Workload execution allows you to deploy existing executable files in a cloud grid environment. An execution task is a child process that is run by a Platform Symphony service instance using a command line specified by a Platform Symphony client.
The Platform Symphony execution application allows you to start and control the remote execution of executable files. Each application is made up of an execution service and an executable file that are distributed among compute hosts. The management console implements a workload submission window that allows a single command to be submitted per session to run the executable file.
You can do this by using the GUI interface. Click Quick Links → Symphony Workload → Workload → Run Executable from the Platform Symphony GUI, then enter the command with required arguments in the Remote Executable Command field as shown in Figure 3-8.
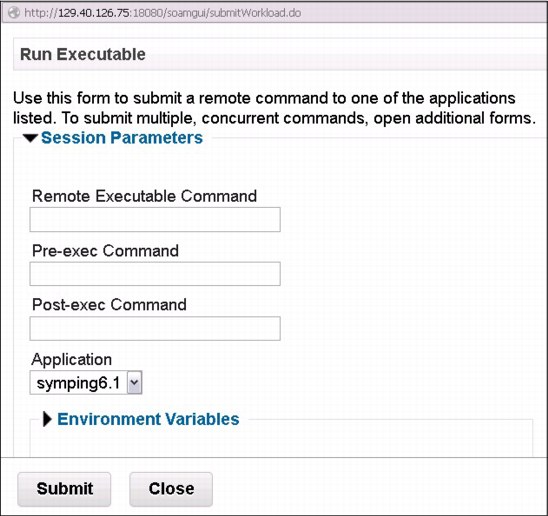
Figure 3-8 Task execution
The execution service implements the process execution logic as a Platform Symphony service and interacts directly with the service instance manager (SIM). It is used to start the remote execution tasks and return results to the client.
When the command that you submit is processed by the system, the task can get a relevant execution session ID created by the client application. The client application then sends the execution tasks to the execution service. After receiving the input message, the execution service creates a new process based on the execution task data. When the execution task is completed, the exit code of the process is sent back to the client in the execution task status.
If the command execution is successful, a control code message is displayed. If the command execution is not successful, an exception message with a brief description is returned by the system. The interface can also provide the entry of associated pre- and post- commands, and environment variables, and pass their values to the execution service.
3.4 Advanced resource sharing
In a multi-tenant environment, Platform Symphony can provide enterprise level resource management, including enterprise sharing and ownership of these resources. Different lines of business (LOBs), implemented as consumers, can share resources. When one LOB does not need its resources, it can lend them out and others can borrow them. In this way, all LOBs of an enterprise can share and use computing resources efficiently and effectively based on resource plans. Symphony also allows flexible configurations of resource plans.
In a Technical Computing cloud environment, you can define Platform Symphony shared resources in the resource distribution plan. In Figure 3-9, a client works through the SSM to request n slots from the resource manager. Based on the values specified in the resource distribution plan, the service resource manager returns m available slots on the hosts.

Figure 3-9 Platform Symphony advanced resource sharing
A resource distribution policy defines how many resources an application can use. Resource distribution is a set of rules that defines a behavior for scheduling or resource distribution. Each application has its set of rules. So the resource distribution plan is a collection of resource distribution policies that describes how Platform Symphony assigns resources to satisfy workloads demand. Several resource distribution policies exist. For more information, see Platform Symphony Foundations - Platform Symphony Version 6 Release 1.0.1, SC27-5065-01.
The ability of Platform Symphony to lend and borrow resources from one application to another ensures users access to resources when needed. Both lending and borrowing are introduced in the next sections. These operations can happen at the levels of the ownership pool (resources that are entitled to particular consumers) and the sharing pool (resources that are not entitled to any particular consumer, and thus comprise a shared resource pool).
3.4.1 Lending
If a consumer does not need all the processors that it has, it can lend excess processors. For example, if it owns 10 processors but it does not need all of them, it can lend some of them away. This is called ownership lending because the consumer lends away what it owns. However, if a consumer is entitled processors from the sharing pool and it does not need all of them, it can also lend them away. This operation is called share lending to distinguish it from ownership lending. Basically, consumers can lend processors that they do not need at a specific moment.
3.4.2 Borrowing
If a consumer does not have enough processors and borrows some that belong to other consumers (ownership pool), this is called ownership borrowing. Alternatively, if a consumer gets more processors than its share from the sharing pool, this is called share borrowing. If a consumer needs processors and there are available ones in both the sharing pool and ownership pool, the order of borrowing is to first borrow from the sharing pool, and then borrow from the ownership pool.
3.4.3 Resource sharing models
Resources are distributed in the cluster as defined in the resource distribution plan, which can implement one or more resource sharing models. There are three resource sharing models:
•Siloed model
•Directed share model
•Brokered share or utility model
Siloed model
The siloed model ensures resource availability to all consumers. Consumers do not share resources, nor are the cluster resources pooled. Each application brings its designated resources to the cluster, and continues to use them exclusively.
Figure 3-10 exemplifies this model. It shows a cluster with 1000 slots available, where application A has exclusive use of 150 slots, and application B has exclusive use of 850 slots.

Figure 3-10 Symphony resource sharing: Siloed model
Directed share model
The directed share model is based on the siloed model: Consumers own a specified number of resources, and are still guaranteed that number when they have demand. However, the directed share model allows a consumer to lend its unused resources to sibling consumers when their demand exceeds their owned slots.
Figure 3-11 exemplifies this model. It shows that applications A and B each owns 500 slots. If application A is not using all of its slots, and application B requires more than its owned slots, application B can borrow a limited number of slots from application A.

Figure 3-11 Symphony resource sharing: Directed share model
Brokered share or utility model
The brokered share or utility model is based entirely on sharing of the cluster resources. Each consumer is assigned a proportional quantity of the processor slots in the cluster. The proportion is specified as a ratio.
Figure 3-12 is an example of the brokered share model. It shows that application A is guaranteed two of every five slots, and application B is guaranteed three. Slots are only allocated when a demand exists. If application A has no demand, application B can use all slots until application A requires some.
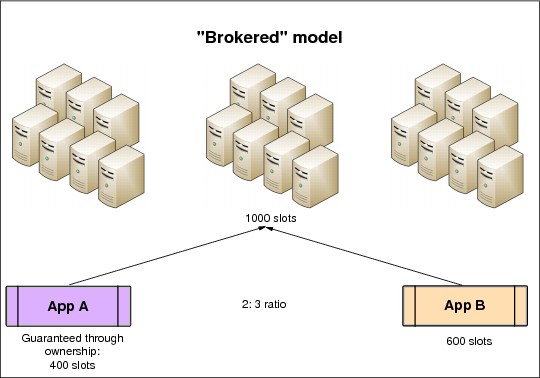
Figure 3-12 Symphony resource sharing: Brokered share or utility model
3.4.4 Heterogeneous environment support
Platform Symphony supports management of nodes running multiple operating systems, such as Linux, Windows, and Solaris. Nodes with these operating systems can exist within the same grid.
Platform Symphony clients and services can be implemented on different operating system environments, languages, and frameworks. Clusters can also be composed of nodes that run multiple operating systems. For example, 32- and 64-bit Linux hosts can be mixed running different Linux distributions, and multiple Microsoft Windows operating systems can be deployed as well. Platform Symphony can manage all these different types of hosts in the same cluster, and control which application services run on each host.
Also, application services that run on top of Linux, Windows, and Solaris can use the same service package and the same consumer. For more information, see Figure 3-6 on page 35. From a hardware perspective, Platform Symphony can be used with multiple hardware platforms.
Table 3-1 lists the hardware, operating systems, languages, and applications supported by Platform Symphony.
Table 3-1 Supported environments and applications in Platform Symphony
|
Infrastructure hardware and software support
|
|
|
Hardware support
|
•IBM System x iDataPlex® and other rack-based servers, as well as non-IBM x86 and x64 servers
•IBM Power Systems1
|
|
Operating system support
|
•Microsoft Windows 2003, 2003 R2 64-bit, 2008, 2008 R2 64-bit, Vista
•Windows 7, Windows HPC Server 2008
•RHEL 4, 5, and 6
•SLES 9, 10, and 11
•PowerLinux supported distributions (RHEL and SLES)
|
|
Application support
|
|
|
Tested applications
|
•IBM GPFS 3.4
•IBM BigInsights™ 1.3, 1.4 and 2.0
•Appistry CloudIQ storage
•Datameer Analytics solution
•Open source Hadoop applications, including Pig, Mahout, Nutch, HBase, Oozie, Zookeeper, Hive, Pipes, Jaql
|
|
Third-party applications that are known to work with Platform Symphony
|
Murex, Microsoft Excel, Sungard Front Arena, Adaptiv, IBM Algorithmics® Algo® Risk, Oracle Coherence, Milliman Hedge, Alfa, Polysis, Fermat, Numeric, Calypso, Mathworks MATLAB, Quantifico, Tillinghast MoSes, Sophis Risque, Misys, GGY Axis, Openlink, Kondor+
|
|
Application and data integration
|
|
|
Available APIs
|
•C++, C#
•.NET
•Java
•Excel COM
•Native binaries
|
1 Running PowerLinux
3.4.5 Multi-tenancy
Platform Symphony can manage heterogeneous environments, both in terms of hardware and operating systems, and can share grid resources using scheduling algorithms that can provide low-latency and service levels. These characteristics make it a perfect match for being a multi-tenant middleware.
|
Note: Platform Symphony is a multi-tenant shared services platform with unique resource sharing capabilities.
|
Platform Symphony provides these capabilities:
•Share the grid among compute and data intensive workloads simultaneously
•Manage UNIX and Windows based applications simultaneously
•Manage different hardware models, simultaneously
Figure 3-13 demonstrates how powerful it is when it comes to sharing grid resources to multiple applications.

Figure 3-13 Multi-tenant support with Platform Symphony
3.4.6 Resources explained
Resources on the grid are divided into flexible resource groups. Resource groups can be composed of the following components:
•Systems that are owned by particular departments.
•Systems that have particular capabilities. For example, systems that have lots of disk spindles or graphics processing units installed.
•Heterogeneous systems. For example, some hosts run Windows operating system while others run Linux.
As explained in Figure 3-6 on page 35, a consumer is something that consumes resources from the grid. A consumer might be a department, a user, or an application. Consumers can also be expressed in hierarchies that are called consumer trees.
Each node in a consumer tree owns a share of the grid in terms of resource slots from the resource groups. Shares can change with time. Consumers can define how many slots they are willing to loan to others when not in use and how many they are willing to borrow from others, thus characterizing a resource sharing behavior as explained in 3.4.3, “Resource sharing models” on page 43.
|
Note: Owners of slots can be ranked.
|
Applications are associated with each of these consumers, and application definitions provide even more configurability in terms of resources that an application needs to run.
With all of this granularity of resource sharing configuration, organizations can protect their SLAs and the notion of resource ownership. Users can actually get more capacity than they own. Grids generally run at 100% utilization because usage can expand dynamically to use all available capacity.
3.5 Dynamic growth and shrinking
When the need for resources grows and shrinks with processing loads, middleware software that is intended to control these resources must be able to address dynamic changes to grid topology. This avoids under-utilization of resources during low processing periods, and allows for temporary resource assignment to meet peak processing demands.
New nodes can be added to a Platform Symphony-managed grid dynamically without interrupting services. This, however, characterizes a definitive topology change to the grid itself. That is, the added node is now part of the grid, unless it is removed by the grid administrators. Subtracting nodes from a grid follows the same concept. This mechanism allows Platform Symphony to dynamically grow and shrink its grid, a characteristic that is in accordance to a cloud environment, which is also dynamic.
Platform Symphony, however, offers an extra type of dynamism when it comes to adding temporary capacity to its grid. Imagine that you exhausted your grid capacity during a peak processing time and are clearly in need of more resources. Purchasing more hardware to meet this demand is expensive and cannot be done in a timely manner. Instead, you want to make use of idle resources that you already own outside of that grid. With Platform Symphony, you can.
The following mechanisms can be used by Platform Symphony to attend to a peak demand by using existing resources within your environment, or by borrowing extra capacity from a provider:
•Desktop and server scavenging
•Virtual server harvesting
•On-demand HPC capacity
3.5.1 Desktop and server scavenging
Platform Symphony is able to scavenge idle servers and desktops that are not part of its grid. This is a dynamic operation in which these resources, which are not part of the permanent grid, can be requested to process a grid workload. Desktops might be common workstations that are used by office people in its daily tasks, and servers can be web servers, mail servers, file servers, and so on.
The scavenging of extra servers and desktops for grid processing does not compete against the usual jobs that are run on these systems. That is, if a user is actually using its desktop to perform a task, Platform Symphony does not send workloads to it. Similarly, when a web server is actually under load servicing HTTP requests, Platform Symphony does not send workloads to it. When these desktops and servers are busy, they are said to be closed to the Platform Symphony grid and cannot receive grid workloads. After they become idle, their state changes to open for accepting grid workloads. Servers can be configured with a custom load threshold under which it becomes open to grid processing.
Figure 3-14 shows a diagram for Platform Symphony desktop and server scavenging.

Figure 3-14 Symphony desktop and server scavenging
Desktop and server scavenging has the following advantages:
•Uses idle capacity of existing resources within your company or institution.
•Scavenging does not compete for resources when desktops and servers are not idle (open stated or closed state for grid use). Therefore, there is no impact to users or applications that usually run on these desktops and servers.
•Improves the performance of your Platform Symphony grid.
•Reduces costs by using existing resources, avoiding new capital expenditure.
3.5.2 Virtual server harvesting
Similarly to desktop and server scavenging, Platform Symphony is also able to harvest virtual servers into the grid. Again, this happens as a temporary resource addition to the grid.
Virtual servers can receive grid jobs when its usual processing is below a custom threshold, or when the virtual server is idle only. You might have different virtual environments as depicted in Figure 3-15. Also, you can either choose to create more virtual servers managed by their original clusters or pools.
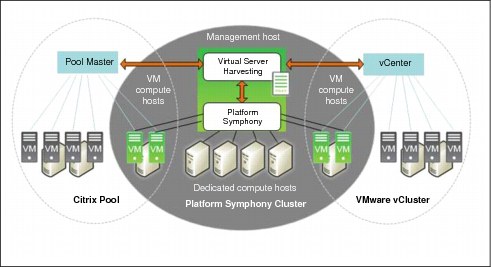
Figure 3-15 Symphony virtual server harvesting
Virtual server harvesting provides these benefits:
•Gives the grid access to idle cycles from virtual server infrastructures.
•Harvesting causes minimal impacts to existing virtual machine environments.
•Avoids costly duplication of infrastructure.
•Increases grid capacity without capital expenditure.
•Improves grid service levels.
3.5.3 On-demand HPC capacity
If your HPC cluster peaks at a particular time, Platform Symphony allows you to use external HPC resources from providers in an on-demand fashion. You can think of on-demand HPC capacity as the act of instantiating and connecting extra resources to your existing infrastructure to serve your peak demands. This concept is also called cloud bursting.
You can have your infrastructure ready to connect to a cloud resource provider at all times, but set up a policy to use this on-demand extra capacity only when a certain threshold processing level is reached. This can be automatically managed by a threshold policy.
Figure 3-16 depicts the idea of on-demand HPC capacity.
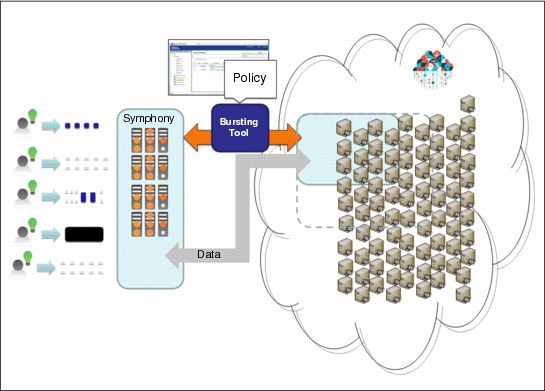
Figure 3-16 Platform Symphony using on-demand HPC capacity
Platform Symphony has plug-ins that allow an easy integration of your internal grid with external HPC capacity. Moreover, no changes are required to the job submitting processes. After you burst your grid with extra cloud resources, Platform Symphony is able to use them transparently.
On-demand HPC capacity also provides the following advantages:
•Minimize capital expenses: No need to acquire extra hardware for short peak demands.
•Ensure service level agreements: Jobs can be serviced on time by quickly using extra grid capacity.
•Scale endlessly: Ability to scale as much resources as needed with cloud burst.
•Capacity planning becomes less critical.
•Existing infrastructure can be reshaped while still meeting processing demands.
•Capital expenses become operational expenses.
Figure 3-17 shows a grid workload behavior that can make good use of on-demand HPC resources.

Figure 3-17 Workload opportunities for bursting existing grid capacity
Using external resources for a grid offers some challenges because the extra resources are not local to your infrastructure:
•Security
– Do the providers offer data protection?
– Your network IP addresses on third-party infrastructure are outside of your firewall.
•Application licenses
– Legal agreements might limit technology use to certain geographic locations only or to corporate sites, preventing a more free choice of where you can burst your environment to.
•Performance
– Applications must be able to efficiently use general, multi-purpose external resources.
•Data movement
– As depicted in Figure 3-16 on page 51, you must exchange data between your site and the on-demand provider’s site.
Even after the challenges mentioned, using on-demand HPC capacity is a reality with Platform Symphony.
3.6 Data management
Workload schedulers focus on dispatching tasks to compute hosts and transferring data either directly to the compute hosts or delegating data retrieval to the service. The time that is required for this data transfer from various sources to where the work is being processed can lead to inefficient use of processor cycles and underutilization of the resource.
Platform Symphony has a mechanism called data-aware scheduling, or data affinity, to optimize the scheduling of jobs to nodes where data is found to be local. It is a feature available in IBM Platform Symphony Advanced Edition.
3.6.1 Data-aware scheduling
The data-aware scheduling (data affinity) feature allows Platform Symphony to intelligently schedule application tasks and improve performance by taking into account data location when dispatching tasks. By directing tasks to resources that already contain the required data, application run times can be significantly reduced. In addition, this feature can help to meet the challenges of latency requirements for real-time applications.
|
Note: Data-aware scheduling is a feature available in the Advanced Edition version of Platform Symphony.
|
With the data-aware scheduling feature, you can specify a preferential association between a task and a service instance or host that already possesses the data that is required to process the workload. This association is based on the evaluation of a user-defined expression that contains data attributes capable of being collected. The evaluation of this expression is carried out against the data attributes of each service instance available to the session. Typically, a data attribute is an identifier for a data set that is already available to a service instance before it processes the workload.
Figure 3-18 illustrates the concept of data-aware scheduling at the task level. The data preference expression is evaluated and it is determined that a task in the queue prefers to run on a service instance where the service instance already possesses Dataset1. The SSM collects metadata (service attributes) from all the resources available to the session at that moment. Service B with Dataset1 is available and, because it is the best match for that task according to the specified preference, the task is then dispatched to Service B.

Figure 3-18 Data-aware scheduling
The following is a list of benefits of the data-aware scheduling provided by Platform Symphony:
•Elimination of data bottlenecks by intelligently placing workload on systems that are physically close to the required data.
– More flexible scaling of data-intensive applications with improved performance.
– Reduced application run times.
– Improved utilization through deployment of applications on enterprise grids that previously were difficult to run in a shared environment.
– Reduced reliance on expensive network storage hardware.
•Service level data publishing.
•Use of previously calculated results to speed up subsequent calculations.
•Tasks that are matched with data.
•Interfacing with data caching and distributed file system solutions.
3.7 Advantages of Platform Symphony
Platform Symphony is an enterprise class scheduler for HPC, technical computing, and cloud-computing environments.
In addition, there are other advantages of Platform Symphony:
•Get higher quality results faster:
– Starts and runs jobs fast
– Scales very high
•Lower costs:
– By increasing resource utilization levels
– Easier to manage
– Simplifies application integration
•Better resource sharing:
– Both compute and data intensive workloads can use the same resources
– Provides a sophisticated hierarchical sharing model
– Multi-tenancy model for applications
– Provides harvesting and multi-site sharing options
•Smarter data handling:
– Through an optimized and low-latency MapReduce implementation
– Consideration of data locality when scheduling tasks
– Adapts to multiple data sources
This chapter focuses on the product characteristics that are related to cloud and grid environments. The following advantages of Platform Symphony are as detailed in this publication:
•Advanced monitoring
– Node status, grid component status, application service failures, consumer host under allocated, client communication status, session status (aborted, paused, resumed, priority change), and failed tasks.
•Full reporting
– Symphony provides nine built-in standard reports based on the following information: Consumer resource allocation, consumer resource list, consumer demand, orchestrator allocation events, resource attributes, resource metrics, session attributes, task attributes, session property, and session history. Also, users can create their own custom reports.
•Analytics and metrics
•Full high availability and resiliency at all levels
– Client, middleware, schedulers, and service instances.
For more information about Platform Symphony’s software components and architecture, and its monitoring, reporting, metrics, and high availability features, see IBM Platform Computing Solutions, SG24-8073.
3.7.1 Advantages of Platform Symphony in Technical Computing Cloud
Platform Symphony is able to manage grid resources for multiple applications that are running within a grid. However, let us know move one step further. It can also host a grid with multiple applications for multiple customers, and provide requires a complete isolation of its grid environment for each customer from the other tenants (other customers).
You can use the IBM Platform Cluster Manager Advanced Edition (PCM-AE) to deploy separate grid environments to serve distinct tenants, isolating one from another. For more information, see 5.2, “Platform Cluster Manager - Advanced Edition capabilities and benefits” on page 90. Each cluster then has its own Platform Symphony scheduler that manages the resources of that particular cluster grid only. Platform Symphony can be integrated with PCM-AE as Platform Symphony’s installation and setup can be managed by a post-installation script during PCM-AE cluster deployment.
Also, cluster clouds must be able to dynamically reprovision resources to technical computing cluster environments. This can be accomplished with PCM-AE as described in 5.2, “Platform Cluster Manager - Advanced Edition capabilities and benefits” on page 90, and is called cluster flexing. With that, you can dynamically grow or shrink your cluster. Whichever middleware is used within a cluster to control the use of its resources must also be capable of following PCM-AE’s provisioning and reprovisioning operations. Platform Symphony is flexible to dynamically add or remove nodes from its grids.
In summary, Platform Symphony is not only able to manage a grid of computing resources, but is also ready to use and deploy inside a higher level of resource organization: A cloud of clusters.
3.7.2 Multi-core optimizer
The multi-core optimizer is an IBM Platform Symphony add-on product that can make most out of multi-core servers within Technical Computing cloud environments.
What can the multi-core optimizer do in a cloud multi-core environment? It cannot only reduce capital and operating expenses through running multiple I/O-intensive tasks per core. It must also efficiently matching resources with non-uniform workloads on non-uniform hardware. Moreover, it improves the performance and scalability of applications by reducing I/O and memory contention in cloud multi-core environments. This can help improve the performance and scalability of applications for these reasons:
•Optimize utilization in mixed environments. The multi-core optimizer dynamically maps services onto slots, and also allows applications to specify a service to slot ratio. Therefore, you can share heterogeneous environments among any mix of application architectures. This includes single-threaded, multi-threaded, data-intensive, I/O-intensive, compute-intensive, and so on. For example, an application that runs eight threads can be assigned eight slots.
•Reduce data and memory contention. Sometimes, the same data must be sent multiple times to a host, which places a burden on host memory and network bandwidth. This causes greater I/O contention with multiple cores on a processor, and is not good for cloud multi-core environments. The multi-core optimizer extends the common data optimization feature in Platform Symphony to optimize the distribution of common data and common data updates so that only one copy of the data is sent to each multi-core host serving the same session. This process reduces the burden on memory and network bandwidth.
•Oversubscribe slots to improve utilization. The multi-core optimizer improves overall cluster utilization by enabling intelligent over-scheduling of low priority work to available cores. It preempts the lower priority tasks currently running when a high priority task comes in to ensure that high priority tasks can reclaim the cores as needed so SLAs are met.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.