
A security breach is often referred to as an incident. An incident is any breach that results from an external intruder attack, unintentional damage, an employee testing some new program and inadvertently exploiting a software vulnerability, or a disgruntled employee causing intentional damage. Each of these possible events should be addressed in advance by adequate contingency plans.
The time to think about how to handle a security incident is not after an intrusion has occurred. When a security breach hits, it can cause widespread panic for unprepared corporations where a flurry of disorganized activity can cause even more disruption as impatient managers try to ascertain the damage while defensive administrators and engineers try and figure out a reasoned course of action. Planning and developing procedures to handle incidents before they occur is a critical piece of any security policy. The procedures should be detailed enough to encompass the practical steps in recognizing that a breach has occurred, evaluating the breach, and restoring and recovering from your losses.
NOTE
Acceptable use policy violations—for example, employees who are using corporate computing resources to trade pirated music or software—may also be handled similarly to a security breach. With the continuing pursuit of digital rights management legislation, this issue is becoming increasingly relevant to large corporations who may be held liable for their employees' actions.
Fearing unknown intrusion threats to their computer systems, some corporations restrict access to their systems and networks. Consequently, these organizations spend far too much time reacting to recurring incidents at costs to convenience and productivity. What is needed is a form of computer security response that can quickly detect and respond to incidents in a way that is both cost-efficient and cost-effective.
Several factors have contributed to the growing presence of computer network security incidents:
Reliance on computers—. An increasing number of corporations rely on computers and networks for communications and critical business transactions. Consequently, many corporations would suffer great losses to productivity should their systems become unavailable. Because of system complexity, reliance on computer networks often presents unanticipated risks and vulnerabilities.
Use of large networks—. Large networks that link governments, businesses, and academia are growing by leaps and bounds. Efficient response to computer security incidents is very important for anyone relying on a large network. Compromise of one computer network can affect a significant number of other systems connected to the network but located in different organizations—with resulting legal and financial ramifications. Incident response teams note that intruder attempts to penetrate systems occur daily at numerous sites throughout the United States, and that many corporations are often unaware that their systems have been penetrated or have been used as springboards for attacks on other systems.
How bad is the problem? Table 8-1 summarizes some major security incidences in a timeline.
Table 8-1. Timeline of Major Security Incidences
Year | Incident |
|---|---|
1988 | The first major publicized incident, the Internet Worm caused shutdowns and denial-of-service (DoS) problems for weeks to more than 6000 sites. |
1989 | The NASA WANK (Worms Against Nuclear Killers) worm caused a major loss of availability on two large government networks, resulting in significant expense and investigations by the U.S. Government Accounting Office (GAO) into network management and security. |
1995 | Attacks became more specific and intentional, such as Kevin Mitnick's theft of numerous credit card numbers in California from 1992 to 1995 (http://kevinmitnick.com/indictment.html) and the widely publicized attempted attack against a telecommunications infrastructure initiated by the Chaos Computer Club (CCC) in Germany in September 1995. The CCC called for a DoS attack against the French telecommunications systems to protest French nuclear testing in the Pacific (Chaos Computer Club, “Stop the Test,” http://www.zerberus.de/texte/aktion/atom/, September 1, 1995). |
1998 | Intruders infiltrate and take control of more than 500 military, government, and private-sector computer systems. Although originally this incident was thought to have originated from operatives in Iraq, it was later learned that two California teenagers were behind the attacks. |
1999 | The infamous Melissa virus infects thousands of computers worldwide, causing at least an estimated $80 million in damage. |
2000 | The I Love You virus infects millions of computers virtually overnight and authorities trace the virus to a young Filipino computer student. However, the Philippine government cannot prosecute him because the country has no laws against hacking and spreading computer viruses. A distributed denial of service (DDoS) attack causes Yahoo!, e-Bay, Amazon, Datek, and dozens of other high-profile websites to be offline for up to several hours. These attacks were traced back to violated computers at the University of California, Santa Barbara. |
2001 | The Code Red and Code Red II viruses, or “worms,” infect tens of thousands of systems running Microsoft Windows NT and Windows 2000 Server software, causing an estimated $2 billion in damages. The Nimda virus infects hundreds of thousands of computers around the world. |
2002 | A Danish antiglobalization group warned that protesters unable to get to Copenhagen to demonstrate in person against a European Union (EU) summit discussing enlargement of the union would attempt to shut down an EU website by having more than 10,000 people simultaneously launch a WebScript program to overload the EU presidency home page and block access to the site. Someone broke into a U.S. Department of Defense contractor HMO's server farm and stole all the drives. This organized identity theft got the names, medical records, and social security numbers of half a million U.S. soldiers and their families. |
2003 | The Sapphire worm (also called Slammer) was the fastest computer worm in history and provided the first incident demonstrating the capabilities of a high-speed worm. As the worm began spreading throughout the Internet, it doubled in size every 8.5 seconds and infected more than 90 percent of vulnerable hosts within 10 minutes. In comparison, the Code Red worm doubled in size about every 37 minutes. The slammer worm infected at least 75,000 hosts, and although it did not contain a malicious payload, it caused considerable harm just by overloading networks and taking database servers out of operation, causing significant disruption of financial, transportation, and government institutions. |
The problem of security incidences is very real, and as malicious intruders get more creative, the impact of the resulting attacks can be devastating to businesses. E-mail spam has been exploding in the past year, and corporations have been battling to thwart attacks based on e-mail bombardment. Multiple variations of DDoS attacks can cause major disruptions in business services by making unavailable critical resources. Intruders also break into computer networks and steal, among other information, credit card numbers, social security numbers, private medical records, passwords, and proprietary business information.
In a survey conducted in 2001 by the Computer Security Institute and the FBI, security experts from a variety of corporations, government agencies, financial institutions, and universities were questioned. Of 538 respondents, 85 percent detected security breaches over the previous year, and 64 percent experienced financial losses as a result. Of the 186 respondents willing to detail how much they lost, the deficits totaled nearly $378 million. In 2000, 249 respondents said they lost about $265 million. Seventy percent of those surveyed in 2001 cited the Internet as a frequent point of attack, compared to 59 percent in 2000.
It is interesting to note that a research study conducted by Jupiter Media Metrix in July 2001 reported that IT and web managers were more concerned about the impact a security breach could have on customer confidence rather than direct financial loss. More than 40 percent of the 471 IT managers surveyed by Jupiter said they are concerned about the impact online security break-ins would have on consumer trust and confidence, while only 12.1 percent cited financial loss as a top concern. Jupiter analysts said this data suggests a dramatic undervaluing of assets, especially in the wake of the rampant spread of the Code Red worm throughout the Internet in the summer of 2001 and other highly publicized security breaches.
Accurate accounting costs and profit losses caused by security incidents are rather difficult to obtain, yet it is clear that the threat of security incidences and the resulting losses in business dollars is increasing very dramatically each year. This information is extremely sensitive to corporations whose business relies more and more on reliable computing services. Many times, computer incidents are kept under cover and are not even reported, although that trend also seems to be shifting as new legislation is put into place to prosecute the perpretrators The problem is very real; corporations should have procedures in place to recover from a security breach should one occur.
An organization must first create a centralized group to be the primary focus when an incident happens. This group is usually a small core team whose responsibilities include the following:
Keeping current with the latest threats and incidents
Being the main point of contact for incident reporting
Notifying others of the incident
Assessing the damage and impact of the incident
Finding out how to avoid further exploitation of the same vulnerability
Recovering from the incident
This centralized group should map into the organizational structure of the company to make sure that someone is responsible for representing each particular area of the organization. This also helps ensure that incidents and exposures are communicated and followed up throughout the corporate hierarchy.
The core incident response team should consist of a well-rounded representation from the corporation. Essential are people who can diagnose and understand technical problems; therefore, technical knowledge is a primary qualification. Good communication skills are equally important. Because computer security incidents can provoke emotionally charged situations, a skilled communicator must know how to resolve technical problems without fueling emotions or adding complications. For example, it is not effective to call someone a moron for not having adequate access control filters in place, the lack of which may have inadvertently led to outages due to some DoS attack. In addition, the individuals on the response team may spend much of their time communicating with affected users and managers, either directly or by preparing alert information, bulletins, and other guidance.
News about computer security incidents can be extremely damaging to an organization's stature among current or potential clients. Therefore, a company spokesperson is also needed to interact with the media. If the incident is significant, the corporation will want to represent itself clearly without worrying its customers or the stock market and causing negative business repercussions. You must find personnel who have the correct mix of technical, communication, and political skills.
A member of the core incident response team should have many of the following qualifications:
Determining whether some suspicious system or user behavior is really an incident is tricky. When looking for signs of a security breach, some of the areas to look for from a network viewpoint include the following:
Accounting discrepancies
Data modification and deletion
Users complaining of poor system performance
Atypical traffic patterns
Atypical time of system use
Large numbers of failed login attempts
Detecting any anomalies in normal network behavior requires a knowledge of what is “normal” behavior. Using auditing tools that keep track of traffic patterns and historical trends can be one of the many ways you can determine normal behavior. Realistically, a corporation should not delude itself in thinking it can detect and stop all intrusions from occurring. Rather, it should put procedures in place that limit any impact of an intrusion.
It is important to have the capability to collect as much evidence as you can when a security incident has occurred. This means you should make sure you have full auditing and logging enabled on systems making up your network infrastructure. This includes switches, routers, and critical servers. In addition, it may be prudent to use packet sniffers to capture trace files and save them to regularly archived disks.
It is also critical to save all log files in a tamper-proof way, because the first thing most intruders try to do is to hide any evidence of the break-in. You can significantly diminish the threat of tampering by using a “write-once” storage system whereby once data is written, it can never be altered.
How to gather additional data when a host is suspected of being compromised can be tricky. In some instances, you may want to isolate the device to avoid any further modification to data or worse damage and try to ascertain any attack-trail information left on the device. However, you risk not having enough information to catch the attacker; therefore, some people choose to observe the attack in progress, as long as the damage created is manageable and not catastrophic. Observing the attack in progress sometimes enables you to capture a great deal of evidence on the device before the cleanup process has been able to occur, where the attacker tries to erase any trail that could potentially lead to him.
Many of the considerations for keeping track of important information when dealing with a security breach were described in the preceding chapter in the section “Audit Trails.” One of the biggest problems facing people who run large networks is correlating all the information that can be obtained from myriad networking devices. This is where the use of intrusion detection systems can be invaluable.
Because of the multitude of existing known attacks and new ones cropping up on a regular basis, the use of automated tools is essential. Intrusion detection systems are designed to detect known attack signatures and network anomolies, and these should be used at critical network access points to signal appropriate alarms that a security breach may have occurred.
Many intrusion detection systems are based on a combination of statistical analysis methods and rule-based methods:
Statistical analysis—. The statistical analysis method maintains historical statistical profiles for each user or system that is monitored. The method raises an alarm when observed activity departs from established patterns of use. This type of analysis is intended to detect intruders masquerading as legitimate users. Statistical analysis may also detect intruders who exploit previously unknown vulnerabilities that cannot be detected by any other means.
Rule-based analysis—. The rule-based analysis method uses rules that characterize known security attack scenarios and raise an alarm if observed activity matches any of its encoded rules. This type of analysis is intended to detect attempts to exploit known security vulnerabilities of the monitored systems. This analysis can also detect intruders who exhibit specific patterns of behavior known to be suspicious or in violation of site security policy. Most rule-based systems are user configurable so that you can define your own rules based on your own corporate environment.
Although intrusion detection is discussed in the preceding chapter, it is important to emphasize in the context of incident handling some of the issues to be aware of when deploying intrusion systems within your network infrastructure.
Switched networks (such as 100-Mbps and Gigabit Ethernet switches) can pose problems to network intrusion detection systems because there is no easy place to “plug in” a sensor to see all the traffic. The problem is illustrated in Figure 8-1, which shows hub versus switch functionality. Hubs differ from switches in how they transmit data from port to port. If two computers are connected to ports on a hub and computer A wants to send information to computer B, the packet is sent, the hub receives it, and then sends the packet out to all the ports on the hub. Because all traffic is sent to every port, a network intrusion detection system (NIDS) connected to port 12 can detect traffic no matter where it is being sent across the hub.

If a switch were used rather than a hub, however, data destined for computer B would only be sent to port 12. This increases efficiency by reducing packet collision, and optimizes bandwidth by reducing unnecessary transmissions. The problem is that the NIDS connected to port 12 also does not receive any data unless traffic is explicitly sent to that port.
To overcome the limitations of placing a NIDS in a switched environment, consider the following solutions:
Embed IDS within the switch—. Some vendors embed intrusion detection capabilities directly into switches. This gives administrators the flexibility to tag certain frames for inspection that will be pulled directly off the switch's backplane. The functionality of these systems needs to be ascertained because many of these intrusion detection systems do not have the full range of detection as a dedicated standalone-device NIDS.
Monitor/span/mirror port—. Many switches have a monitor (also sometimes referred to as a span or mirror) port for attaching devices such as network analyzers or a NIDS. A spanning port configures the switch to behave like a hub for a specific port and thus will echo every packet to the dedicated span port in addition to delivering it to the intended recipient. This raises a few issues, the most obvious of which is that of packet loss to the mirror/span port. Make sure that the NIDS used will have the capability to see all the traffic on a heavily loaded switch and that the switch itself can be relied on to pass 100 percent of the traffic to the spanned port; otherwise, attacks could go unnoticed even when the IDS is configured properly to look for a specific attack. If the switch enables you to mirror more than one port at a time, you also need to be aware of your traffic loads. If the switch enables you to simultaneously mirror ports 1 through 11 by copying the traffic to port 12, and the combined traffic of ports 1 through 12 exceeds that available via port 12, for instance, your IDS sensor is going to start missing a significant amount of traffic. Be aware also of an increase in packet collisions, because all ports on the switch will be continually sending packets to the mirror/span port. Often, port mirroring presents additional problems because it does not receive VLAN information and only presents one side of a full-duplex connection.
Cable taps—. A NIDS can also be connected directly to the cable via inline taps to monitor the traffic. This is illustrated in Figure 8-2 using a NIDS with cable taps. Passive Ethernet taps can be used, where “copies” of the frames are sent to a second switch dedicated to IDS sensors. The tap is able to give a NIDS the capability to view both sides of a full-duplex conversation, reduce packet loss due to collisions, and view all packets transmitted across the line. Taps can effectively increase the security of an IDS installation in a switched environment. Because the tap takes all data off the line and sends it directly to the NIDS, the NIDS behind a tap does not require an address; therefore, no traffic can be directed specifically toward the NIDS. This prevents directed attacks against the NIDS, and can actually make attackers believe that no NIDS is present to identify and track their attacks.
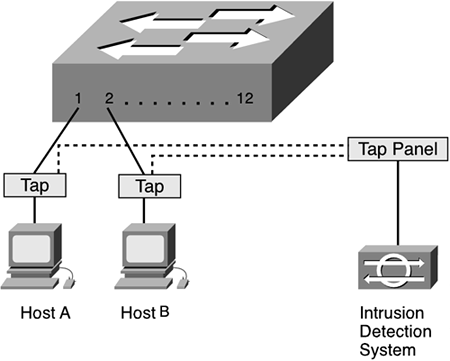
NOTE
Honey pots may also provide a useful tool. These are locations to send suspected traffic to/from an attack. For example, all traffic destined to a certain protocol that is known to be characteristic of an attack is sent to a collection host or NIDS. The data can then be collectively analyzed to mitigate some possible attacks.
Network intrusion detection systems reside at critical and often centralized locations on the network. Therefore, they must be able to keep up with, analyze, and store information about potentially thousands of hosts. The following are some of the more common limitations to be aware of:
Traffic loads—. Some network intrusion detection systems have trouble keeping up with fully loaded networking segments. An intruder can attack the sensor by just saturating the link. If the sensor cannot keep up with the high traffic rate, it starts dropping packets that it cannot process or, in the worst case, it can completely shut down the sensor. Keep in mind that frame reception and frame analysis are two different activities. Most architectures require the system to capture the packet even when it is too busy to analyze it, which takes even more time away from analysis. The key factor is in how many packets per second the system can handle capturing while simultaneously being able to analyze the captured traffic. Most vendors can handle 100-Mbps traffic using 1518-byte packets; few can handle 100-Mbps traffic using 64-byte packets. In addition, some network intrusion detection systems are capable of receiving only one direction of two-way communication, which greatly misrepresents the traffic characteristics.
State information—. State information, such as TCP connection information, IP fragmentation, and Address Resolution Protocol (ARP) tables, requires an extensive amount of memory. Make sure the system is capable of handling many simultaneous TCP connections and that it can keep track of state for a long enough time to detect slow scans (ping sweeps or port scans) where intruders scan one port/address every hour.
Attacks against a NIDS—. The IDS itself can be attacked in several ways. The system must be able to withstand the vulnerabilities discussed in Chapter 5, “Threats in an Enterprise Network,” including traffic directed at the IDS, which encompasses TCP SYN attacks, fragmentation attacks, and attacks where unexpected protocol traffic is seen.
Bypassing a NIDS—. Some clever intruders can direct their traffic in such a way as to bypass the IDS. Exploitations often relate to how varying TCP/IP stacks behave to slightly invalid input. Typical ways of causing different traffic to be accepted/rejected is to send TCP options, cause timeouts to occur for IP fragments or TCP segments, overlap fragments/segments, or send slightly wrong values in TCP flags or sequence numbers. If overlapping fragments are sent with different data, for example, some systems prefer the data from the first fragment (Windows NT, Solaris), whereas others keep the data from the last fragment (Linux, BSD). The NIDS has no way of knowing which the end node will accept, and may guess wrong.
For readers who are interested in more detail about how NIDS can be bypassed, the following two papers offer an excellent analysis of the problem:
Vern Paxon's USENIX presentation in 1998 on “Bro: A System for Detecting Network Intruders in Real-Time” (ftp://ftp.ee.lbl.gov/papers/bro-usenix98-revised.ps.Z)
Thomas H. Ptacek and Timothy N. Newsham, “Insertion, Evasion, and Denial Of Service: Eluding Network Intrusion Detection,” Technical Report, Secure Networks, Inc., January 1998 (http://citeseer.nj.nec.com/ptacek98insertion.html)
The previous information on NIDS limitations is not meant to cause undue skepticism when making the decision to use network-based intrusion detection systems. Rather, it is meant to highlight some issues that have been problematic in the past and which should be taken into consideration when shopping around for a more robust system to handle current networking security needs. A system that only gives the illusion of security should be avoided. As the limitations of these systems have become apparent—many issues were raised as early as 1998 when papers were first being written on the subject—many evolutionary improvements have been made in this area in the past few years.
Keep the previously discussed limitations in mind when looking for an IDS to deploy in your environment, and consider the following characteristics indicative of a good system. (You can find a complete list at http://www.cs.purdue.edu/coast/intrusion-detection/detection.html.)
It must run continually without human supervision. The system must be reliable enough to allow it to run in the background of the system being observed. However, it should not be a black box—that is, its internal workings should be verifiable from the outside.
It must be fault tolerant. The system must survive a system crash without rebuilding its knowledge base at restart.
It must impose minimal overhead on the system. An IDS that slows a computer to a crawl will simply not be used.
It must observe deviations from normal behavior and have timely alerting mechanisms.
It must be easily tailored to fit into various corporate environments. Every network has a different usage pattern, and the statistical analysis database or rule database should adapt easily to these patterns.
It must cope with changing system behavior over time as new applications are added.
It must be difficult to bypass. The IDS should itself be secure and not open to compromise in any way.
You must follow certain steps when you handle an incident. These steps should be clearly defined in security policies to ensure that all actions have a clear focus. The goals for handling any security breaches should be defined by management and legal counsel in advance.
One of the most fundamental objectives is to restore control of the affected systems and to limit the impact and damage. In the worst-case scenario, shutting down the system, or disconnecting the system from the network, may be the only practical solution.
Prioritizing actions to be taken during incident handling is necessary to avoid confusion about where to start. Priorities should correspond to the organization's security policy and may be influenced by government regulations and business plans. The following are things to be considered:
Protecting human life and people's safety. Systems should be implemented that control plant processes, medical procedures, transportation safety, or other critical functions that affect human life and safety and are required by law to be operational (as per Occupational Safety & Health Administration [OSHA] and other governmental safety regulations).
Protecting sensitive or classified data.
Protecting data that is costly in terms of resources. With any security incident, you want to reduce the loss as much as possible.
Preventing damage to systems.
Minimizing the disruption of computing resources. You want to reduce the spread of any damage across additional parts of the network.
A very time-consuming task is initially determining the impact of the attack and assessing the extent of any damages. When a breach has occurred, all parts of the network become suspect. You should start the process of a systematic check through the network infrastructure to see how many systems could have been impacted. Check all router, switch, network access server, and firewall configurations as well as all servers that have services that support the core network infrastructure. Traffic logs must be analyzed to detect unusual behavior patterns. The following checklist is a useful starting point:
Check log statistics for unusual activity on corporate perimeter network access points, such as Internet access or dial-in access.
Verify infrastructure device checksum or operating system checksum on critical servers to see whether operating system software has been compromised.
Verify configuration changes on infrastructure devices and servers to ensure that no one has tampered with them.
Check sensitive data to see whether it was accessed or changed.
Check traffic logs for unusually large traffic streams from a single source or streams going to a single destination.
Run a check on the network for any new or unknown devices.
Check passwords on critical systems to ensure that they have not been modified. (It would be prudent to change them at this point.)
You should establish a systematic approach for reporting incidents and subsequently notifying affected areas. Effective incident response depends on the corporate constituency's ability to quickly and conveniently communicate with the incident response team. Essential communications mechanisms include a central telephone “hotline” monitored on a 24-hour basis, a central e-mail address, or a pager arrangement. To make it easy for users to report an incident, an easy-to-remember phone number such as XXX-HELP (where XXX is the company internal extension) should be used. Users should have to remember only this one number; technology can handle the issues of call forwarding and sending out e-mail and pager alerts.
Who to alert largely depends on the scope and impact of the incident. Because of the widespread use of worldwide networks, most incidents are not restricted to a single site. In some cases, vulnerabilities apply to several million systems, and many vulnerabilities are exploited within the network itself. Therefore, it is vital that all sites with involved parties be informed as soon as possible. The incident response team should be able to quickly reach all users by sending to a central mailing list or, alternatively, sending telephone voice mailbox messages or management points-of-contact lists.
Although you want to inform all affected people, it is prudent to make a list of points of contacts and decide how much information will be shared with each class of contact. The classes of contact include people within your own organization (management, users, network staff), vendors and service providers, other sites, and other incident response teams. Here is an example of a message that can be sent to corporate employees in some situations:
We are currently experiencing a possible security breach and have disconnected all outside corporate connections. Please review the current status at http://corporate/security.info. We will let you know as soon as connectivity is restored.
Efficient incident handling minimizes the potential for negative exposure. Some guidelines for the level of detail to provide are given here (taken from RFC 2196):
Keep the technical level of detail low. Detailed information about the incident may provide enough information for others to launch similar attacks on other sites, or even damage the site's ability to prosecute the guilty party after the event has ended.
Work with law enforcement officials to ensure that evidence is protected. Many times, you may have to show law enforcement officials why they should be involved in your case—they are not yet equipped to handle an initial response to an electronic security incident. If prosecution is involved, ensure that the evidence collected is not divulged to the public.
Delegate all handling of the public to in-house PR people who know how to handle the press. These PR people should be trained professionals who know how to handle the public diplomatically.
When a security vulnerability is disclosed by a vendor without an explicit security breach occurring in your network, what are the appropriate steps for applying the appropriate system updates (patches) to the affected system? This is a very controversial subject but one which requires careful consideration for any corporation. It is imperative that a risk assessment be carried out to determine what potential effect the vulnerability of a particular device will have on your corporate network. If it is determined that a patch must be applied, all operating system updates for critical infrastructure devices should be thoroughly tested under the same guidelines and procedures as set forth by the infrastructure equipment certification process prior to initial deployment. Also, procedures must be in place to restore the system to its original state as soon as it is determined that the new software is causing added network issues and/or outages that may not have been uncovered during the certification process.
NOTE
Although outside of the scope of this book, I'd like to make a point regarding patch management of hosts in general. It is very difficult today to control corporate employee host machines that may consist of a myriad of operating systems and that have essentially no cohesive patch management control. You must carefully consider any corporate policy that may call for automated patch management in the event of a major disclosed vulnerability.
Can you trust your users to apply the appropriate patches themselves once they are educated on the risk they can cause if they don't use patches? How do you verify that the hosts are patched? If you decide that automation is the way to go, would you apply this automation directly from the vendor or have your IT department do a thorough test and then make the applicable software patch(es) available from the corporate network? At this time, patch management is a headache, but there is work in progress that may help IT departments more easily assess their corporate hosts (regardless of operating system) and in the future apply software patches in a more cohesive and controlled manner.
Do not break or halt lines of communication with the public. Bad PR can result if the public doesn't hear anything or is speculating on its own.
Keep the speculation out of public statements. Speculation of who is causing the incident or the motives behind the incident are very likely to be in error and can give a poor impression of the people handling the incident (for example, that they are given to speculation rather than to factual analysis).
Do not allow the public attention to detract from the handling of the event. Always remember that the successful closure of an incident is of primary importance.
WARNING
Never allow anyone within the organization who is not properly trained to talk to the public. The most embarrassing leaks and stories typically originate from employees who are cornered by a persistent press person. Employees are usually instructed not to talk to the public concerning contracts, mergers, financial reports, and so on for the same reasons, so the typical corporate policy need only be extended to include security incidents.
Governements are starting to become much more aware and responsive to security incident needs. The following links are good sources of information for reporting security breaches and give guidelines on how to structure reporting procedures in a corporate environment:
A general source of government information regarding cybercrime from the Computer Crime and Intellectual Property Section (CCIPS) of the Criminal Division of the U.S. Department of Justice: http://www.cybercrime.gov
An example of incident reporting procedure from the U.S. Department of Energy: http://www.ciac.org/ciac/CIAC_incident_reporting_procs.html
How to report Internet crimes as specified by the CCIPS of the Criminal Division of the U.S. Department of Justice: http://www.cybercrime.gov/reporting.htm
One of the most fundamental objectives is to restore control of the affected systems and to limit the impact and damage. In the worst-case scenario, whether it is an inside or outside attacker, you can usually shut off the attacker's access point. Doing so limits the potential for further loss, damage, or disruption but can have some adverse effects:
It can be disruptive to legitimate users.
You cannot obtain more legal evidence against the attacker.
You may not have enough information to find out who the attacker is or what motivated the attack.
An alternative is to wait and monitor the intruder's activities. This may provide evidence about who the intruder is and what the intruder is up to. This alternative must be considered very carefully because delays in stopping the intruder can cause further damage. Although monitoring an intruder's activities can be useful, it may not be worth the risk of further damage.
Documenting all details relating to the incident is crucial because doing so provides the information necessary to later analyze any cause-and-effect scenarios. Details recorded should include who was notified and what actions were taken—all with the proper date and time. A logbook for incident response should be kept that will make it easier to sort through all the details later to reconstruct events in their proper chronological order. For legal purposes, all documentation should be signed and dated to avoid the invalidation of any piece of data that could later be used as evidence if legal action is taken.
The following sections cover three example scenarios of real-world problems.
The Internet connection mysteriously collapses a number of different times. By looking at the corporate network traffic charts, we see that there is a huge disparity between incoming and outgoing traffic. A huge number of outgoing packets are heading out to the Internet without any responses. Looks like we are generating a significant number of User Datagram Protrocol (UDP) packets. What is going on? Using our cool RMON probes and data, we see that 3 million packets per minute are being generated from an internal computer to some Internet Relay Chat (IRC) site in Russia. We block out the IRC site thinking that it is the problem. Later that night, it happens again to an IRC site in the Netherlands. The corporation again loses connectivity to the Internet.
This time, we are ready and watching for the perpetrator. We catch the intruder in the act: It turns out that she is using one of the corporate computers to attack the IRC sites! The intruder was running a version of a spray program that floods UDP packets to the victim. A check of the computer being used as the attack launch site finds that its password file has more than 200 compromised accounts, so there is little chance of being able to lock out the intruder.
We have a significant dilemma. This computer is a critical corporate resource for thousands of users. Do we take down the machine, notify all users, and create new passwords? Do we take down the Internet connection and lock out everyone working on the Internet?
The answer depends largely on the corporation's decision about how to handle this and other types of scenarios. How would you handle this scenario in your environment? The answer should be obvious if you have gone through the process of doing a risk analysis and created a comprehensive corporate security policy that also includes rules and procedures for incident handling.
Some internal intrusions may be completely harmless yet still violate an acceptable-use policy. Consider the following scenario.
You notice that traffic from an unusual IP address is on the engineering network and is connecting to privileged machines. Instead of hastily turning off the Internet connection and locking out 1000 users, you take some time to trace the connection. You find no entry for the IP address in DNS, and it's not a new corporate IP address (which you probably would have known about). It turns out that the supposed intruder is an engineer who has a separate account at home and has dialed in to the modem he set up on the workstation in his office at work. Once logged on to the workstation, the engineer was able to continue gaining access to the rest of the engineering network. (See Figure 8-3.)
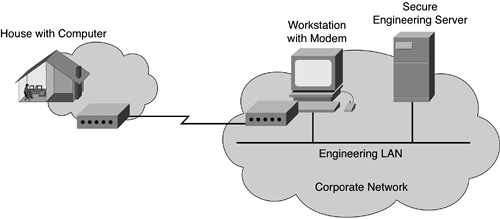
Assuming that the employee was just working overtime, you should put in place procedures about the proper usage of network access. Most likely, the corporation would mandate that all access to the corporate network be achieved through legitimate connections.
As an administrator of a corporate network, you suddenly notice a significant increase in traffic use from one of the remote office sites. This remote office uses a wireless network within the building and connects to the corporate office via a high-speed Digital Subscriber Line (DSL) line. Because this remote office has approximately 20 users who primarily use the network for e-mail and web-based order processing with the corporate servers, usual traffic loads are minimal. Now all of a sudden, the DSL line is saturated and you wonder whether it is worth getting a more expensive higher-bandwidth service.
Upon closer investigation, however, you see that the number of users sending/receiving traffic exceeds the number of employees at the remote office. It turns out that there is a bartending school next door and some savvy employees there have discovered “free” Interent access via the wireless network of the remote office and are using it to blast music from some avant-garde Internet music site while teaching students the trade of mixology.
The best way to discourage random interloping on wireless networks is to place simple authentication mechanisms in place before allowing access to a wireless network.
Recovering from an incident involves a post-mortem analysis of what happened, how it happened, and what steps should be taken to prevent a similar incident from occurring again.
A formal report with the correct chronological sequence of events should be presented to management along with a recommendation of further security measures to be put in place. It may be prudent to perform a new risk analysis at this time and to change past security policies if the incident was caused by a poor or ineffective policy. It is good practice to periodically review your corporate security policy to ensure that it is up-to-date with current corporate direction and new threats.
It is not very productive to turn your computing environment into a virtual fortress after surviving a security breach. Instead, re-evaluate current procedures and prepare yourself before another incident occurs so that you can respond quickly. Having procedures formulated before an incident happens enables the system operators to tell management what is expected should an incident occur. This arrangement aids in setting expectations about how quickly the incident can be handled and which one of many possible outcomes results from a security incident.
This chapter focused on how to deal with security incidents. Planning and developing procedures to handle incidents before they occur is a critical part of any security policy. With these procedures in place, it will be easier for the group responsible for dealing with security incidents to prioritize its actions. All organizations should create a centralized group to be the primary focus when an incident happens.
The hardest part is actually determining whether some suspicious system or user behavior is really an incident. In many corporate environments, myriad traffic information must be correlated. Intrusion detection systems are designed to detect known attack signatures and network anomolies, and these should be used at critical network access points to signal appropriate alarms that a security breach may have occurred.
After it has been determined that a security breach has indeed occurred, one of the most fundamental objectives is to restore control of the affected systems and to limit the impact and damage. Only when control is restored can the recovery process begin. Recovering from an incident involves a post-mortem analysis of what happened, how it happened, and what steps should be taken to prevent a similar incident from occurring again.
The following questions provide you with an opportunity to test your knowledge of the topics covered in this chapter. You can find the answers to these questions in Appendix E, “Answers to Review Questions.”