
In this chapter: |
The objectives of this chapter are to:
Describe the transaction semantics of the X++ language and explain how the Microsoft Dynamics AX 2009 application runtime supports database transactions.
Introduce record and company identification.
Provide an overview of the Unicode support available in Dynamics AX 2009.
Introduce the database access layer in the application runtime.
Discuss the database-triggering methods that are available on record buffer instances.
Explain the concept of temporary tables and describe when and how they are used.
Introduce Query framework enhancements and describe modeling and the reuse of complex query models in Dynamics AX.
The Dynamics AX 2009 application runtime provides a set of strong features that can help you quickly design international functionality. These runtime features store data in a database without requiring you to consider user locales or the databases that Dynamics AX supports. This chapter describes how the application runtime supports atomicity, consistency, isolation, durability (ACID) transactions in a multiple-user environment and explains the intricacies of the two supported concurrency models: optimistic concurrency and pessimistic concurrency. When committing transactions, identification is important at both the individual record level and the company level. This chapter also explains how identifiers work across application areas. Dynamics AX supports concurrent handling of multiple languages through its application runtime, which fully supports Unicode.
Two sections in this chapter focus on how Dynamics AX implements a database abstraction layer. Queries executed using specialized X++ methods provide operations support that is independent of the supported databases. Combined with the ability to write X++ code tied to specific database triggers, this independence makes it easy to write code that is reused throughout an application, whether specific data is accessed through a rich client or a Web client, or through X++.
We also explain the concept of temporary tables. Temporary tables make it possible to have local database data that is isolated from other users but that can be accessed as if it were stored directly in the database with other shared data. The concept of temporary tables is also important when you’re designing an application that allows the licensing of multiple modules; when designing the modules, you don’t need to consider whether they are enabled or disabled.
The query model enhancement sections explain the core concepts behind the reusability and complex query modeling techniques. The composite Query framework enables application developers to reuse a named query and apply additional filters and to embed a query in another query definition.
Paging extensions to the query runtime enable batch retrieval of a query result set using two modes: position-based paging and value-based paging. Position-based paging is useful for applications that need to retrieve a batch of records from a starting position in the result set. Value-based paging is useful for applications that need to retrieve a batch of records relative to a record.
The Query modeling framework enhancements allow Dynamics AX developers to model advanced query patterns. The new modeling framework introduces Query as a central data metamodel construct that can be reused across various constructs such as forms, views, and reports and within query definitions. The framework introduces functional predicates, which can be used in range filters in a query definition.
X++ includes the statements ttsbegin, ttscommit, and ttsabort for marking the beginning and ending of database transactions. To write effective business logic for Dynamics AX, you need to understand how the transaction scope affects exception handling. This section describes tts-prefixed statements and exception handling, as well as the optimistic and pessimistic concurrency models.
In this section, we include code examples of how the ttsbegin, ttscommit, and ttsabort statements affect interaction with SQL Server 2005. The X++ statements executed in the application are written in lowercase letters (select, for example), and SQL statements passed to and executed in the database are written in uppercase letters (SELECT, for example).
Note
An instance of a Dynamics AX table type is both a record object and a cursor object. In the remainder of this chapter, we refer to this combined object as a record buffer.
A transaction in X++ starts with ttsbegin and ends with either ttscommit or ttsabort. When these statements are used to start or end a transaction, the following equivalent statements are being sent to SQL Server 2005: BEGIN TRANSACTION, COMMIT TRANSACTION, and ROLLBACK TRANSACTION. In Dynamics AX 2009, transactions behave differently when they begin and end differently than they did in Dynamics AX 4.0. Whereas Dynamics AX 4.0 runs on SQL Server 2000 using implicit transaction mode, Dynamics AX 2009 runs on SQL Server 2005 using explicit transaction mode, so a transaction in the database is always initiated when a ttsbegin statement is executed. When ttsabort is executed, the equivalent statement ROLLBACK TRANSACTION is executed in the database. The execution of ttscommit results in the execution of COMMIT TRANSACTION if a SQL data manipulation language (DML) statement has been executed after the transaction has started. Otherwise, the ttscommit results in the execution of ROLLBACK TRANSACTION. COMMIT TRANSACTION is executed only if a SELECT, an UPDATE, an INSERT, or a DELETE is executed after BEGIN TRANSACTION. The execution of the different TRANSACTION statements is illustrated in the following X++ code, in which the comments show the SQL statements that are sent to the database and executed. The remaining code samples in this chapter contain the same notation, with the SQL statement shown in comments.
You can, however, have nested levels of transaction blocks to accommodate encapsulation and allow for the reuse of business logic. Setting up these accommodations involves the notion of transaction level, also known as ttslevel, and nested transaction scopes involving inner and outer transaction scopes.
Note
Consider a class developed to update a single customer record within a transaction. This class contains a ttsbegin/ttscommit block, which states the transaction scope for the update of the single instance of the customer. This class can be consumed by another class, which selects multiple customer records and updates them individually by calling the first class. If the entire update of all the customers is executed as a single transaction, the consuming class also contains a ttsbegin/ttscommit block, stating the outer transaction scope.
When X++ code is executed outside a transaction scope, the transaction level is 0. When a ttsbegin statement is executed, the transaction level is increased by one, and when a ttscommit statement is executed, the transaction level is decreased by one. Only when the transaction level is decreased from 1 to 0 is the COMMIT TRANSACTION statement sent. The execution of ttsabort causes a ROLLBACK TRANSACTION statement to be sent to the database and the transaction level to be reset to 0.
The following example illustrates the use of nested transactions and TRANSACTION statements sent to the database, as well as the changes in the transaction level.
Tip
You can always query the current transaction level by calling appl.ttslevel. The returned value is the current transaction level.
The number of ttsbegin statements must balance the number of ttscommit statements. If the Dynamics AX application runtime discovers that the ttsbegin and ttscommit statements are not balanced, an error dialog box (shown in Figure 14-1) is presented to the user, or an error with the following text is written to the Infolog: "Error executing code: Call to TTSCOMMIT without first calling TTSBEGIN."

Prior versions of Dynamics AX supported installations running on a SQL Server 2000 database. Dynamics AX 2009, however, supports only installations running on the SQL Server 2005 and SQL Server 2008 versions of the SQL Server database. With this change, Dynamics AX no longer supports the READ UNCOMMITTED isolation level and no longer provides the ability to read uncommitted data. Installations running on a SQL Server 2005 database must have Read Committed Snapshot Isolation (RCSI) enabled on the database.
RCSI prevents readers from being blocked behind writers—the reader simply reads the prior version of the record. In earlier versions of Dynamics AX, when installations were running on a SQL Server 2000 database, readers could be blocked behind writers. The READ UNCOMMITTED isolation level partly mitigated this issue when executing select statements outside a transaction scope. Now that SQL Server 2000 databases are not supported, the isolation level is READ COMMITTED both outside and inside a transaction scope in Dynamics AX.
The selectLocked record buffer method is essentially obsolete because executing selectLocked(false) on a record buffer before selecting any rows with it has no effect. Records are no longer read as uncommitted.pass.
As explained earlier, explicit transaction mode is used inside a transaction scope in Dynamics AX 2009 when it is running on SQL Server 2005. Outside the transaction scope, the autocommit transaction mode is used. Any insert, update, or delete statement sent to the database in autocommit mode is automatically committed. Although it’s still possible to execute these statements outside a transaction scope, we advise you not to because insert, update, or delete statements are committed instantly to the database. In the event of an error, you wouldn’t be able to roll back the database.
The Application Object Server (AOS) gives each transaction in Dynamics AX a unique transaction ID only if one of the following circumstances is true:
A record is inserted into a table in which the CreatedTransactionId property is set to Yes.
A record is updated on a table in which the ModifiedTransactionId property is set to Yes.
The X++ code explicitly requests a transaction by calling appl.curTransactionsId(true).
We explain allocation and types of transaction IDs in the "Record Identifiers" section later in this chapter.
The Dynamics AX application runtime has built-in support both in metadata and in X++ for the two concurrency models used when updating data in the database: optimistic concurrency and pessimistic concurrency. The optimistic model is also referred to as optimistic concurrency control (OCC), which is the term used in properties and in the application runtime.
The differences between the two models are the methods they use to avoid "last writer wins" scenarios and, consequently, to control the timing of locks requested in the database. In a "last writer wins" scenario, two or more processes select and update the same record with different data, each believing that it is the only process updating that record. All processes commit their data assuming that their version has been stored in the database. In reality, only the data from the last writing process is stored in the database. The data from the other processes is stored only for a moment, but there is no indication that their data has been overwritten and lost.
Caution
In Dynamics AX, you can develop "last writer wins" X++ code both intentionally and unintentionally. If you don’t select records for update before actually updating them, and you simply skip the transaction check by calling skipTTSCheck(true) on the record buffer, you’re likely to overwrite a different version of the record than the one you selected.
The Dynamics AX runtime manages the two concurrency models generically, and you don’t need to decide whether to use pessimistic or optimistic concurrency when you are writing transactional X++ code. You can switch from optimistic to pessimistic concurrency merely by changing a property on a table.
The following example illustrates what happens from a locking perspective when executing X++ code using pessimistic concurrency and running SQL Server 2005. The select statement contains the forupdate keyword that instructs the application runtime to execute a SELECT statement in the database with an UPDLOCK hint added. The database is instructed to acquire an update lock on all the selected records and to hold it until the end of the transaction, thereby ensuring that no other process can modify the rows. Other readers aren’t prevented from reading the rows, assuming that they don’t require an update lock. Later, when the update method is called, an UPDATE statement is executed in the database, knowing that no other process has been able to modify the record since it was selected. At the same time, the update lock is transformed into an exclusive lock, which is held until the transaction is committed to the database. The exclusive lock blocks readers requiring an update lock, as well as other writers.
The following X++ code illustrates the same scenario as in the preceding code, but it uses optimistic concurrency and SQL Server 2005. The select statement contains the forupdate keyword, which instructs the application runtime to execute a SELECT statement without acquiring any locks. Because the process doesn’t hold any locks, other processes can potentially modify the same rows. When the update method is called, an UPDATE statement is executed in the database, at which time a predicate is added to determine whether the RecVersion field still contains the value that it contained when the record was originally selected.
Note
The RecVersion field is a 32-bit integer with a default value of 1, which is changed to a random value when the record is updated.
If the RecVersion check fails when executing the UPDATE statement, another process has modified the same record. If the check doesn’t fail, an exclusive lock is acquired for the record and the record is updated. In the event of a failure, the Dynamics AX application runtime throws an update conflict exception.
The two models differ in concurrency and throughput. The concurrency difference lies in the number of locks held at the time of the commit. Whether the preceding scenario is executed using the optimistic or pessimistic model doesn’t affect the number of exclusive locks the process holds because the number of custTable records that need to be updated is the same. When you use the pessimistic model, the update locks are held for the remainder of the custTable records that were not updated. When you use the optimistic model, no locks are held on rows that are not updated. The optimistic model allows other processes to update these rows, and the pessimistic model prevents other processes from updating the rows, which results in lower concurrency. The optimistic model involves a risk, however: the update could fail because other processes can update the same rows.
The optimistic model is better than the pessimistic model for throughput. Fewer database resources are used because fewer locks are acquired. When an update fails, however, the optimistic model must retry, which leads to inferior throughput.
To illustrate the difference in the models, assume that the preceding X++ code example selected 100 custTable rows but updated only 35 of them; the updated rows are distributed evenly among the 100 selected rows. Using the pessimistic concurrency model, a graphical representation would appear as shown in Figure 14-2.

If the optimistic concurrency model were used, the picture would look slightly different, as shown in Figure 14-3. The number of exclusive locks would be the same, but there would be no update locks. Also notice that no locks would be held from the time of the selection of the rows until the first record was updated.

When choosing between the two models, you must consider the potential risk or likelihood of an update conflict. If the risk is minimal, the optimistic concurrency model most likely fits the scenario; if the risk is significant, the pessimistic concurrency model is probably your best choice. But the estimated cost of handling an update conflict and retrying can also influence your decision.
Note
Although all the preceding examples mention updates only, the same RecVersion check is made when deleting records and is therefore also applicable in those scenarios.
When two processes attempt to update the same record at the same time, locking, blocking, or potential failure can occur, depending on the concurrency model. The following scenario illustrates the behavior differences when two processes using SQL Server 2005 attempt to update two fields on the same records using pessimistic and optimistic concurrency.
Figure 14-4 illustrates pessimistic concurrency, in which Process 1 selects the CustTable record with a forupdate keyword and holds an update lock on the records. When Process 2 attempts to read the same record, also with a forupdate keyword, it is blocked behind the lock acquired by Process 1. Process 1 continues to set the new customer group and updates the record, and it converts the update lock into an exclusive lock. But Process 1 must commit before the locks can be released, and Process 2 can continue by acquiring the update lock and reading the record. Process 2 can then set the new credit maximum, update the record, and commit the transaction.

Figure 14-5 illustrates one possible outcome of the same two processes executing, using optimistic concurrency. Process 1 selects the same CustTable record with the forupdate keyword, but no locks are acquired or held for the remainder of the transaction. Process 2 can therefore select the same record in the same way, and both processes hold a record with a RecVersion value of 789. Process 1 again sets the customer group field to a new value, updates the record, and acquires an exclusive lock. At the same time, the selected RecVersion is compared to the value in the database to ensure that no other processes have updated the same record, and then the RecVersion field is assigned a new value of 543. Process 2 takes over and assigns a new credit maximum value and executes an update. As the database first attempts to acquire an exclusive lock on the record, Process 2 gets blocked behind the lock of Process 1 on the same record until Process 1 commits and releases its locks. Process 2 can then acquire the lock, but because the selected RecVersion of 789 is not equal to the value of 543 in the database, the update fails and an update conflict is thrown.
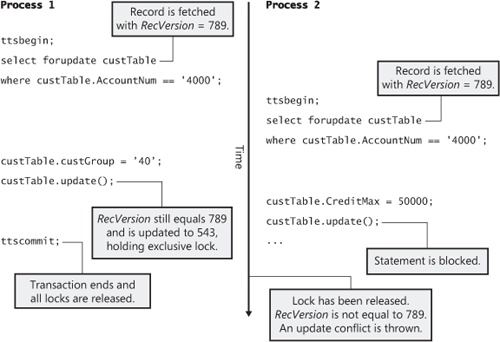
If, however, Process 1 updates its changes before Process 2 selects the record, the two processes complete successfully. This scenario is shown in Figure 14-6, in which Process 2 reads the updated version where the RecVersion value is 543. Although Process 2 is blocked behind Process 1 when it tries to update the record, the RecVersion check does not fail when Process 1 commits and releases its locks because Process 2 has read the uncommitted version from Process 1.

The examples shown in Figure 14-5 and Figure 14-6 illustrate how the application runtime behaves when the same record is updated by two processes. In the following section, we describe how the runtime behaves when the same record is updated more than once within the same process.
Consider a scenario in which two separate pieces of application logic in the same process have copied the same record into two separate buffers, both with the intent of updating different fields on each buffer. Both records would have been selected with the forupdate keyword added to the select statement. In a pessimistic concurrency scenario, both select statements would request an update lock, but because the select statements are both executed with the same database process, they wouldn’t lock or block each other. In an optimistic concurrency scenario, both select statements would retrieve the same value for the RecVersion field but wouldn’t, of course, acquire any locks.
When the two pieces of application logic consequently change and update their records, the Dynamics AX application runtime doesn’t encounter a problem when using pessimistic concurrency because each update statement updates its changed fields by using the primary key to locate the record in the database. When the application logic uses optimistic concurrency, however, the first update statement determines whether the selected RecVersion value is equal to the value in the database and also updates the RecVersion to a new value. But when the second update statement executes, it ought to fail because the selected RecVersion value no longer matches the value in the database. Fortunately, the Dynamics AX application runtime manages this situation. When the update statement is executed, the application runtime locates all other buffers holding the same record that have been retrieved with the forupdate keyword and changes the RecVersion value on these buffers to the value in the database. The second update, therefore, doesn’t fail.
The following X++ code illustrates the behavior of the Dynamics AX application runtime when the same record is copied into three different buffers. Two of the select statements also include the forupdate keyword and copy the record into the custTableSelectedForUpdate and custTableUpdated buffers. When the creditMax field on the custTableUpdated buffer changes and is later updated in the database, the RecVersion field in the custTableUpdated buffer changes to the new value in the database—but now the RecVersion field in the custTableSelectedForUpdate buffer also changes to the same value. The RecVersion field in the custTableSelected buffer doesn’t change, however, because the record was retrieved without the forupdate keyword. The X++ code is shown here.
Caution
When multiple processes want to simultaneously update the same record, the application runtime prevents the "last writer wins" scenario by acquiring update locks when using pessimistic concurrency and by performing the RecVersion check when using optimistic concurrency. However, nothing in the database or the application runtime prevents the "last writer wins" scenario if disconnected application logic within the same scenario and database process changes the same field by using two different buffers.
Dynamics AX has always included built-in support for relative updates. But it is in combination with optimistic concurrency that this support is truly useful. Relative updates can be applied only to fields of type integer and real. You apply them by changing the FieldUpdate property from the default value of Absolute to Relative, as shown in Figure 14-7.
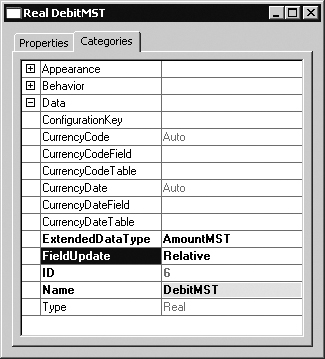
The difference between an absolute update and a relative update is that an absolute update submits FIELD = <new value> in the UPDATE statement sent to the database, and a relative update submits FIELD = FIELD + <delta value>. The delta value is the difference between the originally selected value and the newly applied value. So if you change the SalesQty field on the SalesLine table from 2 to 5, the update statement contains either SALESQTY = 5 or SALESQTY = SALESQTY + 3, depending on whether you set the FieldUpdate property on the SalesQty field to Absolute or Relative.
When you use relative updates, neither the previous value in the database nor the value it becomes is important to the updating of the application logic. The only important thing is that the difference is added to the value in the database. If all fields being updated in an update statement use relative updates and the record is selected using optimistic concurrency, the RecVersion check isn’t added to the update statement. The previous value isn’t added because it isn’t important, regardless of whether any other process changes the value between the select and the update.
Using relative updates on tables combined with pessimistic concurrency has no benefit because an update lock is acquired when the application logic selects the record, so no other processes can update the same record between the select and the update.
Warning
You shouldn’t use relative updates for fields on which the application logic is making decisions if the select is made using optimistic concurrency. You can’t guarantee that any decision made is based on the actual value of the field. For example, a Boolean field shouldn’t be set to true or false based on whether a relative updated field is equal to zero because another process could update the relative field at the same time. The Boolean field would be set based on the value in memory, which might not be the value that is eventually written to the database.
When developing applications in Dynamics AX, you can control the use of a concurrency model on two levels. The first is at a table level, by setting a property on the table definition in the Application Object Tree (AOT), and the second is by enforcing a specific model in X++ code.
Figure 14-8 shows the table-level setting, in which the OccEnabled property can be set to either Yes (the default value) or No.
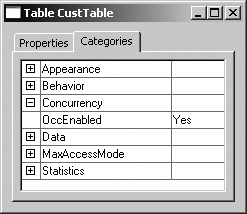
When the runtime has to execute a statement such as select forupdate custTable where custTable.AccountNum == ‘4000’, it consults the OccEnabled property on the table and translates the statement into an SQL statement with either no hint or an UPDLOCK hint added to the SELECT statement.
The concurrency model setting on the tables in Dynamics AX is based on an assessment of whether the risk of update conflict is minimal for the majority of the daily business scenarios in the application in which the specific table is updated or deleted. The scenarios can be found by using the cross-reference system in Dynamics AX or by searching for places in the X++ code where the table is either updated or deleted. If a table is never updated or deleted in the X++ code, the execution of the code isn’t influenced by whether the table is OCC enabled because the table is manipulated only from a rich client form or a Web client form. Because the form application runtime doesn’t use the table-level setting when updating records, the OccEnabled property is set to Yes by default on these tables.
Note
Only about 40 of the approximately 2100 tables in the SYS layer don’t use optimistic concurrency.
If you encounter business scenarios that require the use of a different concurrency model, you should handle them individually by applying statement-level concurrency code.
You can apply statement-level concurrency control by exchanging the forupdate keyword with either optimisticlock or pessimisticlock. This enforces the use of either optimistic or pessimistic concurrency in a scenario in which the keyword is used and overrules the table-level setting. In case of enforced pessimistic concurrency, the select statement would be written as follows: select pessimisticlock custTable where custTable.AccountNum == ‘4000’.
Note
You can also control the concurrency model with the use of a variable by calling the concurrencyModel(ConcurrencyModel concurrencyModel) method on a cursor and passing the concurrency model as the parameter. The ConcurrencyModel type is an enumeration type. A similar method is available on the QueryBuildDataSource class, and you can even specify the concurrency model in metadata when defining a query element in the AOT.
You should enforce pessimistic concurrency when serialization is necessary; serialization is implemented by requiring an update lock on a record in the database. The lock prevents two processes from entering the same scenario because entering requires an update lock. Only the process holding the update lock can enter the scenario, and the other process is blocked until the lock is released. The serializing select statement should therefore include the pessimisticlock keyword.
Best Practices
Enforcing pessimistic concurrency by using the pessimisticlock keyword is a best practice for developing serialization logic, although you can implement the same pessimistic concurrency behavior by using the forupdate keyword on a table where pessimistic concurrency is chosen at the table level. The X++ code explicitly states that an update lock is required; more important, the scenario doesn’t fail if the table property is changed. You can change the OccEnabled property through customization in higher layers.
You should enforce optimistic concurrency in situations in which it is apparent that the optimistic model would improve concurrency and throughput compared to the pessimistic model, especially when use of the pessimistic model would cause major blocking because of update locks that are never converted into exclusive locks. For example, optimistic concurrency is enforced in the Dynamics AX consistency check classes, where you can assume that only a few records are in an inconsistent state and therefore need to be corrected and updated.
You can disable the table-level concurrency settings at run time. Disabling these settings has a global impact on the business logic, however. You can override the table-level setting and enforce either optimistic or pessimistic concurrency for all tables by using the Concurrency Model Configuration form from the Administration menu. The property on the tables doesn’t change, but when the Dynamics AX application runtime interprets the forupdate keyword, it uses the global setting rather than the table-level setting. The global setting honors the interpretation of the optistimiclock or pessimisticlock keyword, so optimistic and pessimistic concurrency are still enforced in scenarios in which these keywords are used.
Although exception handling is described in Chapter 4, it deserves special attention in a discussion of optimistic concurrency because an UpdateConflict exception is thrown when the application runtime discovers an update conflict. The UpdateConflict exception is one of only two exceptions that can be caught both inside and outside a transaction scope. All other exceptions in X++ can be caught only outside a transaction scope. When the update conflict exception is caught inside a transaction scope, the database isn’t rolled back, as it is when caught outside a transaction scope.
Update conflict exceptions can be caught inside a transaction scope so that you can catch the exception, execute compensating logic, and then retry the update. The compensating logic must insert, update, or delete records in the database to get to a state in which you can retry the application logic.
There are two types of update conflicts exceptions, structured and unstructured. With structured exception handling, the catch block signature that is specific to this exception type contains an instance of the table variable. This catch block is executed only when the update conflict happens on the table instance specified in that signature. A structured exception handling framework can be particularly useful when a block of code issues multiple updates and the application intends to catch and recover from an updateconflict exception in a table buffer. The following example demonstrates the use of a structured updateconflict exception.
You might find it very difficult, however, to write compensation logic that reverts all changes within a given scenario and makes it possible to retry the application logic from a consistent state, especially because update methods can be customized to manipulate records in other tables. These changed records are then not compensated for by the compensation logic, which might be located in a completely different element. Because of these difficulties, the standard Dynamics AX application doesn’t attempt to compensate for changes to database records and retry within a transaction scope. The implemented X++ code to catch the update conflict exception and retry outside transaction scopes uses the X++ code pattern shown in the following example. The validation on the returned value from appl.ttsLevel determines whether the exception is caught inside or outside the transaction. If the exception is caught inside a transaction scope, the exception is simply thrown again. If the exception is caught outside a transaction scope, the transaction is retried unless the scenario has already been retried a certain number of times, in which case the application logic stops trying and throws an UpdateConflictNotRecovered exception. In Dynamics AX, the maximum number of retries, which is set in the OCCRetryCount macro element in the AOT, is 5.
The execution of the rich client and Web client form application runtime always uses optimistic concurrency when updating and deleting records in forms. This means that the form application runtime doesn’t use the OccEnabled property on the tables.
In a Dynamics AX installation that uses SQL Server 2005, records are always read into the form by using an uncommitted isolation level, and when records are updated or deleted, the RecVersion check is performed. This check prevents an extra round-trip to the database to reselect the record and requires an update lock. This was not the case in earlier versions of Dynamics AX (Microsoft Axapta 3.x and earlier), in which optimistic concurrency wasn’t not implemented.
If you don’t need to modify any data and merely want to ensure that the same data can be read numerous times within a transaction scope without changes, you can use the repeatable read option supported in Dynamics AX. You ensure repeatable read by issuing the following select statement, which includes the repeatableread keyword.
When Dynamics AX running with SQL Server 2005 executes the preceding statement, it adds a REPEATABLEREAD hint to the SQL SELECT statement, which is passed to the database. This hint ensures that a shared lock is held until the end of the transaction on all records the statement selects. Because the repeatableread keyword prevents any other process from modifying the same records, it guarantees that the same record can be reselected and that the field values remain the same.
When a transaction scope is committed and a record set is inserted in the database table, the AOS assigns the inserted record a unique record identifier. Record identifiers are also referred to as record IDs, and RecID is the column name. Record IDs are 64-bit integers that are used throughout the application to ensure data integrity. MorphX automatically creates RecID fields in all Dynamics AX application tables and system tables. Unlike the IDs in normal fields, record IDs can’t be removed from the tables because they are defined by the MorphX environment.
Note
The transaction ID framework uses the same numbering scheme to identify unique transactions across the application and within the company accounts. It is also modified to use a 64-bit integer as the transaction identifier. The approach in Dynamics AX 2009 is the same one used in earlier versions of the application.
The record ID allocation method uses a sequential numbering scheme to allocate record identifiers to all rows inserted in the Dynamics AX database. Sequential numbering isn’t strictly required (numbers can be used out of sequence, manually modified, or skipped), but duplicates aren’t allowed.
The AOS allocates record IDs as needed when a record is about to be inserted in the database. Each AOS allocates blocks of 250 record IDs, which are allocated per table. So each AOS holds an in-memory pool of up to 249 record IDs per table. When the entire pool for a table is used, the AOS allocates 250 new record IDs for that table.
There is no guarantee that records inserted in the same table will have sequential record IDs if they are inserted by different instances of the AOS. There is also no guarantee that the sequence of record IDs will not be fragmented. Used record IDs are not reclaimed when transactions are aborted. Unused record IDs are lost when an AOS is stopped. Because of the 64-bit integer scheme, the available number of record IDs is inexhaustible, and the fragmentation has no practical impact.
The SystemSequences database table holds the next available record ID block for each table. A specific record for a table isn’t created in SystemSequences until Dynamics AX inserts the first record into the specific table. Keep in mind that the allocation of record IDs is not per company (as it was in versions prior to Dynamics AX 4.0), but per table.
Inserted records always have a record ID, but they can also have a company account identifier (DataAreaID) for grouping all data that belongs to a legal business entity. If data in a table must be saved per company (meaning that the developer has set the SaveDataPerCompany table property to Yes), the Dynamics AX application runtime always applies the DataAreaID column as part of every index and every database access command.
In Dynamics AX 2009, multiple instances of a record ID within the same company are allowed as long as they don’t occur within the same table. The coexistence of identical record IDs is possible because the generator that creates the individual identifier exists on a per-table basis, and the uniqueness of the record includes the table ID in the reference. All companies share the same record ID allocator per table, which ensures that only one instance of each record ID exists across all companies within a particular table.
Figure 14-9 shows the differences in generation and allocation between Dynamics AX 2009 and versions prior to Dynamics AX 4.0.
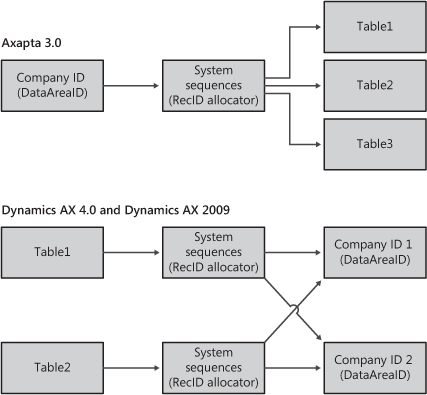
In Dynamics AX 4.0, the record ID type changed from 32-bit to 64-bit integer to prevent particularly high-volume customers from running out of available record IDs. Another reason for the change was to balance the requirements for maximum performance, minimum impact on customer and partner extensions, database upgrade time, and code upgrade time. The 64-bit integer enhancement allows for a total of 18,446,744,073,709,551,615 (0xFFFF FFFF FFFF FFFF) record IDs and provides more flexibility in allocating certain ranges for specific purposes.
From Dynamics AX 4.0, the record ID range, equivalent to the entire 32-bit range used in earlier versions, is reserved to support existing customers when they upgrade. This approach is the safest and most efficient model and can be implemented without modifying any record IDs, including foreign key references to record IDs. Only the content of the sequence number allocation table is modified during upgrade. The range from 0x0000 0001 0000 0000 through 0x7FFF FFFF FFFF FFFF is used for new records after Dynamics 4.0 to prevent possible conflict with data from previous versions.
Figure 14-10 illustrates the new allocation range for record IDs using the 64-bit integer, and it also shows where the SystemSequences database table operates. The complete identifier range is essentially divided into three groups (Upgrade Range Only, All New Record IDs, and Reserved—Do Not Use), thus extending the existing record ID range of use from 232 to 263 – 1 numbers.

The kernel generates the record ID that the AOS allocates and assigns. In two prominent scenarios, you might want the application code to overwrite this behavior:
upgrade. The DB Upgrade Preparation tool uses the direct SQL statement to insert data into the destination table from one or more source tables. In this scenario, the record ID can be allocated up front for optimization. You can also refactor the direct SQL statement by using INSERT_RECORDSET.
Performance optimization using constructs such as RecordInsertList and RecordSortedList. The application can use these two constructs to perform a bulk insert operation. In addition, the application might want to maintain referential integrity between the parent and the child table. For example, assume that the application inserts more than one customer record and the related customer transaction records. In such cases, the related record ID (foreign key) of the customer transaction record is the record ID of the customer record. To maintain this referential integrity, your application code can preallocate record IDs and assign them to the record buffers when using RecordInsertList/RecordSortedList to bulk insert records.
Dynamics AX offers a programming model to preallocate record IDs in your application. The programming model has been enhanced in Dynamics AX 2009 to have stricter control over allocation and assignment.
The SystemSequence class exposes this programming model. This class has three methods you need to know and understand:
SuspendRecId. Suspends the record ID allocation for the table passed as a parameter. The kernel no longer allocates a record ID automatically for this table for the current session.
RemoveRecIdSuspension. Releases the record ID allocation suspension for the table passed as a parameter for the current session.
ReserveValues. Reserves (preallocates) record IDs and returns the starting sequence number for the application to use. The number of record IDs to allocate is passed in as a parameter.
The following example shows how an application would use the SystemSequence class to preallocate record IDs.
If the application assigns a record ID without suspending the record ID allocator, the system throws an exception. Once the record ID allocation is suspended, the system raises an exception if the application assigns a record ID that wasn’t reserved by that session.
The Dynamics AX application runtime administers the numbering scheme automatically, according to individual record IDs and record ID blocks. The record IDs are managed in memory at the AOS cache level, whereas the block allocation uses the SystemSequences database to get information about the next record ID block value (NextVAL), native Dynamics AX table IDs (TabID), and the corresponding DataAreaID. By default, the administration toolset provides very limited manipulation possibilities for the database administrator, who can set the next block value but can’t manipulate the next individually assigned record ID. You can, however, use the SystemSequence system class to manually alter the automatic record ID assignment behavior, but only for local block assignment.
Caution
To avoid destruction of data integrity and to maintain the inter-table referencing, use the SystemSequence class with the utmost caution.
The entities in the SystemSequences table are not created when synchronizing the table definition from the MorphX Data Dictionary, nor does the record ID block of 250 numbers get allocated when starting the AOS. The entity is created the first time a record is inserted into the table.
The enhanced record ID is based on a 64-bit integer and requires existing 3.0 installations to upgrade. The upgrade process for the record ID requires changes to the 3.0 application that must be made before starting the application and data upgrade. The Dynamics AX DB Upgrade Preparation tool handles the record ID data pre-upgrade. However, some prerequisites must be met before you can use the tool. Additionally, the existing application logic must be upgraded to support the 64-bit integer. For detailed information on upgrading from Axapta 3.0 to Dynamics AX 2009, see Chapter 18, and the Upgrade Guide on the http://www.microsoft.com/dynamics/ax/default.mspx.
The business and system information in Dynamics AX is associated with company accounts and their interactions with the database tables. Several company accounts can share the same database infrastructure and use the same application logic. However, each company account must have its own set of data that other company accounts can’t directly access. Tables can contain information that can be reused by several company accounts. The design of company accounts involves the following elements:
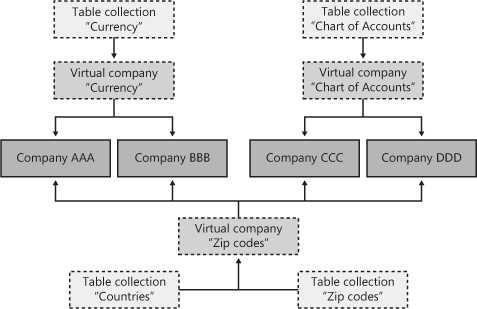
Companies. A company account can be based on one or more virtual company accounts. When you add data to a table that isn’t in a virtual company account, the data is stored directly in the company account.
Virtual companies. A virtual company account is a collection of data from several company accounts that is common to all the companies and uses a list of one or more table collections to define the tables that it contains. The data in the tables included in the table collections is stored in the virtual company account. The user can’t work directly in a virtual company account, but the contents of the shared tables can be changed through the company account.
Table collections. A table collection is a specification of a list of table names. Table collections define a graph of tables that have no foreign key relationships with tables outside the table collection. Developers define table collections. Each table and view in the system can occur only once in any one table collection, but tables and views can be added to more than one table collection. A table collection stores no table data; only companies and virtual companies store data.
The Dynamics AX application runtime uses these components to provide a powerful framework for integrating and optimizing the available and required business data across the enterprise, allowing chosen processes and structures to be centralized. The virtual company feature also improves data integrity because identical information is administrated only once and doesn’t have to be saved in multiple companies. Another significant benefit is that users don’t perceive the virtual company as a separate company account because it is completely transparent to users who are using the current company account.
Figure 14-11 illustrates how three virtual company accounts interact with company accounts and how a virtual company account can have multiple table collections associated with the individual virtual company account. Company AAA and Company BBB share the maintenance of currencies, whereas Company CCC and Company DDD share the chart of accounts. All companies share the maintenance of zip codes and countries. The last virtual company account also shows how company accounts can use multiple virtual company accounts.
Company accounts translate the organizational structures of the enterprise into elements that can be configured using Dynamics AX applications. Building the company structures by using company accounts involves the following straightforward steps:
Create company accounts.
Create table collections.
Create virtual company accounts and associate the company accounts.
When you create a table collection, the foreign keys must not be part of the table in a virtual company where the key is in the (nonvirtual) company. When developing the table collection, you might have to adjust the data model to get the full benefit of the collection. Figure 14-12 shows the location of the table collection within the AOT and the tables included in the particular table collection.

Company accounts are identified by any four characters within the Unicode-supported character set in arbitrary combination, covering both real company accounts and virtual company accounts. So the Dynamics AX application can host thousands of companies within the same database using the same application logic. When choosing identification characters, be aware of characters that can affect the generated SQL statement (such as reserved words, !, ‘’ and "") because the company identifier is an important part of the statement.
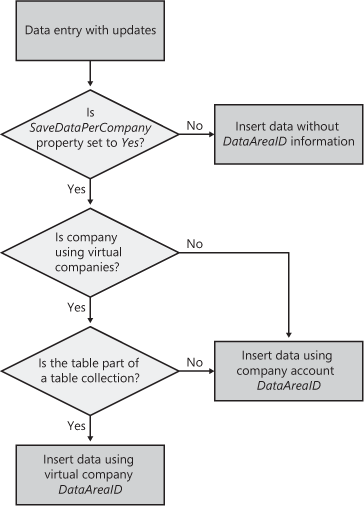
The DataArea table the application runtime uses when saving data stores information about company accounts. The SaveDataPerCompany table property determines, on a table level, whether data should be saved per company or exist as general available data without company account affiliation. If the property is set to Yes, the DataAreaID column is applied automatically for storing the company account reference.
The data flow diagram in Figure 14-13 illustrates how records are evaluated before they are inserted into tables. The process for inserting records into non-company-specific tables is important to recognize because data is related across companies, installation, database, AOT, tracing, or OLAP and is therefore accessible from all company accounts.
You can change the company account context at run time by using multiple methods, but you can also change the context at startup by using the configuration utility or by adding a company parameter directly in the application shortcut. Within the application runtime, users can launch the selection form to change the context by double-clicking the company name in the system’s status bar or by clicking FileOpenCompany on the menu bar.
Changing the company account from within the code is even more interesting when working across company accounts, such as with consolidations, sales between operations, or multisite planning. MorphX supports changing of the company account by using the changeCompany function in X++, which also exists as a reserved keyword. The changeCompany statement alters the database settings to another (separate) company account. Here is the syntax of the statement.
In this statement, expression is a string that defines the company to be used. The statement is executed on the new company. The following code example shows how to use the changeCompany statement.
The changeCompany function is heavily used by the classes tagged InterCompany*, but you can also find it elsewhere.
You can access the company-specific data in Dynamics AX from external sources by using COM Business Connector or .NET Business Connector and the X++ application logic for extracting or modeling the required data sets, or by using the Application Integration Framework (AIF). You can also access the data by interacting directly with the database.
Consultants often prefer to work directly with the database because they usually know the database tools well but sometimes don’t have experience with Dynamics AX. This approach can be challenging, however, if virtual company accounts are part of the company account data set. The database doesn’t include any information about references between company accounts and virtual company accounts.
You can use business views to expose a collection of data as self-contained database views that provide an accurate picture of a company’s status translated into human-readable format. Using business views can also provide valuable details about natively calculated fields (based on either edit or display methods), numeric field values, grouping of data, and company accounts, thereby increasing the data visibility for external parties. The Dynamics AX administrator defines and populates the business view to the database for further external processing. Creating business views doesn’t necessarily require changes to the application logic or Data Dictionary because the views are created from the application side and are data driven. Business views use existing tables and views from the AOT, but they create new database views within the same transactional database that the application runtime uses.
Here is the process for creating business views:
Create database view prefixes.
Manage the virtual company accounts from within the business views.
Define the company accounts collection.
Define groups of particular values, such as colors, numbers, and text.
Define calculated fields by company accounts.
Manage the numeric field values.
Create and define the business view.
Synchronize the created business view with the database.
In Dynamics AX 2009, the application runtime completely supports Unicode and multiple-locale input and output without the risk of data loss. The version prior to Dynamics AX 4.0 provided support for data storage in the database as Unicode data and handled Asian characters in double-byte character sets, but the application runtime didn’t support multiple codepage characters or Unicode. In any given installation, only one character set was supported because data from one character set written to the database might not get correctly converted into another character set. Data could be lost when incorrectly converted data was eventually written back to the database.
This problem was eliminated from Dynamics AX 4.0, but developers and users of Dynamics AX 2009 should still be aware that Unicode support doesn’t imply multiple-locale sorting and comparison or other features such as multiple time zone functionality or multiple country-specific functionality.
The Dynamics AX application runtime supports only Unicode data types in the database, so all data persists in the N-prefixed versions of the data types in SQL Server and Oracle. These are the NVARCHAR and NTEXT data types in SQL Server and the NVARCHAR2 and NCLOB data types in Oracle. When you upgrade to Dynamics AX 2009 from versions prior to Dynamics AX 4.0, the conversion from non-Unicode to Unicode is handled as part of the upgrade process.
Note
Although the upgrade process handles the conversion of text stored in VARCHAR, TEXT, and the equivalent Oracle data types, text could still be stored in fields of type container, which persists in columns in the database of type IMAGE in SQL Server and BLOB in Oracle. These values are not converted during the upgrade process, but the Dynamics AX application runtime converts non-Unicode data to Unicode data when the values are read from the database and extracted from the container field.
SQL Server 2005 and SQL Server 2008 store Unicode data using the UCS-2 encoding scheme, and Oracle Database 10g stores Unicode data using the UTF-16 encoding scheme. Every Unicode character generally uses 2 bytes, but in special cases, 4 bytes, to store the single character. The required disk space to store the database is therefore higher for a Dynamics AX 2009 installation than it is for installations of versions prior to Dynamics AX 4.0, given the same amount of tables and data. The required disk space isn’t doubled, however, because only string data is affected by the conversion to Unicode; the int, real, date, and container data types don’t consume additional space in the database.
As the amount of space needed to store the data increases, so does the time required to read and write data because more bytes have to be read and written. Obviously, the size of packages sent between the client tier and the server tier, and on to the database tier, is affected as well.
When you create the database to be used for the Dynamics AX installation, you can specify a collation. Collation determines the sorting order for data retrieved from the database and the comparison rules used when searching for the data.
Note
Although SQL Server 2005, SQL Server 2008, and Oracle Database 10g support the specification of collations at lower levels than the database instance (such as at the column level), the Dynamics AX application runtime does not.
Because the collation is specified at the database instance level, the Dynamics AX application runtime supports sorting using the collation setting only; it doesn’t support sorting using a different locale. Dynamics AX supports input and output according to multiple locales, but not sorting and comparison according to multiple locales.
The Dynamics AX application runtime supports Unicode through the use of UTF-16 encoding, which is also the primary encoding scheme used by Windows 2000, Windows XP, Windows Vista, Windows Server 2003, and Windows Server 2008. The use of UTF-16 encoding makes the Dynamics AX application surrogate-aware; it can handle more than 65,536 Unicode characters, which is the maximum number of Unicode characters supported by the UCS-2 encoding scheme. Dynamics AX generally uses only 2 bytes to store the Unicode character, but it uses 4 bytes when it needs to store supplementary Unicode characters. Supplementary characters are stored as surrogate pairs of 2 bytes each. An example of a supplementary character is the treble clef music symbol shown in Figure 14-14. The treble clef symbol has the Unicode code point 01D120 expressed as a hexadecimal number.
Although the application runtime uses UTF-16 encoding and the SQL Server back-end database uses UCS-2 encoding, you won’t experience loss of data because the SQL Server database is surrogate safe; it stores a Unicode character occupying 4 bytes of data as two unknown 2-byte Unicode characters. It retrieves the character in this manner as well, and returns it intact to the application runtime.
The maximum string length of a table field is, however, passed directly as the string length to use when creating the NVARCHAR type column in the database. A string field with a maximum length of 10 characters results in a new column in the SQL Server database with a maximum length of 10 double bytes. A maximum length of 10, therefore, doesn’t necessarily mean that the field can contain 10 Unicode characters. For example, a string field can store a maximum of 5 treble clef symbols, with each occupying 4 bytes, totaling 20 bytes, which is equivalent to the maximum length of 10 double bytes declared for the column in the database. No problems result, though, because the expected use of supplementary characters is minimal, especially in an application such as Dynamics AX 2009. Supplementary characters are currently used, for example, for mathematical symbols, music symbols, and rare Han characters.
The Dynamics AX application runtime also supports the use of temporary tables that are stored either in memory or in files. The temporary tables use an indexed sequential access method (ISAM)–based architecture, which doesn’t support the specific setting of collations, so data stored in temporary tables is sorted locale invariant and case insensitive. The indexes on the temporary tables have a similar behavior, so searching for data in the temporary table is also locale invariant and case insensitive.
The application runtime also performs string comparisons in a locale-invariant and case-insensitive manner. However, some string functions, such as strlwr and strupr, use the user’s locale.
Important
String comparison was changed slightly in Dynamics AX 4.0. Dynamics AX 2009 ignores case when comparing strings, but it doesn’t ignore diacritics, meaning that the letter A is different from the letter Ä. The versions prior to Dynamics AX 4.0 ignored most, but not all, diacritics. For example, the letter A was equal to Ä, but not equal to Å.
The MorphX development environment also supports Unicode. You can write X++ code and define metadata that contains Unicode characters. However, you can define elements only in the Data Dictionary, which conforms to the ASCII character set, and you can declare variables only in X++, which also conforms to the ASCII character set. The remaining metadata and language elements allow the use of all Unicode characters. So you can write comments in X++ using Unicode characters as well as string constants in X++ and in metadata.
All strings and string functions in X++ support Unicode characters, so the strlen function returns the number of Unicode characters in a string, not the number of bytes or double bytes used to store the Unicode characters. Therefore, a string that contains only the treble clef symbol, as shown earlier, has a string length of 1 rather than 2, even though it uses 2 double bytes to store the single Unicode character.
Important
Because SQL Server stores Unicode characters using UCS-2 encoding, it could return a different value when using the LEN function in Transact-SQL (T-SQL). A column that contains a single treble clef symbol stored by the Dynamics AX application would return a length of 2 when using the LEN function because the treble clef symbol is stored as two unknown Unicode characters in the database. The Dynamics AX application runtime doesn’t use or expose the LEN function, so this behavior isn’t an issue for users of the Dynamics AX application; an issue arises only if the database is accessed directly from other programs or if direct SQL statements are written from within X++, thereby circumventing the database access layer.
Dynamics AX 2009 supports reading, creation, and writing of Unicode files. All text files written by the Dynamics AX application runtime are created as Unicode files, and all text files that are part of the Dynamics AX installation are Unicode files. The application runtime also supports reading of non-Unicode files.
Two file I/O classes exist that allow you to implement X++ code that reads and writes Unicode text files: TextIO and CommaTextIO. These classes are equivalent to the AsciiIO and CommaIO ASCII character set classes. You should use these classes instead of the ASCII file I/O classes to avoid losing data when writing to files. However, you might encounter scenarios in which market, legal, or proprietary requirements demand the use of the ASCII file I/O classes.
All areas of Dynamics AX 2009 that use DLLs and COM components use the Unicode-enabled versions of the DLLs. The createFile method in the WinApi class has been replaced with the CreateFileW implementation, rather than the CreateFileA implementation of the createFile function, because CreateFileW supports Unicode and CreateFileA supports ANSI. When passing parameters to the functions in X++ code, the parameters are defined as ExtTypes::WString when passing in Unicode characters, whereas the ExtTypes::String expects non-Unicode characters to be passed.
The Binary helper class used for COM interoperability and DLL function calls has also been changed. A wString function is available to support Unicode characters to complement the existing string function.
The Dynamics AX application runtime supports the following three database platforms:
SQL Server 2005
SQL Server 2008
Oracle Database 10g
However, as mentioned earlier, you don’t usually need to focus on the underlying database because most of the differences in the databases are abstracted away by the application runtime. Unless an individual database offers very specific features, you can be almost certain that application logic developed using one database platform will execute without problems on the other platforms.
The Dynamics AX application runtime also supports the concurrent use of temporary tables where data is stored in files. You use these tables for temporary storage of records, and the application runtime uses them to mirror database records. Temporary tables are described near the end of this chapter.
Figure 14-15 shows how the execution of an update method on a record buffer in the application logic results in subsequent execution of application runtime logic. The database layer decides how to issue the correct statement through the appropriate API based on the installed database, the table itself, and how the table is mapped to the underlying database.
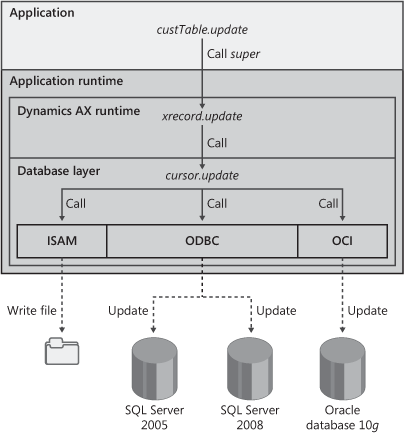
As shown in the diagram, database statements to the SQL Server 2005 and SQL Server 2008 database platforms are invoked through the Open Database Connectivity (ODBC) interface, and statements to Oracle database 10g are invoked through the Oracle Call Interface (OCI).
When tables with fields and indexes are defined in the AOT, they eventually become tables in a database. Through its database layer, the Dynamics AX application runtime synchronizes the tables defined in the application with the tables in the database. Synchronization is invoked when any of the following actions occurs:
A Dynamics AX application is installed or upgraded.
Newly licensed modules and configurations are enabled.
A table is created, changed, or deleted.
An extended data type is changed.
The Dynamics AX application runtime uses one-way synchronization in which the table definitions in the Dynamics AX application are the master, and the database schemas in the database reflect the definitions inside Dynamics AX. If the database schemas don’t match the table definitions in Dynamics AX, the schemas are modified to match the table definitions in Dynamics AX when the application is synchronized against the database.
Not all tables, fields, and indexes defined in Dynamics AX are reflected in the database. A table is synchronized to the database if it isn’t defined in metadata as a temporary table (its Temporary property is set to Yes) and the associated configuration key isn’t disabled. The configuration key could be explicitly disabled, or it could be implicitly disabled if the associated license key isn’t enabled. A field is synchronized to the database if the content should be stored in the database (its SaveContents property is set to Yes) and the associated configuration key isn’t disabled. An index is synchronized to the database if it is enabled (its Enabled property is set to Yes) and the associated configuration key isn’t disabled.
When you compare a table defined in Dynamics AX to the corresponding table in the database, the database table could contain fewer columns than defined fields in Dynamics AX and fewer indexes than defined in Dynamics AX. The indexes in the database could also contain fewer columns than defined because a defined field might not be enabled, preventing it from appearing in the database index.
Important
There is no guarantee that the application runtime can synchronize the database if a configuration key is disabled while there is data in the database because re-creating the indexes could result in duplicate values in the index.
The Dynamics AX runtime applies several system fields to each table, which are synchronized to the database. The system fields are real columns in the database tables even though they aren’t visible as columns in the AOT. The database table could therefore contain more columns than you see when you view the table definition in the AOT. Also, in certain circumstances, the Dynamics AX runtime includes an extra column in a database index to make it unique.
The Dynamics AX application runtime applies the columns shown in Table 14-1 to the tables in the database based on whether the following system fields are enabled on the table.
Table 14-1. Dynamics AX System Fields
Dynamics AX System Field | Database Column | Table Property |
|---|---|---|
RecID | RECID | Always |
recVersion | RECVERSION | Always |
dataAreaId | DATAAREAID | SaveDataPerCompany = Yes |
createdBy | CREATEDBY | CreatedBy = Yes |
createdDateTime | CREATEDDATETIME | CreatedDateTime = Yes |
createdTransactionId | CREATEDTRANSACTIONID | CreatedTransactionId = Yes |
modifiedBy | MODIFIEDBY | ModifiedBy = Yes |
modifiedDateTime | MODIFIEDDATETIME | ModifiedDateTime = Yes |
modifiedTransactionId | MODIFIEDTRANSACTIONID | ModifiedTransactionId = Yes |
The Dynamics AX application runtime requires a unique index on each table in the database to ensure that it can specifically identify each record in the database through the use of an index. The application runtime always ensures that at least one unique index exists on each table in the database; if no indexes are defined on the table or they are all disabled, the application runtime creates a RecID index as if the CreateRecIdIndex property had been set to Yes on the table. If indexes exist but none are unique, the application runtime estimates the average key length of each index, chooses the index with the lowest key length, and makes this index unique by appending the RECID column.
If you want data in the tables to be saved per company (you set the SaveDataPerCompany property to Yes), the application runtime always applies the DATAAREAID column as the first column on every index.
The tables and columns in the database generally have the same name as defined in Dynamics AX. Indexes, however, are prefixed with I_<table id>. Any index on the SALESTABLE table in the database is therefore prefixed with I_366 because the ID for the SalesTable table in Dynamics AX is 366. The Dynamics AX application runtime allows a maximum of 30 characters for names in the database, so if names of tables, fields, or indexes exceed this number, they are truncated to 30 characters, including the appended ID of the table, field, or index. For example, a table named LedgerPostingJournalVoucherSeries with an ID of 1014 becomes LEDGERPOSTINGJOURNALVOUCHE1014.
The Dynamics AX application runtime provides support for left and right justification of fields of type string. By default, string fields are left-justified, and values are stored without modification in the database. If a string field is right-justified, however, the value is prefixed with enough blanks when inserted into the database that all available space in the field is used. When values from a right-justified field are selected from the database, the application runtime removes the blanks. The application logic doesn’t know whether a field is right-justified or left-justified because both left-justified and right-justified fields appear the same when used in the X++ application code.
When the application runtime formulates WHERE clauses in DML statements, it must determine whether fields are left-justified or right-justified because it adds extra blanks to a search value when searching for values equal to, lower than, higher than, and not equal to a field in the database. The application runtime adds extra blanks to the variable in a statement like the following when passing the statement to the database. In the following statement, assume that the accountNum field is right-justified.
The statement passed to the database looks like this.
But if the search condition contains wildcard characters, as in the following X++ select statement, the application runtime must remove the blanks from the field being searched by applying LTRIM to the statement.
This code produces the expected result of selecting all custTable records where the accountNum field starts with ‘4’, and the preceding X++ statement produces a statement like the following.
The introduction of the LTRIM function in the WHERE clause prevents both of the supported databases from searching in an index for the value in accountNum, which could have a severe effect on the performance of the statement.
Note
None of the preceding SQL statements is a clear match to the statement passed to either of the databases; they are intended to serve as examples only. The application runtime applies some additional functions when the LIKE operator is used.
The application runtime also applies LTRIM if a right-justified field is compared with a left-justified field. In the following select statement written in X++, assume that accountNum is right-justified and accountRelation is left-justified.
select priceDiscTable notexists join custTable where priceDiscTable.accountRelation == custTable.accountNum |
The statement passed to the database wraps the right-justified column in an LTRIM function, and it looks like this.
SELECT ... FROM PRICEDISCTABLE A WHERE NOT EXISTS (SELECT 'x' FROM CUSTTABLE B WHERE A.ACCOUNTRELATION=LTRIM(B.ACCOUNTNUM)) |
As mentioned earlier, this behavior could have a severe effect on performance, so you should decide whether this possible degradation of performance is acceptable before you change a field from left to right justification.
The database layer in the Dynamics AX application runtime formulates SQL statements containing either placeholders or literals—that is, variables or constants. Whether the application runtime chooses to use placeholders instead of literals has nothing to do with using variables or constants when the statements are formulated in either X++ or the application runtime. The following X++ select statement, which selects the minimum price for a given customer, contains constants and a variable.
select minof(amount) from priceDiscTable
where priceDiscTable.Relation == PriceType::PriceSales &&
priceDiscTable.AccountCode == TableGroupAll::Table &&
priceDiscTable.AccountRelation == custAccount |
The statement is passed to the SQL Server 2005 database when placeholders are used, as shown here.
SELECT MIN(A.AMOUNT) FROM PRICEDISCTABLE A WHERE DATAAREAID=@P1 AND RELATION=@P2 AND ACCOUNTCODE=@P3 AND ACCOUNTRELATION=@P4 |
The statement is passed as follows when literals are used. Assume that the statement is executed in the ‘dat’ company and that you are searching for the lowest price for customer ‘4000’.
SELECT MIN(A.AMOUNT) FROM PRICEDISCTABLE A WHERE DATAAREAID=N'dat' AND RELATION=4 AND ACCOUNTCODE=0 AND ACCOUNTRELATION=N'4000' |
As you can see, the use of constants or variables in the formulation of the statement in X++ has no effect on the use of placeholders or literals when the SQL statement is formulated. However, using join or specific keywords in the statement when formulating the statement in X++ does have an effect.
The default behavior of Dynamics AX is to use placeholders, but if the Microsoft Dynamics AX Server Configuration Utility option Use Literals In Complex Joins From X++ is selected, statements containing joins use literals if the application runtime considers the statement to be a complex join. The application runtime determines that a join is complex if the statement contains two or more tables associated with the following table groups: Main, WorksheetHeader, WorksheetLine, Transaction, and Miscellaneous. Tables associated with the Group and Parameter table groups are not included when determining whether the join is complex.
Note
The SYS layer in Dynamics AX contains approximately 2100 ordinary tables, and about 700 of these are associated with the Group and Parameter table groups.
Figure 14-16 shows an example of the TableGroup property in the list of metadata properties for a table.

Note
The Server Configuration Utility option Use Literals In Complex Joins From X++ is selected by default when you install Axapta 3.0 and cleared when you install or upgrade to Dynamics AX 2009.
The difference between using placeholders and literals lies mainly in the ability of the database to reuse execution plans and the accuracy of the calculated execution plan. When literals are used in a statement, the query optimizer in the database knows the exact values being searched for and can therefore use its statistics more accurately; when placeholders are used, the optimizer doesn’t know the values. But because the execution plan is based on the exact values when literals are used, it can’t be reused when the same statement is passed again with different search values. Placeholders do allow reuse of the execution plan. Whether placeholders or literals result in the best performance depends on three factors:
How often the same statement is executed with different values
How much better the query optimizer is at calculating the optimal execution plan when the exact values are known
The total time required to execute the actual statement
Usually, both approaches result in similar execution plans; placeholders are generally preferred because execution plans can be reused, which results in better performance overall.
You can explicitly state that a join statement should always use placeholders when the SQL statement is formulated by the application runtime, regardless of the table group settings on the tables in the statement and the Server Configuration Utility options. You do this by adding the forceplaceholders keyword to the statement in X++, as shown in the following select statement (which would use literals if the previously mentioned Server Configuration Utility option were selected).
select forceplaceholders priceDiscTable notexists join custTable where priceDiscTable.accountRelation == custTable.accountNum |
The alternate keyword forceliterals is also available in X++. This keyword explicitly causes literals to be used when the application runtime formulates the SQL statements.
Tip
The Query framework also allows you to explicitly state whether placeholders or literals should be used for a given query by calling query.literals(1) to enforce literals, query.literals(2) to enforce placeholders, and query.literals(0) to let the application runtime decide which to use. Unfortunately, no enumeration is available from the Dynamics AX application runtime to use in place of these integer constants, but the macros #QueryLiteralsDefault, #QueryForceLiterals, and #QueryForcePlaceholders are available from the Query macro library.
Because Dynamics AX application table definitions are the master for the table definitions in the database, the Dynamics AX application runtime also explicitly controls the mapping between the Dynamics AX data types and types in the supported databases. Table 14-2 describes the mapping between the Dynamics AX type system and the database type system. The Dynamics AX application runtime doesn’t support database types not shown in this table.
Table 14-2. Dynamics AX and Database Type Systems
Dynamics AX | SQL Server 2005 | SQL Server 2008 | Oracle Database 10g |
|---|---|---|---|
int | INT | INT | NUMBER(10,0) |
real | NUMERIC(28,12) | NUMERIC(28,12) | NUMBER(32,16) |
string (fixed length) | NVARCHAR(length) | NVARCHAR(length) | NVARCHAR2(length) |
string(memo) | NTEXT | NTEXT | NCLOB |
date | DATETIME | DATETIME | DATE |
time | INT | INT | NUMBER(10,0) |
utcdatetime | DATETIME | DATETIME | DATE |
enum | INT | INT | NUMBER(10,0) |
container | IMAGE | IMAGE | BLOB |
guid | UNIQUEIDENTIFIER | UNIQUEIDENTIFIER | RAW(16) |
int64 | BIGINT | BIGINT | NUMBER(20,0) |
Dynamics AX includes two features that base their functionality on the fact that data has been manipulated in tables: the database log and alerts. Both features use information the Dynamics AX application runtime exposes when specific data is manipulated and when the application runtime uses configuration data entered into a Dynamics AX framework table from the application. The configuration that identifies which statements to trace and log is stored in the Databaselog table provided by the application runtime. When a statement that should be traced and logged is executed, the application is notified by executing a callback method on the Application class.
Figure 14-17 illustrates a scenario in which Dynamics AX is configured to log updates to custTable records. When the custTable.update method is called, it invokes the base version of the update method on the xrecord object by calling super. The base version method determines whether database logging has been configured for the given table and the update statement by querying the Databaselog table. If logging is enabled, a call is made to the logUpdate method on the Application object, and the X++ application logic inserts a record into the SysDataBaseLog table.

The scenario is the same for inserts, deletes, and renaming of the primary key as well as for raising events that triggers alerts.
You can use the application runtime table Databaselog to configure all the logging and events because it contains a logType field of type DatabaseLogType, which is an enumeration that contains the following four values for the database log feature: Insert, Delete, Update, and RenameKey. It also contains the following four values for alerts: EventInsert, EventDelete, EventUpdate, and EventRenameKey. When the application runtime queries the Databaselog table, it therefore queries for the configuration of a specific type of logging on a given table.
Table 14-3 shows the correlation between the database log and alert configuration. It shows what triggers the log or event, which method on Application the callback is made to, and to which table the log or event is logged.
Table 14-3. Database Log and Alert Implementation Details
Logged Event | Triggering Method on Xrecord Class | Callback Method on Application Class | Where Logged |
|---|---|---|---|
Database insert | insert | logInsert | SysDataBaseLog |
Database update | update | logUpdate | SysDataBaseLog |
Database delete | delete | logDelete | SysDataBaseLog |
Database rename primary key | renamePrimaryKey | logRenameKey | SysDataBaseLog |
Insert event | insert | eventInsert | EventCUD |
Update event | update | eventUpdate | EventCUD |
Delete event | delete | eventDelete | EventCUD |
Rename primary key event | renamePrimaryKey | eventRenameKey | EventCUD |
Note
The application runtime doesn’t query the Databaselog table in the database every time a trigger method is executed because the AOS caches all records in memory when first needed. When records are changed in the Databaselog table, the cached version must be flushed. To flush the cache, call SysFlushDatabaseLogSetup::main from X++, which not only flushes the cached memory on the current AOS but also informs other AOSs that they should flush their caches as well. The other AOSs read the flushed information from the database at predefined intervals, so they are flushed with minor delays.
A record buffer contains a variety of instance methods, and when called directly or indirectly, it results in statements or affects the number of statements sent to the database. Some of the methods can be called explicitly, and some are called implicitly by the Dynamics AX application runtime. Some of the methods are final, and others can be overridden. All the base versions of these methods are implemented on the xRecord system class. In this section, we provide an overview of these methods and describe how the Dynamics AX application runtime interprets the execution of these methods and other built-in constructs in X++. We also explain how this interpretation results in different SQL statements being passed to the database for execution.
The three main methods used on the record buffer to manipulate data in the database are insert, update, and delete. When called, each method results in an INSERT, an UPDATE, or a DELETE statement being passed from the AOS to the database where each statement manipulates a single row.
Note
If a RecID index exists on the table when the Dynamics AX application runtime formulates an UPDATE or a DELETE statement, RECID is used as a predicate in the WHERE clause to find the record. Otherwise, the shortest unique index is used as the predicate.
You can override all three methods on each table individually, as shown for the insert method in the following code. You follow the same pattern for update and delete. The super call to the base class method makes the application runtime formulate the SQL DML statement and passes it to the database. Consequently, when you override one of these methods, the application can execute additional X++ code before or after the statement is passed to the database.
public void insert()
{
// Additional code before insertion record
super(); // The SQL statement is formulated when executing super();
// Additional code after insertion of record
} |
Although none of the three methods explicitly contains the server or client method modifier, they all are always executed on the tier where the data source is located. The methods are executed on the server tier, but the methods on a temporary table can be executed on either the client tier or the server tier. Applying the server or client method modifier to these methods doesn’t change this behavior.
There are also three equivalent methods for inserting, updating, and deleting: doInsert, doUpdate, and doDelete. Each method executes the same run-time logic as the base class version of the insert, update, and delete methods; using these methods circumvents any X++ logic in the overridden versions of insert, update, and delete, so use them with caution. The doInsert, doUpdate, and doDelete methods can’t be overridden.
Caution
If you override the insert, update, and delete methods, you should honor the application runtime logic in the base class methods. If you move the logic in the methods to a class hierarchy, make sure that the X++ code there executes the equivalent doInsert, doUpdate, and doDelete methods on the record buffer. If this isn’t possible because of an error, an exception should be thrown.
The record buffer also contains a write method that can be overridden. The execution of this methods leads to the execution of either the update method or the insert method, depending on whether the record has already been inserted.
Caution
Any X++ application logic written in an overridden version of the write method is executed only if the method is explicitly called from other X++ code or when records are inserted or updated from rich client forms or Web client forms. If you’ve written X++ code using the write method, you should consider migrating the code to the insert or update method.
As with the insert, update, and delete methods, write is forced by the application runtime to execute on the tier where the data source is located, no matter what is stated in the definition of the method.
The record buffer also contains the overridable method postLoad. You don’t need to execute postLoad from X++ because the application runtime executes it when the AOS retrieves records from the database. When you override postLoad, the super call copies the retrieved buffer to the original record buffer that is accessible through the orig method. Before an overridden postLoad method calls the base class method, the state of the original buffer is undefined.
Caution
Any application logic written in the postLoad method should be lightweight code because it executes every time a record of this type is retrieved from the database. You should always consider whether the X++ code could be written elsewhere, such as in a display method.
The application runtime also forces postLoad to execute on the tier where the data source is located. Assuming that the table isn’t temporary and a client retrieves multiple records, postLoad executes on all the retrieved records sent from the database to the AOS before the AOS sends them individually to the client.
The record buffer contains two sets of validation methods that can be overridden: the validateField, validateWrite, and validateDelete methods and the aosValidateRead, aosValidateInsert, aosValidateUpdate, and aosValidateDelete methods, which were introduced in Dynamics AX 4.0.
The difference between the two sets of methods is that validateField, validateWrite, and validateDelete are invoked only from rich client and Web client forms or if called directly from X++ code, whereas aosValidateInsert, aosValidateUpdate, and aosValidateDelete are invoked implicitly from the insert, update, and delete base version methods, respectively. The aosValidateRead method is invoked when the application retrieves records from the database.
The aosValidate methods prevent reading, writing, or deleting, so they should return a Boolean value of false if the user isn’t allowed to perform the operation that the method is validating. If the method returns false, an error is written to the Infolog, and the Dynamics AX application runtime throws an Exception::Error. The form application runtime also writes an error to the Infolog if any of the validate methods return false. When a validate method is called from X++ code, the calling method determines how to handle a validate method that returns false.
The record buffer contains a dozen methods used to change the default behavior of DML statements issued in X++ code. You can call all the methods except one, concurrencyModel, with a Boolean parameter to change the default behavior, and you can call all of them without a parameter to query the current status. None of the methods can be overridden.
The following methods on the record buffer influence how the application runtime interprets select statements that use the record buffer.
Calling selectForUpdate(true) on a record buffer replaces the use of the forupdate keyword in a select statement. The X++ code
is equal in behavior to this code
Depending on the concurrency model settings on the table, no hint or UPDLOCK hint is added to the SELECT statement passed to SQL Server 2005.
Calling concurrencyModel(ConcurrencyModel::OptimisticLock) on a record buffer replaces the use of the optimisticlock keyword, and calling concurrencyModel(ConcurrencyModel:: PessimisticLock) replaces the use of the pessimisticlock keyword. The X++ code
custTable.concurrencyModel(ConcurrencyModel::OptimisticLock); select custTable where custTable.AccountNum == '4000'; |
is equal in behavior to this code
This method overrules any concurrency model setting on the table and causes either no hint or a UPDLOCK hint to the SELECT statement passed to SQL Server 2005. The type of hint depends on whether the OptimisticLock or PessimisticLock enumeration value was passed as a parameter when the application logic called the concurrencyModel method.
Tip
If you use the Query framework instead of select statements to retrieve records, you can retrieve these records with a specific concurrency model by calling concurrencyModel (ConcurrencyModel::OptimisticLock) or concurrencyModel(ConcurrencyModel::PessimisticLock) on the QueryBuildDataSource object.
Calling selectWithRepeatableRead(true) on a record buffer replaces the use of the repeatableread keyword in a select statement. The X++ code
is equal in behavior to this code
Using this keyword results in the addition of a REPEATABLEREAD hint to the SELECT statement passed to SQL Server 2005.
When readPast(true) is called on a record buffer, a READPAST ROWLOCK hint is added to the SELECT statement passed to SQL Server 2005. This hint instructs the database to skip rows on which an exclusive lock is held. But because RCSI is enabled, SQL Server 2005 doesn’t skip records on which an exclusive lock is held; it only returns the previous committed version.
The record buffer also contains a method that affects the behavior of updates and deletes. Calling skipTTSCheck(true) on a record buffer makes it possible to later call update or delete on the record buffer without first selecting the record for update. The following code, in which a custTable record is selected without a forupdate keyword and is later updated with skipTTSCheck set to true, doesn’t fail.
The execution of update method doesn’t throw an error in this example because the Dynamics AX application runtime doesn’t verify that the buffer was selected with forupdate or an equivalent keyword. In a pessimistic concurrency scenario, no update lock would be acquired before the update, and in an optimistic concurrency scenario, the RecVersion check wouldn’t be made. Using skipTTSCheck(true) could lead to the "last writer wins" scenarios described earlier in this chapter.
If skipTTSCheck hadn’t been called in the preceding scenario, the application runtime would have thrown an error and presented the following in the Infolog: "The operation cannot be completed, since the record was not selected for update. Remember TTSBEGIN/TTSCOMMIT as well as the FORUPDATE clause."
As explained in the preceding sections, insert, update, and delete methods are available on the buffer to manipulate data in the database. The buffer also offers the less frequently used write, doInsert, doUpdate, and doDelete methods for use when writing application logic in X++ code. All these methods are record-based methods; when they are executed, at least one statement is sent to the database, representing the INSERT, UPDATE, or DELETE statement being executed in the database. Each execution of these statements therefore results in a call from the AOS to the database server in addition to previous calls to select and retrieve the records.
X++ contains set-based insert, update, and delete operators as well as set-based classes that can reduce the number of round-trips made from the AOS to the database tier. The Dynamics AX application runtime can downgrade these set-based operations to row-based statements because of metadata setup, overriding of methods, or configuration of the Dynamics AX application. The record buffer, however, offers methods to change this behavior and prevent downgrading. The set-based statements and the remaining methods on the record buffer are covered in Chapter 12.
By default, any table defined in the AOT is mapped in a one-to-one relationship to a table in the underlying relational database. Any table can also, however, be mapped to an ISAM file–based table that is available only during the runtime scope of the AOS or a client. This mapping can take place as follows:
At design time by setting metadata properties
At configuration time by enabling licensed modules or configurations
At application run time by writing explicit X++ code
The ISAM file contains data and all the indexes defined on the table that maps to the temporary table that the file represents. Because working on smaller data sets is generally faster than working on larger data sets, the Dynamics AX application runtime monitors the space each data set needs. If the number exceeds 128 kilobytes (KB), the data set is written to the ISAM file; everything is kept in memory if the consumed space is less than 128 KB. Switching from memory to file has a significant effect on performance. A file with the syntax $tmp<8 digits>.$$$ is created when data is switched from memory to file. You can monitor the threshold limit by noting when this file is created.
Note
A small test run by the product development team using the Dynamics AX demo data showed that 220 CustTable records could be stored in the temporary table before data was written to the file. However, this number varies depending on the amount of data in each record.
Although the temporary tables don’t map to a relational database, all the DML statements in X++ are valid for tables operating as temporary tables. The application runtime executes some of the statements in a downgraded fashion because the ISAM file functionality doesn’t offer the same amount of functionality as a relational database. Therefore, set-based operators always execute as record-by-record operations.
Any table that acts as a temporary table is, indeed, temporary. When you declare a record buffer of a temporary table type, the table doesn’t contain any records, so you must insert records to work with the temporary table. The temporary table and all the records are lost when no more declared record buffers point to the temporary data set.
Memory and file space aren’t allocated to the temporary table before the first record is inserted, and the table resides on the tier where the first record was inserted. For example, if the first insert occurs on the server tier, the memory is allocated on this tier, and eventually a file is created on the server tier. The tier on which the record buffer is declared or subsequent inserts, updates, or deletes are executed is insignificant.
Important
A careless temporary table design could lead to a substantial number of round-trips between the client and the server and result in degraded performance.
A declared temporary record buffer contains a pointer to the data set. If two temporary record buffers are used, they point to different data sets by default, even though the table type is the same. To illustrate this, the X++ code in the following example uses the TmpLedgerTable temporary table defined in Dynamics AX 2009. The table contains three fields: AccountName, AccountNum, and CompanyId. The AccountNum and CompanyId fields are both part of a unique index, AccountNumIdx, as shown in Figure 14-18.

The following X++ code shows how the same record can be inserted in two record buffers of the same type. Because the record buffers point to two different data sets, a "duplicate value in index" failure doesn’t result, as it would if both record buffers had pointed to the same temporary data set or if the record buffers had been mapped to a database table.
To share the same data set, you must call the setTmpData method on the record buffer, as illustrated in the following similar X++ code in which the setTmpData method is called on the second record buffer and passed in the first record buffer as a parameter.
The preceding X++ code fails on the second insert with a "duplicate value in index" error because both record buffers point to the same data set. You would notice similar behavior if, instead of calling setTmpData, you simply assigned the second record buffer to the first record buffer, as illustrated here.
However, the variables would point to the same object, which means that they use the same data set.
When you want to use the data method to copy data from one temporary record buffer to another, where both buffers point to the same data set, you should write the copy like this.
Warning
The connection from the two record buffers to the same data set would be lost if the code were written as tmpLedgerTable2 = tmpLedgerTable1.data. The temporary record buffer would be assigned to a new record buffer in which only the data part is filled in, but with a connection to a new data set.
As mentioned earlier, when no record buffer points to the data set, the records in the temporary table are lost, the allocated memory is freed, and the file is deleted. The following X++ code example illustrates this situation, in which the same record is inserted twice using the same record buffer. But because the record buffer is set to null between the two inserts, the first data set is lost, so the second insert doesn’t result in a duplicate value in the index because the new record is inserted into a new data set.
These temporary table examples don’t use ttsbegin and ttscommit statements because you must call the ttsbegin, ttscommit, and ttsabort methods on the temporary record buffer to work with transaction scopes on temporary tables. The ttsbegin, ttscommit, and ttsabort statements affect only manipulation of data related to ordinary tables that are mapped to relational database tables, as illustrated in the following X++ code, where the value of the accountNum field is printed to the Infolog even though the ttsabort statement was executed.
To successfully abort the inserts of the table in the preceding scenario, you must instead call the ttsbegin and ttsabort methods on the temporary record buffer, as shown here.
When you work with multiple temporary record buffers, you must call the ttsbegin, ttscommit, and ttsabort methods on each record buffer because there is no correlation between the individual temporary data sets.
Important
When exceptions are thrown and caught outside the transaction scope, where the Dynamics AX application runtime has already called the ttsabort statement, temporary data isn’t rolled back.
When you work with temporary data sets, make sure that you’re aware of how the data sets are used inside and outside transaction scopes.
Important
It is generally not a problem that the ttsbegin, ttscommit, and ttsabort statements have no impact on temporary data if the temporary record buffer isn’t declared until after the first ttsbegin statement is executed. This only means that the record buffer will be out of scope and the data set destroyed if an exception is thrown and caught outside the transaction scope.
The database-triggering methods on temporary tables behave in almost the same manner as they do with ordinary tables, with a few exceptions. When insert, update, and delete are called on the temporary record buffer, they don’t call any of the database-logging or event-raising methods on the application class if database logging or alerts have been set up for the table.
Note
In general, you can’t set up logging or events on defined temporary tables. However, because ordinary tables can be changed to temporary tables, logging or events could already be set up. We describe how to change the behavior of an ordinary table later in this chapter.
Delete actions are also not executed on temporary tables. Although you can set up delete actions, the Dynamics AX application runtime doesn’t try to execute them.
Tip
You can query a record buffer for acting on a temporary data set by calling the isTmp record buffer method, which returns true or false depending on whether the table is temporary.
Dynamics AX allows you to trace SQL statements, either from within the rich client or from the Dynamics AX Configuration Utility or the Server Configuration Utility. However, SQL statements can be traced only if they are sent to the relational database. You can’t trace data manipulation in temporary tables with these tools.
As explained earlier, you can make a table temporary during various phases of a Dynamics AX implementation. To define a table as temporary, you change the Temporary property on the table from the default value of No to Yes. This prevents a matching table from being created in the underlying relational database when the table is synchronized against the database. Instead, memory or a file is allocated for the table when needed. Figure 14-19 shows the Temporary property on a table where the value is set to Yes, thereby marking the table as temporary at design time.

Best Practices
Tables that are defined as temporary at design time should have Tmp inserted as part of the table name rather than at the beginning or end (e.g., InventCostTmpTransBreakdown). This improves readability of the X++ code when temporary tables are explicitly used. In previous versions of Dynamics AX, the best practice was to prefix temporary tables with Tmp, which is why a number of temporary tables are still using this syntax.
When you define a table by using the AOT, you can attach a configuration key to the table by setting the ConfigurationKey property on the table. The property belongs to the Data section of the table properties, as illustrated in Figure 14-19.
When the Dynamics AX application runtime synchronizes the tables to the database, it synchronizes tables for licensed modules and enabled configurations only. Whether a table belongs to a licensed module or an enabled configuration depends on the settings in the ConfigurationKey property. If the configuration key is enabled, the table is synchronized to the database; if the configuration key isn’t enabled, the table is disabled and behaves like a temporary table. Therefore, a run-time error doesn’t occur when the application runtime interprets X++ code that accesses tables that aren’t enabled.
You can use X++ code to turn an ordinary table into a temporary table and use it as such by calling the setTmp method on the record buffer. From then on, the record buffer is treated as though the Temporary property on the table were set to Yes.
Note
You can’t define a record buffer of a temporary table type and turn it into an ordinary table, partly because there is no underlying table in the relational database.
The following X++ code illustrates the use of the setTmp method, in which two record buffers of the same type are defined; one is made temporary, and all records from the database are inserted into the temporary version of the table. The temporary record buffer therefore points to a data set containing a complete copy of all the records from the database belonging to the current company.
Notice that the preceding X++ code uses the doInsert method to insert records into the temporary record buffer. It does this to prevent execution of the overridden insert method. This method inserts and updates records in other tables that aren’t switched automatically to temporary mode just because the custTable record buffer is temporary.
Caution
You should use great care when changing an ordinary record buffer to a temporary record buffer because application logic in overridden methods that manipulates data in ordinary tables could be inadvertently executed. This could happen if the temporary record buffer is used in a form and the form application runtime makes the call to the database-triggering methods.
The composite query framework builds on the extensible query framework in Dynamics AX. A composite query allows you to embed one query into another query to provide database subquery equivalent functionality. Composite queries are very useful for personalization. For example, if a query ‘Cust’ retrieves all the data from CustTable, you can bind this query to one or more primary list pages. The secondary list pages are personalized for the user. In this example, the secondary list page displays only the customers belonging to a particular customer group or all the customers who live or operate in a particular state. The fundamental idea here is that the secondary list page provides additional filters on the data displayed in the primary list page. To facilitate this framework, composite queries build additional filters on top of existing queries.
Follow these steps to create a composite query:
Create a new query.
Change the name to CustomersInWA.
Drag the existing Cust query to the Composite Query node of the query CustomersInWA.
Expand the Cust query under the Composite Query node.
Expand the Data Sources node under the Cust query.
Expand the Customers data source under the Data Sources node.
Right-click Ranges and add a new range.
Select properties for the range.
Change the field to State.
Change the value to WA.
This composite query is now ready to use. When this composite query is bound to the secondary list page, the list page displays only customers who live and or operate in Washington State.
Note
The composite query doesn’t guarantee to return more data than the primary query it is built on.
The list pages framework in Dynamics AX 2009 is built using composite queries.
The paging framework for queries is new in Dynamics AX 2009. It supports primarily the Enterprise Portal framework and the list pages framework.
There are two types of paging: position-based paging and value-based paging.
Position-based paging is used primarily in Enterprise Portal. In position-based paging, a Web page displays a specified number of records. The user has to click Next or Previous to navigate to additional records.
Position-based paging uses the ROW_NUMBER function provided by the database and has the same limitations as the ROW_NUMBER function. Performance degrades when the table has huge amounts of data and the page appears toward the end of the result set. The database is then forced to use table scans. Though this is not a common usage pattern for Web-based scenarios, we discourage using position-based paging for such scenarios.
Two APIs, both available on the QueryRun object, are important to understand when you’re using position-based paging:
QueryRun.EnablePositionPaging(true/false) enables or disables position-based paging and is false by default.
QueryRun.AddPageRange(startingPosition, numberOfRecordsToFetch) indicates the starting position and the number of records to fetch.
The following example illustrates the usage of position-based paging APIs.
Value-based paging is primarily used by the list pages framework. In value-based paging, records that are greater or lesser than the specific value for a field in the ‘ORDER BY’ clause are returned.
Note
The query should have at least one valid data source with at least one valid ‘ORDER BY’ field. The ‘ORDER BY’ field indicates the location of the records to be fetched. Like position-based paging, value-based paging doesn’t support temporary tables. Also, value-based paging can’t be used on queries that contain outer joins.
Two APIs, both available on the QueryRun object, are used in value-based paging:
QueryRun.EnableValueBasedPaging(true/false) enables or disables value-based paging and is false by default.
QueryRun.ApplyValueBasedPaging(Common,ForwardDirection) indicates the starting position and direction in which to fetch. The first parameter takes the table as a parameter. The assumption is that this table has the value for all the ‘ORDER BY’ fields that can be used as a starting position. The first parameter should match the exact structure of the query.
The following example illustrates the usage of value-based paging in queries.
The Query framework in Dynamics AX 2009 has some noticeable enhancements. You can now write complex queries, such as nested joins, and design union queries. You can also create a query once and use it in multiple places; in earlier versions, you had to remodel the same query to achieve this functionality.
Using the X++ select statement and the AOT Query object model are two ways to retrieve data from the database. AOT Query provides a set of object models and APIs that allow the query to be constructed and modified dynamically at run time. For example, based on run-time requirements, such as user input, you can add or modify query data sources, range filters, order by fields, and group by fields. AOT Query is more flexible than the X++ select statement, which can’t be modified at run time.
Prior to Dynamics AX 2009, AOT Query had some limitations when compared with the X++ statement. The most noticeable was the lack of support for complex query structures. Certain query structures would lead to dropped data sources and thus an incorrect SQL statement.
In Dynamics AX 2009, Exist Join statements are nested only when joined nodes are nested on the AOT.
To join a query data source to another query data source that isn’t its direct parent inside MorphX, you can choose the name of any data source from the drop-down list of the JoinDataSource property, as shown in Figure 14-20.

The drop-down list is prepopulated with a list of query data sources that the current query data source can join to. Query data sources inside an Exist Join, for example, can’t be joined to another query data source outside of the Exist Join because the Exist Join query data source doesn’t return any data. To join data sources in X++, add the name of the query data source to the current data source.
In SQL, when you want to merge the results of two or more select statements and work on them as one, you use a union query. Dynamics AX 2009 supports union queries through the AOT Query object. When designing a union query, you must pick the first query data source and its fields carefully because all the data retrieved is stored inside the table buffer of the first data source.
You also need to be sure that the configuration key associated with the table of the first data source is a super key of the configuration keys of the rest of the query data sources. Using this super key ensures that the first query data source isn’t disabled while some of the secondary data sources are enabled.
To create a union query on the AOT, follow these steps:
Create a query and specify the QueryType to be Union, as shown in Figure 14-21.
Add the first query data source. Optionally add Exist Joins and NotExist Joins.
Add the secondary query data sources and specify the union type, as shown in Figure 14-22. You can add Exist Joins and NotExist Joins as an option.

Be sure to align the fields of the query data sources properly. The data types of the fields need to be compatible—both type compatible and size compatible—with those of the first query data source. The size of the field of the first query data source can’t be smaller than that of the corresponding field in other query data sources. Figure 14-23 shows the Align field in a union query.
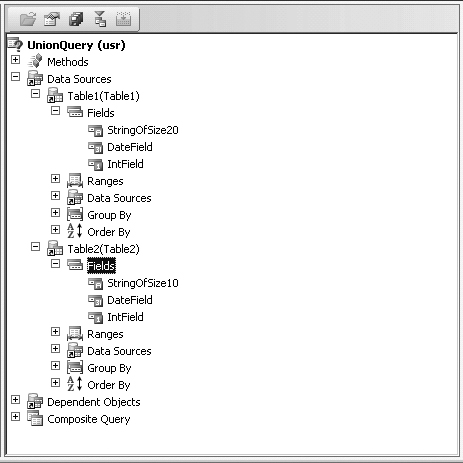
When aligning fields, you also need to consider that the field size could change during customization. For a union query, if the size of an extended data type associated with a field in the secondary query data source is increased, incompatibility could result. In Figure 14-23, the first field of the first data source has a string size of 20, and the first field of the second data source has a string size of 10. So they are compatible in size.
Note
A couple other issues can come up when you’re using union queries. First, when a secondary query data source is disabled through the configuration key, the union ignores that branch. Second, the configuration key has another implication for field alignment. If a field in the first query data source of a union query is disabled, the corresponding fields in the secondary query data sources must also be disabled.
When you use union queries, two code elements are important: the UnionBranchID field and the Forupdate flag.
All the data retrieved is stored in the records in the table buffer of the first query data source. When you want to know where the data on the current record came from, check the UnionBranchId field on the table buffer. This field returns the 1-based branch number of the data source. The reason a branch number is used instead of a table ID value is because a table might appear multiple times in a union. Also, if future versions of Dynamics AX support inner/outer joins, fields might need to come from multiple tables. Keep in mind that when UnionBranchId is calculated, all branches are taken into account, including those disabled through configuration keys. So you can write code without having to worry about configuration keys at run time.
When you set the forupdate flag on the data sources of a union query, the union query can be used to update the data in the underlying tables. UnionBranchId and the alignment mapping information on the Query object help in this effort. Dynamics AX 2009 maps the data on the table buffer of the first query data source to the table buffer of the corresponding query data source and performs an update.
The following code example shows how to create and use a union query in X++.
People often work with data specific to their domain. This data comes from different tables. The same data may be created, displayed, and modified on forms and Web forms. The forms are then processed in business logic and analyzed in reports.
Before Dynamics AX 2009, the shape of the data had to be defined in multiple places: on forms and Web forms, and forms and data set data sources; in X++ code, the X++ select statement, or the AOT Query object; and view uses view data source, and report uses report query. In other words, view data source is the building block for view. View data sources, which represent tables, are added to view to form the definition of view. The report query construct under each report in the AOT defines the table joins for the report. Shaping data for so many different places is not only redundant but also error-prone and not maintainable. The design of the AOT imposes some extra limitations. For example, when you design a form using a form data source, you can’t explicitly choose a join relationship between two form data sources. The first relationship between the two is automatically picked up, which in some cases might be incorrect. Another example is view, in which you can construct only a single parent/child lineage. Also, any enhancement made to AOT Query, like the union support just added, needs to be duplicated in all the other places.
Dynamics AX 2009 lets you deal with all these data reuse issues by using a single tool: AOT Query. In AOT Query, you can define the collection of tables and the relationship between the tables once and then reuse the data in many different venues. As we mentioned earlier, AOT Query now supports complex joins and union queries. In most cases, reusing a query is as easy as dragging and dropping an AOT Query. You can do this in AOT Reports and AOT View nodes, as shown in Figure 14-24 (for reports) and Figure 14-25 (for views).

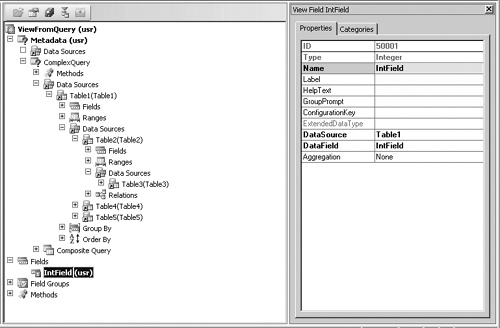
When you drag a modeled query onto a form or a Web form, a number of form data sources are automatically generated. These form data sources match the visible query data sources of the modeled query. Just as on conventional forms, these places are where you specify form-specific behavior and add form-specific code.
When using a modeled query on forms and Web forms, users need to specify how the data is to be retrieved to match the behavior of the user interface. For example, when you define the shape of your data to include a sales header with sales lines, your query is simply an outer join between SalesTable and SalesLine. But when you design a form that has a sales header shown in one grid and a sales line shown in another grid, where the sales line grid shows only the sale lines of the sales order that is currently selected, you don’t issue a single outer join to retrieve data for both sales orders and sales lines in one query. Instead, you need to issue two queries, one for the sales header grid to retrieve all sales headers and one for the sales line to retrieve sales lines only for the sales header that is currently selected.
To reuse the same query on forms, you have to annotate the data-fetching behavior of the form data sources through LinkType, on the join between SalesTable and SalesLine. The LinkType concept is on par with the existing form data source design experience. LinkType has six values for designing the form data source: active, delayed, inner, outer, exist, and NotExist. When you use a modeled query on a form, the modeled query has already captured inner, outer, exist, and NotExist joins. The only relevant LinkType is active and delayed. For a single join relationship, you can specify the LinkType on either end of the joined data source. To decide where to put an active or delayed LinkType, ask the question, which data needs to be retrieved first on the user interface? Depending on the answer to that question, put the LinkType on the other data source.
Figure 14-26 shows a form using a modeled query and the setting of the LinkType property between the Table3 and Table4 data sources.

The collection of active or delayed link types specified effectively break a single query into multiple queries. These subqueries have to be executed in a specific order in response to user interface events. Some of these subqueries are linked through dynalinks to other subqueries.
When a modeled query is used on a form or a Web form, the form engine does the following:
It generates corresponding form data sources from query data sources. If some form data sources already exist, it checks the compatibility of the form data sources and keeps all the compatible form data sources. This means that no work is lost on those form data sources. For data sources that are not compatible, it issues a dialog box asking the user to confirm that the form data source should be deleted.
When the form is opened, the form engine takes the LinkType annotation on the form, analyzes the query structure, checks for any error conditions, and computes the sub-queries that are associated with a form data source.
Compare this behavior to how the form engine works on a conventional form that doesn’t use a modeled query. Both create queries and associate them to form data sources. One computes that from a query, using query structure and LinkType information. The other uses JoinSource and LinkType information.
Dynamics AX 2009 allows you to specify range values for queries using a restricted set of function calls. This mechanism is in addition to the existing ways to specify range values, which use either literal values or specify expressions by enclosing them in "( )" symbols. To use the new syntax, you need to follow these rules:
The function should be a static function in the SysQueryRangeUtil class.
The function should return a value that is of the same syntax as regular range values.
The SysQueryRangeUtil class in Dynamics AX 2009 includes a number of functions that list pages used to dynamically control the data that is shown based on the value that is returned by the function. For example, the currentUserId function returns the user ID of the current logged-on user. Some other functions and their usage are shown here.
The function call has to use the same syntax as passing expressions in a range value. The whole value needs to be surrounded by an opening "(" and closing ")" parenthesis. You can see the SysQueryRangeUtil class for a number of examples of the functions that ship with Dynamics AX 2009, and you can see their usage in some of the queries in the AOT for example, EmplTableListPage. In this class, all the functions return string values. You can write functions that return any of the primitive data types supported by Dynamics AX 2009. For example, if you have a function named orders that returns the count of orders that might be an int64, you can use it in the query in a number of ways, such as (orders()) or (orders() + 1). The following code shows how to specify range values using this syntax.