
In this chapter: |
The objectives of this chapter are to:
Describe how to control the execution of logic in a three-tier environment and what issues to consider when designing and implementing high-performance X++ code.
Explain how to optimize database performance and minimize database interaction by using set-based operators and caching, limiting locking, and optimized sql statements.
Explain the usage of tools available in the Microsoft Dynamics AX 2009 development environment for monitoring client/server calls, database calls, and X++ calls.
Performance is often an afterthought. Many development teams rarely pay attention to performance until late in the development process or, more critically, after a customer reports severe performance problems in a production environment. After a feature is implemented, making more than minor performance improvements is often too difficult. But if you know how to use the performance-optimization features in Dynamics AX, you can create designs that allow for optimal performance within the boundaries of the Dynamics AX development and runtime environments.
This chapter describes what to consider when developing features to be executed in a three-tier environment in which X++ code can be executed on either the client tier or the server tier. It also introduces the performance-enhancing features available within the Dynamics AX development environment, such as set-based operators for database interaction; caching, which can be set up in metadata or directly in code; and optimistic concurrency control for limiting database locking. The chapter concludes by describing some of the performance-monitoring tools available within the Dynamics AX development environment that provide a reliable foundation for monitoring client/server calls, database activity, and X++ code execution.
Client/server communication is one of the key areas of optimization for Dynamics AX. In this section, we detail the best practices, patterns, and programming techniques that yield optimal communication between the client and the server.
The following three techniques can cover between 50 and 80 percent of round-trips in most scenarios:
Use CacheAddMethod for all display and edit methods on a form.
Refactor RunBase classes to support marshaling of the dialog between client and server.
Properly index tables.
Display and edit fields are used on forms to display data that must be derived or calculated based on other information in the table. They can be written on either the table or the form. By default, these fields are calculated one by one, and if there is any need to go to the server during one of these methods, as there usually is, each of these functions goes to the server individually. These fields are recalculated every time a refresh is triggered on the form, which can originate from editing fields, using menu items, or the user requesting a form refresh. Such a technique is expensive both from a round-tripping perspective as well as in the number of calls it places to the database from the Application Object Server (AOS).
For display and edit fields declared in the form’s Data Source, no caching can be performed because the fields need access to the form metadata. If possible, you should move these methods to the table. For display and edit fields declared on a table, you have to use FormDataSource.CacheAddMethod to enable caching. (See http://msdn.microsoft.com/en-us/library/aa893273.aspx for a detailed definition of display methods.) This method allows the form’s engine to calculate all the necessary fields in one round-trip to the server and then to cache the results from this call. To use cacheAddMethod, in the init method of a Data Source that uses display or edit methods, call cacheAddMethod on that Data Source, passing in the method string for the display or edit method. For an example of this, look at the SalesTable form’s SalesLine Data Source. In the init method, you find the following code.
If this code is commented out, each of these display methods is computed for every operation on the form Data Source, thus increasing the number of round-trips to the server as well as the number of calls to the database server.
For Dynamics AX 2009, Microsoft made a significant investment in the CacheAddMethod infrastructure. In previous releases, this worked only for display fields, and only on form load. In Dynamics AX 2009, the cache is used for both display and edit fields, and is used throughout the lifetime of the form, including reread, write, refresh, and any other method that reloads the data behind the form. On all these methods, the fields are refreshed, but the kernel now refreshes them all at once rather than individually, as it did in previous versions of Dynamics AX.
RunBase classes form the basis for most business logic inside of Dynamics AX. RunBase provides much of the basic functionality needed to perform a business process, such as displaying a dialog, running the business logic, and running the business logic in batches. When business logic executes through RunBase, the logic flows as shown in Figure 12-1.
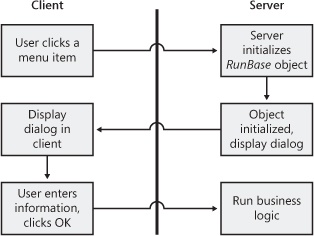
Most of the round-trip problems of RunBase originate with the dialog. The RunBase class should be running on the server for security reasons as well as for the fact that it is accessing lots of data from the database and writing it back. A problem occurs when the RunBase class itself is marked to run on the server. When the RunBase class is running on the server, the dialog is created and driven from the server, causing an immense number of round-trips between the client and the server.
To avoid excessive round-trips, mark the RunBase class to run on Called From, meaning that it will run on either tier, and then mark either the construct method for the RunBase class or the menu item to run on the server. Called From enables the RunBase framework to marshal the class back and forth between the client and the server without having to drive the dialog from the server, significantly reducing the round-trips needed across the application. Keep in mind that you must implement the pack and unpack methods in a way that allows this serialization to happen.
For an example of the RunBase class, examine the SalesFormLetter class in the base application. For an in-depth guide to implementing RunBase to optimally handle round-trips between the client and the server, refer to the Microsoft Dynamics AX 2009 White Paper, "RunBase Patterns," which you can find at the Microsoft Download Center.
Dynamics AX has a data caching framework on the client that can help you greatly reduce the number of times the client goes to the server. In previous releases of Dynamics AX, this cache operated only on primary keys. In Dynamics AX 2009, this cache has been moved and now operates across all the unique keys in a table. Therefore, if a piece of code is accessing data from the client, the code should use a unique key if possible. Also, you need to ensure that all keys that are unique are marked as such in the Application Object Tree (AOT). You can use the Best Practices tool to ensure that all your tables have a primary key.
Properly setting the CacheLookup property is a prerequisite for using the cache on the client. Table 12-1 shows the values that CacheLookup can have.
Table 12-1. Table Cache Definitions
Cache Setting | Description |
|---|---|
Found | If a table is accessed by a primary key or a unique index, the value is cached for the duration of the session or until the record is updated. If another AOS updates this record, all AOSs will flush their cache. This cache setting is appropriate for master data. |
NotInTTS | Same as Found except every time a transaction is started, the cache is flushed and the query goes to the database. This cache setting is appropriate for transactional tables. |
FoundAndEmpty | Same as Found except if the query fails to find a record, the absence of the record is stored. This cache setting is appropriate for region-specific master data or master data that isn’t always present. |
EntireTable | The entire table is cached in memory on the AOS, and the client treats this cache as "Found." This cache setting is appropriate for tables with a known number of limited records, such as parameter tables. |
None | No caching occurs. This setting is appropriate in only a few cases, such as when optimistic concurrency control has to be disabled. |
When caching is set, the client stores up to 100 records per table, and the AOS stores up to 2000 records per table.
Index caching works only if the where clause has column names that are unique. In other words, caching won’t work if a join is present, if the query is a cross-company query, or if any range operations are in the query. Therefore, if you’re checking whether a query record that has a particular primary key and some other attribute exists, search the database only by primary key. For an example of this, refer to xDataArea.isVirtualCompany.
Notice that this code queries the database by ID and then the primary key, and then it checks the virtual company in memory. This operates at around the same speed but allows the query to hit the cache and the result of the query to be cached on both the client and server tiers.
EntireTable caches store the entire contents of a table on the server, but the cache is treated as a "Found" cache on the client. For tables that have only one row per company, such as parameter tables, you should add a key column that always has a known value, such as 0. This allows the client to use the cache when accessing these tables. An example of the use of a key column in the base application (i.e., Dynamics AX 2009 without any customizations) is CustParameters table.
When you’re writing code, you should be aware of what tier the code is going to run on and what tier the objects you’re accessing are on. Objects that have their RunOn property set to Server/Client/Called From are always instantiated on the server. Objects that are marked to RunOn Client are always instantiated on the client, and Called From is instantiated wherever the class is created. One caveat: if you mark classes to RunOn either the client or the server, you can’t serialize them to another tier via pack and unpack. If you attempt to serialize a server class to the client, all you get is a new object on the server with the same values. Static methods run on whatever tier they are specified to run on via the Client, Server, or Client Server keyword in the declaration.
Temp tables can be a common source of both client callbacks and calls to the server. Unlike regular table buffers, temp tables reside on the tier on which the first record was inserted. For example, if a temp table is declared on the server, the first record is inserted on the client, and the rest of the records are inserted on the server, all access to that table from the server happens on the client. It’s best to populate a temp table on the server because the data you need is probably coming from the database; still, you must be careful when your intent is to iterate over the data to populate a form. The easiest way to achieve this efficiently is to populate the temp table on the server, serialize the entire table down to a container, and then read all the records from the container back into a temp table on the client.
Client callbacks occur when the client places a call to a server-bound method, and then the server places a call to a client-bound method. These calls can happen for two reasons. First, they occur when the client doesn’t send enough information to the server during its call, or sends the server a client object that encapsulates the information. Second, client callbacks occur when the server is either updating or accessing a form.
To remove the first kind of call, ensure that you send all the information the server needs in a serializable format, such as a packed container, record buffers, or value types (e.g., int, str, real, boolean). When the server accesses these types, it doesn’t need to go back to the client, as it does if you use an object type.
To remove the form’s logic, just send any necessary information about the form into the method, and manipulate the form only when the call returns instead of directly from inside the server. One of the best ways to defer operations on the client is with pack and unpack. By utilizing pack and unpack, you can serialize a class down to a container and then deserialize it on the other side.
To ensure the minimum number of round-trips between the client and the server, chunk them into one, static server method and pass in all the state needed to perform the operation.
One static server method you can use is NumberSeq::getNextNumForRefParmId. This method call is a static server call that contains the following line of code.
Had this code run on the client, it would have caused four remote procedure call (RPC) round-trips (one for newGetNum, one for numRefParmId, one for num, and one to clean up the NumberSeq object that was created). By using a static server method, you can complete this operation in one RPC round-trip.
Another common example of chunking occurs when the client is doing Transaction Tracking System (TTS) operations. Frequently, a developer writes code similar to the following.
You can save two round-trips if you chunk this code into one static server call. All TTS operations are initiated only on the server. To take advantage of this fact, do not invoke the ttsbegin and ttscommit call from the client to start the database transaction when the ttslevel is 0.
In the preceding section, we focused on limiting traffic between the client and server tiers. When a Dynamics AX application is executed, however, these tiers are just two of the three tiers involved. The third tier is the database tier. You need to optimize the exchange of packages between the server tier and the database tier, just as you do between the client and server tiers. In this section, we explain how you can optimize the transactional part of the execution of application logic. The Dynamics AX application runtime helps you minimize calls made from the server tier to the database tier by supporting set-based operators and data caching. However, you should also do your part by reducing the amount of data you send from the database tier to the server tier. The less data you send, the faster that data is fetched from the database. Fewer packages are sent back as well. These reductions result in less memory consumed. All these efforts promote faster execution of application logic, which results in smaller transaction scope, less locking and blocking, and improved concurrency and throughput.
As mentioned in Chapter 14, in the section "Database-Triggering Methods," the X++ language contains specific operators and classes to enable set-based manipulation in the database. The set-based constructs have an advantage over record-set constructs—they make fewer round-trips to the database. The following X++ code example, which shows the selection of several custTable records, each updated with a new value in the creditMax field, illustrates that a round-trip is required for the execution of the select statement and for each execution of update.
In a scenario in which 100 custTable records qualify for the update because the custGroup field equals 20, the number of round-trips would be 1 select + 100 updates = 101 round-trips.
The number of round-trips for the select statement might be slightly higher, depending on the number of custTable records that can be retrieved simultaneously from the database and sent to the AOS.
Theoretically, you could rewrite the preceding scenario to result in only one round-trip to the database by changing the X++ code as indicated in the following example. The example shows how to use the update_recordset operator, resulting in a single SQL UPDATE statement being parsed to the database.
For several reasons, however, using a custTable record buffer doesn’t result in only one round-trip. We explain why in the following subsections on the set-based constructs supported by the Dynamics AX application runtime. In these sections, we also describe features available that allow you to modify the preceding scenario to ensure a single round-trip to the database, even when you’re using a custTable record buffer.
Important
None of the following set-based operations improves performance when used on temporary tables. The Dynamics AX application runtime always downgrades set-based operations on temporary tables to record-based operations. This downgrading happens regardless of how the table became a temporary table (whether specified in metadata in the table’s properties, disabled because of the configuration of the Dynamics AX application, or explicitly stated in the X++ code using the table). Also, the downgrade by the application runtime always invokes the doInsert, doUpdate, and doDelete methods on the record buffer, so no application logic in the overridden methods is executed.
The insert_recordset operator enables the insertion of multiple records into a table in one round-trip to the database. The following X++ code illustrates the use of insert_recordset as the code copies sizes from one item to another item. The item to which the sizes are copied is selected from inventTable.
The round-trip to the database involves the execution of three statements in the database:
The select part of the insert_recordset statement is executed where the selected rows are inserted into a temporarily created new table in the database. The syntax of the select statement when executed in Microsoft SQL Server is similar to SELECT <field list> INTO <temporary table> FROM <source tables> WHERE <predicates>.
The records from the temporary table are inserted directly into the target table using syntax such as INSERT INTO <target table> (<field list>) SELECT <field list> FROM <temporary table>.
The temporary table is dropped with the execution of DROP TABLE <temporary table>.
This approach has a tremendous performance advantage over inserting the records one by one, as shown in the following X++ code, which addresses the same scenario as the preceding X++ code.
If 10 sizes were copied, this scenario would result in 1 round-trip caused by the select statement and an additional 10 round-trips caused by the inserts, totaling 11 round-trips.
The insert_recordset operation could be downgraded, however, from a set-based operation to a record-based operation. The operation is downgraded if any of the following conditions is true:
The table is entire-table cached.
The insert method or the aosValidateInsert method is overridden on the target table.
Alerts have been set to be triggered by inserts into the target table.
The database log has been configured to log inserts into the target table.
Record level security (RLS) is enabled on the target table. If RLS is enabled only on the source table or tables, insert_recordset isn’t downgraded to row-by-row operation.
The Dynamics AX application runtime automatically handles the downgrade and internally executes a scenario similar to the while select scenario shown in the preceding example.
Important
When the Dynamics AX application runtime checks for overridden methods, it determines only whether the methods are implemented. It doesn’t determine whether the overridden methods contain only the default X++ code. A method is therefore considered to be overridden by the application runtime even though it contains the following X++ code.
Any set-based insert is then downgraded. You need to remember to delete such a method to avoid the downgrade, with its performance ramifications.
If a table is not entire-table cached, however, you can avoid any downgrade caused by the previously mentioned functionality. The record buffer contains methods that turn off the checks that the application runtime performs when determining whether to downgrade the insert_recordset operation.
Calling skipDataMethods(true) prevents the check that determines whether the insert method is overridden.
Calling skipAosValidation(true) prevents the check on the aosValidateInsert method.
Calling skipDatabaseLog(true) prevents the check that determines whether the database log is configured to log inserts into the table.
Calling skipEvents(true) prevents the check that determines whether any alerts have been set to be triggered by the insert event on the table.
The following X++ code, which includes the call to skipDataMethods(true), ensures that the insert_recordset operation is not downgraded because the insert method is overridden on the InventSize table.
You must use skip methods with extreme caution because they can lead to the logic in the insert method not being executed, events not being raised, and potentially, the database log not being written to. If you override the insert method, you should use the cross-reference system to determine whether any X++ code calls skipDataMethods(true). If you don’t, the X++ code could fail to execute the insert method. Moreover, when you implement calls to skipDataMethods(true), make sure that not executing the X++ code in the overridden insert method won’t lead to data inconsistency.
Skip methods can be used only to influence whether the insert_recordset operation is downgraded. If a call to skipDataMethods(true) is implemented to prevent downgrading because the insert method is overridden, the overridden version of the insert method will eventually be executed if the operation is still downgraded. The operation would be downgraded, if, for example, the database log had been configured to log inserts into the table. In the previous example, the overridden insert method on the InventSize table would be executed if the database log were configured to log inserts into the InventSize table because the insert_recordset operation would then revert to a while select scenario in which the overridden insert method would get called.
Dynamics AX 2009 introduces support for literals in insert_recordset. The literal support for insert_recordset was introduced primarily to support upgrade scenarios in which the target table is populated with records from one or more source tables (using joins) and one or more columns in the target table need to be populated with a literal value that doesn’t exist in the source. The following code example illustrates the usage of literals in insert_recordset.
The behavior of the update_recordset operator is very similar to that of the insert_recordset operator. This similarity is illustrated by the following piece of X++ code, in which all sizes for an item are updated with a new description.
static void UpdateSizes(Args _args)
{
InventSize inventSize;
;
ttsbegin;
update_recordset inventSize
setting Description = 'This size is for item 1000'
where inventSize.itemId == '1000';
ttscommit;
} |
The execution of update_recordset results in one statement being parsed to the database, which in SQL Server uses a syntax similar to UPDATE <table> <SET> <field and expression list> WHERE <predicates>. As with insert_recordset, update_recordset provides a tremendous improvement in performance over the record-based version, in which each record is updated individually. This improvement is shown in the following X++ code, which serves the same purpose as the preceding example. The code selects all the records qualified for update, sets the new description value, and updates the record.
If 10 records qualified, 1 select statement and 10 update statements would be parsed to the database rather than the single update statement that would be parsed if you used update_recordset.
The update_recordset operation can be downgraded if specific methods have been overridden or the the Dynamics AX application is configured. The update_recordset operation is downgraded if any of the following conditions is true:
The table is entire-table cached.
The update method, the aosValidateUpdate method, or the aosValidateRead method is overridden on the target table.
Alerts have been set up to be triggered by update queries into the target table.
The database log has been configured to log update queries into the target table.
RLS is enabled on the target table.
The Dynamics AX application runtime automatically handles the downgrade and internally executes a scenario similar to the while select scenario shown in the preceding example.
You can avoid any downgrade caused by the previously mentioned functionality unless the table is entire-table cached. The record buffer contains methods that turn off the checks that the application runtime performs when determining whether to downgrade the update_recordset operation.
Calling skipDataMethods(true) prevents the check that determines whether the update method is overridden.
Calling skipAosValidation(true) prevents the checks on the aosValidateUpdate and aosValidateRead methods.
Calling skipDatabaseLog(true) prevents the check that determines whether the database log is configured to log updates to records in the table.
Calling skipEvents(true) prevents the check to determine whether any alerts have been set to be triggered by the update event on the table.
As we explained earlier, you should use the skip methods with great caution, and you should take the same precautions before using the skip methods in combination with the update_recordset operation. Again, using the skip methods only influences whether the update_recordset operation is downgraded to a while select scenario. If the operation is downgraded, database logging, alerting, and execution of overridden methods occurs even though the respective skip methods have been called.
Tip
If an update_recordset operation is downgraded to a while select scenario, the select statement uses the concurrency model specified at the table level. You can apply the optimisticlock and pessimisticlock keywords to the update_recordset statements and enforce a specific concurrency model to be used in case of downgrade.
Dynamics AX 2009 supports inner and outer joins in update_recordset. Previous versions of Dynamics AX supported only exists and not exists joins. The support for joins in update_recordset enables an application to perform set-based operations when the source data is fetched from more than one related Data Source.
The following example illustrates the usage of joins with update_recordset.
The delete_from operator is similar to the insert_recordset and update_recordset operators in that it parses a single statement to the database to delete multiple rows. The following X++ code shows the deletion of all sizes for an item.
static void DeleteSizes(Args _args)
{
InventSize inventSize;
;
ttsbegin;
delete_from inventSize
where inventSize.itemId == '1000';
ttscommit;
} |
This code parses a statement to SQL Server in a similar syntax to DELETE <table> WHERE <predicates> and executes the same scenario as the following X++ code, which uses record-by-record deletes.
static void DeleteSizes(Args _args)
{
InventSize inventSize;
;
ttsbegin;
while select forupdate inventSize
where inventSize.itemId == '1000'
{
inventSize.delete();
}
ttscommit;
} |
Again, the use of delete_from is preferred with respect to performance because a single statement is parsed to the database, rather than the multiple statements that the record-by-record version parses.
Like the downgrading insert_recordset and update_recordset operations, the delete_from operation could also be downgraded, and for similar reasons. Downgrade occurs if any of the following is true:
The table is entire-table cached.
The delete method, the aosValidateDelete method, or the aosValidateRead method is overridden on the target table.
Alerts have been set up to be triggered by deletes into the target table.
The database log has been configured to log deletes into the target table.
Downgrade also occurs if delete actions are defined on the table. The Dynamics AX application runtime automatically handles the downgrade and internally executes a scenario similar to the while select scenario shown in the preceding example.
You can avoid downgrades caused by the previously mentioned functionality, unless the table is entire-table cached. The record buffer contains methods that turn off the checks that the application runtime performs when determining whether to downgrade the delete_from operation. Here are the skip descriptions:
Calling skipDataMethods(true) prevents the check that determines whether the delete method is overridden.
Calling skipAosValidation(true) prevents the checks on the aosValidateDelete and aosValidateRead methods.
Calling skipDatabaseLog(true) prevents the check that determines whether the database log is configured to log deletion of records in the table.
Calling skipEvents(true) prevents the check that determines whether any alerts have been set to be triggered by the delete event on the table.
The preceding descriptions about the use of the skip methods, the no-skipping behavior in the event of downgrade, and the concurrency model for the update_recordset operator are equally valid for the use of the delete_from operator.
Note
The record buffer also contains a skipDeleteMethod method. Calling the methods as skipDeleteMethod(true) has the same effect as calling skipDataMethods(true). It invokes the same Dynamics AX application runtime logic, so you can use skipDeleteMethod in combination with insert_recordset and update_recordset, although it might not improve the readability of the X++ code.
In addition to the set-based operators, Dynamics AX also allows you to use the RecordInsertList and RecordSortedList classes when inserting multiple records into a table. When the records are ready to be inserted, the Dynamics AX application runtime packs multiple records into a single package and sends it to the database. The database executes individual inserts for each record in the package. This process is illustrated in the following example, in which a RecordInsertList object is instantiated, and each record to be inserted into the database is added to the RecordInsertList object. When all records are inserted into the object, the insertDatabase method is called to ensure that all records are inserted into the database.
Based on the Server Configuration buffer size, the Dynamics AX application runtime determines the number of records in a buffer as a function of the size of the records and buffer size. If the buffer is filled up, the records in the RecordInsertList object are packed, parsed to the database, and inserted individually on the database tier. This check is made when the add method is called. When the insertDatabase method is called from the application logic, the remaining records are inserted with the same mechanism.
Using these classes has an advantage over using while select: fewer round-trips are made from the AOS to the database because multiple records are sent simultaneously. However, the number of INSERT statements in the database remains the same.
Note
Because the timing of insertion into the database depends on the size of the record buffer and the package, you shouldn’t expect a record to be selectable from the database until the insertDatabase method has been called.
You can rewrite the preceding example using the RecordSortedList class instead of RecordInsertList, as shown in the following X++ code.
When the application logic uses a RecordSortedList object, the records aren’t parsed and inserted in the database until the insertDatabase method is called. The number of round-trips and INSERT statements executed is the same as for the RecordInsertList object.
Both RecordInsertList objects and RecordSortedList objects can be downgraded in application logic to record-by-record inserts, in which each record is sent in a separate round-trip to the database and the INSERT statement is subsequently executed. Downgrading occurs if the insert method or the aosValidateInsert method is overridden, or if the table contains fields of type container or memo. Downgrading doesn’t occur if the database log is configured to log inserts or alerts that have been set to be triggered by the insert event on the table. One exception is if logging or alerts have been configured and the table contains CreatedDateTime or ModifiedDateTime columns—in this case, record-by-record inserts are performed. The database logging and eventing occurs on a record-by-record basis after the records have been sent and inserted into the database.
When instantiating the RecordInsertList object, you can specify that the insert and aosValidateInsert methods be skipped. You can also specify that the database logging and eventing be skipped if the operation isn’t downgraded.
In multiple scenarios in the Dynamics AX application, the execution of some application logic involves manipulating multiple rows from the same table. Some scenarios require that all rows be manipulated within a single transaction scope; if something fails and the transaction is aborted, all modifications are rolled back, and the job can be restarted manually or automatically. Other scenarios commit the changes on a record-by-record basis; in case of failure, only the changes to the current record are rolled back, and all previously manipulated records are already committed. When a job is restarted in this scenario, it starts where it left off by skipping all the records already changed.
An example of the first scenario is shown in the following code, in which all update queries to the custTable records are wrapped into a single transaction scope.
An example of the second scenario, executing the same logic, is shown in the following code, in which the transaction scope is handled record by record. You must reselect each individual custTable record inside the transaction for the Dynamics AX application runtime to allow the update of the record.
In a scenario in which 100 custTable records qualify for the update, the first example would involve 1 select and 100 update statements being parsed to the database, and the second example would involve 1 large select query and 100 single ones, plus the 100 update statements. So the first scenario would execute faster than the second, but the first scenario would also hold the locks on the updated custTable records longer because it wouldn’t commit for each record. The second example demonstrates superior concurrency over the first example because locks are held for less time.
The optimistic concurrency model in Dynamics AX lets you take advantage of the benefits offered by both of the preceding examples. You can select records outside a transaction scope and update records inside a transaction scope—but only if the records are selected optimistically. In the following example, the optimisticlock keyword is applied to the select statement while maintaining a per-record transaction scope. Because the records are selected with the optimisticlock keyword, it isn’t necessary to reselect each record individually within the transaction scope. (For a detailed description of the optimistic concurrency model, see Chapter 14.)
This approach provides the same number of statements parsed to the database as in the first example, with the improved concurrency from the second example because commits execute record by record. The code in this example still doesn’t perform as fast as the code in first example because it has the extra burden of the per-record transaction management. You could optimize the example even further by committing on a scale somewhere between all records and the single record, without decreasing the concurrency considerably. However, the appropriate choice of commit frequency always depends on the circumstances of the job.
Best Practices
You can use the forupdate keyword when selecting records outside the transaction if the table has been enabled for optimistic concurrency at the table level. The best practice, however, is to explicitly use the optimisticlock keyword because the scenario won’t fail if the table-level setting is changed. Using the optimisticlock keyword also improves the readability of the X++ code because the explicit intention of the developer is stated in the code.
The Dynamics AX application runtime supports the enabling of single-record and set-based record caching. You can enable set-based caching in metadata by switching a property on a table definition or writing explicit X++ code, which instantiates a cache. Regardless of how you set up caching, you don’t need to know which caching method is used because the application runtime handles the cache transparently. To optimize the use of the cache, however, you must understand how each caching mechanism works.
The Microsoft Dynamics AX 2009 software development kit (SDK) contains a good description of the individual caching options and how they are set up (http://msdn.microsoft.com/en-us/library/bb278240.aspx). In this section, we focus on how the caches are implemented in the Dynamics AX application runtime and what you should expect when using the individual caching mechanisms.
You can set up three types of record caching on a table by setting the CacheLookup property on the table definition:
Found
FoundAndEmpty
NotInTTS
One additional value (besides None) is EntireTable, which is a set-based caching option we describe later in this section.
The three record-caching possibilities are fundamentally the same. The differences lie in what is cached and when cached values are flushed. For example, the Found and FoundAndEmpty caches are preserved across transaction boundaries, but a table that uses the NotInTTS cache doesn’t use the cache when first accessed inside a transaction scope—it uses it in consecutive select statements, unless a forupdate keyword is applied to the select statement. The following X++ code example describes when the cache is used inside and outside a transaction scope, when a table uses the NotInTTS caching mechanism, and when the AccountNum field is the primary key. The code comments indicate when the cache is or isn’t used. In the example, it appears that the first two select statements after the ttsbegin command don’t use the cache. The first doesn’t use the cache because it’s the first statement inside the transaction scope; the second doesn’t use the cache because the forupdate keyword is applied to the statement. The use of the forupdate keyword forces the application runtime to look up the record in the database because the previously cached record wasn’t selected with the forupdate keyword applied.
If the table had been set up with Found or FoundAndEmpty caching in the preceding example, the cache would have been used when executing the first select statement inside the transaction, but not when the first select forupdate statement was executed.
Note
By default, all Dynamics AX system tables are set up using a Found cache. This cannot be changed.
For all three caching mechanisms, the cache is used only if the select statement contains equal-to (==) predicates in the where clause that exactly match all the fields in the primary index of the table or any one of the unique indexes defined for the table. The PrimaryIndex property on the table must therefore be set correctly on one of the unique indexes used when accessing the cache from application logic. For all other unique indexes, without any additional settings in metadata, the kernel automatically uses the cache, if it is already present. Support for unique-index-based caching is a new feature in Dynamics AX 2009.
The following X++ code examples show when the Dynamics AX application runtime will try to use the cache and when it won’t. The cache is used only in the first select statement; the remaining three statements don’t match the fields in the primary index, so they will all perform lookups in the database.
Note
The RecId index, which is always unique on a table, can be set as the PrimaryIndex in the table’s properties. You can therefore set up caching using the RecId field.
The following X++ code examples show how unique-index caching works in the Dynamics AX application runtime. InventDim in the base application has InventDimId as the primary key and a combination of keys (inventBatchId, wmsLocationId, wmsPalletId, inventSerialId, inventLocationId, configId, inventSizeId, inventColorId, and inventSiteId) as the unique index on the table.
The Dynamics AX application runtime ensures that all fields on a record are selected before they are cached. The application runtime therefore always changes a field list to include all fields on the table before submitting the SELECT statement to the database when it can’t find the record in the cache. The following X++ code illustrates this behavior.
static void expandingFieldList(Args _args)
{
CustTable custTable;
;
select creditRating // The field list will be expanded to all fields.
from custTable
where custTable.AccountNum == '1101';
} |
If the preceding select statement doesn’t find a record in the cache, it expands the field to contain all fields, not just the creditRating field. This ensures that the fetched record from the database contains values for all fields before it is inserted into the cache. Even though performance when fetching all fields is inferior compared to performance when fetching a few fields, this approach is acceptable because in subsequent use of the cache, the performance gain outweighs the performance loss from populating it.
Tip
You can disregard the use of the cache by calling the disableCache method on the record buffer with a Boolean true parameter. This method forces the application runtime to look up the record in the database, and it also prevents the application runtime from expanding the field list.
The Dynamics AX application runtime creates and uses caches on both the client tier and the server tier. The client-side cache is local to the rich client, and the server-side cache is shared among all connections to the server, including connections coming from rich clients, Web clients, .NET Business Connector, and any another connection.
The cache used depends on which tier the lookup is made from. If the lookup is made on the server tier, the server-side cache is used. If the lookup is executed from the client tier, the client first looks in the client-side cache; if it doesn’t find anything, it makes a lookup in the server-side cache. If there is still no record, a lookup is made in the database. When the database returns the record to the server and on to the client, the record is inserted into both the server-side cache and the client-side cache.
The caches are implemented using AVL trees (which are balanced binary trees), but the trees aren’t allowed to grow indefinitely. The client-side cache can contain a maximum of 100 records for a given table in a given company, and the shared server-side cache can contain a maximum of 2000 records. When a new record is inserted into the cache and the maximum is reached, the application runtime removes approximately 5 to 7 percent of the oldest records by scanning the entire tree.
Scenarios that repeat lookups on the same records and expect to find the records in the cache can suffer performance degradation if the cache is continuously full—not only because records won’t be found in the cache because they were removed based on the aging scheme, forcing a lookup in the database, but also because of the constant scanning of the tree to remove the oldest records. The following X++ code shows an example in which all SalesTable records are looped twice, and each loop looks up the associated CustTable record. If this X++ code were executed on the server and the number of CustTable record lookups was more than 2000, the oldest records would be removed from the cache, and the cache wouldn’t contain all CustTable records when the first loop ended. When the code loops through the SalesTable records again, the records might not be in the cache, and the selection of the CustTable record would continue to go to the database to look up the record. The scenario would therefore perform much better with fewer than 2000 records in the database.
Important
If you test code on small databases, you can’t track repeat lookups only by tracing the number of statements parsed to the database. When you execute such code in a production environment, you can encounter severe performance issues because this scenario doesn’t scale very well.
Before the Dynamics AX application runtime searches for, inserts, updates, or deletes records in the cache, it places a mutually exclusive lock that isn’t released until the operation is complete. This lock means that two processes running on the same server can’t perform insert, update, or delete operations in the cache at the same time; only one process can hold the lock at any given time, and the remaining processes are blocked. Blocking occurs only when the application runtime accesses the server-side cache. So although the caching possibilities the application runtime supports are useful features, you shouldn’t abuse them. If you can reuse a record buffer that is already fetched, you should do so. The following X++ code shows the same record fetched twice. The second fetch uses the cache even though it could have used the first fetched record buffer. When you execute the following X++ code on the server tier, the process might get blocked when the application runtime searches the cache.
In addition to using the three caching methods described so far—Found, FoundAndEmpty, and NotInTTS—you can set a fourth caching option, EntireTable, on a table. EntireTable enables a set-based cache. It causes the AOS to mirror the table in the database by selecting all records in the table and inserting them into a temporary table when any record from the table is selected for the first time. The first process to read from the table could therefore experience a longer response time because the application runtime reads all records from the database. Subsequent select queries then read from the entire-table cache instead of from the database.
A temporary table is usually local to the process that uses it, but the entire-table cache is shared among all processes that access the same AOS. Each company (as defined by the DataAreaId field) has an entire-table cache, so two processes requesting records from the same table but from different companies use different caches, and both could experience a longer response time to instantiate the entire-table cache.
The entire-table cache is a server-side cache only. When requesting records from the client tier on a table that is entire-table cached, the table behaves as a Found cached table. If a request for a record is made on the client tier that qualifies for searching the record cache, the client first searches the local Found cache. If the record isn’t found, the client calls the AOS to search the entire-table cache. When the application runtime returns the record to the client tier, it inserts the record into the client-side Found cache.
The entire-table cache isn’t used when executing a select statement by which an entire-table-cached table is joined to a table that isn’t entire-table cached. In this situation, the entire select statement is parsed to the database. However, when select statements are made that access only the single entire-table cached table, or when joining other entire-table cached tables, the entire-table cache is used.
The Dynamics AX application runtime flushes the entire-table cache when records are inserted, updated, or deleted in the table. The next process, which selects records from the table, suffers a degradation in performance because it must reread the entire table into the cache. In addition to flushing its own cache, the AOS that executes the insert, update, or delete also informs other AOSs in the same installation that they must flush their caches on the same table. This prevents old and invalid data from being cached for too long in the entire Dynamics AX application environment. In addition to this flushing mechanism, the AOS flushes all the entire-table caches every 24 hours.
Because of the flushing that results when modifying records in a table that has been entire-table cached, you should avoid setting up entire-table caches on frequently updated tables. Rereading all records into the cache results in a performance loss, which could outweigh the performance gain achieved by caching records on the server tier and avoiding round-trips to the database tier. You can overwrite the entire-table cache setting on a specific table at run time when you configure the Dynamics AX application.
Even if the records in a table are fairly static, you might achieve better performance by not using the entire-table cache if the table has a large number of records. Because the entire-table cache uses temporary tables, it changes from an in-memory structure to a file-based structure when the table uses more than 128 kilobytes (KB) of memory. This results in performance degradation during record searches. The database search engines have also evolved over time and are faster than the ones implemented in the Dynamics AX application runtime. It might be faster to let the database search for the records than to set up and use an entire-table cache, even though a database search involves round-trips to the database tier.
The RecordViewCache class allows you to establish a set-based cache from the X++ code. You initiate the cache by writing the following X++ code.
select nofetch custTrans where custTrans.accountNum == '1101'; recordViewCache = new RecordViewCache(custTrans); |
The records to cache are described in the select statement, which must include the nofetch keyword to prevent the selection of the records from the database. The records are selected when the RecordViewCache object is instantiated with the record buffer parsed as a parameter. Until the RecordViewCache object is destroyed, select statements will execute on the cache if they match the where clause defined when it was instantiated. The following X++ code shows how the cache is instantiated and used.
The cache can be instantiated only on the server tier. The defined select statement can contain only equal-to (==) predicates in the where clause and is accessible only by the process instantiating the cache object. If the table buffer used for instantiating the cache object is a temporary table or it uses EntireTable caching, the RecordViewCache object isn’t instantiated.
The records are stored in the cache as a linked list of records. Searching therefore involves a sequential search of the cache for the records that match the search criteria. When defining select statements to use the cache, you can specify a sort order. When a sort order is specified, the Dynamics AX application runtime creates a temporary index on the cache, which contains the requested records sorted as specified in the select statement. The application runtime iterates the temporary index when it returns the individual rows. If no sorting is specified, the application runtime merely iterates the linked list.
If the table cached in the RecordViewCache is also record-cached, the application runtime can use both caches. If a select statement is executed on a Found cached table and the select statement qualifies for lookup in the Found cache, the application runtime performs a lookup in this cache first. If nothing is found and the select statement also qualifies for lookup in the RecordViewCache, the runtime uses the RecordViewCache and updates the Found cache after retrieving the record.
Inserts, updates, and deletes of records that meet the cache criteria are reflected in the cache at the same time that the data manipulation language (DML) statements are sent to the database. Records in the cache are always inserted at the end of the linked list. A hazard associated with this behavior is that an infinite loop can occur when application logic is iterating the records in the cache and at the same time inserting new records that meet the cache criteria. An infinite loop is shown in the following X++ code example, in which a RecordViewCache object is created containing all custTable records associated with CustGroup ‘20’. The code iterates each record in the cache when executing the select statement, but because each cached record is duplicated and still inserted with CustGroup ‘20’, the records are inserted at the end of the cache. Eventually, the loop fetches these newly inserted records as well.
To avoid the infinite loop, simply sort the records when selecting them from the cache, which creates a temporary index that contains only the records in the cache from where the records were first retrieved. Any inserted records are therefore not retrieved. This is shown in the following example, in which the order by operator is applied to the select statement.
Changes made to records in a RecordViewCache object can’t be rolled back. If one or more RecordViewCache objects exist, if the ttsabort operation executes, or if an error is thrown that results in a rollback of the database, the RecordViewCache objects still contain the same information. Any instantiated RecordViewCache object that is subject to modification by the application logic should therefore not have a lifetime longer than the transaction scope in which it is modified. The RecordViewCache object must be declared in a method that isn’t executed until after the transaction has begun. In the event of a rollback, the object and the cache are both destroyed.
As described earlier, the RecordViewCache object is implemented as a linked list that allows only a sequential search for records. When you use the cache to store a large number of records, a performance degradation in search occurs because of this linked-list format. You should weigh the use of the cache against the extra time spent fetching the records from the database where the database uses a more optimal search algorithm. Consider the time hit especially when you search only for a subset of the records; the application runtime must continuously match each record in the cache against the more granular where clause in the select statement because no indexing is available for the records in the cache.
However, for small sets of records, or for situations in which the same records are looped multiple times, RecordViewCache offers a substantial performance advantage compared to fetching the same records multiple times from the database.
Most of the X++ select statements in Dynamics AX retrieve all fields on a record, although the values in only a few of the fields are actually used. The main reason for this coding style is that the Dynamics AX application runtime doesn’t report compile-time or run-time errors if a field on a record buffer is accessed and it hasn’t been retrieved from the database. The following X++ code, which selects only the AccountNum field from the CustTable table but evaluates the value of the CreditRating field and sets the CreditMax field, won’t fail because the application runtime doesn’t detect that the fields haven’t been selected.
This code updates all CustTable records to a CreditMax value of 1000, regardless of the previous value in the database for the CreditRating and CreditMax fields. Adding the CreditRating and CreditMax fields to the field list of the select statement might not solve the problem because the application logic could still update other fields incorrectly because the update method on the table could be evaluating and setting other fields on the same record.
Important
You could, of course, examine the update method for other fields accessed in the method and then select these fields as well, but new problems would soon surface. For example, if you customize the update method to include application logic that uses additional fields, you might not be aware that the X++ code in the preceding example also needs to be customized.
Limiting the field list when selecting records does result in a performance gain, however, because less data is retrieved from the database and sent to the AOS. The gain is even bigger if you can retrieve the fields by using the indexes without lookup of the values on the table. This performance gain can be experienced and the select statements written safely when you use the retrieved data within a controlled scope, such as a single method. The record buffer must be declared locally and not parsed to other methods as a parameter. Any developer customizing the X++ code can easily see that only a few fields are selected and act accordingly.
To truly benefit from a limited field list, you must understand that the Dynamics AX application runtime sometimes automatically adds extra fields to the field list before parsing a statement to the database. We explained one example earlier in this chapter, in the "Caching" section. In this example, the application runtime expands the field list to include all fields if the select statement qualifies for storing the retrieved record in the cache. In an example in Chapter 14, in the "Transaction Semantics" section, you see that the application runtime ensures that the fields contained in the unique index, used by the application runtime to update and delete the record, are always retrieved from the database.
In the following X++ code, you can see how the application runtime adds additional fields and how to optimize some select statements. The code calculates the total balance for all customers in customer group ‘20’ and converts it into the company’s currency unit. The amountCur2MST method converts the value in the currency specified by the currencyCode field to the company’s monetary unit.
When the select statement is parsed to the database, it retrieves all CustTable and CustTrans record fields, even though only the AmountCur and CurrencyCode fields on the CustTrans table are used. The result is the retrieval of more than 100 fields from the database.
You can optimize the field list simply by selecting the AmountCur and CurrencyCode fields from CustTrans and, for example, only the AccountNum field from CustTable, as shown in the following code.
As explained earlier, the application runtime expands the field list from the three fields shown in the preceding X++ code example to five fields because it adds the fields used when updating the records. These fields are added even though neither the forupdate keyword nor any of the specific concurrency model keywords are applied to the statement. The statement parsed to the database starts as shown in the following example, in which the RECID column is added for both tables.
To prevent retrieval of any CustTable fields, you can rewrite the select statement to use the exists join operator, as shown here.
This code retrieves only three fields (AmountCur, CurrencyCode, and RecId) from the CustTrans table and none from the CustTable table.
In some situations, however, it might not be possible to rewrite the statement to use exists join. In such cases, including only TableId as a field in the field list prevents the retrieval of any fields from the table. The original example is modified as follows to include the TableId field.
This code causes the application runtime to parse a select statement to the database with the following field list.
If you rewrite the select statement to use exists join or include only TableId as a field, the select statement sent to the database retrieves just three fields instead of more than 100. As you can see, you can substantially improve your application’s performance just by rewriting queries to retrieve only the necessary fields.
Best Practices
A best practice warning is implemented in Dynamics AX 2009 to analyze X++ code for the use of select statements and recommend whether to implement field lists based on the number of fields accessed in the method. The best practice check is made if (in the Best Practice Parameters dialog box) the AOS Performance Check under General Checks is enabled and the Warning Level is set to Errors And Warnings.
Dynamics AX supports left and right justification of extended data types. With our current releases, nearly all extended data types are left justified to reduce the impact of space consumption because of double and triple byte storage as a result of Unicode enablement. Left justifying also helps performance by increasing the speed of access through indexes.
Where sorting is critical, you can use right justification. This has to be an exception as is clearly evident in our usage within the application layers we ship.
You can further improve transactional performance by giving more thought to the design of your application logic. For example, ensuring that various tables and records are always modified in the same order helps prevent deadlocks and ensuing retries. Spending time preparing the transactions before starting a transaction scope to make it as brief as possible can reduce the locking scope and resulting blocking, and ultimately improve the concurrency of the transactions. Database design factors, such as index design and use, are also important. These topics are beyond the scope of this book.
Without a way to monitor the execution of the implemented application logic, you would implement features almost blindly with regard to performance. Fortunately, the Dynamics AX development environment contains a set of easy-to-use tools to help you monitor client/server calls, database activity, and application logic. These tools provide good feedback on the feature being monitored. The feedback is integrated directly with the development environment, making it possible for you to jump directly to the relevant X++ code.
The Dynamics AX Trace Parser is a user interface and data analyzer added to Dynamics AX 2009 and built on top of SQL Server 2005 and SQL Server 2008 and the Event Tracing for Windows (ETW) framework enabled in the core Dynamics AX kernel. The Event Tracing for Windows framework allows an administrator to conduct tracing with system overhead of approximately 4 percent. This low overhead allows administrators to diagnose performance problems in live environments as opposed to just development environments.
The Trace Parser enables rapid analysis of traces to find the longest-running code, longest-running SQL query, highest call count, and other metrics useful in debugging a performance problem. In addition, it provides a call tree of the code that was executed, allowing you to quickly gain insight into unfamiliar code. It also provides the ability to jump from the search feature to the call tree so that the person analyzing the trace can determine how the problematic code was called.
The Dynamics AX Trace Parser is available as a free download from Partner Source and Customer Source.
Dynamics AX Tracing provides multiple locations where you can set tracing options for server and client activity:
In the Microsoft Dynamics AX Server Configuration Utility, on the computer running the AOS instance.
In the Microsoft Dynamics AX Configuration Utility, on a client.
Within Dynamics AX, in the ToolsOptions dialog box, on the Development and SQL tabs.
The following procedures describe how to set tracing options in the AOS and the Dynamics AX client.
Note
SQL Trace isn’t available unless you also select Allow Client Tracing On Application Object Server Instance using the following instructions:
Open the Microsoft Dynamics AX Server Configuration Utility (StartAdministrative ToolsMicrosoft Dynamics AX 2009 Server Configuration Utility).
Verify that the currently selected AOS instance and configuration are the ones you want to modify.
On the Tracing tab, choose Options, and click Start Trace. If the AOS service is running, the trace starts within 15 seconds. If the service is stopped, the trace starts the next time the service is started.
Open the Microsoft Dynamics AX Server Configuration Utility (StartControl PanelAdministrative ToolsMicrosoft Dynamics AX Configuration Utility).
Verify that the currently selected configuration is the one you want to modify.
On the Tracing tab, evaluate the type of tracing you need to do, and choose Settings.
To start tracing once you’ve set the options you want, close the utility and restart your Dynamics AX client.
The tracing options in the configuration utilities are described in Table 12-2. Later in this section, we cover additional tracing information you need to know, such as troubleshooting common tracing problems and importing and analyzing traces.
Table 12-2. Tracing Options in the Configuration Utilities
Tracing Option | Description |
|---|---|
RPC round-trips to server | Traces all RPC round-trips from any client to the server |
X++ method calls | Traces all X++ methods that are invoked on the server |
Number of nested calls | Limits tracing to the specified number of nested method calls |
Function calls | Traces all function calls that are invoked on the server |
SQL statements | Traces all SQL Server statements that are invoked on the server |
Bind variables | Traces all columns that are used as input bind variables |
Row fetch | Traces all rows that are fetched using SQL Server |
Row fetch summary (count and time) | Counts all rows that are fetched, and records the time spent fetching |
Connect and disconnect | Traces each time the AOS connects and disconnects from the database |
Transactions: ttsBegin, ttsCommit, ttsAbort | Traces all transactions that use the TTSBegin, TTSCommit, and TTSAbort statements |
Files from traces are saved to the locations described in Table 12-3.
Table 12-3. Trace Locations
Type of Trace | Location |
|---|---|
AOS trace files | AOS computer log<servername>_<timestamp>.trc |
AOS settings and SQL Settings triggered from the client (Allow Client Tracing On Application Object Server Instance is selected.) | AOS computer log<username>_<clientIP>_<sessionID>_<server>.trc |
Client method trace triggered from the client (Enable Method Tracing To Client Desktop is selected.) | Client computer log <username>_<clientIP>_<sessionID>_<client>. trc |
A new file is created each time tracing is started or at the start of each new day. If you’re running frequent traces, be sure to remove or archive unneeded trace files often.
The default trace buffer settings in Dynamics AX 2009 are not optimal for collecting traces and can lead to dropped events. Dropping events leaves much of the trace file unusable. We recommend that you set values for the following registry settings for the AOS: (HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesDynamics Server5.0�1 Configurationname):
tracebuffersize = 512
traceminbuffers = 30
tracemaxbuffers = 120
In this section, we provide information on how to troubleshoot the two most common issues you encounter while tracing.
Sometimes a trace that appears to be running in the configuration utility doesn’t look like it’s running in Windows. Here’s why: When a trace file reaches its size limit, Windows stops the trace. The configuration utility interface doesn’t synchronize with Windows until Stop Trace is clicked. Additionally, the Event Tracing for Windows framework drops the trace and the trace events when the disk has insufficient space. So make sure that there is more free space than the value set in tracemaxfilesize in the registry.
If you run more than one client-tracing session simultaneously, don’t be surprised when your system slows down. Tracing is processing intensive and space intensive. We recommend that you don’t turn on tracing for more than one client at a time.
You can import traces collected on either the client or the server by downloading the Dynamics AX Trace Parser. Detailed documentation for importing traces is available with the tool.
Once you load the trace files into the Trace Parser, they are available with ready-made analysis views. Figure 12-2 shows the Open Trace Database view.

When you open a trace from the trace listings view, you see a summary view with many search capabilities and an integrated view of the code as the call tree is analyzed.
Figure 12-3 shows a sample trace summary view.

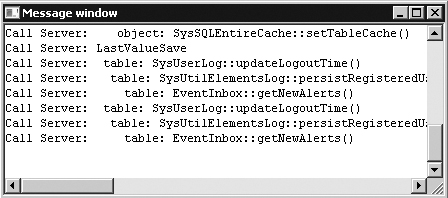
When you develop and test a Dynamics AX application, you can monitor the client and server calls by turning on the Client/Server Trace option, found on the Development tab in the Options dialog box, which can be accessed from the Tools menu. The Development tab shows the calls made that force the application runtime to parse from one tier to the other. Figure 12-4 shows an example of the client/server trace for one of the previous X++ examples.
You can also trace database activity when you’re developing and testing the Dynamics AX application logic. You can enable tracing on the SQL tab in the Options dialog box. You can trace all SQL statements or just the long queries, warnings, and deadlocks. SQL statements can be traced to the Infolog, a message window, a database table, or a file. If statements are traced to the Infolog, you can use the context menu to open the statement in the SQL Trace dialog box, in which you can view the entire statement as well as the path to the method that executed the statement. The SQL Trace dialog box is shown in Figure 12-5.

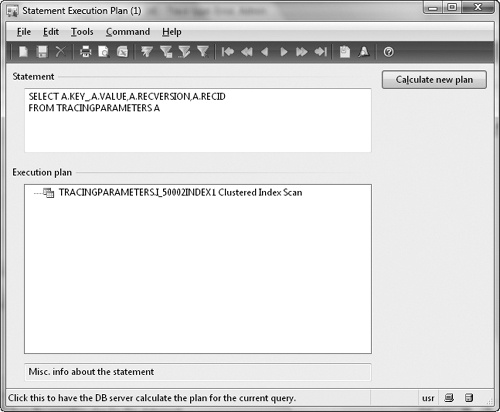
You can open the Statement Execution Plan dialog box from the SQL Trace dialog box, as shown in Figure 12-6. This dialog box shows a simple view of the execution plan to help you understand how the the underlying database will execute the statement.
Important
To trace SQL statements, you must select the Allow Client Tracing On Application Object Server Instance option on the Tracing tab in the Microsoft Dynamics AX Server Configuration Utility.
From either the SQL Trace or the Statement Execution Plan dialog box, you can copy the statement and, if you’re using SQL Server 2005, paste it into SQL Server Query Analyzer to get a more detailed view of the execution plan. In SQL Server 2008, open a new Query window in SQL Server Management Studio and paste in the query. If the Dynamics AX application runtime uses placeholders to execute the statement, the placeholders are shown as question marks in the statement. These must be replaced by variables or constants before they can be executed in the SQL Server Query Analyzer. If the application runtime uses literals, the statement can be pasted directly into the SQL Server Query Analyzer and executed.
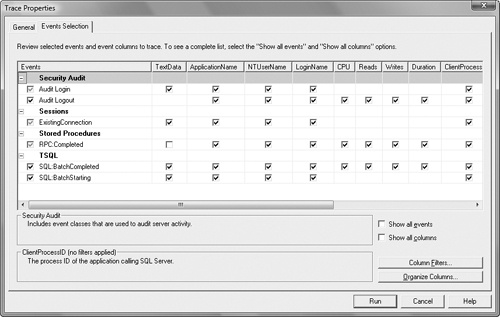
When you trace SQL statements in Dynamics AX, the application runtime displays only the DML statement. It doesn’t display other commands sent to the database, such as transaction commits or isolation level changes. With SQL Server 2008, you can use the SQL Server Profiler to trace these statements using the event classes RPC:Completed and SP: StmtCompleted in the Stored Procedures collection, and the SQL:BatchCompleted event in the TSQL collection, as shown in Figure 12-7.
The Code Profiler tool in Dynamics AX 2009 calculates the profile much faster, and it includes a new view of the code profile, providing a better user experience. Figure 12-8 shows the traverse view, in which each of the called methods in the profiled scenario appears in the top grid. The view also displays a duration count that shows the number of ticks that it took to execute the method and a method count that shows the number of times the methods have been called. The grid for parent calls and children calls shows the methods that called the specific method and the other methods calling the specific method, respectively.
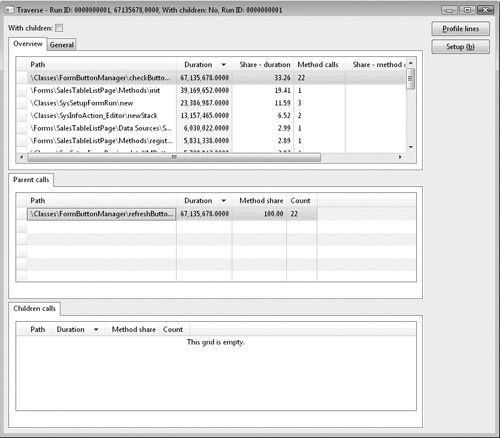
If you use the Code Profiler as a performance optimization tool, you can focus on the methods with the longest duration to optimize the internal structure of the method, or you can focus on the methods called the most and try to limit the number of calls to those methods. You can inspect the internal operation of the methods by clicking the Profile Lines button, which opens the view shown in Figure 12-9. This view shows the duration of every line in the method.

The Code Profiler is a powerful tool for finding issues such as problem areas in the X++ code, code that doesn’t have to be executed in certain scenarios, and code that makes multiple calls to the same methods.