
Appendix 1
Presentation of the Benchmarks used in our Experiments
This appendix describes the benchmarks and the data dependence graphs (DDG) that we used in our experiments. The DDGs have been generated by the st200cc compiler from STmicroelectronics, using the option -03. Superblock formation and loop unrolling are enabled, and instruction selection has been performed for the ST231 VLIW processor.
The ST231 processor used for our experiments executes up to four operations per clock cycle with a maximum of one control operation (goto, jump, call, return), one memory operation (load, store, prefetch) and two multiply operations per clock cycle. All arithmetic instructions operate on integer values with operands belonging either to the general register (GR) file (64 × 32 bit) or to the branch register (BR) file (8 × 1 bit). Floating-point computations are emulated by software. In order to eliminate some conditional branches, the ST200 architecture also provides conditional selection. The processing time of any operation is a single clock cycle, while the latencies between operations range from 0 to 3 clock cycles.
Note that we make our DDG public for helping the research community to share their data and to reproduce our performance numbers.
A1.1. Qualitative benchmarks presentation
We consider a representative set of applications for both high performance and embedded benchmarks. We chose to optimize the set of the following collections of well-known applications programmed in C and C++.
Both FFMPEG and MEDIABENCH collections have been successfully compiled, linked and executed on the embedded ST231 platform. For SPEC2000 and SPEC CPU2006, they have been successfully compiled and statically optimized but not executed because of one of the three following reasons:
Consequently, our experiments report static performance numbers for all benchmark collections. The dynamic performance numbers (executions) are reported only for FFMPEG and MEDIABENCH applications.
The next section provides some useful quantitative metrics to analyze the complexity of our benchmarks.
A1.2. Quantitative benchmarks presentation
In order to gain a precise idea on problem sizes handled by our register optimization methods, we report six metrics using histograms (the x-axis represents the values and the y-axis represents the number of loops of the given values):
Figure A1.1. Histograms on the number of nodes (loop statements): || V ||
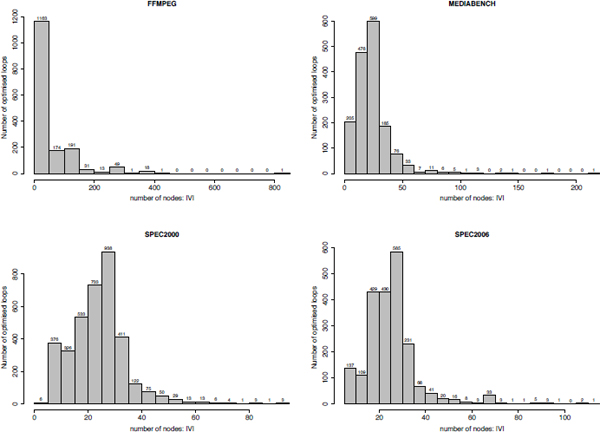
Figure A1.2. Histograms on the number of statements writing inside general registers ||VR, GR||
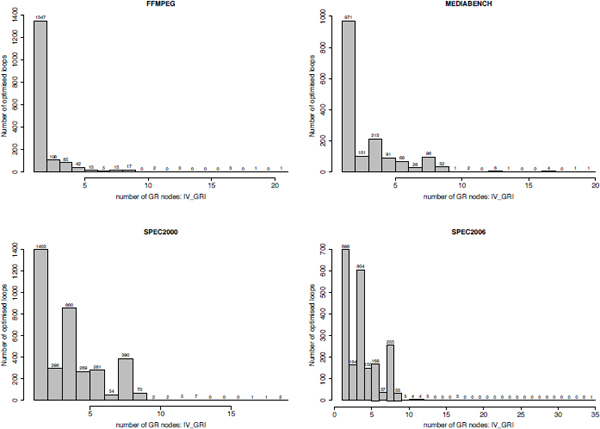
Figure A1.3. Histograms on the number of statements writing inside branch registers ||VR, BR||

These quantitative measures show that the FFMPEG application brings a priori the most difficult and complex DDG instances for code optimization. This analysis is confirmed by our experiments below.
A1.3. Changing the architectural configuration of the processor
The previous section shows a quantitative presentation of our benchmarks when we consider the ST231 VLIW processor with its architectural configuration. In order to emulate more complex architectures, we configured the st200cc compiler to generate DDG for a processor architecture with three register types T = {FP, GR, BR} instead of two. Consequently, the distribution of the number of values per register type becomes the following.2
Figure A1.4. Histograms on the number of data dependences ||E||
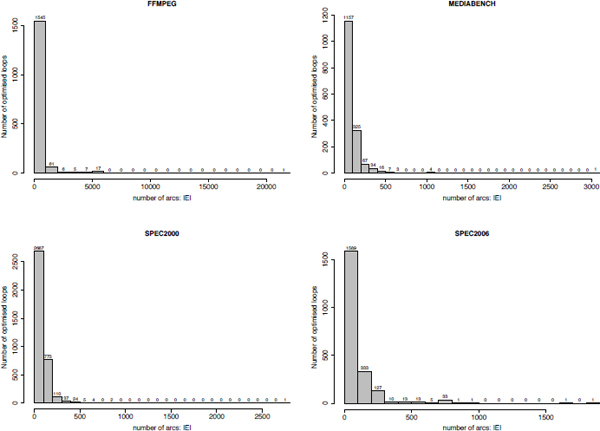
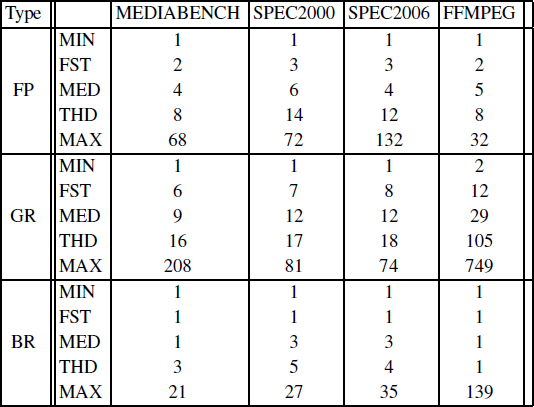
Figure A1.5. Histograms on MinII values

We also considered various configurations for the number of architectural registers. We considered three possible configurations named small, medium and large architectures, respectively:

Figure A1.6. Histograms on the number of strongly connected components

1 We deliberately choose to report the median value instead of the mean value because the histograms show a skewed (biased) distribution [JAI 91].
2 MIN stands for MINimum, FST stands for FirST quantile (25% of the population), MED stands for MEDian (50% of the population), THD stands for THirD quantile (75% of the population) and MAX stands for MAXimum.