
2.2.7 Vector product, scalar triple product
The angle θ between two vectors u and v in ε3![]() is defined by
is defined by
cosθ=u·v|u||v|,
where |u| is the natural norm, i.e., |u| = (u · u)1/2. Then the vector product in ε3![]() is defined by
is defined by
u×v=|u||v|nsinθ,|n|=1,u·n=v·n=0.
As such, the vector product accepts two vectors u and v as inputs, and provides a single vector in the direction of n as output. Note that n is the unit normal to the plane containing u and v; thus, two vector products are possible in ε3![]() . We single out the one for which {u, v, n} form a right-handed set. We also demand that the basis {e1, e2, e3} is right-handed, so
. We single out the one for which {u, v, n} form a right-handed set. We also demand that the basis {e1, e2, e3} is right-handed, so
e1×e2=e3,e2×e3=e1,e3×e1=e2,e1×e3=−e2,e2×e1=−e3,e3×e2=−e1,e1×e1=0,e2×e2=0,e3×e3=0.
Using indicial notation, we can write the nine equations in (2.56) as the single expression
ei×ej=εijkek,
where εijk is the permutation symbol, defined such that
εijk={1ifijk=123=231=312,−1ifijk=132=213=321,0otherwise.

Then, it can be shown (refer to Problem 2.41) that
u×v=εijkuivjek,
i.e.,
u×v=(u2v3−u3v2)e1+(u3v1−u1v3)e2+(u1v2−u2v1)e3=|e1e2e3u1u2u3v1v2v3|.

Note that the vector product is anticommutative, i.e.,
u×v=−v×u.
The scalar triple product [u v w] of three vectors is defined by
[uvw]=u·(v×w).
It can be shown that
[uvw]=[vwu]=[wuv].
The absolute value of [u v w] is the volume of the parallelepiped determined by u, v, and w. Also,
detS=[SuSvSw][uvw].

Corresponding to each skew tensor W∈L![]() is an axial vector w∈ε3
is an axial vector w∈ε3![]() , i.e.,
, i.e.,
Wv=w×v
for any v∈ε3![]() . Because of this correspondence, the set of all skew tensors is a three-dimensional inner product space ε3
. Because of this correspondence, the set of all skew tensors is a three-dimensional inner product space ε3![]() (refer to Problem 2.42).
(refer to Problem 2.42).
Problem 2.42
Verify in Cartesian component notation that the set of all symmetric tensors is a six-dimensional inner product space ε6![]() , and the set of all skew tensors is a three-dimensional inner product space ε3
, and the set of all skew tensors is a three-dimensional inner product space ε3![]() .
.
Consider an arbitrary symmetric tensor D. The Cartesian component form of D is
D=Dijei⊗ej=D11e1⊗e1+D12e1⊗e2+D13e1⊗e3+D21e2⊗e1+D22e2⊗e2+D23e2⊗e3+D31e3⊗e1+D32e3⊗e2+D33e3⊗e3.
But, since D is symmetric (i.e., DT = D),
Dij=ei·Dej=Dej·ei=ej·DTei=ej·Dei=Dji,
so
D12=D21,D13=D31,D23=D32.
Thus,
D=D11e1⊗e1+D12(e1⊗e2+e2⊗e1)+D13(e1⊗e3+e3⊗e1)+D22e2⊗e2+D23(e2⊗e3+e3⊗e2)+D33e3⊗e3.
It follows that the basis of any symmetric tensor D has six elements, so the set of all symmetric tensors is a six-dimensional inner product space ε6![]() . Note that only six components (D11, D12, D13, D22, D23, D33) are required to fully specify D.
. Note that only six components (D11, D12, D13, D22, D23, D33) are required to fully specify D.
Similarly, since W is skew (i.e., WT = −W),
Wij=ei·Wej=Wej·ei=ej·WTei=−ej·Wei=−Wji,
so
W11=W22=W33=0,W12=−W21,W13=−W31,W23=−W32.
Thus,
W=W12(e1⊗e2−e2⊗e1)+W13(e1⊗e3−e3⊗e1)+W23(e2⊗e3−e3⊗e2).
It follows that the basis of any skew tensor W has three elements, so the set of all skew tensors is a three-dimensional inner product space ε3![]() . Note that only three components (W12, W13, W23) are required to fully specify W.
. Note that only three components (W12, W13, W23) are required to fully specify W.
2.3 Eigenvalues, eigenvectors, polar decomposition, invariants
The presentation of the conceptual material in this section again follows [2]. In general, a tensor S maps a vector u to a vector Su. The vector Su typically has a length and orientation different from those of u. However, for special unit vectors a called eigenvectors, the tensor S maps a to a vector Sa that is parallel to a, i.e.,
Sa=αa.
The scalar α is referred to as an eigenvalue of S corresponding to the eigenvector a.
It can be shown that if S is positive definite, then its eigenvalues are strictly positive (refer to Problem 2.43). Further, if S is both symmetric and positive definite, then it can be shown that det S > 0, so S−1 exists (refer to Problem 2.44).
Problem 2.43
Prove that the eigenvalues of a positive-definite tensor are strictly positive.
Recall from (2.53) that if the tensor P is positive definite, then v · Pv > 0 for any vector v ≠ 0. Suppose, then, that we choose v = a, where a is any eigenvector of P. Then
a·Pa>0.
But, by (2.66), we have Pa = αa, where α is the eigenvalue corresponding to a, which implies that
α(a·a)>0.
Since eigenvectors are of unit length (a · a = |a|2 = 1), it follows that α > 0, i.e., the eigenvalue α corresponding to any eigenvector a of tensor P is positive.
Problem 2.44
Prove that if the tensor P is symmetric and positive definite, then det P > 0, so its inverse P−1 exists.
If P is a symmetric tensor, then by (2.67a) we have
P=α1a1⊗a1+α2a2⊗a2+α3a3⊗a3,
where a1, a2, a3 are the eigenvectors of P, and α1, α2, α3 are the corresponding eigenvalues of P. Hence, by (2.46),
detP=det[P]=det[α1000α2000α3]=α1α2α3.

Recall from Problem 2.43 that if a tensor P is positive definite, then its eigenvalues α1, α2, and α3 are all positive. Hence, det P = α1α2α3 > 0, and P is invertible.
If S is symmetric, its eigenvectors {a1, a2, a3} constitute an orthonormal basis for ε3![]() (the corresponding eigenvalues are α1, α2, and α3). Additionally, any symmetric S in L
(the corresponding eigenvalues are α1, α2, and α3). Additionally, any symmetric S in L![]() can be written with respect to a basis of its eigenvectors {ai ⊗ aj} as
can be written with respect to a basis of its eigenvectors {ai ⊗ aj} as
S=α1a1⊗a1+α2a2⊗a2+α3a3⊗a3=∑i=1αiai⊗ai,
or, in matrix form,
[S]=[α1000α2000α3].

If B is a symmetric, positive-definite tensor, then there exists a unique symmetric, positive-definite tensor V such that
V2≡VV=B.
That is, V=√B![]() .
.
If F is an invertible tensor (det F ≠ 0), then
F=RU=VR,
where U and V are symmetric, positive-definite tensors, and R is an orthogonal tensor. The multiplicative decomposition (2.69) is referred to as the polar decomposition of F. The tensors U, V, and R are unique, with
U=√FTF,V=√FFT,R=FU−1.
The terms in (2.70) make sense, because FTF and FFT can be shown to be symmetric and positive definite (refer to Problem 2.45), so we may use (2.68); also, det F ≠ 0 implies that det U ≠ 0, so U−1 exists. Note that if det F > 0, then R is proper orthogonal.
Problem 2.45
Prove that if F is nonsingular, then FTF and F FT are symmetric and positive definite.
First, we verify that FTF and F FT are symmetric. We have
(FTF)T=FT(FT)T=FTF,(FFT)T=(FT)TFT=FFT.
Thus, according to definition (2.15), FTF and F FT are symmetric.
Next, we verify that FTF is positive definite. We have
v·(FTF)v=v·FT(Fv)=Fv·Fv.
According to property (2.6)4 of inner product spaces, if Fv ≠ 0, then Fv · Fv > 0. Since F is nonsingular, det F ≠ 0, i.e., Fv = 0 if and only if v = 0. Hence, it follows that
v·(FTF)v>0
for any vector v ≠ 0, so, according to definition (2.53), FTF is positive definite.
Lastly, we verify that F FT is positive definite. We use result (2.47)2 to argue that det FT = det F ≠ 0 (i.e., if F is nonsingular, then so is FT), so FTv = 0 if and only if v = 0, which implies
v·(FFT)v=v·F(FTv)=FTv·FTv>0
for any vector v ≠ 0. Thus, according to definition (2.53), F FT is positive definite.
A nontrivial solution of the eigenvalue problem (2.66) requires
det(S−αI)=0.
It can be shown that
det(S−αI)=−α3+α3I1(S)−αI2(S)+I3(S),
so (2.71) becomes
−α3+α2I1(S)−αI2(S)+I3(S)=0,
where
I1(S)=trS,I2(S)=12[(trS)2−tr(S2)],I3(S)=detS
are called the principal invariants of S. Equation (2.73) is called the characteristic equation of S. According to the Cayley-Hamilton theorem, every tensor S satisfies its own characteristic equation, i.e.,
−S3+S2I1(S)−SI2(S)+II3(S)=0.
Note that if S is symmetric, then it follows from (2.67b) and (2.74) that
I1(S)=α1+α2+α3,I2(S)=α1α2+α2α3+α1α3,I3(S)=α1α2α3.
Thus, two symmetric tensors with the same eigenvalues have the same principal invariants.
2.4 Tensors of order three and four
We call linear transformations from ε3![]() to L
to L![]() , or from L
, or from L![]() to ε3
to ε3![]() , third-order tensors. Thus, a third-order tensor D(3) is a linear map that assigns to each vector u∈ε3
, third-order tensors. Thus, a third-order tensor D(3) is a linear map that assigns to each vector u∈ε3![]() a second-order tensor D(3)u∈L
a second-order tensor D(3)u∈L![]() such that
such that
D(3)(u+v)=D(3)u+D(3)v,D(3)(αv)=α(D(3)v),
or a linear map that assigns to each second-order tensor T∈L![]() a vector D(3)T∈ε3
a vector D(3)T∈ε3![]() such that
such that
D(3)(S+T)=D(3)S+D(3)T,D(3)(αT)=α(D(3)T)
for any second-order tensors S,T∈L![]() , vectors u,v∈ε3
, vectors u,v∈ε3![]() , and scalars α∈R
, and scalars α∈R![]() . The set of all third-order tensors is denoted by L(3)
. The set of all third-order tensors is denoted by L(3)![]() .
.
If a, b, and c are vectors in ε3![]() , we define the third-order tensor a ⊗ b ⊗ c by
, we define the third-order tensor a ⊗ b ⊗ c by
(a⊗b⊗c)v=a⊗b(c·v),(a⊗b⊗c)v⊗w=a(c·v)(b·w)
for any vectors v,w∈ε3![]() .
.
The Cartesian components Dijk of a third-order tensor D(3) are defined by
Dijk=(ei⊗ej)·(D(3)ek),
and we have
D(3)=Dijkei⊗ej⊗ek.
ei ⊗ ej ⊗ ek is a basis for L(3)=ε27![]() , a 27-dimensional inner product space.
, a 27-dimensional inner product space.
We call linear transformations from ε3![]() to L(3)
to L(3)![]() , L
, L![]() to L
to L![]() , or L(3)
, or L(3)![]() to ε3
to ε3![]() fourth-order tensors. Thus, a fourth-order tensor C(4) is a linear map that assigns to each vector u∈ε3
fourth-order tensors. Thus, a fourth-order tensor C(4) is a linear map that assigns to each vector u∈ε3![]() a third-order tensor
a third-order tensor
D(3)=C(4)u,
or to each second-order tensor T∈L![]() a second-order tensor
a second-order tensor
S=C(4)T,
or to each third-order tensor ε(3)∈L(3)![]() a vector
a vector
v=C(4)ε(3).
The set of all fourth-order tensors is denoted by L(4)![]() .
.
If a, b, c, and d are vectors in ε3![]() , we define the fourth-order tensor a ⊗ b ⊗ c ⊗ d by
, we define the fourth-order tensor a ⊗ b ⊗ c ⊗ d by
(a⊗b⊗c⊗d)v=a⊗b⊗c(d·v),(a⊗b⊗c⊗d)v⊗w=a⊗b(d·v)(c·w),(a⊗b⊗c⊗d)v⊗w⊗z=a(d·v)(c·w)(b·z)

for any vectors v,w,z∈ε3![]() .
.
The Cartesian components Cijkl of C(4) are defined by
Cijkl=(ei⊗ej)·(C(4)ek⊗el),
and we have
C(4)=Cijklei⊗ej⊗ek⊗el.
ei ⊗ ej ⊗ ek ⊗ el is a basis for L(4)=ε81![]() , an 81-dimensional inner product space.
, an 81-dimensional inner product space.
2.5 Tensor calculus
2.5.1 Partial derivatives
Let φ be a scalar-valued function of a tensor T, vector x, and scalar t, i.e.,
φ=φ(T,x,t).
We define the partial derivatives of φ by
∂∂tφ(T,x,t)=limα→01α[φ(T,x,t+α)−φ(T,x,t)],[∂∂xφ(T,x,t)]·u=limα→01α[φ(T,x,t+αu,t)−φ(T,x,t)],[∂∂Tφ(T,x,t)]·S=limα→01α[φ(T+αS,x,t)−φ(T,x,t)]

for all vectors u in ε3![]() and all tensors S in L
and all tensors S in L![]() . Note that α is a real number. Also note that ∂φ/∂t is a scalar, ∂φ/∂x is a vector, and ∂φ/∂T is a tensor.
. Note that α is a real number. Also note that ∂φ/∂t is a scalar, ∂φ/∂x is a vector, and ∂φ/∂T is a tensor.
Let v be a vector-valued function of tensor T, vector x, and scalar t, i.e.,
v=v(T,x,t).
We define the partial derivatives of v by
∂∂tv(T,x,t)=limα→01α[v(T,x,t+α)−v(T,x,t)],[∂∂xv(T,x,t)]u=limα→01α[v(T,x,t+αu,t)−v(T,x,t)],[∂∂Tv(T,x,t)]S=limα→01α[v(T+αS,x,t)−v(T,x,t)],

for all vectors u in ε3![]() and all tensors S in L
and all tensors S in L![]() . Note that ∂v/∂t is a vector and ∂v/∂x is a tensor. The quantity ∂v/∂T maps a tensor S to a vector, and is called a third-order tensor (refer to Section 2.4).
. Note that ∂v/∂t is a vector and ∂v/∂x is a tensor. The quantity ∂v/∂T maps a tensor S to a vector, and is called a third-order tensor (refer to Section 2.4).
Let A be a tensor-valued function of tensor T, vector x, and scalar t, i.e.,
A=A(T,x,t).
The partial derivatives of A are defined by
∂∂tA(T,x,t)=limα→01α[A(T,x,t+α)−A(T,x,t)],[∂∂xA(T,x,t)]u=limα→01α[A(T,x+αu,t)−A(T,x,t)],[∂∂TA(T,x,t)]S=limα→01α[A(T+αS,x,t)−A(T,x,t)],

for all vectors u in ε3![]() and all tensors S in L
and all tensors S in L![]() . Note that ∂A/∂t is a tensor. The quantity ∂A/∂x is a third-order tensor, i.e., it maps vectors to tensors; the fourth-order tensor ∂A/∂T maps tensors to tensors (refer to Section 2.4).
. Note that ∂A/∂t is a tensor. The quantity ∂A/∂x is a third-order tensor, i.e., it maps vectors to tensors; the fourth-order tensor ∂A/∂T maps tensors to tensors (refer to Section 2.4).
Recall from Section 2.3 that the principal invariants of a tensor A are
I1(A)=trA,I2(A)=12[(trA)2−tr(A2)],I3(A)=detA.
It can be shown that (refer to Problems 2.46–2.48)
dI1(A)dA=I,dI2(A)dA=I1(A)I−AT,dI3(A)dA=I3(A)A−T.
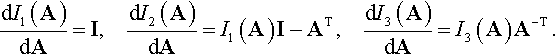
Problem 2.46
Prove in direct notation that dI1(A)dA=I .
.
Using the definition (2.89)3 of the derivative of a scalar with respect to a tensor, and the properties of the trace, we have, for all tensors S in L![]() ,
,

Since S is arbitrary, it follows that dI1(A)dA=I .
.
Problem 2.47
Prove in direct notation that dI2(A)dA=I1(A)I−AT![]() .
.
Note that in what follows, we employ the notation AA ≡ A2, as is done elsewhere in this book. Using the definition (2.89)3 of the derivative of a scalar with respect to a tensor, and the properties of the trace, we have, for all tensors S in L![]() ,
,

Recall from Problem 2.46 that
trS=tr(SI)=tr(SIT)=S·I=I·S.
Thus, it follows that
dI2(A)dA·S=(I1(A)I−AT)·S.

Since S is arbitrary, dI2(A)dA=I1(A)I−AT .
.
Problem 2.48
Prove in direct notation that dI3(A)dA=I3(A)A−T![]() .
.
In this problem, we will make use of the result
det(U+I)=1+trU+12[(trU)2−trU2]+detU=det(I+U),
which holds for any tensor U in L![]() and follows from (2.72) with α = −1. Note that I3(A) = det A, and det A is a scalar. Using the definition (2.89)3 of the derivative of a scalar with respect to a tensor, we have, for all tensors S in L
and follows from (2.72) with α = −1. Note that I3(A) = det A, and det A is a scalar. Using the definition (2.89)3 of the derivative of a scalar with respect to a tensor, we have, for all tensors S in L![]() ,
,


Since S is arbitrary and I3(A) = det A, it follows that dI3(A)dA=I3(A)A−T![]() .
.
2.5.2 Chain rule, gradient, divergence, curl, divergence theorem
If T and x in (2.88), (2.90), and (2.92) also depend on t, then the chain rule implies that
ddtφ(T(t),x(t),t)=∂φ∂T·dTdt+∂φ∂x·dxdt+∂φ∂t,ddtv(T(t),x(t),t)=∂v∂TdTdt+∂v∂xdxdt+∂v∂t,ddtA(T(t),x(t),t)=∂A∂TdTdt+∂A∂xdxdt+∂A∂t.

If the vector x in (2.88), (2.90), and (2.92) is a position vector, we define gradients of the scalar-valued function φ, vector-valued function v, and tensor-valued function A by
gradφ=∂∂xφ(T,x,t),gradv=∂∂xv(T,x,t),gradA=∂∂xA(T,x,t).

Note that the gradients of scalars, vectors, and tensors are vectors, tensors, and third-order tensors, respectively.
The divergence of a vector-valued function v of position is defined
divv=tr(gradv),
which is a scalar. The divergence of a tensor-valued function A of position is defined through
(divA)·a=div(ATa)
for any vector a. The divergence of a tensor is a vector. It can be shown (refer to Problems 2.49–2.51) that
grad(φv)=φgradv+v⊗gradφ,div(φv)=φdivv+v·gradφ,grad(v·w)=(gradv)Tw+(gradw)Tv,div(ATv)=A·gradv+v·divA,grad(1φ)=−1φ2gradφ,div(φA)=φdivA+Agradφ,div(v⊗w)=vdivw+(gradv)w.

Problem 2.49
Prove in direct notation that grad (φv) = φ grad v + v ⊗ grad φ.
Note that φv is a vector. Definition (2.96)2 of the gradient of a vector and definition (2.91)2 of the partial derivative of a vector with respect to a vector imply that
[grad(φv)]u=∂(φv)∂xu=limα→0φ(x+αu)v(x+αu)−φ(x)v(x)α.
Then adding and subtracting φ(x + αu) v(x) to and from the numerator, we have
[grad(φv)]u=limα→01α[φ(x+αu)v(x+αu)−φ(x+αu)v(x)+φ(x+αu)v(x)−φ(x)v(x)]=limα→0{φ(x+αu)[v(x+αu)−v(x)α]}+limα→0{[φ(x+αu)−φ(x)α]v(x)}=[limα→0φ(x+αu)]{limα→0v(x+αu)−v(x)α}+{limα→0φ(x+αu)−φ(x)α}v(x)=φ(x)(∂v∂xu)+(∂φ∂x·u)v(x)=(φgradv)u+(v⊗gradφ)u=(φgradv+v⊗gradφ)u.

Since u is arbitrary, it follows that grad (φv) = φ grad v + v ⊗ grad φ.
Problem 2.50
Prove in direct notation that div (φv) = φ div v + v · grad φ.
Again, note that φv is a vector. Using the definition (2.97) of the divergence of a vector, the result grad (φv) = φ grad v + v ⊗ grad φ from Problem 2.49, and the properties (2.38) of the trace, we have
div(φv)=tr[grad(φv)]=tr(φgradv+v⊗gradφ)=tr(φgradv)+tr(v⊗gradφ)=φtr(gradv)+v·gradφ=φdivv+v·gradφ.
Problem 2.51
Prove in direct notation that grad (v · w) = (grad v)Tw + (grad w)Tv.
Definition (2.96)1 of the gradient of a scalar and definition (2.89)2 of the partial derivative of a scalar with respect to a vector imply that
[grad(v·w)]·u=∂(v·w)∂x·u=limα→0v(x+αu)·w(x+αu)−v(x)·w(x)α=limα→01α[v(x+αu)·w(x+αu)−v(x)·w(x+αu)+v(x)·w(x+αu)−v(x)·w(x)]=limα→0{[v(x+αu)−v(x)α]·w(x+αu)}+limα→0{v(x)·[w(x+αu)−w(x)α]}=[limα→0v(x+αu)−v(x)α]·[limα→0w(x+αu)]+v(x)·[limα→0w(x+αu)−w(x)α]=∂v∂xu·w+v·∂w∂xu=(gradv)u·w+v·(gradw)u=(gradv)Tw·u+(gradw)Tv·u=[(gradv)Tw+(gradw)Tv]·u.

Since the vector u is arbitrary, it follows that grad (v · w) = (grad v)Tw + (grad w)Tv.
The curl of a vector v is defined by
(curlv)×a=[gradv−(gradv)T]a.
We can show that the divergence of the curl of a vector v vanishes, i.e.,
div(curlv)=0.
Also,
curl(v×w)=(gradv)w−(gradw)v+v(divw)−w(divv).
Note that a useful property of the gradient, divergence, and curl is distributivity over vector and tensor addition, e.g.,
curl(v+w)=curlv+curlw,
div(A+B)=divA+divB.
If R![]() is an open region (volume) bounded by a closed surface ∂R
is an open region (volume) bounded by a closed surface ∂R![]() , and φ, v, and A are smooth functions of position, then, according to the divergence theorem,
, and φ, v, and A are smooth functions of position, then, according to the divergence theorem,
∫Rgradφdv=∫∂Rφnda,∫Rdivvdv=∫∂Rv·nda,∫RdivAdv=∫∂RAnda,
where dv is the volume element of R![]() , da is the area element of ∂R
, da is the area element of ∂R![]() , and n is the outward unit normal on ∂R
, and n is the outward unit normal on ∂R![]() . It follows that (refer to Problem 2.52)
. It follows that (refer to Problem 2.52)
∫∂Rv·Anda=∫R(A·gradv+v·divA)dv.
Problem 2.52
Prove in direct notation that ∫∂Rv·Anda=∫R(A·gradv+v·divA)dv.
Recall that R![]() is an open volume bounded by a closed surface ∂R
is an open volume bounded by a closed surface ∂R![]() , dv is the volume element of R
, dv is the volume element of R![]() , da is the area element of ∂R
, da is the area element of ∂R![]() , and n is the outward unit normal on ∂R
, and n is the outward unit normal on ∂R![]() . We have
. We have
∫∂Rv·Anda=∫∂Rv·(AT)Tnda=∫∂RATv·nda=∫Rdiv(ATv)dv=∫∂R(A·gradv+v·divA)dv.
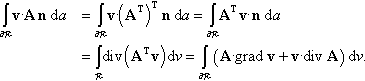
Note that we have used result (2.99)4.
2.5.3 Tensor calculus in cartesian component form
The Cartesian component form of the chain rule (2.95) is
ddtφ(T(t),x(t),t)=∂φ∂TijdTijdt+∂φ∂xjdxidt+∂φ∂t,ddtvi(T(t),x(t),t)=∂vi∂TjkdTjkdt+∂vi∂xjdxjdt+∂vi∂t,ddtAij(T(t),x(t),t)=∂Aij∂TkldTkldt+∂Aij∂xkdxkdt+∂Aij∂t.

It can be shown (refer to Problems 2.53–2.57) that
(gradφ)i=∂φ∂xi≡φi,(gradv)ij=∂vi∂xj≡vi,j,(gradA)ijk=∂Aij∂xk≡Aij,k,divv=∂vi∂xi=vi,i,(divA)i=∂Aij∂xj=Aij,j.

Then, it follows that the Cartesian component form of the divergence theorem is
∫Rφidv=∫∂Rφnida,∫Rvi,idv=∫∂Rvinida,∫RAij,jdv=∫∂RAijnjda.

The Cartesian component form of the curl of a vector v is
(curlv)i=εijkvk,j.
Problem 2.53
Prove that (grad φ)i = φ,i (i.e., the Cartesian components of grad φ are φ,i).
Note that the gradient of a scalar φ is a vector. Its Cartesian components are
(gradφ)i=(gradφ)·ei=∂φ∂x·ei=limα→01α[φ(x+αei)−φ(x)]=∂φ∂xi≡φ,i.

Thus,
gradφ=φ,iei=φ,1e1+φ,2e2+φ,3e3.
Problem 2.54
Prove that (grad v)ij = vi,j (i.e., the Cartesian components of grad v are vi,j).
Note that the gradient of a vector v is a tensor. Its Cartesian components are
(gradv)ij=ei•(gradv)ej=ei•∂v∂xej=ei•[limα→0v(x+αej)−v(x)α]=ei•∂v∂xj=∂∂xj(ei•v)=∂vi∂xj≡vi,j.
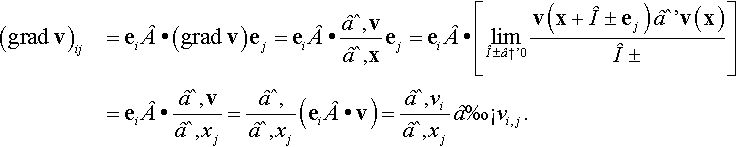
Thus,
gradv=vi,jei⊗ej=v1,1e1⊗e1+v1,2e1⊗e2+v1,3e1⊗e3+v2,1e2⊗e1+v2,2e2⊗e2+v2,3e2⊗e3+v3,1e3⊗e1+v3,2e3⊗e2+v3,3e3⊗e3
and
[gradv]=[v1,1v1,2v1,3v2,1v2,2v2,3v3,1v3,2v3,3].

Problem 2.55
Verify that (grad A)ijk = Aij,k.
Note that the gradient of a tensor A is a third-order tensor. Hence, according to (2.80), its Cartesian components are
(gradA)ijk=(ei⊗ej)·[(gradA)ek].
Then,
(gradA)ijk=(ei⊗ej)·(∂A∂xek)(definition(2.96)3)=(ei⊗ej)·{limα→01α[A(x+αek)−A(x)]}(definition(2.93)2)=(ei⊗ej)·∂A∂xk(definition of partial derivative)=∂∂xk[A·(ei⊗ej)](eiandejindependent ofxk)=∂∂xktr[A(ei⊗ej)T](definition(2.41))=∂∂xktr[A(ej⊗ei)](result(2.20)1)=∂∂xktr[(Aej)⊗ei](result(2.20)2)=∂∂xk(ei⊗Aej)(definition(2.38)3)=∂Aij∂xk(definition(2.29))≡Aij,k.

Thus, grad A = Aij,kei ⊗ ej ⊗ ek.
Problem 2.56
Show that div v = vi,i.
Note that the divergence of a vector v is a scalar. Using definition (2.97) and the result grad v = vi,jei ⊗ ej from Problem 2.54, we have
divv=tr(gradv)=tr(vi,jei⊗ej)=vi,jtr(ei⊗ej)=vi,j(ei·ej)=vi,jδij=vi,i.
Expanding this result, we obtain
divv=vi,i=v1,1+v2,2+v3,3.
Problem 2.57
Prove that (div A)i = Aij,j.
The divergence of a tensor A is a vector. The ith component of this vector is
(divA)i=(divA)·ei=div(ATei),
where we have used definition (2.24) of the Cartesian component of a vector and definition (2.98) of the divergence of a tensor. Then
div(ATei)=div[(Akjej⊗ek)ei]=div[Akj(ek·ei)ej]=div(Akjδkiej)=div(Aijej).
Recalling that div v = div (viei) = vi,i from Problem 2.56, we deduce by analogy that div (Aijej) = Aij,j. Thus,
(divA)i=Aij,j,
so
divA=(divA)iei=Aij,jei=(A11,1+A12,2+A13,3)e1+(A21,1+A22,2+A23,3)e2+(A31,1+A32,2+A33,3)e3.