
Chapter 18. Camera Models and Calibration
Vision begins with the detection of light from the world. That light begins as rays emanating from some source (e.g., a light bulb or the sun), which travel through space until striking some object. When that light strikes the object, much of the light is absorbed, and what is not absorbed we perceive as the color of the object. Reflected light that makes its way to our eye (or our camera) is collected on our retina (or our imager). The geometry of this arrangement—particularly of the rays’ travel from the object, through the lens in our eye or camera, and to the retina or imager—is of particular importance to practical computer vision.
A simple but useful model of how this happens is the pinhole camera model.1 A pinhole is an imaginary wall with a tiny hole in the center that blocks all rays except those passing through the tiny aperture in the center. In this chapter, we will start with a pinhole camera model to get a handle on the basic geometry of projecting rays. Unfortunately, a real pinhole is not a very good way to make images because it does not gather enough light for rapid exposure. This is why our eyes and cameras use lenses to gather more light than what would be available at a single point. The downside, however, is that gathering more light with a lens not only forces us to move beyond the simple geometry of the pinhole model but also introduces distortions from the lens itself.
In this chapter, we will learn how, using camera calibration, to correct (mathematically) for the main deviations from the simple pinhole model that the use of lenses imposes on us. Camera calibration is also important for relating camera measurements to measurements in the real, three-dimensional world. This is important because scenes are not only three-dimensional; they are also physical spaces with physical units. Hence, the relation between the camera’s natural units (pixels) and the units of the physical world (e.g., meters) is a critical component of any attempt to reconstruct a three-dimensional scene.
The process of camera calibration gives us both a model of the camera’s geometry and a distortion model of the lens. These two informational models define the intrinsic parameters of the camera. In this chapter, we use these models to correct for lens distortions; in Chapter 19, we will use them to interpret the entire geometry of the physical scene.
We will begin by looking at camera models and the causes of lens distortion. From there, we will explore the homography transform, the mathematical instrument that allows us to capture the effects of the camera’s basic behavior and of its various distortions and corrections. We will take some time to discuss exactly how the transformation that characterizes a particular camera can be calculated mathematically. Once we have all this in hand, we’ll move on to the OpenCV functions that handle most of this work for us.
Just about all of this chapter is devoted to building enough theory that you will truly understand what is going into (and coming out of) the OpenCV function cv::calibrateCamera() as well as what that function is doing “under the hood.” This is important stuff if you want to use the function responsibly. Having said that, if you are already an expert and simply want to know how to use OpenCV to do what you already understand, jump right ahead to “Calibration function” and get to it. Note that Appendix B references other calibration patterns and techniques in the ccalib function group.
Camera Model
We begin by looking at the simplest model of a camera, the pinhole. In this simple model, light is envisioned as entering from the scene or a distant object, but only a single ray enters the pinhole from any particular point in that scene. In a physical pinhole camera, this point is then “projected” onto an imaging surface. As a result, the image on this image plane (also called the projective plane) is always in focus, and the size of the image relative to the distant object is given by a single parameter of the camera: its focal length. For our idealized pinhole camera, the distance from the pinhole aperture to the screen is precisely the focal length.2 This is shown in Figure 18-1, where f is the focal length of the camera, Z is the distance from the camera to the object, X is the length of the object, and x is the object’s image on the imaging plane. In the figure, we can see by similar triangles that –x/f = X/Z, or:


Figure 18-1. Pinhole camera model: a pinhole (the pinhole aperture) lets through only those light rays that intersect a particular point in space; these rays then form an image by “projecting” onto an image plane
We will now rearrange our pinhole camera model to a form that is equivalent but in which the math comes out easier. In Figure 18-2, we swap the pinhole and the image plane.3 The main difference is that the object now appears right side up. The point in the pinhole is reinterpreted as the center of projection. In this way of looking at things, every ray leaves a point on the distant object and heads for the center of projection. The point at the intersection of the image plane and the optical axis is referred to as the principal point. On this new frontal image plane (see Figure 18-2), which is the equivalent of the old projective or image plane, the image of the distant object is exactly the same size as it was on the image plane in Figure 18-1. The image is generated by intersecting these rays with the image plane, which happens to be exactly a distance f from the center of projection. This makes the similar triangles relationship x/f = X/Z more directly evident than before. The negative sign is gone because the object image is no longer upside down.

Figure 18-2. A point  is projected onto the image plane by the ray passing through the center of projection, and the resulting point on the image is
is projected onto the image plane by the ray passing through the center of projection, and the resulting point on the image is  ; the image plane is really just the projection screen “pushed” in front of the pinhole (the math is equivalent but simpler this way)
; the image plane is really just the projection screen “pushed” in front of the pinhole (the math is equivalent but simpler this way)
You might think that the principal point is equivalent to the center of the imager, but this would imply that some guy with tweezers and a tube of glue was able to attach the imager in your camera to micron accuracy. In fact, the center of the imager chip is usually not on the optical axis. We thus introduce two new parameters, cx and cy, to model a possible displacement (away from the optic axis) of the center of coordinates on the projection screen. The result is that a relatively simple model in which a point ![]() in the physical world, whose coordinates are (X, Y, Z), is projected onto the imager at some pixel location given by (xscreen, yscreen) in accordance with the following equations:4
in the physical world, whose coordinates are (X, Y, Z), is projected onto the imager at some pixel location given by (xscreen, yscreen) in accordance with the following equations:4

Note that we have introduced two different focal lengths; the reason for this is that the individual pixels on a typical low-cost imager are rectangular rather than square. The focal length fx, for example, is actually the product of the physical focal length of the lens and the size sx of the individual imager elements (this should make sense because sx has units of pixels per millimeter,5 while f has units of millimeters, which means that fx is in the required units of pixels). Of course, similar statements hold for fy and sy. It is important to keep in mind, though, that sx and sy cannot be measured directly via any camera calibration process, and neither is the physical focal length f directly measurable. We can derive only the combinations fx = F · sx and fy = F · sy without actually dismantling the camera and measuring its components directly.
The Basics of Projective Geometry
The relation that maps a set of points ![]() in the physical world with coordinates (Xi, Yi, Zi) to the points on the projection screen with coordinates (xi, yi) is called a projective transform. When you are working with such transforms, it is convenient to use what are known as homogeneous coordinates. The homogeneous coordinates associated with a point in a projective space of dimension n are typically expressed as an (n + 1)-dimensional vector (e.g., x, y, z becomes x, y, z, w), with the additional restriction that any two points whose values are proportional are, in fact, equivalent points. In our case, the image plane is the projective space and it has two dimensions, so we will represent points on that plane as three-dimensional vectors
in the physical world with coordinates (Xi, Yi, Zi) to the points on the projection screen with coordinates (xi, yi) is called a projective transform. When you are working with such transforms, it is convenient to use what are known as homogeneous coordinates. The homogeneous coordinates associated with a point in a projective space of dimension n are typically expressed as an (n + 1)-dimensional vector (e.g., x, y, z becomes x, y, z, w), with the additional restriction that any two points whose values are proportional are, in fact, equivalent points. In our case, the image plane is the projective space and it has two dimensions, so we will represent points on that plane as three-dimensional vectors ![]() . Recalling that all points having proportional values in the projective space are equivalent, we can recover the actual pixel coordinates by dividing through by q3. This allows us to arrange the parameters that define our camera (i.e., fx, fy, cx and cy) into a single 3 × 3 matrix, which we will call the camera intrinsics matrix.6 The projection of the points in the physical world into the camera is now summarized by the following simple form:
. Recalling that all points having proportional values in the projective space are equivalent, we can recover the actual pixel coordinates by dividing through by q3. This allows us to arrange the parameters that define our camera (i.e., fx, fy, cx and cy) into a single 3 × 3 matrix, which we will call the camera intrinsics matrix.6 The projection of the points in the physical world into the camera is now summarized by the following simple form:

where:

Multiplying this out, you will find that w = Z and so, since the point ![]() is in homogeneous coordinates, we can divide through by w (or Z) in order to recover our earlier definitions. The minus sign is gone because we are now looking at the noninverted image on the projective plane in front of the pinhole rather than the inverted image on the projection screen behind the pinhole.
is in homogeneous coordinates, we can divide through by w (or Z) in order to recover our earlier definitions. The minus sign is gone because we are now looking at the noninverted image on the projective plane in front of the pinhole rather than the inverted image on the projection screen behind the pinhole.
While we are on the topic of homogeneous coordinates, there are a few functions in the OpenCV library that are appropriate to introduce here. The functions cv::convertPointsToHomogeneous() and cv::convertPointsFromHomogeneous() allow us to convert to and from homogeneous coordinates.7 They have the following prototypes:
void cv::convertPointsToHomogeneous( cv::InputArray src, // Input vector of N-dimensional points cv::OutputArray dst // Result vector of (N+1)-dimensional points ); void cv::convertPointsFromHomogeneous( cv::InputArray src, // Input vector of N-dimensional points cv::OutputArray dst // Result vector of (N-1)-dimensional points );
The first function expects a vector of N-dimensional points (in any of the usual representations) and constructs a vector of (N + 1)-dimensional points from that vector. All of the entries of the newly constructed vector associated with the added dimension are set to 1. The result is that:

The second function does the conversion back from homogeneous coordinates. Given an input vector of points of dimension N, it constructs a vector of (N – 1)-dimensional points by first dividing all of the components of each point by the value of the last components of the point’s representation and then throwing away that component. The result is that:

With the ideal pinhole, we have a useful model for some of the three-dimensional geometry of vision. Remember, however, that very little light goes through a pinhole; thus, in practice, such an arrangement would make for very slow imaging while we wait for enough light to accumulate on whatever imager we are using. For a camera to form images at a faster rate, we must gather a lot of light over a wider area and bend (i.e., focus) that light to converge at the point of projection. To accomplish this, we use a lens. A lens can focus a large amount of light on a point to give us fast imaging, but it comes at the cost of introducing distortions.
Rodrigues Transform
When dealing with three-dimensional spaces, one most often represents rotations in that space by 3 × 3 matrices. This representation is usually the most convenient because multiplying a vector by this matrix is equivalent to rotating the vector in some way. The downside is that it can be difficult to intuit just what 3 × 3 matrix goes with what rotation. Briefly, we are going to introduce an alternative representation for such rotations that is used by some of the OpenCV functions in this chapter, as well as a useful function for converting to and from this alternative representation.
This alternate, and somewhat easier-to-visualize,8 representation for a rotation is essentially a vector about which the rotation operates together with a single angle. In this case it is standard practice to use only a single vector whose direction encodes the direction of the axis to be rotated around, and to use the length of the vector to encode the amount of rotation in a counterclockwise direction. This is easily done because the direction can be equally well represented by a vector of any magnitude; hence, we can choose the magnitude of our vector to be equal to the magnitude of the rotation. The relationship between these two representations, the matrix and the vector, is captured by the Rodrigues transform.9
Let ![]() be the three-dimensional vector
be the three-dimensional vector ![]() ; this vector implicitly defines θ, the magnitude of the rotation by the length (or magnitude) of
; this vector implicitly defines θ, the magnitude of the rotation by the length (or magnitude) of ![]() . We can then convert from this axis-magnitude representation to a rotation matrix R as follows:
. We can then convert from this axis-magnitude representation to a rotation matrix R as follows:

We can also go from a rotation matrix back to the axis-magnitude representation by using:

Thus we find ourselves in the situation of having one representation (the matrix representation) that is most convenient for computation and another representation (the Rodrigues representation) that is a little easier on the brain. OpenCV provides us with a function for converting from either representation to the other:
void cv::Rodrigues( cv::InputArray src, // Input rotation vector or matrix cv::OutputArray dst, // Output rotation matrix or vector cv::OutputArray jacobian = cv::noArray() // Optional Jacobian (3x9 or 9x3) );
Suppose we have the vector ![]() and need the corresponding rotation matrix representation R; we set
and need the corresponding rotation matrix representation R; we set src to be the 3 × 1 vector ![]() and
and dst to be the 3 × 3 rotation matrix R. Conversely, we can set src to be a 3 × 3 rotation matrix R and dst to be a 3 × 1 vector ![]() . In either case,
. In either case, cv::Rodrigues() will do the right thing. The final argument is optional. If jacobian is something other than cv::noArray(), then it should be a pointer to a 3 × 9 or a 9 × 3 matrix that will be filled with the partial derivatives of the output array components with respect to the input array components. The jacobian outputs are mainly used for the internal optimization of the cv::solvePnP() and cv::calibrateCamera() functions; your use of the cv::Rodrigues() function will mostly be limited to converting the outputs of cv::solvePnP() and cv::calibrateCamera() from the Rodrigues format of 1 × 3 or 3 × 1 axis-angle vectors to rotation matrices. For this, you can leave jacobian set to cv::noArray().
Lens Distortions
In theory, it is possible to define a lens that will introduce no distortions. In practice, however, no lens is perfect. This is mainly for reasons of manufacturing; it is much easier to make a “spherical” lens than to make a more mathematically ideal “parabolic” lens. It is also difficult to mechanically align the lens and imager exactly. Here we describe the two main lens distortions and how to model them.10 Radial distortions arise as a result of the shape of lens, whereas tangential distortions arise from the assembly process of the camera as a whole.
We start with radial distortion. The lenses of real cameras often noticeably distort the location of pixels near the edges of the imager. This bulging phenomenon is the source of the “barrel” or “fisheye” effect (see the room-divider lines at the top of Figure 18-17 for a good example). Figure 18-3 gives some intuition as to why this radial distortion occurs. With some lenses, rays farther from the center of the lens are bent more than those closer in. A typical inexpensive lens is, in effect, stronger than it ought to be as you get farther from the center. Barrel distortion is particularly noticeable in cheap web cameras but less apparent in high-end cameras, where a lot of effort is put into fancy lens systems that minimize radial distortion.

Figure 18-3. Radial distortion: rays farther from the center of a simple lens are bent too much compared to rays that pass closer to the center; thus, the sides of a square appear to bow out on the image plane (this is also known as barrel distortion)
For radial distortions, the distortion is 0 at the (optical) center of the imager and increases as we move toward the periphery. In practice, this distortion is small and can be characterized by the first few terms of a Taylor series expansion around r = 0.11 For cheap web cameras, we generally use the first two such terms; the first of which is conventionally called k1 and the second k2. For highly distorted cameras such as fisheye lenses, we can use a third radial distortion term, k3. In general, the radial location of a point on the imager will be rescaled according to the following equations:12

and:

Here, (x, y) is the original location (on the imager) of the distorted point and ![]() is the new location as a result of the correction. Figure 18-4 shows displacements of a rectangular grid that are due to radial distortion. External points on a front-facing rectangular grid are increasingly displaced inward as the radial distance from the optical center increases.
is the new location as a result of the correction. Figure 18-4 shows displacements of a rectangular grid that are due to radial distortion. External points on a front-facing rectangular grid are increasingly displaced inward as the radial distance from the optical center increases.

Figure 18-4. Radial distortion plot for a particular camera lens: the arrows show where points on an external rectangular grid are displaced in a radially distorted image (courtesy of Jean-Yves Bouguet)13
The second-largest common distortion is tangential distortion. This distortion is due to manufacturing defects resulting from the lens not being exactly parallel to the imaging plane; see Figure 18-5.

Figure 18-5. Tangential distortion results when the lens is not fully parallel to the image plane; in cheap cameras, this can happen when the imager is glued to the back of the camera (image courtesy of Sebastian Thrun)
Tangential distortion is minimally characterized by two additional parameters: p1 and p2, such that:14

and:

Thus in total there are five distortion coefficients that we require. Because all five are necessary in most of the OpenCV routines that use them, they are typically bundled into one distortion vector; this is just a 5 × 1 matrix containing k1, k2, p1, p2, and k3 (in that order). Figure 18-6 shows the effects of tangential distortion on a front-facing external rectangular grid of points. The points are displaced elliptically as a function of location and radius.

Figure 18-6. Tangential distortion plot for a particular camera lens: the arrows show where points on an external rectangular grid are displaced in a tangentially distorted image (courtesy of Jean-Yves Bouguet)
There are many other kinds of distortions that occur in imaging systems, but they typically have lesser effects than radial and tangential distortions. Hence, neither we nor OpenCV will deal with them further.
Calibration
Now that we have some idea of how we’d describe the intrinsic and distortion properties of a camera mathematically, the next question that naturally arises is how we can use OpenCV to compute the intrinsics matrix and the distortion vector.15
OpenCV provides several algorithms to help us compute these intrinsic parameters. The actual calibration is done via cv::calibrateCamera(). In this routine, the method of calibration is to target the camera on a known structure that has many individual and identifiable points. By viewing this structure from a variety of angles, we can then compute the (relative) location and orientation of the camera at the time of each image as well as the intrinsic parameters of the camera (see Figure 18-10 in the section “Finding chessboard corners with cv::findChessboardCorners()”). To provide multiple views, we rotate and translate the object, so let’s pause to learn a little more about rotation and translation.
OpenCV continues to improve its calibration techniques; there are now many different types of calibration board patterns, as described in the section “Calibration Boards”. There are also specialized calibration techniques for “out of the ordinary” cameras. For fisheye lenses, you want to use the fisheye methods in the cv::fisheye class in the user documentation.
There are also techniques for omnidirectional (180-degree) camera and multicamera calibration; see opencv_contrib/modules/ccalib/samples, opencv_contrib/modules/ccalib/tutorial/omnidir_tutorial.markdown, opencv_contrib/modules/ccalib/tutorial/multi_camera_tutorial.markdown, and/or search on “omnidir” and “multiCameraCalibration,” respectively, in the user documentation; see Figure 18-7.16

Figure 18-7. An omnidirectional camera17
Rotation Matrix and Translation Vector
For each image the camera takes of a particular object, we can describe the pose of the object relative to the camera coordinate system in terms of a rotation and a translation; see Figure 18-8.

Figure 18-8. Converting from object to camera coordinate systems: the point P on the object is seen as point p on the image plane; we relate the point p to point P by applying a rotation matrix R and a translation vector t to P
In general, a rotation in any number of dimensions can be described in terms of multiplication of a coordinate vector by a square matrix of the appropriate size. Ultimately, a rotation is equivalent to introducing a new description of a point’s location in a different coordinate system. Rotating the coordinate system by an angle θ is equivalent to counter-rotating our target point around the origin of that coordinate system by the same angle θ. The representation of a two-dimensional rotation as matrix multiplication is shown in Figure 18-9. Rotation in three dimensions can be decomposed into a two-dimensional rotation around each axis in which the pivot axis measurements remain constant. If we rotate around the x-, y-, and z-axes in sequence18 with respective rotation angles ψ, φ, and θ, the result is a total rotation matrix R that is given by the product of the three matrices ![]() ,
, ![]() , and
, and ![]() , where:
, where:


Figure 18-9. Rotating points by θ (in this case, around the z-axis) is the same as counter-rotating the coordinate axis by θ; by simple trigonometry, we can see how rotation changes the coordinates of a point
Thus ![]() . The rotation matrix R has the property that its inverse is its transpose (we just rotate back); hence, we have
. The rotation matrix R has the property that its inverse is its transpose (we just rotate back); hence, we have ![]() , where I3 is the 3 × 3 identity matrix consisting of 1s along the diagonal and 0s everywhere else.
, where I3 is the 3 × 3 identity matrix consisting of 1s along the diagonal and 0s everywhere else.
The translation vector is how we represent a shift from one coordinate system to another system whose origin is displaced to another location; in other words, the translation vector is just the offset from the origin of the first coordinate system to the origin of the second coordinate system. Thus, to shift from a coordinate system centered on an object to one centered at the camera, the appropriate translation vector is simply ![]() . We then know (with reference to Figure 18-8) that a point in the object (or world) coordinate frame
. We then know (with reference to Figure 18-8) that a point in the object (or world) coordinate frame ![]() has coordinates
has coordinates ![]() in the camera coordinate frame:
in the camera coordinate frame:

Combining this equation for ![]() with the camera intrinsic-corrections will form the basic system of equations that we will be asking OpenCV to solve. The solution to these equations will contain the camera calibration parameters we seek.
with the camera intrinsic-corrections will form the basic system of equations that we will be asking OpenCV to solve. The solution to these equations will contain the camera calibration parameters we seek.
We have just seen that a three-dimensional rotation can be specified with three angles and that a three-dimensional translation can be specified with the three parameters (x, y, z); thus we have six parameters so far. The OpenCV intrinsics matrix for a camera has four parameters (fx, fy, cx, and cy), yielding a grand total of 10 parameters that must be solved for each view (but note that the camera-intrinsic parameters stay the same between views). Using a planar object, we’ll soon see that each view fixes eight parameters. Because the six parameters of rotation and translation change between views, for each view we have constraints on two additional parameters that we then use to resolve the camera-intrinsic matrix. Thus, we need (at least) two views to solve for all the geometric parameters.
We’ll provide more details on the parameters and their constraints later in the chapter, but first we’ll discuss the calibration object. The calibration objects used in OpenCV are flat patterns of several types described next. The first OpenCV calibration object was a “chessboard” as shown in Figure 18-10. The following discussion will mostly refer to this type of pattern, but other patterns are available, as we will see.
Calibration Boards
In principle, any appropriately characterized object could be used as a calibration object. One practical choice is a regular pattern on a flat surface, such as a chessboard19 (see Figure 18-10), circle-grid (see Figure 18-15), randpattern20 (see Figure 18-11), ArUco (see Figure 18-12), or ChArUco patterns21 (see Figure 18-13). Appendix C has usable examples of all the calibration patterns available in OpenCV. Some calibration methods in the literature rely on three-dimensional objects (e.g., a box covered with markers), but flat chessboard patterns are much easier to deal with; among other things, it is rather difficult to make (and to store and distribute) precise three-dimensional calibration objects. OpenCV thus opts for using multiple views of a planar object rather than one view of a specially constructed three-dimensional object. For the moment, we will focus on the chessboard pattern. The use of a pattern of alternating black and white squares (see Figure 18-10) ensures that there is no bias toward one side or the other in measurement. Also, the resulting grid corners lend themselves naturally to the subpixel localization function discussed in Chapter 16. We will also discuss another alternative calibration board, called a circle-grid (see Figure 18-15), which has some desirable properties, and which in some cases may give superior results to the chessboard. For the other patterns, please see the documentation referenced in the figures in this chapter. The authors have had particularly good success using the ChArUco pattern.

Figure 18-10. Images of a chessboard being held at various orientations (left) provide enough information to completely solve for the locations of those images in global coordinates (relative to the camera) and the camera intrinsics

Figure 18-11. A calibration pattern made up of a highly textured random pattern; see the multicamera calibration tutorial in the opencv_contrib/modules/ccalib/tutorial directory22

Figure 18-12. A calibration pattern made up of a grid of ArUco (2D barcode) squares. Note that because each square is identified by its ArUco pattern, much of the board can be occluded and yet still have enough spatially labeled points to be used in calibration. See “ArUco marker detection (aruco module)” in the OpenCV documentation23

Figure 18-13. Checkerboard with embedded ArUco (ChArUco). A checkerboard calibration pattern where each corner is labeled with an ArUco (2D barcode) pattern. This allows much of the checkerboard to be occluded while allowing for the higher positional accuracy of corner intersections. See “ArUco marker detection (aruco module)” in the OpenCV documentation24
Finding chessboard corners with cv::findChessboardCorners()
Given an image of a chessboard (or a person holding a chessboard, or any other scene with a chessboard and a reasonably uncluttered background), you can use the OpenCV function cv::findChessboardCorners() to locate the corners of the chessboard:
bool cv::findChessboardCorners( // Return true if corners were found
cv::InputArray image, // Input chessboard image, 8UC1 or 8UC3
cv::Size patternSize, // corners per row, and per column
cv::OutputArray corners, // Output array of detected corners
int flags = cv::CALIB_CB_ADAPTIVE_THRESH
| cv::CALIB_CB_NORMALIZE_IMAGE
);
This function takes as arguments a single image containing a chessboard. This image must be an 8-bit image. The second argument, patternSize, indicates how many corners are in each row and column of the board (e.g., cv::Size(cols,rows)). This count is the number of interior corners; thus, for a standard chess game board, the correct value would be cv::Size(7,7).25 The next argument, corners, is the output array where the corner locations will be recorded. The individual values will be set to the locations of the located corners in pixel coordinates. The final flags argument can be used to implement one or more additional filtration steps to help find the corners on the chessboard. You may combine any or all of the following arguments using a Boolean OR:
cv::CALIB_CB_ADAPTIVE_THRESH- The default behavior of
cv::findChessboardCorners()is first to threshold the image based on average brightness, but if this flag is set, then an adaptive threshold will be used instead. cv::CALIB_CB_NORMALIZE_IMAGE- If set, this flag causes the image to be normalized via
cv::equalizeHist()before the thresholding is applied. cv::CALIB_CB_FILTER_QUADS- Once the image is thresholded, the algorithm attempts to locate the quadrangles resulting from the perspective view of the black squares on the chessboard. This is an approximation because the lines of each edge of a quadrangle are assumed to be straight, which isn’t quite true when there is radial distortion in the image. If this flag is set, then a variety of additional constraints are applied to those quadrangles in order to reject false quadrangles.
cv::CALIB_CV_FAST_CHECK- When this option is present, a fast scan will be done on the image to make sure that there actually are any corners in the image. If there are not, then the image is skipped entirely. This is not necessary if you are absolutely certain that your input data is “clean” and has no images without the chessboard in them. On the other hand, you will save a great deal of time using this option if there actually turn out to be images without chessboards in them in your input.
The return value of cv::findChessboardCorners() will be set to true if all of the corners in the pattern could be found and ordered;26 otherwise, it will be false.
Subpixel corners on chessboards and cv::cornerSubPix()
The internal algorithm used by cv::findChessboardCorners() gives only the approximate location of the corners. Therefore, cv::cornerSubPix() is automatically called by cv::findChessboardCorners() in order to give more accurate results. What this means in practice is that the locations are going to be relatively accurate. However, if you would like them located to very high precision, you will want to call cv::cornerSubPix() yourself (effectively calling it again) on the output, but with tighter termination criteria.
Drawing chessboard corners with cv::drawChessboardCorners()
Particularly when one is debugging, it is often desirable to draw the found chessboard corners onto an image (usually the image that we used to compute the corners in the first place); this way, we can see whether the projected corners match up with the observed corners. Toward this end, OpenCV provides a convenient routine to handle this common task. The function cv::drawChessboardCorners() draws the corners found by cv::findChessboardCorners() onto an image that you provide. If not all of the corners were found, then the available corners will be represented as small red circles. If the entire pattern was found, then the corners will be painted into different colors (each row will have its own color) and connected by lines representing the identified corner order.
void cv::drawChessboardCorners( cv::InputOutputArray image, // Input/output chessboard image, 8UC3 cv::Size patternSize, // Corners per row, and per column cv::InputArray corners, // corners from findChessboardCorners() bool patternWasFound // Returned from findChessboardCorners() );
The first argument to cv::drawChessboardCorners() is the image to which the drawing will be done. Because the corners will be represented as colored circles, this must be an 8-bit color image. In most cases, this will be a copy of the image you gave to cv::findChessboardCorners() (but you must convert it to a three-channel image yourself, if it wasn’t already). The next two arguments, patternSize and corners, are the same as the corresponding arguments for cv::findChessboardCorners(). Finally, the argument patternWasFound indicates whether the entire chessboard pattern was successfully found; this can be set to the return value from cv::findChessboardCorners(). Figure 18-14 shows the result of applying cv::drawChessboardCorners() to a chessboard image.
We now turn to what a planar object such as the calibration board can do for us. Points on a plane undergo a perspective transformation when viewed through a pinhole or lens. The parameters for this transform are contained in a 3 × 3 homography matrix, which we will describe shortly, after a brief discussion of an alternative pattern to square grids.

Figure 18-14. Result of cv::drawChessboardCorners(); once you find the corners using cv::findChessboardCorners(), you can project where these corners were found (small circles on corners) and in what order they belong (as indicated by the lines between circles)
Circle-grids and cv::findCirclesGrid()
An alternative to the chessboard is the circle-grid. Conceptually, the circle-grid is similar to the chessboard, except that rather than an array of alternating black and white squares, the board contains an array of black circles on a white background.
Calibration with a circle-grid proceeds exactly the same as with cv::findChessboardCorners() and the chessboard, except that a different function is called and a different calibration image is used. That different function is cv::findCirclesGrid(), and it has the following prototype:
bool cv::findCirclesGrid(// Return true if corners were found
cv::InputArray image, // Input chessboard image, 8UC1 or 8UC3
cv::Size patternSize, // corners per row, and per column
cv::OutputArray centers, // Output array of detected circle centers
int flags = cv::CALIB_CB_SYMMETRIC_GRID,
const cv::Ptr<cv::FeatureDetector>& blobDetector
= new SimpleBlobDetector()
);
Like cv::findChessboardCorners(), it takes an image and a cv::Size object defining the number (and arrangement) of the circle pattern. It outputs the location of the centers, which are equivalent to the corners in the chessboard.
The flags argument tells the function what sort of array the circles are arranged into. By default, cv::findCirclesGrid() expects a symmetric grid of circles. A “symmetric” grid is a grid in which the circles are arranged neatly into rows and columns in the same way as the chessboard corners. The alternative is an asymmetric grid. We use the asymmetric grid by setting the flags argument to cv::CALIB_CB_ASYMMETRIC_GRID. In an “asymmetric” grid, the circles in each row are staggered transverse to the row. (The grid shown in Figure 18-15 is an example of an asymmetric grid.)

Figure 18-15. With the regular array of circles (upper left), the centers of the circles function analogously to the corners of the chessboard for calibration. When seen in perspective (lower right), the deformation of the circles is regular and predictable
When you are using an asymmetric grid, it is important to remember how rows and columns are counted. By way of example, in the case shown in Figure 18-15, because it is the rows that are “staggered,” then the array shown has only 4 rows, and 11 columns. The final option for flags is cv::CALIB_CB_CLUSTERING. It can be set along with cv::CALIB_CB_SYMMETRIC_GRID or cv::CALIB_CB_ASYMMETRIC_GRID with the logical OR operator. If this option is selected, then cv::findCirclesGrid() will use a slightly different algorithm for finding the circles. This alternate algorithm is more robust to perspective distortions, but (as a result) is also a lot more sensitive to background clutter. This is a good choice when you are trying to calibrate a camera with an unusually wide field of view.
Note
In general, one often finds the asymmetric circle-grid to be superior to the chessboard, both in terms of the quality of final results, as well as the stability of those results between multiple runs. For these reasons, asymmetric circle-grids increasingly became part of the standard toolkit for camera calibration. In very modern times, patterns such as ChArUco (see the contrib experimental code section of the library) are gaining significant traction as well.
Homography
In computer vision, we define planar homography as a projective mapping from one plane to another.27 Thus, the mapping of points on a two-dimensional planar surface to the imager of our camera is an example of planar homography. It is possible to express this mapping in terms of matrix multiplication if we use homogeneous coordinates to express both the viewed point ![]() and the point
and the point ![]() on the imager to which
on the imager to which ![]() is mapped. If we define:
is mapped. If we define:

then we can express the action of the homography simply as:

Here we have introduced the parameter s, which is an arbitrary scale factor (intended to make explicit that the homography is defined only up to that factor). It is conventionally factored out of H, and we’ll stick with that convention here.
With a little geometry and some matrix algebra, we can solve for this transformation matrix. The most important observation is that H has two parts: the physical transformation, which essentially locates the object plane we are viewing, and the projection, which introduces the camera intrinsics matrix. See Figure 18-16.

Figure 18-16. View of a planar object as described by homography: a mapping—from the object plane to the image plane—that simultaneously comprehends the relative locations of those two planes as well as the camera projection matrix
The physical transformation part is the sum of the effects of some rotation R and some translation ![]() that relate the plane we are viewing to the image plane. Because we are working in homogeneous coordinates, we can combine these within a single matrix as follows:28
that relate the plane we are viewing to the image plane. Because we are working in homogeneous coordinates, we can combine these within a single matrix as follows:28

Then, the action of the camera matrix M, which we already know how to express in projective coordinates, is multiplied by ![]() , which yields:
, which yields:

where:

It would seem that we are done. However, it turns out that in practice our interest is not the coordinate ![]() that is defined for all of space, but rather a coordinate
that is defined for all of space, but rather a coordinate ![]() that is defined only on the plane we are looking at. This allows for a slight simplification.
that is defined only on the plane we are looking at. This allows for a slight simplification.
Without loss of generality, we can choose to define the object plane so that Z = 0. We do this because, if we also break up the rotation matrix into three 3 × 1 columns (i.e., ![]() ), then one of those columns is no longer needed. In particular:
), then one of those columns is no longer needed. In particular:

The homography matrix H that maps a planar object’s points onto the imager is then described completely by ![]() , where:
, where:

Observe that H is now a 3 × 3 matrix.29
OpenCV uses the preceding equations to compute the homography matrix. It uses multiple images of the same object to compute both the individual translations and rotations for each view as well as the intrinsics (which are the same for all views). As we have discussed, rotation is described by three angles and translation is defined by three offsets; hence there are six unknowns for each view. This is OK, because a known planar object (such as our chessboard) gives us eight equations—that is, the mapping of a square into a quadrilateral can be described by four (x, y) points. Each new frame gives us eight equations at the cost of six new extrinsic unknowns, so given enough images we should be able to compute any number of intrinsic unknowns (more on this shortly).
The homography matrix H relates the positions of the points on a source image plane to the points on the destination image plane (usually the imager plane) by the following simple equations:

Notice that we can compute H without knowing anything about the camera intrinsics. In fact, computing multiple homographies from multiple views is the method OpenCV uses to solve for the camera intrinsics, as we’ll see.
OpenCV provides us with a handy function, cv::findHomography(), that takes a list of correspondences and returns the homography matrix that best describes those correspondences. We need a minimum of four points to solve for H, but we can supply many more if we have them30 (as we will with any chessboard bigger than 3 × 3). Using more points is beneficial, because invariably there will be noise and other inconsistencies whose effect we would like to minimize:
cv::Mat cv::findHomography( cv::InputArray srcPoints, // Input array source points (2-d) cv::InputArray dstPoints, // Input array result points (2-d) cv::int method = 0, // 0, cv::RANSAC, cv::LMEDS, etc. double ransacReprojThreshold = 3, // Max reprojection error cv::OutputArray mask = cv::noArray() // use only non-zero pts );
The input arrays srcPoints and dstPoints contain the points in the original plane and the target plane, respectively. These are all two-dimensional points, so they must be N × 2 arrays, N × 1 arrays of CV_32FC2 elements, or STL vectors of cv::Point2f objects (or any combination of these).
The input called method determines the algorithm that will be used to compute the homography. If left as the default value of 0, all of the points will be considered and the computed result will be the one that minimizes the reprojection error. In this case, the reprojection error is the sum of squared Euclidean distances between H times the “original” points and the target points.
Conveniently, fast algorithms exist to solve such problems in the case of an error metric of this kind. Unfortunately, however, defining the error in this way leads to a system in which outliers—individual data points that seem to imply a radically different solution than the majority—tend to have a drastic effect on the solution. In practical cases such as camera calibration, it is common that measurement errors will produce outliers, and the resulting solution will often be very far from the correct answer because of these outliers. OpenCV provides three robust fitting methods that can be used as an alternative, and tend to give much better behavior in the presence of noise.
The first such option, which we select by setting method to cv::RANSAC, is the RANSAC method (also known as the “random sampling with consensus” method). In the RANSAC method, subsets of the provided points are selected at random, and a homography matrix is computed for just that subset. It is then refined by all of the remaining data points that are roughly consistent with that initial estimation. The “inliers” are those that are consistent, while the “outliers” are those that are not. The RANSAC algorithm computes many such random samplings, and keeps the one that has the largest portion of inliers. This method is extremely efficient in practice for rejecting noisy outlier data and finding the correct answer.
The second alternative is the LMeDS algorithm (also known as the “least median of squares” algorithm). As the name suggests, the idea behind LMeDS is to minimize the median error, as opposed to what is essentially the mean squared error minimized by the default method.31
The advantage of LMeDS is that it does not need any further information or parameters to run. The disadvantage is that it will perform well only if the inliers constitute at least a majority of the data points. In contrast, RANSAC can function correctly and give a satisfactory answer given almost any signal-to-noise ratio. The cost of this, however, is that you will have to tell RANSAC what constitutes “roughly consistent”—the maximum distance reprojected points can be from its source and still be considered worth including in the refined model. If you are using the cv::RANSAC method, then the input ransacReprojThreshold controls this distance. If you are using any other method, this parameter can be ignored.
Note
The value of ransacReprojThreshold is measured in pixels. For most practical cases, it is sufficient to set it to a small integer value (i.e., less than 10) but, as is often the case, this number must be increased for very high-resolution images.
Finally, there is RHO algorithm, introduced in [Bazargani15] and available in OpenCV 3, which is based on a “weighted” RANSAC modification called PROSAC and runs faster in the case of many outliers.
The final argument, mask, is used only with the robust methods, and it is an output. If an array is provided, cv::findHomography() will fill that array indicating which points were actually used in the best computation of H.
The return value will be a 3 × 3 matrix. Because there are only eight free parameters in the homography matrix, we chose a normalization where H33 = 1 (which is usually possible except for the quite rare singular case H33 = 0). Scaling the homography could be applied to the ninth homography parameter, but usually prefer to instead scale by multiplying the entire homography matrix by a scale factor, as described earlier in this chapter.
Camera Calibration
We finally arrive at camera calibration for camera intrinsics and distortion parameters. In this section, we’ll explain how to compute these values using cv::calibrateCamera() and also how to use these models to correct distortions in the images that the calibrated camera would have otherwise produced. First we will say a little more about just how many views of a chessboard are necessary in order to solve for the intrinsics and distortion. Then we’ll offer a high-level overview of how OpenCV actually solves this system before moving on to the code that makes it all easy to do.
How many chess corners for how many parameters?
To begin, it will prove instructive to review our unknowns; that is, how many parameters are we attempting to solve for through calibration? In the OpenCV case, we have four parameters associated with the camera intrinsic matrix (fx, fy, cx, cy) and five (or more) distortion parameters—the latter consisting of three (or more) radial parameters (k1, k2, k3 [, k4, k5, k6]) and the two tangential (p1, p2).32 The intrinsic parameters control the linear projective transform that relates a physical object to the produced image. As a result, they are entangled with the extrinsic parameters, which tell us where that object is actually located.
The distortion parameters are tied to the two-dimensional geometry of how a pattern of points gets distorted in the final image. In principle, then, it would seem that just three corner points in a known pattern, yielding six pieces of information, might be all that is needed to solve for our five distortion parameters. Thus a single view of our calibration chessboard could be enough.
However, because of the coupling between the intrinsic parameters and the extrinsic parameters, it turns out that one will not be enough. To understand this, first note that the extrinsic parameters include three rotation parameters ![]() and three translation parameters (Tx, Ty, Tz) for a total of six per view of the chessboard. Together, the four parameters of the camera intrinsic matrix and six extrinsic parameters make 10 altogether that we must solve for, in the case of a single view, and 6 more for each additional view.
and three translation parameters (Tx, Ty, Tz) for a total of six per view of the chessboard. Together, the four parameters of the camera intrinsic matrix and six extrinsic parameters make 10 altogether that we must solve for, in the case of a single view, and 6 more for each additional view.
Let’s say we have N corners and K images of the chessboard (in different positions). How many views and corners must we see so that there will be enough constraints to solve for all these parameters?
-
K images of the chessboard provide 2 · N · K constraints (the factor of 2 arises because each point on the image has both an x- and a y-coordinate).
-
Ignoring the distortion parameters for the moment, we have 4 intrinsic parameters and 6 · K extrinsic parameters (since we need to find the 6 parameters of the chessboard location in each of the K views).
-
Solving then requires that we have: 2 · N · K ≥ 6 · K + 4 (or, equivalently, (N – 3) · K ≥ 2).
So it would seem that if N = 5, then we need only K = 1 image, but watch out! For us, K (the number of images) must be more than 1. The reason for requiring K > 1 is that we are using chessboards for calibration to fit a homography matrix for each of the K views. As discussed previously, a homography can yield at most eight parameters from four (x, y) pairs. This is because only four points are needed to express everything that a planar perspective view can do: it can stretch a square in four different directions at once, turning it into any quadrilateral (see the perspective images in Chapter 11). So, no matter how many corners we detect on a plane, we only get four corners’ worth of information. Per chessboard view, then, the equation can give us only four corners of information or (4 – 3) · K > 1, which means K > 1. This implies that two views of a 3 × 3 chessboard (counting only internal corners) are the minimum that could solve our calibration problem. Consideration for noise and numerical stability is typically what requires the collection of more images of a larger chessboard. In practice, for high-quality results, you’ll need at least 10 images of a 7 × 8 or larger chessboard (and that’s only if you move the chessboard enough between images to obtain a “rich” set of views).
This disparity between the theoretically minimal 2 images and the practically required 10 or more views is a result of the very high degree of sensitivity that the intrinsic parameters have on even very small noise.
What’s under the hood?
This subsection is for those who want to go deeper; it can be safely skipped if you just want to call the calibration functions.
If you’re still with us, the question remains: how does the actual mathematics work for calibration? Although there are many ways to solve for the camera parameters, OpenCV chose one that works well on planar objects. The algorithm OpenCV uses to solve for the focal lengths and offsets is based on Zhang’s method [Zhang00], but OpenCV uses a different method based on Brown [Brown71] to solve for the distortion parameters.
To get started, we pretend that there is no distortion in the camera while solving for the other calibration parameters. For each view of the chessboard, we collect a homography H, as described previously (i.e., a map from the physical object to the imager). We’ll write H out as column vectors, ![]() , where each h is a 3 × 1 vector. Then, in view of the preceding homography discussion, we can set H equal to the camera intrinsics matrix M multiplied by a combination of the first two rotation matrix columns,
, where each h is a 3 × 1 vector. Then, in view of the preceding homography discussion, we can set H equal to the camera intrinsics matrix M multiplied by a combination of the first two rotation matrix columns, ![]() and
and ![]() , and the translation vector
, and the translation vector ![]() . After we include the scale factor s, this yields:
. After we include the scale factor s, this yields:

Reading off these equations, we have:



with:

The rotation vectors are orthogonal to each other by construction, and since the scale is extracted we can take ![]() and
and ![]() to be orthonormal. Orthonormal implies two things: the rotation vector’s dot product is 0, and the vectors’ magnitudes are equal. Starting with the dot product, we have:
to be orthonormal. Orthonormal implies two things: the rotation vector’s dot product is 0, and the vectors’ magnitudes are equal. Starting with the dot product, we have:

For any vectors ![]() and
and ![]() we have
we have ![]() , so we can substitute for
, so we can substitute for ![]() and
and ![]() to derive our first constraint:
to derive our first constraint:

where M–T is shorthand for (M–1)T. We also know that the magnitudes of the rotation vectors are equal:
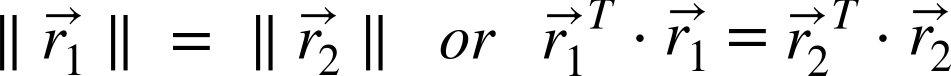
Substituting for ![]() and
and ![]() yields our second constraint:
yields our second constraint:

To make things easier to manage, we define B = M–T · M–1. Writing this out, we have:

It so happens that this matrix B has a general closed-form solution:

Using the B-matrix, both constraints have the general form ![]() in them. Let’s multiply this out to see what the components are. Because B is symmetric, it can be written as one six-dimensional vector dot product. Arranging the necessary elements of B into the new vector
in them. Let’s multiply this out to see what the components are. Because B is symmetric, it can be written as one six-dimensional vector dot product. Arranging the necessary elements of B into the new vector ![]() , we have:
, we have:

Using this definition for ![]() , our two constraints may now be written as:
, our two constraints may now be written as:

If we collect K images of chessboards together, then we can stack K of these equations together:

where V is a 2 · K × 6 matrix. As before, if K ≥ 2 then this equation can be solved for our vector ![]() . The camera intrinsics are then pulled directly out of our closed-form solution for the B-matrix:
. The camera intrinsics are then pulled directly out of our closed-form solution for the B-matrix:



and:

with:

The extrinsics (rotation and translation) are then computed from the equations we read off of the homography condition:



and:

Here the scaling parameter is determined from the orthonormality condition ![]() . Some care is required because, when we solve using real data and put the r-vectors together (
. Some care is required because, when we solve using real data and put the r-vectors together (![]() ), we will not likely end up with an exact rotation matrix for which
), we will not likely end up with an exact rotation matrix for which ![]() holds.33
holds.33
To get around this problem, the usual trick is to take the singular value decomposition (SVD) of R. As discussed in Chapter 5, SVD is a method of factoring a matrix into two orthonormal matrices, U and V, and a middle matrix D of scale values on its diagonal. This allows us to turn R into ![]() . Because R is itself orthonormal, the matrix D must be the identity matrix I3 such that
. Because R is itself orthonormal, the matrix D must be the identity matrix I3 such that ![]() . We can thus “coerce” our computed R into being a rotation matrix by taking R’s singular value decomposition, setting its D matrix to the identity matrix, and multiplying by the SVD again to yield our new, conforming rotation matrix R.
. We can thus “coerce” our computed R into being a rotation matrix by taking R’s singular value decomposition, setting its D matrix to the identity matrix, and multiplying by the SVD again to yield our new, conforming rotation matrix R.
Despite all this work, we have not yet dealt with lens distortions. We use the camera intrinsics found previously—together with the distortion parameters set to 0—for our initial guess to start solving a larger system of equations.
The points we “perceive” on the image are really in the wrong place owing to distortion. Let (xp, yp) be the point’s location if the pinhole camera were perfect and let (xd, yd) be its distorted location; then:

We use the results of the calibration without distortion using the following substitution:34

A large list of these equations are collected and solved to find the distortion parameters, after which the intrinsics and extrinsics are re-estimated. That’s the heavy lifting that the single function cv::calibrateCamera()35 does for you!
Calibration function
Once we have the corners for several images, we can call cv::calibrateCamera(). This routine will do the number crunching and give us the information we want. In particular, the results we receive are the camera intrinsics matrix, the distortion coefficients, the rotation vectors, and the translation vectors. The first two of these constitute the intrinsic parameters of the camera, and the latter two are the extrinsic measurements that tell us where the objects (i.e., the chessboards) were found and what their orientations were. The distortion coefficients (k1, k2, p1, p2, and any higher orders of kj) are the coefficients from the radial and tangential distortion equations we encountered earlier; they help us when we want to correct that distortion away. The camera intrinsic matrix is perhaps the most interesting final result, because it is what allows us to transform from three-dimensional coordinates to the image’s two-dimensional coordinates. We can also use the camera matrix to do the reverse operation, but in this case we can only compute a line in the three-dimensional world to which a given image point must correspond. We will return to this shortly.
Let’s now examine the camera calibration routine itself:
double cv::calibrateCamera(
cv::InputArrayOfArrays objectPoints, // K vecs (N pts each, object frame)
cv::InputArrayOfArrays imagePoints, // K vecs (N pts each, image frame)
cv::Size imageSize, // Size of input images (pixels)
cv::InputOutputArray cameraMatrix, // Resulting 3-by-3 camera matrix
cv::InputOutputArray distCoeffs, // Vector of 4, 5, or 8 coefficients
cv::OutputArrayOfArrays rvecs, // Vector of K rotation vectors
cv::OutputArrayOfArrays tvecs, // Vector of K translation vectors
int flags = 0, // Flags control calibration options
cv::TermCriteria criteria = cv::TermCriteria(
cv::TermCriteria::COUNT | cv::TermCriteria::EPS,
30, // ...after this many iterations
DBL_EPSILON // ...at this total reprojection error
)
);
When calling cv::calibrateCamera(), you have many arguments to keep straight. The good news is that we’ve covered (almost) all of them already, so hopefully they’ll all make sense.
The first argument is objectPoints. It is a vector of vectors, each of which contains the coordinates of the points on the calibration pattern for a particular image. Those coordinates are in the coordinate system of the object, so it is acceptable to make them simply integers in the x- and y-dimensions and zero in the z-dimension.36
The imagePoints argument follows. It is also a vector of vectors, and contains the location of each point as it was found in each image. If you are using the chessboard, each vector will be the corners output array from the corresponding image.
Note
When you are defining the objectPoints input, you are implicitly altering the scale for some of the outputs of cv::calibrateCamera. Specifically, you are affecting the tvecs output. If you say that one corner on the chessboard is at (0, 0, 0), the next is at (0, 1, 0), and the next is at (0, 2, 0), and so on, then you are implicitly saying that you would like the distances measured in “chessboard squares.” If you want physical units for the outputs, you must measure the chessboard in physical units. For example, if you want distances in meters, then you will have to measure your chessboard and use the correct square size in meters. If the squares turn out to be 25mm across, then you should set the same corners to (0, 0, 0), (0, 0.025, 0), (0, 0.050, 0), and so on. In contrast, the camera intrinsic matrix parameters are always reported in pixels.
The imageSize argument just tells cv::calibrateCamera() how large the images were (in pixels) from which the points in imagePoints were extracted.
The camera intrinsics are returned in the cameraMatrix and distCoeffs arrays. The former will contain the linear intrinsics, and should be a 3 × 3 matrix. The latter may be 4, 5, or 8 elements. If distCoeffs is of length 4, then the returned array will contain the coefficients (k1, k2, p1, and p2). If the length is 5 or 8, then the elements will be either (k1, k2, p1, p2, and k3) or (k1, k2, p1, p2, k3, k4, k5, and k6), respectively. The five-element form is primarily for use fisheye lenses, and is generally useful only for them. The eight-element form is run only if you set the cv::CALIB_RATIONAL_MODEL, and is for very high-precision calibration of exotic lenses. It is important to remember, however, that the number of images you require will grow dramatically with the number of parameters you wish to solve for.
The rvecs and tvecs arrays are vectors of vectors, like the input points arrays. They contain a representation of the rotation matrix (in Rodrigues form—that is, as a three-component vector) and the translation matrix for each of the chessboards shown.
Note
Because precision is very important in calibration, the cameraMatrix and distCoeffs arrays (as well as the rvecs and tvecs arrays) will always be computed and returned in double precision, even if you do not initially allocate these input arrays in this form.
Finding parameters through optimization can be something of an art. Sometimes trying to solve for all parameters at once can produce inaccurate or divergent results, especially if your initial starting position in parameter space is far from the actual solution. Thus, it is often better to “sneak up” on the solution by getting close to a good parameter starting position in stages. For this reason, we often hold some parameters fixed, solve for other parameters, then hold the other parameters fixed and solve for the original, and so on. Finally, when we think all of our parameters are close to the actual solution, we use our close parameter setting as the starting point and solve for everything at once. OpenCV allows you this control through the flags setting.
The flags argument allows for some finer control of exactly how the calibration will be performed. The following values may be combined together with a Boolean OR operation as needed:
cv::CALIB_USE_INTRINSIC_GUESS- Normally the intrinsic matrix is computed by
cv::calibrateCamera()with no additional information. In particular, the initial values of the parameters cx and cy (the image center) are taken directly from theimageSizeargument. If this argument is set, thencameraMatrixis assumed to contain valid values that will be used as an initial guess to be further optimized bycv::calibrateCamera(). -
Note
In many practical applications, we know the focal length of a camera because we can read it off the side of the lens.37 In such cases, it is usually a good idea to leverage this information by putting it into the camera matrix and using
cv::CALIB_USE_INTRINSIC_GUESS. In most such cases, it is also safe (and a good idea) to usecv::CALIB_FIX_ASPECT_RATIO, discussed shortly. cv::CALIB_FIX_PRINCIPAL_POINT- This flag can be used with or without
cv::CALIB_USE_INTRINSIC_GUESS. If used without, then the principal point is fixed at the center of the image; if used with, then the principal point is fixed at the supplied initial value in thecameraMatrix. cv::CALIB_FIX_ASPECT_RATIO- If this flag is set, then the optimization procedure will vary only fx and fy together and will keep their ratio fixed to whatever value is set in the
cameraMatrixwhen the calibration routine is called. (If thecv::CALIB_USE_INTRINSIC_GUESSflag is not also set, then the values of fx and fy incameraMatrixcan be any arbitrary values and only their ratio will be considered relevant.) cv::CALIB_FIX_FOCAL_LENGTH- This flag causes the optimization routine to just use the fx and fy that were passed in the
cameraMatrix. cv::CALIB_FIX_K1,cv::CALIB_FIX_K2, ...cv::CALIB_FIX_K6- Fix the radial distortion parameters k1, k2, up through k6. You may set the radial parameters in any combination by adding these flags together.
cv::CALIB_ZERO_TANGENT_DIST- This flag is important for calibrating high-end cameras that, as a result of precision manufacturing, have very little tangential distortion. Trying to fit parameters that are near
0can lead to noisy, spurious values and to problems of numerical stability. Setting this flag turns off fitting the tangential distortion parameters p1 and p2, which are thereby both set to0. cv::CALIB_RATIONAL_MODEL- This flag tells OpenCV to compute the k4, k5, and k6 distortion coefficients. This is here because of a backward compatibility issue; if you do not add this flag, only the first three kj parameters will be computed (even if you gave an eight-element array for
distCoeffs).
The final argument to cv::calibrateCamera() is the termination criteria. As usual, the termination criteria can be a number of iterations, an “epsilon” value, or both. In the case of the epsilon value, what is being computed is called the reprojection error. The reprojection error, as with the case of cv::findHomography(), is the sum of the squares of the distances between the computed (projected) locations of the three-dimensional points onto the image plane and the actual location of the corresponding points on the original image.
Note
It is increasingly common to use asymmetric circle-grids for camera calibration. In this case, it is important to remember that the objectPoints argument must be set accordingly. For example, a possible set of coordinates for the object points in Figure 18-15 would be (0, 0, 0), (1, 1, 0), (2, 1, 0), (3, 1, 0), and so on, with the ones on the next row being (0, 2, 0), (1, 3, 0), (2, 2, 0), (3, 3, 0), and so on through all of the rows.
Computing extrinsics only with cv::solvePnP()
In some cases, you will already have the intrinsic parameters of the camera and therefore need only to compute the location of the object(s) being viewed. This scenario clearly differs from the usual camera calibration, but it is nonetheless a useful task to be able to perform.38 In general, this task is called the Perspective N-Point or PnP problem:
bool cv::solvePnP( cv::InputArray objectPoints, // Object points (object frame) cv::InputArray imagePoints, // Found pt locations (img frame) cv::InputArray cameraMatrix, // 3-by-3 camera matrix cv::InputArray distCoeffs, // Vector of 4, 5, or 8 coeffs cv::OutputArray rvec, // Result rotation vector cv::OutputArray tvec, // Result translation vector bool useExtrinsicGuess = false, // true='use vals in rvec and tvec' int flags = cv::ITERATIVE );
The arguments to cv::solvePnP() are similar to the corresponding arguments for cv::calibrateCamera() with two important exceptions. First, the objectPoints and imagePoints arguments are those from just a single view of the object (i.e., they are of type cv::InputArray, not cv::InputArrayOfArrays). Second, the intrinsic matrix and the distortion coefficients are supplied rather than computed (i.e., they are inputs instead of outputs). The resulting rotation output is again in the Rodrigues form: three-component rotation vector that represents the three-dimensional axis around which the chessboard or points were rotated, with the vector magnitude or length representing the counterclockwise angle of rotation. This rotation vector can be converted into the 3 × 3 rotation matrix we’ve discussed before via the cv::Rodrigues() function. The translation vector is the offset in camera coordinates to where the chessboard origin is located.
The useExtrinsicGuess argument can be set to true to indicate that the current values in the rvec and tvec arguments should be considered as initial guesses for the solver. The default is false.
The final argument, flags, can be set to one of three values—cv::ITERATIVE, cv::P3P, or cv::EPNP—to indicate which method should be used for solving the overall system. In the case of cv::ITERATIVE, a Levenberg-Marquardt optimization is used to minimize reprojection error between the input imagePoints and the projected values of objectPoints. In the case of cv::P3P, the method used is based on [Gao03]. In this case, exactly four object and four image points should be provided. The return value for cv::SolvePNP will be true only if the method succeeds. Finally, in the case of cv::EPNP, the method described in [Moreno-Noguer07] will be used. Note that neither of the latter two methods is iterative and, as a result, should be much faster than cv::ITERATIVE.
Note
Though we introduced cv::solvePnP() as a way to compute the pose of an object (e.g., the chessboard) in each of many frames relative to which the camera is imagined to be stationary, the same function can be used to solve what is effectively the inverse problem. In the case of, for example, a mobile robot, we are more interested in the case of a stationary object (maybe a fixed object, maybe just the entire scene) and a moving camera. In this case, you can still use cv::solvePnP(); the only difference is in how you interpret the resulting rvec and tvec vectors.
Computing extrinsics only with cv::solvePnPRansac()
One shortcoming with cv::solvePnP is that it is not robust to outliers. In camera calibration, this is not as much of a problem, mainly because the chessboard itself gives us a reliable way to find the individual features we care about and to verify that we are looking at what we think we are looking at through their relative geometry. However, in cases in which we are trying to localize the camera relative to points not on a chessboard, but in the real world (e.g., using sparse keypoint features), mismatches are likely and will cause severe problems. Recall from our discussion in “Homography” that the RANSAC method can be an effective way to handle outliers of this kind:
bool cv::solvePnPRansac( cv::InputArray objectPoints, // Object points (object frame) cv::InputArray imagePoints, // Found pt locations (img frame) cv::InputArray cameraMatrix, // 3-by-3 camera matrix cv::InputArray distCoeffs, // Vector of 4, 5, or 8 coeffs cv::OutputArray rvec, // Result rotation vector cv::OutputArray tvec, // Result translation vector bool useExtrinsicGuess = false, // read vals in rvec and tvec ? int iterationsCount = 100, // RANSAC iterations float reprojectionError = 8.0, // Max error for inclusion int minInliersCount = 100, // terminate if this many found cv::OutputArray inliers = cv::noArray(), // Contains inlier indices int flags = cv::ITERATIVE // same as solvePnP() )
All of the arguments for cv::solvePnP() that are shared by cv::solvePnPRansac() have the same interpretation. The new arguments control the RANSAC portion of the algorithm. In particular, the iterationsCount argument sets the number of RANSAC iterations and the reprojectionError argument indicates the maximum reprojection error that will still cause a configuration to be considered an inlier.39 The argument minInliersCount is somewhat misleadingly named; if at any point in the RANSAC process the number of inliers exceeds minInliersCount, the process is terminated, and this group is taken to be the inlier group. This can improve performance substantially, but can also cause a lot of problems if set too low. Finally, the inliers argument is an output that, if provided, will be filled with the indices of the points (from objectPoints and imagePoints) selected as inliers.
Undistortion
As we have alluded to already, there are two things that one often wants to do with a calibrated camera: correct for distortion effects and construct three-dimensional representations of the images it receives. Let’s take a moment to look at the first of these before diving into the more complicated second task in the next chapter.
OpenCV provides us with a ready-to-use undistortion algorithm that takes a raw image and the distortion coefficients from cv::calibrateCamera() and produces a corrected image (Figure 18-17). We can access this algorithm either through the function cv::undistort(), which does everything we need in one shot, or through the pair of routines cv::initUndistortRectifyMap() and cv::remap(), which allow us to handle things a little more efficiently for video or other situations where we have many images from the same camera.40

Figure 18-17. Camera image before undistortion (left) and after (right)
Undistortion Maps
When performing undistortion on an image, we must specify where every pixel in the input image is to be moved in the output image. Such a specification is called an undistortion map (or sometimes just a distortion map). There are several representations available for such maps.
The first and most straightforward representation is the two-channel float representation. In this representation, a remapping for an N × M image is represented by an N × M array of two-channel floating-point numbers as shown in Figure 18-18. For any given entry (i, j) in the image, the value of that entry will be a pair of numbers (i*, j*) indicating the location to which pixel (i, j) of the input image should be relocated. Of course, because (i*, j*) are floating-point numbers, interpolation in the target image is implied.41

Figure 18-18. In the float-float representation, two different floating-point arrays, the X-map and the Y-map, encode the destination of a pixel at (i, j) in the original image. A pixel at (i, j) is mapped to (x_map(i, j), y_map(i, j)) in the destination image. Because that destination is not necessarily integer, the interpolation is used to compute the final image pixel intensities
The next representation is the two-array float representation. In this representation, the remapping is described by a pair of N × M arrays, each of which is a single-channel floating-point array. The first of these arrays contains at location (i, j) the value i*, the x-coordinate of the remapped location of pixel (i, j) from the original array. Similarly, the second array contains at the same location j*, the y-coordinate of the remapped location of pixel (i, j).
The final representation is the fixed-point representation. In this representation, a mapping is specified by a two-channel signed integer array (i.e., of type CV_16SC2). The interpretation of this array is the same as the two-channel float representation, but operations with this format are much faster. In the case in which higher precision is required, the necessary information required for interpolation during the remapping is encoded in a second single-channel unsigned integer array (i.e., CV_16UC1). The entries in this array refer to an internal lookup table, which is used for the interpolation (and thus there are no “user-serviceable parts” in this array).
Converting Undistortion Maps Between Representations with cv::convertMaps()
Because there are multiple representations available for undistortion maps, it is natural that one might want to convert between them. We do this with the cv::convertMaps() function. This function allows you to provide a map in any of the four formats we just discussed, and convert it into any of the others. The prototype for cv::convertMaps() is the following:
void cv::convertMaps( cv::InputArray map1, // First in map: CV_16SC2/CV_32FC1/CV_32FC2 cv::InputArray map2, // Second in map: CV_16UC1/CV_32FC1 or none cv::OutputArray dstmap1, // First out map cv::OutputArray dstmap2, // Second out map int dstmap1type, // dstmap1 type: CV_16SC2/CV_32FC1/CV_32FC2 bool nninterpolation = false // For conversion to fixed point types );
The inputs map1 and map2 are your existing maps, and the outputs dstmap1 and dstmap2 are the outputs where the converted maps will be stored. The argument dstmap1type tells cv::convertMaps() what sort of maps to create for you; from the type specified here, the remapping you want is then inferred. You use the final argument, nninterpolation, when converting to the fixed point type to indicate whether you would like the interpolation tables to be computed as well. The possible conversions are shown in Table 18-1, along with the correct settings for dstmap1type and nninterpolation for each conversion.
| map1 | map2 | dstmap1type | nninterpolation | dstmap1 | dstmap2 |
|---|---|---|---|---|---|
CV_32FC1 |
CV_32FC1 |
CV_16SC2 |
true |
CV_16SC2 |
CV_16UC1 |
CV_32FC1 |
CV_32FC1 |
CV_16SC2 |
false |
CV_16SC2 |
cv::noArray() |
CV_32FC2 |
cv::noArray() |
CV_16SC2 |
true |
CV_16SC2 |
CV_16UC1 |
CV_32FC2 |
cv::noArray() |
CV_16SC2 |
false |
CV_16SC2 |
cv::noArray() |
CV_16SC2 |
CV_16UC1 |
CV_32FC1 |
true |
CV_32FC1 |
CV_32FC1 |
CV_16SC2 |
cv::noArray() |
CV_32FC1 |
false |
CV_32FC1 |
CV_32FC1 |
CV_16SC2 |
CV_16UC1 |
CV_32FC2 |
true |
CV_32FC2 |
cv::noArray() |
CV_16SC2 |
cv::noArray() |
CV_32FC2 |
false |
CV_32FC2 |
cv::noArray() |
Note that, because the conversion from floating point to fixed point naturally loses precision (even if nninterpolation is used), if you convert one way and then convert back again, you should not expect to necessarily receive back exactly what you started with.
Computing Undistortion Maps with cv::initUndistortRectifyMap()
Now that we understand undistortion maps, the next step is to see how to compute them from camera parameters. In fact, distortion maps are much more general than just this one specific situation, but for our current purpose, the interesting thing is to know how we can use the results of our camera calibrations to create nicely rectified images. So far, we have been discussing the situation of monocular imaging. In fact, one of the more important applications of rectification is in preparing a pair of images to be used for stereoscopic computation of depth images. We will get back to the topic of stereo in the next chapter, but it is worth keeping this application in mind, partially because some of the arguments to the functions that do undistortion are primarily for use in that stereo vision context.
The basic process is to first compute the undistortion maps, and then to apply them to the image. The reason for this separation is that, in most practical applications, you will compute the undistortion maps for your camera only once, and then you will use those maps again and again as new images come streaming in from your camera. The function cv::initUndistortRectifyMap() computes the distortion map from camera-calibration information:
void cv::initUndistortRectifyMap( cv::InputArray cameraMatrix, // 3-by-3 camera matrix cv::InputArray distCoeffs, // Vector of 4, 5, or 8 coefficients cv::InputArray R, // Rectification transformation cv::InputArray newCameraMatrix, // New camera matrix (3-by-3) cv::Size size, // Undistorted image size int m1type, // 'map1' type: 16SC2, 32FC1, or 32FC2 cv::OutputArray map1, // First output map cv::OutputArray map2, // Second output map );
The function cv::initUndistortRectifyMap() computes the undistortion map (or maps). The first two arguments are the camera intrinsic matrix and the distortion coefficients, both in the form you received them from cv::calibrateCamera().
The next argument, R, may be used or, alternatively, set to cv::noArray(). If used, it must be a 3 × 3 rotation matrix, which will be preapplied before rectification. The function of this matrix is to compensate for a rotation of the camera relative to some global coordinate system in which that camera is embedded.
Similar to the rotation matrix, newCameraMatrix can be used to affect how the images are undistorted. If used, it will “correct” the image before undistortion to how it would have looked if taken from a different camera with different intrinsic parameters. In practice, the aspect that one changes in this way is the camera center, not the focal length. You will typically not use this when dealing with monocular imaging, but it is important in the case of stereo image analysis. For monocular images, you will typically just set this argument to cv::noArray().
Note
It is unlikely that you will use the rotation or newCameraMatrix arguments unless you are dealing with stereo images. In that case, the correct arrays to give to cv::initUndistortRectifyMap() will be computed for you by cv::stereoRectify(). After calling cv::stereoRectify(), you will rectify the image from the first camera with the R1 and P1 arrays, and the image from the second camera with the R2 and P2 arrays. We will revisit this topic in the next chapter when we discuss stereo imaging.42
The argument size simply sets the size of the output maps; this should correspond to the size of images you will be undistorting.
The final three arguments—m1type, map1, and map2—specify the final map type and provide a place for that map to be written, respectively. The possible values of m1type are CV_32FC1 or CV_16SC2, and correspond to the type that will be used to represent map1. In the case of CV_32FC1, map2 will also be of type CV_32FC1. This corresponds to the two-array float representation of the map we encountered in the previous section. In the case of CV_16SC2, map1 will be in the fixed-point representation (recall that this single-channel array contains the interpolation table coefficients).
Undistorting an Image with cv::remap()
Once you have computed the undistortion maps, you can apply them to incoming images using cv::remap(). We encountered cv::remap() earlier, when discussing general image transforms; this is one specific, but very important, application for that function.
As we saw previously, the cv::remap() function has two map arguments that correspond to the undistortion maps, such as those computed by cv::initUndistortRectifyMap(). cv::remap() will accept any of the distortion map formats we have discussed: the two-channel float, the two-array float, or the fixed-point format (with or without the accompanying array of interpolation table indexes).
Note
If you use the cv::remap() with the two different two-channel float representations, or the fixed-point representation without the interpolation table array, you should just pass cv::noArray() for the map2 argument.
Undistortion with cv::undistort()
In some cases, you will either have only one image to rectify, or need to recompute the undistortion maps for every image. In such cases, you can use the somewhat more compact cv::undistort(), which effectively computes the maps and applies them in a single go.
void cv::undistort( cv::InputArray src, // Input distorted image cv::OutputArray dst, // Result corrected image cv::InputArray cameraMatrix, // 3-by-3 camera matrix cv::InputArray distCoeffs, // Vector of 4, 5, or 8 coeffs cv::InputArray newCameraMatrix = noArray() // Optional new camera matrix );
The arguments to cv::undistort() are identical to the corresponding arguments to cv::initUndistortRectifyMap().
Sparse Undistortion with cv::undistortPoints()
Another situation that arises occasionally is that, rather than rectifying an entire image, you have a set of points you have collected from an image, and you care only about the location of those points. In this case, you can use cv::undistortPoints() to compute the “correct” locations for your specific list of points:
void cv::undistortPoints(
cv::InputArray src, // Input array, N pts. (2-d)
cv::OutputArray dst, // Result array, N pts. (2-d)
cv::InputArray cameraMatrix, // 3-by-3 camera matrix
cv::InputArray distCoeffs, // Vector of 4, 5, or 8 coeffs
cv::InputArray R = cv::noArray(), // 3-by-3 rectification mtx.
cv::InputArray P = cv::noArray() // 3-by-3 or 3-by-4 new camera
// or new projection matrix
);
As with cv::undistort(), the arguments to cv::undistortPoints() are analogous to the corresponding arguments to cv::initUndistortRectifyMap(). The primary difference is that the src and dst arguments are vectors of two-dimensional points, rather than two-dimensional arrays. (As always, these vectors can be of any of the usual forms: N × 1 array of cv::Vec2i objects, N × 1 array of float objects, an STL-style vector of cv::Vec2f objects, etc.)
The argument P of cv::undistortPoints() corresponds to newCameraMatrix of cv::undistortPoints(). As before, these two extra parameters relate primarily to the function’s use in stereo rectification, which we will discuss in Chapter 19. The rectified camera matrix P can have dimensions of 3 × 3 or 3 × 4 deriving from the first three or four columns of cv::stereoRectify()’s return value for camera matrices P1 or P2 (for the left or right camera; see Chapter 19). These parameters are by default cv::noArray(), which the function interprets as identity matrices.
Putting Calibration All Together
Now it’s time to put all of this together in an example. Example 18-1 presents a program that performs the following tasks: it looks for chessboards of the dimensions that the user specified, grabs as many full images (i.e., those in which it can find all the chessboard corners) as the user requested, and computes the camera intrinsics and distortion parameters. Finally, the program enters a display mode whereby an undistorted version of the camera image can be viewed.
Note
When using this program, you’ll want to substantially change the chessboard views between successful captures. Otherwise, the matrices of points used to solve for calibration parameters may form an ill-conditioned (rank-deficient) matrix and you will end up with either a bad solution or no solution at all.
Example 18-1. Reading a chessboard’s width and height, reading and collecting the requested number of views, and calibrating the camera
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
void help( char *argv[] ) {
...
}
int main(int argc, char* argv[]) {
int n_boards = 0; // Will be set by input list
float image_sf = 0.5f;
float delay = 1.f;
int board_w = 0;
int board_h = 0;
if(argc < 4 || argc > 6) {
cout << "
ERROR: Wrong number of input parameters";
help( argv );
return -1;
}
board_w = atoi( argv[1] );
board_h = atoi( argv[2] );
n_boards = atoi( argv[3] );
if( argc > 4 ) delay = atof( argv[4] );
if( argc > 5 ) image_sf = atof( argv[5] );
int board_n = board_w * board_h;
cv::Size board_sz = cv::Size( board_w, board_h );
cv::VideoCapture capture(0);
if( !capture.isOpened() ) {
cout << "
Couldn't open the camera
";
help( argv );
return -1;
}
// ALLOCATE STORAGE
//
vector< vector<cv::Point2f> > image_points;
vector< vector<cv::Point3f> > object_points;
// Capture corner views: loop until we've got n_boards successful
// captures (all corners on the board are found).
//
double last_captured_timestamp = 0;
cv::Size image_size;
while( image_points.size() < (size_t)n_boards ) {
cv::Mat image0, image;
capture >> image0;
image_size = image0.size();
cv::resize(image0, image, cv::Size(), image_sf, image_sf, cv::INTER_LINEAR );
// Find the board
//
vector<cv::Point2f> corners;
bool found = cv::findChessboardCorners( image, board_sz, corners );
// Draw it
//
drawChessboardCorners( image, board_sz, corners, found );
// If we got a good board, add it to our data
//
double timestamp = (double)clock()/CLOCKS_PER_SEC;
if( found && timestamp - last_captured_timestamp > 1 ) {
last_captured_timestamp = timestamp;
image ^= cv::Scalar::all(255);
cv::Mat mcorners(corners); // do not copy the data
mcorners *= (1./image_sf); // scale the corner coordinates
image_points.push_back(corners);
object_points.push_back(vector<Point3f>());
vector<cv::Point3f>& opts = object_points.back();
opts.resize(board_n);
for( int j=0; j<board_n; j++ ) {
opts[j] = cv::Point3f((float)(j/board_w), (float)(j%board_w), 0.f);
}
cout << "Collected our " << (int)image_points.size() <<
" of " << n_boards << " needed chessboard images
" << endl;
}
cv::imshow( "Calibration", image ); //show in color if we did collect the image
if((cv::waitKey(30) & 255) == 27)
return -1;
}
// END COLLECTION WHILE LOOP.
cv::destroyWindow( "Calibration" );
cout << "
*** CALIBRATING THE CAMERA...
" << endl;
// CALIBRATE THE CAMERA!
//
cv::Mat intrinsic_matrix, distortion_coeffs;
double err = cv::calibrateCamera(
object_points,
image_points,
image_size,
intrinsic_matrix,
distortion_coeffs,
cv::noArray(),
cv::noArray(),
cv::CALIB_ZERO_TANGENT_DIST | cv::CALIB_FIX_PRINCIPAL_POINT
);
// SAVE THE INTRINSICS AND DISTORTIONS
cout << " *** DONE!
Reprojection error is " << err <<
"
Storing Intrinsics.xml and Distortions.xml files
";
cv::FileStorage fs( "intrinsics.xml", FileStorage::WRITE );
fs << "image_width" << image_size.width << "image_height" << image_size.height
<<"camera_matrix" << intrinsic_matrix << "distortion_coefficients"
<< distortion_coeffs;
fs.release();
// EXAMPLE OF LOADING THESE MATRICES BACK IN:
fs.open( "intrinsics.xml", cv::FileStorage::READ );
cout << "
image width: " << (int)fs["image_width"];
cout << "
image height: " << (int)fs["image_height"];
cv::Mat intrinsic_matrix_loaded, distortion_coeffs_loaded;
fs["camera_matrix"] >> intrinsic_matrix_loaded;
fs["distortion_coefficients"] >> distortion_coeffs_loaded;
cout << "
intrinsic matrix:" << intrinsic_matrix_loaded;
cout << "
distortion coefficients: " << distortion_coeffs_loaded << endl;
// Build the undistort map which we will use for all
// subsequent frames.
//
cv::Mat map1, map2;
cv::initUndistortRectifyMap(
intrinsic_matrix_loaded,
distortion_coeffs_loaded,
cv::Mat(),
intrinsic_matrix_loaded,
image_size,
CV_16SC2,
map1,
map2
);
// Just run the camera to the screen, now showing the raw and
// the undistorted image.
//
for(;;) {
cv::Mat image, image0;
capture >> image0;
if( image0.empty() ) break;
cv::remap(
image0,
image,
map1,
map2,
cv::INTER_LINEAR,
cv::BORDER_CONSTANT,
cv::Scalar()
);
cv::imshow("Undistorted", image);
if((cv::waitKey(30) & 255) == 27) break;
}
return 0;
}
Summary
We began the chapter with a brief review of the pinhole camera model and an overview of the basics of projective geometry. After introducing the Rodrigues transform as an alternate representation of rotations, we introduced the concept of lens distortions and learned how they are modeled in OpenCV and that this model is summarized by the camera intrinsics matrix.
With this model in hand, we proceeded to learn how to calibrate a camera using chessboards or circle-grids (and that there are yet other calibration patterns and techniques, referenced in Appendix B, in the ccalib function group). We saw how we could have OpenCV compute these intrinsic and extrinsic parameters for us using the results of intersection or circle finding from many calibration images. The calibration function led us to the topic of image homography. We learned the difference between intrinsic and extrinsic parameters in calibration, and related those extrinsics to the general “PnP” pose estimation problem. We saw finally how to undistort images by making use of the computed intrinsic parameters of a camera to correct away common distortions that arise from real-world lenses.
We finished off with a complete example in which images were captured, calibration data was extracted from those images, camera intrinsics were computed from that data, and incoming video was corrected using that camera information.
Exercises
-
If you had only a ruler, how could you determine the focal length of a camera? Assume that the camera has negligible distortion and that the principal point is the center of the image.
-
Use Figure 18-2 to derive the equations x = fx · (X/Z) + cx and y – fy · (Y/Z) + cy using similar triangles with a center-position offset.
-
Will errors in estimating the true center location (cx, cy) affect the estimation of other parameters such as focus?
Hint: See the q = MQ equation.
-
Draw an image of a square:
-
under radial distortion;
-
under tangential distortion; and
-
under both distortions.
-
-
Refer to Figure 18-19. For perspective views, explain the following.
-
Where does the “line at infinity” come from?
-
Why do parallel lines on the object plane converge to a point on the image plane?
-
Assume that the object and image planes are perpendicular to one another. On the object plane, starting at a point p1, move 10 units directly away from the image plane to p2. What is the corresponding movement distance on the image plane?
-
-
Figure 18-3 shows the outward-bulging “barrel distortion” effect of radial distortion, which is especially evident in the left panel of Figure 18-12. Could some lenses generate an inward-bending effect? How would this be possible?
-
Using a cheap web camera or cell phone, take pictures that show examples of radial and tangential distortion using images of concentric squares or chessboards.
-
Calibrate the camera using
cv::calibrateCamera()and at least 15 images of chessboards. Then usecv::projectPoints()to project an arrow orthogonal to the chessboards (the surface normal) into each of the chessboard images using the rotation and translation vectors from the camera calibration. -
Display the distorted pictures before and after undistortion.
-
-
What would happen to your calibration for focal length and principal point if you subsampled the image array by a factor of 2 (skip every other pixel in the x- and y-direction)?
-
Experiment with numerical stability and noise by collecting many images of chessboards and doing a “good” calibration on all of them. Then see how the calibration parameters change as you reduce the number of chessboard images. Graph your results: camera parameters as a function of number of chessboard images.

Figure 18-19. Homography diagram showing intersection of the object plane with the image plane and a viewpoint representing the center of projection
-
High-end cameras typically have systems of lenses that correct physically for distortions in the image. What might happen if you nevertheless use a multiterm distortion model for such a camera?
Hint: This condition is known as overfitting.
-
Three-dimensional joystick trick. Calibrate a camera. Using video, wave a chessboard around and use
cv::solvePnP()as a three-dimensional joystick. Remember thatcv::solvePnP()outputs rotation as a 3 × 1 or 1 × 3 vector axis of rotation, where the magnitude of the vector represents the counterclockwise angle of rotation along with a three-dimensional translation vector.-
Output the chessboard’s axis and angle of the rotation along with where it is (i.e., the translation) in real time as you move the chessboard around. Handle cases where the chessboard is not in view.
-
Use
cv::Rodrigues()to translate the output ofcv::solvePnP()into a 3 × 3 rotation matrix and a translation vector. Use this to animate a simple three-dimensional stick figure of an airplane rendered back into the image in real time as you move the chessboard in view of the video camera.
-
1 Knowledge of lenses goes back at least to Roman times. The pinhole camera model goes back almost 1,000 years to al-Hytham (1021) and is the classic way of introducing the geometric aspects of vision. Mathematical and physical advances followed in the 1600s and 1700s with Descartes, Kepler, Galileo, Newton, Hooke, Euler, Fermat, and Snell (see O’Connor [O’Connor02]). Some key modern texts for geometric vision include those by Trucco [Trucco98], Jaehne (also sometimes spelled Jähne) [Jaehne95; Jaehne97], Hartley and Zisserman [Hartley06], Forsyth and Ponce [Forsyth03], Shapiro and Stockman [Shapiro02], and Xu and Zhang [Xu96].
2 You are probably used to thinking of the focal length in the context of lenses, in which case the focal length is a property of a particular lens, not the projection geometry. This is the result of a common abuse of terminology. It might be better to say that the “projection distance” is the property of the geometry and the “focal length” is the property of the lens. The f in the previous equations is really the projection distance. For a lens, the image is in focus only if the focus length of the configuration matches the focal length of the lens, so people tend to use the terms interchangeably.
3 Typical of such mathematical abstractions, this new arrangement is not one that can be built physically; the image plane is simply a way of thinking of a “slice” through all of those rays that happen to strike the center of projection. This arrangement is, however, much easier to draw and do math with.
4 Here the subscript screen is intended to remind you that the coordinates being computed are in the coordinate system of the screen (i.e., the imager). The difference between (xscreen,yscreen) in the equation and (x,y) in Figure 18-2 is precisely the point of cx and cy. Having said that, we will subsequently drop the “screen” subscript and simply use lowercase letters to describe coordinates on the imager.
5 Of course, millimeter is just a stand-in for any physical unit you like. It could just as easily be meter, micron, or furlong. The point is that sx converts physical units to pixel units.
6 The approach OpenCV takes to camera intrinsics is derived from Heikkila and Silven; see [Heikkila97].
7 There is also a third function, cv::convertPointsHomogeneous(), which is just a convenient way to call either of the former two. It will look at the dimensionality of the points provided in dst and determine automatically whether you want it to convert to or from homogeneous coordinates. This function is now considered obsolete. It is primarily present for backward compatibility. It should not be used in new code, as it substantially reduces code clarity.
8 This “easier” representation is not just for humans. Rotation in three-dimensional space has only three components. For numerical optimization procedures, it is more efficient to deal with the three components of the Rodrigues representation than with the nine components of a 3 × 3 rotation matrix.
9 Rodrigues was a 19th-century French mathematician.
10 The approach to modeling lens distortion taken here derives mostly from Brown [Brown71] and earlier Fryer and Brown [Fryer86].
11 If you don’t know what a Taylor series is, don’t worry too much. The Taylor series is a mathematical technique for expressing a (potentially) complicated function in the form of a polynomial of similar value to the approximated function in at least a small neighborhood of some particular point (the more terms we include in the polynomial series, the more accurate the approximation). In our case we want to expand the distortion function as a polynomial in the neighborhood of r = 0. This polynomial takes the general form f(r) = a0 + a1r + a2r2 + ..., but in our case the fact that f(r) = 0 at r = 0 implies a0 = 0. Similarly, because the function must be symmetric in r, only the coefficients of even powers of r will be nonzero. For these reasons, the only parameters that are necessary for characterizing these radial distortions are the coefficients of r2, r4, and (sometimes) higher even powers of r.
12 Now it’s possible to use much more complex “rational” and “thin prism” models in OpenCV. There is also support for omni (180-degree) cameras, omni stereo, and multicamera calibration. See samples of use in the opencv_contrib/modules/ccalib/samples directory.
13 Some old cameras had nonrectangular sensors. These sensors were actually parallelograms, due to some imperfect manufacturing technology (and some other possible reasons). The camera-intrinsic matrices for such cameras had the form [[fx skew cx] [0 fy cy] [0, 0, 1]]. This is the origin of the “skew” in Figure 18-4. Almost all modern cameras have no skew, so the OpenCV calibration functions assume it is zero and do not compute it.
14 The derivation of these equations is beyond the scope of this book, but the interested reader is referred to the “plumb bob” model; see D. C. Brown, “Decentering Distortion of Lenses,” Photometric Engineering 32, no. 3 (1966): 444–462.
15 For a great online tutorial of camera calibration, see Jean-Yves Bouguet’s calibration website.
16 As these are highly specialized cases, their details are beyond the scope of this book. However, you should find them easily understandable once you are comfortable with the calibration of more common cameras as we describe here.
17 This image was originally contributed to the OpenCV library by Baisheng Lai.
18 Just to be clear: the rotation we are describing here is first around the z-axis, then around the new position of the y-axis, and finally around the new position of the x-axis.
19 The specific use of this calibration object—and much of the calibration approach itself—comes from Zhang [Zhang99; Zhang00] and Sturm [Sturm99].
20 There are also random-pattern calibration pattern generators in the opencv_contrib/modules/ccalib/samples directory. These patterns can be used for multicamera calibration, as seen in the tutorial in that directory.
21 These boards came from Augmented Reality 2D barcodes called ArUco [Garrido-Jurado]. Their advantage is that the whole board does not have to be in view to get labeled corners on which to calibrate. The authors recommend you use the ChArUco pattern. The OpenCV documentation describes how to make and use these patterns (search on “ChArUco”). The code and tutorials are in the opencv_contrib/modules/aruco directory.
22 This image was originally contributed to the OpenCV library by Baisheng Lai.
23 This image was originally contributed to the OpenCV library by Sergio Garrido.
24 This image was originally contributed to the OpenCV library by Sergio Garrido.
25 In practice, it is often more convenient to use a chessboard grid that is asymmetric and of even and odd dimensions—for example, (5, 6). Using such even-odd asymmetry yields a chessboard that has only one symmetry axis, so the board orientation can always be defined uniquely.
26 In this context, ordered means that a model of the found points could be constructed that was consistent with the proposition that they are in fact sets of collinear points on a plane. Obviously not all images containing 49 points, for example, are generated by a regular 7 × 7 grid on a plane.
27 The term homography has different meanings in different sciences; for example, it has a somewhat more general meaning in mathematics. The homographies of greatest interest in computer vision are a subset of the other more general meanings of the term.
28 Here ![]() is a 3 × 4 matrix whose first three columns comprise the nine entries of R and whose last column consists of the three-component vector
is a 3 × 4 matrix whose first three columns comprise the nine entries of R and whose last column consists of the three-component vector ![]() .
.
29 The astute reader will have noticed that we have been a little cavalier with the factor s. The s that appears in this final expression is not identical to those that appear in the previous equations, but rather the product of them. In any case, the product of two arbitrary scale factors is itself an arbitrary scale factor, so no harm is done.
30 Of course, an exact solution is guaranteed only when there are four correspondences. If more are provided, then what’s computed is a solution that is optimal in the sense of least-squares error (possibly also with some points rejected; see the upcoming RANSAC discussion).
31 For more information on robust methods, consult the original papers: Fischler and Bolles [Fischler81] for RANSAC; Rousseeuw [Rousseeuw84] for least median squares; and Inui, Kaneko, and Igarashi [Inui03] for line fitting using LMedS.
32 It is commonplace to refer to the total set of the camera intrinsic matrix parameters and the distortion parameters as simply the intrinsic parameters or the intrinsics. In some cases, the matrix parameters will also be referred to as the linear intrinsic parameters (because they collectively define a linear transformation), while the distortion parameters are referred to as the nonlinear intrinsic parameters.
33 This is mainly due to precision errors.
34 Camera calibration functionality is now very expanded to include fisheye and omni cameras; see the opencv_contrib/modules/ccalib/src and the opencv_contrib/modules/ccalib/samples directories.
35 The cv::calibrateCamera() function is used internally in the stereo calibration functions we will see in Chapter 19. For stereo calibration, we’ll be calibrating two cameras at the same time and will be looking to relate them together through a rotation matrix and a translation vector.
36 In principle, you could use a different object for each calibration image. In practice, the outer vector will typically just contain K copies of the same list of point locations where K is the number of views.
37 This is a slight oversimplification. Recall that the focal lengths that appear in the intrinsics matrix are measured in units of pixels. So if you have a 2,048 × 1,536 pixel imager with a 1/1.8” sensor format, that gives you 3.45μm pixels. If your camera has a 25.0mm focal length lens, then the initial guesses for f are not 25 (mm) but 7,246.38 (pixels) or, if you are realistic about significant digits, just 7,250.
38 In fact, this task is a component of the overall task of camera calibration, and this function is called internally by cv::calibrateCamera().
39 For the PnP problem, what is effectively sought is a perspective transform, which is fully determined by four points. Thus, for a RANSAC iteration, the initial number of selected points is four. The default value of reprojectionError corresponds to an average distance of ![]() between each of these points and its corresponding reprojection.
between each of these points and its corresponding reprojection.
40 We should take a moment to clearly make a distinction here between undistortion, which mathematically removes lens distortion, and rectification, which mathematically aligns the two (or more) images with respect to each other. The latter will be important in the next chapter.
41 As is typically the case, the interpolation is actually performed in the opposite direction. This means that, given the map, we compute a pixel in the final image by determining which pixels in the original image map into its vicinity, and then interpolating between those pixel values appropriately.
42 The exceptionally astute reader may have noticed that the camera-matrix is a 3 × 3 matrix, while the return values from cv::stereoRectify() called P1 and P2 are in fact 3 × 4 projection matrices. Not to worry. In fact, the first three columns of P1 and P2 contain the same information as the camera matrix, and this is the part that is actually used internally by cv::initUndistortRectifyMap().