
Chapter 5. Array Operations
More Things You Can Do with Arrays
As we saw in the previous chapter, there are many basic operations on arrays that are now handled by member functions of the array classes. In addition to those, however, there are many more operations that are most naturally represented as “friend” functions that either take array types as arguments, have array types as return values, or both. The functions, together with their arguments, will be covered in more detail after Table 5-1.
| Function | Description |
|---|---|
cv::abs() |
Return absolute value of all elements in an array |
cv::absdiff() |
Return absolute value of differences between two arrays |
cv::add() |
Perform element-wise addition of two arrays |
cv::addWeighted() |
Perform element-wise weighted addition of two arrays (alpha blending) |
cv::bitwise_and() |
Compute element-wise bit-level AND of two arrays |
cv::bitwise_not() |
Compute element-wise bit-level NOT of two arrays |
cv::bitwise_or() |
Compute element-wise bit-level OR of two arrays |
cv::bitwise_xor() |
Compute element-wise bit-level XOR of two arrays |
cv::calcCovarMatrix() |
Compute covariance of a set of n-dimensional vectors |
cv::cartToPolar() |
Compute angle and magnitude from a two-dimensional vector field |
cv::checkRange() |
Check array for invalid values |
cv::compare() |
Apply selected comparison operator to all elements in two arrays |
cv::completeSymm() |
Symmetrize matrix by copying elements from one half to the other |
cv::convertScaleAbs() |
Scale array, take absolute value, then convert to 8-bit unsigned |
cv::countNonZero() |
Count nonzero elements in an array |
cv::arrToMat() |
Convert pre–version 2.1 array types to cv::Mat |
cv::dct() |
Compute discrete cosine transform of array |
cv::determinant() |
Compute determinant of a square matrix |
cv::dft() |
Compute discrete Fourier transform of array |
cv::divide() |
Perform element-wise division of one array by another |
cv::eigen() |
Compute eigenvalues and eigenvectors of a square matrix |
cv::exp() |
Perform element-wise exponentiation of array |
cv::extractImageCOI() |
Extract single channel from pre–version 2.1 array type |
cv::flip() |
Flip an array about a selected axis |
cv::gemm() |
Perform generalized matrix multiplication |
cv::getConvertElem() |
Get a single-pixel type conversion function |
cv::getConvertScaleElem() |
Get a single-pixel type conversion and scale function |
cv::idct() |
Compute inverse discrete cosine transform of array |
cv::idft() |
Compute inverse discrete Fourier transform of array |
cv::inRange() |
Test if elements of an array are within values of two other arrays |
cv::invert() |
Invert a square matrix |
cv::log() |
Compute element-wise natural log of array |
cv::magnitude() |
Compute magnitudes from a two-dimensional vector field |
cv::LUT() |
Convert array to indices of a lookup table |
cv::Mahalanobis() |
Compute Mahalanobis distance between two vectors |
cv::max() |
Compute element-wise maxima between two arrays |
cv::mean() |
Compute the average of the array elements |
cv::meanStdDev() |
Compute the average and standard deviation of the array elements |
cv::merge() |
Merge several single-channel arrays into one multichannel array |
cv::min() |
Compute element-wise minima between two arrays |
cv::minMaxLoc() |
Find minimum and maximum values in an array |
cv::mixChannels() |
Shuffle channels from input arrays to output arrays |
cv::mulSpectrums() |
Compute element-wise multiplication of two Fourier spectra |
cv::multiply() |
Perform element-wise multiplication of two arrays |
cv::mulTransposed() |
Calculate matrix product of one array |
cv::norm() |
Compute normalized correlations between two arrays |
cv::normalize() |
Normalize elements in an array to some value |
cv::perspectiveTransform() |
Perform perspective matrix transform of a list of vectors |
cv::phase() |
Compute orientations from a two-dimensional vector field |
cv::polarToCart() |
Compute two-dimensional vector field from angles and magnitudes |
cv::pow() |
Raise every element of an array to a given power |
cv::randu() |
Fill a given array with uniformly distributed random numbers |
cv::randn() |
Fill a given array with normally distributed random numbers |
cv::randShuffle() |
Randomly shuffle array elements |
cv::reduce() |
Reduce a two-dimensional array to a vector by a given operation |
cv::repeat() |
Tile the contents of one array into another |
cv::saturate_cast<>() |
Convert primitive types (template function) |
cv::scaleAdd() |
Compute element-wise sum of two arrays with optional scaling of the first |
cv::setIdentity() |
Set all elements of an array to 1 for the diagonal and 0 otherwise |
cv::solve() |
Solve a system of linear equations |
cv::solveCubic() |
Find the (only) real roots of a cubic equation |
cv::solvePoly() |
Find the complex roots of a polynomial equation |
cv::sort() |
Sort elements in either the rows or columns in an array |
cv::sortIdx() |
Serve same purpose as cv::sort(), except array is unmodified and indices are returned |
cv::split() |
Split a multichannel array into multiple single-channel arrays |
cv::sqrt() |
Compute element-wise square root of an array |
cv::subtract() |
Perform element-wise subtraction of one array from another |
cv::sum() |
Sum all elements of an array |
cv::theRNG() |
Return a random number generator |
cv::trace() |
Compute the trace of an array |
cv::transform() |
Apply matrix transformation on every element of an array |
cv::transpose() |
Transpose all elements of an array across the diagonal |
In these functions, some general rules are followed. To the extent that any exceptions exist, they are noted in the function descriptions. Because one or more of these rules applies to just about every function described in this chapter, they are listed here for convenience:
- Saturation
- Outputs of calculations are saturation-casted to the type of the output array.
- Output
- The output array will be created with
cv::Mat::create()if its type and size do not match the required type or size. Usually the required output type and size are the same as inputs, but for some functions size may be different (e.g.,cv::transpose) or type may be different (e.g.,cv::split). - Scalars
- Many functions such as
cv::add()allow for the addition of two arrays or an array and a scalar. Where the prototypes make the option clear, the result of providing a scalar argument is the same as if a second array had been provided with the same scalar value in every element. - Masks
- Whenever a mask argument is present for a function, the output will be computed only for those elements where the mask value corresponding to that element in the output array is nonzero.
dtype- Many arithmetic and similar functions do not require the types of the input arrays to be the same, and even if they are the same, the output array may be of a different type than the inputs. In these cases, the output array must have its depth explicitly specified. This is done with the
dtypeargument. When present,dtypecan be set to any of the basic types (e.g.,CV_32F) and the result array will be of that type. If the input arrays have the same type, thendtypecan be set to its default value of-1, and the resulting type will be the same as the types of the input arrays. - In-place operation
- Unless otherwise specified, any operation with an array input and an array output that are of the same size and type can use the same array for both (i.e., it is allowable to write the output on top of an input).
- Multichannel
- For those operations that do not naturally make use of multiple channels, if given multichannel arguments, each channel is processed separately.
cv::abs()
cv::MatExpr cv::abs( cv::InputArray src ); cv::MatExpr cv::abs( const cv::MatExpr& src ); // Matrix expression
These functions compute the absolute value of an array or of some expression of arrays. The most common usage computes the absolute value of every element in an array. Because cv::abs() can take a matrix expression, it is able to recognize certain special cases and handle them appropriately. In fact, calls to cv::abs() are actually converted to calls to cv::absDiff() or other functions, and handled by those functions. In particular, the following special cases are implemented:
-
m2 = cv::abs( m0 - m1 )is converted tocv::absdiff( m0, m1, m2 ) -
m2 = cv::abs( m0 )is converted tom2 = cv::absdiff( m0, cv::Scalar::all(0), m2 ) -
m2 = cv::Mat_<Vec<uchar,n> >( cv::abs( alpha*m0 + beta ) )(for alpha, beta real numbers) is converted tocv::convertScaleAbs( m0, m2, alpha, beta )
The third case might seem obscure, but this is just the case of computing a scale and offset (either of which could be trivial) to an n-channel array. This is typical of what you might do when computing a contrast correction for an image, for example.
In the cases that are implemented by cv::absdiff(), the result array will have the same size and type as the input array. In the case implemented by cv::convertScaleAbs(), however, the result type of the return array will always be CV_U8.
cv::absdiff()
void cv::absdiff( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst // Result array )

Given two arrays, cv::absdiff() computes the difference between each pair of corresponding elements in those arrays, and places the absolute value of that difference into the corresponding element of the destination array.
cv::add()
void cv::add( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero int dtype = -1 // Output type for result array );

cv::add() is a simple addition function: it adds all of the elements in src1 to the corresponding elements in src2 and puts the results in dst.
cv::addWeighted()
void cv::addWeighted( cv::InputArray src1, // First input array double alpha, // Weight for first input array cv::InputArray src2, // Second input array double beta, // Weight for second input array double gamma, // Offset added to weighted sum cv::OutputArray dst, // Result array int dtype = -1 // Output type for result array );
The function cv::addWeighted() is similar to cvAdd() except that the result written to dst is computed according to the following formula:

The two source images, src1 and src2, may be of any pixel type as long as both are of the same type. They may also have any number of channels (grayscale, color, etc.) as long as they agree.
This function can be used to implement alpha blending [Smith79; Porter84]; that is, it can be used to blend one image with another. In this case, the parameter alpha is the blending strength of src1, and beta is the blending strength of src2. You can convert to the standard alpha blend equation by setting α between 0 and 1, setting β to 1 − α, and setting γ to 0; this yields:

However, cv::addWeighted() gives us a little more flexibility—both in how we weight the blended images and in the additional parameter γ, which allows for an additive offset to the resulting destination image. For the general form, you will probably want to keep alpha and beta at 0 or above, and their sum at no more than 1; gamma may be set depending on average or max image value to scale the pixels up. A program that uses alpha blending is shown in Example 5-1.
Example 5-1. Complete program to alpha-blend the ROI starting at (0,0) in src2 with the ROI starting at (x,y) in src1
// alphablend <imageA> <image B> <x> <y> <width> <height> <alpha> <beta>
//
#include <cv.h>
#include <highgui.h>
int main(int argc, char** argv) {
cv::Mat src1 = cv::imread(argv[1],1);
cv::Mat src2 = cv::imread(argv[2],1);
if( argc==9 && !src1.empty() && !src2.empty() ) {
int x = atoi(argv[3]);
int y = atoi(argv[4]);
int w = atoi(argv[5]);
int h = atoi(argv[6]);
double alpha = (double)atof(argv[7]);
double beta = (double)atof(argv[8]);
cv::Mat roi1( src1, cv::Rect(x,y,w,h) );
cv::Mat roi2( src2, cv::Rect(0,0,w,h) );
cv::addWeighted( roi1, alpha, roi2, beta, 0.0, roi1 );
cv::namedWindow( "Alpha Blend", 1 );
cv::imshow( "Alpha Blend", src2 );
cv::waitKey( 0 );
}
return 0;
}
The code in Example 5-1 takes two source images: the primary one (src1) and the one to blend (src2). It reads in a rectangle ROI for src1 and applies an ROI of the same size to src2, but located at the origin. It reads in alpha and beta levels but sets gamma to 0. Alpha blending is applied using cv::addWeighted(), and the results are put into src1 and displayed. Example output is shown in Figure 5-1, where the face of a child is blended onto a cat. Note that the code took the same ROI as in the ROI addition in Example 5-1. This time we used the ROI as the target blending region.

Figure 5-1. The face of a child, alpha-blended onto the face of a cat
cv::bitwise_and()
void cv::bitwise_and( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );

cv::bitwise_and() is a per-element bitwise conjunction operation. For every element in src1, the bitwise AND is computed with the corresponding element in src2 and put into the corresponding element of dst.
cv::bitwise_not()
void cv::bitwise_not( cv::InputArray src, // Input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );

cv::bitwise_not() is a per-element bitwise inversion operation. For every element in src1, the logical inversion is computed and placed into the corresponding element of dst.
cv::bitwise_or()
void cv::bitwise_and( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );

cv::bitwise_or() is a per-element bitwise disjunction operation. For every element in src1, the bitwise OR is computed with the corresponding element in src2 and put into the corresponding element of dst.
cv::bitwise_xor()
void cv::bitwise_and( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );

cv::bitwise_and() is a per-element bitwise “exclusive or” (XOR) operation. For every element in src1, the bitwise XOR is computed with the corresponding element in src2 and put into the corresponding element of dst.
cv::calcCovarMatrix()
void cv::calcCovarMatrix( const cv::Mat* samples, // C-array of n-by-1 or 1-by-n matrices int nsamples, // num matrices pointed to by 'samples' cv::Mat& covar, // ref to return array for covariance cv::Mat& mean, // ref to return array for mean int flags, // special variations, see Table 5-2. int ctype = cv::F64 // output matrix type for covar ); void cv::calcCovarMatrix( cv::InputArray samples, // n-by-m matrix, but see 'flags' below cv::Mat& covar, // ref to return array for covariance cv::Mat& mean, // ref to return array for mean int flags, // special variations, see Table 5-2. int ctype = cv::F64 // output matrix type for covar );
Given any number of vectors, cv::calcCovarMatrix() will compute the mean and covariance matrix for the Gaussian approximation to the distribution of those points. This can be used in many ways, of course, and OpenCV has some additional flags that will help in particular contexts (see Table 5-2). These flags may be combined by the standard use of the Boolean OR operator.
| Flag in flags argument | Meaning |
|---|---|
cv::COVAR_NORMAL |
Compute mean and covariance |
cv::COVAR_SCRAMBLED |
Fast PCA “scrambled” covariance |
cv::COVAR_USE_AVERAGE |
Use mean as input instead of computing it |
cv::COVAR_SCALE |
Rescale output covariance matrix |
cv::COVAR_ROWS |
Use rows of samples for input vectors |
cv::COVAR_COLS |
Use columns of samples for input vectors |
There are two basic calling conventions for cv::calcCovarMatrix(). In the first, a pointer to an array of cv::Mat objects is passed along with nsamples, the number of matrices in that array. In this case, the arrays may be n × 1 or 1 × n. The second calling convention is to pass a single array that is n × m. In this case, either the flag cv::COVAR_ROWS should be supplied, to indicate that there are n (row) vectors of length m, or cv::COVAR_COLS should be supplied, to indicate that there are m (column) vectors of length n.
The results will be placed in covar in all cases, but the exact meaning of avg depends on the flag values (see Table 5-2).
The flags cv::COVAR_NORMAL and cv::COVAR_SCRAMBLED are mutually exclusive; you should use one or the other but not both. In the case of cv::COVAR_NORMAL, the function will simply compute the mean and covariance of the points provided:

Thus the normal covariance ![]() is computed from the m vectors of length n, where
is computed from the m vectors of length n, where ![]() is defined as the nth element of the average vector:
is defined as the nth element of the average vector: ![]() . The resulting covariance matrix is an n × n matrix. The factor z is an optional scale factor; it will be set to
. The resulting covariance matrix is an n × n matrix. The factor z is an optional scale factor; it will be set to 1 unless the cv::COVAR_SCALE flag is used.
In the case of cv::COVAR_SCRAMBLED, cv::calcCovarMatrix() will compute the following:

This matrix is not the usual covariance matrix (note the location of the transpose operator). This matrix is computed from the same m vectors of length n, but the resulting scrambled covariance matrix is an m × m matrix. This matrix is used in some specific algorithms such as fast PCA for very large vectors (as in the eigenfaces technique for face recognition).
The flag cv::COVAR_USE_AVG is used when the mean of the input vectors is already known. In this case, the argument avg is used as an input rather than an output, which reduces computation time.
Finally, the flag cv::COVAR_SCALE is used to apply a uniform scale to the covariance matrix calculated. This is the factor z in the preceding equations. When used in conjunction with the cv::COVAR_NORMAL flag, the applied scale factor will be 1.0/m (or, equivalently, 1.0/nsamples). If instead cv::COVAR_SCRAMBLED is used, then the value of z will be 1.0/n (the inverse of the length of the vectors).
The input and output arrays to cv::calcCovarMatrix() should all be of the same floating-point type. The size of the resulting matrix covar will be either n × n or m × m depending on whether the standard or scrambled covariance is being computed. It should be noted that when you are using the cv::Mat* form, the “vectors” input in samples do not actually have to be one-dimensional; they can be two-dimensional objects (e.g., images) as well.
cv::cartToPolar()
void cv::cartToPolar( cv::InputArray x, cv::InputArray y, cv::OutputArray magnitude, cv::OutputArray angle, bool angleInDegrees = false );


This function cv::cartToPolar() takes two input arrays, x and y, which are taken to be the x- and y-components of a vector field (note that this is not a single two-channel array, but two separate arrays). The arrays x and y must be of the same size. cv::cartToPolar() then computes the polar representation of each of those vectors. The magnitude of each vector is placed into the corresponding location in magnitude, and the orientation of each vector is placed into the corresponding location in angle. The returned angles are in radians unless the Boolean variable angleInDegrees is set to true.
cv::checkRange()
bool cv::checkRange( cv::InputArray src, bool quiet = true, cv::Point* pos = 0, // if non-Null, location of first outlier double minVal = -DBL_MAX, // Lower check bound (inclusive) double maxVal = DBL_MAX // Upper check bound (exclusive) );
This function cv::checkRange() tests every element of the input array src and determines if that element is in a given range. The range is set by minVal and maxVal, but any NaN or inf value is also considered out of range. If an out-of-range value is found, an exception will be thrown unless quiet is set to true, in which case the return value of cv::checkRange() will be true if all values are in range and false if any value is out of range. If the pointer pos is not NULL, then the location of the first outlier will be stored in pos.
cv::compare()
bool cv::compare( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array int cmpop // Comparison operator, see Table 5-3. );
This function makes element-wise comparisons between corresponding pixels in two arrays, src1 and src2, and places the results in the image dst. cv::compare() takes as its last argument a comparison operator, which may be any of the types listed in Table 5-3. In each case, the result dst will be an 8-bit array where pixels that match are marked with 255 and mismatches are set to 0.
| Value of cmp_op | Comparison |
|---|---|
cv::CMP_EQ |
(src1i == src2i) |
cv::CMP_GT |
(src1i > src2i) |
cv::CMP_GE |
(src1i >= src2i) |
cv::CMP_LT |
(src1i < src2i) |
cv::CMP_LE |
(src1i <= src2i) |
cv::CMP_NE |
(src1i != src2i) |
All the listed comparisons are done with the same functions; you just pass in the appropriate argument to indicate what you would like done.
These comparison functions are useful, for example, in background subtraction to create a mask of the changed pixels (e.g., from a security camera) such that only novel information is pulled out of the image.
Note
These same results can be achieved with the matrix operations:
dst = src1 == src2; dst = src1 > src2; dst = src1 >= src2; dst = src1 < src2; dst = src1 <= src2; dst = src1 != src2;
cv::completeSymm()
bool cv::completeSymm( cv::InputArray mtx, bool lowerToUpper = false );
![]() (
(lowerToUpper = false)
![]() (
(lowerToUpper = true)
Given a matrix (an array of dimension two) mtx, cv::completeSymm() symmetrizes the matrix by copying.1 Specifically, all of the elements from the lower triangle are copied to their transpose position on the upper triangle of the matrix. The diagonal elements of the mtx are left unchanged. If the flag lowerToUpper is set to true, then the elements from the lower triangle are copied into the upper triangle instead.
cv::convertScaleAbs()
void cv::convertScaleAbs( cv::InputArray src, // Input array cv::OutputArray dst, // Result array double alpha = 1.0, // Multiplicative scale factor double beta = 0.0 // Additive offset factor );

The cv::convertScaleAbs() function is actually several functions rolled into one; it will perform four operations in sequence. The first operation is to rescale the source image by the factor a, the second is to offset by (add) the factor b, the third is to compute the absolute value of that sum, and the fourth is to cast that result (with saturation) to an unsigned char (8-bit).
When you simply pass the default values (alpha = 1.0 or beta = 0.0), you need not have performance fears; OpenCV is smart enough to recognize these cases and not waste processor time on useless operations.
Note
A similar result can be achieved, with somewhat greater generality, through the following loop:
for( int i = 0; i < src.rows; i++ )
for( int j = 0; j < src.cols*src.channels(); j++ )
dst.at<dst_type>(i, j) = satuarate_cast<dst_type>(
(double)src.at<src_type>(i, j) * alpha + beta
);

cv::cvarrToMat()
cv::Mat cv::cvarrToMat( const CvArr* src, // Input array: CvMat, IplImage, or CvMatND bool copyData = false, // if false just make new header, else copy data bool allowND = true, // if true and possible, convert CvMatND to Mat int coiMode = 0 // if 0: error if COI set, if 1: ignore COI );
cv::cvarrToMat() is used when you have an “old-style” (pre–version 2.1) image or matrix type and you want to convert it to a “new-style” (version 2.1 or later, which uses C++) cv::Mat object. By default, only the header for the new array is constructed without copying the data. Instead, the data pointers in the new header point to the existing data array (so do not deallocate it while the cv::Mat header is in use). If you want the data copied, just set copyData to true, and then you can freely do away with the original data object.
cv::cvarrToMat() can also take CvMatND structures, but it cannot handle all cases. The key requirement for the conversion is that the matrix should be continuous, or at least representable as a sequence of continuous matrices. Specifically, A.dim[i].size*A.dim.step[i] should be equal to A.dim.step[i-1] for all i, or at worst all but one. If allowND is set to true (default), cv::cvarrToMat() will attempt the conversion when it encounters a CvMatND structure, and throw an exception if that conversion is not possible (the preceding condition). If allowND is set to false, then an exception will be thrown whenever a CvMatND structure is encountered.
Because the concept of COI2 is handled differently in the post–version 2.1 library (which is to say, it no longer exists), COI has to be handled during the conversion. If the argument coiMode is 0, then an exception will be thrown when src contains an active COI. If coiMode is nonzero, then no error will be reported, and instead a cv::Mat header corresponding to the entire image will be returned, ignoring the COI. (If you want to handle COI properly, you will have to check whether the image has the COI set, and if so, use cv::extractImageCOI() to create a header for just that channel.)
Note
Most of the time, this function is used to help migrate old-style code to the new. In such cases, you will probably need to both convert old-style CvArr* structures to cv::Mat, as well as doing the reverse operation. The reverse operation is done using cast operators. If, for example, you have a matrix you defined as cv::Mat A, you can convert that to an IplImage* pointer simply with:
Cv::Mat A( 640, 480, cv::U8C3 ); // casting is implicit on assignment IplImage. my_img = A; iplImage* img = &my_img;
cv::dct()
void cv::dct( cv::InputArray src, // Input array cv::OutputArray dst, // Result array int flags, // for inverse transform or row-by-row );
This function performs both the discrete cosine transform and the inverse transform depending on the flags argument. The source array src must be either one- or two-dimensional, and the size should be an even number (you can pad the array if necessary). The result array dst will have the same type and size as src. The argument flags is a bit field and can be set to one or both of DCT_INVERSE or DCT_ROWS. If DCT_INVERSE is set, then the inverse transform is done instead of the forward transform. If the flag DCT_ROWS is set, then a two-dimensional n × m input is treated as n distinct one-dimensional vectors of length m. In this case, each such vector will be transformed independently.
Note
The performance of cv::dct() depends strongly on the exact size of the arrays passed to it, and this relationship is not monotonic. There are just some sizes that work better than others. It is recommended that when passing an array to cv::dct(), you first determine the most optimal size that is larger than your array, and extend your array to that size. OpenCV provides a convenient routine to compute such values for you, called cv::getOptimalDFTSize().
As implemented, the discrete cosine transform of a vector of length n is computed via the discrete Fourier transform (cv::dft()) on a vector of length n/2. This means that to get the optimal size for a call to cv::dct(), you should compute it like this:
size_t opt_dft_size = 2 * cv::getOptimalDFTSize((N+1)/2);
This function (and discrete transforms in general) is covered in much greater detail in Chapter 11. In that chapter, we will discuss the details of how to pack and unpack the input and output, as well as when and why you might want to use the discrete cosine transform.
cv::dft()
void cv::dft( cv::InputArray src, // Input array cv::OutputArray dst, // Result array int flags = 0, // for inverse transform or row-by-row int nonzeroRows = 0 // only this many entries are nonzero );
The cv::dft() function performs both the discrete Fourier transform as well as the inverse transform (depending on the flags argument). The source array src must be either one- or two-dimensional. The result array dst will have the same type and size as src. The argument flags is a bit field and can be set to one or more of DFT_INVERSE, DFT_ROWS, DFT_SCALE, DFT_COMPLEX_OUTPUT, or DFT_REAL_OUTPUT. If DFT_INVERSE is set, then the inverse transform is done. If the flag DFT_ROWS is set, then a two-dimensional n × m input is treated as n distinct one-dimensional vectors of length m and each such vector will be transformed independently. The flag DFT_SCALE normalizes the results by the number of elements in the array. This is typically done for DFT_INVERSE, as it guarantees that the inverse of the inverse will have the correct normalization.
The flags DFT_COMPLEX_OUTPUT and DFT_REAL_OUTPUT are useful because when the Fourier transform of a real array is computed, the result will have a complex-conjugate symmetry. So, even though the result is complex, the number of array elements that result will be equal to the number of elements in the real input array rather than double that number. Such a packing is the default behavior of cv::dft(). To force the output to be in complex form, set the flag DFT_COMPLEX_OUTPUT. In the case of the inverse transform, the input is (in general) complex, and the output will be as well. However, if the input array (to the inverse transform) has complex-conjugate symmetry (for example, if it was itself the result of a Fourier transform of a real array), then the inverse transform will be a real array. If you know this to be the case and you would like the result array represented as a real array (thereby using half the amount of memory), you can set the DFT_REAL_OUTPUT flag. (Note that if you do set this flag, cv::dft() does not check that the input array has the necessary symmetry; it simply assumes that it does.)
The last parameter to cv::dft() is nonzeroRows. This defaults to 0, but if set to any nonzero value, will cause cv::dft() to assume that only the first nonzeroRows of the input array are actually meaningful. (If DFT_INVERSE is set, then it is only the first nonzeroRows of the output array that are assumed to be nonzero.) This flag is particularly handy when you are computing cross-correlations of convolutions using cv::dft().
Note
The performance of cv::dft() depends strongly on the exact size of the arrays passed to it, and this relationship is not monotonic. There are just some sizes that work better than others. It is recommended that when passing an array to cv::dft(), you first determine the most optimal size larger than your array, and extend your array to that size. OpenCV provides a convenient routine to compute such values for you, called cv::getOptimalDFTSize().
Again, this function (and discrete transforms in general) is covered in much greater detail in Chapter 11. In that chapter, we will discuss the details of how to pack and unpack the input and output, as well as when and why you might want to use the discrete Fourier transform.
cv::cvtColor()
void cv::cvtColor( cv::InputArray src, // Input array cv::OutputArray dst, // Result array int code, // color mapping code, see Table 5-4. int dstCn = 0 // channels in output (0='automatic') );
cv::cvtColor() is used to convert from one color space (number of channels) to another [Wharton71] while retaining the same data type. The input array src can be an 8-bit array, a 16-bit unsigned array, or a 32-bit floating-point array. The output array dst will have the same size and depth as the input array. The conversion operation to be done is specified by the code argument, with possible values shown in Table 5-4.3 The final parameter, dstCn, is the desired number of channels in the destination image. If the default value of 0 is given, then the number of channels is determined by the number of channels in src and the conversion code.
| Conversion code | Meaning |
|---|---|
cv::COLOR_BGR2RGB cv::COLOR_RGB2BGR cv::COLOR_RGBA2BGRA cv::COLOR_BGRA2RGBA |
Convert between RGB and BGR color spaces (with or without alpha channel) |
cv::COLOR_RGB2RGBA cv::COLOR_BGR2BGRA |
Add alpha channel to RGB or BGR image |
cv::COLOR_RGBA2RGB cv::COLOR_BGRA2BGR |
Remove alpha channel from RGB or BGR image |
cv::COLOR_RGB2BGRA cv::COLOR_RGBA2BGR cv::COLOR_BGRA2RGB cv::COLOR_BGR2RGBA |
Convert RGB to BGR color spaces while adding or removing alpha channel |
cv::COLOR_RGB2GRAY cv::COLOR_BGR2GRAY |
Convert RGB or BGR color spaces to grayscale |
cv::COLOR_GRAY2RGB cv::COLOR_GRAY2BGR cv::COLOR_RGBA2GRAY cv::COLOR_BGRA2GRAY |
Convert grayscale to RGB or BGR color spaces (optionally removing alpha channel in the process) |
cv::COLOR_GRAY2RGBA cv::COLOR_GRAY2BGRA |
Convert grayscale to RGB or BGR color spaces and add alpha channel |
cv::COLOR_RGB2BGR565 cv::COLOR_BGR2BGR565 cv::COLOR_BGR5652RGB cv::COLOR_BGR5652BGR cv::COLOR_RGBA2BGR565 cv::COLOR_BGRA2BGR565 cv::COLOR_BGR5652RGBA cv::COLOR_BGR5652BGRA |
Convert from RGB or BGR color space to BGR565 color representation with optional addition or removal of alpha channel (16-bit images) |
cv::COLOR_GRAY2BGR565 cv::COLOR_BGR5652GRAY |
Convert grayscale to BGR565 color representation or vice versa (16-bit images) |
cv::COLOR_RGB2BGR555 cv::COLOR_BGR2BGR555 cv::COLOR_BGR5552RGB cv::COLOR_BGR5552BGR cv::COLOR_RGBA2BGR555 cv::COLOR_BGRA2BGR555 cv::COLOR_BGR5552RGBA cv::COLOR_BGR5552BGRA |
Convert from RGB or BGR color space to BGR555 color representation with optional addition or removal of alpha channel (16-bit images) |
cv::COLOR_GRAY2BGR555 cv::COLOR_BGR5552GRAY |
Convert grayscale to BGR555 color representation or vice versa (16-bit images) |
cv::COLOR_RGB2XYZ cv::COLOR_BGR2XYZ cv::COLOR_XYZ2RGB cv::COLOR_XYZ2BGR |
Convert RGB or BGR image to CIE XYZ representation or vice versa (Rec 709 with D65 white point) |
cv::COLOR_RGB2YCrCb cv::COLOR_BGR2YCrCb cv::COLOR_YCrCb2RGB cv::COLOR_YCrCb2BGR |
Convert RGB or BGR image to luma-chroma (a.k.a. YCC) color representation or vice versa |
cv::COLOR_RGB2HSV cv::COLOR_BGR2HSV cv::COLOR_HSV2RGB cv::COLOR_HSV2BGR |
Convert RGB or BGR image to HSV (hue saturation value) color representation or vice versa |
cv::COLOR_RGB2HLS cv::COLOR_BGR2HLS cv::COLOR_HLS2RGB cv::COLOR_HLS2BGR |
Convert RGB or BGR image to HLS (hue lightness saturation) color representation or vice versa |
cv::COLOR_RGB2Lab cv::COLOR_BGR2Lab cv::COLOR_Lab2RGB cv::COLOR_Lab2BGR |
Convert RGB or BGR image to CIE Lab color representation or vice versa |
cv::COLOR_RGB2Luv cv::COLOR_BGR2Luv cv::COLOR_Luv2RGB cv::COLOR_Luv2BGR |
Convert RGB or BGR image to CIE Luv color representation or vice versa |
cv::COLOR_BayerBG2RGB cv::COLOR_BayerGB2RGB cv::COLOR_BayerRG2RGB cv::COLOR_BayerGR2RGB cv::COLOR_BayerBG2BGR cv::COLOR_BayerGB2BGR cv::COLOR_BayerRG2BGR cv::COLOR_BayerGR2BGR |
Convert from Bayer pattern (single-channel) to RGB or BGR image |
We will not go into the details of these conversions nor the subtleties of some of the representations (particularly the Bayer and the CIE color spaces) here. Instead, we will just note that OpenCV contains tools to convert to and from these various color spaces, which are important to various classes of users.
The color-space conversions all use the following conventions: 8-bit images are in the range 0 to 255, 16-bit images are in the range 0 to 65,536, and floating-point numbers are in the range 0.0 to 1.0. When grayscale images are converted to color images, all components of the resulting image are taken to be equal; but for the reverse transformation (e.g., RGB or BGR to grayscale), the gray value is computed through the perceptually weighted formula:

In the case of HSV or HLS representations, hue is normally represented as a value from 0 to 360.4 This can cause trouble in 8-bit representations and so, when you are converting to HSV, the hue is divided by 2 when the output image is an 8-bit image.
cv::determinant()
double cv::determinant( cv::InputArray mat );
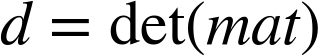
cv::determinant() computes the determinant of a square array. The array must be of one of the floating-point data types and must be single-channel. If the matrix is small, then the determinant is directly computed by the standard formula. For large matrices, this is not efficient, so the determinant is computed by Gaussian elimination.
Note
If you know that a matrix has a symmetric and positive determinant, you can use the trick of solving via singular value decomposition (SVD). For more information, see the section “Singular Value Decomposition (cv::SVD)” in Chapter 7, but the trick is to set both U and V to NULL, and then just take the products of the matrix W to obtain the determinant.
cv::divide()
void cv::divide( cv::InputArray src1, // First input array (numerators) cv::InputArray src2, // Second input array (denominators) cv::OutputArray dst, // Results array (scale*src1/src2) double scale = 1.0, // Multiplicative scale factor int dtype = -1 // dst data type, -1 to get from src2 ); void cv::divide( double scale, // Numerator for all divisions cv::InputArray src2, // Input array (denominators) cv::OutputArray dst, // Results array (scale/src2) int dtype = -1 // dst data type, -1 to get from src2 );


cv::divide() is a simple division function; it divides all of the elements in src1 by the corresponding elements in src2 and puts the results in dst.
cv::eigen()
bool cv::eigen( cv::InputArray src, cv::OutputArray eigenvalues, int lowindex = -1, int highindex = -1 ); bool cv::eigen( cv::InputArray src, cv::OutputArray eigenvalues, cv::OutputArray eigenvectors, int lowindex = -1, int highindex = -1 );
Given a symmetric matrix mat, cv::eigen() will compute the eigenvectors and eigenvalues of that matrix. The matrix must be of one of the floating-point types. The results array eigenvalues will contain the eigenvalues of mat in descending order. If the array eigenvectors was provided, the eigenvectors will be stored as the rows of that array in the same order as the corresponding eigenvalues in eigenvalues. The additional parameters lowindex and highindex allow you to request only some of the eigenvalues to be computed (both must be used together). For example, if lowindex=0 and highindex=1, then only the largest two eigenvectors will be computed.

cv::extractImageCOI()
bool cv::extractImageCOI( const CvArr* arr, cv::OutputArray dst, int coi = -1 );
The function cv::extractImageCOI() extracts the indicated COI from a legacy-style (pre–version 2.1) array, such as an IplImage or CvMat given by arr, and puts the result in dst. If the argument coi is provided, then that particular COI will be extracted. If not, then the COI field in src will be checked to determine which channel to extract.
Note
The cv::extractImageCOI() method described here is specifically for use with legacy arrays. If you need to extract a single channel from a modern cv::Mat object, use cv::mixChannels() or cv::split().
cv::flip()
void cv::flip( cv::InputArray src, // Input array cv::OutputArray dst, // Result array, size and type of 'src' int flipCode = 0 // >0: y-flip, 0: x-flip, <0: both );
This function flips an image around the x-axis, the y-axis, or both. By default, flipCode is set to 0, which flips around the x-axis.
If flipCode is set greater than zero (e.g., +1), the image will be flipped around the y-axis, and if set to a negative value (e.g., –1), the image will be flipped about both axes.
When doing video processing on Win32 systems, you will find yourself using this function often to switch between image formats with their origins at the upper left and lower left of the image.
cv::gemm()
void cv::gemm( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array double alpha, // Weight for 'src1' * 'src2' product cv::InputArray src3, // Third (offset) input array double beta, // Weight for 'src3' array cv::OutputArray dst, // Results array int flags = 0 // Use to transpose source arrays );
Generalized matrix multiplication (GEMM) in OpenCV is performed by cv::gemm(), which performs matrix multiplication, multiplication by a transpose, scaled multiplication, and so on. In its most general form, cv::gemm() computes the following:

where src1, src2, and src3 are matrices, α and β are numerical coefficients, and op() is an optional transposition of the matrix enclosed. The transpositions are controlled by the optional argument flags, which may be 0 or any combination (by means of Boolean OR) of cv::GEMM_1_T, cv::GEMM_2_T, and cv::GEMM_3_T (with each flag indicating a transposition of the corresponding matrix).
All matrices must be of the appropriate size for the (matrix) multiplication, and all should be of floating-point types. The cv::gemm() function also supports two-channel matrices that will be treated as two components of a single complex number.
Note
You can achieve a similar result using the matrix algebra operators. For example:
cv::gemm( src1, src2, alpha, src3, bets, dst,cv::GEMM_1_T | cv::GEMM_3_T );
would be equivalent to:
dst = alpha * src1.T() * src2 + beta * src3.T()
cv::getConvertElem() and cv::getConvertScaleElem()
cv::convertData cv::getConvertElem( // Returns a conversion function (below) int fromType, // Input pixel type (e.g., cv::U8) int toType // Output pixel type (e.g., CV_32F) ); cv::convertScaleData cv::getConvertScaleElem( // Returns a conversion function int fromType, // Input pixel type (e.g., cv::U8) int toType // Output pixel type (e.g., CV_32F) ); // Conversion functions are of these forms: // typedef void (*ConvertData)( const void* from, // Pointer to the input pixel location void* to, // Pointer to the result pixel location int cn // number of channels ); typedef void (*ConvertScaleData)( const void* from, // Pointer to the input pixel location void* to, // Pointer to the result pixel location int cn, // number of channels double alpha, // scale factor double beta // offset factor );
The functions cv::getConvertElem() and cv::getConvertScaleElem() return function pointers to the functions that are used for specific type conversions in OpenCV. The function returned by cv::getConvertElem() is defined (via typedef) to the type cv::ConvertData, which can be passed a pointer to two data areas and a number of “channels.” The number of channels is given by the argument cn of the conversion function, which is really the number of contiguous-in-memory objects of fromType to convert. This means that you could convert an entire (contiguous-in-memory) array by simply setting the number of channels equal to the total number of elements in the array.
Both cv::getConvertElem() and cv::getConvertScaleElem() take as arguments two types: fromType and toType. These types are specified with the integer constants (e.g., CV_32F).
In the case of cv::getConvertScaleElem(), the returned function takes two additional arguments, alpha and beta. These values are used by the converter function to rescale (alpha) and offset (beta) the input value before conversion to the desired type.
cv::idct()
void cv::idct( cv::InputArray src, // Input array cv::OutputArray dst, // Result array int flags, // for row-by-row );
cv::idct() is just a convenient shorthand for the inverse discrete cosine transform. A call to cv::idct() is exactly equivalent to a call to cv::dct() with the arguments:
cv::dct( src, dst, flags | cv::DCT_INVERSE );
cv::idft()
void cv::idft( cv::InputArray src, // Input array cv::OutputArray dst, // Result array int flags = 0, // for row-by-row, etc. int nonzeroRows = 0 // only this many entries are nonzero );
cv::idft() is just a convenient shorthand for the inverse discrete Fourier transform. A call to cv::idft() is exactly equivalent to a call to cv::dft() with the arguments:
cv::dft( src, dst, flags | cv::DCT_INVERSE, outputRows );
Note
Neither cv::dft() nor cv::idft() scales the output by default. So you will probably want to call cv::idft() with the cv::DFT_SCALE argument; that way, the transform and its “inverse” will be true inverse operations.
cv::inRange()
void cv::inRange( cv::InputArray src, // Input array cv::InputArray upperb, // Array of upper bounds (inclusive) cv::InputArray lowerb, // Array of lower bounds (inclusive) cv::OutputArray dst // Result array, cv::U8C1 type );

When applied to a one-dimensional array, each element of src is checked against the corresponding elements of upperb and lowerb. The corresponding element of dst is set to 255 if the element in src is between the values given by upperb and lowerb; otherwise, it is set to 0.
However, in the case of multichannel arrays for src, upperb, and lowerb, the output is still a single channel. The output value for element i will be set to 255 if and only if the values for the corresponding entry in src all lay inside the intervals implied for the corresponding channel in upperb and lowerb. In this sense, upperb and lowerb define an n-dimensional hypercube for each pixel and the corresponding value in dst is only set to true (255) if the pixel in src lies inside that hypercube.
cv::insertImageCOI()
void cv::insertImageCOI( cv::InputArray img, // Input array, single channel CvArr* arr, // Legacy (pre v2.1) output array int coi = -1 // Target channel );
Like the cv::extractImageCOI() function we encountered earlier in this chapter, the cv::insertImageCOI() function is designed to help us work with legacy (pre-v2.1) arrays like IplImage and CvMat. Its purpose is to allow us to take the data from a new-style C++ cv::Mat object and write that data onto one particular channel of a legacy array. The input img is expected to be a single-channel cv::Mat object, while the input arr is expected to be a multichannel legacy object. Both must be of the same size. The data in img will be copied onto the coi channel of arr.
Note
The function cv::extractImageCOI() is used when you want to extract a particular COI from a legacy array into a single-channel C++ array. On the other hand, cv::insertImageCOI() is used to write the contents of a single-channel C++ array onto a particular channel of a legacy array. If you aren’t dealing with legacy arrays and you just want to insert one C++ array into another, you can do that with cv::merge().
cv::invert()
double cv::invert( // Return 0 if 'src' is singular cv::InputArray src, // Input Array, m-by-n cv::OutputArray dst // Result array, n-by-m int method = cv::DECOMP_LU // Method for (pseudo) inverse );
cv::invert() inverts the matrix in src and places the result in dst. The input array must be a floating-point type, and the result array will be of the same type. Because cv::invert() includes the possibility of computing pseudo-inverses, the input array need not be square. If the input array is n × m, then the result array will be m × n. This function supports several methods of computing the inverse matrix (see Table 5-5), but the default is Gaussian elimination. The return value depends on the method used.
| Value of method argument | Meaning |
|---|---|
cv::DECOMP_LU |
Gaussian elimination (LU decomposition) |
cv::DECOMP_SVD |
Singular value decomposition (SVD) |
cv::DECOMP_CHOLESKY |
Only for symmetric positive matrices |
In the case of Gaussian elimination (cv::DECOMP_LU), the determinant of src is returned when the function is complete. If the determinant is 0, inversion failed and the array dst is set to all 0s.
In the case of cv::DECOMP_SVD, the return value is the inverse condition number for the matrix (the ratio of the smallest to the largest eigenvalues). If the matrix src is singular, then cv::invert() in SVD mode will compute the pseudo-inverse. The other two methods (LU and Cholesky decomposition) require the source matrix to be square, nonsingular, and positive.

cv::LUT()
void cv::LUT( cv::InputArray src, cv::InputArray lut, cv::OutputArray dst );

The function cv::LUT() performs a “lookup table transform” on the input in src. cv::LUT() requires the source array src to be 8-bit index values. The lut array holds the lookup table. This lookup table array should have exactly 256 elements, and may have either a single channel or, in the case of a multichannel src array, the same number of channels as the source array. The function cv::LUT() then fills the destination array dst with values taken from the lookup table lut using the corresponding value from src as an index into that table.
In the case where the values in src are signed 8-bit numbers, they are automatically offset by +128 so that their range will index the lookup table in a meaningful way. If the lookup table is multichannel (and the indices are as well), then the value in src is used as a multidimensional index into lut, and the result array dst will be single channel. If lut is one-dimensional, then the result array will be multichannel, with each channel being separately computed from the corresponding index from src and the one-dimensional lookup table.
cv::magnitude()
void cv::magnitude( cv::InputArray x, cv::InputArray y, cv::OutputArray dst );

cv::magnitude() essentially computes the radial part of a Cartesian-to-polar conversion on a two-dimensional vector field. In the case of cv::magnitude(), this vector field is expected to be in the form of two separate single channel arrays. These two input arrays should have the same size. (If you have a single two-channel array, cv::split() will give you separate channels.) Each element in dst is computed from the corresponding elements of x and y as the Euclidean norm of the two (i.e., the square root of the sum of the squares of the corresponding values).
cv::Mahalanobis()
cv::Size cv::mahalanobis(
cv::InputArray vec1,
cv::InputArray vec2,
cv::OutputArray icovar
);
cv::Mahalanobis() computes the value:

The Mahalanobis distance is defined as the vector distance measured between a point and the center of a Gaussian distribution; it is computed using the inverse covariance of that distribution as a metric (see Figure 5-2). Intuitively, this is analogous to the z-score in basic statistics, where the distance from the center of a distribution is measured in units of the variance of that distribution. The Mahalanobis distance is just a multivariable generalization of the same idea.

Figure 5-2. A distribution of points in two dimensions with superimposed ellipsoids representing Mahalanobis distances of 1.0, 2.0, and 3.0 from the distribution’s mean
The vector vec1 is presumed to be the point x, and the vector vec2 is taken to be the distribution’s mean.5 That matrix icovar is the inverse covariance.
Note
This covariance matrix will usually have been computed with cv::calcCovarMatrix() (described previously) and then inverted with cv::invert(). It is good programming practice to use the cv::DECOMP_SVD method for this inversion because someday you will encounter a distribution for which one of the eigenvalues is 0!
cv::max()
cv::MatExpr cv::max( const cv::Mat& src1, // First input array (first position) const cv::Mat& src2 // Second input array ); MatExpr cv::max( // A matrix expression, not a matrix const cv::Mat& src1, // First input array (first position) double value // Scalar in second position ); MatExpr cv::max( // A matrix expression, not a matrix double value, // Scalar in first position const cv::Mat& src1 // Input array (second position) ); void cv::max( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst // Result array ); void cv::max( const Mat& src1, // First input array const Mat& src2, // Second input array Mat& dst // Result array ); void cv::max( const Mat& src1, // Input array double value, // Scalar input Mat& dst // Result array );

cv::max() computes the maximum value of each corresponding pair of pixels in the arrays src1 and src2. It has two basic forms: those that return a matrix expression and those that compute a result and put it someplace you have indicated. In the three-argument form, in the case where one of the operands is a cv::Scalar, comparison with a multichannel array is done on a per-channel basis with the appropriate component of the cv::Scalar.
cv::mean()
cv::Scalar cv::mean( cv::InputArray src, cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );


The function cv::mean() computes the average value of all of the pixels in the input array src that are not masked out. The result is computed on a per-channel basis if src is multichannel.
cv::meanStdDev()
void cv::meanStdDev( cv::InputArray src, cv::OutputArray mean, cv::OutputArray stddev, cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero );



The function cv::meanStdDev() computes the average value of the pixels in the input array src that are not masked out, as well as their standard deviation. The mean and standard deviation are computed on a per-channel basis if src is multichannel.
cv::merge()
void cv::merge( const cv::Mat* mv, // C-style array of arrays size_t count, // Number of arrays pointed to by 'mv' cv::OutputArray dst // Contains all channels in 'mv' ); void merge( const vector<cv::Mat>& mv, // STL-style array of arrays cv::OutputArray dst // Contains all channels in 'mv' );
cv::merge() is the inverse operation of cv::split(). The arrays contained in mv are combined into the output array dst. In the case in which mv is a pointer to a C-style array of cv::Mat objects, the additional size parameter count must also be supplied.
cv::min()
cv::MatExpr cv::min( // A matrix expression, not a matrix const cv::Mat& src1, // First input array const cv::Mat& src2 // Second input array ); MatExpr cv::min( // A matrix expression, not a matrix const cv::Mat& src1, // First input array (first position) double value // Scalar in second position ); MatExpr cv::min( // A matrix expression, not a matrix double value, // Scalar in first position const cv::Mat& src1 // Input array (second position) ); void cv::min( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst // Result array ); void cv::min( const Mat& src1, // First input array const Mat& src2, // Second input array Mat& dst // Result array ); void cv::min( const Mat& src1, // Input array double value, // Scalar input Mat& dst // Result array );

cv::min() computes the minimum value of each corresponding pair of pixels in the arrays src1 and src2 (or one source matrix and a single value). Note that the variants of cv::min() that return a value or a matrix expression can then be manipulated by OpenCV’s matrix expression machinery.
In the three-argument form, in the case where one of the operands is a cv::Scalar, comparison with a multichannel array is done on a per-channel basis with the appropriate component of the cv::Scalar.
cv::minMaxIdx()
void cv::minMaxIdx( cv::InputArray src, // Input array, single channel only double* minVal, // min value goes here (in not NULL) double* maxVal, // min value goes here (in not NULL) int* minIdx, // loc of min goes here (if not NULL) int* maxIdx, // loc of max goes here (if not NULL) cv::InputArray mask = cv::noArray() // search only nonzero values ); void cv::minMaxIdx( const cv::SparseMat& src, // Input sparse array double* minVal, // min value goes here (in not NULL) double* maxVal, // min value goes here (in not NULL) int* minIdx, // C-style array, indices of min locs int* maxIdx, // C-style array, indices of max locs );
These routines find the minimal and maximal values in the array src and (optionally) returns their locations. The computed minimum and maximum values are placed in minVal and maxVal. Optionally, the locations of those extrema can also be returned; this will work for arrays of any number of dimensions. These locations will be written to the addresses given by minIdx and maxIdx (provided that these arguments are non-NULL).
cv::minMaxIdx() can also be called with a cv::SparseMat for the src array. In this case, the array can be of any number of dimensions and the minimum and maximum will be computed and their location returned. In this case, the locations of the extrema will be returned and placed in the C-style arrays minLoc and maxLoc. Both of those arrays, if provided, should have the same number of elements as the number of dimensions in the src array. In the case of cv::SparseMat, the minimum and maximum are computed only for what are generally referred to as nonzero elements in the source code; however, this terminology is slightly misleading, as what is really meant is elements that exist in the sparse matrix representation in memory. In fact, there may, as a result of how the sparse matrix came into being and what has been done with it in the past, be elements that exist and are also zero. Such elements will be included in the computation of the minimum and maximum.
Warning
When a single-dimensional array is supplied, the arrays for the locations must still have memory allocated for two integers. This is because cv::minMaxLoc() uses the convention that even a single-dimensional array is, in essence, an N×1 matrix. The second value returned will always be 0 for each location in this case.
cv::minMaxLoc()
void cv::minMaxLoc( cv::InputArray src, // Input array double* minVal, // min value goes here (in not NULL) double* maxVal, // min value goes here (in not NULL) cv::Point* minLoc, // loc of min goes here (if not NULL) cv::Point* maxLoc, // loc of max goes here (if not NULL) cv::InputArray mask = cv::noArray() // search only nonzero values ); void cv::minMaxLoc( const cv::SparseMat& src, // Input sparse array double* minVal, // min value goes here (in not NULL) double* maxVal, // min value goes here (in not NULL) cv::Point* minLoc, // C-style array, indices of min locs cv::Point* maxLoc, // C-style array, indices of max locs );
This routine finds the minimal and maximal values in the array src and (optionally) returns their locations. The computed minimum and maximum values are placed in minVal and maxVal, respectively. Optionally, the locations of those extrema can also be returned. These locations will be written to the addresses given by minLoc and maxLoc (provided that these arguments are non-NULL). Because these locations are of type cv::Point, this form of the function should be used only on two-dimensional arrays (i.e., matrices or images).
As with cv::MinMaxIdx(), in the case of sparse matrices, only active entries will be considered when searching for the minimum or the maximum.
When working with multichannel arrays, you have several options. Natively, cv::minMaxLoc() does not support multichannel input. Primarily this is because this operation is ambiguous.
Note
If you want the minimum and maximum across all channels, you can use cv::reshape() to reshape the multichannel array into one giant single-channel array. If you would like the minimum and maximum for each channel separately, you can use cv::split() or cv::mixChannels() to separate the channels out and analyze them separately.
In both forms of cv::minMaxLoc, the arguments for the minimum or maximum value or location may be set to NULL, which turns off the computation for that argument.
cv::mixChannels()
void cv::mixChannels( const cv::Mat* srcv, // C-style array of matrices int nsrc, // Number of elements in 'srcv' cv::Mat* dstv, // C-style array of target matrices int ndst, // Number of elements in 'dstv' const int* fromTo, // C-style array of pairs, ...from,to... size_t n_pairs // Number of pairs in 'fromTo' ); void cv::mixChannels( const vector<cv::Mat>& srcv, // STL-style vector of matrices vector<cv::Mat>& dstv, // STL-style vector of target matrices const int* fromTo, // C-style array of pairs, ...from,to... size_t n_pairs // Number of pairs in 'fromTo' );
There are many operations in OpenCV that are special cases of the general problem of rearranging channels from one or more images in the input, and sorting them into particular channels in one or more images in the output. Functions like cv::split(), cv::merge(), and (at least some cases of) cv::cvtColor() all make use of such functionality. Those methods do what they need to do by calling the much more general cv::mixChannels(). This function allows you to supply multiple arrays, each with potentially multiple channels, for the input, and the same for the output, and to map the channels from the input arrays into the channels in the output arrays in any manner you choose.
The input and output arrays can either be specified as C-style arrays of cv::Mat objects with an accompanying integer indicating the number of cv::Mats, or as an STL vector<> of cv::Mat objects. Output arrays must be preallocated with their size and number of dimensions matching those of the input arrays.
The mapping is controlled by the C-style integer array fromTo. This array can contain any number of integer pairs in sequence, with each pair indicating with its first value the source channel and with its second value the destination channel to which that should be copied. The channels are sequentially numbered starting at zero for the first image, then through the second image, and so on (see Figure 5-3). The total number of pairs is supplied by the argument n_pairs.

Figure 5-3. A single four-channel RGBA image is converted to one BGR and one alpha-only image
Note
Unlike most other functions in the post–version 2.1 library, cv::mixChannels() does not allocate the output arrays. They must be preallocated and have the same size and dimensionality as the input arrays.
cv::mulSpectrums()
doublevoid cv::mulSpectrums(
cv::InputArray arr1, // First input array
cv::InputArray arr2, // Second input array, same size as 'arr1'
cv::OutputArray dst, // Result array, same size as 'arr1'
int flags, // used to indicate independent rows
bool conj = false // If true, conjugate arr2 first
);
In many operations involving spectra (i.e., the results from cv::dft() or cv::idft()), one wishes to do a per-element multiplication that respects the packing of the spectra (real arrays), or their nature as complex variables. (See the description of cv::dft() for more details.) The input arrays may be one- or two-dimensional, with the second the same size and type as the first. If the input array is two-dimensional, it may either be taken to be a true two-dimensional spectrum, or an array of one-dimensional spectra (one per row). In the latter case, flags should be set to cv::DFT_ROWS; otherwise it can be set to 0.
When the two arrays are complex, they are simply multiplied on an element-wise basis, but cv::mulSpectrums() provides an option to conjugate the second array elements before multiplication. For example, you would use this option to perform correlation (using the Fourier transform), but for convolution, you would use conj=false.
cv::multiply()
void cv::multiply( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array double scale = 1.0, // overall scale factor int dtype = -1 // Output type for result array );

cv::multiply() is a simple multiplication function; it multiplies the elements in src1 by the corresponding elements in src2 and puts the results in dst.
cv::mulTransposed()
void cv::mulTransposed( cv::InputArray src1, // Input matrix cv::OutputArray dst, // Result array bool aTa, // If true, transpose then multiply cv::InputArray delta = cv::noArray(), // subtract from 'src1' before multiply double scale = 1.0, // overall scale factor int dtype = -1 // Output type for result array );

cv::mulTransposed() is used to compute the product of a matrix and its own transpose—useful, for example, in computing covariance. The matrix src should be two-dimensional and single-channel, but unlike cv::GEMM(), it is not restricted to the floating-point types. The result matrix will be the same type as the source matrix unless specified otherwise by dtype. If dtype is not negative (default), it should be either CV_32F or cv::F64; the output array dst will then be of the indicated type.
If a second input matrix delta is provided, that matrix will be subtracted from src before the multiplication. If no matrix is provided (i.e., delta=cv::noArray()), then no subtraction is done. The array delta need not be the same size as src; if delta is smaller than src, delta is repeated (also called tiling; see cv::repeat()) in order to produce an array whose size matches the size of src. The argument scale is applied to the matrix after the multiplication is done. Finally, the argument aTa is used to select the multiplication in which the transposed version of src is multiplied either from the left (aTa=true) or from the right (aTa=false).
cv::norm()
double cv::norm( // Return norm in double precision cv::InputArray src1, // Input matrix int normType = cv::NORM_L2, // Type of norm to compute cv::InputArray mask = cv::noArray() // do for nonzero values (if present) ); double cv::norm( // Return computed norm of difference cv::InputArray src1, // Input matrix cv::InputArray src2, // Second input matrix int normType = cv::NORM_L2, // Type of norm to compute cv::InputArray mask = cv::noArray() // do for nonzero values (if present) ); double cv::norm( const cv::SparseMat& src, // Input sparse matrix int normType = cv::NORM_L2, // Type of norm to compute );

The cv::norm() function is used to compute the norm of an array (see Table 5-6) or a variety of distance norms between two arrays if two arrays are provided (see Table 5-7). The norm of a cv::SparseMat can also be computed, in which case zero-entries are ignored in the computation of the norm.
| normType | Result |
|---|---|
cv::NORM_INF |
|
cv::NORM_L1 |
 |
cv::NORM_L2 |
 |
If the second array argument src2 is non-NULL, then the norm computed is a difference norm—that is, something like the distance between the two arrays.6 In the first three cases (shown in Table 5-7), the norm is absolute; in the latter three cases, it is rescaled by the magnitude of the second array, src2.
| normType | Result |
|---|---|
cv::NORM_INF |
|
cv::NORM_L1 |
|
cv::NORM_L2 |
 |
cv::NORM_RELATIVE_INF |
 |
cv::NORM_RELATIVE_L1 |
 |
cv::NORM_RELATIVE_L2 |
 |
In all cases, src1 and src2 must have the same size and number of channels. When there is more than one channel, the norm is computed over all of the channels together (i.e., the sums in Tables 5-6 and 5-7 are not only over x and y but also over the channels).
cv::normalize()
void cv::normalize( cv::InputArray src1, // Input matrix cv::OutputArray dst, // Result matrix double alpha = 1, // first parameter (see Table 5-8) double beta = 0, // second parameter (see Table 5-8) int normType = cv::NORM_L2, // Type of norm to compute int dtype = -1 // Output type for result array cv::InputArray mask = cv::noArray() // do for nonzero values (if present) ); void cv::normalize( const cv::SparseMat& src, // Input sparse matrix cv::SparseMat& dst, // Result sparse matrix double alpha = 1, // first parameter (see Table 5-8) int normType = cv::NORM_L2, // Type of norm to compute );


As with so many OpenCV functions, cv::normalize() does more than it might at first appear. Depending on the value of normType, image src is normalized or otherwise mapped into a particular range in dst. The array dst will be the same size as src, and will have the same data type, unless the dtype argument is used. Optionally, dtype can be set to one of the OpenCV fundamental types (e.g., CV_32F) and the output array will be of that type. The exact meaning of this operation is dependent on the normType argument. The possible values of normType are shown in Table 5-8.
| norm_type | Result |
|---|---|
cv::NORM_INF |
|
cv::NORM_L1 |
|
cv::NORM_L2 |
|
cv::NORM_MINMAX |
Map into range [α, β] |
In the case of the infinity norm, the array src is rescaled such that the magnitude of the absolute value of the largest entry is equal to alpha. In the case of the L1 or L2 norm, the array is rescaled so that the norm equals the value of alpha. If normType is set to cv::MINMAX, then the values of the array are rescaled and translated so that they are linearly mapped into the interval between alpha and beta (inclusive).
As before, if mask is non-NULL then only those pixels corresponding to nonzero values of the mask image will contribute to the computation of the norm—and only those pixels will be altered by cv::normalize(). Note that if the operation dtype=cv::MINMAX is used, the source array may not be cv::SparseMat. The reason for this is that the cv::MIN_MAX operation can apply an overall offset, and this would affect the sparsity of the array (specifically, a sparse array would become nonsparse as all of the zero elements became nonzero as a result of this operation).
cv::perspectiveTransform()
void cv::perspectiveTransform( cv::InputArray src, // Input array, 2 or 3 channels cv::OutputArray dst, // Result array, size, type, as src1 cv::InputArray mtx // 3-by-3 or 4-by-4 transoform matrix );

The cv::perspectiveTransform() function performs a plane-plane projective transform of a list of points (not pixels). The input array should be a two- or three-channel array, and the matrix mtx should be 3 × 3 or 4 × 4, respectively, in the two cases. cv::perspectiveTransform() thus transforms each element of src by first regarding it as a vector of length src.channels() + 1, with the additional dimension (the projective dimension) set initially to 1.0. This is also known as homogeneous coordinates. Each extended vector is then multiplied by mtx and the result is rescaled by the value of the (new) projective coordinate7 (which is then thrown away, as it is always 1.0 after this operation).
Note
Note again that this routine is for transforming a list of points, not an image as such. If you want to apply a perspective transform to an image, you are actually asking not to transform the individual pixels, but rather to move them from one place in the image to another. This is the job of cv::warpPerspective().
If you want to solve the inverse problem to find the most probable perspective transformation given many pairs of corresponding points, use cv::getPerspectiveTransform() or cv::findHomography().
cv::phase()
void cv::phase( cv::InputArray x, // Input array of x-components cv::InputArray y, // Input array of y-components cv::OutputArray dst, // Output array of angles (radians) bool angleInDegrees = false // degrees (if true), radians (if false) );

cv::phase() computes the azimuthal (angle) part of a Cartesian-to-polar conversion on a two-dimensional vector field. This vector field is expected to be in the form of two separate single-channel arrays. These two input arrays should, of course, be of the same size. (If you happen to have a single two-channel array, a quick call to cv::split() will do just what you need.) Each element in dst is then computed from the corresponding elements of x and y as the arctangent of the ratio of the two.
cv::polarToCart()
void cv::polarToCart( cv::InputArray magnitude, // Input array of magnitudes cv::InputArray angle, // Input array of angles cv::OutputArray x, // Output array of x-components cv::OutputArray y, // Output array of y-components bool angleInDegrees = false // degrees (if true) radians (if false) );


cv::polarToCart() computes a vector field in Cartesian (x, y) coordinates from polar coordinates. The input is in two arrays, magnitude and angle, of the same size and type, specifying the magnitude and angle of the field at every point. The output is similarly two arrays that will be of the same size and type as the inputs, and which will contain the x and y projections of the vector at each point. The additional flag angleInDegrees will cause the angle array to be interpreted as angles in degrees rather than in radians.
cv::pow()
void cv::pow( cv::InputArray src, // Input array double p, // power for exponentiation cv::OutputArray dst // Result array );

The function cv::pow() computes the element-wise exponentiation of an array by a given power p. In the case in which p is an integer, the power is computed directly. For noninteger p, the absolute value of the source value is computed first, and then raised to the power p (so only real values are returned). For some special values of p, such as integer values, or ±½, special algorithms are used, resulting in faster computation.
cv::randu()
template<typename _Tp> _Tp randu(); // Return random number of specific type void cv::randu( cv::InputOutArray mtx, // All values will be randomized cv::InputArray low, // minimum, 1-by-1 (Nc=1,4), or 1-by-4 (Nc=1) cv::InputArray high // maximum, 1-by-1 (Nc=1,4), or 1-by-4 (Nc=1) );

There are two ways to call cv::randu(). The first method is to call the template form of randu<>(), which will return a random value of the appropriate type. Random numbers generated in this way are uniformly distributed8 in the range from zero to the maximum value available for that type (for integers), and in the interval from 0.0 to 1.0 (not inclusive of 1.0) for floating-point types. This template form generates only single numbers.9
The second way to call cv::randu() is to provide a matrix mtx that you wish to have filled with values, and two additional arrays that specify the minimum and maximum values for the range from which you would like a random number drawn for each particular array element. These two additional values, low and high, should be 1 × 1 with 1 or 4 channels, or 1 × 4 with a single channel; they may also be of type cv::Scalar. In any case, they are not the size of mtx, but rather the size of individual entries in mtx.
The array mtx is both an input and an output, in the sense that you must allocate the matrix so that cv::randu() will know the number of random values you need and how they are to be arranged in terms of rows, columns, and channels.
cv::randn()
void cv::randn( cv::InputOutArray mtx, // All values will be randomized cv::InputArray mean, // mean values, array is in channel space cv::InputArray stddev // standard deviations, channel space );

The function cv::randn() fills a matrix mtx with random normally distributed values.10 The parameters from which these values are drawn are taken from two additional arrays (mean and stddev) that specify the mean and standard deviation for the distribution from which you would like a random number drawn for each particular array element.
As with the array form of cv::randu(), every element of mtx is computed separately, and the arrays mean and stddev are in the channel space for individual entries of mtx. Thus, if mtx were four channels, then mean and stddev would be 1 × 4 or 1 × 1 with four channels (or equivalently of type cv::Scalar).11
cv::randShuffle()
void cv::randShuffle( cv::InputOutArray mtx, // All values will be shuffled double iterFactor = 1, // Number of times to repeat shuffle cv::RNG* rng = NULL // your own generator, if you like );
cv::randShuffle() attempts to randomize the entries in a one-dimensional array by selecting random pairs of elements and interchanging their position. The number of such swaps is equal to the size of the array mtx multiplied by the optional factor iterFactor. Optionally, a random number generator can be supplied (for more on this, see “Random Number Generator (cv::RNG)” in Chapter 7). If none is supplied, the default random number generator theRNG() will be used automatically.
cv::reduce()
void cv::reduce( cv::InputArray src, // Input, n-by-m, 2-dimensional cv::OutputArray vec, // Output, 1-by-m or n-by-1 int dim, // Reduction direction 0=row, 1=col int reduceOp = cv::REDUCE_SUM, // Reduce operation (see Table 5-9) int dtype = -1 // Output type for result array );
With reduction, you systematically transform the input matrix src into a vector vec by applying some combination rule reduceOp on each row (or column) and its neighbor until only one row (or column) remains (see Table 5-9).12 The argument dim controls how the reduction is done, as summarized in Table 5-10.
| Value of op | Result |
|---|---|
cv::REDUCE_SUM |
Compute sum across vectors |
cv::REDUCE_AVG |
Compute average across vectors |
cv::REDUCE_MAX |
Compute maximum across vectors |
cv::REDUCE_MIN |
Compute minimum across vectors |
| Value of dim | Result |
|---|---|
0 |
Collapse to a single row |
1 |
Collapse to a single column |
cv::reduce() supports multichannel arrays of any type. Using dtype, you can specify an alternative type for dst.
Note
Using the dtype argument to specify a higher-precision format for dst is particularly important for cv::REDUCE_SUM and cv::REDUCE_AVG, where overflows and summation problems are possible.
cv::repeat()
void cv::repeat( cv::InputArray src, // Input 2-dimensional array int ny, // Copies in y-direction int nx, // Copies in x-direction cv::OutputArray dst // Result array ); cv::Mat cv::repeat( // Return result array cv::InputArray src, // Input 2-dimensional array int ny, // Copies in y-direction int nx // Copies in x-direction );

This function copies the contents of src into dst, repeating as many times as necessary to fill dst. In particular, dst can be of any size relative to src. It may be larger or smaller, and it need not have an integer relationship between any of its dimensions and the corresponding dimensions of src.
cv::repeat() has two calling conventions. The first is the old-style convention in which the output array is passed as a reference to cv::repeat(). The second actually creates and returns a cv::Mat, and is much more convenient when you are working with matrix expressions.
cv::scaleAdd()
void cv::scaleAdd( cv::InputArray src1, // First input array double scale, // Scale factor applied to first array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array );

cv::scaleAdd() is used to compute the sum of two arrays, src1 and src2, with a scale factor scale applied to the first before the sum is done. The results are placed in the array dst.
Note
The same result can be achieved with the matrix algebra operation:
dst = scale * src1 + src2;
cv::setIdentity()
void cv::setIdentity( cv::InputOutputArray dst, // Array to reset values const cv::Scalar& value = cv::Scalar(1.0) // Apply to diagonal elements );

cv::setIdentity() sets all elements of the array to 0 except for elements whose row and column are equal; those elements are set to 1 (or to value if provided). cv::setIdentity() supports all data types and does not require the array to be square.
Note
This can also be done through the eye() member function of the cv::Mat class. Using eye() is often more convenient when you are working with matrix expressions.
cv::Mat A( 3, 3, CV_32F ); cv::setIdentity( A, s ); C = A + B;
For some other arrays B and C, and some scalar s, this is equivalent to:
C = s * cv::Mat::eye( 3, 3, CV_32F ) + B;
cv::solve()
int cv::solve( cv::InputArray lhs, // Lefthand side of system, n-by-n cv::InputArray rhs, // Righthand side of system, n-by-1 cv::OutputArray dst, // Results array, will be n-by-1 int method = cv::DECOMP_LU // Method for solver );
The function cv::solve() provides a fast way to solve linear systems based on cv::invert(). It computes the solution to:

where A is a square matrix given by lhs, B is the vector rhs, and C is the solution computed by cv::solve() for the best vector X it could find. That best vector X is returned in dst. The actual method used to solve this system is determined by the value of the method argument (see Table 5-11). Only floating-point data types are supported. The function returns an integer value where a nonzero return indicates that it could find a solution.
| Value of method argument | Meaning |
|---|---|
cv::DECOMP_LU |
Gaussian elimination (LU decomposition) |
cv::DECOMP_SVD |
Singular value decomposition (SVD) |
cv::DECOMP_CHOLESKY |
For symmetric positive matrices |
cv::DECOMP_EIG |
Eigenvalue decomposition, symmetric matrices only |
cv::DECOMP_QR |
QR factorization |
cv::DECOMP_NORMAL |
Optional additional flag; indicates that the normal equations are to be solved instead |
The methods cv::DECOMP_LU and cv::DECOMP_CHOLESKY cannot be used on singular matrices. If a singular lhs argument is provided, both methods will exit and return 0 (a 1 will be returned if lhs is nonsingular). You can use cv::solve() to solve overdetermined linear systems using either QR decomposition (cv::DECOMP_QR) or singular value decomposition (cv::DECOMP_SVD) methods to find the least-squares solution for the given system of equations. Both of these methods can be used in case the matrix lhs is singular.
Though the first five arguments in Table 5-11 are mutually exclusive, the last option, cv::DECOMP_NORMAL, may be combined with any of the first five (e.g., by logical OR: cv_DECOMP_LU | cv::DECOMP_NORMAL). If provided, then cv::solve() will attempt to solve the normal equations: ![]() instead of the usual system
instead of the usual system ![]() .
.
cv::solveCubic()
int cv::solveCubic( cv::InputArray coeffs, cv::OutputArray roots );
Given a cubic polynomial in the form of a three- or four-element vector coeffs, cv::solveCubic() will compute the real roots of that polynomial. If coeffs has four elements, the roots of the following polynomial are computed:

If coeffs has only three elements, the roots of the following polynomial are computed:

The results are stored in the array roots, which will have either one or three elements, depending on how many real roots the polynomial has.
Note
A word of warning about cv::solveCubic() and cv::solvePoly(): the order of the coefficients in the seemingly analogous input arrays coeffs is opposite in the two routines. In cv::solveCubic(), the highest-order coefficients come last, while in cv::solvePoly() the highest-order coefficients come first.
cv::solvePoly()
int cv::solvePoly ( cv::InputArray coeffs, cv::OutputArray roots // n complex roots (2-channels) int maxIters = 300 // maximum iterations for solver );
Given a polynomial of any order in the form of a vector of coefficients coeffs, cv::solvePoly() will attempt to compute the roots of that polynomial. Given the array of coefficients coeffs, the roots of the following polynomial are computed:

Unlike cv::solveCubic(), these roots are not guaranteed to be real. For an order-n polynomial (i.e., coeffs having n+1 elements), there will be n roots. As a result, the array roots will be returned in a two-channel (real, imaginary) matrix of doubles.
cv::sort()
void cv::sort( cv::InputArray src, cv::OutputArray dst, int flags );
The OpenCV sort function is used for two-dimensional arrays. Only single-channel source arrays are supported. You should not think of this like sorting rows or columns in a spreadsheet; cv::sort() sorts every row or column separately. The result of the sort operation will be a new array, dst, which is of the same size and type as the source array.
You can sort on every row or on every column by supplying either the cv::SORT_EVERY_ROW or cv::SORT_EVERY_COLUMN flag. Sort can be in ascending or descending order, which is indicated by the cv::SORT_ASCENDING or cv::SORT_DESCENDING flag, respectively. One flag from each of the two groups is required.
cv::sortIdx()
void cv::sortIdx( cv::InputArray src, cv::OutputArray dst, int flags );
Similar to cv::sort(), cv::sortIdx() is used only for single-channel two-dimensional arrays. cv::sortIdx() sorts every row or column separately. The result of the sort operation is a new array, dst, of the same size as the source array but containing the integer indices of the sorted elements. For example, given an array A, a call to cv::sortIdx( A, B, cv::SORT_EVERY_ROW | cv::SORT_DESCENDING ) would produce:

In this toy case, every row was previously ordered from lowest to highest, and sorting has indicated that this should be reversed.
cv::split()
void cv::split( const cv::Mat& mtx, cv::Mat* mv ); void cv::split( const cv::Mat& mtx, vector<Mat>& mv // STL-style vector of n 1-channel cv::Mat's );
The function cv::split() is a special, simpler case of cv::mixChannels(). Using cv::split(), you separate the channels in a multichannel array into multiple single-channel arrays. There are two ways of doing this. In the first, you supply a pointer to a C-style array of pointers to cv::Mat objects that cv::split() will use for the results of the split operation. In the second option, you supply an STL vector full of cv::Mat objects. If you use the C-style array, you need to make sure that the number of cv::Mat objects available is (at least) equal to the number of channels in mtx. If you use the STL vector form, cv::split() will handle the allocation of the result arrays for you.
cv::sqrt()
void cv::sqrt( cv::InputArray src, cv::OutputArray dst );
As a special case of cv::pow(), cv::sqrt() will compute the element-wise square root of an array. Multiple channels are processed separately.
Note
There is also (sometimes) such thing as a square root of a matrix; that is, a matrix B whose relationship with some matrix A is that BB = A. If A is square and positive definite, then if B exists, it is unique.
If A can be diagonalized, then there is a matrix V (made from the eigenvectors of A as columns) such that A = VDV–1, where D is a diagonal matrix. The square root of a diagonal matrix D is just the square roots of the elements of D. So to compute A ½, we simply use the matrix V and get:

Math fans can easily verify that this expression is correct by explicitly squaring it:

In code, this would look something like:13
void matrix_square_root( const cv::Mat& A, cv::Mat& sqrtA ) {
cv::Mat U, V, Vi, E;
cv::eigen( A, E, U );
V = U.T();
cv::transpose( V, Vi ); // inverse of the orthogonal V
cv::sqrt(E, E); // assume that A is positively
// defined, otherwise its
// square root will be
// complex-valued
sqrtA = V * Mat::diag(E) * Vi;
}
cv::subtract()
void cv::subtract( cv::InputArray src1, // First input array cv::InputArray src2, // Second input array cv::OutputArray dst, // Result array cv::InputArray mask = cv::noArray(), // Optional, do only where nonzero int dtype = -1 // Output type for result array );

cv::subtract() is a simple subtraction function: it subtracts all of the elements in src2 from the corresponding elements in src1 and puts the results in dst.
cv::sum()
cv::Scalar cv::sum( cv::InputArray arr );

cv::sum() sums all of the pixels in each channel of the array arr. The return value is of type cv::Scalar, so cv::sum() can accommodate multichannel arrays, but only up to four channels. The sum for each channel is placed in the corresponding component of the cv::scalar return value.
cv::trace()
cv::Scalar cv::trace( cv::InputArray mat );

The trace of a matrix is the sum of all of the diagonal elements. The trace in OpenCV is implemented on top of cv::diag(), so it does not require the array passed in to be square. Multichannel arrays are supported, but the trace is computed as a scalar so each component of the scalar will be the sum over each corresponding channel for up to four channels.
cv::transform()
void cv::transform( cv::InputArray src, cv::OutputArray dst, cv::InputArray mtx );

The function cv::transform() can be used to compute arbitrary linear image transforms. It treats a multichannel input array src as a collection of vectors in what you could think of as “channel space.” Those vectors are then each multiplied by the “small” matrix mtx to affect a transformation in this channel space.
The mtx matrix must have as many rows as there are channels in src, or that number plus one. In the second case, the channel space vectors in src are automatically extended by one and the value 1.0 is assigned to the extended element.
Note
The exact meaning of this transformation depends on what you are using the different channels for. If you are using them as color channels, then this transformation can be thought of as a linear color space transformation. Transformation between RGB and YUV color spaces is an example of such a transformation. If you are using the channels to represent the x,y or x,y,z coordinates of points, then these transformations can be thought of as rotations (or other geometrical transformations) of those points.
cv::transpose()
void cv::transpose( cv::InputArray src, // Input array, 2-dimensional, n-by-m cv::OutputArray dst, // Result array, 2-dimensional, m-by-n );
cv::transpose() copies every element of src into the location in dst indicated by reversing the row and column indices. This function does support multichannel arrays; however, if you are using multiple channels to represent complex numbers, remember that cv::transpose() does not perform complex conjugation.
Summary
In this chapter, we looked at a vast array of basic operations that can be done with the all-important OpenCV array structure cv::Mat, which can contain matrices, images, and multidimensional arrays. We saw that the library provides operations ranging from very simple algebraic manipulations up through some relatively complicated features. Some of these operations are designed to help us manipulate arrays as images, while others are useful when the arrays represent other kinds of data. In the coming chapters, we will look at more sophisticated algorithms that implement meaningful computer vision algorithms. Relative to those algorithms, and many that you will write, the operations in this chapter will form the basic building blocks for just about anything you want to do.
Exercises
In the following exercises, you may need to refer to the reference manual for details of the functions outlined in this chapter.
-
This exercise will accustom you to the idea of many functions taking matrix types. Create a two-dimensional matrix with three channels of type
bytewith data size 100 × 100. Set all the values to0.-
Draw a circle in the matrix using
void cv::circle(InputOutputArray img, cv::point center, intradius, cv::Scalar color, int thickness=1, int line_type=8, int shift=0). -
Display this image using methods described in Chapter 2.
-
-
Create a two-dimensional matrix with three channels of type
bytewith data size 100 × 100, and set all the values to0. Use thecv::Matelement access functions to modify the pixels. Draw a green rectangle between (20, 5) and (40, 20). -
Create a three-channel RGB image of size 100 × 100. Clear it. Use pointer arithmetic to draw a green square between (20, 5) and (40, 20).
-
Practice using region of interest (ROI). Create a 210 × 210 single-channel
byteimage and zero it. Within the image, build a pyramid of increasing values using ROI andcv::Mat::setTo(). That is: the outer border should be0, the next inner border should be20, the next inner border should be40, and so on until the final innermost square is set to value200; all borders should be 10 pixels wide. Display the image. -
Use multiple headers for one image. Load an image that is at least 100 × 100. Create two additional headers that are ROIs where
width=20and theheight=30. Their origins should be at (5, 10) and (50, 60), respectively. Pass these new image subheaders tocv::bitwise_not(). Display the loaded image, which should have two inverted rectangles within the larger image. -
Create a mask using
cv::compare(). Load a real image. Usecv::split()to split the image into red, green, and blue images.-
Find and display the green image.
-
Clone this green plane image twice (call these
clone1andclone2). -
Find the green plane’s minimum and maximum value.
-
Set
clone1’s values tothresh = (unsigned char)((maximum - minimum)/2.0). -
Set
clone2to0and usecv::compare (green_image, clone1, clone2, cv::CMP_GE). Nowclone2will have a mask of where the value exceedsthreshin the green image. -
Finally, use
cv::subtract (green_image,thresh/2, green_image, clone2)and display the results.
-
1 Mathematically inclined readers will realize that there are other symmetrizing processes for matrices that are more “natural” than this operation, but this particular operation is useful in its own right—for example, to complete a symmetric matrix when only half of it was computed—and so is exposed in the library.
2 “COI” is an old concept from the pre-v2 library that meant “channel of interest.” In the old IplImage class, this COI was analogous to ROI (region of interest), and could be set to cause certain functions to act only on the indicated channel.
3 Long-time users of IPL should note that the function cvCvtColor() ignores the colorModel and channelSeq fields of the IplImage header. The conversions are done exactly as implied by the code argument.
4 Excluding 360, of course.
5 Actually, the Mahalanobis distance is more generally defined as the distance between any two vectors; in any case, the vector vec2 is subtracted from the vector vec1. Neither is there any fundamental connection between mat in cvMahalanobiscv::Mahalanobis() and the inverse covariance; any metric can be imposed here as appropriate.
6 At least in the case of the L2 norm, there is an intuitive interpretation of the difference norm as a Euclidean distance in a space of dimension equal to the number of pixels in the images.
7 Technically, it is possible that after multiplying by mtx, the value of w′ will be zero, corresponding to points projected to infinity. In this case, rather than dividing by zero, a value of 0 is assigned to the ratio.
8 Uniform-distribution random numbers are generated using the Multiply-With-Carry algorithm [Goresky03].
9 In particular, this means that if you call the template form with a vector argument, such as: cv::randu<Vec4f>, the return value, though it will be of the vector type, will be all zeros except for the first element.
10 Gaussian-distribution random numbers are generated using the Ziggurat algorithm [Marsaglia00].
11 Note that stddev is not a square matrix; correlated number generation is not supported by cv::randn().
12 Purists will note that averaging is not technically a proper fold in the sense implied here. OpenCV has a more practical view of reductions and so includes this useful operation in cvReduce.
13 Here “something like” means that if you were really writing a responsible piece of code, you would do a lot of checking to make sure that the matrix you were handed was in fact what you thought it was (i.e., square). You would also probably want to check the return values of cv::eigen() and cv::invert(), think more carefully about the actual methods used for the decomposition and inversion, and make sure the eigenvalues were positive before blindly calling sqrt() on them.