
C H A P T E R 18
Building Robust Solutions
The egoism which enters into our theories does not affect their sincerity; rather, the more our egoism is satisfied, the more robust is our belief.
—Novelist George Eliot
Developing an SSIS package typically focuses on the known—the data source, transformations, and destinations—and fails to address the unknown—schema changes, data type mismatches, and a changing network environment. Obviously, all development must come from a starting point—the known. However, in order to ensure that an SSIS package provides portability, stability, and resilience, it is critical to handle the unknown and to record the unidentified and inconsistent behavior. This chapter outlines the steps necessary to plan and handle the unexpected within an SSIS package.
What Makes a Solution Robust
Quite often an SSIS solution is created to fulfill an easily defined process in a specific and static environment. The source and destination schema are considered immutable and unchanging, and there is no accounting for change or error. This type of project is effortlessly created and quickly deployed, but frequently the developer fails to play what if in such cases and thus provides little means for the following:
- Tracking of:
- Performance
- Error information
- Historic metrics
- Handling variations to:
- Sources
- Connections
- Schema
- Portability and ease of deploying to different environments
There are several factors to be considered when attempting to create a robust solution:
Resilience: The capability of a package to proactively deal with errors, document them, and still complete
Dynamism: The capability to deal with a dynamic fluid environment based on a set of rules and not static numbers, paths, or connections
Accountability: The capability to record the behavior of steps within a package, allowing historic performance to be tracked
Portability: The capability to easily deploy a package to different environments without having to overhaul each step and connection
Taking these factors into consideration during package development can streamline troubleshooting and deployment/migration, as well as the tracking of historic performance.
Resilience
Errors can occur within an SSIS task for various reasons, and how they are handled depends on the specific task. For example, a Script task can handle errors easily and efficiently by using try-catch-finally blocks and can provide a means of dynamic error handling, whereas an FTP task has a limited means of proactive error handling. To ensure resiliency, tasks should provide a means of preemptive error handling and a way to reprocess tasks after an error is handled.
Data Flow Task
One of the most commonly used SSIS tasks is also one of the more difficult to incorporate error handling. A Data Flow task is the backbone of the ETL process, but lacks true structured error handling within the data flow. A prime example of this is the occurrence of a truncation error from source or transformation to destination. In this situation, there is no way to dynamically handle the error, but you can redirect the affected row to another destination, where additional evaluation can be done to ensure a successful import.
This can be easily exhibited by creating a package that contains an Execute SQL task and a Data Flow task connected by the Execute SQL tasks with an on success precedent constraint. The Execute SQL task, renamed Create People Tbl, will create a destination table in the default instance by using the AdventureWorks 2012 database with the following query:
IF NOT EXISTS( SELECT * FROM sys.tables WHERE name = 'People')
BEGIN
CREATE TABLE People(
FirstName NVARCHAR(50),
MiddleName NVARCHAR(50),
LastName NVARCHAR(21)
)
END;
GO
After the Execute SQL task has been configured, change the name of the Data Flow task to Populate People. The control flow pane of the package should resemble Figure 18-1.

Figure 18-1. Data flow error redirection in the control flow pane
In the data flow pane, add an OLE DB source, OLE DB destination, Flat File destination, and a Data Conversion transformation. The OLE DB source should be renamed AdventureWorks Person and configured to connect to the default instance of SQL and use the AdventureWorks 2012 database. In the table selection drop-down list, select the Person schema’s Person table, as shown in Figure 18-2.

Figure 18-2. Data flow source
From the columns, only the FirstName, MiddleName, and LastName columns should be selected, as depicted in Figure 18-3.
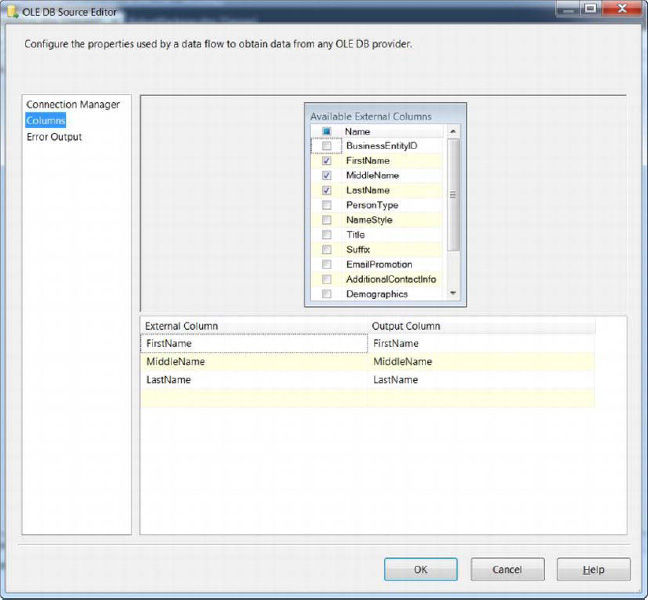
Figure 18-3. Selecting the data flow source column
Connect the data flow path from the OLE DB source to the data conversion task and rename the task Convert LastName. In the editor for the transformation task, select LastName from the available input columns and set the output alias to Coverted LastName and length to 20. This causes a single row from the source to be truncated, as shown in Figure 18-4.
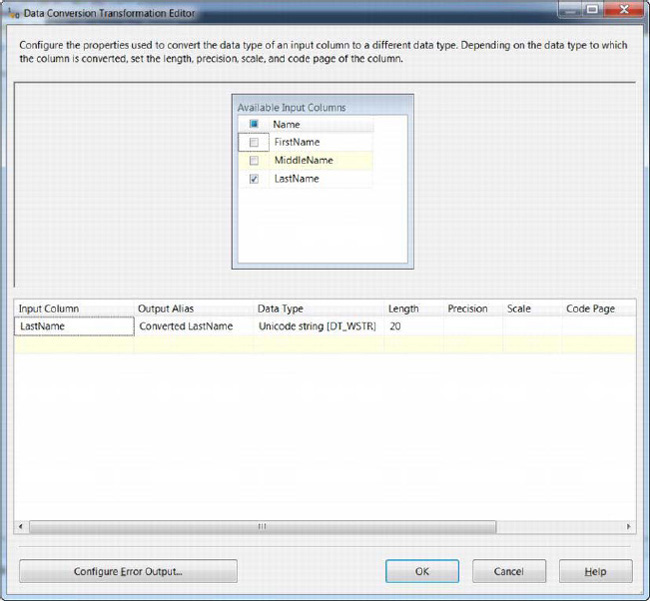
Figure 18-4. Data transformation task
To configure the error output, first open the editor by clicking the Configure Error Output button. of the data conversion task and change the Error and Truncation values from “Fail componenet” to “Redirect row,” as shown in Figure 18-5.

Figure 18-5. Data transformation error output
Connect the data transformation task error flow to the flat file destination and name the destination Errors. Configure a new Flat File Connection Manager named Errors File to write to the path C:RobustPeopleErrors.txt, as shown in Figure 18-6.
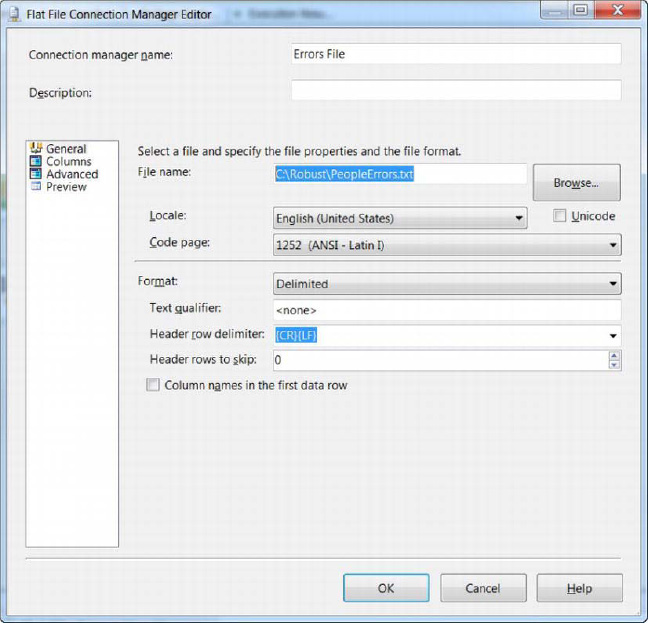
Figure 18-6. Flat File Connection Manager
In order to ensure that an error is not raised due to truncation from the transformation to the Errors file destination, select the Advanced configuration and make sure that the LastName column is set to Unicode String with a column width of 50, as shown in Figure 18-7.
![]() NOTE: Adjust the target filename of the destination as needed to ensure that the path is valid.
NOTE: Adjust the target filename of the destination as needed to ensure that the path is valid.

Figure 18-7. Advanced destination editor
Finally, connect the data flow from the Convert LastName transformation task to the OLE DB destination. Open the destination editor, change the name to People Table and select the dbo.People table as the destination table. From the mappings editor, change the LastName input mapping column to the Converted LastName column, as illustrated in Figure 18-8.

Figure 18-8. OLE DB Destination editor
The final data flow pane should resemble Figure 18-9.
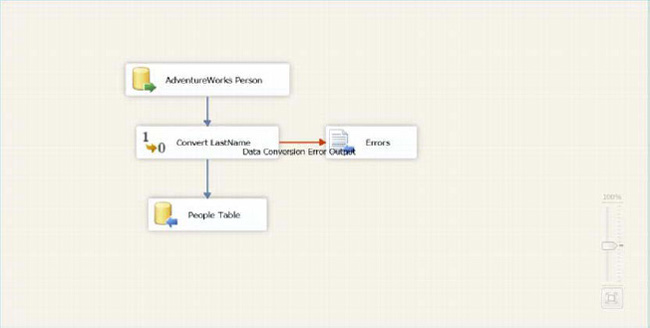
Figure 18-9. Data flow editor pane
When running the package, the data flow should show that 19,971 rows were successfully sent to the People Table destination, and one row to the Errors flat file destination. Instead of the Data Flow task failing due to a truncation error of a single row, the task completes and the row is still available for later processing in the flat file destination.
Although this error cannot be processed from within the Data Flow task, the fact that the redirected row contains not only the original data, but also the error code and error column in the flat file destination does provide a means of dynamic handling outside of the Data Flow task.
The ability to dynamically handle data flow errors can still be implemented, although outside of the Data Flow task, by incorporating various package components. Adding a package-level variable and using a Row Count transformation between the Convert LastName data transformation and the Error Count Data source in the Data Flow task provides the capability of utilizing a Script task to later evaluate the error flat file. Figure 18-10 displays the tasks within the Data Flow task. Figure 18-11 illustrates the control flow pane with the precedent constraint using an expression to evaluate whether the variable, Error, is greater than 0.
![]() TIP: Make sure that the redirected rows are sent to a flexible destination. Creating a table with an identical schema as that of the intended destination will only cause the redirected row to fail again for truncation or constraint errors. In addition to the failed rows, the error description can be included in an additional column.
TIP: Make sure that the redirected rows are sent to a flexible destination. Creating a table with an identical schema as that of the intended destination will only cause the redirected row to fail again for truncation or constraint errors. In addition to the failed rows, the error description can be included in an additional column.

Figure 18-10. Data flow editor pane

Figure 18-11. Control flow editor pane
As shown in Figure 18-11, the script component will be executed only if the Populate People Data Flow task completes successfully, and if the Row Count transformation incremented the Error variable. The following code illustrates how a Script task can be used to parse the redirected error rows from the text file by using the TextFieldParser class:
Public Sub Main()
Dim rdr As New TextFieldParser("C:RobustPeopleErrors.txt")
rdr.TextFieldType = FileIO.FieldType.Delimited
rdr.SetDelimiters(",")
Dim row As String()
While Not rdr.EndOfData
Try
row = rdr.ReadFields()
MessageBox.Show(row(0).ToString)
Catch ex As Microsoft.VisualBasic.FileIO.MalformedLineException
MsgBox("Line " & ex.Message & _
"is not valid and will be skipped.")
End Try
End While
Dts.TaskResult = ScriptResults.Success
End Sub
The MessageBox returns the indexed value of the error number from the row string array, which can be used to identify the specific cause. Obviously, to dynamically handle the error requires additional code, but armed with the error codes and descriptions (provided in the following Tip), a VB.NET Select Case statement can be included to iterate through the error codes, and based on the error, the appropriate action can be taken.
Event Handlers
Event handlers provide a means to proactively handle events on packages and executables and can be used to capture task-specific information for the following events:
OnErrorOnExecStatusChangeOnExecutionOnPostExecuteOnPostValidateOnPreExecuteOnPreValidateOnQueryCancelOnTaskFailedOnVariableValueChangedOnWarning
An OnError event handler can be used to capture the error description and code, which can then be used to dynamically handle errors as well as record more in-depth information into the specific issue. Because event handlers are available only on executables and packages, this precludes their use from within the data flow, but can capture the failure of the data flow executable. In order for the OnError event handler to be reached, the Data Flow task must first fail, which will expel all data from the buffers, making it unavailable for later investigation.
Processing the error information within the event handler can be done most easily with a Script task passing in System:ErrorCode and System:ErrorDescription as read-only variables. Chapter 11 outlined how to create a Script task to capture error information and provided a demonstration of the OnError event bubbling up from the task level all the way to the package level. Obviously, a more complex type of logic would need to be incorporated within the script component to proactively address the specific error.
The package outlined in the preceeding sectionabove uses error redirection in the Data Flow task to prevent errors from arising and to ensure that all rows are directed to a destination. If the same package was created without redirecting the row, an OnError event handler could be used to capture the error information. Adding a Script task to the OnError event and setting the System:ErrorDescripton as a ReadOnly variable will allow the ability to capture the entire error message and provides more insight into the true cause. Using the following VB.NET code will display the message of any error that occurs within the Data Flow task:
MessageBox.Show(Dts.Variables(0).Value.ToString)
The resulting message box specifies the truncation error as well as the specific affected column. The primary difference between error redirection and the OnError event handler is that if error redirection is used, the OnError event handler will not be raised. In the preceding example, the Data Flow task stops after the truncation error occurs, and the failing row information would not be stored for later evaluation.
![]() TIP: SSIS error messages and numbers are outlined at
TIP: SSIS error messages and numbers are outlined at http://msdn.microsoft.com/en-us/library/ms345164.aspx.
Dynamism
Beginning with SSIS 2005, configuration enabled you to make a package more portable and to easily import a package into multiple instances of SQL without requiring you to create multiple packages or to specifically configure a package for its environment. This capability has been streamlined even more in SSIS 2012 with the introduction of parameters.
Environments allow the mapping of parameters to their variables and can be used to execute a single package in multiple environments. It is common to be required to develop a package in one environment, test in another, and finally deploy to production. This kind of scenario shows the true flexibility and power of using environments in SSIS.
Parameters and environments are outlined in Chapter 19, with examples of dynamic package execution.
Accountability
After a package has been deployed and running for some time, you often have to see how each task is fairing “in the wild.” I often get requests as to the total or average number of rows that are passed through a single data flow or how long a single task is taking. Although it can be easy to ascertain package run times that are scheduled within a SQL Server agent, separating task times and counts is not as simple.
Log Providers
Chapter 11 outlined configuring log providers and the saving of package execution information within a specific provider, XML, SQL, CSV, and so forth. Log providers can also be used to provide general task metrics, such as execution time. Log providers enable you to capture information that is raised by an event handler. For example, selecting the OnPreExecute and OnPostExecute events provides a means of tracking the general start and end time of tasks within a package.
Configuration of log providers is done from within the control flow pane by right-clicking and choosing Log Providers. The initial window requires defining the executable to log and in which format the log is to be written, such as XML, SQL or any supported format. After the executable and destination is configured, the event handlers can be selected, as well as the specific columns to collect. Figure 18-12 illustrates the event handlers available through the log provider.

Figure 18-12. Log provider events
Using a SQL log provider for the selected events allows querying the data to find the specific task durations. Each package has its own GUID, as does each task, so utilizing a common table expression with the DATEDIFF function quickly returns the associated task’s execution time. The following query uses the table created through the log shipping configuration to find the difference between the start and end time of the specific package identified by its GUID. The results are displayed in Figure 18-13.
WITH eventexecution
AS(
SELECT sourceid ,
starttime
FROM sysssislog
WHERE executionid = 'B0885A09-A1BA-4638-9999-29698F357B40'
AND event = 'OnPreExecute'
)
SELECT source,
DATEDIFF(SECOND, c.starttime, endtime) AS 'seconds'
FROM sysssislog s JOIN eventexecution c
ON s.sourceid = c.sourceid
WHERE event = 'OnPostExecute';
GO

Figure 18-13. Task duration query results
Custom Logging
Although log providers can capture a great deal of information in regards to package execution, some measures are missed, such as data flow row counts. Another common request is to show the total rows affected in a Data Flow task over time. Counts such as this are not included in SSIS log providers but can still be captured using custom logging.
The first step is creating a table that will hold the custom logged information, which in this example will be the package GUID, package name, task name, destination name, number of rows, and the date the task ran. For example:
IF NOT EXISTS(SELECT * FROM sys.tables WHERE name = 'SSISCounts')
BEGIN
CREATE TABLE SSISCounts(
ExecGUID NVARCHAR(50),
PackageName NVARCHAR(50),
TaskName NVARCHAR(50),
DestinationName NVARCHAR(50),
NumberRows INT,DateImported DATETIME2)
END;
GO
A package-level variable needs to be created that will hold the row count of all Data Flow tasks that is of a data type integer. Each Data Flow task should include a Row Count transformation immediately before the destination that uses the package-level variable to record imported rows.

Figure 18-14. Row count transformation
Finally, in the PostExecute event handler of the Data Flow tasks, create an Execute SQL task that will insert the appropriate information using both system and user-defined variables. Clicking the event handlers opens the EventHandlers pane and provides two drop-downs, Executable and Event Handler, as shown in Figure 18-15. After the executable is selected, the desired event handler can be selected and the specific task can be placed on the pane.

Figure 18-15. Execute SQL task parameter configuration
The Execute SQL task will be used to insert the count information from the Data Flow task with information that is system provided and user provided. The system-provided information is the package GUID, name, task, and the row count, and the database and time will be supplied within the query. The SQLStatement property should be set to utilize the parameters that will be defined in the task by using a question mark (?), as shown in the following code:
INSERT SSISCounts
VALUES(?, ?, ?, 'AdventureWorks2012DW', ?, SYSDATETIME())
The parameters should be organized in the same ordinal position as they appear in the query in the Execute SQL Task Editor. Figure 18-16 depicts the parameter configuration. Note that the parameter name is replaced with the index position of the variables as they appear in the insert statement.
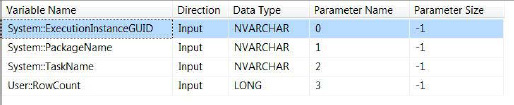
Figure 18-16. Execute SQL task parameter configuration
There is typically confusion in the mapping of the parameters to the ? in the SQL statement property. From the preceding figure, remember that the first parameter defined, in this case ExecutionInstanceGUID, will go where the first question mark occurs, and each parameter will follow in order. The insert statement could be rewritten, for demonstration purposes only, to better visualize this, as shown in the following code:
INSERT SSISCounts
VALUES(ExecutionInstanceGUID, PackageName, TaskName,
'AdventureWorks2012DW', RowCount, SYSDATETIME())
The preceding example demonstrates that using both system and user-defined variables in cooperation with event handlers can provide a means of custom logging. The information contained within the SSISCounts table can be used to establish a means of tracking the number of records added by the data flow and tracking the specific tasks.
Summary
This chapter presented ways to ensure durability, portability, and resiliency in SSIS packages and tasks. Many of the methods discussed in this chapter are extensions of features that are outlined throughout this book. The key concept to creating robust solutions is to do the following:
- Plan for the unknown.
- Proactively handle possible errors.
- Provide error redirection for data flow.
- Configure packages and tasks to be portable.
- Record error and metric package and task information.