
 CHAPTER 11
CHAPTER 11
Divide and Conquer: Advanced Techniques
C. LEÓN, G. MIRANDA, and C. RODRÍGUEZ
Universidad de La Laguna, Spain
11.1 INTRODUCTION
The divide-and-conquer (DnC) technique is a general method used to solve problems. Algorithms based on this technique divide the original problem in to smaller subproblems, solve them, and combine the subsolutions obtained to get a solution to the original problem. The scheme of this technique can be generalized to develop software tools that allow the analysis, design, and implementation of solvers for specific problems. Unfortunately, in many applications it is not possible to find a solution in a reasonable time. Nevertheless, it is possible to increase the size of the problems that can be approached by means of parallel techniques.
There are several implementations of general-purpose schemes using object-oriented paradigms [1–4]. Regarding divide and conquer, we can mention the following: Cilk [5] based on the C language and Satin [6] codified in Java. Satin [7] is a Java framework that allows programmers to easily parallelize applications based on the divide-and-conquer paradigm. The ultimate goal of Satin is to free programmers from the burden of modifying and hand-tuning applications to exploit parallelism. Satin is implemented on top of Ibis [8], a programming environment with the goal of providing an efficient Java-based platform for grid programming. Ibis consists of a highly efficient communication library and a variety of programming models, mostly for developing applications as a number of components exchanging messages through messaging protocols such as MPI [9]. The MALLBA [10, 11] project is an effort to develop an integrated library of skeletons for combinatorial optimization, including exact, heuristic, and hybrid techniques. A skeleton [12] is a parameterized program schema with efficient implementations over diverse architectures. MALLBA allows the combined and nested use of all of its skeletons. Also, sequential and parallel execution environments are supported. This work focuses on the skeleton approach to parallel programming instead of the one based on programming language extensions. The skeleton approach can be viewed as an alternative to the current practice of low-level programming for parallel machines. Nevertheless, the formalism employed to define skeletons such as higher-order functions [13] do not comprise our objectives.
The MALLBA::DnC skeleton requires from the user the implementation of a C++ class Problem defining the problem data structures, a class Solution to represent the result, and a class SubProblem to specify subproblems. In some cases an additional Auxiliar class is needed to represent the subproblems in case they do not have exactly the same structure as the original problem.
In the SubProblem class the user has to provide the methods easy(), solve(), and divide(). The easy() function checks if a problem is simple enough to apply the simple resolution method solve(). The divide() function must implement an algorithm to divide the original problem into smaller problems with the same structure as that of the original problem.
The class Solution has to provide an algorithm to put together partial solutions in order to obtain the solution to a larger problem through the combine() function. MALLBA::DNC provides a sequential resolution pattern and a message-passing master–slave resolution pattern for distributed memory machines [14, 15]. This work presents a new fully distributed parallel skeleton that provides the same user interface and consequently is compatible with codes already implemented. The new algorithm is a MPI asynchronous peer–processor implementation where all the processors are peers and behave in the same way (except during the initialization phase) and where decisions are taken based on local information.
The contents of the chapter are as follows. In Section 11.2 we describe the data structures used to represent the search space and the parallel MPI skeleton. To clarify the tool interface and flexibility, two problem implementation examples are introduced and discussed in Section 11.3. Conclusions and future prospectives are noted in Section 11.4.
11.2 ALGORITHM OF THE SKELETON
The algorithm has been implemented using object-oriented and message-passing techniques. Figure 11.1 graphically displays the data structure used to represent the tree space. It is a tree of subproblems (sp) where each node has a pointer to its father, the solution of the subproblem (sol), and the auxiliary variable (aux) for the exceptional cases when the subproblems do not have the same structure as the original problem. Additionally, a queue with the nodes pending to be explored is kept (p and n). The search tree is distributed among the processors. Registered in each node is the number of unsolved children and the number of children sent to other processors (remote children). Also, an array of pointers to the solutions of the children nodes (subsols) is kept. When all the children nodes are solved, the solution of the actual node, sol, will be calculated combining the partial solutions stored in subsols. The solution is sent up to the father node in the tree and the partial solutions are disposed of. Since the father of a node can be located in another processor, the rank of the processor owning the father is stored on each node. Implementation of the algorithmic skeleton has been divided into two stages: initialization and resolution.

Figure 11.1 Data structure for the tree space.
11.2.1 Initialization Stage
The data required to tackle resolution of a problem are placed into the processors. Initially, only the master processor (master) has the original problem and proceeds to distribute it to the remaining processors. Next, it creates the node representing the initial subproblem and inserts it into its queue. All the processors perform monitor and work distribution tasks. The state of the set of processors intervening in the resolution is kept by all the processors. At the beginning, all the processors except master are idle. Once this phase is finished, all the processors behave in the same way.
11.2.2 Resolution Stage
The goal of the resolution stage is to find a solution to the original problem. The majority of the skeleton tasks occur during this phase. The main aim of the design of the skeleton has been to achieve a balanced distribution of the workload. Furthermore, such an arrangement is performed in a fully distributed manner using only asynchronous communication and information that is local to each processor, avoiding in this way the use of a central control and synchronization barriers.
The control developed is based on a request–answer system. When a processor is idle, it requests work from the remaining processors. This request is answered by the remaining processors either with work or with a message indicating their inability to send work. Since the state of the processors has to be registered locally, each sends its answer not only to the processor requesting work but also to those remaining, informing them of the answer (whether work was or was not sent) and to which processor it was sent. This allows us to keep the state of busy or idle updated for each processor. According to this approach, the algorithm would finish when all the processors are marked idle. However, since request and answer messages may arrive in any arbitrary order, a problem arises: The answers may arrive before the requests or messages referring to different requests may be tangled. Additionally, it may also happen that a message is never received if the processors send a message corresponding to the resolution phase to a processor which has decided that the others are idle.
To cope with these problems, a turn of requests is associated with each processor, assigning a rank or order number to the requests in such a way that it can be determined which messages correspond to what request. They also keep a counter of pending answers. To complete the frame, additional constraints are imposed on the issue of messages:
- A processor that becomes idle performs a single request until it becomes busy again. This avoids an excess of request messages at the end of the resolution phase.
- A processor does not perform any request while the number of pending answers to its previous request is not zero. Therefore, work is not requested until checking that there is no risk to acknowledge work corresponding to a previous request.
- No processor sends messages not related to this protocol while it is idle.
Although the former restrictions solve the aforementioned protocol problems, a new problem has been introduced: If a processor makes a work request and none sends work as answer, that processor, since it is not allowed to initiate new petitions, will remain idle until the end of the stage (starvation). This has been solved by making the busy processors, when it is their turn to communicate, check if there are idle processors without pending answers to their last petition and, if there is one and they have enough work, to force the initiation of a new turn of request for that idle processor. Since the processor(s) initiating the new turns are working, such messages will be received before any subsequent messages for work requests produced by it (them), so there is no danger of a processor finishing the stage before those messages are received, and therefore they will not be lost.
The pseudocode in Algorithm 11.1 shows the five main tasks performed in this phase. The “conditional communication” part (lines 3 to 23) is in charge of the reception of all sort of messages and the work delivery. The communication is conditional since it is not made per iteration of the main loop but when the condition time to communicate takes a true value. The goal of this is to limit the time spent checking for messages, assuring a minimum amount of work between communications. The current implementation checks that the time that has passed is larger than a given threshold. The threshold value has been established as a small value, since for larger values the workload balance gets poorer and subsequent delay of the propagation of bounds leads to the undesired exploration of nonpromising nodes.
Algorithm 11.1 Resolution Phase Outline

Inside the “message reception” loop (lines 5 to 21) the labels to handle the messages described in previous paragraphs are specified. Messages of the type CHILD_SOL_MSG are used to communicate the solution of a subproblem to the receiver processor.
The “computing subproblems” part (line 24) is where the generic divide-and-conquer algorithm is implemented. Each time the processor runs out of work, one and only one “work request” (line 25) is performed. This request carries the beginning of a new petition turn. To determine the “end of the resolution phase” (line 26) there is a check that no processor is working and that there are no pending answers. Also, it is required that all the nodes in the tree have been removed. In this case the problem is solved and the optimal solution has been found. The last condition is needed because the algorithm does not establish two separate phases for the division and combination processes, but both tasks are made coordinately. Therefore, if some local nodes have not been removed, there are one or more messages with a partial solution (CHILD_SOL_MSG) pending to be received, to combine them with the not-deleted local nodes.
Algorithm 11.2 shows the computing task in more depth. First, the queue is checked and a node is removed if it is not empty. If the subproblem is easy (lines 4 to 16), the user method solve() is invoked to obtain the partial solution. Afterward, the call to combineNode() will combine all the partial solutions that are available. The combineNode() method inserts the solution received as a parameter in the array of partial solutions subsols in the father node. If after adding this new partial solution the total number of subsolutions in the father node is completed, all of them are combined using the user method combine(). Then the father node is checked to determine if the combination process can be applied again. The combination process stops in any node not having all its partial solutions or when the root node is reached. This node is returned by the combineNode() method. If the node returned is the root node (it has no father) and the number of children pending to solutions is zero, the problem is solved (lines 8 to 11). If the node has no unsolved children but is an intermediate node, its father must be in another processor (lines 12 to 15). The solution is sent to this processor with a CHILD_SOL_MSG message, and it continues from this point with the combination process. If the subproblem removed from the queue is not simple (lines 16 to 21), it is divided into new subproblems using the divide() method provided by the user. The new subproblems are inserted at the end of the queue. To traverse the tree in depth, the insert and remove actions in the queue are always made at the end. This is a faster way to combine partial solutions and a more efficient use of memory.
Algorithm 11.2 Divide-and-Conquer Computing Tasks

11.3 EXPERIMENTAL ANALYSIS
The experiments were performed instantiating the MALLBA::DnC skeleton for some classic divide-and-conquer algorithms: sorting (quicksort and mergesort), convex hull, matrix multiplication, fast Fourier transform, and huge integer product. Results were taken on a heterogeneous PC network, configured with four 800-MHz AMD Duron processors and seven AMD-K6 3D 500-MHz processors, each with 256 Mbytes of memory and a 32-Gbyte hard disk. The operating system installed was Debian Linux version 2.2.19 (herbert@gondolin), the C++ compiler used was GNU gcc version 2.95.4, and the message-passing library was mpich version 1.2.0.
Figure 11.2 shows the speedups obtained for the huge integer product implementation with a problem of size 4096. The parallel times were the average of five executions. The experiments labeled “ULL 500 MHz” and “ULL 800 MHz” were carried out on a homogeneous set of machines of sizes 7 and 4, respectively. ULL 800-500 MHz depicts the experiment on a heterogeneous set of machines where half the machines (four) were at 800 MHz and the other half were at 500 MHz. The sequential execution for the ULL 800–500 MHz experiment was performed on a 500-MHz processor. To interpretate the ULL 800–500 MHz line, take into account that the ratio between the sequential executions was 1.53. For eight processors the maximum speedup expected will be 10.12; that is, 1.53 × 4(fast processors) +4 (slow processors); see Figure 11.2(b). Comparing the three experiments depicted [Figure 11.2 (c)], we conclude that the algorithm does not experiment any loss of performance due to the fact of being executed on a heterogeneous network. Figure 11.3(a) represents the average number of nodes visited, for the experiment labeled “ULL 800–500 MHz.” It is clear that an increase in the number of processors carries a reduction in the number of nodes visited. This shows the good behavior of the parallel algorithm.

Figure 11.2 Times and speedup for the huge integer product, n = 4096: (a) homogeneous case; (b) heterogeneous case; (c) speedups.
A parameter to study is the load balance among the different processors intervening in the execution of the algorithm. Figure 11.3(b) shows the per processor average of the number of visited nodes for the five executions. Observe how the slow processors examine fewer nodes than the faster ones. It is interesting to compare these results with those appearing in Figure 11.3(c), corresponding to the homogeneous executions. Both pictures highlight the fairness of the workload distribution.

Figure 11.3 Nodes visited for the huge integer product: (a) average number of nodes visited (800–500 MHz); (b) heterogeneous case (800–500 MHz); (c) homogeneous case (500 MHz).
Similar results are obtained for implementation of the other algorithms. Figures 11.4 and 11.5 present the same study for Strassen's matrix product algorithm. Even though the grain is finer than in the previous example, the performance behavior is similar.
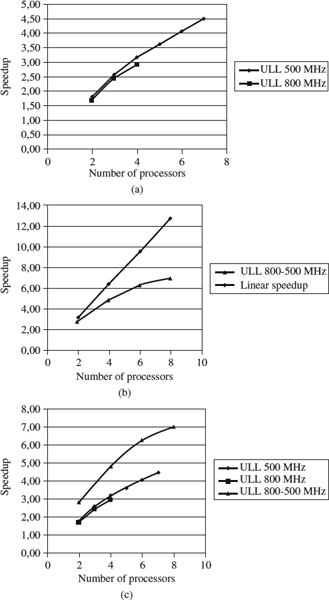
Figure 11.4 Times and speedup for Strassen's matrix multiplication (n = 512): (a) homogeneous case; (b) heterogeneous case; (c) speedups.

Figure 11.5 Nodes visited for Strassen's matrix multiplication: (a) average number of nodes visited (800–500 MHz); (b) heterogeneous case (800–500 MHz); (c) homogeneous case (500 MHz).
11.4 CONCLUSIONS
In this work chapter we describe a parallel implementation of a skeleton for the divide-and-conquer technique using the message-passing paradigm. The main contribution of the algorithm is the achievement of a balanced workload among the processors. Furthermore, such an arrangement is accomplished in a fully distributed manner, using only asynchronous communication and information local to each processor. To this extent, the use of barriers and a central control has been avoided. The results obtained show good behavior in the homogeneous and heterogeneous cases. Ongoing work focuses on lightening the replication of information relative to the state of a certain neighborhood. An OpenMP [16]-based resolution pattern for shared memory has also been developed. Due to the fine-grained parallelism scheme required for implementation, the results obtained are not scalable.
Acknowledgments
This work has been supported by the EC (FEDER) and by the Spanish Ministry of Education and Science under the Plan Nacional de I+D+i, contract TIN2005-08818-C04-04. The work of G. Miranda has been developed under grant FPU-AP2004-2290.
REFERENCES
1. J. Anvik and et al. Generating parallel programs from the wavefront design pattern. In Proceedings of the 7th International Workshop on High-Level Parallel Programming Models and Supportive Environments (HIPS'02), Fort Lauderdale, FL, 2002.
2. B. Le Cun, C. Roucairol, and TNN Team. BOB: a unified platform for implementing branch-and-bound like algorithms. Technical Report 95/016. PRiSM, Université de Versailles, France, 1995.
3. A. Grama and V. Kumar. State of the art in parallel search techniques for discrete optimization problems. Knowledge and Data Engineering, 11(1):28–35, 1999.
4. H. Kuchen. A skeleton library. In Proceedings of Euro-Par, vol. 2400 of Lecture Notes in Computer Science. Springer-Verlag, New York, 2002, pp. 620–629.
5. T. Kielmann, R. Nieuwpoort, and H. Bal. Cilk-5.3 Reference Manual. Supercomputing Technologies Group, Cambridge, MA, 2000.
6. T. Kielmann, R. Nieuwpoort, and H. Bal. Satin: efficient parallel divide-and-conquer in Java. In Proceedings of Euro-Par, vol. 1900 of Lecture Notes in Computer Science. Springer-Verlag, New York, 2000, pp. 690–699.
7. R. Nieuwpoort, J. Maassen, T. Kielmann, and H. Bal. Satin: simple and efficient Java-based grid programming. Scalable Computing: Practice and Experience, 6(3):19–32, 2005.
8. R. Nieuwpoort and et al. Ibis: a flexible and efficient Java-based grid programming environment. Concurrency and Computation: Practice and Experience, 17(7–8):1079–1107, 2005.
9. M. Snir, S. W. Otto, S. Huss-Lederman, D. W. Walker, and J. J. Dongarra. MPI: The Complete Reference. MIT Press, Cambridge, MA, 1996.
10. E. Alba and et al. MALLBA: A library of skeletons for combinatorial optimization. In Proceedings of Euro-Par, vol. 2400 of Lecture Notes in Computer Science. Springer-Verlag, New York, 2002, pp. 927–932.
11. E. Alba et al. Efficient parallel LAN/WAN algorithms for optimization: the MALLBA project. Parallel Computing, 32:415–440, 2006.
12. M. Cole. Algorithmic skeletons: a structured approach to the management of parallel computation. Research Monographs in Parallel and Distributed Computing. Pitman, London, 1989.
13. S. Gorlatch. Programming with divide-and-conquer skeletons: an application to FFT. Journal of Supercomputing, 12(1–2):85–97, 1998.
14. I. Dorta, C. León, and C. Rodríguez. A comparison between MPI and OpenMP branch-and-bound skeletons. In Proceedings of the 8th International Workshop on High Level Parallel Programming Models and Supportive Environments. IEEE Computer Society Press, Los Alamitos, CA, 2003, pp. 66–73.
15. I. Dorta, C. León, C. Rodríguez, and A. Rojas. Parallel skeletons for divide-and-conquer and branch-and-bound techniques. In Proceedings of the 11th Euromicro Conference on Parallel, Distributed and Network Based Processing, Geneva, 2003, pp. 292–298.
16. OpenMP Architecture Review Board. OpenMP C and C++ Application Program Interface, Version 1.0. http://www.openmp.org, 1998.
Optimization Techniques for Solving Complex Problems, Edited by Enrique Alba, Christian Blum, Pedro Isasi, Coromoto León, and Juan Antonio Gómez
Copyright © 2009 John Wiley & Sons, Inc.