
 CHAPTER 26
CHAPTER 26
Remote Services for Advanced Problem Optimization
J. A. GÓMEZ, M. A. VEGA, and J. M. SÁNCHEZ
Universidad de Extremadura, Spain
J. L. GUISADO
Universidad de Sevilla, Spain
D. LOMBRAÑA and F. FERNÁNDEZ
Universidad de Extremadura, Spain
26.1 INTRODUCTION
In this chapter we present some remote services for advanced problem optimization. These tools permit us to get a set of resources useful to approach problems easily using the Internet as a channel of experimentation with the optimization algorithms involved.
The chapter is structured as follows. Section 26.2 covers the development of image-processing services via the Internet by means of algorithms implemented by software and reconfigurable hardware. In this way, advanced optimization techniques are used to implement the image-processing algorithms by custom-designed electronic devices, and an open platform is offered to the scientific community, providing the advantages of reconfigurable computing anywhere. Next, in Section 26.3 two web services using time series as optimization subjects are presented. The optimization algorithms are driven by the remote user, and the results are shown in graphical and tabular forms. Finally, Section 26.4 demonstrates the Abacus-GP tool: a web platform developed to provide access to a cluster to be used by researchers in the genetic programming area.
26.2 SIRVA
In this section we present the results obtained inside the research line SIRVA (sistema reconfigurable de visión artificial) of the project TRACER (advanced optimization techniques for complex problems) [1]. The main goal of this research line is the development of image-processing services via the Internet by means of algorithms implemented by software and reconfigurable hardware with field-programmable gate arrays (FPGAs). In this way, advanced optimization techniques are used to implement image-processing algorithms by FPGAs and an open platform is offered to the scientific community, providing the advantages of reconfigurable computing anywhere (e.g., where these resources do not exist).
26.2.1 Background
At present, FPGAs are very popular devices in many different fields. In particular, FPGAs are a good alternative for many real applications in image processing. Several systems using programmable logic devices have been designed showing the utility of these devices for artificial-vision applications [2]. Whereas other papers display the results from implementing image-processing techniques by means of “standard” FPGAs or reconfigurable computing systems [3], in our work we have not only implemented image-processing operations using reconfigurable hardware and obtained very good results, but have also looked to add other services, thanks to the Internet. Basically, these services are:
- A client–server system: to access all the image-processing circuits we have developed in FPGAs. In this way, the user can send his or her artificial-vision problem, choose between hardware (FPGA) or software implementation, and then obtain a solution to the problem.
- A web repository of artificial-vision problems with interesting information about each problem: description, practical results, links, and so on. This repository can easily be extended with new problems or by adding new languages to existing descriptions.
These two additional services offer a set of benefits to the scientific community: They provide reconfigurable computing advantages where these resources are not physically available (without cost, and at any time), they promote the FPGA virtues because any researcher can compare the FPGA and software results (in fact, some of our FPGA-based implementations are even more than 149 times faster than the corresponding software implementation), and the easy extension of the open repository could convert it in a reference point.
26.2.2 Description
When a user accesses the web service (http://tracer.unex.es, then selects the research line SIRVA), the main page of the site is presented. The user can choose any of the options shown on this page. For space limitations we only explain the most important options of SIRVA. If the user selects Manual Configuration in the main page, he or she will go to the page shown in Figure 26.1. In this page the user can introduce, one by one, all the operation parameters: image-processing operation to perform, other configuration parameters, the format for the resulting image file (BMP, PNG, or JPEG), and the implementation he or she wants to use for performing the operation (software in a Pentium-4 or hardware in a FPGA).
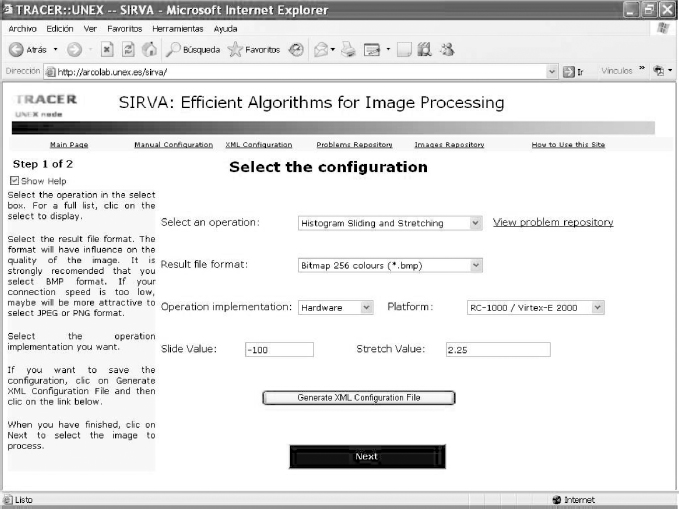
Figure 26.1 Page for manual configuration of SIRVA.
After configuring the web service (using an XML file or manually), the following step (the Next button) is to select the image to process. After that, the user will see the result page. In this page (Figure 26.2), not only the original and processed images are shown, but also the main characteristics of the process performed: implementation selected (HW or SW), platform used (Virtex FPGA, Pentium-4), operation performed, image dimensions, operation time, and so on. On the other hand, the problem repository is based on an ASP page that shows the contents of the diverse XML files used to store the descriptions of different artificial-vision problems. Figure 26.3 presents an example (a more detailed explanation of SIRVA is included in ref. 4).
26.2.3 Technical Details
On the hardware side, we have used the Celoxica RC1000 board (http://www.celoxica.com) with a Xilinx Virtex XCV2000E-8 FPGA (http://www.xilinx.com). The circuit design has been carried out by means of the Handel-C language and the Celoxica DK platform. Thanks to DK the hardware description files have been obtained for the various circuits which are used later in the Xilinx ISE tool to generate the corresponding configuration files (.bit) for the FPGA.

Figure 26.2 Result page (process summary) in SIRVA.

Figure 26.3 Problem repository of SIRVA.
For SIRVA system implementation we use Microsoft .NET, due to the facilities it offers for the creation of web services, and because the control library of the Virtex FPGA we use is implemented in C++ and the corresponding API provided by Celoxica advises the use of Microsoft Visual C++. In this platform the following technologies have been used for the implementation: ASP .NET, C#, ATL server, CGI, C++, and XML-XSLT.
26.2.4 Results and Conclusions
Table 26.1 presents several comparisons between the software and hardware (FPGA) versions of the various image-processing operations implemented in SIRVA. The software versions are executed in a 1.7-GHz Pentium-4 with 768 Mbytes of RAM, and the hardware versions in a Virtex-E 2000 FPGA. The software versions are written in C++ and compiled with the appropriate optimizations. All the results refer to images with 256 gray levels and are expressed in seconds. These times also include the communication time, and they are the average response times after 10 executions of each experiment. In order not to influence the results, all the measurements in Table 26.1 have been carried out with the same workload in the server.
As we can observe in Table 26.1, FPGA-based implementation clearly improves the performance obtained by software (some operations are more than 149 times faster). This is possible because our FPGA implementations use several parallelism techniques, include diverse optimizations, and have high operational frequencies (see ref. 4 for a more detailed explanation).
TABLE 26.1 Software Versus FPGA for 2032 × 1524 Pixel Images

26.3 MOSET AND TIDESI
Here we present two web services that compute several algorithms to perform system identification (SI) for time series (TS). Although the main purpose of these developments was to experiment in optimization of the main parameters of the algorithms involved, it was found that due to their handling ease, configurability, and free online access, these services could be of great utility in teaching courses where SI is a subject: for example in the systems engineering field. The possible utility of these systems comes from their capacity to generate practical contents that support the theoretical issues of the courses.
26.3.1 Modeling and Prediction of Time Series
TSs are used to describe behaviors in many fields: astrophysics, meteorology, economy, and others. SI techniques [5] permit us to obtain the TS model. With this model a prediction can be made, but taking into account that the model precision depends on the values assigned to certain parameters. Basically, the identification consists of determining the ARMAX [6] model from measured samples, allowing us to compute the estimated signal and compare it with the real one, then reporting the error generated.
The recursive estimation updates the model at each time step, thus modeling the system. The more samples processed, the model's better the precision, because it has more information on the system's behavior history. We consider SI performed by the well-known recursive least squares (RLS) algorithm [6], which is very useful for prediction purposes. This identification is influenced strongly by the forgetting factor constant λ. There is no fixed value for λ, but a value between 0.97 and 0.995 is often used. Then the optimization problem consists basically of finding the λ value such that the error made in identification is minimal.
Recursive identification can be used to predict the following behavior of the TS from the data observed up to the moment. With the model identified in k time it is possible to predict the behavior in k + 1, k + 2, and so on. As identification advances over time, the predictions improve, using more precise models. If ks is the time until the model is elaborated and from which we carry out the prediction, the prediction will have a larger error and we will be farther away from ks. The value predicted for ks + 1 corresponds with the last value estimated before ks. When we have more data, the model has to be restarted to compute the new estimated values.
To find the optimum value of λ, we propose use of the parallel adaptive recursive least squares (PARLS) algorithm [7], where an optimization parameter λ is evolved for predicting new situations during iterations of the algorithm. This algorithm uses parallel processing units performing RLS identifications (Figure 26.4), and the results are processed in an adaptive unit to obtain the best solution. The goal of the iterations of the algorithm is that identifications performed by the processing units will converge to optimum λ values so that the final TS model will be a high-precision model.

Figure 26.4 Parallel adaptive scheme used to optimize the time series problem.
26.3.2 MOSET
MOSET is an acronym for the Spanish term “modelacion de series temporales” (time series modeling). MOSET [Figure 26.5(a)] is an open-access web service [8] dedicated to the identification of TSs that use the RLS and PARLS algorithms.
All the experiments are made on a TS database obtained from several sources [7]. Each experiment consists of selecting a TS, the model size, a range of values for λ (several identifications are processed), and the algorithm to be used. According to the algorithm chosen, additional parameters must be selected (e.g., the number of parallel processing units if PARLS), as shown in Figure 26.5(b). After a certain processing time (from seconds to minutes, depending on the TS selected), the downloadable results are shown by means of a curve whose minimum indicates the best value for λ (Figure 26.6).

Figure 26.5 MOSET web service for identification of time series: (a) welcome page; (b) database and parameter selection.

Figure 26.6 MOSET results shown in graphics and tables: (a) RLS results; (b) PARLS results.
26.3.3 TIDESI
TIDESI is an acronym for “tide system identification,” a web service designed to model and predict a set of time series defining the tide levels in the city of Venice, Italy in recent decades. Although the database of TIDESI consists of this type of TS, the techniques are capable of supporting any other type of TS. The online access is public and free, and the prediction is programmed for the short, medium, and long term.
TIDESI has two options for processing the TS selected. The first option computes a simple RLS identification (calculating the estimated value, equal to prediction of the k + 1 time). The second option computes a RLS identification whose model serves as a base to carry out future predictions for any term as a function of the user's requirements. In Figure 26.7 we can observe the selection of the TS, the identification/prediction method chosen, and the parameters that should be specified. In Figure 26.8 we observe how numerical and graphical results are shown, displaying signals with real, identified, and simulated values of the TS. In addition, the user can download the results for a more detailed study.
26.3.4 Technologies Used
To develop MOSET and TIDESI, a 2.4-GHz Pentium-4 PC with a Microsoft Windows 2003 Server operating system was used, running the Microsoft Internet Information Server. To program the modeling, identification, and prediction algorithms, the Matlab language has been used [9], and the source codes are executed by means of the Matlab Webserver. Finally, TS database management has been carried out using Microsoft Active Server Pages and Microsoft Access.

Figure 26.7 TIDESI web service to predict time series.
26.3.5 Conclusions
Courses in the systems engineering area have enjoyed strong support in recent years thanks to the development of online teaching tools. The web services that we have described in this section can be used for teaching purposes, although they were developed with other experimental motivations. In addition, we want to allow the user the possibility of selecting external TS so that any researcher can use the TS of his or her interest.
26.4 ABACUS
Evolutionary algorithms (EAs) are one of the traditional techniques employed in optimization problems. EAs are based on natural evolution, where individuals represent candidate solutions for a given problem. The modus operandi of these algorithms is to crossover and mutate individuals to obtain a good enough solution for a given problem by repeating these operations in a fixed number of generations (steps). However, when difficult problems are faced, these algorithms usually require a prohibitive amount of time and computing resources.

Figure 26.8 TIDESI results shown in graphics and tables.
Two decades ago Koza developed a new EA called genetic programming (GP) [10]. GP is based on the creation of a population of programs considered as solutions for a given problem. Usually, GP individuals' structure is a tree, and they have different sizes. Therefore, different analysis times are needed to evaluate each one. This feature distinguish GPs from other EAs, such as genetic algorithms [11] or evolutionary strategies where individuals have a fixed size, so the evaluation time and computing resources (CPU and memory) required are always the same.
Several researchers have tried to reduce the computational time by means of parallelism. For instance, Andre and Koza employed a transputer network to improve GP performance [12]. Researchers usually employ two parallel models: fine and coarse grain (also known as an island model) [14,15]. As described by Cantu-Paz and Goldberg [16], two major benefits are obtained, thanks to parallel computers running EAs: first, several microprocessors improve the computational speedup; and second, the parallel-based coarse-grain model (another models are also possible) can produce improved performance.
Recently, new tools have been developed to employ the benefits of multiprocessor systems for EAs [17,18]), but there are few public multiprocessor systems that allow these parallel tools to be run. There are also several clusters where it is possible to run these tools, although they do not provide public access. Therefore, we introduce a new platform here, Abacus-GP [19], developed at the University of Extremadura (Spain) and publicly accessible (through a petition) to enable it to be used by GP researchers. Abacus-GP is a GNU/Linux-based parallel cluster comprising two modules: a web interface site in the cluster's firewall and an internal application running in the cluster master node. The Abacus-GP platform allows users to run GP experiments in the cluster by using a web interface. The GP-employed tool necessary to run jobs in Abacus is explained in ref. 20.
26.4.1 Cluster
The Abacus-GP platform is based on the high-performance computational cluster Abacus, set up by the research group on artificial evolution from the University of Extremadura in Spain, using the hardware components Commodity-Off-The-Self (COTS) and open-source software. Abacus is a parallel MPI/PVM-based Linux Beowulf cluster consisting of 10 nodes with Intel Pentium-4 microprocessors. The operating system is Rocks Linux Cluster (http://www.rocksclusters.org), a Linux-based distribution designed especially to create high-performance clusters.
The Abacus cluster consists of a master node and nine working nodes. The master node is in charge of running the jobs and scheduling the cluster, while the working nodes are focused exclusively on running jobs. Figure 26.9 shows the cluster structure. All the nodes are interconnected through a 100-Mbps fast Ethernet switch. Finally, the cluster is connected to the Internet using a GNU/Linux firewall which filters outside access to the cluster.
26.4.2 Platform
With the goal of achieving a more secure and easier access to the cluster and to help in the collaboration between researchers, we have developed a web tool that allows us to run experiments remotely and monitorize them later. When a job is finished, the system sends the results to the job owner by e-mail. Additionally, the user can access the final results (numerical and graphical modes) through the web interface. The website also has two additional tools: a finished experiment repository and a forum where web users can exchange information. Thanks to the web interface, this tool can be employed from any place in the world without knowing the underlying cluster structure.

Figure 26.9 Communication between modules.
The cluster consists of two modules: a multiuser-authenticated website (Abacus web), which is the user interface and runs in the firewall, and Gatacca, a server that runs in the cluster and communicates uniquely with the web interface in order to launch new jobs in the cluster (Figure 26.9).
Both modules are coded in PHP and shell script and access the same MySQL data base (DB), which runs on the cluster. The website checks the job status in the DB and gatacca updates the information in the DB with the experimental results. Thus, gatacca has two main goals: first, to receive requests from the website in order to manage jobs and to know the ongoing status of the jobs launched, and second, to maintain the DB updated with the status of all the experiments running.
Figure 26.10 shows the web interface. This interface shows all the user-finished and still-running experiments, showing the startup time for each experiment and the estimated time to completion. When a user wants to launch a new experiment [Figure 26.10a], the system will ask the user to designate the necessary parameters to run it (population size, generations, etc.). Once the parameters are set up, the website sends a message to gatacca to launch the new job in the cluster. Once the message is received, gataccca creates a new folder in the cluster master node, copies in it all the necessary files, and finally, launches the job. Moreover, each completed job generation triggers gatacca to update the DB with the experiment information and estimates the time left to finish the job. Additionally, the user can consult the ongoing experiment status because gatacca provides the user with real-time numerical and graphical results. When the experiment is finished, gatacca provides the user with the results and charts through the web interface (Figure 26.11).
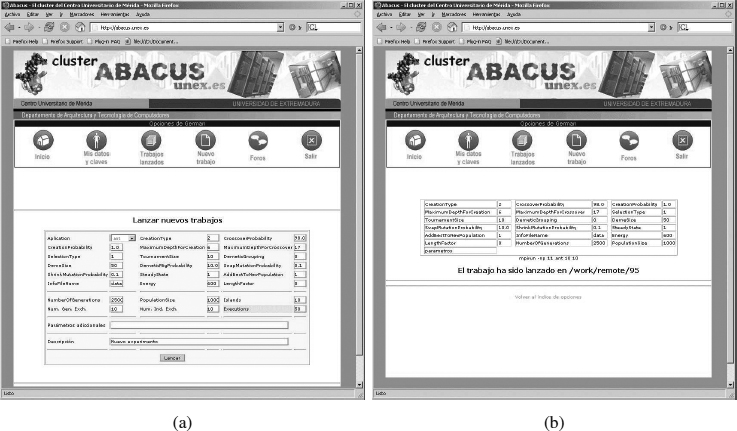
Figure 26.10 Abacus-GP web interface: (a) parameter setup; (b) experiment launch.

Figure 26.11 Abacus-GP result representation: (a) data; (b) charts.
To test the operation of the cluster, we have developed two well-known GP problems in Abacus-GP: the Ant and the Even Parity 5 problems [10].
26.4.3 Conclusions
Abacus-GP is a public and secure platform for GP experimentation through the Internet that is useful to researchers since they can employ a cluster to run their experiments and share them with other colleagues easily by creating result repositories that can be shared. In the future, more bioinspired applications will be implemented and the web tool will also be improved to schedule several clusters using the same tool. This will allow us to distribute jobs between clusters and between zones, which will allow us to employ grid computing concepts.
Acknowledgments
The authors are partially supported by the Spanish MEC and FEDER under contracts TIC2002-04498-C05-01 (the TRACER project) and TIN2005-08818-C04-03 (the OPLINK project).
REFERENCES
1. J. A. Gomez-Pulido. TRACER::UNEX project. http://www.tracer.unex.es.
2. M. A. Vega-Rodríguez, J. M. Sanchez-Perez, and J. A. Gomez-Pulido. Guest editors' introduction—special issue on FPGAs: applications and designs. Microprocessors and Microsystems, 28(5–6):193–196, 2004.
3. M. A. Vega-Rodríguez, J. M. Sanchez-Perez, and J. A. Gomez-Pulido. Recent advances in computer vision and image processing using reconfigurable hardware. Microprocessors and Microsystems, 29(8–9):359–362, 2005.
4. M. A. Vega-Rodríguez, J. M. Sanchez-Perez, and J. A. Gomez-Pulido. Reconfigurable computing system for image processing via the Internet. Microprocessors and Microsystems, 31(8):498–515, 2007.
5. T. Soderstrom. System Identification. Prentice Hall, Englewood Cliffs, NJ, 1989.
6. L. Ljung. System Identification. Prentice Hall, Upper Saddle River, NJ, 1999.
7. J. A. Gomez-Pulido, M. A. Vega-Rodriguez, and J. M. Sanchez-Perez. Parametric identification of solar series based on an adaptive parallel methodology. Journal of Astrophysics and Astronomy, 26:1–13, 2005.
8. J. A. Gomez-Pulido. MOSET. http://www.tracer.unex.es/moset.
9. R. Pratap. Getting Started with Matlab. Oxford University Press, New York, 2005.
10. J. Koza. Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, Cambridge, MA, 1992.
11. D. Goldberg. Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley, Reading, MA, 1989.
12. D. Andre and J. Koza. Parallel Genetic Programming: A Scalable Implementation Using the Transputer Network Architecture. MIT Press, Cambridge, MA, 1996.
13. D. Andre and J. Koza. Parallel genetic programming: a scalable implementation using the transputer network architecture. In Advances in Genetic Programming, vol. 2. MIT Press, Cambridge, MA, 1996, pp. 317–337.
14. F. Fernández, M. Tomassini, and L. Vanneschi. An empirical study of multipopulation genetic programming. Genetic Programming and Evolvable Machines, 4:21–51, 2003.
15. F. Fernandez de Vega. Parallel genetic programming: methodology, history, and application to real-life problems. In Handbook of Bioinspired Algorithms and Applications, Chapman & Hall, London, 2006, pp. 65–84.
16. E. Cantu-Paz and D. Goldberg. Predicting speedups of ideal bounding cases of parallel genetic algorithms. In Proceedings of the 7th International Conference on Genetic Algorithms. Morgan Kaufmann, San Francisco, CA, 2007.
17. F. Fernández. Parallel and distributed genetic programming models, with application to logic sintesis on FPGAs. Ph.D. thesis, University of Extremadura, Caceres, Spain, 2001.
18. F. Fernandez, M. Tomassini, W. F. Punch, and J. M. Sanchez. Experimental study of multipopulation parallel genetic programming. Lecture Notes on Computer Sciences, 1802:283–293, 2000.
19. F. Fernandez. ABACUS cluster. http://www.abacus.unex.es.
20. M. Tomassini, L. Vanneschi, L. Bucher, and F. Fernandez. An MPI-based tool for distributed genetic programming. In Proceedings of the IEEE International Conference on Cluster Computing (Cluster'00). IEEE Computer Society Press, Los Alamitos, CA, 2000, pp. 209–216.
Optimization Techniques for Solving Complex Problems, Edited by Enrique Alba, Christian Blum, Pedro Isasi, Coromoto León, and Juan Antonio Gómez
Copyright © 2009 John Wiley & Sons, Inc.