
Perf
The Linux kernel’s performance event infrastructure is designed to expose both hardware and software performance counters. In theory, this interface provides an abstraction of performance events to user space. In reality, hardware performance counters are too processor-specific to fully abstract. Instead, the performance event infrastructure focuses on providing a flexible interface to accommodate architecture-specific usages. As a result, an understanding of PMU fundamentals, discussed in Chapter 6, is required.
The most common method for utilizing this infrastructure is the perf tool. This application multiplexes a series of tools designed to complement different profiling situations. Additionally, the kernel infrastructure is also available for direct use. This allows developers to write highly customized monitors and to embed the use of performance counters into their applications.
This chapter begins with an introduction to the kernel’s performance event infrastructure API, and also provides the necessary information and examples to utilize it from user space. Then, Section 8.2 explores the perf tool and its usage.
8.1 Event Infrastructure
The first step is to determine whether the kernel supports the event infrastructure and whether the system is configured appropriately for data collection. In order for the events to be available, the kernel must have been compiled with the appropriate Kconfig options: CONFIG_HAVE_PERF_EVENTS, CONFIG_PERF_EVENTS, CONFIG_HAVE_PERF_EVENTS_NMI, CONFIG_HAVE_PERF_REGS, and CONFIG_HAVE_PERF_USER_STACK_DUMP. At the time of this writing, most Linux distributions enable these options by default.
Similar to Intel® VTune™ Amplifier XE, data collection with the performance events infrastructure requires that the kernel’s NMI watchdog and kernel pointer hiding functionality are disabled. A discussion on these features, why they interfere with data collection, and instructions on how to disable them can be found in Section 7.1.2.
Additionally, the visibility of the data collection can be controlled with the /proc/sys/kernel/perf_event_paranoid file. If this file does not exist, either the kernel was compiled without support for performance events or procfs isn’t mounted. If the file does exist, it contains a string of an integer. This integer specifies the access restrictions enforced by the kernel for measurements. Table 8.1 lists the possible values and their subsequent meanings.
Table 8.1
Values for perf_event_paranoid (Molnar et al., 2014)
| Value | Measurements Allowed |
| 2 | User-Space |
| 1 | User-Space and Kernel-Space |
| 0 | CPU Events But Not Kernel Tracepoints |
| − 1 | No Restrictions |
8.1.1 perf_event_open(2)
The actual functionality of the performance infrastructure is exposed by the kernel through one system call, perf_event_open(2). Prior to invoking this system call, a struct, perf_event_attr, is populated. This struct describes the event to be collected, how the measurements should occur, and how the results should be reported. The system call then returns a file descriptor that is utilized for accessing the data collected. In other words, this system call is invoked once for each event to be monitored.
At the time of this writing, no wrapper exists for this system call in glibc, and thus the call must be invoked either with syscall(2), or manually, for instance, with the SYSENTER instruction. The function prototype can be found in Listing 8.1.

As mentioned above, the attr argument is responsible for communicating the event configuration.
The pid argument specifies the process to monitor. A pid of 0 measures the current process, a pid of − 1 measures all processes on the system, and a positive pid measures the process with the given pid.
The cpu argument specifies the logical processor to monitor. A cpu value of − 1 monitors all logical processors, while a positive or zero value limits collection to the specified logical processor.
The group_fd argument is the file descriptor of the group leader. This allows for multiple events to be grouped together. An event group is only scheduled to be collected when all members are available to be measured. Thus, all events that will be calculated or compared together should be members of the same group, ensuring that each event metric is computed based on similar code execution. The first event, the leader, is created with a group_fd of − 1. The file descriptor returned for the leader is then passed as the value for group_fd during the creation of all other events in the group.
Finally, the flags argument allows for specifying any behavioral modifiers. Currently, the only flag the author sees of any value is PERF_FLAG_PID_CGROUP, which allows for system-wide monitoring limited to a cgroup.
The perf_event_open(2) function follows the standard conventions for a function that opens a file descriptor, that is, returning the new file descriptor or − 1 and setting errno.
8.1.2 Selecting an Event
Events are selected by populating the perf_event_attr structure and then passing it to the kernel. This data structure, as expected by the kernel ABI, is defined in /usr/include/linux/perf_event.h. This header file also includes the enumerations for the various events, as well as any other ABI definitions.
Due to the flexibility of the interface, the event attribute structure is fairly complex. Determining which fields to populate in this structure depends on the desired information.
The first step is to select the event and event type, corresponding to the perf_event_attr.config and perf_event_attr.type fields, respectively. At the time of this writing, the following predefined event types are listed in the perf_event.h header file:
PERF_TYPE_HARDWARE Hardware Event
PERF_TYPE_SOFTWARE Software Event
PERF_TYPE_TRACEPOINT Tracing Event
PERF_TYPE_HW_CACHE Hardware Cache Event
PERF_TYPE_RAW Raw Hardware Event
PERF_TYPE_BREAKPOINT Hardware Breakpoint
Additionally, the supported events and event types can be enumerated via sysfs.
The event types can be iterated via the event_source bus in sysfs. Each directory in /sys/bus/event_source/devices/ represents an event type. To select that event type, set the perf_event_attr.type field to the value in that corresponding directory’s type file. Notice that the values exported via sysfs should correspond with the predefined values. For instance:
Each of these event types has a corresponding directory in /sys/devices. Within some of these directories is an events subdirectory. Within this events directory is a file for each predefined event. These predefined event files contain the necessary information to program the event. For example:
Notice that in the above sysfs example, an event type named “power” was available; however, this event type was not present in the prior list of ABI event types. This is because, at the time of this writing, the ABI header doesn’t have a corresponding entry in the perf_type_id enum for this type. The “power” event type, introduced less than a year ago, adds events that utilize the RAPL interface, described in Section 3.2.4, to provide power consumption information. This illustrates how quickly the infrastructure is evolving. Andi Kleen has written a library, libjevents, to parse the events listed in sysfs. It is available at https://github.com/andikleen/pmu-tools/tree/master/jevents.
PERF_TYPE_HARDWARE
When perf_type_attr.type is set to PERF_TYPE_HARDWARE, the contents of perf_event_attr.config are interpreted as one of the predefined processor events. Some of these events and their meanings are listed in Table 8.2. The exact PMU counter corresponding to each of these events can be determined by searching for the event name in the ${LINUX_SRC}/arch/x86/kernel/cpu/ directory. This information can then be cross-referenced with Volume 3, Chapter 19 of the Intel® Software Developer Manual to determine the precise meaning.
Table 8.2
Architectural Events of Type PERF_TYPE_HARDWARE (Kleen et al., 2014)
| Event | Meaning |
| PERF_COUNT_HW_CPU_CYCLES | Unhalted Core Cycles. This counter only increments when the core is in C0 and is not halted. Affected by changes in clock frequency. |
| PERF_COUNT_HW_INSTRUCTIONS | Instructions Retired. This counter increments once when the last μop of an instruction is retired. Only incremented once for an instruction with a REP prefix. |
| PERF_COUNT_HW_CACHE_REFERENCES | LLC Reference. |
| PERF_COUNT_HW_CACHE_MISSES | LLC Miss. |
| PERF_COUNT_HW_BRANCH_INSTRUCTIONS | Branch Instruction At Retirement. Due to PMU skid, the flagged instruction during sampling is typically the first instruction of the taken branch. |
| PERF_COUNT_HW_BRANCH_MISSES | Mispredicted Branch Instruction at Retirement. Due to PMU skid, the flagged instruction during sampling is typically the first instruction of the taken branch. |
| PERF_COUNT_HW_BUS_CYCLES | Unhalted Reference Cycles. Unlike Unhalted Core Cycles, this counter increments at a fixed frequency. |
| PERF_COUNT_HW_REF_CPU_CYCLES | This event currently uses the Fixed-Function events rather than the programmable events. Similar to BUS_CYCLES, this counter increments at a fixed rate, irrespective of frequency. Since the event code in the kernel source assumes programmable events, the event code and umask hard coded in the config are bogus. |
As mentioned in the introduction, abstracting PMU events is challenging. The vast majority of events are nonarchitectural, that is, their behavior can vary from one processor architecture to the next. As a result, defining predefined events for every available event would clutter the API with thousands of events that are only useful on a specific platform. Thus, most PMU events are only accessible with the PERF_TYPE_RAW event type.
Another challenge with the predefined events is that there is no guarantee that these events will continue measuring the same counters in future kernel versions.
In summary, the predefined events of type PERF_TYPE_HARDWARE are convenient for basic PMU usage. For more serious performance work, it is better to use the PERF_TYPE_RAW events and specify the desired counters directly.
PERF_TYPE_RAW
The interpretation of perf_event_attr.config when perf_event_attr.type is set to PERF_TYPE_RAW depends on the architecture. For Intel® platforms, the expected format is that of the programmable PMU MSR, shown in Figure 6.1. Of these bits, only the ones that identify the event are required. The kernel automatically sets the other bits based on the other attributes in the perf_event_attr struct. For example, whether the OS and USR fields are set depends on the values of perf_event_attr.exclude_kernel and perf_event_attr.exclude_user. In other words, only the umask and event number fields need to be set for most events. Some events may also require setting the cmask, inverse, or edge detect fields. The encoding information for each event is listed in Volume 3, Chapter 19 of the Intel Software Developer Manual.
Additionally, some PMU events also require configuring other MSRs. Within the kernel are lists, partitioned by processor generation, of these events and the MSRs they utilize. When one of these events is selected, the contents of perf_event_attr.config1 and perf_event_attr.config2 are loaded into the extra MSRs. Since these extra registers vary depending on the event, the format will be specific to the event. Obviously for this to work, the event must be properly configured within the kernel’s PMU lists. These lists, arrays of type struct extra_reg, can be found in ${LINUX_SRC}/arch/x86/kernel/cpu/perf_event_intel.c.
PERF_TYPE_SOFTWARE
When perf_type_attr.type is set to PERF_TYPE_SOFTWARE, the contents of perf_event_attr.config are interpreted as one of the predefined software events. Some of these events can be found in Table 8.3. As the name implies, software events are provided and updated by the kernel. Therefore, these events focus on aspects of the software’s interaction with the operating system. Unlike the hardware events, these events should be available and consistent across all platforms.
Table 8.3
PERF_TYPE_SOFTWARE Events (Molnar et al., 2014; Torvalds and et al., 2014)
| Event | Meaning |
| PERF_COUNT_SW_CPU_CLOCK | The wall time, as measured by a monotonic high-resolution timer. |
| PERF_COUNT_SW_TASK_CLOCK | The process time, as measured by a monotonic high-resolution timer. |
| PERF_COUNT_SW_PAGE_FAULTS | The number of page faults. |
| PERF_COUNT_SW_CONTEXT_SWITCHES | The number of context switches. |
| PERF_COUNT_SW_CPU_MIGRATIONS | The number of migrations, that is, where the process moved from one logical processor to another. |
| PERF_COUNT_SW_PAGE_FAULTS_MIN | The number of minor page faults, that is, where the page was present in the page cache, and therefore the fault avoided loading it from storage. |
| PERF_COUNT_SW_PAGE_FAULTS_MAJ | The number of major page faults, that is, where the page was not present in the page cache, and had to be fetched from storage. |
PERF_EVENT_TRACEPOINT
In order to count kernel tracepoints, set perf_event_attr.type to PERF_TYPE_TRACEPOINT and set perf_event_attr.config to the tracepoint id. This value can be retrieved from debugfs by looking at the respective id file under the appropriate subdirectory in /sys/kernel/debug/tracing/events/. For more information about kernel tracepoints, see Chapter 9.
PERF_EVENT_HW_CACHE
In order to utilize hardware counters to measure cache events, the value of perf_event_attr.type is set to PERF_TYPE_HW_CACHE, and the value of perf_event_attr.config is based on Figure 8.1.

The Cache_ID field in Figure 8.1 can be one of the following:
PERF_COUNT_HW_CACHE_L1D L1 Data Cache
PERF_COUNT_HW_CACHE_L1I L1 Instruction Cache
PERF_COUNT_HW_CACHE_LL LLC
PERF_COUNT_HW_CACHE_DTLB Data TLB
PERF_COUNT_HW_CACHE_ITLB Instruction TLB
PERF_COUNT_HW_CACHE_BPU Branch Prediction Unit
PERF_COUNT_HW_CACHE_NODE Local memory
The Cache_Op field in Figure 8.1 can be one of the following:
PERF_COUNT_HW_CACHE_OP_READ Read Access
PERF_COUNT_HW_CACHE_OP_WRITE Write Access
PERF_COUNT_HW_CACHE_OP_PREFETCH Prefetch Access
Finally, the Cache_Result field in Figure 8.1 can be one of the following:
PERF_COUNT_HW_CACHE_RESULT_ACCESS Cache Reference
PERF_COUNT_HW_CACHE_RESULT_MISS Cache Miss
PERF_TYPE_BREAKPOINT
Unlike the other event types, PERF_TYPE_BREAKPOINT doesn’t use the value in perf_event_attr.config. Instead, it should be set to zero. The breakpoint is set by setting perf_event_attr.bp_type to one or more of the memory access types described in Table 8.4. Then, set perf_event_attr.bp_addr and perf_event_attr.bp_len, to set the address, as well as the length of bytes after perf_event_attr.bp_addr to break upon.
Table 8.4
Values for perf_event_attr.bp_type (Howells, 2012)
| Value | Meaning |
| HW_BREAKPOINT_EMPTY | Don’t Break |
| HW_BREAKPOINT_R | Break on Read |
| HW_BREAKPOINT_W | Break on Write |
| HW_BREAKPOINT_RW | Break on Reads or Write |
| HW_BREAKPOINT_X | Break on Code Fetch |
8.1.3 Measurement Parameters
Now that the event is configured, it’s time to configure how the event will be measured and how the results will be reported.
In order to determine which API revision the system call should conform to, the perf_event_attr.size field is set to the size of the perf_event_attr structure. If a specific revision is desired, the field can be set to the corresponding size for that revision. These values are defined in the perf_event.h header file, taking the form of PERF_ATTR_SIZE_VER. For instance:
Besides the size, the other common configuration options are bitfields within the structure. There are four bitfields that allow for the exclusion of contexts: (0) perf_event_attr.exclude_user (1) perf_event_attr.exclude_kernel (2) perf_event_attr.exclude_hv, for hypervisor, (3) perf_event_attr.exclude_idle. There are three bitfields that control the monitoring of child processes, (0) perf_event_attr.inherit, which determines whether child processes should be included in the measurements, (1) perf_event_attr.inherit_stat, which determines whether the counters are preserved between context switches to an inherited process, and (2) perf_event_attr.enable_on_exec, which automatically enables the counters after an exec(2), thus simplifying the task of monitoring another process.
The perf_event_attr.pinned field specifies that the event should always be enabled on the core. The perf_event_attr.exclusive field specifies that the event, including its group, should be the only events enabled on the processor. This is designed for handling events that may interfere with other counters. The perf_event_attr.disabled field specifies that the event should be started disabled, leaving the event to be selectively enabled when measurement is desired.
The perf_event_attr.precise_ip allows for PEBS, as described in Chapter 6, to be enabled.
As mentioned previously, events can be counted and sampled. While counted events are accessed through read(2), samples are accessed via pages obtained with mmap(2). The process of parsing the results will be covered in more detail in Sections 8.1.5 and 8.1.6.
Counted event configuration
Configuring counting events is fairly straightforward. Unlike sampled events, there is really only one counting-specific configuration option, perf_event_attr.read_ format. This option controls what information is present in the buffer filled by the read(2) call.
There is no predefined struct in perf_event.h for the result’s format. This is because the result’s format is customizable. The fields whose associated flags aren’t specified in perf_event_attr.read_format will be excluded. As a result, updating the perf_event_attr.read_format field without updating the associated code that parses the result buffer will lead to erroneous data values. Table 8.5 lists the valid options for perf_event_attr.read_format.
Table 8.5
Values for perf_event_attr.read_format (Gleixner and Molnar, 2014)
| Value | Meaning |
| PERF_FORMAT_TOTAL_TIME_ENABLED | Report the time in nanoseconds that the event was enabled and the task was running. |
| PERF_FORMAT_TOTAL_TIME_RUNNING | Report the time in nanoseconds that the task was running. |
| PERF_FORMAT_ID | Report a unique id for this event. |
| PERF_FORMAT_GROUP | Report values for all counters within a group in one read(2). |
In the case where PERF_FORMAT_GROUP is specified, the reporting format is as follows:
On the other hand, when PERF_FORMAT_GROUP is not specified, the reporting format is as follows:
In both cases, the time_enabled and time_running fields are only enabled if PERF_FORMAT_TOTAL_TIME_ENABLED and PERF_FORMAT_TOTAL_TIME_RUNNING flags are set.
Sampled event configuration
Similar to the counted event configuration, the result format is customizable. Instead of using the perf_event_attr.read_format field, the perf_event_attr.sample_ type field is used. Table 8.6 contains the supported flags.
Table 8.6
Values for perf_event_attr.sample_type (Gleixner and Molnar, 2014)
| Value | Records |
| PERF_SAMPLE_IP | Instruction pointer |
| PERF_SAMPLE_TID | Thread id |
| PERF_SAMPLE_TIME | Timestamp |
| PERF_SAMPLE_ADDR | Address |
| PERF_SAMPLE_READ | Counter values |
| PERF_SAMPLE_CALLCHAIN | Stack backtrace |
| PERF_SAMPLE_ID | Unique id for group leader |
| PERF_SAMPLE_CPU | CPU number |
| PERF_SAMPLE_PERIOD | Sampling period. |
| PERF_SAMPLE_STREAM_ID | Unique id for opened event |
| PERF_SAMPLE_RAW | Additional data (depends on event) |
| PERF_SAMPLE_BRANCH_STACK | Record of recent branches |
| PERF_SAMPLE_REGS_USER | Userspace CPU registers |
| PERF_SAMPLE_STACK_USER | Userspace stack |
| PERF_SAMPLE_WEIGHT | Hardware weight for cost of event |
| PERF_SAMPLE_DATA_SRC | Data source in hierarchy |
Another important configuration is the frequency of events collected. This is controlled with either the perf_event_attr.sample_period or perf_event_attr. sample_freq fields. The perf_event_attr.sample_period is the same interface described in Chapter 6, where the counter is set to (unsigned)-1 - perf_event_attr.sample_period, generating an interrupt after every sample_ period events.
On the other hand with perf_event_attr.sample_freq, the kernel will adjust the sampling period to receive the requested rate.
8.1.4 Enabling, Disabling, and Resetting Counters
Event counts can be controlled by performing an ioctl(2) on the associated file descriptor. Modifications can be per event or per event group. To modify an individual event, the ioctl(2) is invoked on the event’s associated file descriptor and uses 0 as the last argument. On the other hand, the full event group can be modified by invoking the ioctl(2) on the group leader’s file descriptor and using PERF_IOC_FLAG_GROUP as the last argument.
The PERF_EVENT_IOC_ENABLE and PERF_EVENT_IOC_DISABLE ioctls enable and disable the counters, respectively. This does not change the counter values.
The PERF_EVENT_IOC_RESET ioctl resets the counter to zero. However, any other data associated with the event counter, such as the time_enabled or time_running values, are not reset.
8.1.5 Reading Counting Events
As mentioned earlier, event counts can be accessed by invoking read(2) on the event file descriptor. Additionally, all event counts within a group can be obtained together, via a read(2) on the group leader’s file descriptor, if the PERF_FORMAT_GROUP flag was specified as part of perf_event_attr.read_format.
Consider the simple example in Listing 8.2. In this example, two branch hardware events, retired and misses, are measured for a trivial workload that alternates back and forth between two branches. Notice that in order to prevent the compiler from optimizing the workload out of the executable, the termination condition is dependent on user input and the results are printed.
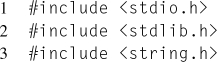
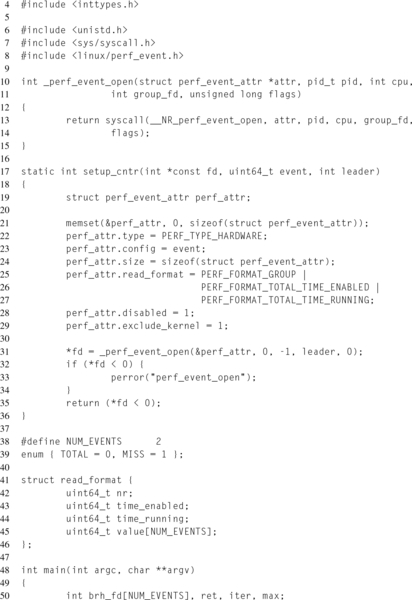


On lines 61 and 65, the two event descriptors are created, with the PERF_COUNT_HW_ BRANCH_INSTRUCTIONS event as the group leader. In this example, the predefined events of type PERF_TYPE_HARDWARE are used. This is okay because both counters, branch instructions retired and branch misses retired, are architectural events. If desired, these events could also be encoded using the PERF_TYPE_RAW event type. This would require changing the value of perf_attr.type on line 22, and then setting perf_attr.config to 0x00C4 and 0x00C5 instead of PERF_COUNT_HW_BRANCH_INSTRUCTIONS and PERF_COUNT_HW_BRANCH_MISSES respectively.
On line 25, the perf_event_attr.read_format field is set to report both event counts together in the same read(2) call, which occurs on line 99. Additionally, it is also set to report the time the counters were enabled and run, in order to monitor counter multiplexing.
Then, the counters are prepared to begin measurement. First, the counters are reset, line 69, to ensure the starting values are known. Secondly, the counters are enabled, line 75, since they were disabled at creation, line 28. Notice that each ioctl(2) affects both counters in the group, because of the PERF_IOC_FLAG_GROUP flag.
The trivial microbenchmark, lines 81 to 91, is designed to determine whether the branch predictor will correctly identify this pattern. The advantage of such a simple workload for this example is the ease of validating the results. For each loop iteration, two branches occur. The first branch checks whether the loop index, i, has exceeded the limit, max. The second branch checks whether the loop index is even or odd. Therefore, the total number of branches is ![]() or simply max + 1.
or simply max + 1.
Once the workload has finished, the counters are disabled, line 93, and the results are read into the results structure. Remember that the format of this buffer depends on the values set in perf_event_attr.read_format. Changing one of those values may require rearranging the structure. Due to the usage of PERF_FORMAT_GROUP, only one read(2) call is required to return both counter values. Otherwise, a separate read would be necessary on each file descriptor.
When the author ran the application in Listing 8.2, the following results were produced:
Earlier, the number of branches during the workload had been calculated as max + 1, and thus we would expect 101 branches for our workload, as opposed to the 133 branches recorded. Looking at the example code, another branch can be accounted as checking for the return value for the ioctl(2) to enable the performance counters. Perhaps others can be accounted to the glibc wrapper for ioctl(2), that is, the validation code to check that the various arguments are correct, or perhaps to the return path from the ioctl(2) call that enables the counters. Additionally, this discrepancy could be caused by a nuance of the specific event counter.
When using performance counters, these sorts of discrepancies are common. Remember that PMU events measure the behavior of the processor’s internals. In other words, what is counted toward an event and when it is counted, depends on the specific hardware implementation. This is especially problematic when using lower level events, because these events rely more upon internal core state than higher level events. In this example, the counter values remain consistent across multiple runs, which indicates the data is stable enough to be useful.
The important element here is not the individual counter values, but their relationship to one another. For the 133 branch instructions retired, only about 6 branches were mispredicted. That’s a branch hit ratio of about 95%, which suggests that the branch predictor is very adept at predicting the trivial branching pattern in this microbenchmark.
8.1.6 Reading Sampling Events
While counting events provides an estimate of how well a given code snippet is performing, sampling events provides the ability to estimate which instructions are responsible for the generated events. Continuing the trivial microbenchmarking example shown in Listing 8.2, consider if the measuring code were rewritten to determine which branches were being mispredicted. Listing 8.3 is written to leverage the Intel® Last Branch Record (LBR), which stores information about the sampled branch events.




Starting within the main() function at line 88, notice that only one event is configured, branch mispredictions. The perf_attr.sample_period attribute, set to 1 on line 92, controls how many events occur before an interrupt occurs. By setting this to one, an interrupt is generated after every event. In general, this is a bad idea for frequent events, but for this trivial microbenchmark it is acceptable.
On line 93, the perf_attr.sample_type field specifies what information should be recorded for each event. In this situation, there are two items specified. The first, the instruction pointer, identifies which branch was mispredicted. The second, the LBR branch stack, lists the recently encountered branches and whether they were correctly predicted. Notice that in the function signature on line 29, the result structure corresponds to this field.
On line 105, the resulting event file descriptor is mapped into the virtual address space of the process. As events occur, the kernel writes the collected samples into these pages. Starting on line 45, the actual memory mapped data is parsed. The first memory mapped page contains a header, which specifies information about the following event buffer data. This data header is defined by the perf_event_header structure. The following buffer data, starting at the second memory mapped page, is a ring buffer. There are two fields in the header that correspond with the read and write offsets into the buffer. The valid unread buffer starts at the offset described by the data_tail field and the end of the valid buffer is defined by the data_head field. If the pages were mapped as writable, the new entries are marked as read, by the user space process, by writing the new value to the data_tail field.
After accessing the data_tail, a memory barrier is utilized to ensure that the data written by the kernel to the memory mapped pages is visible to the user space process. This memory barrier is implemented on line 19, and utilizes the LFENCE instruction, that is, a load fence.
Each entry into the ring buffer has a header, which describes the record’s type and size. The while loop on line 54 handles parsing this header and dispatching the appropriate function to handle that record type.
One run of this code sample is replicated below:
Looking at these results, a couple of different branches are highlighted. These results seem to corroborate the earlier hypothesis that the branch predictor was very adept at predicting the microbenchmark workload. The branches with an instruction pointer around 0x400000 are clearly the user space application’s branches, while addresses such as 0xffffffff8172e8be are clearly branches in kernel code. Notice that on line 97 of Listing 8.3, perf_attr.exclude_kernel is set. As a result, even if one of the kernel branches was mispredicted, it would not appear in the sample data. At the same time, the LBR records all branches, which is why both user and kernel space addresses appear in the branch stack.
While this example prints the raw results, a more sophisticated application could perform some automatic analysis on the results. For instance, as branches show up in the profile, a running tally, associated by the instruction pointer, could be kept. After the workload finishes, this tally could be used to summarize the results, listing the hottest branches.
Additionally, the application could look up the source code lines associated with these instruction pointers for its report. This would involve examining the virtual address space of the process, by parsing the associated maps file in procfs, such as /proc/self/maps. This will correlate virtual memory addresses with specific memory mapped files, including executables and shared libraries. Then, using debug information, the offset from the base address of the file can be translated into a source code file and line. For simplicity’s sake, this information can also be obtained on the sample application:
8.2 Perf Tool
The perf tool leverages the functionality of the kernel’s performance event infrastructure for profiling. In other words, perf provides access to counting and sampling events, handles the parsing of the results and relevant debug information, and produces reports that highlight the corresponding hotspots in the code.
Data collection can occur either for specific processes, either by perf forking a new process or attaching to an existing process, or for every process on the system. To monitor a new process, simply pass the command and related arguments to perf as the last arguments. For instance, perf stat ls would cause perf to create a new process running the ls executable, and then perform the requested monitoring on that process. To attach to an existing process, the -p argument is used. For instance, perf record -p 12345 would cause perf record to attach to an existing process with a process id of 12345, and then perform measurements. Finally, every process can be monitored by instead passing perf the -a option.
8.2.1 Expressing Events
Events are selected by using the -e command argument. Multiple events can be specified by either repeating the argument per event, or by providing the argument with a comma-separated list of events. Event groups are created by enclosing the comma-separated list of events in brackets, e.g., perf stat -e “{cycles, instructions}.” For most perf tools, if no events are specified, CPU cycles are used.
The events described in Section 8.2.1, excluding PERF_TYPE_RAW, fall into the category of “cooked” events. A full list of these events, and how they should be expressed on the command line, can be obtained with perf list.
Events not contained in that list, that is, “raw” events, can be used with the format “r<config number>.” Where the config number is the hexadecimal representation of the MSR format described in Section 6.1. For most cases, this will simply be “r<umask value><event value>.” For instance, given that the architectural event for Unhalted Core Cycles, that is, the “cooked” cycles event, has an Event Number of 0x3C and a Umask Value of 0x00:
Those are the only two required fields most of the time because event modifiers have a special syntax. These are expressed by appending a colon to the end of the event they modify, and then a list of modifiers. Table 8.7 lists the available modifiers. Modifiers can be applied to either “cooked” or “raw” events. Consider:
Table 8.7
Perf Event Modifiers (Zijlstra et al., 2014)
| Value | Meaning |
| u | Restrict events to userspace |
| k | Restrict events to kernelspace |
| h | Restrict events to the hypervisor |
| G | Restrict events to Guest |
| H | Restrict events to Host |
| p | Constant skid for SAMPLE_IP |
| pp | Request 0 skid for SAMPLE_IP |
| D | Events pinned to PMU |
When sampling, the “p” and “pp” modifiers attempt to leverage PEBS to reduce skid.
8.2.2 Perf Stat
The perf stat tool counts the specified performance counters for the given process or processes. This provides the ability to calculate the necessary metrics in order to determine where further analysis should focus, and allows for the comparison of multiple implementations.
As mentioned in Section 5.2.2, each counter value represents one member of a sample that estimates the infinite population. As the number of samples increases, the more accurate the sample becomes. To accommodate this, perf stat supports a - -repeat N command line argument, which causes the measurement to be performed N times, with the average and standard deviation reported.
If no events are specified, the default events, including the “task-clock,” “wall-clock,” and the number of “context-switches,” “migrations,” “page-faults,” “cycles,” “stalled-cycles-frontend,” “stalled-cycles-backend,” “instructions,” “branches,” and “branch-misses,” are chosen.
For instance, to calculate the CPI, ![]() , for compressing a Linux kernel tarball with gzip, at the default deflate compression ratio:
, for compressing a Linux kernel tarball with gzip, at the default deflate compression ratio:
Therefore, ![]() . Notice that the standard deviation is reported at the end of the line for each event. As mentioned in Chapter 6, it’s important to only correlate events collected together. Notice that the events calculated together are included within the same event group. It would be incorrect to calculate the CPI with the cycles from one run of perf stat, and the instructions from a different run.
. Notice that the standard deviation is reported at the end of the line for each event. As mentioned in Chapter 6, it’s important to only correlate events collected together. Notice that the events calculated together are included within the same event group. It would be incorrect to calculate the CPI with the cycles from one run of perf stat, and the instructions from a different run.
8.2.3 Perf Record, Perf Report, and Perf Top
Once analysis of the counting values isolates the bottleneck, sampling can be used to determine what instructions are responsible. This can be performed with either perf record or perf top. The main difference between the two is that perf top dynamically displays the results of the samples collected, updating as new samples are collected. The delay between data updates is controlled with the -d command line argument, taking as an argument the number of seconds between refreshes.
On the other hand, perf record saves the sampling data into a file, which can then be manipulated once all of the data collection has completed. By default, the data file created will be called perf.data. If that file already exists, the existing file will be moved to perf.data.old, and then perf.data will be created. However, a backup will not be made of perf.data.old if it already exists, resulting in that data being lost. The output file name can be changed via the -o command-line argument. If using an output file name other than the default, then all subsequent perf commands that manipulate that file will need the -i command line argument, specifying the correct file name to use. For instance, continuing the example from the previous section, to determine which instructions are consuming the most CPU time while compressing a Linux kernel tarball using gzip:
Using the -g command-line argument instructs perf to record not only the instruction pointer of the sample, but also the function callchain. Now that the data has been collected, the perf report and perf annotate commands will allow for accessing the collected data.
If the terminal supports it, the perf report command will open an interactive text user interface (TUI) for reviewing the results. This view consists of a list of functions, sorted by the functions with the highest event counts, along with their percentage of sampled events, the file, executable or shared library they reside in, and their callchain. Otherwise, perf report will print a similar noninteractive view. When navigating the TUI, the arrow keys move the cursor to the next or previous lines. Pressing Enter when the cursor highlights a line beginning with “+” will expand that line, to show the callchain. Functions from executables or libraries that lack debug information will be displayed as hexadecimal numbers. This can be remedied by compiling with or installing the appropriate debug flags or packages, and this does not require rerunning the data collection.
Figure 8.2 shows the interactive TUI for the data collection from above. Looking at the results, out of approximately sixty billion cycle events recorded, 60.34% resided in one function, longest_match. From these results, it follows that optimizing this function, or its callers to invoke it less, has the potential to improve performance much more significantly than, say optimizing build_tree, which only accounts for about 0.05%.

While knowing which functions to focus on is incredibly helpful, the profiler can help even more. By highlighting an entry in the TUI and pressing the “a” key, the disassembly for the function will be shown, annotated with the event samples. This is the same as invoking perf annotate [function name]. Just like perf report, depending on the terminal capabilities, perf annotate will either launch an interactive TUI or print the results to stdout. If the source code is available, perf will interleave the instructions with their associated lines of code.
Figure 8.3 shows a snippet of the annotation for the longest_match function highlighted in Figure 8.2. On the far left side is the percentage of samples accounted to that instruction. By default, the cursor will start on the instruction with the highest percentage. Pressing the Tab key will cycle through the other instructions in decreasing order of samples.

Remember when interpreting annotations to account for skid. For example, a constant skid of 1 would mean that the samples reported are for the instruction prior to the one labeled.
8.2.4 Perf Timechart
Perf timechart is a tool to graphically describe the interactions on the system. These interactions include those between the processes, cores, and sleep states.
Timechart commands are multiplexed through the perf timechart command. First, events are collected using the record command, which takes a command to run, similar to perf record. Next, perf timechart is run without any arguments. This generates a SVG timeline, named output.svg, of system events. That is,
For example, running perf timechart on a gzip compression workload:
The output for this example can be seen in Figure 8.4.

The advantage of using a vector image format is the ability to provide scalable detail. Viewing the graph at different sizes, that is, zooming in and out, shows different levels of detail. For instance, zooming in on the CPU bars shows different color bars representing the transitions in CPU state, such as the idle state. In order to properly utilize the zoomable levels of detail, make sure to view the SVG in an SVG editor or viewer, such as inkscape, and not one that converts the vector image to a bitmap image for viewing.
The downside to the zoomable detail is the size of both the file and the timeline. In order to keep the results manageable, the author recommends avoiding the use of timechart on long running processes.
The timeline itself highlights the interactions between various processes. At the top of the graph is a series of bars representing CPU state. At a high level of detail, these bars show what the CPU is doing at that moment in time. These categories include Running, Idle, Deeper Idle, Deepest Idle, Sleeping, Waiting for CPU, and Blocked on IO. Increasing the level of detail, that is, zooming into the image, reveals more information about the state. This is shown in Figure 8.5.

Below the CPU state are bars representing processes active on the system at the given time. Similar to the CPU bars, these bars also show the individual process state with the same color-coded categories.