
In Chapter 13, Parallelizing Neural Network Training with TensorFlow, you may recall that we implemented a multilayer neural network for handwritten digit recognition problems, using different API levels of TensorFlow. You may also recall that we achieved about 97 percent accuracy.
So now, we want to implement a CNN to solve this same problem and see its predictive power in classifying handwritten digits. Note that the fully connected layers that we saw in the Chapter 13, Parallelizing Neural Network Training with TensorFlow were able to perform well on this problem. However, in some applications, such as reading bank account numbers from handwritten digits, even tiny mistakes can be very costly. Therefore, it is crucial to reduce this error as much as possible.
The architecture of the network that we are going to implement is shown in the following figure. The input is 28 x 28 grayscale images. Considering the number of channels (which is 1 for grayscale images) and a batch of input images, the input tensor's dimensions will be batchsize x 28 x 28 x 1.
The input data goes through two convolutional layers that have a kernel size of 5 x 5. The first convolution has 32 output feature maps, and the second one has 64 output feature maps. Each convolution layer is followed by a subsampling layer in the form of a max-pooling operation.
Then a fully-connected layer passes the output to a second fully-connected layer, which acts as the final softmax output layer. The architecture of the network that we are going to implement is shown in the following figure:

The dimensions of the tensors in each layer are as follows:
- Input:

- Conv_1:

- Pooling_1:

- Conv_2:
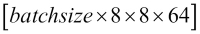
- Pooling_2:

- FC_1:

- FC_2 and softmax layer:

We'll implement this network using two APIs: the low-level TensorFlow API and the TensorFlow Layers API. But first, let's define some helper functions at the beginning of the next section.
If you'll recall again from Chapter 13, Parallelizing Neural Network Training with TensorFlow, we used a function called load_mnist to read the MNIST handwritten digit dataset. Now we need to repeat the same procedure here as well, as follows:
>>> #### Loading the data
>>> X_data, y_data = load_mnist('./mnist/', kind='train')
>>> print('Rows: {}, Columns: {}'.format(
... X_data.shape[0], X_data.shape[1]))
>>> X_test, y_test = load_mnist('./mnist/', kind='t10k')
>>> print('Rows: {}, Columns: {}'.format(
... X_test.shape[0], X_test.shape[1]))
>>> X_train, y_train = X_data[:50000,:], y_data[:50000]
>>> X_valid, y_valid = X_data[50000:,:], y_data[50000:]
>>> print('Training: ', X_train.shape, y_train.shape)
>>> print('Validation: ', X_valid.shape, y_valid.shape)
>>> print('Test Set: ', X_test.shape, y_test.shape)We are splitting the data into a training, a validation, and a test sets. The following result shows the shape of each set:
Rows: 60000, Columns: 784 Rows: 10000, Columns: 784 Training: (50000, 784) (50000,) Validation: (10000, 784) (10000,) Test Set: (10000, 784) (10000,)
After we've loaded the data, we need a function for iterating through mini-batches of data, as follows:
>>> def batch_generator(X, y, batch_size=64,
... shuffle=False, random_seed=None):
...
... idx = np.arange(y.shape[0])
...
... if shuffle:
... rng = np.random.RandomState(random_seed)
... rng.shuffle(idx)
... X = X[idx]
... y = y[idx]
... for i in range(0, X.shape[0], batch_size):
... yield (X[i:i+batch_size, :], y[i:i+batch_size])This function returns a generator with a tuple for a match of samples, for instance, data X and labels y. We then need to normalize the data (mean centering and division by the standard deviation) for better training performance and convergence.
We compute the mean of each feature using the training data (X_train) and calculate the standard deviation across all features. The reason why we don't compute the standard deviation for each feature individually is because some features (pixel positions) in image datasets such as MNIST have a constant value of 255 across all images corresponding to white pixels in a grayscale image.
A constant value across all samples indicates no variation, and therefore, the standard deviation of those features will be zero, and a result would yield the division-by-zero error, which is why we compute the standard deviation from the X_train array using np.std without specifying an axis argument:
>>> mean_vals = np.mean(X_train, axis=0) >>> std_val = np.std(X_train) >>> X_train_centered = (X_train - mean_vals)/std_val >>> X_valid_centered = (X_valid - mean_vals)/std_val >>> X_test_centered = (X_test - mean_vals)/std_val
Now we are ready to implement the CNN we just described. We will proceed by implementing the CNN model in TensorFlow.
For implementing a CNN in TensorFlow, first we define two wrapper functions to make the process of building the network simpler: a wrapper function for a convolutional layer and a function for building a fully connected layer.
The first function for a convolution layer is as follows:
import tensorflow as tf
import numpy as np
def conv_layer(input_tensor, name,
kernel_size, n_output_channels,
padding_mode='SAME', strides=(1, 1, 1, 1)):
with tf.variable_scope(name):
## get n_input_channels:
## input tensor shape:
## [batch x width x height x channels_in]
input_shape = input_tensor.get_shape().as_list()
n_input_channels = input_shape[-1]
weights_shape = list(kernel_size) +
[n_input_channels, n_output_channels]
weights = tf.get_variable(name='_weights',
shape=weights_shape)
print(weights)
biases = tf.get_variable(name='_biases',
initializer=tf.zeros(
shape=[n_output_channels]))
print(biases)
conv = tf.nn.conv2d(input=input_tensor,
filter=weights,
strides=strides,
padding=padding_mode)
print(conv)
conv = tf.nn.bias_add(conv, biases,
name='net_pre-activation')
print(conv)
conv = tf.nn.relu(conv, name='activation')
print(conv)
return convThis wrapper function will do all the necessary work for building a convolutional layer, including defining the weights, biases, initializing them, and the convolution operation using the tf.nn.conv2d function. There are four required arguments:
input_tensor: The tensor given as input to the convolutional layername: The name of the layer, which is used as the scope namekernel_size: The dimensions of the kernel tensor provided as a tuple or listn_output_channels: The number of output feature maps
Notice that the weights are initialized using the Xavier (or Glorot) initialization method by default when using tf.get_variable (we discussed the Xavier/Glorot initialization scheme in Chapter 14, Going Deeper: The Mechanics of TensorFlow), while the biases are initialized to zeros using the tf.zeros function. The net pre-activations are passed to the ReLU activation function. We can print the operations and TensorFlow graph nodes to see the shape and type of tensors. Let's test this function with a simple input by defining a placeholder, as follows:
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
... conv_layer(x, name='convtest',
... kernel_size=(3, 3),
... n_output_channels=32)
>>>
>>> del g, x
<tf.Variable 'convtest/_weights:0' shape=(3, 3, 1, 32) dtype=float32_ref>
<tf.Variable 'convtest/_biases:0' shape=(32,) dtype=float32_ref>
Tensor("convtest/Conv2D:0", shape=(?, 28, 28, 32), dtype=float32)
Tensor("convtest/net_pre-activaiton:0", shape=(?, 28, 28, 32), dtype=float32)
Tensor("convtest/activation:0", shape=(?, 28, 28, 32), dtype=float32)The next wrapper function is for defining our fully connected layers:
def fc_layer(input_tensor, name,
n_output_units, activation_fn=None):
with tf.variable_scope(name):
input_shape = input_tensor.get_shape().as_list()[1:]
n_input_units = np.prod(input_shape)
if len(input_shape) > 1:
input_tensor = tf.reshape(input_tensor,
shape=(-1, n_input_units))
weights_shape = [n_input_units, n_output_units]
weights = tf.get_variable(name='_weights',
shape=weights_shape)
print(weights)
biases = tf.get_variable(name='_biases',
initializer=tf.zeros(
shape=[n_output_units]))
print(biases)
layer = tf.matmul(input_tensor, weights)
print(layer)
layer = tf.nn.bias_add(layer, biases,
name='net_pre-activaiton')
print(layer)
if activation_fn is None:
return layer
layer = activation_fn(layer, name='activation')
print(layer)
return layerThe wrapper function fc_layer also builds the weights and biases, initializes them similar to the conv_layer function, and then performs a matrix multiplication using the tf.matmul function. The fc_layer function has three required arguments:
input_tensor: The input tensorname: The name of the layer, which is used as the scope namen_output_units: The number of output units
We can test this function for a simple input tensor as follows:
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(tf.float32,
... shape=[None, 28, 28, 1])
... fc_layer(x, name='fctest', n_output_units=32,
... activation_fn=tf.nn.relu)
>>>
>>> del g, x
<tf.Variable 'fctest/_weights:0' shape=(784, 32) dtype=float32_ref>
<tf.Variable 'fctest/_biases:0' shape=(32,) dtype=float32_ref>
Tensor("fctest/MatMul:0", shape=(?, 32), dtype=float32)
Tensor("fctest/net_pre-activaiton:0", shape=(?, 32), dtype=float32)
Tensor("fctest/activation:0", shape=(?, 32), dtype=float32)The behavior of this function is a bit different for the two fully connected layers in our model. The first fully connected layer gets its input right after a convolutional layer; therefore, the input is still a 4D tensor. For the second fully connected layer, we need to flatten the input tensor using the tf.reshape function. Furthermore, the net pre-activations from the first FC layer are passed to the ReLU activation function, but the second one corresponds to the logits, and therefore, a linear activation must be used.
Now we can utilize these wrapper functions to build the whole convolutional network. We define a function called build_cnn to handle the building of the CNN model, as shown in the following code:
def build_cnn(learning_rate=1e-4)
## Placeholders for X and y:
tf_x = tf.placeholder(tf.float32, shape=[None, 784],
name='tf_x')
tf_y = tf.placeholder(tf.int32, shape=[None],
name='tf_y')
# reshape x to a 4D tensor:
# [batchsize, width, height, 1]
tf_x_image = tf.reshape(tf_x, shape=[-1, 28, 28, 1],
name='tf_x_reshaped')
## One-hot encoding:
tf_y_onehot = tf.one_hot(indices=tf_y, depth=10,
dtype=tf.float32,
name='tf_y_onehot')
## 1st layer: Conv_1
print('
Building 1st layer:')
h1 = conv_layer(tf_x_image, name='conv_1',
kernel_size=(5, 5),
padding_mode='VALID',
n_output_channels=32)
## MaxPooling
h1_pool = tf.nn.max_pool(h1,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
## 2n layer: Conv_2
print('
Building 2nd layer:')
h2 = conv_layer(h1_pool, name='conv_2',
kernel_size=(5, 5),
padding_mode='VALID',
n_output_channels=64)
## MaxPooling
h2_pool = tf.nn.max_pool(h2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
## 3rd layer: Fully Connected
print('
Building 3rd layer:')
h3 = fc_layer(h2_pool, name='fc_3',
n_output_units=1024,
activation_fn=tf.nn.relu)
## Dropout
keep_prob = tf.placeholder(tf.float32, name='fc_keep_prob')
h3_drop = tf.nn.dropout(h3, keep_prob=keep_prob,
name='dropout_layer')
## 4th layer: Fully Connected (linear activation)
print('
Building 4th layer:')
h4 = fc_layer(h3_drop, name='fc_4',
n_output_units=10,
activation_fn=None)
## Prediction
predictions = {
'probabilities': tf.nn.softmax(h4, name='probabilities'),
'labels': tf.cast(tf.argmax(h4, axis=1), tf.int32,
name='labels')
}
## Loss Function and Optimization
cross_entropy_loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
logits=h4, labels=tf_y_onehot),
name='cross_entropy_loss')
## Optimizer
optimizer = tf.train.AdamOptimizer(learning_rate)
optimizer = optimizer.minimize(cross_entropy_loss,
name='train_op')
## Computing the prediction accuracy
correct_predictions = tf.equal(
predictions['labels'],
tf_y, name='correct_preds')
accuracy = tf.reduce_mean(
tf.cast(correct_predictions, tf.float32),
name='accuracy')In order to get stable results, we need to use a random seed for both NumPy and TensorFlow. Setting the TensorFlow random seed can be done at the graph level by placing the tf.set_random_seed function within the graph scope, which we will see later. The following figure shows the TensorFlow graph related to our multilayer CNN as visualized by TensorBoard:

Note
Note that in this implementation, we used the tf.train.AdamOptimizer function for training the CNN model. The Adam optimizer is a robust gradient-based optimization method suited for nonconvex optimization and machine learning problems. Two popular optimization methods inspired Adam: RMSProp and AdaGrad.
The key advantage of Adam is in the choice of update step size derived from the running average of gradient moments. Please feel free to read more about the Adam optimizer in the manuscript, Adam: A Method for Stochastic Optimization, Diederik P. Kingma and Jimmy Lei Ba, 2014. The article if freely available at https://arxiv.org/abs/1412.6980.
Furthermore, we will define four other functions: save and load for saving and loading checkpoints of the trained model, train for training the model using training_set, and predict to get prediction probabilities or prediction labels of the test data. The code for these functions is as follows:
def save(saver, sess, epoch, path='./model/'):
if not os.path.isdir(path):
os.makedirs(path)
print('Saving model in %s' % path)
saver.save(sess, os.path.join(path,'cnn-model.ckpt'),
global_step=epoch)
def load(saver, sess, path, epoch):
print('Loading model from %s' % path)
saver.restore(sess, os.path.join(
path, 'cnn-model.ckpt-%d' % epoch))
def train(sess, training_set, validation_set=None,
initialize=True, epochs=20, shuffle=True,
dropout=0.5, random_seed=None):
X_data = np.array(training_set[0])
y_data = np.array(training_set[1])
training_loss = []
## initialize variables
if initialize:
sess.run(tf.global_variables_initializer())
np.random.seed(random_seed) # for shuflling in batch_generator
for epoch in range(1, epochs+1):
batch_gen = batch_generator(
X_data, y_data,
shuffle=shuffle)
avg_loss = 0.0
for i,(batch_x,batch_y) in enumerate(batch_gen):
feed = {'tf_x:0': batch_x,
'tf_y:0': batch_y,
'fc_keep_prob:0': dropout}
loss, _ = sess.run(
['cross_entropy_loss:0', 'train_op'],
feed_dict=feed)
avg_loss += loss
training_loss.append(avg_loss / (i+1))
print('Epoch %02d Training Avg. Loss: %7.3f' % (
epoch, avg_loss), end=' ')
if validation_set is not None:
feed = {'tf_x:0': validation_set[0],
'tf_y:0': validation_set[1],
'fc_keep_prob:0': 1.0}
valid_acc = sess.run('accuracy:0', feed_dict=feed)
print(' Validation Acc: %7.3f' % valid_acc)
else:
print()
def predict(sess, X_test, return_proba=False):
feed = {'tf_x:0': X_test,
'fc_keep_prob:0': 1.0}
if return_proba:
return sess.run('probabilities:0', feed_dict=feed)
else:
return sess.run('labels:0', feed_dict=feed)Now we can create a TensorFlow graph object, set the graph-level random seed, and build the CNN model in that graph, as follows:
>>>## Define random seed >>>random_seed = 123 >>>>>>>>>## create a graph >>>g = tf.Graph() >>>with g.as_default(): ... tf.set_random_seed(random_seed) ... ## build the graph ... build_cnn() ... ... ## saver: ... saver = tf.train.Saver()
Note that in the preceding code, after we built the model by calling the build_cnn function, we created a saver object from the tf.train.Saver class for saving and restoring trained models, as we saw in Chapter 14, Going Deeper – The Mechanics of TensorFlow.
The next step is to train our CNN model. For this, we need to create a TensorFlow session to launch the graph; then, we call the train function. To train the model for the first time, we have to initialize all the variables in the network.
For this purpose, we have defined an argument named initialize that will take care of the initialization. When initialize=True, we will execute tf.global_variables_initializer through session.run. This initialization step should be avoided in case you want to train additional epochs; for example, you can restore an already trained model and train further for additional 10 epochs. The code for training the model for the first time is as follows:
>>> ## create a TF session >>> ## and train the CNN model >>> >>> with tf.Session(graph=g) as sess: ... train(sess, ... training_set=(X_train_centered, y_train), ... validation_set=(X_valid_centered, y_valid), ... initialize=True, ... random_seed=123) ... save(saver, sess, epoch=20) Epoch 01 Training Avg. Loss: 272.772 Validation Acc: 0.973 Epoch 02 Training Avg. Loss: 76.053 Validation Acc: 0.981 Epoch 03 Training Avg. Loss: 51.309 Validation Acc: 0.984 Epoch 04 Training Avg. Loss: 39.740 Validation Acc: 0.986 Epoch 05 Training Avg. Loss: 31.508 Validation Acc: 0.987 ... Epoch 19 Training Avg. Loss: 5.386 Validation Acc: 0.991 Epoch 20 Training Avg. Loss: 3.965 Validation Acc: 0.992 Saving model in ./model/
After the 20 epochs are finished, we save the trained model for future use so that we do not have to retrain the model every time, and therefore, save computational time. The following code shows how to restore a saved model. We delete the graph g, then create a new graph g2, and reload the trained model to do prediction on the test set:
>>> ### Calculate prediction accuracy
>>> ### on test set
>>> ### restoring the saved model
>>>
>>> del g
>>>
>>> ## create a new graph
>>> ## and build the model
>>> g2 = tf.Graph()
>>> with g2.as_default():
... tf.set_random_seed(random_seed)
... ## build the graph
... build_cnn()
...
... ## saver:
... saver = tf.train.Saver()
>>>
>>> ## create a new session
>>> ## and restore the model
>>> with tf.Session(graph=g2) as sess:
... load(saver, sess,
... epoch=20, path='./model/')
...
... preds = predict(sess, X_test_centered,
... return_proba=False)
...
... print('Test Accuracy: %.3f%%' % (100*
np.sum(preds == y_test)/len(y_test)))
Building 1st layer:
..
Building 2nd layer:
..
Building 3rd layer:
..
Building 4th layer:
..
Test Accuracy: 99.310%The output contains several extra lines from the print statements in the build_cnn function, but they are not shown here for brevity. As you can see, the prediction accuracy on the test set is already better than what we achieved using the multilayer perceptron in Chapter 13, Parallelizing Neural Network Training with TensorFlow.
Please, make sure you use X_test_centered, which is the preprocessed version of the test data; you will get lower accuracy if you try using X_test instead.
Now, let's look at the predicted labels as well as their probabilities on the first 10 test samples. We already have the predictions stored in preds; however, in order to have more practice in using the session and launching the graph, we repeat those steps here:
>>> ## run the prediction on >>> ## some test samples >>> np.set_printoptions(precision=2, suppress=True) >>> >>> with tf.Session(graph=g2) as sess: ... load(saver, sess, ... epoch=20, path='./model/') ... ... print(predict(sess, X_test_centered[:10], ... return_proba=False)) ... ... print(predict(sess, X_test_centered[:10], ... return_proba=True)) Loading model from ./model/ INFO:tensorflow:Restoring parameters from ./model/cnn-model.ckpt-20 [7 2 1 0 4 1 4 9 5 9] [[ 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ] [ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. ] [ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ] [ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. ] [ 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. ] [ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ] [ 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. ] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ] [ 0. 0. 0. 0. 0. 0.99 0.01 0. 0. 0. ] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
Finally, let's see how we can train the model further to reach a total of 40 epochs. Since, we have already trained 20 epochs from the initialized weights and biases. We can save time by restoring the already trained model and continue training for 20 additional epochs. This will be very easy to do with our setup. We need to call the train function again, but this time, we set initialize=False to avoid the initialization step. The code is as follows:
## continue training for 20 more epochs
## without re-initializing :: initialize=False
## create a new session
## and restore the model
with tf.Session(graph=g2) as sess:
load(saver, sess,
epoch=20, path='./model/')
train(sess,
training_set=(X_train_centered, y_train),
validation_set=(X_valid_centered, y_valid),
initialize=False,
epochs=20,
random_seed=123)
save(saver, sess, epoch=40, path='./model/')
preds = predict(sess, X_test_centered,
return_proba=False)
print('Test Accuracy: %.3f%%' % (100*
np.sum(preds == y_test)/len(y_test)))The result shows that training for 20 additional epochs slightly improved the performance to get 99.37 percent prediction accuracy on the test set.
In this section, we saw how to implement a multilayer convolutional neural network in the low-level TensorFlow API. In the next section, we'll now implement the same network but we'll use the TensorFlow Layers API.
For the implementation in the TensorFlow Layers API, we need to repeat the same process of loading the data and preprocessing steps to get X_train_centered, X_valid_centered, and X_test_centered. Then, we can implement the model in a new class, as follows:
import tensorflow as tf
import numpy as np
class ConvNN(object):
def __init__(self, batchsize=64,
epochs=20, learning_rate=1e-4,
dropout_rate=0.5,
shuffle=True, random_seed=None):
np.random.seed(random_seed)
self.batchsize = batchsize
self.epochs = epochs
self.learning_rate = learning_rate
self.dropout_rate = dropout_rate
self.shuffle = shuffle
g = tf.Graph()
with g.as_default():
## set random-seed:
tf.set_random_seed(random_seed)
## build the network:
self.build()
## initializer
self.init_op =
tf.global_variables_initializer()
## saver
self.saver = tf.train.Saver()
## create a session
self.sess = tf.Session(graph=g)
def build(self):
## Placeholders for X and y:
tf_x = tf.placeholder(tf.float32,
shape=[None, 784],
name='tf_x')
tf_y = tf.placeholder(tf.int32,
shape=[None],
name='tf_y')
is_train = tf.placeholder(tf.bool,
shape=(),
name='is_train')
## reshape x to a 4D tensor:
## [batchsize, width, height, 1]
tf_x_image = tf.reshape(tf_x, shape=[-1, 28, 28, 1],
name='input_x_2dimages')
## One-hot encoding:
tf_y_onehot = tf.one_hot(indices=tf_y, depth=10,
dtype=tf.float32,
name='input_y_onehot')
## 1st layer: Conv_1
h1 = tf.layers.conv2d(tf_x_image,
kernel_size=(5, 5),
filters=32,
activation=tf.nn.relu)
## MaxPooling
h1_pool = tf.layers.max_pooling2d(h1,
pool_size=(2, 2),
strides=(2, 2))
## 2n layer: Conv_2
h2 = tf.layers.conv2d(h1_pool, kernel_size=(5, 5),
filters=64,
activation=tf.nn.relu)
## MaxPooling
h2_pool = tf.layers.max_pooling2d(h2,
pool_size=(2, 2),
strides=(2, 2))
## 3rd layer: Fully Connected
input_shape = h2_pool.get_shape().as_list()
n_input_units = np.prod(input_shape[1:])
h2_pool_flat = tf.reshape(h2_pool,
shape=[-1, n_input_units])
h3 = tf.layers.dense(h2_pool_flat, 1024,
activation=tf.nn.relu)
## Dropout
h3_drop = tf.layers.dropout(h3,
rate=self.dropout_rate,
training=is_train)
## 4th layer: Fully Connected (linear activation)
h4 = tf.layers.dense(h3_drop, 10,
activation=None)
## Prediction
predictions = {
'probabilities': tf.nn.softmax(h4,
name='probabilities'),
'labels': tf.cast(tf.argmax(h4, axis=1),
tf.int32, name='labels')
}
## Loss Function and Optimization
cross_entropy_loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
logits=h4, labels=tf_y_onehot),
name='cross_entropy_loss')
## Optimizer
optimizer = tf.train.AdamOptimizer(self.learning_rate)
optimizer = optimizer.minimize(cross_entropy_loss,
name='train_op')
## Finding accuracy
correct_predictions = tf.equal(
predictions['labels'],
tf_y, name='correct_preds')
accuracy = tf.reduce_mean(
tf.cast(correct_predictions, tf.float32),
name='accuracy')
def save(self, epoch, path='./tflayers-model/'):
if not os.path.isdir(path):
os.makedirs(path)
print('Saving model in %s' % path)
self.saver.save(self.sess,
os.path.join(path, 'model.ckpt'),
global_step=epoch)
def load(self, epoch, path):
print('Loading model from %s' % path)
self.saver.restore(self.sess,
os.path.join(path, 'model.ckpt-%d' % epoch))
def train(self, training_set,
validation_set=None,
initialize=True):
## initialize variables
if initialize:
self.sess.run(self.init_op)
self.train_cost_ = []
X_data = np.array(training_set[0])
y_data = np.array(training_set[1])
for epoch in range(1, self.epochs+1):
batch_gen =
batch_generator(X_data, y_data,
shuffle=self.shuffle)
avg_loss = 0.0
for i, (batch_x,batch_y) in
enumerate(batch_gen):
feed = {'tf_x:0': batch_x,
'tf_y:0': batch_y,
'is_train:0': True} ## for dropout
loss, _ = self.sess.run(
['cross_entropy_loss:0', 'train_op'],
feed_dict=feed)
avg_loss += loss
print('Epoch %02d: Training Avg. Loss: '
'%7.3f' % (epoch, avg_loss), end=' ')
if validation_set is not None:
feed = {'tf_x:0': batch_x,
'tf_y:0': batch_y,
'is_train:0' : False} ## for dropout
valid_acc = self.sess.run('accuracy:0',
feed_dict=feed)
print('Validation Acc: %7.3f' % valid_acc)
else:
print()
def predict(self, X_test, return_proba=False):
feed = {'tf_x:0' : X_test,
'is_train:0' : False} ## for dropout
if return_proba:
return self.sess.run('probabilities:0',
feed_dict=feed)
else:
return self.sess.run('labels:0',
feed_dict=feed)The structure of this class is very similar to the previous section with the low-level TensorFlow API. The class has a constructor that sets the training parameters, creates a graph g, and builds the model. Besides the constructor, there are five major methods:
.build: Builds the model.save: To save a trained model.load: To restore a saved model.train: Trains the model.predict: To do prediction on a test set
Similar to the implementation in the previous section, we've used a dropout layer after the first fully connected layer. In the previous implementation that used the low-level TensorFlow API, we used the tf.nn.dropout function, but here we used tf.layers.dropout, which is a wrapper for the tf.nn.dropout function. There are two major differences between these two functions that we need to be careful about:
tf.nn.dropout: This has an argument calledkeep_probthat indicates the probability of keeping the units, whiletf.layers.dropouthas arateparameter, which is the rate of dropping units—thereforerate = 1 - keep_prob.- In the
tf.nn.dropoutfunction, we fed thekeep_probparameter using a placeholder so that during the training, we will usekeep_prob=0.5. Then, during the inference (or prediction) mode, we usedkeep_prob=1. However, intf.layers.dropout, the value ofrateis provided upon the creation of the dropout layer in the graph, and we cannot change it during the training or the inference modes. Instead, we need to provide a Boolean argument calledtrainingto determine whether we need to apply dropout or not. This can be done using a placeholder of typetf.bool, which we will feed with the valueTrueduring the training mode andFalseduring the inference mode.
We can create an instance of the ConvNN class, train it for 20 epochs, and save the model. The code for this is as follows:
>>> cnn = ConvNN(random_seed=123) >>> >>> ## train the model >>> cnn.train(training_set=(X_train_centered, y_train), ... validation_set=(X_valid_centered, y_valid), ... initialize=True) >>> cnn.save(epoch=20)
After the training is finished, the model can be used to do prediction on the test dataset, as follows:
>>> del cnn >>> >>> cnn2 = ConvNN(random_seed=123) >>> cnn2.load(epoch=20, path='./tflayers-model/') >>> >>> print(cnn2.predict(X_test_centered[:10, :])) Loading model from ./tflayers-model/ INFO:tensorflow:Restoring parameters from ./tflayers-model/model.ckpt-20 [7 2 1 0 4 1 4 9 5 9]
Finally, we can measure the accuracy of the test dataset as follows:
>>> preds = cnn2.predict(X_test_centered)
>>>
>>> print('Test Accuracy: %.2f%%' % (100*
... np.sum(y_test == preds)/len(y_test)))
Test Accuracy: 99.32%The obtained prediction accuracy is 99.32 percent, which means there are only 68 misclassified test samples!
This concludes our discussion on implementing convolutional neural networks using the TensorFlow low-level API and TensorFlow Layers API. We defined some wrapper functions for the first implementation using the low-level API. The second implementation was more straightforward since we could use the tf.layers.conv2d and tf.layers.dense functions to build the convolutional and the fully connected layers.