
You may remember from Chapter 4, Building Good Training Sets – Data Preprocessing, that we have to convert categorical data, such as text or words, into a numerical form before we can pass it on to a machine learning algorithm. In this section, we will introduce the bag-of-words, which allows us to represent text as numerical feature vectors. The idea behind the bag-of-words model is quite simple and can be summarized as follows:
- We create a vocabulary of unique tokens—for example, words—from the entire set of documents.
- We construct a feature vector from each document that contains the counts of how often each word occurs in the particular document.
Since the unique words in each document represent only a small subset of all the words in the bag-of-words vocabulary, the feature vectors will mostly consist of zeros, which is why we call them sparse. Do not worry if this sounds too abstract; in the following subsections, we will walk through the process of creating a simple bag-of-words model step-by-step.
To construct a bag-of-words model based on the word counts in the respective documents, we can use the CountVectorizer class implemented in scikit-learn. As we will see in the following code section, CountVectorizer takes an array of text data, which can be documents or sentences, and constructs the bag-of-words model for us:
>>> import numpy as np >>> from sklearn.feature_extraction.text import CountVectorizer >>> count = CountVectorizer() >>> docs = np.array([ ... 'The sun is shining', ... 'The weather is sweet', ... ... 'The sun is shining, the weather is sweet, ' ... 'and one and one is two']) >>> bag = count.fit_transform(docs)
By calling the fit_transform method on CountVectorizer, we constructed the vocabulary of the bag-of-words model and transformed the following three sentences into sparse feature vectors:
'The sun is shining''The weather is sweet''The sun is shining, the weather is sweet, and one and one is two'
Now let's print the contents of the vocabulary to get a better understanding of the underlying concepts:
>>> print(count.vocabulary_)
{'and': 0,
'two': 7,
'shining': 3,
'one': 2,
'sun': 4,
'weather': 8,
'the': 6,
'sweet': 5,
'is': 1}As we can see from executing the preceding command, the vocabulary is stored in a Python dictionary that maps the unique words to integer indices. Next, let's print the feature vectors that we just created:
>>> print(bag.toarray()) [[0 1 0 1 1 0 1 0 0] [0 1 0 0 0 1 1 0 1] [2 3 2 1 1 1 2 1 1]]
Each index position in the feature vectors shown here corresponds to the integer values that are stored as dictionary items in the CountVectorizer vocabulary. For example, the first feature at index position 0 resembles the count of the word 'and', which only occurs in the last document, and the word 'is', at index position 1 (the second feature in the document vectors), occurs in all three sentences. These values in the feature vectors are also called the raw term frequencies: ![]() —the number of times a term t occurs in a document d.
—the number of times a term t occurs in a document d.
Note
The sequence of items in the bag-of-words model that we just created is also called the 1-gram or unigram model—each item or token in the vocabulary represents a single word. More generally, the contiguous sequences of items in NLP—words, letters, or symbols—are also called n-grams. The choice of the number n in the n-gram model depends on the particular application; for example, a study by Kanaris and others revealed that n-grams of size 3 and 4 yield good performances in anti-spam filtering of email messages (Words versus character n-grams for anti-spam filtering, Ioannis Kanaris, Konstantinos Kanaris, Ioannis Houvardas, and Efstathios Stamatatos, International Journal on Artificial Intelligence Tools, World Scientific Publishing Company, 16(06): 1047-1067, 2007). To summarize the concept of the n-gram representation, the 1-gram and 2-gram representations of our first document "the sun is shining" would be constructed as follows:
- 1-gram: "the", "sun", "is", "shining"
- 2-gram: "the sun", "sun is", "is shining"
The CountVectorizer class in scikit-learn allows us to use different n-gram models via its ngram_range parameter. While a 1-gram representation is used by default, we could switch to a 2-gram representation by initializing a new CountVectorizer instance with ngram_range=(2,2).
When we are analyzing text data, we often encounter words that occur across multiple documents from both classes. These frequently occurring words typically don't contain useful or discriminatory information. In this subsection, we will learn about a useful technique called term frequency-inverse document frequency (tf-idf) that can be used to downweight these frequently occurring words in the feature vectors. The tf-idf can be defined as the product of the term frequency and the inverse document frequency:

Here the tf(t, d) is the term frequency that we introduced in the previous section, and idf(t, d) is the inverse document frequency and can be calculated as follows:

Here ![]() is the total number of documents, and df(d, t) is the number of documents d that contain the term t. Note that adding the constant 1 to the denominator is optional and serves the purpose of assigning a non-zero value to terms that occur in none of the training samples; the log is used to ensure that low document frequencies are not given too much weight.
is the total number of documents, and df(d, t) is the number of documents d that contain the term t. Note that adding the constant 1 to the denominator is optional and serves the purpose of assigning a non-zero value to terms that occur in none of the training samples; the log is used to ensure that low document frequencies are not given too much weight.
The scikit-learn library implements yet another transformer, the TfidfTransformer class, that takes the raw term frequencies from the CountVectorizer class as input and transforms them into tf-idfs:
>>> from sklearn.feature_extraction.text import TfidfTransformer >>> tfidf = TfidfTransformer(use_idf=True, ... norm='l2', ... smooth_idf=True) >>> np.set_printoptions(precision=2) >>> print(tfidf.fit_transform(count.fit_transform(docs)) ... .toarray()) [[ 0. 0.43 0. 0.56 0.56 0. 0.43 0. 0. ] [ 0. 0.43 0. 0. 0. 0.56 0.43 0. 0.56] [ 0.5 0.45 0.5 0.19 0.19 0.19 0.3 0.25 0.19]]
As we saw in the previous subsection, the word 'is' had the largest term frequency in the third document, being the most frequently occurring word. However, after transforming the same feature vector into tf-idfs, we see that the word 'is' is now associated with a relatively small tf-idf (0.45) in the third document, since it is also present in the first and second document and thus is unlikely to contain any useful discriminatory information.
However, if we'd manually calculated the tf-idfs of the individual terms in our feature vectors, we'd notice that TfidfTransformer calculates the tf-idfs slightly differently compared to the standard textbook equations that we defined previously. The equations for the inverse document frequency implemented in scikit-learn is computed as follows:

Similarly, the tf-idf computed in scikit-learn deviates slightly from the default equation we defined earlier:

While it is also more typical to normalize the raw term frequencies before calculating the tf-idfs, TfidfTransformer class normalizes the tf-idfs directly. By default (norm='l2'), scikit-learn's TfidfTransformer applies the L2-normalization, which returns a vector of length 1 by dividing an un-normalized feature vector v by its L2-norm:

To make sure that we understand how TfidfTransformer works, let's walk through an example and calculate the tf-idf of the word 'is' in the third document.
The word 'is' has a term frequency of 3 (tf=3) in the third document, and the document frequency of this term is 3 since the term 'is' occurs in all three documents (df=3). Thus, we can calculate the inverse document frequency as follows:
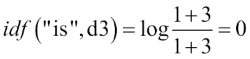
Now, in order to calculate the tf-idf, we simply need to add 1 to the inverse document frequency and multiply it by the term frequency:

If we repeated this calculation for all terms in the third document, we'd obtain the following tf-idf vectors: [3.39, 3.0, 3.39, 1.29, 1.29, 1.29, 2.0, 1.69, 1.29]. However, notice that the values in this feature vector are different from the values that we obtained from TfidfTransformer that we used previously. The final step that we are missing in this tf-idf calculation is the L2-normalization, which can be applied as follows:

As we can see, the results now match the results returned by scikit-learn's TfidfTransformer, and since we now understand how tf-idfs are calculated, let's proceed to the next section and apply those concepts to the movie review dataset.
In the previous subsections, we learned about the bag-of-words model, term bag-of-words model, term frequencies, and tf-idfs. However, the first important step—before we build our bag-of-words model—is to clean the text data by stripping it of all unwanted characters. To illustrate why this is important, let's display the last 50 characters from the first document in the reshuffled movie review dataset:
>>> df.loc[0, 'review'][-50:] 'is seven.<br /><br />Title (Brazil): Not Available'
As we can see here, the text contains HTML markup as well as punctuation and other non-letter characters. While HTML markup does not contain much useful semantics, punctuation marks can represent useful, additional information in certain NLP contexts. However, for simplicity, we will now remove all punctuation marks except for emoticon characters such as :) since those are certainly useful for sentiment analysis. To accomplish this task, we will use Python's regular expression (regex) library, re, as shown here:
>>> import re
>>> def preprocessor(text):
... text = re.sub('<[^>]*>', '', text)
... emoticons = re.findall('(?::|;|=)(?:-)?(?:)|(|D|P)',
... text)
... text = (re.sub('[W]+', ' ', text.lower()) +
... ' '.join(emoticons).replace('-', ''))
... return textVia the first regex <[^>]*> in the preceding code section, we tried to remove all of the HTML markup from the movie reviews. Although many programmers generally advise against the use of regex to parse HTML, this regex should be sufficient to clean this particular dataset. After we removed the HTML markup, we used a slightly more complex regex to find emoticons, which we temporarily stored as emoticons. Next, we removed all non-word characters from the text via the regex [W]+ and converted the text into lowercase characters.
Note
In the context of this analysis, we assume that the capitalization of a word—for example, whether it appears at the beginning of a sentence—does not contain semantically relevant information. However, note that there are exceptions, for instance, we remove the notation of proper names. But again, in the context of this analysis, it is a simplifying assumption that the letter case does not contain information that is relevant for sentiment analysis.
Eventually, we added the temporarily stored emoticons to the end of the processed document string. Additionally, we removed the nose character (-) from the emoticons for consistency.
Note
Although regular expressions offer an efficient and convenient approach to searching for characters in a string, they also come with a steep learning curve. Unfortunately, an in-depth discussion of regular expressions is beyond the scope of this book. However, you can find a great tutorial on the Google Developers portal at https://developers.google.com/edu/python/regular-expressions or check out the official documentation of Python's re module at https://docs.python.org/3.6/library/re.html.
Although the addition of the emoticon characters to the end of the cleaned document strings may not look like the most elegant approach, we shall note that the order of the words doesn't matter in our bag-of-words model if our vocabulary consists of only one-word tokens. But before we talk more about the splitting of documents into individual terms, words, or tokens, let's confirm that our preprocessor works correctly:
>>> preprocessor(df.loc[0, 'review'][-50:])
'is seven title brazil not available'
>>> preprocessor("</a>This :) is :( a test :-)!")
'this is a test :) :( :)'Lastly, since we will make use of the cleaned text data over and over again during the next sections, let us now apply our preprocessor function to all the movie reviews in our DataFrame:
>>> df['review'] = df['review'].apply(preprocessor)
After successfully preparing the movie review dataset, we now need to think about how to split the text corpora into individual elements. One way to tokenize documents is to split them into individual words by splitting the cleaned documents at its whitespace characters:
>>> def tokenizer(text):
... return text.split()
>>> tokenizer('runners like running and thus they run')
['runners', 'like', 'running', 'and', 'thus', 'they', 'run']In the context of tokenization, another useful technique is word stemming, which is the process of transforming a word into its root form. It allows us to map related words to the same stem. The original stemming algorithm was developed by Martin F. Porter in 1979 and is hence known as the Porter stemmer algorithm (An algorithm for suffix stripping, Martin F. Porter, Program: Electronic Library and Information Systems, 14(3): 130–137, 1980). The Natural Language Toolkit (NLTK, http://www.nltk.org) for Python implements the Porter stemming algorithm, which we will use in the following code section. In order to install the NLTK, you can simply execute conda install nltk or pip install nltk.
Note
Although the NLTK is not the focus of the chapter, I highly recommend that you visit the NLTK website as well as read the official NLTK book, which is freely available at http://www.nltk.org/book/, if you are interested in more advanced applications in NLP.
The following code shows how to use the Porter stemming algorithm:
>>> from nltk.stem.porter import PorterStemmer
>>> porter = PorterStemmer()
>>> def tokenizer_porter(text):
... return [porter.stem(word) for word in text.split()]
>>> tokenizer_porter('runners like running and thus they run')
['runner', 'like', 'run', 'and', 'thu', 'they', 'run']Using the PorterStemmer from the nltk package, we modified our tokenizer function to reduce words to their root form, which was illustrated by the simple preceding example where the word 'running' was stemmed to its root form 'run'.
Note
The Porter stemming algorithm is probably the oldest and simplest stemming algorithm. Other popular stemming algorithms include the newer Snowball stemmer (Porter2 or English stemmer) and the Lancaster stemmer (Paice/Husk stemmer), which is faster but also more aggressive than the Porter stemmer. These alternative stemming algorithms are also available through the NLTK package (http://www.nltk.org/api/nltk.stem.html).
While stemming can create non-real words, such as 'thu' (from 'thus'), as shown in the previous example, a technique called lemmatization
aims to obtain the canonical (grammatically correct) forms of individual words—the so-called lemmas. However, lemmatization is computationally more difficult and expensive compared to stemming and, in practice, it has been observed that stemming and lemmatization have little impact on the performance of text classification (Influence of Word Normalization on Text Classification, Michal Toman, Roman Tesar, and Karel Jezek, Proceedings of InSciT, pages 354–358, 2006).
Before we jump into the next section, where we will train a machine learning model using the bag-of-words model, let's briefly talk about another useful topic called stop-word removal. Stop-words are simply those words that are extremely common in all sorts of texts and probably bear no (or only little) useful information that can be used to distinguish between different classes of documents. Examples of stop-words are is, and, has, and like. Removing stop-words can be useful if we are working with raw or normalized term frequencies rather than tf-idfs, which are already downweighting frequently occurring words.
In order to remove stop-words from the movie reviews, we will use the set of 127 English stop-words that is available from the NLTK library, which can be obtained by calling the nltk.download function:
>>> import nltk
>>> nltk.download('stopwords')After we download the stop-words set, we can load and apply the English stop-word set as follows:
>>> from nltk.corpus import stopwords
>>> stop = stopwords.words('english')
>>> [w for w in tokenizer_porter('a runner likes running and runs a lot')[-10:] if w not in stop]
['runner', 'like', 'run', 'run', 'lot']