
Another powerful and widely used learning algorithm is the Support Vector Machine (SVM), which can be considered an extension of the perceptron. Using the perceptron algorithm, we minimized misclassification errors. However, in SVMs our optimization objective is to maximize the margin. The margin is defined as the distance between the separating hyperplane (decision boundary) and the training samples that are closest to this hyperplane, which are the so-called support vectors. This is illustrated in the following figure:

The rationale behind having decision boundaries with large margins is that they tend to have a lower generalization error whereas models with small margins are more prone to overfitting. To get an idea of the margin maximization, let's take a closer look at those positive and negative hyperplanes that are parallel to the decision boundary, which can be expressed as follows:
If we subtract those two linear equations (1) and (2) from each other, we get:

We can normalize this equation by the length of the vector w, which is defined as follows:

So we arrive at the following equation:

The left side of the preceding equation can then be interpreted as the distance between the positive and negative hyperplane, which is the so-called margin that we want to maximize.
Now, the objective function of the SVM becomes the maximization of this margin by maximizing ![]() under the constraint that the samples are classified correctly, which can be written as:
under the constraint that the samples are classified correctly, which can be written as:

Here, N is the number of samples in our dataset.
These two equations basically say that all negative samples should fall on one side of the negative hyperplane, whereas all the positive samples should fall behind the positive hyperplane, which can also be written more compactly as follows:

In practice though, it is easier to minimize the reciprocal term  , which can be solved by quadratic programming. However, a detailed discussion about quadratic programming is beyond the scope of this book. You can learn more about support vector machines in The Nature of Statistical Learning Theory, Springer Science+Business Media, Vladimir Vapnik, 2000 or Chris J.C. Burges' excellent explanation in A Tutorial on Support Vector Machines for Pattern Recognition (Data Mining and Knowledge Discovery, 2(2): 121-167, 1998).
, which can be solved by quadratic programming. However, a detailed discussion about quadratic programming is beyond the scope of this book. You can learn more about support vector machines in The Nature of Statistical Learning Theory, Springer Science+Business Media, Vladimir Vapnik, 2000 or Chris J.C. Burges' excellent explanation in A Tutorial on Support Vector Machines for Pattern Recognition (Data Mining and Knowledge Discovery, 2(2): 121-167, 1998).
Although we don't want to dive much deeper into the more involved mathematical concepts behind the maximum-margin classification, let us briefly mention the slack variable ![]() , which was introduced by Vladimir Vapnik in 1995 and led to the so-called soft-margin classification. The motivation for introducing the slack variable
, which was introduced by Vladimir Vapnik in 1995 and led to the so-called soft-margin classification. The motivation for introducing the slack variable ![]() was that the linear constraints need to be relaxed for nonlinearly separable data to allow the convergence of the optimization in the presence of misclassifications, under appropriate cost penalization.
was that the linear constraints need to be relaxed for nonlinearly separable data to allow the convergence of the optimization in the presence of misclassifications, under appropriate cost penalization.
The positive-values slack variable is simply added to the linear constraints:
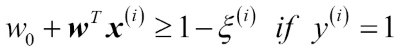

Here, N is the number of samples in our dataset. So the new objective to be minimized (subject to the constraints) becomes:

Via the variable C, we can then control the penalty for misclassification. Large values of C correspond to large error penalties, whereas we are less strict about misclassification errors if we choose smaller values for C. We can then use the C parameter to control the width of the margin and therefore tune the bias-variance trade-off, as illustrated in the following figure:

This concept is related to regularization, which we discussed in the previous section in the context of regularized regression where decreasing the value of C increases the bias and lowers the variance of the model.
Now that we have learned the basic concepts behind a linear SVM, let us train an SVM model to classify the different flowers in our Iris dataset:
>>> from sklearn.svm import SVC
>>> svm = SVC(kernel='linear', C=1.0, random_state=1)
>>> svm.fit(X_train_std, y_train)
>>> plot_decision_regions(X_combined_std,
... y_combined,
... classifier=svm,
... test_idx=range(105, 150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()The three decision regions of the SVM, visualized after training the classifier on the Iris dataset by executing the preceding code example, are shown in the following plot:

Note
Logistic regression versus support vector machines
In practical classification tasks, linear logistic regression and linear SVMs often yield very similar results. Logistic regression tries to maximize the conditional likelihoods of the training data, which makes it more prone to outliers than SVMs, which mostly care about the points that are closest to the decision boundary (support vectors). On the other hand, logistic regression has the advantage that it is a simpler model and can be implemented more easily. Furthermore, logistic regression models can be easily updated, which is attractive when working with streaming data.
The scikit-learn library's Perceptron and LogisticRegression classes, which we used in the previous sections, make use of the LIBLINEAR library, which is a highly optimized C/C++ library developed at the National Taiwan University (http://www.csie.ntu.edu.tw/~cjlin/liblinear/). Similarly, the SVC class that we used to train an SVM makes use of LIBSVM, which is an equivalent C/C++ library specialized for SVMs (http://www.csie.ntu.edu.tw/~cjlin/libsvm/).
The advantage of using LIBLINEAR and LIBSVM over native Python implementations is that they allow the extremely quick training of large amounts of linear classifiers. However, sometimes our datasets are too large to fit into computer memory. Thus, scikit-learn also offers alternative implementations via the SGDClassifier class, which also supports online learning via the partial_fit method. The concept behind the SGDClassifier class is similar to the stochastic gradient algorithm that we implemented in Chapter 2, Training Simple Machine Learning Algorithms for Classification, for Adaline. We could initialize the stochastic gradient descent version of the perceptron, logistic regression, and a support vector machine with default parameters as follows:
>>> from sklearn.linear_model import SGDClassifier >>> ppn = SGDClassifier(loss='perceptron') >>> lr = SGDClassifier(loss='log') >>> svm = SGDClassifier(loss='hinge')