
In this section, now that we understand sequences, we can look at the foundations of RNNs. We'll start by introducing the typical structure of an RNN, and we'll see how the data flows through it with one or more hidden layers. We'll then examine how the neuron activations are computed in a typical RNN. This will create a context for us to discuss the common challenges in training RNNs, and explore the modern solution to these challenges—LSTM.
Let's start by introducing the architecture of an RNN. The following figure shows a standard feedforward neural network and an RNN, in a side by side for comparison:

Both of these networks have only one hidden layer. In this representation, the units are not displayed, but we assume that the input layer (x), hidden layer (h), and output layer (y) are vectors which contain many units.
Note
This generic RNN architecture could correspond to the two sequence modeling categories where the input is a sequence. Thus, it could be either many-to-many if we consider ![]() as the final output, or it could be many-to-one if, for example, we only use the last element of
as the final output, or it could be many-to-one if, for example, we only use the last element of ![]() as the final output.
as the final output.
Later, we will see how the output sequence ![]() can be converted into standard, nonsequential output.
can be converted into standard, nonsequential output.
In a standard feedforward network, information flows from the input to the hidden layer, and then from the hidden layer to the output layer. On the other hand, in a recurrent network, the hidden layer gets its input from both the input layer and the hidden layer from the previous time step.
The flow of information in adjacent time steps in the hidden layer allows the network to have a memory of past events. This flow of information is usually displayed as a loop, also known as a recurrent edge in graph notation, which is how this general architecture got its name.
In the following figure, the single hidden layer network and the multilayer network illustrate two contrasting architectures:

In order to examine the architecture of RNNs and the flow of information, a compact representation with a recurrent edge can be unfolded, which you can see in the preceding figure.
As we know, each hidden unit in a standard neural network receives only one input—the net preactivation associated with the input layer. Now, in contrast, each hidden unit in an RNN receives two distinct sets of input—the preactivation from the input layer and the activation of the same hidden layer from the previous time step t-1.
At the first time step t = 0, the hidden units are initialized to zeros or small random values. Then, at a time step where t > 0, the hidden units get their input from the data point at the current time ![]() and the previous values of hidden units at t - 1, indicated as
and the previous values of hidden units at t - 1, indicated as ![]() .
.
Similarly, in the case of a multilayer RNN, we can summarize the information flow as follows:
 : Here, the hidden layer is represented as
: Here, the hidden layer is represented as  and gets its input from the data point
and gets its input from the data point  and the hidden values in the same layer, but the previous time step
and the hidden values in the same layer, but the previous time step 
 : The second hidden layer,
: The second hidden layer,  receives its inputs from the hidden units from the layer below at the current time step () and its own hidden values from the previous time step
receives its inputs from the hidden units from the layer below at the current time step () and its own hidden values from the previous time step 
Now that we understand the structure and general flow of information in an RNN, let's get more specific and compute the actual activations of the hidden layers as well as the output layer. For simplicity, we'll consider just a single hidden layer; however, the same concept applies to multilayer RNNs.
Each directed edge (the connections between boxes) in the representation of an RNN that we just looked at is associated with a weight matrix. Those weights do not depend on time t; therefore, they are shared across the time axis. The different weight matrices in a single layer RNN are as follows:
 : The weight matrix between the input and the hidden layer h
: The weight matrix between the input and the hidden layer h : The weight matrix associated with the recurrent edge
: The weight matrix associated with the recurrent edge
 : The weight matrix between the hidden layer and output layer
: The weight matrix between the hidden layer and output layer
You can see these weight matrices in the following figure:

In certain implementations, you may observe that weight matrices ![]() and
and ![]() are concatenated to a combined matrix
are concatenated to a combined matrix ![]() . Later on, we'll make use of this notation as well.
. Later on, we'll make use of this notation as well.
Computing the activations is very similar to standard multilayer perceptrons and other types of feedforward neural networks. For the hidden layer, the net input ![]() (preactivation) is computed through a linear combination. That is, we compute the sum of the multiplications of the weight matrices with the corresponding vectors and add the bias unit—
(preactivation) is computed through a linear combination. That is, we compute the sum of the multiplications of the weight matrices with the corresponding vectors and add the bias unit—![]() . Then, the activations of the hidden units at the time step t are calculated as follows:
. Then, the activations of the hidden units at the time step t are calculated as follows:

Here, ![]() is the bias vector for the hidden units and
is the bias vector for the hidden units and ![]() is the activation function of the hidden layer.
is the activation function of the hidden layer.
In case you want to use the concatenated weight matrix ![]() , the formula for computing hidden units will change as follows:
, the formula for computing hidden units will change as follows:

Once the activations of hidden units at the current time step are computed, then the activations of output units will be computed as follows:

To help clarify this further, the following figure shows the process of computing these activations with both formulations:

Note
Training RNNs using BPTT
The learning algorithm for RNNs was introduced in 1990s Backpropagation Through Time: What It Does and How to Do It (Paul Werbos, Proceedings of IEEE, 78(10):1550-1560, 1990).
The derivation of the gradients might be a bit complicated, but the basic idea is that the overall loss L is the sum of all the loss functions at times ![]() to
to ![]() :
:

Since the loss at time ![]() is dependent on the hidden units at all previous time steps
is dependent on the hidden units at all previous time steps ![]() , the gradient will be computed as follows:
, the gradient will be computed as follows:

Here,  is computed as a multiplication of adjacent time steps:
is computed as a multiplication of adjacent time steps:

Backpropagation through time, or BPTT, which we briefly mentioned in the previous information box, introduces some new challenges.
Because of the multiplicative factor 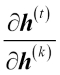 in the computing gradients of a loss function, the so-called vanishing or exploding gradient problem arises. This problem is explained through the examples in the following figure, which shows an RNN with only one hidden unit for simplicity:
in the computing gradients of a loss function, the so-called vanishing or exploding gradient problem arises. This problem is explained through the examples in the following figure, which shows an RNN with only one hidden unit for simplicity:

Basically, has ![]() multiplications; therefore, multiplying the w weight
multiplications; therefore, multiplying the w weight ![]() times results in a factor—
times results in a factor—![]() . As a result, if
. As a result, if ![]() , this factor becomes very small when
, this factor becomes very small when ![]() is large. On the other hand, if the weight of the recurrent edge is
is large. On the other hand, if the weight of the recurrent edge is ![]() , then
, then ![]() becomes very large when
becomes very large when ![]() is large. Note that large
is large. Note that large ![]() refers to long-range dependencies.
refers to long-range dependencies.
Intuitively, we can see that a naïve solution to avoid vanishing or exploding gradient can be accomplished by ensuring ![]() . If you are interested and would like to investigate this in more detail, I encourage you to read On the difficulty of training recurrent neural networks by R. Pascanu, T. Mikolov, and Y. Bengio, 2012 (https://arxiv.org/pdf/1211.5063.pdf).
. If you are interested and would like to investigate this in more detail, I encourage you to read On the difficulty of training recurrent neural networks by R. Pascanu, T. Mikolov, and Y. Bengio, 2012 (https://arxiv.org/pdf/1211.5063.pdf).
In practice, there are two solutions to this problem:
- Truncated backpropagation through time (TBPTT)
- Long short-term memory (LSTM)
TBPTT clips the gradients above a given threshold. While TBPTT can solve the exploding gradient problem, the truncation limits the number of steps that the gradient can effectively flow back and properly update the weights.
On the other hand, LSTM, designed in 1997 by Hochreiter and Schmidhuber, has been more successful in modeling long-range sequences by overcoming the vanishing gradient problem. Let's discuss LSTM in more detail.
LSTMs were first introduced to overcome the vanishing gradient problem (Long Short-Term Memory, S. Hochreiter and J. Schmidhuber, Neural Computation, 9(8): 1735-1780, 1997). The building block of an LSTM is a memory cell, which essentially represents the hidden layer.
In each memory cell, there is a recurrent edge that has the desirable weight ![]() , as we discussed previously, to overcome the vanishing and exploding gradient problems. The values associated with this recurrent edge is called cell state. The unfolded structure of a modern LSTM cell is shown in the following figure:
, as we discussed previously, to overcome the vanishing and exploding gradient problems. The values associated with this recurrent edge is called cell state. The unfolded structure of a modern LSTM cell is shown in the following figure:

Notice that the cell state from the previous time step, ![]() , is modified to get the cell state at the current time step,
, is modified to get the cell state at the current time step, ![]() , without being multiplied directly with any weight factor.
, without being multiplied directly with any weight factor.
The flow of information in this memory cell is controlled by some units of computation that we'll describe here. In the previous figure, ![]() refers to the element-wise product (element-wise multiplication) and
refers to the element-wise product (element-wise multiplication) and ![]() means element-wise summation (element-wise addition). Furthermore,
means element-wise summation (element-wise addition). Furthermore, ![]() refers to the input data at time t, and
refers to the input data at time t, and ![]() indicates the hidden units at time
indicates the hidden units at time ![]() .
.
Four boxes are indicated with an activation function, either the sigmoid function (![]() ) or hyperbolic tangent (tanh), and a set of weights; these boxes apply linear combination by performing matrix-vector multiplications on their input. These units of computation with sigmoid activation functions, whose output units are passed through
) or hyperbolic tangent (tanh), and a set of weights; these boxes apply linear combination by performing matrix-vector multiplications on their input. These units of computation with sigmoid activation functions, whose output units are passed through ![]() , are called gates.
, are called gates.
In an LSTM cell, there are three different types of gates, known as the forget gate, the input gate, and the output gate:
-
The forget gate (
 ) allows the memory cell to reset the cell state without growing indefinitely. In fact, the forget gate decides which information is allowed to go through and which information to suppress. Now, is computed as follows:
Note that the forget gate was not part of the original LSTM cell; it was added a few years later to improve the original model (Learning to Forget: Continual Prediction with LSTM, F. Gers, J. Schmidhuber, and F. Cummins, Neural Computation 12, 2451-2471, 2000).
) allows the memory cell to reset the cell state without growing indefinitely. In fact, the forget gate decides which information is allowed to go through and which information to suppress. Now, is computed as follows:
Note that the forget gate was not part of the original LSTM cell; it was added a few years later to improve the original model (Learning to Forget: Continual Prediction with LSTM, F. Gers, J. Schmidhuber, and F. Cummins, Neural Computation 12, 2451-2471, 2000).
-
The input gate (
 ) and input node (
) and input node ( ) are responsible for updating the cell state. They are computed as follows:
) are responsible for updating the cell state. They are computed as follows:
 The cell state at time t is computed as follows:
The cell state at time t is computed as follows:

-
The output gate (
 ) decides how to update the values of hidden units:
) decides how to update the values of hidden units:

Given this, the hidden units at the current time step are computed as follows:

The structure of an LSTM cell and its underlying computations might seem too complex. However, the good news is that TensorFlow has already implemented everything in wrapper functions that allows us to define our LSTM cells easily. We'll see the real application of LSTMs in action when we use TensorFlow later in this chapter.
Note
We have introduced LSTMs in this section, which provide a basic approach for modeling long-range dependencies in sequences. Yet, it is important to note that there are many variations of LSTMs described in literature (An Empirical Exploration of Recurrent Network Architectures, Rafal Jozefowicz, Wojciech Zaremba, and Ilya Sutskever, Proceedings of ICML, 2342-2350, 2015).
Also, worth noting is a more recent approach, called Gated Recurrent Unit (GRU), which was proposed in 2014. GRUs have a simpler architecture than LSTMs; therefore, they are computationally more efficient while their performance in some tasks, such as polyphonic music modeling, is comparable to LSTMs. If you are interested in learning more about these modern RNN architectures, refer to the paper, Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling by Junyoung Chung and others 2014 (https://arxiv.org/pdf/1412.3555v1.pdf).