
In this chapter, we will make use of two of the first algorithmically described machine learning algorithms for classification, the perceptron and adaptive linear neurons. We will start by implementing a perceptron step by step in Python and training it to classify different flower species in the Iris dataset. This will help us understand the concept of machine learning algorithms for classification and how they can be efficiently implemented in Python.
Discussing the basics of optimization using adaptive linear neurons will then lay the groundwork for using more powerful classifiers via the scikit-learn machine learning library in Chapter 3, A Tour of Machine Learning Classifiers Using scikit-learn.
The topics that we will cover in this chapter are as follows:
- Building an intuition for machine learning algorithms
- Using pandas, NumPy, and Matplotlib to read in, process, and visualize data
- Implementing linear classification algorithms in Python
Before we discuss the perceptron and related algorithms in more detail, let us take a brief tour through the early beginnings of machine learning. Trying to understand how the biological brain works, in order to design AI, Warren McCulloch and Walter Pitts published the first concept of a simplified brain cell, the so-called McCulloch-Pitts (MCP) neuron, in 1943 (A Logical Calculus of the Ideas Immanent in Nervous Activity, W. S. McCulloch and W. Pitts, Bulletin of Mathematical Biophysics, 5(4): 115-133, 1943). Neurons are interconnected nerve cells in the brain that are involved in the processing and transmitting of chemical and electrical signals, which is illustrated in the following figure:

McCulloch and Pitts described such a nerve cell as a simple logic gate with binary outputs; multiple signals arrive at the dendrites, are then integrated into the cell body, and, if the accumulated signal exceeds a certain threshold, an output signal is generated that will be passed on by the axon.
Only a few years later, Frank Rosenblatt published the first concept of the perceptron learning rule based on the MCP neuron model (The Perceptron: A Perceiving and Recognizing Automaton, F. Rosenblatt, Cornell Aeronautical Laboratory, 1957). With his perceptron rule, Rosenblatt proposed an algorithm that would automatically learn the optimal weight coefficients that are then multiplied with the input features in order to make the decision of whether a neuron fires or not. In the context of supervised learning and classification, such an algorithm could then be used to predict if a sample belongs to one class or the other.
More formally, we can put the idea behind artificial neurons into the context of a binary classification task where we refer to our two classes as 1 (positive class) and -1 (negative class) for simplicity. We can then define a decision function (![]() ) that takes a linear combination of certain input values x and a corresponding weight vector w, where z is the so-called net input
) that takes a linear combination of certain input values x and a corresponding weight vector w, where z is the so-called net input ![]() :
:

Now, if the net input of a particular sample ![]() is greater than a defined threshold
is greater than a defined threshold ![]() , we predict class 1, and class -1 otherwise. In the perceptron algorithm, the decision function
, we predict class 1, and class -1 otherwise. In the perceptron algorithm, the decision function ![]() is a variant of a unit step function:
is a variant of a unit step function:

For simplicity, we can bring the threshold ![]() to the left side of the equation and define a weight-zero as
to the left side of the equation and define a weight-zero as ![]() and
and ![]() so that we write z in a more compact form:
so that we write z in a more compact form:
And:

In machine learning literature, the negative threshold, or weight, ![]() , is usually called the bias unit.
, is usually called the bias unit.
Note
In the following sections, we will often make use of basic notations from linear algebra. For example, we will abbreviate the sum of the products of the values in x and w using a vector dot product, whereas superscript T stands for transpose, which is an operation that transforms a column vector into a row vector and vice versa:

For example:

Furthermore, the transpose operation can also be applied to matrices to reflect it over its diagonal, for example:

In this book, we will only use very basic concepts from linear algebra; however, if you need a quick refresher, please take a look at Zico Kolter's excellent Linear Algebra Review and Reference, which is freely available at http://www.cs.cmu.edu/~zkolter/course/linalg/linalg_notes.pdf.
The following figure illustrates how the net input ![]() is squashed into a binary output (
is squashed into a binary output (-1 or 1) by the decision function of the perceptron (left subfigure) and how it can be used to discriminate between two linearly separable classes (right subfigure):

The whole idea behind the MCP neuron and Rosenblatt's thresholded perceptron model is to use a reductionist approach to mimic how a single neuron in the brain works: it either fires or it doesn't. Thus, Rosenblatt's initial perceptron rule is fairly simple and can be summarized by the following steps:
- Initialize the weights to 0 or small random numbers.
-
For each training sample
 :
a. Compute the output value
:
a. Compute the output value  .
b. Update the weights.
.
b. Update the weights.
Here, the output value is the class label predicted by the unit step function that we defined earlier, and the simultaneous update of each weight ![]() in the weight vector w can be more formally written as:
in the weight vector w can be more formally written as:

The value of ![]() , which is used to update the weight
, which is used to update the weight ![]() , is calculated by the perceptron learning rule:
, is calculated by the perceptron learning rule:

Where ![]() is the learning rate (typically a constant between 0.0 and 1.0),
is the learning rate (typically a constant between 0.0 and 1.0), ![]() is the true class label of the ith training sample, and
is the true class label of the ith training sample, and ![]() is the predicted class label. It is important to note that all weights in the weight vector are being updated simultaneously, which means that we don't recompute the
is the predicted class label. It is important to note that all weights in the weight vector are being updated simultaneously, which means that we don't recompute the ![]() before all of the weights
before all of the weights ![]() are updated. Concretely, for a two-dimensional dataset, we would write the update as:
are updated. Concretely, for a two-dimensional dataset, we would write the update as:
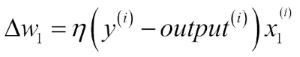

Before we implement the perceptron rule in Python, let us make a simple thought experiment to illustrate how beautifully simple this learning rule really is. In the two scenarios where the perceptron predicts the class label correctly, the weights remain unchanged:


However, in the case of a wrong prediction, the weights are being pushed towards the direction of the positive or negative target class:


To get a better intuition for the multiplicative factor ![]() , let us go through another simple example, where:
, let us go through another simple example, where:

Let's assume that ![]() , and we misclassify this sample as -1. In this case, we would increase the corresponding weight by 1 so that the net input
, and we misclassify this sample as -1. In this case, we would increase the corresponding weight by 1 so that the net input ![]() would be more positive the next time we encounter this sample, and thus be more likely to be above the threshold of the unit step function to classify the sample as +1:
would be more positive the next time we encounter this sample, and thus be more likely to be above the threshold of the unit step function to classify the sample as +1:

The weight update is proportional to the value of ![]() . For example, if we have another sample
. For example, if we have another sample ![]() that is incorrectly classified as -1, we'd push the decision boundary by an even larger extent to classify this sample correctly the next time:
that is incorrectly classified as -1, we'd push the decision boundary by an even larger extent to classify this sample correctly the next time:

It is important to note that the convergence of the perceptron is only guaranteed if the two classes are linearly separable and the learning rate is sufficiently small. If the two classes can't be separated by a linear decision boundary, we can set a maximum number of passes over the training dataset (epochs) and/or a threshold for the number of tolerated misclassifications—the perceptron would never stop updating the weights otherwise:

Note
Downloading the example code
If you bought this book directly from Packt, you can download the example code files from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can download all code examples and datasets directly from https://github.com/rasbt/python-machine-learning-book-2nd-edition.
Now, before we jump into the implementation in the next section, let us summarize what we just learned in a simple diagram that illustrates the general concept of the perceptron:

The preceding diagram illustrates how the perceptron receives the inputs of a sample x and combines them with the weights w to compute the net input. The net input is then passed on to the threshold function, which generates a binary output -1 or +1—the predicted class label of the sample. During the learning phase, this output is used to calculate the error of the prediction and update the weights.