
11.2 Overview of the State of the Art in Context-aware Content Adaptation
This section provides a summary of recent developments and standardization efforts in context-aware content adaptation systems. It presents established concepts in context-aware computing, context models, and existing systems, architectures, and frameworks for context-aware content adaptation. It addresses aspects related to the acquisition of context, forms of processing contextual information, privacy aspects and protection of digital rights, and finally forms of reacting to context.
11.2.1 Recent Developments in Context-aware Systems
Context-awareness can be defined as the ability of systems, devices, or software programs to be aware of the characteristics and constraints of the environment and accordingly perform a number of actions/operations automatically to adapt to sensed environmental changes.
The use of contextual information is instrumental in the successful implementation of useful and meaningful content adaptation operations. These, in turn, are becoming extremely important for the implementation of systems and platforms that deliver multimedia services to the end user. Content adaptation has in fact already gained a considerable importance in today's multimedia communications, and will certainly become an essential functionality of any service, application, or system in the near future. Continuing advances in technology will only emphasize the great heterogeneity that exists today in devices, systems, services, and applications. This will also bring out the desire in consumers for more choices, better quality, and more personalization options. However, to empower these systems to perform meaningful content adaptation operations that meet users' expectations and satisfy their usage environment constraints, it is imperative that they use contextual information, and take decisions based on that information. This section provides an overview of recent developments concerning the use of contextual information. Research on context-awareness started more than a decade ago [1]. However, it was only recently that this concept gained popularity within the multimedia research community and began to be addressed at the standardization level.
11.2.1.1 Concepts and Models
Many different definitions can be found for context-aware applications, but most clearly relate them to adaptation operations. Accordingly, we can formulate the following definition of context, which agrees with most of the research work developed in the last years:
Context-aware applications are those having the ability to detect, interpret and react to aspects of a user's preferences and environment characteristics, device capabilities, or network conditions by dynamically changing or adapting their behavior based on those aspects that describe the context of the application and the user.
A more generic definition of context-aware applications can be used, which doesn't make any explicit reference to adaptation capabilities. Quoting [2]:
A system is context-aware if it uses context to provide relevant information and/or services to the user.
Whereas this is sufficiently generic to include the previous definition or other possible ones, for the purpose of this chapter the first definition is used. This is due to the fact that the objective is to outline the ways of using contextual information to assist and enhance adaptation operations in order to ultimately improve the quality of the user experience, while also satisfying restrictions imposed by DRM on the use of protected content. Accordingly, this chapter focuses on the use of context information to react to the characteristics and conditions of that context and trigger adequate adaptation operations.
Early definitions of context were limited, or specific to a given application, as they were usually made by taking examples of the type of context information being used. Research work around context-aware services was focused in the mobile applications area, mainly on processing information regarding the location and type of device being used to receive and present the content. The work evolved, not only in the mobile communications area, but in others too. Other types of information collected through various sensors started to be used. One example is the area of human computer interfaces (HCI), where information regarding user genre and age, emotions, disabilities, and environmental conditions was used to adapt an application's interface to their particular usages. However, the above definition is more generic as it does not depend on the type of additional information being used to deliver the service, but rather on the effects that information may have on its behavior.
[3] provides a good generic definition of context that can be applied no matter what the type of information being used or the application in use may be. This is probably the most quoted definition of context:
Context is any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and application themselves.
This definition implicitly states that any application using additional information with the capacity to condition the way the user interacts with the content is context-aware.
Contextual information can be any kind of information that characterizes or provides additional information regarding any feature or condition of the complete delivery and consumption environment. This diversity of information can be grouped into four main context classes: Computing, User, Physical, and Time. The first group addresses the characteristics, capabilities, and conditions of the resources that can or must be used to provide the context-aware service. Although the word “computing” could be interpreted as referring exclusively to the terminal device, in fact it has a broader scope, as it refers to all resources involved in the delivery of the service: the terminal where the content is to be consumed, the network through which the content is to be delivered, and any additional service or engine that might provide added value to the multimedia service. Accordingly, we will rename this group “Resources”. Below, some examples of the types of contextual information that fall into each of these four categories are provided:
- Resources Context:Description of the terminal in terms of its hardware platform, including any property, such as processor, screen size, and network interface; description of the terminal in terms of its software platform, such as operating system, software multimedia codecs installed, and any other software application; description of the network, such as maximum capacity, instantaneously-available bandwidth, and losses; description of multimedia servers, for example in terms of maximum number of simultaneous users or maximum throughput; description of transcoding engines in terms of their hardware and software platforms, such as network interface, input/output formats allowed, and bit-rate range supported.
- User Context:Description of the user's general characteristics, such as gender, nationality, and age; description of the preferences of the user related to the consumption of content, such as type of media and language preferred; description of the preferences of the user in terms of their interests, related to the high-level semantics of the content, such as local news versus international news, or action movies versus comedy; description of the user's emotions, such as anxious versus relaxed, or happy versus sad; description of the user's status, such as online versus offline, or stationary versus walking; description of the history/log of actions performed by the user.
- Physical Context:Description of the natural environment surrounding the user, such as lighting and sound conditions, temperature, and location.
- Time Context:Indication of the time at which variations in the context occurred, and scheduling of future events.
Besides these different types of contextual information, which together can describe any entity involved in the delivery and consumption of the multimedia content, another dimension of the contextual information should also be considered. This other dimension refers to the characteristics and nature of the contextual information itself, and not to the type of entity that it describes. In this dimension, the following aspects should be considered:
- The accuracy or level of confidence of the contextual information.
- The period of validity: Contextual information may be static, thus having an unlimited validity period, or it may be dynamic and valid for only a given period of time. For example, general characteristics of the user are obviously static and do not require any additional information to be used; on the other hand, the user's emotions will essentially be dynamic. Likewise, conditions of the natural environment such as lighting or background noise will also be dynamic.
- The dependencies on other types of contextual information: Reasoning about one type of contextual information may depend on other types.
Most of these different types of contextual information and their characteristics can be seen as low-level or basic, in the sense that they can be directly generated by some software or hardware appliance. Based on this basic contextual information, applications may formulate higher-level concepts. Of the several examples given above, clearly only some can be seen as being high-level. This is the case, for example, with some descriptions within the User Context, such as those concerning the emotions of the user and their physical state. This information can be inferred by analyzing low-level contextual information obtained by imaging and sound sensors. Location information belonging to the Physical Context can be low-level contextual information when expressed, for example, by geographic coordinates, or high-level context when referring to the type of physical space the user is in (e.g. indoor versus outdoor, train station, football stadium, etc.). Context-aware applications must thus initially acquire any contextual information, then process it, reason about it to formulate concepts, and take decisions on when and how to react. Furthermore, the acquisition of context, at least of some types of contextual information, must be a continuous (periodic or not) process, so that changes in the context may be perceived by the application. Of course, the process of reasoning about the basic contextual information will also be a continuous process, which will be conducted whenever changes in the basic contextual information are detected. The three phases are sometimes designated as sensing the low-level context, generating higher-level contextual information, and sensing the context changes.
Considerable research work has been conducted worldwide on context-awareness in various areas. Until recently, one of the main challenges faced in context-aware computing was the lack of standardized models to represent, process, and manage contextual information. Using proprietary formats and data models does not allow different systems to interoperate, and thus seriously limits the use of context in distributed heterogeneous environments. Although recently standardization bodies such as the World Wide Web Consortium (W3C) and Motion Picture Experts Group (MPEG) have started working on specifications to represent and exchange context, the mechanisms that are provided for establishing relationships among contextual information and constraints are still very limited. They provide efficient frameworks to develop moderately simple context-aware systems, but they do not address more complex and demanding context-aware applications, which in turn fail to provide the required support to represent additional information about context (as referred to above) or to reason about it. Ongoing major standardization efforts in the area of context representation are described in Section 11.2.2. In an attempt to overcome these limitations, researchers have been studying and proposing the use of ontologies to build context-aware systems. Ontologies provide the means to establish relationships between contextual information reasoning and formalizing of concepts. Thus, they enable the building of complex context models based on knowledge. Moreover, the use of ontologies based on open formats and with good declarative semantics can be the vehicle to achieve interoperability, enabling different systems to reason about the available information, using the part relevant to their contexts.
The use of ontologies to provide efficient and comprehensive models to build context-aware systems seems indeed to be one of the most important issues currently being addressed by researchers working in this area.
[4] discusses the suitability of using ontologies for modeling context-aware service platforms. It investigates the use of Semantic Web technologies
[5] to formalize the properties and structure of context information in order to guarantee common understanding. The Context Ontology Language (CoOL) is an example of a context-oriented ontology approach developed recently.
[6] presents an approach to context mediation by developing a model using the Web Ontology Language (OWL) [5]. The idea is to provide a common open model that can promote interoperability between systems using context information and operating in heterogeneous environments such as the Web.
[7] proposes an extensible context ontology to build context-aware services and allow their interoperability in an ambient intelligence environment. Its proposal is to define a core ontology based on OWL and built around four major entities, among which the user assumes the central role. This ontology defines concepts and their relationships for each of these four entities, trying to address commonly-accepted basic needs of the majority of context-aware applications, while providing the flexibility to scale to new requirements.
[8] defines a context space and formulates a conceptual model for context-aware services. The idea is to build a methodology for designing context-aware services, providing guidelines on the selection of context information and adaptation alternatives. The model can also be used to assess the developed context-aware services.
[9] has developed work for context-awareness applications in the area of pervasive computing. The research group at the College of Computing at Georgia Institute of Technology was involved in diverse projects concerning context-aware applications in different domains, including personal location-aware services and context-aware services for elderly people in the home environment. The motivation of the research in this group is the development of intelligent services for the elderly and/or physically-impaired. The initial focus of context-aware research was on the use of location information to build context-aware services. The work evolved to design a more generic platform to assist the implementation of context-aware applications. Its outcomes will be further cited in the next subsection, when describing the Context Toolkit.
[10] describes a CoOL derived from its proposed approach to model context. It develops an aspect-scale-context (ASC) model where each aspect can have several scales to express some context information. The ASC model can be very interesting for implementing semantic-services discovery using context.
11.2.1.2 Architectures and Frameworks
In parallel to the recent activity on the use of ontologies to develop meaningful and efficient models to support the mediation of context, research groups have also engaged in the development of generic architectures and frameworks, in many cases also using the ontology-based model approach, to support the implementation of context-aware applications.
[11] has investigated flexible architectures using Web Services technologies to allow a dynamic extension of the type of context information without the need to introduce modifications to the systems providing the context-aware applications. In this work, a platform has been built where all the pre- and post-processing of the context information is performed by context plug-ins and context services, which communicate with the core system via Web Services. [11] defines its own extensible Markup Language (XML) schema to specify the syntax and semantics of the context information passed on to the platform. It does not contemplate the problem of the quality of the service, nor the use of feedback to assess the results.
[12] has also investigated the impact of using context information on the core system for the delivery of services. This work proposes a flexible architecture that can easily be extended to use different types of context information. It is developed within the framework of the Simple Environment for Context-Aware Systems (SECAS) project. This project aims at defining ways of capturing context and passing it to the application, which uses it to perform adaptation operations that suit the context of usage. One of the main concerns is to evaluate the impact of using contextual information at the application level. The SECAS architecture is illustrated in Figure 11.2.
SECAS uses context brokers in charge of collecting contextual information, a context provider module that encapsulates the contextual information in an XML document, and a context interpreter that maps low-level contextual parameters' values to a high-level representation. While this architectural approach is interesting from the viewpoint of isolating the higher layers of the application from the modules that actually retrieve and process context, it requires each application or service to register itself in the context mediation platform, indicating what type of contextual information will be of value for it. This requires that applications are aware of the type of contextual information that can be generated and assumes that there are rather static relationships between context characteristics/conditions and the service being delivered. It somehow limits the flexibility of the application to react differently according to various user profiles, or even according to the type of content being used by the service or the available adaptation mechanisms. Some of these limitations could be overcome by allowing applications to frequently update their registration parameters. However, this does not contribute to the performance of the system, and does not account for personalized adaptation.

Figure 11.2 The SECAS functional architecture [12]
[13] and [14] report the work conducted by the Distributed Systems and Computer Networks (DistriNet) group of the Department of Computer Science at the Katholieke Universiteit Leuven, in consortium with other institutions, within the projects Context-Driven Adaptation of Mobile Services (CoDAMoS) and Creation of Smart Local City Services (CROSLOCIS). In the first project, the group developed a middleware framework, designated context gatherer, interpreter, and transformer, using ontologies (CoGITO) [15] to allow the creation of context-aware mobile services in ambient intelligence environments, where it was assumed that a user was surrounded by other multimedia-enabled devices. Figure 11.3 shows a simplified view of the CoGITO architecture.
This work focuses on the possibility of transfering services to nearby devices or replacing a component to save resources. The middleware includes a specific context-aware layer that detects changes in the context of the user and accordingly initiates service relocation and/or replacement of components. In CROSLOCIS, the main focus is on the development of a service architecture that enables the creation of context-aware services, providing the mechanisms to collect, safely distribute, and use contextual information while respecting privacy issues.
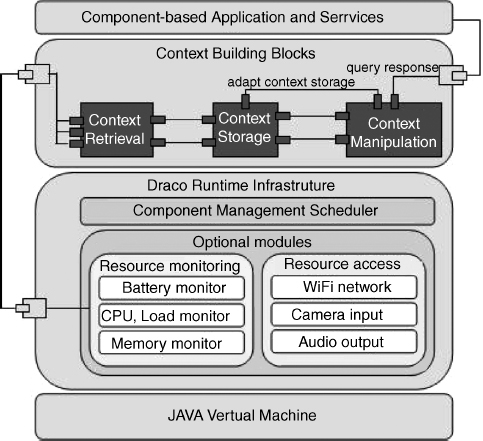
Figure 11.3 Simplified representation of the CoGITO middleware

Figure 11.4 The use of CoBrA for context-aware applications [16]
The Context Broker Architecture (CoBrA) project developed by the ebiquity group at the University of Maryland [16] is an agent-based architecture that supports context-aware systems in smart spaces. It uses the OWL to define a specific ontology for context representation and modeling, enabling the description of persons, intentions, and places. Figure 11.4 illustrates the use of CoBrA for the development of context-aware applications, showing its layered architecture.
An intelligent agent, designated context broker, maintains a model of the context that can be shared by a community of agents, services, and devices present in the space. The system provides mechanisms to ensure privacy protection for users. The project particularly focuses on the intentions of the sensed users, and not on describing system or device characteristics and capabilities.
The Context Toolkit [17] is a framework developed to assist the implementation of context-aware applications. It offers a distributed architecture that interconnects a series of software appliances, designated as context widgets. These software components work as plug-ins to contextual information sources, enabling applications to access different types of contextual information. They can be seen as services providing a uniform and seamless interface to various sensing devices, isolating the applications from the specificities of the context sensors. The services offered by the Context Toolkit and implemented through the widgets include access to network-related contextual information through a network application programming interface (API), and the storage of contextual information. Figure 11.5 presents the conceptual architecture of the Context Toolkit in terms of its functional components.
The Service-Oriented Context-Aware Middleware (SOCAM) framework [19] defines a service-oriented architecture for building high-level context-aware applications using an ontology-based reasoning based on W3C specifications. The SOCAM platform is based on four major modules:

Figure 11.5 The functional blocks of the Context Toolkit [18]
- a context provider
- a context interpreter
- a context database
- a service discovery engine.
Figure 11.6 presents the different components that form the SOCAM platform.

Figure 11.6 Components of the SOCAM architecture [20]
In SOCAM, the role of the CxP is to abstract the applications that process the contextual information from the devices that actually sense the low-level context. Applications can access a CxP service by querying the service discovery engine. The context interpreter conducts logic-reasoning to obtain a higher-level context, using a context ontology stored in the context database.
Several other research groups worldwide have performed investigations on these topics and are still making efforts to build intelligent systems that produce contextual information and react to context changes while focusing on designing middleware layers that allow interoperability with multiple external sensing devices. Such is the case with the project Oxygen at the Massachusetts Institute of Technology (MIT) Media Labs [21], the project CoolTown at Hewlett Packard (HP) Research [22], and the International Business Machines Corporation (IBM) project BlueSpace [23].
Most early context-aware projects were developed within the mobile services application domain. They tried mostly to explore context to improve usability aspects by sensing how the available devices were being used. Generally, they reacted directly to the sensed low-level context. They usually lacked flexibility as they did not make use of ontologies or made only a rather static and limited use of ontologies. Therefore, they did not explore the inter-relations among different types of low-level contextual information, and thus did not sufficiently address the aspects of interoperability, scalability, and security/privacy. In fact, earlier research was typically application-centric, overlooking aspects of gathering different types of contextual information from different spaces, and interoperability in heterogeneous environments. Likewise, aspects concerning the security of content and context metadata, and ensuring the privacy of the user, have only recently started to be addressed. The new generation of projects are now focusing on these aspects, relying on the use of standard ontology specifications, context representation frameworks, and middleware layers. Such is the case with the CoBrA and SOCAM projects.
The current state of research in context-awareness can be summarized as follows:
- The first generation of context-aware systems was mainly concerned with improving usability aspects by directly using individual low-level or explicit contextual information, among which location was assumed to play a central role.
- The second-generation systems focused on abstracting the application from the specificities of the process of sensing the low-level contextual information. They also explored the inter-relations between different types of low-level contextual information, incorporating functionalities to build higher-level or implicit context information. This generation focused on aspects of interoperability at the system level, and on the gathering and use of explicit contextual information from multiple sources.
- The third-generation systems are now focusing on inferring more complex implicit contexts using ontologies that also take into consideration security and privacy issues. Interoperability continues to be a central concern. Accordingly, current research is also looking at context representation through the development of formal specification frameworks. Common ontologies are also a vehicle for enabling interoperability from the semantic point of view. Different applications can use different sets of rules to reason about the same set of low-level contexts using the same ontology.
11.2.2 Standardization Efforts on Contextual Information for Content Adaptation
This subsection describes the recent developments made in relevant international standardization bodies, namely the W3C with its Composite Capability/Preferences Profiles (CC/PP) specification, and the International Organization for Standardization/International Electro-technical Commission (ISO/IEC) MPEG with the MPEG-7 and MPEG-21 Digital Item Adaptation (DIA) standards. In addition to providing support for standardized basic context descriptors essential for the implementation of content adaptation operations, MPEG-21 DIA also provides the means to describe how those descriptors contribute to the authorization of adaptation operations (in Amendment 1). MPEG-21 is the standard adopted in this chapter for describing the content adaptation platform. As such, this subsection provides a succinct description of the most relevant DIA tools, indicating their functionality and scope of application. A description of the W3C standards is also included, due to the wide applicability of these standards and their considerable importance within the Semantic Web paradigm. We start by making reference to MPEG-7, notably its Part 5, Multimedia Description Schemes (MDS), since it is probably the most comprehensive multimedia description standard. It has a wide scope of applicability, in particular in content adaptation applications. MPEG-7 MDS provides support for the description of user preferences and usage history, as well as for adaptation tools [24]. Additionally, the MPEG-21 standard makes use of these kinds of MPEG-7 description tools within the same scope.
It should be emphasized that this subsection does not aim to provide a full description of the standards referred to. Instead, it aims at highlighting some specific features of each standard that can play an important role in the development of context-aware content adaptation systems. For a full description of each standard, the reader should refer to the official documentation and other publications given in the references section of this chapter.
11.2.2.1 MPEG-7
MPEG-7 [25,26] is a very comprehensive multimedia description standard that provides the mechanisms to describe information about the content (also referred to as contextual information of the content within the traditional content description environments, such as libraries) and about the information contained within the content. The first class of descriptions includes, for example, the author of the content and its creation date. The second class includes in reality three different types of description capabilities: 1) low-level features of the content, such as color histogram, motion intensity, and shot boundary detections; 2) structural information related to the encoding parameters, such as coding scheme and aspect ratio format (also referred to as media characteristics); 3) high-level semantics describing the nature of the content (for example, “quiet open-air scene with bright blue sky and green grass fields”).
Within the scope of content adaptation applications, MPEG-7 plays an important role in describing information about the content, notably related to the format of the content, i.e. to the technical parameters with which the content is encoded, and to its media characteristics. This kind of description can also be used to describe the capabilities of the AEs, as in fact what is necessary to know is the range of encoding parameters in which each specific AE can work. Part 5 of the MPEG-7 standard (MPEG-7 MDS) [26] provides the framework for the description of these kinds of feature. For example, the possible variations that can be obtained from a given content can be described using the MPEG-7 variation description tool. Moreover, one of the attributes of this tool, namely the variation relationship attribute, is able to specify the type of operation that needs to be performed to obtain a specific variation. Types of operation specified include transcoding, which in turn may involve modification of the spatio-temporal resolution; bit-rate color depth; transmoding or summarization; and so on [27–29]. When the type of adaptation is a transcoding operation, applications may use the tool transcoding hints, which provides guidelines on how to implement the transcoding operation, so that the quality may be preserved or low-delay and low-complexity requirements may be met.
11.2.2.2 MPEG-21
MPEG-21 [30,31] is the ISO/IEC standard, currently in its final phase of development in MPEG. It focuses on the development of an extensive set of specifications, descriptions, and tools to facilitate the transaction of multimedia content in heterogeneous network environments.
The standard is currently divided into 18 parts. The basic concepts of MPEG-21 are the User and the Digital Item (DI). The User is any type of actor that manipulates content, be it a person or a system (e.g. subscriber, producer, provider, network). A DI is the smallest unit of content for transaction and consumption, and at the conceptual level it can be seen as a package of multimedia resources related to a certain subject (e.g. MPEG-2 video stream, Moving Picture Experts Group Layer 3 Audio: audio file format/extension (MP3) file, a set of Joint Photographic Experts Group (JPEG) pictures, text file, etc.), together with associated descriptions (e.g. rights descriptions, other context descriptors, MPEG-7 audio and video descriptors, etc.), including the respective digital item declaration (DID). Part 2 of the standard, namely Digital Item Declaration Language (DIDL), specifies a standardized method based on XML schema for declaring the structure of the DI. Inside this XML document (i.e. the DID), standard MPEG-21 mechanisms are used to either convey resources and descriptions embedded directly in the DID or provide information on the location of the resources to be fetched. The DID provides an indication of the structure of the DI as well as of the relationships among its several constituents. A DI is thus used to create the concept of a package or single unit, around which a variety of multimedia information is bound by some common attribute. Figure 11.7 illustrates the concept of the MPEG-21 DI.
Part 7 of the standard, namely DIA [32,33] provides a set of tools allowing the description of the characteristics and capabilities of networks, terminals, and environments, as well as of the preferences of users. In addition, this set of tools also provides the definition of the operations that can be performed upon the content and the results that can be expected. Figure 11.8 provides an illustration of the available tools in MPEG-21 DIA and its use for adaptation purposes.
Among others, specific adaptation tools and descriptions of the MPEG-21 DIA standard, such as usage environment descriptor (UED), adaptation quality of service (AQoS), and universal constraints descriptor (UCD), define a set of descriptors and methodologies to describe the context of usage, the operations that can be performed upon the content, and the result that can be expected. Accordingly, these tools can be used to implement context-aware content adaptation systems. They can be used to analyze the current status of the consumption environment and decide upon the need to perform adaptation, including the type of adaptation to perform. The outcome of this process can be used to notify encoders or servers, receivers or intermediate AEs, to adapt the stream to particular usage constraints and/or user preferences. The former can include, for example, the available network bandwidth and terminal display capabilities. The latter can indicate the removal of undesired objects from an MPEG-4 video scene or the filtering out of some of the media components of a DI.

Figure 11.7 Example of an MPEG-21 digital item (DI)
In addition, MPEG-21 DIA provides the means to enable finer-grained control over the operations that can be performed when interacting with the content (e.g. playing, modifying, or adapting DIs) in the form of declarative restrictions and conversion descriptions.

Figure 11.8 Tools and concepts of MPEG-21 DIA. Reproduced by Permission of ©2007 IEEE

Figure 11.9 Concept of DIA
Systems adopting this approach are able to produce different results according to the diverse usage environment constraints and/or user preferences/profiles upon the same query. The concept of the adaptation within MPEG-21 is illustrated in Figure 11.9. Adaptation of DIs involves both resource and descriptor adaptation. Various functions, such as temporal and spatial scaling, cropping, improving error-resilience, prioritization of parts of the content, and format conversion, can be assigned to the AE. Implementation of an AE has not been normatively defined in the MPEG-21 standard, and therefore many technologies can be utilized.
As illustrated in Figure 11.8, Part 7 of the MPEG-21 standard, DIA, specifies the following set of eight tools to assist adaptation operations:
- UED, usage environment description tools: To provide descriptions related to user characteristics, terminal capabilities, network characteristics, and natural environment characteristics.
- AQoS, terminal and network quality of service tools: To provide descriptions of QoS constraints, the adaptation operations capable of meeting those constraints, and the effects of those adaptations upon the DI in terms of its quality.
- UCD, universal constraints description tools: To allow descriptions of constraints on adaptation operations, and a control over the types of operation that are executed upon the content when interacting with it.
- BSDL (Bitstream Syntax Description Language) and gBS (generic Bitstream Syntax) tools: To provide the means to describe the high-level structure of bitstreams using XML and XML schemas. Their goal is to allow the manipulation of the bitstreams through the use of editing-style operations (e.g. data truncation) with a format-agnostic processor. Thus, they provide the means to manipulate the content at the bitstream syntax level.
- Metadata adaptability tools: To provide information that can be used to reduce the complexity involved in adapting the metadata contained in a DI, allowing the filtering and scaling of metadata as well as the integration of XML instances.
- Session mobility tools: To provide the means to transfer state information, regarding the consumption of a DI, from one device to another.
- DIA configuration tools: To carry information required for the configuration of DI AEs.
Among the above tools, the first three provide the core support for building context-aware content adaptation systems by describing both the characteristics of the usage environment, as well as of the operations that can be performed on the multimedia content, and the expected results. Their use enables a decision mechanism to select the adaptation operation that satisfies the constraints of the consumption environment while maximizing a given parameter or utility. This utility is most often realized as the quality of the service or the quality of the user experience. These tools are briefly described below. Furthermore, a description of the BSDL and gBS tools is also included, as they provide support for the implementation of adaptation operations that are independent of the format of the resources to be adapted. As such, in spite of the fact that they are particularly suited for use with scalable formats, they can also be used in a great variety of situations.
UED Tools
UED tools allow the description of characteristics of the environment in which the content is consumed, notably the capabilities of the terminal, the characteristics of the network, and information regarding the user and their surrounding natural environment.
- Terminal capabilities:Refers to the capabilities of the terminal where the content is to be consumed, in terms of the types of encoded format that are supported (i.e. “codec capabilities”), the display and audio output device characteristics and several input devices (i.e. “input–output (I/O) capabilities”), and finally physical characteristics of the terminal, such as the processing power, amount of available storage and memory, and data I/O capabilities (i.e. “device properties”).
- Network characteristics:Includes a description of the static attributes of the network, such as maximum channel capacity (i.e. “network capabilities”), and a description of parameters of the network that may vary dynamically, such as instantaneous available bandwidth, error rate, and delay (i.e. “network conditions”). The former tools are used to assist the selection of the optimum operation point during the setup of the connection, whereas the latter ones are used to monitor the state of the service and update the initial setup accordingly.
- User characteristics:There are four different subsets of descriptions that fall into this category, as follows:
- (i) A generic group of descriptions using MPEG-7 description schemes (DS), more precisely the “user agent” DS. This group provides information on the user themselves, as well as indications of general user preferences and usage history.
- (ii) A second subset of descriptions, which is related to the preferences of the user regarding the way the audiovisual (AV) information is presented, such as audio power and equalizer settings, or video color temperature, brightness and contrast, and so on.
- (iii) A third subset of descriptions, which provide indications regarding auditory and visual impairments of the user, such as hearing frequency thresholds or deficiencies in the perception of colors.
- (iv) A final subset of descriptions related to the instantaneous mobility and destination of the user.
- Natural environment characteristics: Provides information regarding the characteristics of the natural environment surrounding the user who wishes to consume the content. Using MPEG-7 DSs, this provides information regarding the location and the time at which the content is consumed, and information describing AV attributes of the usage environment, such as noise levels experienced in the surrounding environment or the light/illumination conditions.
Figures 11.10 and 11.11 show example excerpts of UED files, describing characteristics of a terminal and the conditions of a network, respectively.
AQoS and UCD Tools
The main purpose of adapting the content is to provide the user with the best possible experience in terms of perceived quality. The perceived quality is greatly conditioned by the instantaneous availability of network and terminal resources, despite also being highly subjective to the user and a number of factors pertaining to their surrounding environment. To cope with varying network and terminal conditions, it is possible to envisage a number of different reactive measures or operations to perform upon the content in most cases. The MPEG-21 DIA standard provides a mechanism that enables decisions on which of those reactive measures to endorse in a given situation, while maximizing the user experience in terms of perceived quality. Through the inclusion of descriptors that indicate the expected result in terms of quality for a set of different operations performed upon the content under certain context usage constraints, ADEs can obtain the best possible operation point and the correspondent transformation to perform. This is accomplished through the AQoS and UCD description tools. The former provides the indication of different sets of encoding parameters and the resulting quality of the encoded bitstream for each of those sets. The latter enables the transformation of that information, together with the information about the current conditions of the usage context conveyed as UED, into the form of restrictions that can further be used by the ADEs.

Figure 11.10 Excerpt of a terminal UED

Figure 11.11 Excerpt of a network UED
Bitstream Syntax Description (BSD) Tools
Within large-scale networked video communications, when some kind of adaptation to the content needs to be performed due to a quality drop, it may prove to be quite difficult to gain access to transcoders or media processors that are able to actually understand the specifications of a particular encoding scheme in order to process and adapt the original encoded bitstream. Quite often, it would be desirable to alter the characteristics of the video bitstream along the transmission chain, but only at specific points so as not to interfere with users sharing the same content who are happy with the level of service quality that they are experiencing. This requires the availability of content adaptation gateways placed along the distribution chain, which have the ability to process specific encoding formats. Given the large number of existing encoding formats and their variants, it may prove to be cumbersome to have such media gateways. In addition, the solution is not easily expandable or scalable towards new encoding formats. One much better approach is to enable the processing of encoded bitstreams without the need to actually understand their specific encoding syntaxes, i.e. in a format-agnostic way.
BSD tools of the MPEG-21 DIA provide the means to convey a description of the encoded bitstream using XML, and to perform the transformation of this description in the XML space. This can be done, for example, through the use of eXtensible Stylesheet Language Transformation (XSLT). The adapted bitstream is then generated from the original bitstream but using the modified description. Figure 11.12 illustrates this process.
In order to be able to generate universally-understandable descriptions of specific encoding schemes, the standard has developed an XML-based language, the BSDL. To generate generic descriptions of binary sources independently of the encoding format, the standard has specified the schema gBS. The description of the syntax of the specific encoding of a bitstream is generated at the encoder side as a BS schema. The schema either travels together with the bitstream or is requested when needed. It essentially provides a high-level description of the structure or organization of the bitstream. Therefore, it only allows for simple adaptation operations, such as filtering, truncation, and removal of data. Nonetheless, more advanced forms are possible when using the gBS schema. This tool enables the use of semantic labels and the establishment of associations between those labels and syntactical elements being described. In addition, it provides the means to describe the bitstream in a hierarchical way. BSD tools can be used with any kind of encoding format, but are extremely interesting when used with scalable encoding formats, as they may enable very simple operation. For example, when the constraints of the environment impose a reduction on the bit rate, having a description of the syntax of the scalable bitstream greatly simplifies the role of an AE in identifying the layer(s) to be dropped.

Figure 11.12 Editing-like content adaptation using BSDL and gBS
Worldwide research groups are investigating the use of the tools specified in the MPEG-21 standard to develop efficient AEs and improve the proposed approaches [24,34–43].
DANAE (Dynamic and distributed Adaptation of scalable multimedia coNtent in a context-Aware Environment) [39,40], an Information Society Technologies (IST) European Commission (EC) co-funded project, addressed the dynamic and distributed adaptation of scalable multimedia content in a context-aware environment. The objective of DANAE was to specify and develop an advanced MPEG-21 infrastructure for such an environment, so as to permit flexible and dynamic media content adaptation, delivery, and consumption. The goal was to enable end-to-end quality of multimedia services at a minimal cost for the end user, with the integration of features and tools available from MPEG-4 and MPEG-7, and DRM support in the adaptation chain. The system focused on DIA and digital item processing (DIP – specified in Part 10 of the MPEG-21 standard), and contributed to the MPEG-21 standardization efforts. DANAE supports the application of DIP for DIA to adapt DIs in a globally-optimized and semantically-aware way in order to allow a dynamic change in the usage context, as well as to enable the adaptation of live content, such that the content may be delivered while still being created.
The ENTHRONE project [41,42], another IST project co-funded by the EC under Framework Programme (FP) 6, has developed a content mediation and monitoring platform based on the MPEG-21 specifications and distributed technologies. The ENTHRONE platform features a core system designated “ENTHRONE Integrated Management Supervisor (EIMS)”, which maintains distributed databases and repositories of MPEG-21 DIs, and enables customized access to them by multiple users through heterogeneous environments and networks. The EIMS incorporates an ADE that uses MPEG-21 DIA tools, notably UED, UCD, and AQoS. The ENTHRONE ADE transforms the UEDs that it receives into UCDs. Different UEDs are used: one to express the capabilities of terminals and the user preferences generated at the consumption peer; another to express the capabilities of available AEs; and a third to express the condition of the network. Thus, the ADE transforms the characteristics of the current usage environment into a constraint representation. It then uses AQoS to describe the operations that can be performed upon the content (i.e. the possible variations of the content through their characteristics, such as frame rate, aspect ratio, and bit rate) and the result in terms of quality that can be obtained with each variation. Although the project provides a complete framework for the generation and management of, and customized access to, multimedia content using the MPEG-21 specifications, the work of ENTHRONE in content adaptation to date has been limited to altering the encoding parameters of each media resource.
The Department of Information Technology (ITEC) at the Klagenfurt University is actively contributing to the development of the MPEG-21 specifications, in particular those that aim to assist the context-aware adaptation of content. This research group has implemented MPEG-21 applications, such as multimedia adaptation tools (e.g. gBSDtoBin, BSDLink Webeditor) and the ViTooKi operating system, which provides the support for describing terminal capabilities and user preferences using MPEG-21 [43].
The Catalan Integrated Project aims to develop an advanced Internet environment based on a universal multimedia access (UMA) [33,44] concept using MPEG-21 standard tools. The project intends to employ the MPEG-21 and MPEG-7 standards extensively for the adaptation decision-taking procedures, which will select the best adaptation of a specific content, taking into account network characteristics, terminal capabilities, and the state of the AV content transcoding servers.