
Channel Extensibility by Example
Before jumping into code, we need to lay a foundation. We will build an intuition using examples and then identify an extensible architecture for a channel. With the architecture in place, alternatives to creating extensions become clear. These alternatives serve to clarify our understanding by showing other ways to achieve the same result.
Scenario: Accepting Custom Data from a Business Partner
A financial broker needs to send its stream of transactions for trades through our fictitious company, illustrated in Figure 18.1. Presumably, we will do something useful with them. They use the financial standard for trades, the Financial Information Exchange (FIX) messaging standard. FIX is a compact, binary message format; it is not XML. See http://www.fixprotocol.org for details, though no FIX expertise is required for this chapter.
Figure 18.1. Scenario for accepting custom business data.
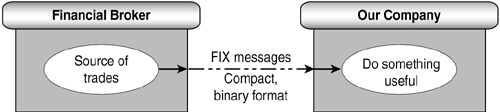
It is useful to see what happens when we try to send the stream of FIX messages into BizTalk. The point that we fail is precisely the point where we will build an extension.
A standard setup, using BizTalk terminology in italics, is as follows:
The Home Organization is our company.
A new organization represents the financial broker in the diagram.
A new channel represents the stream of FIX messages, the dashed line in the diagram, from the financial broker. We need a receive function to accept an external data feed and route data to our channel.
A new port serves as the endpoint for the channel. The port delivers the data to an internal process per the rightmost solid line in the diagram.
An XLANG schedule handles the FIX data as an internal process within the Home Organization, per the rightmost oval in the diagram.
Working through the setup, we trip creating the channel. The channel requires a document definition for data entering the channel and another document definition for data leaving the channel to arrive at the corresponding port.
The problem is that the document definition must be for a supported format: XML, EDIFACT, X12, comma-delimited, or position-based flat file.
Ultimately, the data arriving to the XLANG schedule must be in XML. A mechanism for parsing the inbound FIX format into XML is required. We will use the IBizTalkParserComponent interface later in this chapter for this purpose.
Scenario: Producing Custom Data for a Business Partner
Extending the first scenario, Figure 18.2 shows a financial broker that sends us trade data and expects us to be a link in a chain. Trade data is to be routed through us. We perform our really useful function and then continue the trade data on its route to another financial broker, possibly modifying the trade data as we go. In this scenario, we must format FIX data.
Figure 18.2. Scenario for producing custom business data.

A standard setup, using BizTalk terminology in italics, is as follows:
A new organization represents the second financial broker.
A new channel receives output from the XLANG schedule.
A new port serves as the endpoint for the new channel. The port delivers the data to the new organization.
We trip in this setup for the same reason in the first scenario. Document definitions for data entering and exiting the new channel must be available. The definition for the data outbound to the second financial broker is not possible because it uses the nonsupported FIX format.
A mechanism for serializing the outbound FIX format is required. We will use the IBizTalkSerializerComponent interface later in this chapter for this purpose.
Scenario: Using Business Logic to Transform Data
The trade information needs classification before the XLANG schedule processes it internally. By classification, we mean analyzing the data to calculate a value from some predetermined category, such as HighPriority, Normal, and LowPriority. Classification and ranking are common functions requiring rules specific to a business.
The classification will help simplify the decision nodes on the BizTalk Orchestration diagram, illustrated in Figure 18.3. A single decision node can select among all possible classification values, similar to a C++ switch statement or a VB select case statement.
Figure 18.3. A Decision node on a BizTalk Orchestration diagram.

Using BizTalk maps, we can apply our business rules in the channel. The order is important. The data arrives in the channel using a format defined by an external organization. The data leaves the channel in a format needed internally by a BizTalk Orchestration schedule.
In general, BizTalk maps allow for a flexible data transformation within the channel. This transformation connects an external interface with a trading partner to an internal interface of a business process. The internal interface becomes more important when multiple channels provide the data in different formats such as from different trading partners. A map in each channel can normalize to comply with a single internal interface.
A mechanism for applying business rules in maps is required. We will use the IFunctoid interface later in this chapter for this purpose.
General Scenario
In general, the three preceding scenarios reveal the need for the channel to have an extensible structure. Figure 18.4 diagrams the composite scenario.
Figure 18.4. General scenario for the BizTalk channel.
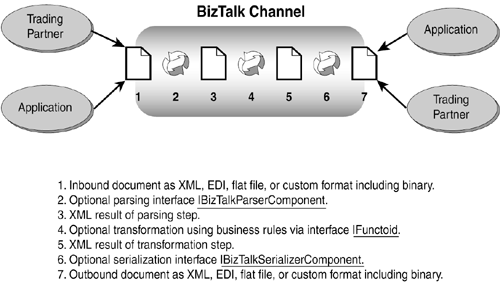
The channel supports two data formats, one inbound and one outbound. A transformation between the two formats can occur inside the channel. The inbound data can have a custom parser to recognize its format. The outbound data can have a custom serializer to render its format. The transformation from inbound format to outbound format can use custom business logic.
Depending on the setup for the channel, the inbound data and outbound data represent public or private interfaces. Public means visible to a trading partner; private means visible to internal applications only. Table 18.1 gives three channel setups.
| Channel Setup | Type of Interface | ||
|---|---|---|---|
| From | To | for Inbound Data | for Outbound Data |
| Trading partner | Internal application | Public | Private |
| Internal application | Trading partner | Private | Public |
| Internal application | Internal application | Private | Private |
When a channel flows data from a trading partner to an internal business process, the inbound data represents a public interface, and the outbound data represents a private interface.
Conversely, when a channel flows data from an internal business process to a trading partner, the inbound data represents a private interface, and the outbound data represents a public interface.
Alternatives to the Extensibility Model
With the extensibility model in place, it is useful to consider programmatic alternatives. These alternatives clarify our understanding by offering other ways to achieve the same result.
The most straightforward alternative to parsing the inbound flow is to intercede before the data arrives at the channel. In the case where data arrives from a trading partner, we need to change the receive function. For example, if we use a queue-based receive function, then whatever code we have posting messages to the queue can parse before posting. Likewise, serialization can occur after data leaves the channel.
The drawback to this approach is a lack of integration. BizTalk has document tracking features for data inside the channel. BizTalk offers a closed environment where a trading partner can submit data in its format directly into a BizTalk channel. This closed environment has other advantages such as reliable delivery and auto-restart. Any componentry inserted between the trading partner and BizTalk poses risks to integrity.
BizTalk provides an integrated alternative to parsing. A receive function can have a preprocessor. An example use is to decompress data before submitting to BizTalk. For more on preprocessors, find the interface IBTSCustomProcess in the product documentation.
The drawback to the preprocessor becomes clear when we design a parser later in this chapter. For example, the preprocessor offers simple data conversion, whereas the parser can structure data into groups.
Considering functoids, there is a functionally equivalent alternative. The Scripting functoid allows an arbitrary script to be used. Later in this chapter, we will see that IFunctoid too must use script in its implementation.
The drawback to the Scripting functoid is usability. With IFunctoid, we can integrate into the user interface of BizTalk Mapper. The Scripting functoid contains the script as a property, which means that reuse requires cut-and-paste.
A second alternative to a custom functoid is available if there is also the custom parsing step. We can eliminate the functoid entirely by performing all custom transformations in the parsing step.
The advantage is performance. Functoids must be script, which means that BizTalk must load a scripting engine as well as execute a slower code set.
The disadvantage is a loss of modularity by mixing public and private interfaces, per Table 18.1. For example, suppose that one trading partner submits the binary FIX format and another submits with another format. The classification functoid from the earlier scenario now has two implementations. One implementation is in the FIX-to-XML parser. The other implementation is in the parser yielding XML from the other financial format. Performance versus modularity is a common trade-off.