
4.9 Error Concealment Using a DVC Approach for Video Streaming Applications
(Portions reprinted, with permission, from R. Bernardini, M. Fumagalli, M. Naccari, R. Rinaldo, M. Tagliasacchi, S. Tubaro, P. Zontone, “Error concealment using a DVC approach for video streaming applications”, EURASIP European Signal Processing Conference, Poznan, Poland, September 2007. ©2007 EURASIP.)
The general framework proposed in [34] considers an MPEG-coded video bitstream which is sent over an error-prone channel with little or no protection; an auxiliary bitstream, generated using Wyner–Ziv coding, is sent for error resilience. At the decoder side, the error-concealed decoded MPEG frame becomes the side information for the Wyner–Ziv decoder, which further enhances the quality of the concealed frame. The auxiliary Wyner–Ziv stream is generated by computing parity bits of a Reed–Solomon code, where the systematic data consists of a downsampled, coarsely-quantized version of the original sequence, together with mode decisions and motion vectors. This scheme works with a fixed rate allocated at the encoder, which does not depend on the actual distortion induced by the channel loss.
If the packet loss rate (PLR) is known, together with the error concealment technique used at the decoder, the ROPE algorithm [35] allows the distortion estimation of a decoded frame without a direct comparison between the original and the decoded signal. In other words, it can estimate, at the encoder side, the expected distortion at the decoder. In its former version [35], the ROPE algorithm performed this estimation by considering integer pixel precision for motion compensation in the video coder. Since half-pixel precision is widely adopted by standard coders, we use the half-pixel precision version of ROPE presented in [36].
A forward error-correcting coding scheme that employs an auxiliary redundant stream encoded according to a Wyner–Ziv approach is proposed. The block diagram of the proposed architecture is depicted in Figure 4.45. Unlike [34], turbo codes to compute the parity bits of the auxiliary stream are used. The proposed solution works in the transform domain, by protecting the most significant bitplanes of DCT coefficients. In order to allocate the appropriate number of parity bits for each DCT frequency band, a modified version of ROPE that works in the DCT domain [25] is used. The information provided by ROPE is also used to determine which frames are more likely to suffer from drift. Therefore, the auxiliary redundant data is sent only for a subset of the frames. We also show how prior information that can be obtained at the decoder, based on the actual error pattern, can be used to efficiently help turbo decoding.

Figure 4.45 Overall architecture of the proposed scheme. Reproduced by permission of ©2007 EURASIP
4.9.1 Proposed Technical Solution
To evaluate the number of Wyner–Ziv parity bits which should be transmitted into the auxiliary bitstream, the expected frame distortion in the DCT domain is estimated. Such distortion estimation is computed by means of the ROPE algorithm [35], which requires knowledge of the transmission channel packet loss rate and of the error concealment strategy used at the decoder. In its first and basic formulation, the ROPE algorithm estimates the expected distortion in the pixel domain and considers video coding with integer-precision motion vectors (MVs). As mentioned before, integer-precision MVs may lead to unacceptable coding performance. In this work, we extend the ROPE algorithm to half-pixel precision, as proposed in [36]. To calculate the expected frame distortion at the decoder in the DCT domain, the EDDD (expected distortion of decoded DCT-coefficients) algorithm [37] is used. This method requires the expected frame distortion in the pixel domain calculated by the ROPE algorithm as input, and outputs the expected distortion of the coefficients in the transform domain. Figure 4.46 shows the rate estimator module and highlights its inputs and its output, i.e. the expected channel induced distortion Di,j(t) for each DCT coefficient, defined as:
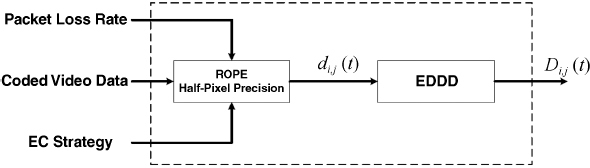
Figure 4.46 Rate estimator module for the expected distortion in DCT domain
where i = 0,…, K − 1 denotes the block index within a frame and j = 0,…, J is the DCT coefficient index within a block. ![]() represents the reconstructed DCT coefficient at the encoder at time t, while
represents the reconstructed DCT coefficient at the encoder at time t, while ![]() is the co-located coefficient reconstructed at the decoder, after the error concealment. (Reproduced by permission of ©2007 EURASIP.)
is the co-located coefficient reconstructed at the decoder, after the error concealment. (Reproduced by permission of ©2007 EURASIP.)
The estimated values of Di,j(t) represent the channel-induced distortion only, and they are obtained as follows: let c, q denote, respectively, transmission and quantization errors, supposed uncorrelated. For each (i, j) DCT coefficient, it is possible to write at the encoder:
where Xi,j(t) is the original DCT coefficient. (Reproduced by permission of ©2007 EURASIP.)
At the decoder, it comes out:
The total distortion at the decoder is given by:
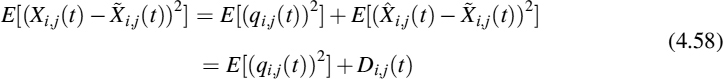
where the left hand side of Equation (4.58) is unknown and represents the variance of drift, provided by EDDD (for details, see [27]). The first term on the right hand side can be approximated by knowing the quantizer step size Δ as E[(qi,j(t))2] = Δ2/12, by assuming uniformly distributed quantization noise.
The distortion Di,j(t) is then used to compute the number of transmitted parity bits, to correct the tth error-concealed decoded frame ![]() into a “cleaner” version X′(t), as will be seen later.
into a “cleaner” version X′(t), as will be seen later.
The proposed scheme is depicted in Figure 4.46. The input video signal is independently coded with a standard motion-compensated predictive (MCP) encoder and a Wyner–Ziv encoder. The generated bitstreams are transmitted over the error-prone channel, characterized by a packet loss probability pl. At the receiver side, the decoder decodes the primary bitstream and performs error concealment. A motion-compensated temporal concealment that can briefly be summarized as follows is used:
- If a macroblock (MB) is lost (this happens with probability pl) then it is replaced with the one in the previous frame, pointed by the motion vectors of the MB above the one under consideration.
- If the MB above the one being concealed is lost too (this happens with probability
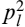 ) then the current MB is replaced with the homologue in the reference frame.
) then the current MB is replaced with the homologue in the reference frame.
The Wyner–Ziv encoder is similar to the one described in [25], with the difference that in [25] the side information is generated at the decoder by motion-compensated interpolation, while here the side information is the concealed reconstructed frame at the decoder ![]() . To prevent mismatch between the encoder and decoder, a locally decoded version of the compressed video
. To prevent mismatch between the encoder and decoder, a locally decoded version of the compressed video ![]() is used as input to the Wyner–Ziv encoder, rather than the original video sequence X(t).
is used as input to the Wyner–Ziv encoder, rather than the original video sequence X(t).
At the encoder, Wyner–Ziv redundancy bits for frame ![]() are only generated if the expected distortion at the frame level is above a predetermined threshold, i.e. only if:
are only generated if the expected distortion at the frame level is above a predetermined threshold, i.e. only if:

Otherwise, no redundancy bits are transmitted. This allows us to concentrate the bit budget on those frames that are more likely to be affected by drift.
To generate the Wyner–Ziv bitstream, DCT is applied to the frame ![]() of the locally decoded sequence; the transform coefficients are grouped together to form coefficient subbands; each subband is then quantized using a dead-zone uniform quantizer, and for each subband the corresponding bitplanes are independently coded using a turbo encoder. The parity bits relative to all the DCT coefficients of each 8 × 8 block are transmitted. In the proposed scheme, the expected distortion that EDDD computes to adaptively estimate the number of parity bits that are required by the Wyner–Ziv decoder is used. As a matter of fact, it is expected that if the distortion calculated by ROPE increases, the rate required by the decoder for exact reconstruction will increase too. At the encoder it is possible to estimate the expected distortion for each DCT coefficient, denoted by Di,j(t). Since encoding is performed by grouping together DCT coefficients belonging to the same subband j, first the average distortion for each subband is computed as:
of the locally decoded sequence; the transform coefficients are grouped together to form coefficient subbands; each subband is then quantized using a dead-zone uniform quantizer, and for each subband the corresponding bitplanes are independently coded using a turbo encoder. The parity bits relative to all the DCT coefficients of each 8 × 8 block are transmitted. In the proposed scheme, the expected distortion that EDDD computes to adaptively estimate the number of parity bits that are required by the Wyner–Ziv decoder is used. As a matter of fact, it is expected that if the distortion calculated by ROPE increases, the rate required by the decoder for exact reconstruction will increase too. At the encoder it is possible to estimate the expected distortion for each DCT coefficient, denoted by Di,j(t). Since encoding is performed by grouping together DCT coefficients belonging to the same subband j, first the average distortion for each subband is computed as:

then the expected crossover probability for each bitplane b of each subband j, ![]() , is obtained. To this end, a Laplacian distribution is assumed for the error
, is obtained. To this end, a Laplacian distribution is assumed for the error ![]() .
.
The distribution parameter αj(t) is derived by the expected distortion ![]() as
as ![]() . The joint knowledge of the Laplacian distribution and of the quantizer used allows us to estimate the crossover probability
. The joint knowledge of the Laplacian distribution and of the quantizer used allows us to estimate the crossover probability ![]() for each bitplane. Therefore, it is possible to calculate
for each bitplane. Therefore, it is possible to calculate ![]() , and using this value the bits
, and using this value the bits ![]() that an ideal receiver needs to recover the original bits are estimated. Note that
that an ideal receiver needs to recover the original bits are estimated. Note that ![]() is the amount of redundancy required by a code for a symmetric binary channel achieving channel capacity.
is the amount of redundancy required by a code for a symmetric binary channel achieving channel capacity.
The encoder transmits about ![]() parity bits1 for each bitplane and subband, until the auxiliary stream bit budget RWZ(t) is exhausted. First, the parity bits of the most significant bitplane of all J DCT subbands are sent. Then encoding proceeds with the remaining bitplanes. The encoder also transmits the average distortion computed by the rate estimator module, i.e.
parity bits1 for each bitplane and subband, until the auxiliary stream bit budget RWZ(t) is exhausted. First, the parity bits of the most significant bitplane of all J DCT subbands are sent. Then encoding proceeds with the remaining bitplanes. The encoder also transmits the average distortion computed by the rate estimator module, i.e. ![]() , since it is exploited by the turbo decoder as explained below. Note that, as was analyzed in [38], by fixing the rate at the encoder, a significant improvement – the transmission rate for a single bitplane never exceeds 1 – is obtained. In fact, if the estimated rate is greater than 1, it is convenient to transmit the uncoded bits. At the receiver side, the Wyner–Ziv decoder takes the concealed frame
, since it is exploited by the turbo decoder as explained below. Note that, as was analyzed in [38], by fixing the rate at the encoder, a significant improvement – the transmission rate for a single bitplane never exceeds 1 – is obtained. In fact, if the estimated rate is greater than 1, it is convenient to transmit the uncoded bits. At the receiver side, the Wyner–Ziv decoder takes the concealed frame ![]() and transforms it using a block-based DCT. The transform coefficients are then grouped together to form the side information subbands
and transforms it using a block-based DCT. The transform coefficients are then grouped together to form the side information subbands ![]() . The received parity bits are used to “correct” each subband
. The received parity bits are used to “correct” each subband ![]() into
into ![]() . Turbo decoding is applied at the bitplane level, starting from the most significant bitplane of each subband. In the proposed system, the turbo decoder exploits the received distortions estimated at the encoder
. Turbo decoding is applied at the bitplane level, starting from the most significant bitplane of each subband. In the proposed system, the turbo decoder exploits the received distortions estimated at the encoder ![]() in order to tune the correlation statistics between the source
in order to tune the correlation statistics between the source ![]() and the side information
and the side information ![]() . Therefore, adaptivity is guaranteed at both subband and frame level.
. Therefore, adaptivity is guaranteed at both subband and frame level.
In addition, it is proposed to exploit the knowledge of the actual error pattern, which is available at the decoder only. In fact, the decoder knows exactly which slices are lost, and can perform an error-tracking algorithm in order to determine which blocks might be affected by errors. Apart from the blocks belonging to lost slices, those blocks that depend upon previously corrupted blocks are flagged as “potentially noisy”. The error tracker produces, for each frame, a binary map that indicates whether the reconstructed block at the decoder might differ from the corresponding one at the encoder. The algorithm is similar to the one presented in [39], with the important difference that, in this case, error tracking is performed at the decoder only. The turbo decoder can take advantage of this information by adaptively setting the conditional probability to 1 for those coefficients that are certainly correct. This means that the turbo decoder totally trusts the side information in these cases.
After turbo decoding, some residual errors might occur if the number of received parity bits is not sufficient for the exact reconstruction of every bitplane. In this case, the error-prone bitplane is not considered in the reconstruction process; only the bits of the correctly decoded bitplanes are regrouped, and the ML reconstruction is finally applied (see [25]). Error detection at the turbo decoder is performed by monitoring the average of the modulus of the LAPP, as described in [19].
Finally, once Wyner–Ziv decoding is successfully completed, the reconstructed frame X′(t) is copied into the buffer of the MCP decoder, to serve as reference frame at time t + 1. This way the amount of drift propagated to successive frames is reduced.
4.9.2 Performance Evaluation
In these simulations, the input video signal is compressed using an H.263 + video coder with half-pixel precision motion estimation. The compressed bitstream is transmitted using the primary channel. The auxiliary bitstream carries Wyner–Ziv redundancy bits, which are used at the decoder to correct the bitplanes of the DCT coefficients of the side information, i.e. of the reconstructed frames after concealment.
For the first set of simulations, 30 frames of the QCIF Foreman sequence are considered. The Foreman sequence is coded at 30 fps, QP = 4, and GOP size = 16. Each slice comprises one row of 16 × 16 macroblocks, with nine slices per frame. For transmission, one slice per packet is sent, and a packet loss probability pl = 10% is assumed, with independent losses.
As mentioned above, Wyner–Ziv redundancy bits are not sent when the expected distortion estimated by ROPE is below a certain threshold, which represents the minimum acceptable quality at the decoder. Note that such a threshold could be computed by the encoder on the basis of the average expected distortion for past frames. In these experiments, the encoder does not send Wyner–Ziv bits when D(t) < τ, where τ is empirically determined for each sequence. When Wyner–Ziv bits are transmitted, the number of bits is set to ![]() , where
, where ![]() ranges from 2 to 4 depending on
ranges from 2 to 4 depending on ![]() . The values
. The values ![]() are set on the basis of operational curves of the turbo coder performance for a binary symmetric channel with crossover probability
are set on the basis of operational curves of the turbo coder performance for a binary symmetric channel with crossover probability ![]() .
.
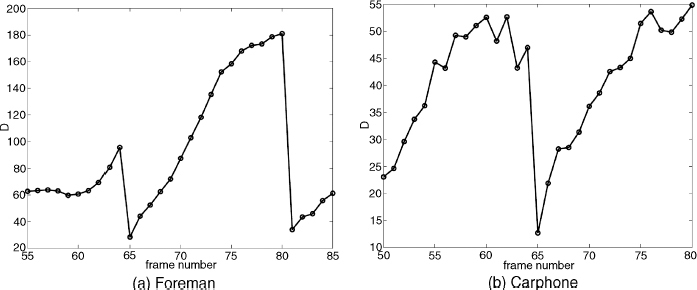
Figure 4.47 Expected distortion given by ROPE for 30 frames of the Foreman and Carphone sequences
In the following, the proposed scheme is compared with one using the H.263 + intra-MB refresh coding option, where error resilience is obtained by coding, in each frame, a certain number of MBs in intra-mode. The proportion is chosen to spend roughly the same additional bit rate as required by the Wyner–Ziv redundancy stream. Figure 4.47(a) shows the ROPE expected distortion for frames 55–85 of the Foreman sequence. For this sequence, τ is equal to 80 (equivalent to an expected PSNR equal to 30 dB).
Figures 4.48 and 4.49 show the PSNR performance of the proposed scheme and the required rate. The results are obtained as the average of 30 different channel simulations. In this experiment, the main H.263 + stream has an average bit rate R = 568 kbps. An additional 63 kbps (equivalent to approximately 11% of the original rate) are spent for the auxiliary Wyner–Ziv-coded stream, for a total rate R = 631 kbps. Figure 4.48 also shows the PSNR for H.263 +, when the intra-MB refresh rate has been set equal to 6 to achieve approximately the same rate (R = 624 kbps) as the proposed scheme.
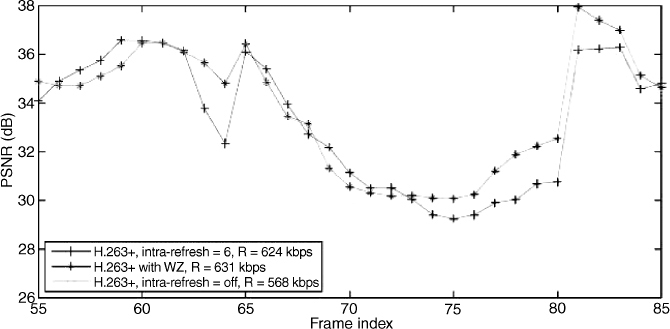
Figure 4.48 PSNR evolution for 30 frames of the Foreman sequence
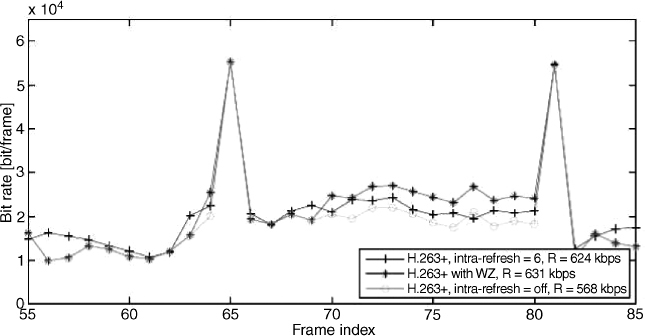
Figure 4.49 Frame-based bit-rate allocation for 30 frames of the Foreman sequence

Figure 4.50 PSNR for 30 frames of the Carphone sequence. Reproduced by permission of ©2007 EURASIP
It is apparent from the figures that the proposed scheme has comparable or better performance than the scheme using the intra-MB refresh procedure. In this respect, note that the intra-MB refresh procedure has to be used at coding time. In the proposed scheme it is possible to start from a precoded sequence (the most common situation for video transmission) instead, and add Wyner–Ziv bits for protection.

Figure 4.51 Frame-based bit-rate allocation for 30 frames of the Carphone sequence. Reproduced by permission of ©2007 EURASIP
Similar results can be seen in Figures 4.50 and 4.51, where 30 frames of the Carphone sequence are considered. In this case, the main H.263 + stream is encoded at a rate R = 294 kbps. An additional 89 kbps are added as Wyner–Ziv parity bits to achieve an overall rate equal to 386kbps. When intra-MB refresh is used, the refresh rate is set to 8. The ROPE expected distortion for the Carphone sequence is depicted in Figure 4.47(b). In this case, no parity bits are sent when the D(t) is below 35.